
原文摘要翻译
最先进的视觉-语言-动作(VLA)模型在语义泛化方面表现出色,但在新环境中难以泛化到未见过的物理动作。我们提出了 DreamZero,一种基于预训练视频扩散主干网络构建的世界动作模型(WAM)。与 VLA 不同,WAM 通过预测未来世界状态和动作来学习物理动力学,利用视频作为世界演化的密集表征。通过联合建模视频和动作,DreamZero 能够有效地从异构机器人数据中学习多样化技能,而无需依赖重复的演示数据。这使得在真实机器人实验中,相比于最先进的 VLA,对新任务和新环境的泛化能力提升了超过 2 倍。重要的是,通过模型和系统优化,我们使得一个 140 亿参数的自回归视频扩散模型能够以 7Hz 的频率进行实时闭环控制。最后,我们展示了两种跨形态迁移形式:来自其他机器人或人类的纯视频演示,仅需 10--20 分钟的数据,即可在未见任务上获得超过 42% 的相对性能提升。更令人惊讶的是,DreamZero 支持少样本的具身适应,仅需 30 分钟的随操作数据即可迁移到新的具身形体,同时保留零样本泛化能力。
从流匹配数学原理到跨本体迁移的工程实现------World Action Model如何突破VLA的泛化瓶颈

引言:VLA的"物理盲区"与WAM的范式转移
当前SOTA的Vision-Language-Action (VLA)模型(如RT-2、π₀、GR00T N1)展现出惊人的语义理解能力------你可以指令它"将可乐罐移到Taylor Swift照片旁",它能借助VLM预训练的互联网知识识别目标并完成操作。然而,当面对"解开鞋带"这类未见过的物理动作时,VLA会彻底失效。
根本症结 :VLA继承自Vision-Language Model (VLM),而VLM的训练数据是静态图文对 。它理解"鞋带"的语义,却缺乏对"解"这一动作的时空几何、动力学与运动控制 的表征。正如NVIDIA GEAR Lab在《World Action Models are Zero-shot Policies》中指出的:VLM先验编码了"做什么"(what),却缺乏"怎么做"(how)的物理直觉。
DreamZero提出了World Action Model (WAM) 范式:不再是直接从视觉映射到动作,而是先预测未来世界状态(视频),再从中提取动作 。这种"世界模型+逆动力学"的架构,让14B参数的视频扩散模型首次实现了零样本物理泛化 ------在未见任务上取得比SOTA VLA高2倍 的成功率,并能通过30分钟数据适应全新机器人本体。
一、数学基础:联合视频-动作预测的生成模型
1.1 问题形式化:分解联合分布
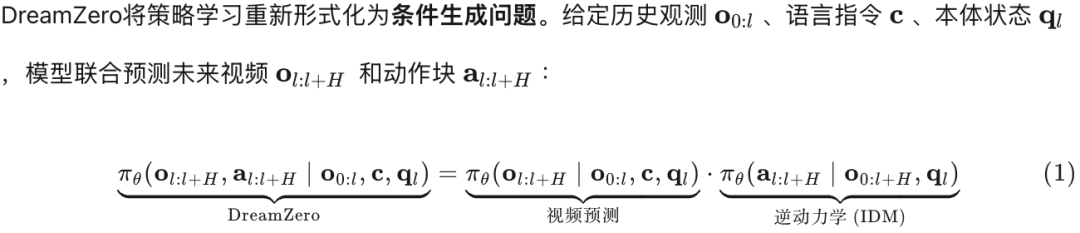
关键洞察:公式(1)右侧的分解揭示了WAM的本质------视频预测作为隐式视觉规划器,动作预测作为逆动力学提取器。这种分解允许模型利用互联网视频预训练优化左侧乘数(世界模型),再通过少量机器人数据对齐右侧乘数(动作策略)。
1.2 流匹配训练目标(Flow Matching)

二、算法实现:训练与推理的流程细节
算法1:Chunk-wise Flow Matching训练
python
# 输入: 轨迹数据 {(o_t, a_t, c, q_t)}_{t=0}^T
# 超参数: Chunk大小 H=24, Chunks数 K
for step in range(N):
# 1. 采样轨迹和起始点
traj = sample_trajectory()
l = random.randint(0, T - H*K)
# 2. VAE编码观测,归一化动作
z_clean = VAE_encode(traj.observations[l:l+H*K]) # [K, H, D]
a_clean = normalize_actions(traj.actions[l:l+H*K])
# 3. 分块处理
chunks_z = split_into_chunks(z_clean, H)
chunks_a = split_into_chunks(a_clean, H)
loss = 0
context = [] # 干净历史缓存
for k in range(K):
# 4. 采样共享时间步(标准版)或解耦时间步(Flash版)
t_k = random.uniform(0, 1)
# 5. 添加噪声(公式2)
z_noise, a_noise = randn_like(chunks_z[k]), randn_like(chunks_a[k])
z_t = t_k * chunks_z[k] + (1 - t_k) * z_noise
a_t = t_k * chunks_a[k] + (1 - t_k) * a_noise
# 6. 计算目标速度
v_target = torch.cat([chunks_z[k] - z_noise, chunks_a[k] - a_noise], dim=-1)
# 7. 前向传播(带因果注意力掩码)
v_pred = model(z=z_t, a=a_t, context=context, instruction=c,
proprio=traj.proprio[l+k*H], timestep=t_k)
# 8. 流匹配损失(公式3)
loss += w(t_k) * MSE(v_pred, v_target)
# 9. Teacher Forcing:使用真实数据更新上下文
context.append((chunks_z[k], chunks_a[k]))
loss.backward()
optimizer.step()
算法2:闭环自回归推理
python
# 输入: 初始观测 o_0, 指令 c, 初始状态 q_0
kv_cache = initialize_cache()
obs_history = [o_0]
while not task_done:
# 1. 编码当前观测历史
z_context = VAE_encode(obs_history)
# 2. 自回归生成未来chunks(使用KV Cache)
actions_chunk = []
for k in range(num_chunks):
z_future, a_future = autoregressive_denoise(
model, context=kv_cache, instruction=c,
proprio=current_proprio, num_steps=16 # 或4步(Flash模式)
)
actions_chunk.append(a_future)
kv_cache.update(z_future) # 更新缓存
# 3. 异步执行动作块(48步@30Hz = 1.6秒)
robot.execute_async(concatenate(actions_chunk))
# 4. 闭环修正:获取真实观测替换预测
sleep(1.6)
real_obs = robot.get_observation()
obs_history.append(real_obs)
kv_cache.replace_last_frame(VAE_encode(real_obs)) # 关键:防止误差累积

三、架构创新:自回归DiT与DreamZero-Flash
3.1 自回归vs双向:模态对齐的关键
DreamZero采用**自回归DiT(Diffusion Transformer)**而非双向扩散,基于三个关键考量:
| 特性 | 双向扩散(BERT-style) | 自回归(DreamZero) |
|---|---|---|
| 上下文长度 | 固定,需降采样 | 任意长,支持历史累积 |
| 帧率保持 | 必须降采样(30fps→10fps) | 原生帧率 ,精确时序对齐 |
| 误差累积 | 无法闭环修正 | KV Cache替换 真实观测 |
| 推理效率 | O(N)历史处理 | O(1)增量生成 |
模态对齐的物理意义 :动作与视频必须在时间维度 上精确对齐。双向模型为适配固定窗口需降采样视频,破坏"手爪闭合"与"视觉接触"的毫秒级对应关系。自回归架构通过KV Cache保留所有历史帧的原生表示,确保动作生成与视频帧的逐帧对齐。
3.2 注意力掩码策略
DreamZero使用非对称QKV注意力掩码:
-
因果掩码:当前chunk只能attend到之前chunks的干净表示
-
跨模态约束 :动作token可以attend到视频token(逆动力学),但视频token不能attend到动作token
这确保了视频预测作为"领导者",动作预测作为"跟随者",符合物理因果(世界状态变化先于动作执行)。
3.3 DreamZero-Flash:解耦噪声调度
标准扩散模型需16步去噪迭代,难以满足实时控制(目标<200ms)。DreamZero-Flash 通过解耦噪声调度实现单步/4步推理:
训练-推理不匹配问题:

Beta分布偏置策略:

四、系统优化:38倍加速的工程实现
DreamZero通过三级优化将14B模型的推理延迟从5.7秒 降至150毫秒(38倍加速):
| 优化层级 | 具体技术 | GB200加速比 | 延迟 |
|---|---|---|---|
| 系统级 | CFG并行(双GPU分布) | 1.8× | 3.0s |
| + DiT缓存(速度方向一致性复用) | 5.4× | 1.05s | |
| 实现级 | + Torch Compile/CUDA Graphs | 10.9× | 520ms |
| + 内核优化(cuDNN注意力) | 14.8× | 385ms | |
| + NVFP4量化(权重/激活4位) | 16.6× | 343ms | |
| 模型级 | + DreamZero-Flash(单步推理) | 38× | 150ms |
关键技术细节:
-
DiT缓存:利用流匹配中速度预测的方向一致性,当相邻步骤速度余弦相似度>阈值时复用缓存,将有效步数从16降至4
-
异步执行:动作块执行(1.6秒)与推理并行,实现7Hz有效闭环控制
-
闭环修正:每执行完一块动作,用真实观测替换KV Cache中的预测帧,防止误差累积
五、实验验证:数据、结果与消融
5.1 数据集:异构性优先于重复性
DreamZero在AgiBot G1上收集的数据呈现高度异构性:
-
时长分布:平均每片段4.4分钟,包含~42个子任务(远高于DROID的短片段)
-
环境覆盖:22个独特环境(家庭、餐厅、超市、咖啡店、办公室)
-
技能分布:导航、躯干调整(适应高度)、双臂/单臂操作
核心原则 :任务多样性 > 重复性。不追求"叠衬衫重复100次",而是收集"100种不同交互各执行1次"的真实世界数据。
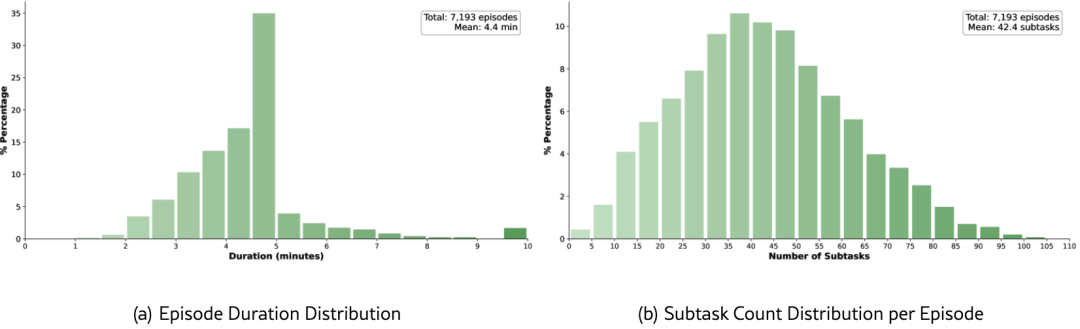
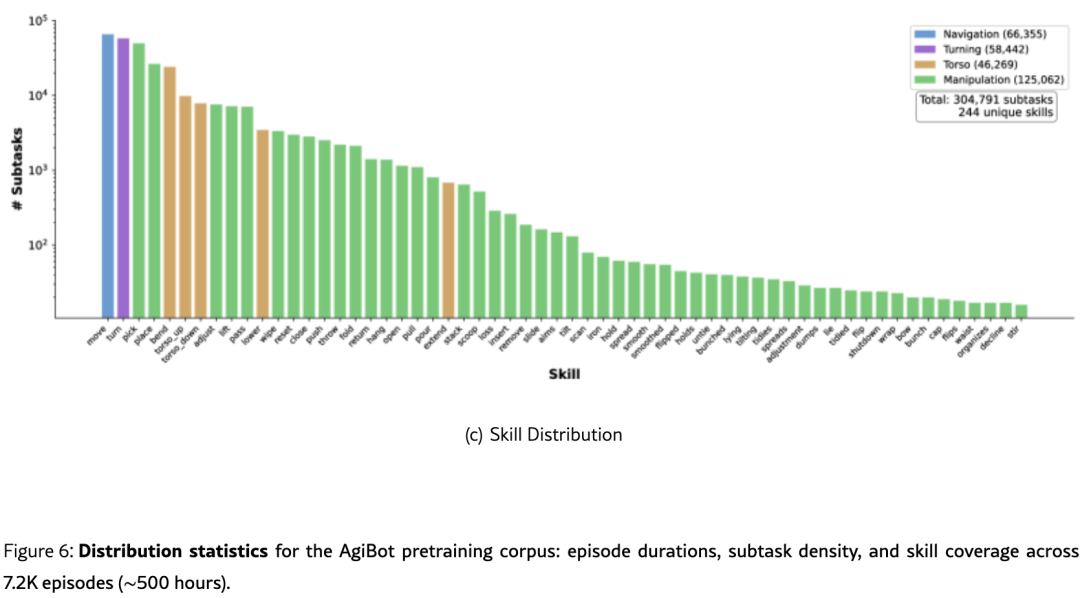
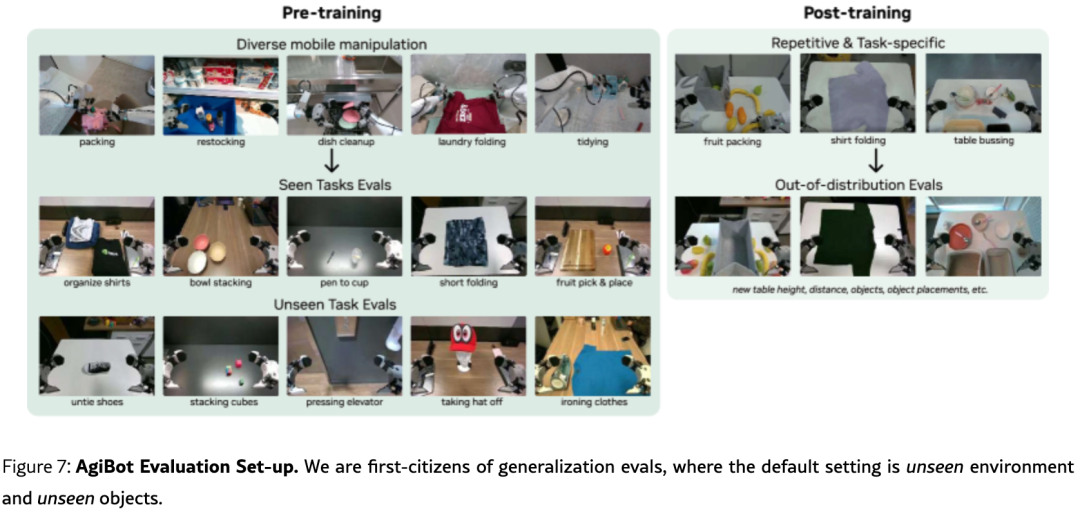
5.2 主实验详细说明
本实验旨在系统验证 World Action Model(WAM)相比传统 Vision-Language-Action(VLA)模型在数据效率、零样本泛化及微调稳定性上的优势。实验采用双阶段训练策略 (预训练→微调)和双平台验证(AgiBot G1 移动双臂机器人 + Franka 单臂机器人),构建了从通用物理理解到特定任务适应的完整评估体系。
1. 机器人平台与数据收集哲学
实验在两个截然不同的机器人本体上进行,以验证方法的跨平台适用性:
AgiBot G1(移动双臂机器人)
-
数据量:约 500 小时(7.2K episodes),自行采集
-
环境覆盖:22 个真实场景(家庭、餐厅、超市、咖啡店、办公室)
-
核心特点:
-
长程异构:每个 episode 平均 4.4 分钟,包含约 42 个子任务(远超传统数据集的短片段)
-
多样化优先:刻意避免单一任务的重复演示,采集真实场景中的实用行为轨迹
-
技能分布:导航(移动工作空间)、躯干调整(不同高度操作)、物体操作
-
Franka(固定单臂机器人)
-
数据量:使用公开 DROID 数据集(最具异构性的开源机器人数据)
-
目的:验证方法在公开可复现数据上的有效性
2. 预训练阶段:通用物理理解
训练配置
-
骨干网络:Wan2.1-I2V-14B-480P(140亿参数图像到视频扩散模型)
-
初始化:利用 Web-scale 视频预训练权重,继承物理动态先验
-
训练步数:100K 步(AgiBot 和 DROID 各 100K 步)
-
Batch Size:全局 128
-
可训练参数:所有 DiT 块、状态编码器、动作编码器/解码器(冻结文本/图像编码器及 VAE)
对比基线设置为公平比较,对 SOTA VLA 模型(GR00T N1.6 和 π₀.₅)设置两种初始化:
-
Scratch:仅使用预训练 VLM 权重,无机器人数据预训练
-
Pretrained:使用已在数千小时跨机器人数据上预训练的官方 checkpoint
3. 评估协议:零样本泛化测试
默认评估设置 :未见环境 + 未见物体(训练与评估在不同地理位置进行,确保分布外测试)
任务分类:
-
Seen Tasks:训练分布内的任务(如拾取放置、擦拭桌面)
-
Unseen Tasks:全新任务(如解鞋带、熨衣服、从人体模型摘帽子等)
4. 微调阶段:特定任务适应与泛化保持
在预训练基础上,针对三个具体任务进行微调,验证任务专业化 与环境泛化的平衡:
微调任务数据(AgiBot G1)
| 任务 | 数据量 | 特点 |
|---|---|---|
| Shirt Folding | 33小时 | 5个顺序折叠阶段,2种衬衫类型,随机初始位置 |
| Fruit Packing | 12小时 | 10个水果装袋,随机组合和位置 |
| Table Bussing | 40小时 | 5件垃圾+5件餐具分类,随机物体类型和位置 |
训练配置
-
训练步数:每个任务 50K 步
-
参数更新:与预训练阶段一致(更新 DiT 块及状态/动作编码器)
-
评估重点 :在全新环境中测试任务完成进度(Task Progress),检验微调后是否仍保持环境泛化能力
5. 实验核心假设与验证逻辑
本实验设计围绕三个核心假设展开验证:
-
数据多样性优于重复性:通过对比"多样化异构数据"与"重复演示"的预训练效果,验证 WAM 能否打破"通用策略需要大量重复演示"的传统认知。
-
视频预训练先验的不可替代性:通过对比 DreamZero(视频扩散初始化)与 VLA(VLM 初始化)在相同数据下的表现,证明视频生成能力对物理动态理解的关键作用。
-
微调不损泛化 :通过微调后在未见环境中的测试,验证 WAM 的世界建模目标使模型学习"物理规则本身"而非特定环境的视觉特征,从而避免 VLA 常见的"微调即过拟合"问题。
5.3 已见任务表现
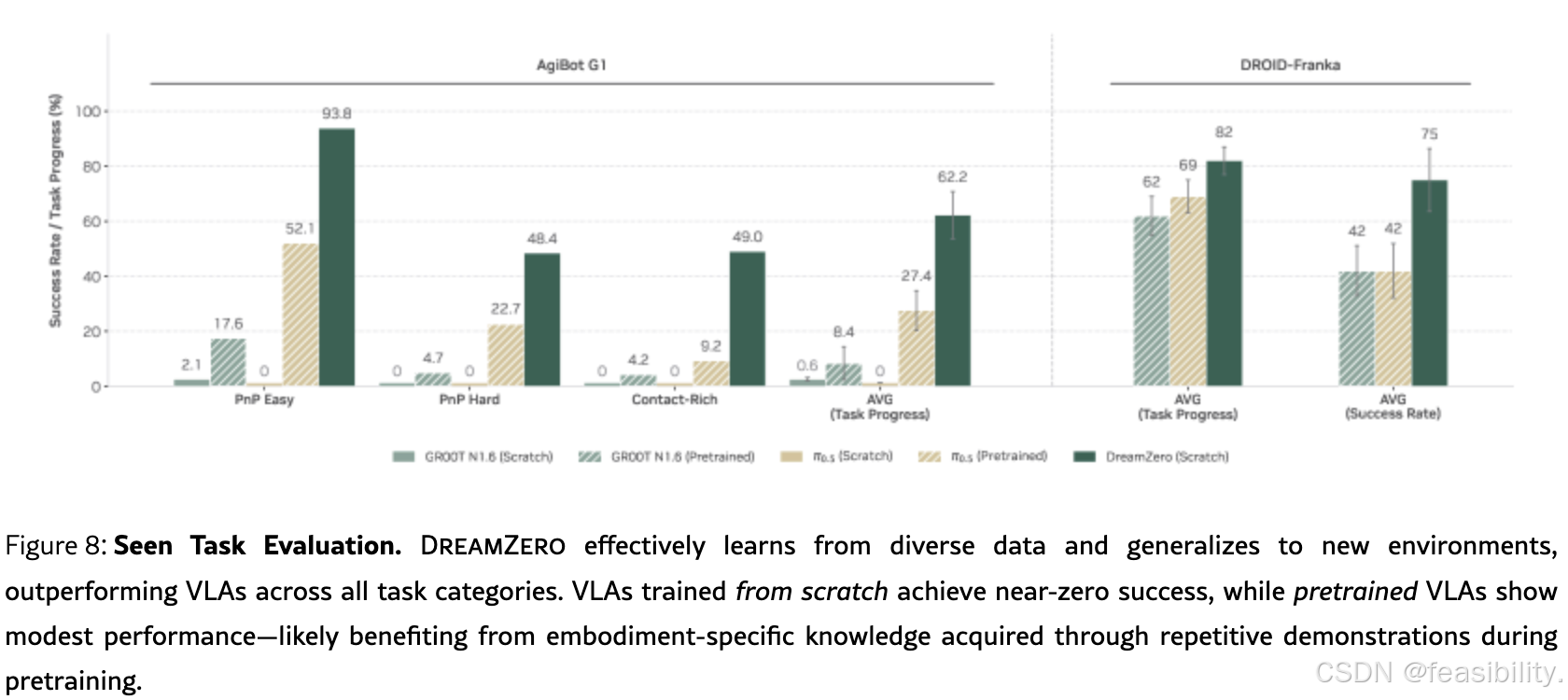
AgiBot G1上的对比(深绿色为DreamZero):
| 任务类别 | DreamZero | π₀.₅ (Pretrained) | GR00T N1.6 (Pretrained) | 倍数提升 |
|---|---|---|---|---|
| PnP Easy | 93.8% | 52.1% | 17.6% | 1.8× vs π₀.₅ |
| PnP Hard | 48.4% | 22.7% | 4.7% | 2.1× vs π₀.₅ |
| Contact-Rich | 49.0% | 9.2% | 4.2% | 5.3× vs π₀.₅ |
| AVG (Task Progress) | 62.2% | 27.4% | 8.4% | 2.3× vs π₀.₅ |
关键发现:
-
在接触丰富任务(Contact-Rich,如折叠、擦拭)中,DreamZero优势最大(5.3倍),证明世界模型对精细物理交互的理解远超VLA
-
即使是已见任务,DreamZero的平均进度(62.2%)也显著高于预训练VLA(27.4%),证明异构数据训练优于重复演示
DROID数据集对比(右侧):
-
Task Progress : DreamZero 82% vs π₀.₅ 69% vs GR00T N1.6 62%
-
Success Rate : DreamZero 75% vs π₀.₅ 42% vs GR00T N1.6 42%
5.4 零样本泛化:未见任务
AgiBot G1未见任务详细分解:
| AVG/Robot | DreamZero(Scratch) | π₀.₅ (Scratch) | GR00T N1.6 (Scratch) | π₀.₅ (Pretrained) | GR00T N1.6 (Pretrained) |
|---|---|---|---|---|---|
| **AgiBot G1(**Task Progress) | 39.5% | 0% | 0.7% | 16.3% | 5% |
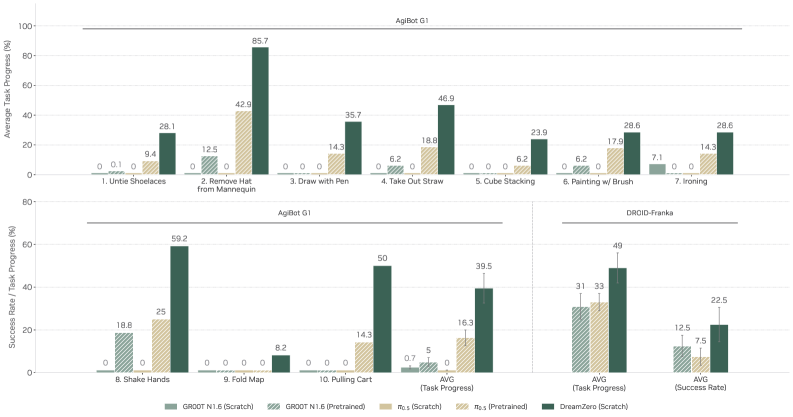

关键洞察
1. DreamZero 的零样本泛化能力 DreamZero 在完全没有见过的新任务 (如解鞋带、熨衣服、从人体模型上摘帽子等)上达到了 39.5% 的任务进度,这是状态最优VLA模型(π₀.₅ Pretrained,16.3%)的2.4倍。
2. "Scratch" vs "Pretrained" 的反差
-
VLA模型(π₀.₅ 和 GR00T N1.6):从VLM权重直接训练(Scratch)时几乎无法完成未见任务(0%-0.7%),必须经过大量机器人数据预训练才能有一定表现(5%-16.3%)
-
DreamZero:即使没有机器人预训练,仅依靠视频扩散模型的世界先验知识,就能有效泛化到新任务
3. 为什么 DreamZero 只有 Scratch?
DreamZero没有"Pretrain"这一行是因为它直接继承了视频扩散模型(Wan2.1)的物理动态先验,跳过了传统VLA的"机器人数据预训练"阶段。它的"Scratch"实际上是从视频生成权重开始,而非从零随机初始化。
4. 任务进度(Task Progress)的计算这个数字代表任务完成的百分比。例如在解鞋带任务中,可能包括"找到鞋带→抓住鞋带→解开结→拉出鞋带"等多个阶段,39.5%意味着平均完成了约40%的子步骤。
这行数据有力地证明了世界动作模型(WAM)通过视频预测学习物理动态,相比传统VLA具有更强的零样本任务泛化能力------即使在训练数据中没有见过的全新操作,也能基于对物理世界的理解进行尝试。
| 指标 | DreamZero | π₀.₅ | GR00T N1.6 | DreamZero 优势 |
|---|---|---|---|---|
| Task Progress | 49% | 33% | 31% | 相对提升 48% (vs π₀.₅) |
| Success Rate | 22.5% | 7.5% | 12.5% | 提升 3倍 (vs π₀.₅) |
关键差异:Task Progress vs Success Rate
这两个指标衡量的维度不同:
Task Progress(任务进度)
-
衡量任务完成的程度(0-100%)
-
例如:若任务是把5个物品放入盒子,成功放了2个,进度就是40%
-
DreamZero 达到 49%,意味着在未见任务中平均能完成近一半的操作步骤
Success Rate(成功率)
-
衡量任务完全成功的比例(二值:成功/失败)
-
例如:只有5个物品全部放入盒子才算成功
-
DreamZero 的 22.5% 意味着每4-5次尝试中就有1次完全成功,而基线模型每10次只有1次成功(π₀.₅)或不到2次(GR00T N1.6)
为什么 Success Rate 提升比 Task Progress 更显著?
Success Rate 提升 3倍 (22.5% vs 7.5%),而 Task Progress 只提升 48%(49% vs 33%),这说明:
-
DreamZero 更擅长"完成任务":不仅动作做得更多,而且更有可能把任务做完
-
基线模型容易"半途而废":虽然能做一些正确动作(Task Progress 33%),但经常在中途失败,导致最终成功率很低(7.5%)
-
DreamZero 的动作一致性更强:得益于联合视频-动作预测,它能更好地规划完整动作序列,减少中途放弃的情况
与 AgiBot G1 结果的对比
相比 AgiBot G1(DreamZero 39.5% vs π₀.₅ 16.3%),Franka 上 DreamZero 的优势比例较小但绝对值更高:
-
原因 1:DROID 是公开的异构数据集,基线模型(尤其是 π₀.₅-DROID)已经在这个数据集上优化过
-
原因 2:Franka 是单臂操作,任务复杂度相对较低,VLA 模型的表现空间更大
-
原因 3:AgiBot G1 是移动双臂机器人,环境更复杂,DreamZero 的世界建模优势被进一步放大
尽管如此,DreamZero 在 Success Rate 上 3倍 的提升仍然是非常显著的,证明即使在基线已经优化的设置下,世界动作模型(WAM)在零样本任务泛化上依然碾压传统 VLA。
5.4 后训练保持性
测试DreamZero在特定任务微调后是否仍保持环境泛化能力:
| 任务 | DreamZero | π₀.₅ (Scratch) | GR00T N1.6 (Scratch) | π₀.₅ (Pretrained) | GR00T N1.6 (Pretrained) |
|---|---|---|---|---|---|
| Shirt Folding | 92.5% | 1.5% | 2.5% | 92.5% | 65% |
| Fruit Packing | 96% | 0% | 2.7% | 71% | 56% |
| Table Bussing | 83% | 0% | 0% | 76% | 39% |
| AVG | 90.5% | 0.5% | 9.8% | 79.8% | 53.3% |
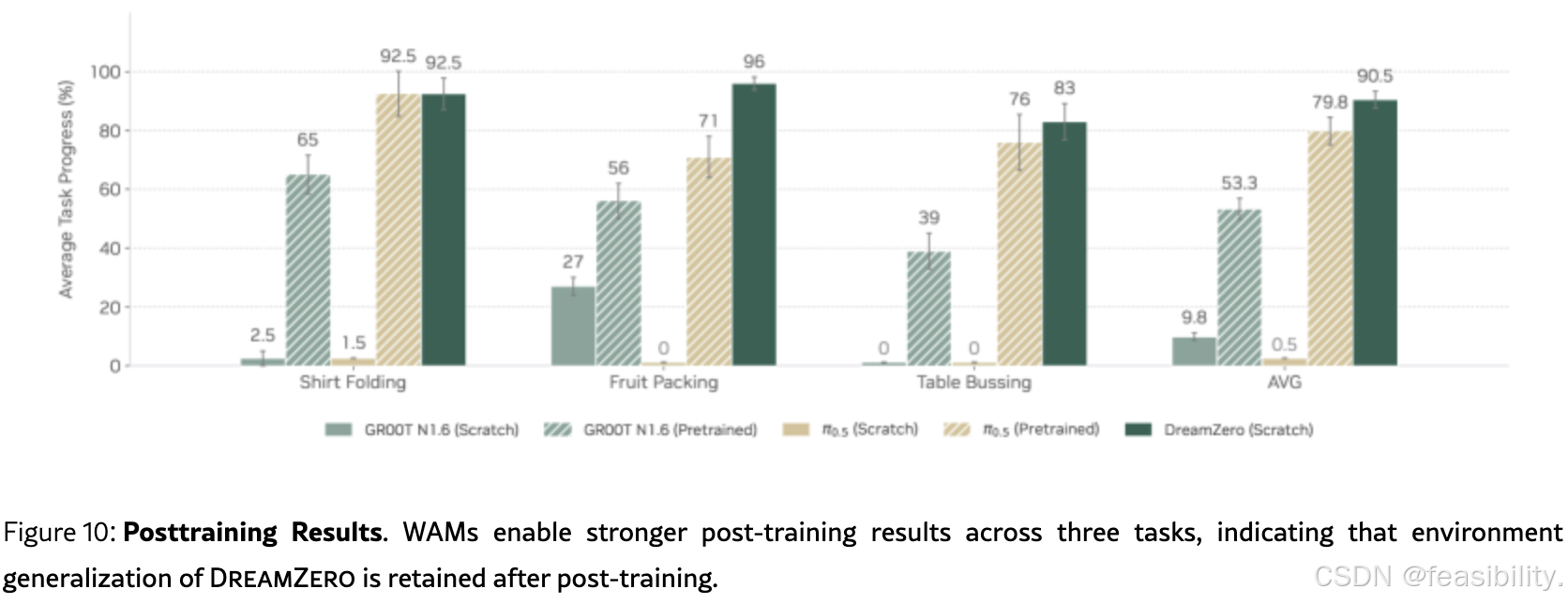
关键结论
1. DreamZero 微调后仍保持极强的环境泛化
DreamZero 在微调后平均达到 90.5% 的任务进度,而且这是在新环境(与训练数据收集地点不同的地理区域)中测试的结果。
2. 与预训练 VLA 的关键差异
-
π₀.₅ (Pretrained):虽然在 Shirt Folding 上与 DreamZero 持平(92.5%),但在 Fruit Packing 和 Table Bussing 上明显落后(71% vs 96%,76% vs 83%)
-
GR00T N1.6 (Pretrained) :在微调后出现明显的环境过拟合 ,平均只有 53.3% ,远低于 DreamZero 的 90.5%
3. 为什么 DreamZero 能保持泛化?
这是因为 DreamZero 的世界建模(World Modeling)特性:
-
VLA:微调时容易过拟合到训练环境的特定视觉特征和动作模式,丧失对新环境的适应能力
-
DreamZero:通过视频预测学习物理动态,即使针对特定任务微调,也仍然保持对"物理世界如何运作"的理解,因此能在新环境中表现稳定
4. 实际意义
在真实机器人部署中,通常需要针对特定任务进行后训练(post-training)。这组实验证明:
-
DreamZero 不仅零样本能力强 ,而且在实际微调后不会牺牲泛化能力
-
传统 VLA 虽然可以通过大量预训练达到较高性能(如 π₀.₅ Pretrained),但在新环境中的表现不如 DreamZero 稳定,且需要大量预训练数据
-
从零训练的 VLA(Scratch)在微调后几乎无法工作(0%-2.7%),再次证明视频预训练先验的重要性
5.3 跨本体迁移:30分钟适应新机器人
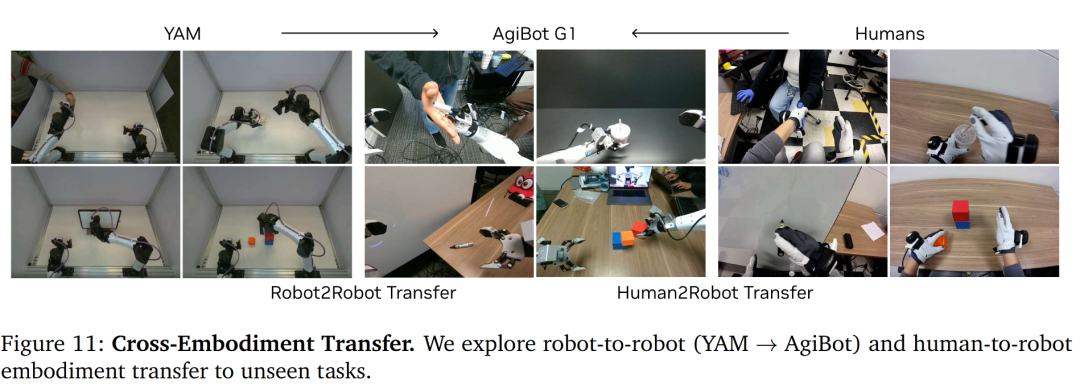
视频仅迁移(Video-only Transfer):
-
源数据 :YAM机器人或人类演示视频(10-20分钟),无动作标签
-
效果 :相比无迁移基线,未见任务成功率相对提升**>42%**
-
意义:人类视频可直接用于机器人训练,无需昂贵的动作重定向
小样本适应(Few-shot Adaptation):
-
设置:AgiBot G1预训练(500小时)→ YAM微调(30分钟玩耍数据)
-
惊人结果 :适应YAM的同时保留零样本泛化------能在YAM上执行从未训练过的新任务
-
数据效率:打破"每个新机器人需从头收集海量数据"的诅咒
六、消融实验:验证设计决策
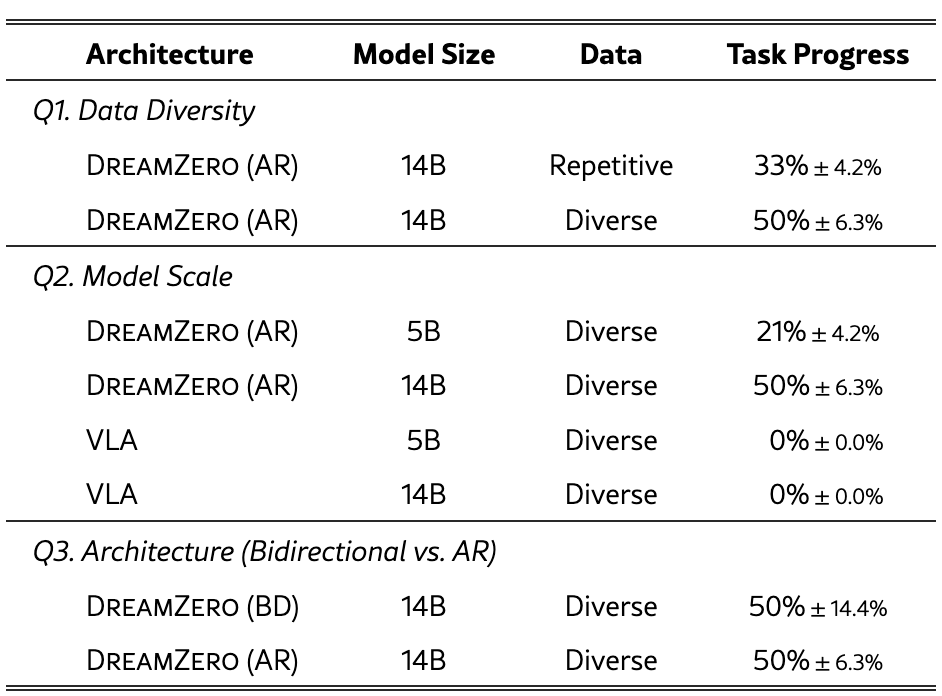
Q1. 数据多样性(Data Diversity)
| 数据类型 | Task Progress | 关键洞察 |
|---|---|---|
| Repetitive (重复演示) | 33% ± 4.2% | 传统方法:每个任务多次重复采集 |
| Diverse (多样化异构数据) | 50%± 6.3% | DreamZero 方法:少量重复,强调任务多样性 |
解读:
-
多样性 > 重复性 :使用同样数量的训练数据(约500小时),多样化数据的任务进度比重复演示高出 17个百分点(提升51%)
-
打破传统认知 :传统VLA需要每个任务多次重复演示才能学习,而 DreamZero 的世界建模目标使其能从异构、非重复的轨迹中有效学习物理动态
-
方差更低:虽然多样性数据的方差略高(6.3% vs 4.2%),但绝对性能优势明显,且更符合真实场景数据收集的实际条件
Q2. 模型规模(Model Scale)
| 模型 | 规模 | Task Progress | 关键洞察 |
|---|---|---|---|
| DreamZero (AR) | 5B | 21% ± 4.2% | 较小规模仍有一定能力 |
| DreamZero (AR) | 14B | 50% ± 6.3% | 规模效应显著 |
| VLA | 5B | 0% ± 0.0% | 完全失败 |
| VLA | 14B | 0% ± 0.0% | 即使扩大规模也无效 |
解读:
-
DreamZero 的扩展性 :从 5B 到 14B,性能提升 29个百分点(相对提升138%),说明视频扩散骨干网的规模直接转化为下游控制性能
-
架构差异的本质 :VLA(基于VLM)即使扩展到14B,在多样化数据上仍然 0% 完全失效,这证明了:
-
视频预训练先验的不可替代性:VLM在静态图像-文本数据上预训练,缺乏时空动态理解
-
世界建模的必要性:只有具备视频生成能力的模型才能从异构机器人数据中有效学习
-
-
数据效率 :即使是 5B 的 DreamZero(21%)也远超 14B VLA(0%),说明架构选择比单纯扩大规模更重要
Q3. 架构对比(双向 vs 自回归)
| 架构 | Task Progress | 标准差 | 关键洞察 |
|---|---|---|---|
| BD (Bidirectional,双向扩散) | 50% | ±14.4% | 性能波动大,不稳定 |
| AR (Autoregressive,自回归) | 50% | ±6.3% | 同样平均性能,但更稳定 |
解读:
-
平均性能持平 :两种架构在平均任务进度上没有差异(都是50%),但稳定性差异巨大
-
AR 的优势:
-
方差降低 56%(14.4% → 6.3%):自回归架构在不同任务和环境中的表现更加一致
-
KV Cache 效率:自回归允许使用 KV Cache 进行高效推理,支持长程依赖
-
避免下采样失真:双向模型通常需要固定长度序列,导致视频帧率被下采样(损害时序对齐);AR 支持任意长度,保持原生帧率
-
-
选择依据 :虽然双向和AR都能达到相似的平均性能上限,但 AR 的稳定性和推理效率 使其成为 DreamZero 的最终选择
综合结论
这组消融实验验证了 DreamZero 的三个核心设计决策:
-
数据策略 :优先采集多样化、长程、异构的真实世界操作数据,而非重复演示单一任务
-
模型规模 :基于14B视频扩散模型(Wan2.1),利用规模效应提升视频生成质量,进而提升控制性能
-
架构选择 :采用自回归(AR)架构而非双向扩散,获得更稳定的泛化能力和更高效的推理性能
最关键的是,这些实验证明了 WAM(World Action Model)的范式优越性------即使在相同数据规模和模型规模下,基于视频预训练的架构(DreamZero)显著优于基于VLM的VLA架构,且这种优势在扩大规模时更加明显。
七、局限与未来方向
当前局限
-
计算门槛:14B模型需H100/GB200级硬件,边缘部署困难(虽有5B版本,性能损失约30%)
-
推理延迟:150ms对于抛接球等高频反馈任务仍显不足
-
视频幻觉:扩散模型可能生成物理不一致的未来(物体穿透、漂浮),导致危险动作
与VLA的互补性
DreamZero并非取代VLA,而是分层架构的关键组件:
-
高层规划(VLA):利用语义知识进行任务分解、常识推理
-
低层执行(WAM):利用物理动态进行动作生成、环境交互
未来方向:VLA生成子目标("打开抽屉"),DreamZero执行物理交互(手爪轨迹、接触力控制)。
八、结论:从行为克隆到物理理解
DreamZero代表了机器人学习范式的根本转变:
传统VLA范式:

局限:需要覆盖所有可能行为的海量重复数据,缺乏物理常识。
DreamZero WAM范式:

优势:利用互联网视频预训练获得物理直觉,通过联合生成实现零样本泛化。
通过联合流匹配目标(公式3) 、自回归闭环架构 、解耦噪声调度(Flash) 与38倍系统优化,DreamZero在真实机器人上实现了:
-
数据效率:从异构非重复数据学习,无需重复演示
-
零样本泛化:未见任务成功率2倍于SOTA VLA
-
跨本体迁移:30分钟适应新机器人,打破硬件绑定
作为全面开源项目(模型+代码+数据集),DreamZero推动机器人社区从"大数据+大模型的暴力美学",转向"物理理解+高效迁移"的智能范式。当14B参数的视频扩散模型开始理解重力、接触与物体永久性,我们或许正在见证具身智能的临界点。
资源链接:
创作不易,禁止抄袭,转载请附上原文链接及标题