RNN 面试复习文档(结合匝道汇入决策论文)
一、这一讲视频到底讲了什么
主要讲的是循环神经网络 RNN 的基本原理、工作方式以及结构性缺陷 。
它的核心在于:RNN 不是一次性处理整段输入,而是按时间顺序逐步处理序列信息,并通过隐藏状态保存历史信息,因此特别适合文本、语音、轨迹这类有时序依赖的数据。
视频的重点其实可以概括成一句话:
RNN 开创了序列建模,但它的"短期记忆"能力有限,一旦序列变长,就容易因为梯度消失或梯度爆炸而失效。
这也是为什么后续会发展出 LSTM、GRU,以及更适合长时依赖建模的其他结构。
二、RNN 的核心知识点
1. RNN 的核心处理规则
RNN 的核心思想是:当前时刻的输出,不只依赖当前输入,还依赖上一时刻的隐藏状态 。
你可以把隐藏状态理解成一个不断更新的"动态记事本",它会随着每一步新输入的到来,保留一部分旧信息并写入新信息。
以翻译 "i love China" 为例:
-
T0:初始隐藏状态 H0H_0H0,相当于空白记忆
-
T1:输入 "i",更新得到 H1H_1H1,记住"主语是我"
-
T2:输入 "love",结合 H1H_1H1,更新得到 H2H_2H2,记住"我发出爱的动作"
-
T3:输入 "China",结合 H2H_2H2,最终理解为"我爱中国"
所以 RNN 的本质就是:
每个时刻都在做"当前输入 + 历史记忆"的融合。
2. 隐藏状态更新公式
RNN 当前时刻隐藏状态 HtH_tHt 的更新公式是:
Ht=tanh(WHHHt−1+WXHXt+bh)H_t = \tanh(W_{HH} H_{t-1} + W_{XH} X_t + b_h)Ht=tanh(WHHHt−1+WXHXt+bh)
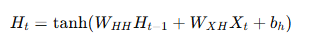
这里可以这样理解:

-
Ht−1H_{t-1}Ht−1:上一时刻的记忆
-
XtX_tXt:当前输入
-
WHHW_{HH}WHH:控制旧记忆对当前的影响
-
WXHW_{XH}WXH:控制当前输入对当前的影响
-
bhb_hbh:偏置项
-
tanh\tanhtanh:把结果压缩到 −1,1-1,1−1,1,增强非线性表达能力
最重要的一点是:
这些参数在所有时间步共享。
这叫做参数共享,是 RNN 很重要的设计思想。它让模型能够处理任意长度的序列,同时控制参数规模,避免每个时间步都单独学一套参数。
3. RNN 解决了什么问题
RNN 主要解决的是:
-
前馈网络无法利用历史上下文
-
普通模型不能天然处理变长序列
-
序列任务中需要考虑时间依赖
所以它特别适合:
-
文本建模
-
语音识别
-
时间序列预测
-
简单轨迹序列建模
4. RNN 的结构缺陷
RNN 最大的问题不是"不会建模时序",而是:
它只能比较自然地建模短期依赖,难以稳定学习长期依赖。
原因体现在训练过程中:
梯度消失
在反向传播穿越时间(BPTT)时,梯度会不断连乘。如果每次乘上的值偏小,梯度会越来越小,最后接近于 0。
这会导致早期时间步几乎收不到误差信号,也就学不到远距离依赖关系。
梯度爆炸
相反,如果连乘项偏大,梯度会迅速放大,导致参数更新剧烈波动,训练不稳定,甚至直接发散。
所以面试里可以这样概括:
RNN 的主要缺陷不是不能处理序列,而是不能稳定处理长序列。
三、面试高频考点整理
考点1:RNN 的工作原理是什么
答题核心:
RNN 通过循环结构,把上一时刻隐藏状态和当前输入一起用于当前状态更新,从而实现对序列信息的逐步建模。隐藏状态本质上承担短期记忆的作用。
考点2:为什么 RNN 能处理变长序列
答题核心:
因为 RNN 在不同时间步共享同一组参数,输入长度变化只会带来展开步数变化,不会带来参数量爆炸。
考点3:什么是梯度消失和梯度爆炸
答题核心:
在 BPTT 中,梯度沿时间维传播时需要连续乘雅可比矩阵,如果谱半径小于 1,梯度会指数衰减;大于 1,则会指数增长。
考点4:为什么梯度消失会导致学不到长期依赖
答题核心:
因为早期时间步参数几乎收不到误差信号,模型无法根据远期输出误差去修正前期权重,所以远距离依赖学不到。
考点5:RNN、LSTM、GRU 的关系
答题核心:
LSTM 和 GRU 都是为了解决标准 RNN 长时依赖建模弱的问题,通过门控机制改善梯度传播与信息选择。
四、学生视角下,学习 RNN 时应该怎么思考
这一部分是最重要的,因为它决定你在面试里像不像"会思考的人"。
1. 不要只记"RNN有记忆",要想"它的记忆为什么不够好"
RNN 的隐藏状态虽然叫"记忆",但它其实更像一种不断被新信息冲刷的缓存 。
它没有显式的"保留什么、遗忘什么"的机制,所以新信息进来后,旧信息很容易被稀释。
这意味着:
RNN 的记忆不是选择性记忆,而是混合式记忆。
这就是它后面需要升级为 LSTM 的根本原因。
2. 不要只记"梯度消失",要想到"这对任务意味着什么"
梯度消失不是一个抽象数学问题,它直接决定模型能不能学到远距离依赖。
比如在自动驾驶汇入决策里,如果模型无法记住几秒前对方车辆的减速、让行或逼近行为,那么它就难以正确判断当前的合流时机。
这说明在时序决策任务里,能不能记住历史,不是加分项,而是核心能力。
3. 不要只问"RNN是什么",还要问"它是为了解决谁的问题而出现的"
RNN 是为了解决前馈网络无法建模时序依赖的问题。
但它自己又带来了新的问题:长期依赖难学、串行计算慢、训练不稳定。
所以一个研究型学习者的思路应该是:
-
它为什么出现
-
它解决了什么
-
它没解决什么
-
后续为什么要有 LSTM/GRU/TCN/Transformer
这才是完整的模型演进理解。
五、结合你们论文,RNN 对我们研究意味着什么
你们的研究不是一般的分类问题,而是匝道汇入场景下的双车交互决策 。
论文里明确建模了:
-
SV / FV 双车交互
-
潜变量:交互激进性、认知层级、收益
-
历史状态池
-
EWMA 加权融合
-
LSTM 历史融合
-
滑动窗口
-
Modern-TCN 长时依赖更新
-
SHAP 可解释性分析
这些设计说明:你们面对的不是简单时序,而是带潜变量演化、带交互反馈、带长时记忆需求的复杂时序决策问题。
六、为什么标准 RNN 不适合直接作为我们研究的主模型
1. 因为我们的任务需要更强的长期依赖建模
在匝道汇入场景中,车辆不是在某一帧突然做决定,而是在一段时间内不断观察、博弈、调整。
论文也明确指出,这个过程具有明显的历史依赖、多步反馈和认知演化特征,而传统只依赖前一状态的建模方式不足以刻画这种长程关系。
标准 RNN 在这种场景下的问题是:
-
早期关键交互信息容易丢
-
难以稳定建模多轮互动
-
对长期博弈过程不够敏感
所以它不适合作为你们研究中的主时序建模器。
2. 因为我们的研究不只是序列预测,还要解释交互机制
你们论文不是单纯预测"会不会并线",而是显式建模:
-
激进性如何变化
-
认知层级如何演化
-
收益如何影响策略
-
对方如何根据我方激进性做保守响应
这类问题要求模型不仅有时序能力,还要有一定结构先验和解释能力。论文里通过 CH 博弈 + 潜变量 + SHAP 建立了"行为---认知---决策"的闭环解释链条。
而标准 RNN 更适合做一般序列映射,不擅长解释潜变量之间的机制关系。
3. 因为我们的研究需要兼顾训练效率和长感受野
论文中没有把 LSTM 作为总的主更新器,而是:
-
用 EWMA + LSTM 做历史状态融合
-
再用 Modern-TCN 更新交互激进性、认知层级和收益这三个潜变量
也就是说,你们实际上做了一个明确的工程取舍:
-
LSTM 负责历史连续性的融合
-
Modern-TCN 负责更高效、更稳定的长时依赖建模
论文里明确写到,Modern-TCN 通过大卷积核获得更大的有效感受野,并且更适合学习时间依赖和变量依赖。
这比单纯用标准 RNN 更适合你们的数据和任务。
七、RNN、LSTM、TCN 在你们研究中的关系
这部分很适合面试时展开。
RNN
适合做基础序列建模入门。
优点是结构简单、容易理解。
缺点是长时依赖弱、训练不稳定、串行计算限制大。
LSTM
是在 RNN 基础上的升级。
通过门控机制和细胞状态,解决了标准 RNN 长时记忆差的问题。
在你们论文中,LSTM 主要体现在历史状态融合部分,而不是整个决策主干。
TCN / Modern-TCN
更适合长时依赖、多变量时序和高效并行训练。
在你们论文里,Modern-TCN 被用来更新三个潜变量,是核心的时序更新模块。
所以一句话概括就是:
我们不是简单地"弃用RNN",而是沿着 RNN → LSTM → 更强时序建模器 的脉络,结合任务特点做了更合适的选择。
八、面试时可以直接说的高质量回答
版本1:通用八股文版
RNN 的核心思想是通过隐藏状态把历史信息传递到当前时刻,因此它适合处理文本、语音和时间序列这类顺序数据。它的优点是结构简单、参数共享,可以处理变长序列。但标准 RNN 的主要问题是梯度消失和梯度爆炸,尤其在长序列任务中,很难稳定学习长期依赖,这也是后续 LSTM、GRU 等模型出现的主要原因。
版本2:结合你们论文版
RNN 对我们最大的启发,不是它本身够不够好,而是它开创了"时序状态递推"这条思路。我们研究的匝道汇入决策本质上也是一个时序交互问题,需要根据历史状态来判断当前决策。但标准 RNN 对长期依赖建模能力有限,而我们的场景存在多轮博弈、历史反馈和潜变量演化,因此我们没有直接使用标准 RNN,而是采用了 LSTM 做历史融合,再用 Modern-TCN 做潜变量更新,这样更适合我们论文中的长时依赖和交互建模需求。
版本3:更像研究生/工程岗候选人的回答
我认为学习 RNN 不能只停留在"它能处理序列",更重要的是理解它为什么在长序列中失效。标准 RNN 的隐藏状态本质上是一个不断被新信息覆盖的短期缓存,没有显式的保留和遗忘机制,所以很难稳定记住远处信息。对于我们做的匝道汇入决策任务,这种缺陷会直接影响模型对早期交互行为的利用。也正因为如此,我们在论文里没有直接使用标准 RNN,而是把 LSTM 放在历史融合模块里,再用 Modern-TCN 去建模更长范围的潜变量演化,这样在时序表达能力和工程效率之间更平衡。
九、面试官可能追问的几个问题
1. 既然 LSTM 能解决 RNN 问题,为什么你们还要用 TCN?
因为 LSTM 虽然改善了长时记忆,但本质上仍然是串行递推,训练效率和长范围感受野仍有限。我们任务里既有历史状态连续性,又有更长时间范围的潜变量演化,所以用 LSTM 做历史融合,再用 Modern-TCN 做长时更新更合适。
2. 为什么不直接用标准 RNN 做汇入决策?
因为汇入决策不是短程依赖问题,而是多轮交互和历史反馈问题。标准 RNN 容易丢失远期关键信息,难以稳定建模几秒级别的交互演化。
3. RNN 更适合什么场景?
更适合短序列、依赖跨度不长、结构简单的时序建模任务,比如基础文本序列建模、简单时间序列预测、教学演示等。
4. 标准 RNN 不适合什么场景?
不适合长依赖强、决策链条长、交互反馈复杂、对训练稳定性要求高的任务,比如复杂自动驾驶决策、多轮行为建模、长文本理解等。
十、最后给你一个"最小背诵清单"
今天必须记住的 5 个点
-
RNN 通过隐藏状态递推处理序列
-
参数共享让它能处理变长序列
-
隐藏状态本质是短期记忆
-
标准 RNN 主要问题是梯度消失和梯度爆炸
-
RNN 开创了时序建模,但不适合复杂长时依赖任务
今天必须会说的 3 句话
-
RNN 的价值在于提出了时序递推建模思路,但它的短期记忆机制限制了长依赖学习能力。
-
在我们的匝道汇入研究里,历史交互信息非常重要,所以标准 RNN 不足以支撑主模型。
-
我们最终采用 LSTM 做历史融合、Modern-TCN 做潜变量长时更新,是基于任务需求做出的结构选择。