内存查找与磁盘查找
- 内存虽然速度很快,在各种搜索结构中,查1次和查10次区别不是很大,但是空间相比与内存小得多,一旦涉及到GB甚至是PB级的数据存储、检索,将所有数据都放到内存中查找是不现实的,这就需要从内存查找过渡到磁盘查找。
- 所以我们要把数据放到磁盘中,检索的时候,只把需要的部分加载进内存,这样才是合理的 ✅
- 但是这样就引入了一个新的问题:磁盘操作和内存操作的效率不在同一个数量级啊!更不要提其中包含的硬件中断、CPU上下文切换等等OS中的操作。因此,我们需要一种搜索结构,既能够帮助我们检索到数据,又能够只通过很少的磁盘访问次数就完成检索
- 我们先来看常见的结构:
- 平衡二叉搜索树:太高了,能完成检索,但是有极大量的磁盘IO操作
- 哈希表:虽然查询操作是O(1),但是哈希冲突是不可避免的,虽然可以通过将哈希桶某个位置的链表转换为红黑树的方式优化,但这本质上还是回到了第一种结构
- 💡 综上,目前这些简单常用的结构不能满足我们的需求,但是平衡二叉搜索树的思想是好的,只是高度太高。所以我们可以使用B树来解决磁盘查找的问题
What's B树?
一棵m阶的B树,是一棵空树,或者是一棵满足以下性质的M路平衡搜索树:
- 根节点至少有两个孩子
- 每个分支节点都包含k-1个关键字和k个孩子(或者换一种方式解释:k-1个数据域和k个指针域),其中
ceil(m/2) <= k <= m,ceil是向上取整函数 - 所有的叶子节点都在同一层
- 每个节点的关键字都是从小到大排列,节点中k-1个关键字正好划分k个孩子包含关键字的值域
上面的文字对于初学者来说不好理解,用一张图来解释B树
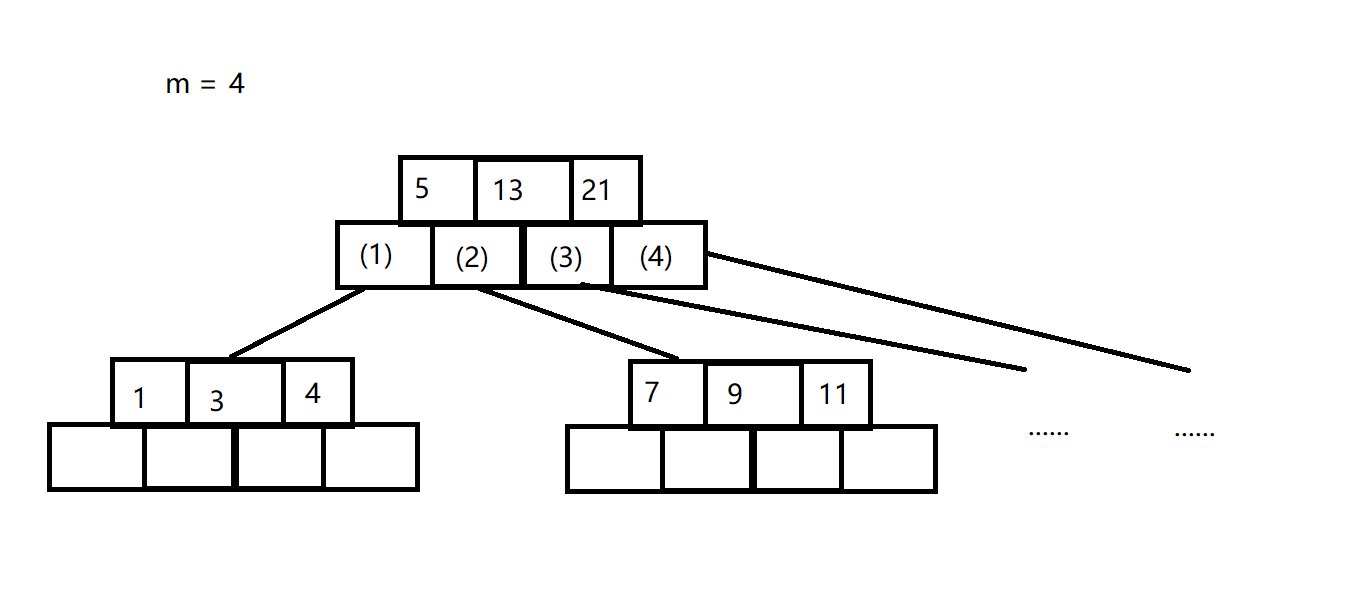
- 在m=4的情况下,一个节点有三个关键字,四个孩子,比如根节点(5、13、21),他的
(1)孩子,就保存着小于5的值;(2)孩子,就保存着小于13大于5的值,以此类推(3)(4)孩子。 - 之后,每个节点又通过同样的方式指向自己的孩子,这就是B树
- B树依然是搜索树,所以保有"左小右大"的性质
B树的插入
B树平衡的特性,就是通过插入来维持的,具体操作就是分裂。
下面演示B树插入的过程。
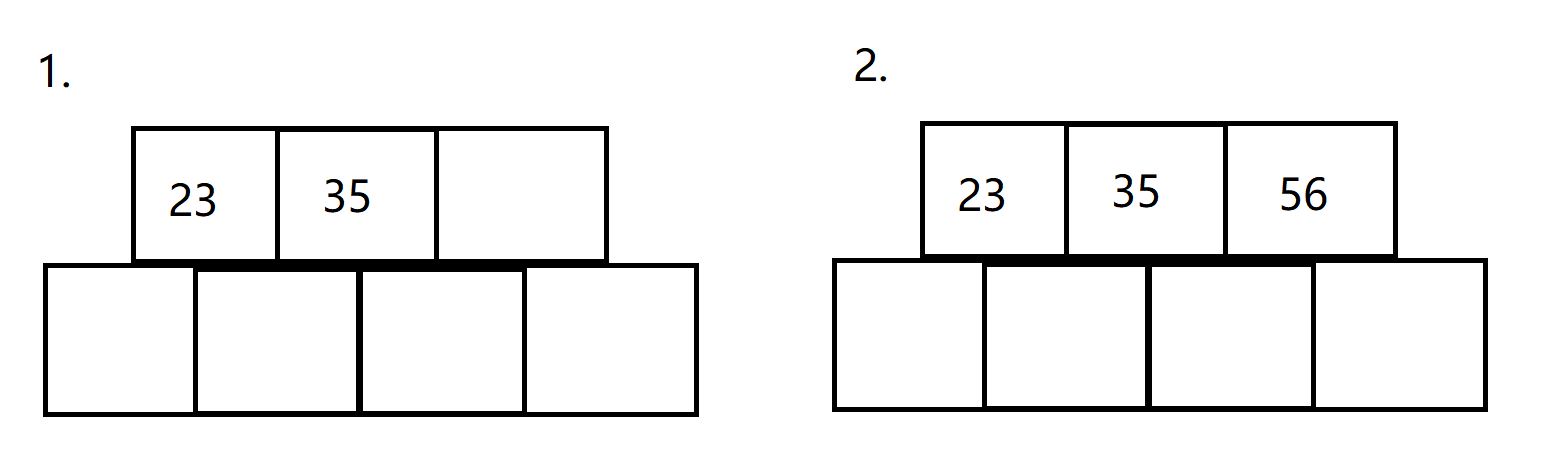
首先,我们往空节点(先不要管是不是根节点,这里主要理解B树的分裂是怎么一回事)中插入23、35两个关键字,这个时候还没有满,所以我们继续插入56。
这时我们发现满了,所以需要进行分裂。
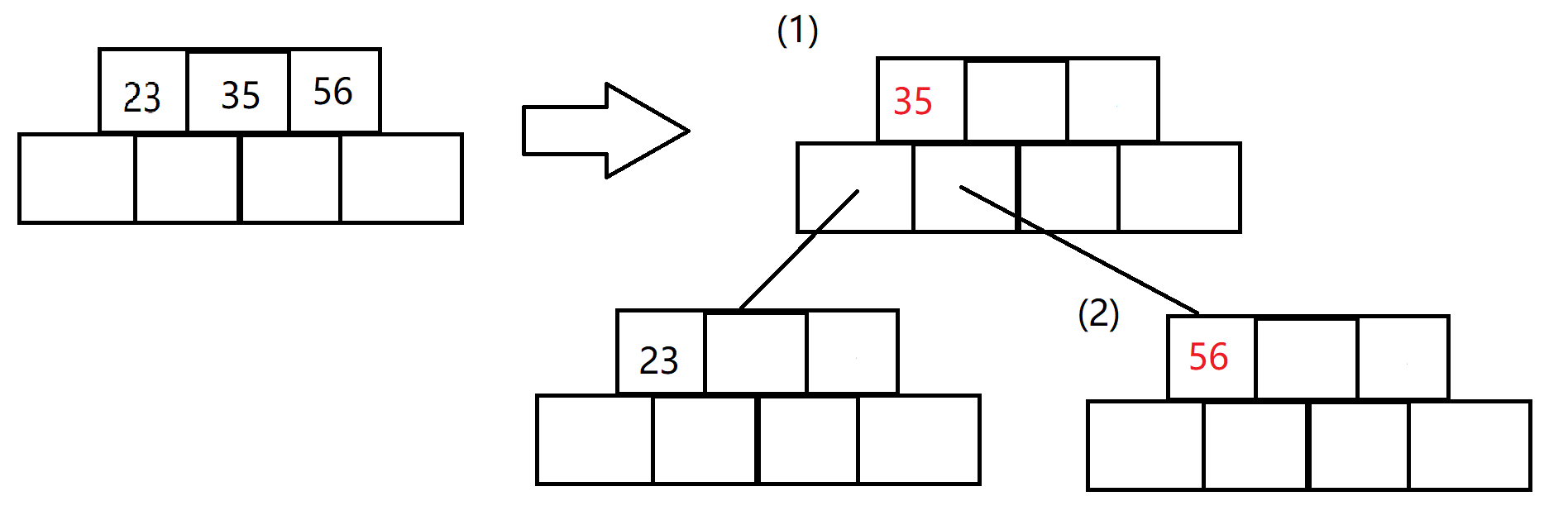
-
找到关键字的中间元素,把中间元素移动给当前节点的父节点
-
以中间位置为界,将中间位置后面的都拷贝给新的兄弟节点
-
连接新节点
这就是B树分裂的过程,也就是说:
1. 只要不是更新到了根节点,就一直横向更新
2. 分裂只往横向分裂,除非根节点分裂会出现新的根节点,所以B树是平衡的
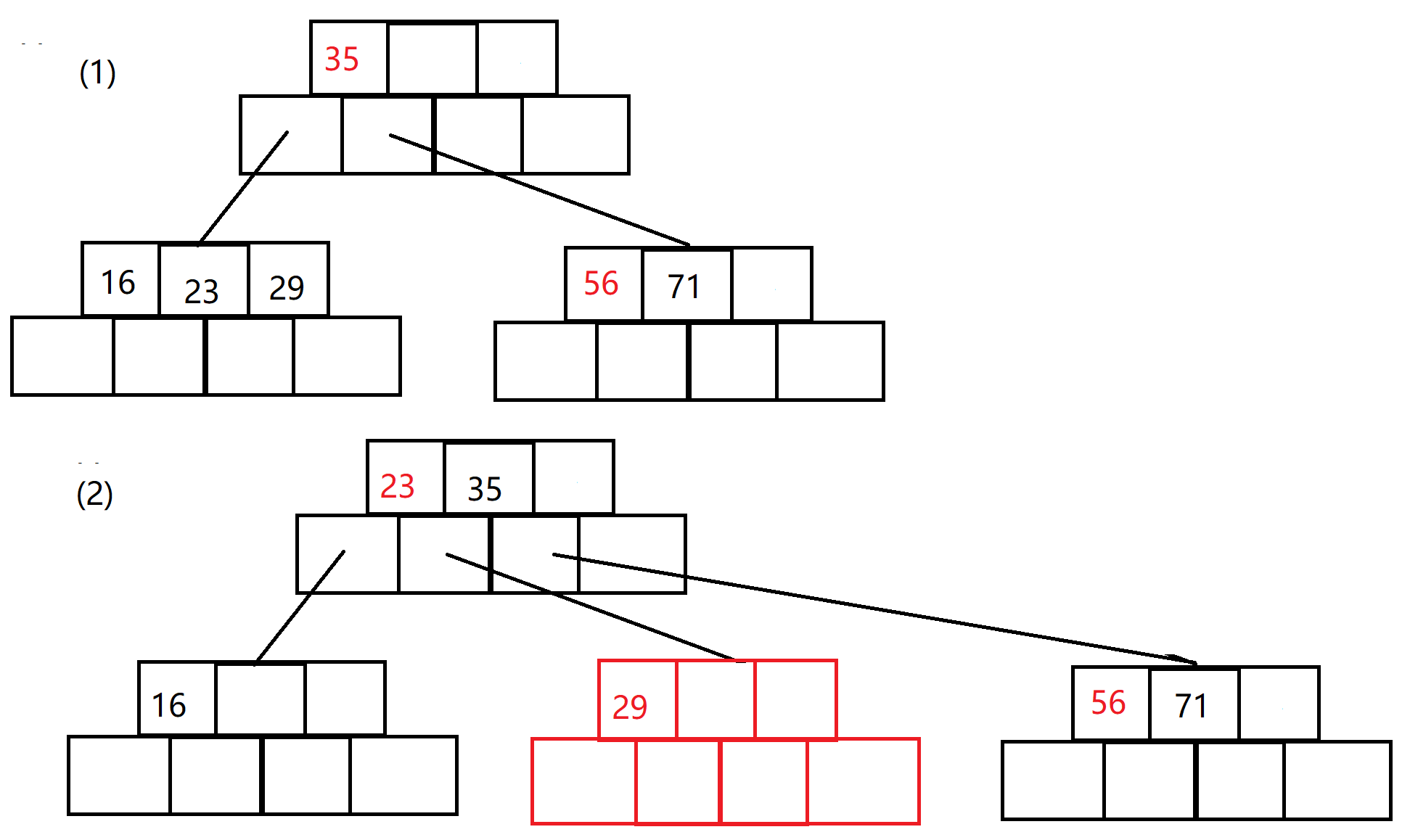
接下来我们继续插入16、71、29,这时我们发现最左面的孩子(16、23、29)满了,不满足B树的规则,需要分裂处理。
如(2)所示,将源节点的之间元素拷给父元素,同时开辟新节点,将中间位置之后的元素拷给它,在更新父节点指针的指向
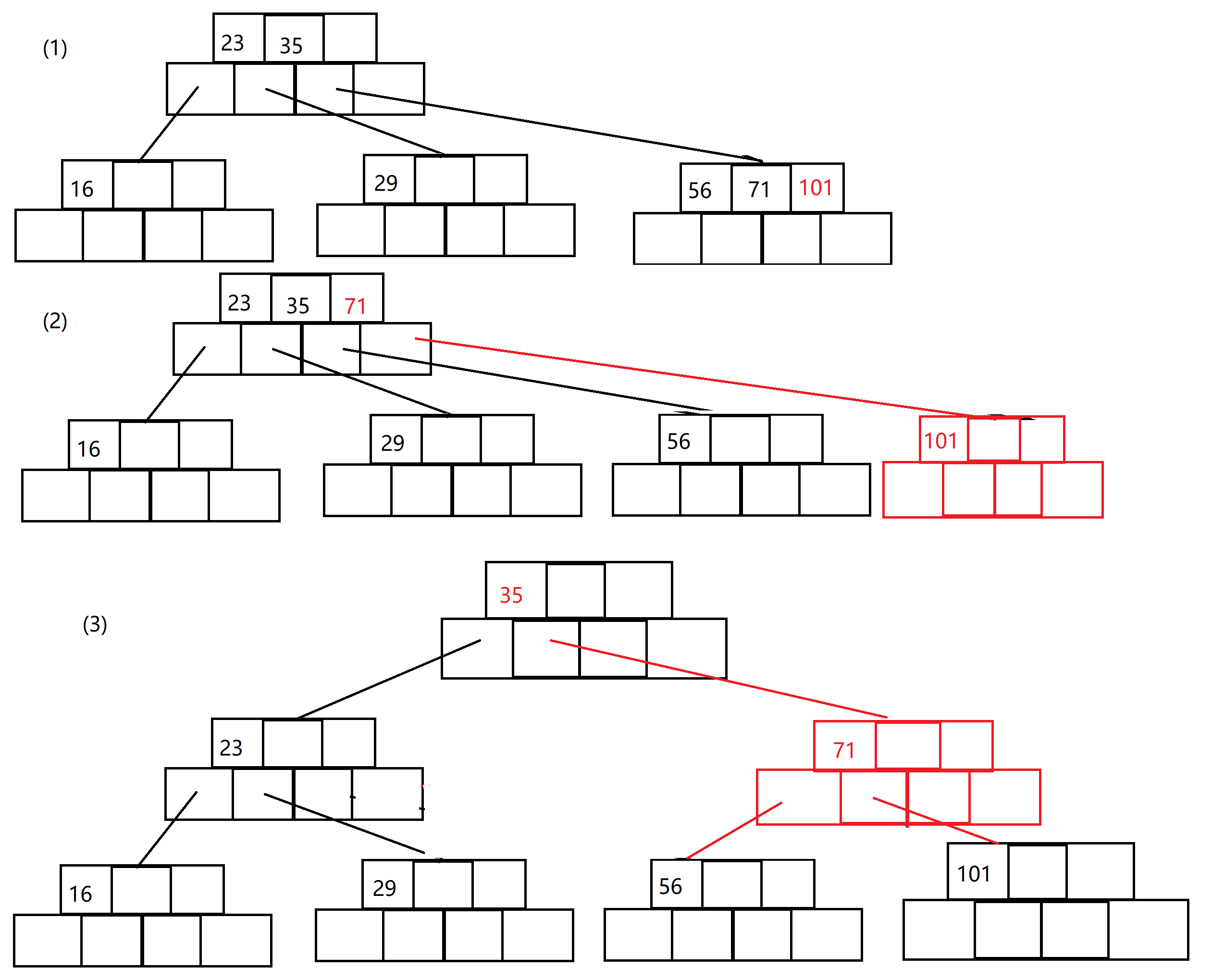
最后我们来看连续分裂的情况:
- 我们插入了101这个数字,显然他会插入到56开头的那个孩子
- 这时这个节点满了,需要进行分裂。把71给父节点,这时发现父节点也满了,还需要再进行分裂
- 父节点把35给父节点(或者是新的根节点),再把71给新的兄弟节点,挪动父节点的后两个孩子给新的兄弟之后,就完成了连续分裂
总结
-
树为空,直接插入
-
寻找插入位置,并检测是否找到插入位置(可以定义是否允许重复元素,我这里不允许),插入位置一定是在叶子节点
-
按照插入排序的方式插入之后,检查是否满足B树的规则,简单概括:插入之后该节点数据域不满
-
如果插入时候满了,那么就需要分裂,也就是我们上面展示的过程
-
不断向上检查是否满足B树的规则(因为中间元素要交给父节点,所以可能出现连续分裂的情况)
-
父节点满足,则停止更新;更新到了根节点(开辟了新的根节点),也停止更新
代码实现
BTreeNode
cpp
template <class K, int M = 1024>
struct BTreeNode{
K _keys[M];
BTreeNode<K, M>* _subs[M + 1];
BTreeNode<K, M>* _parent = nullptr;
int _size;
BTreeNode(){
_parent = nullptr;
_size = 0;
for(int i = 0; i < M; i++){
_subs[i] = nullptr;
_keys[i] = K();
}
}
};查找的实现
cpp
std::pair<BNode*, int> Find(K& key){
BNode* pCur = _root;
BNode* pParent = nullptr;
while(pCur){
int i = 0;
for(; i < pCur->_size; i++){
if(key < pCur->_keys[i]){
break;
}
else if(key == pCur->_keys[i]){
return std::make_pair(pCur, i);
}
}
pParent = pCur;
pCur = pCur->_subs[i];
}
//没有找到才需要插入
return std::make_pair(pParent, -1);
}插入的实现
cpp
void _Insert(BNode* pCur, BNode* brother, K& key){
int end = pCur->_size - 1;
while(end >= 0){
if(pCur->_keys[end] < key){
break;
}
else{
pCur->_keys[end + 1] = pCur->_keys[end];
pCur->_subs[end + 2] = pCur->_subs[end + 1];
end--;
}
}
pCur->_keys[end + 1] = key;
pCur->_subs[end + 2] = brother;
if(brother){
brother->_parent = pCur;
}
pCur->_size++;
}
bool Insert(K& key){
if(_root == nullptr){
_root = new BNode();
_root->_keys[_root->_size++] = key;
return true;
}
std::pair<BNode*, int> ret = Find(key);
if(ret.second >= 0){
return false;
}
BNode* pCur = ret.first;
BNode* brother = nullptr;
K newkey = key;
while(1){
_Insert(pCur, brother, newkey);
if(pCur->_size < M){
return true;
}
int mid = M >> 1;
brother = new BNode();
for(int i = mid + 1; i < pCur->_size; i++){
brother->_subs[brother->_size] = pCur->_subs[i];
if(pCur->_subs[i]){
pCur->_subs[i]->_parent = brother;
}
brother->_keys[brother->_size++] = pCur->_keys[i];
}
brother->_subs[brother->_size] = pCur->_subs[pCur->_size]; //分裂出来的兄弟要多拷贝一个右孩子
if(pCur->_subs[pCur->_size]){
pCur->_subs[pCur->_size]->_parent = brother;
}
pCur->_size -= brother->_size + 1;
if(pCur->_parent == nullptr){
BNode* newRoot = new BNode();
newRoot->_keys[newRoot->_size++] = pCur->_keys[mid];
newRoot->_subs[0] = pCur;
newRoot->_subs[1] = brother;
pCur->_parent = newRoot;
brother->_parent = newRoot;
_root = newRoot;
return true;
}
else{
newkey = pCur->_keys[mid];
pCur = pCur->_parent;
}
}
return true;
}这里实现的是最简单的模拟B树,理论上100万个数据在1024阶的B树上只需要两层即可存储(1023 * 1024),但是因为不是每个节点利用率都是100%,所以实际测试需要4层。
标准的B树也是如此,理论上(即节点利用率100%),100万个数据需要两层,10亿个数据需要3层,但是实际上会出现存储层数更多的情况,因为不可能做到每个几点都能100%利用(也依然是多一两层,撑死撑死三四层的样子,不会多非常多)
性能分析
我们的B树,插入和查询的效率都是以m为底N的对数,相比红黑树以2为底小了很多了。理论上,那怕620亿个数据,四层也能完成工作
B+ 树
What's B+树?
首先B+树整体思路上依然和B树相同,不过是对B树进行的优化,尤其适合数据库的操作需要
-
分支节点的字数指针和关键字个数相同
-
分支节点的字数指针指向关键字值大小在
k[i], k[i+1]之间 -
所有叶子节点增加一个指针连接(数据库中一定实现的是双向的,满足范围查找的需要)
-
所有关键字及其映射数据都在叶子节点出现
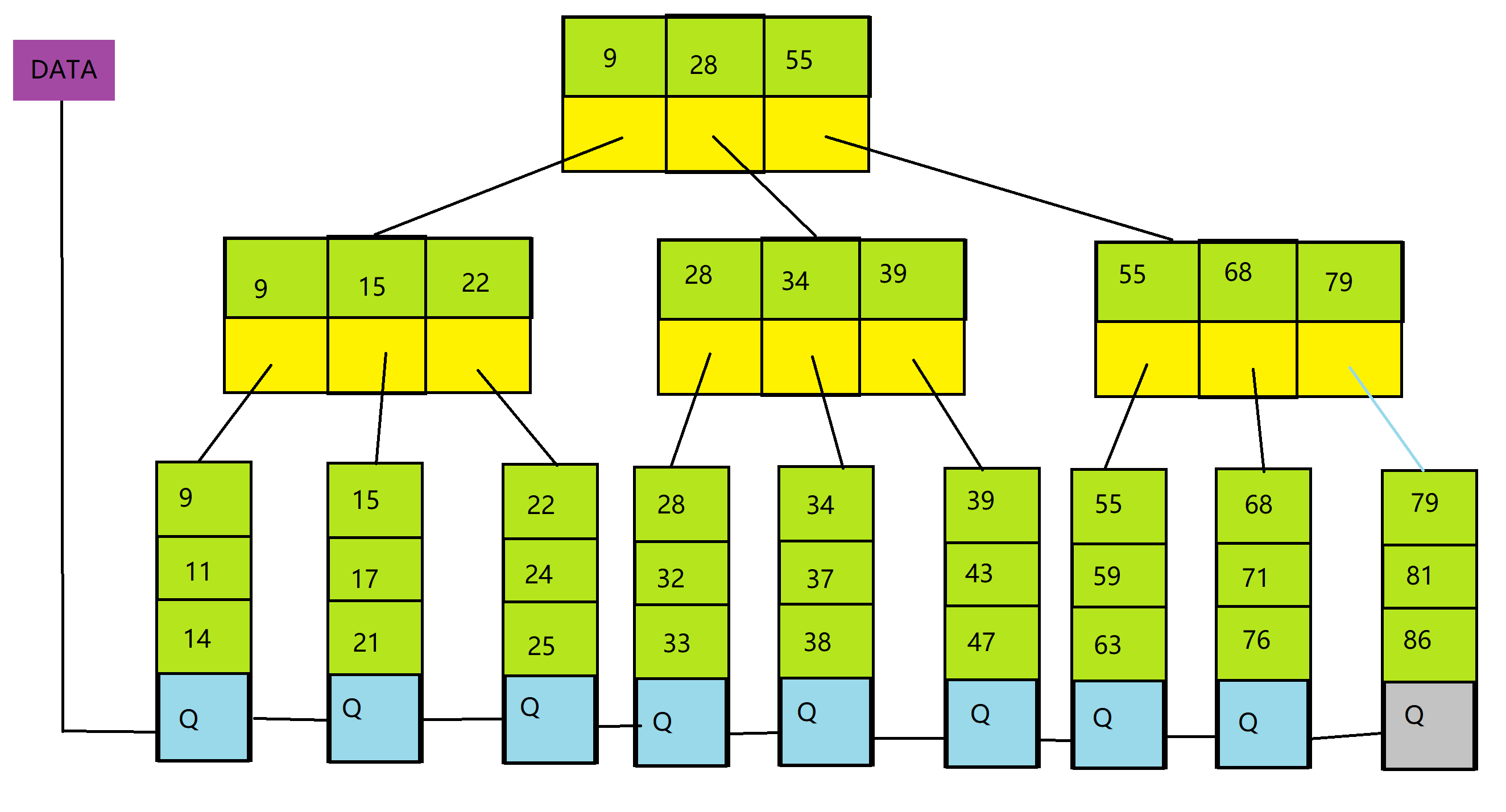
加入我们现在要查找76,按照B+树的逻辑,查找过程如下:
- 遍历9、28、55,发现76 > 55,往55为索引的孩子找
- 遍历55、68、79,发现68 < 76 < 79,到68为索引的孩子找
- 遍历孩子,找到76,找到实际的数据
B+树的分裂
- 一个节点满时,分配一个新的节点,将源节点的一半数据拷贝给新节点,再在父节点中增加新节点的指针
- B+树的分裂只影响源节点和父节点,不会影响兄弟节点
B+树的特性
- 所有关键字都出现在叶子节点的链表中,且链表中的节点都是有序的
- 不可能在分支节点中命中
- 分支节点都是叶子结点的索引,只有叶子节点来存储数据
B+树的优点
- 效率更加稳定:分支节点都是叶子的索引,插入、查找、删除的效率都更加稳定
- 非叶子节点能够保存更多的索引,能使加载到磁盘的场景中磁盘IO次数更少
- 范围查找效率更高:根据局部性原理,当用户查询某个元素时,很有可能再次需要与其相近的元素,这杨我们将叶子节点串联起来的链表就能起到很大的优化作用
- 全表扫描更高效:使用B树需要遍历整张表,B+树可以直接遍历叶子节点
B*树
What's B*树
其实就是在B+树的基础上,在同一层非跟且非叶子节点上也增加了类似B+树叶子节点的指针,可以实现比B+树节点利用率更高。但实际上,因为没有改变叶子节点存储数据的方式,并且磁盘的空间也大的很,同时B*树相比B+树还要复杂,所以虽然B*树的节点利用率更高,但是使用的并不多
B*树的分裂
分为两种情况:
- 当某个节点满时,如果他的兄弟节点没有满,那么就把一般的数据拷给兄弟节点,并更新兄弟节点在父节点中的关键字
- 当某个节点满时,并且它的兄弟节点也满了,那么就开辟一个新节点在两者之间,各自拷贝三分之一数据给新节点(前三分之一和后三分之一),再连接父节点到新节点的指针