题目


知识点
auto
C++11中,标准委员会赋予了auto全新的含义即:auto不再是一个存储类型指示符,而是作为一个新的类型指示符来指示编译器,auto声明的变量必须由编译器在编译时期推导而得。
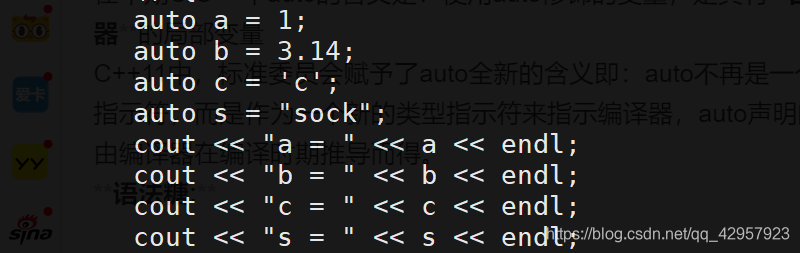

这个还不能体现出 auto 的真正意义。但是当类型名过长时, auto 的作用就发挥出来了。
注:使用auto定义变量时必须对其进行初始化,在编译阶段编译器需要根据初始化表达式来推导auto的实际类型。因此auto并非是一种"类型"的声明,而是一个类型声明时的"占位符",编译器在编译期会将auto替换为变量实际的类型。
auto迭代:对于一个有范围的集合而言,由程序员来说明循环的范围是多余的,有时候还会容易犯错误。因此C++11中引入了基于范围的for循环 。for循环后的括号由冒号" :"分为两部分:第一部分是范围内用于迭代的变量,第二部分则表示被迭代的范围
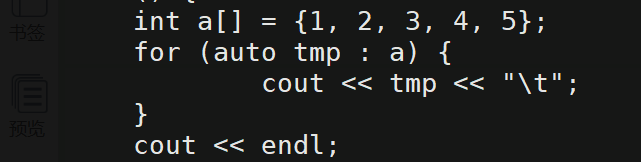

但是这样不会对原数组 a 造成影响
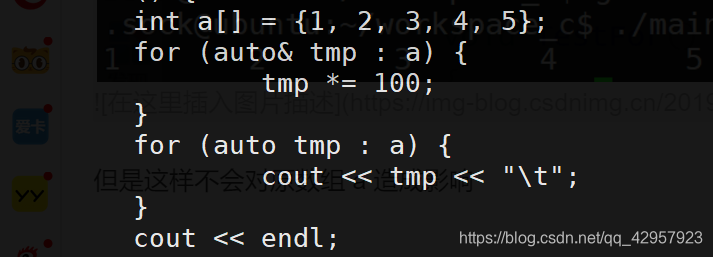

auto& 可以对数组 a 中的元素进行修改。
auto特性:
- auto不能作为函数参数
- auto不能直接声明数组
- 为了避免与C++98中的auto发生混淆,C++11只保留了auto作为类型指示符的用法
- auto在实际中最常见的优势用法就是跟以后会讲到的C++11提供的新式for循环,还有lambda表达式等进行配合使用。
- auto不能定义类的非静态成员变量
- 实例化模板时不能使用auto作为模板参数
思路
1、最小堆------灵茶山艾府
合并后的第一个节点 first,一定是某个链表的头节点(因为链表已按升序排列)。
合并后的第二个节点,可能是某个链表的头节点,也可能是 first 的下一个节点。例如有三个链表 1->2->5,3->4->6,4->5->6,找到第一个节点 1 之后,第二个节点不是另一个链表的头节点,而是节点 1 的下一个节点 2。
按照这个过程继续思考,每当我们找到一个节点值最小的节点 x,就把节点 x.next 加入「可能是最小节点」的集合中。因此,我们需要一个数据结构,它支持:1、从数据结构中找到并移除最小节点。2、插入节点。
这可以用最小堆实现。初始把所有链表的头节点入堆,然后不断弹出堆中最小节点 x,如果 x.next 不为空就加入堆中。循环直到堆为空。把弹出的节点按顺序拼接起来,就得到了答案。实现时,可以用哨兵节点简化代码。
2、分治
(1)递归
暴力做法是,按照 21 合并两个有序链表 的题解思路,先合并前两个链表,再把得到的新链表和第三个链表合并,再和第四个链表合并,依此类推。但是这种做法,平均每个节点会参与到 O(m) 次合并中(用 (1+2+⋯+m)/m 粗略估计),所以总的时间复杂度为 O(L⋅m)。
一个巧妙的思路是,把 lists 一分为二(尽量均分),先合并前一半的链表,再合并后一半的链表,然后把这两个链表合并成最终的链表。如何合并前一半的链表呢?我们可以继续一分为二。如此分下去直到只有一个链表,此时无需合并。
按照一分为二再合并的逻辑,递归像是在后序遍历一棵平衡二叉树。由于平衡树的高度是 O(logm),所以每个链表节点只会出现在 O(logm) 次合并中!这样就做到了更快的 O(Llogm) 时间。
(2)迭代
直接自底向上合并链表:
- 两两合并:把 lists0 和 lists1 合并,合并后的链表保存在 lists0 中;把 lists2 和 lists3 合并,合并后的链表保存在 lists2 中;依此类推。
- 四四合并:把 lists0 和 lists2 合并(相当于合并前四条链表),合并后的链表保存在 lists0 中;把 lists4 和 lists6 合并,合并后的链表保存在 lists4 中;依此类推。
- 八八合并:把 lists0 和 lists4 合并(相当于合并前八条链表),合并后的链表保存在 lists0 中;把 lists8 和 lists12 合并,合并后的链表保存在 lists8 中;依此类推。
依此类推,直到所有链表都合并到 lists0 中。最后返回 lists0。
错误
//合并从listi到listj-1的链表
题解
1、最小堆
//最小堆
class Solution {
public:
ListNode* mergeKLists(vector<ListNode*>& lists) {
// 定义比较函数,构建最小堆
auto cmp = [](const ListNode* a, const ListNode* b) {
return a->val > b->val; // 注意:返回true表示a应该排在b后面
};
// 创建优先队列(最小堆)
priority_queue<ListNode*, vector<ListNode*>, decltype(cmp)> pq(cmp);
// 将所有非空链表的头节点加入堆中
for (ListNode* head : lists) {
if (head) {
pq.push(head);
}
}
// 创建哨兵节点
ListNode dummy(0);
ListNode* cur = &dummy;
// 不断从堆中取出最小节点,加入结果链表
while (!pq.empty()) {
ListNode* smallest = pq.top();
pq.pop();
// 如果该节点还有下一个节点,将其加入堆中
if (smallest->next) {
pq.push(smallest->next);
}
// 将当前最小节点加入结果链表
cur->next = smallest;
cur = cur->next;
}
return dummy.next;
}
};2、分治
cpp
class Solution {
//21 合并两个有序链表
ListNode* mergeTwoLists(ListNode* list1, ListNode* list2) {
ListNode* dummy = new ListNode(0);
ListNode* cur = dummy;
while (list1 != nullptr && list2 != nullptr) {
if (list1->val < list2->val) {
cur->next = list1;
list1 = list1->next;
}
else {
cur->next = list2;
list2 = list2->next;
}
cur = cur->next;
}
cur->next = list1 != nullptr ? list1 : list2;
return dummy->next;
}
//合并从list[i]到list[j-1]的链表
ListNode* mergeKLists(vector<ListNode*>& lists,int i,int j) {
int m = j - 1;
if (m == 0) {
return nullptr;
}
if (m == 1) {
return lists[i];
}
auto left = mergeKLists(lists, i, i + m / 2);//合并左半部分
auto right = mergeKLists(lists, i + m / 2, j);
return mergeTwoLists(left, right);
}
public:
ListNode* mergeKLists(vector<ListNode*>& lists) {
return mergeKLists(lists, 0, lists.size());
}
};
cpp
class Solution {
// 21. 合并两个有序链表
ListNode* mergeTwoLists(ListNode* list1, ListNode* list2) {
ListNode dummy{}; // 用哨兵节点简化代码逻辑
auto cur = &dummy; // cur 指向新链表的末尾
while (list1 && list2) {
if (list1->val < list2->val) {
cur->next = list1; // 把 list1 加到新链表中
list1 = list1->next;
} else { // 注:相等的情况加哪个节点都是可以的
cur->next = list2; // 把 list2 加到新链表中
list2 = list2->next;
}
cur = cur->next;
}
cur->next = list1 ? list1 : list2; // 拼接剩余链表
return dummy.next;
}
public:
ListNode* mergeKLists(vector<ListNode*>& lists) {
int m = lists.size();
if (m == 0) {
return nullptr;
}
for (int step = 1; step < m; step *= 2) {
for (int i = 0; i < m - step; i += step * 2) {
lists[i] = mergeTwoLists(lists[i], lists[i + step]);
}
}
return lists[0];
}
};