如果你手头已经有一份「每行一个地址」的 txt,要在 Windows 上批量产出整页或视口截图,可以用【批量网页截图工具】记一条工作流。下面只写界面参数怎么配,不涉及任何浏览器内核或渲染实现。
准备 urls.txt:一行一个链接,可以不带协议,软件会按规则补全。主界面「网址文件」指向该 txt,支持拖入;「保存目录」指向空目录或专用归档盘,同样支持拖入。
保存方式二选一:按轮次文件夹适合定时多轮对比;按域名文件夹适合链接来自很多站点、想按站点分堆。
截图模式选全页面得到长图,选可视区域只截当前窗口高度内可见部分。宽度用像素旋钮在 320~3840 之间设,默认 1280,按你们设计基准或文档要求调。格式 PNG 无损体积大;JPG/WebP 可调质量,发邮件或进附件时更省体积。
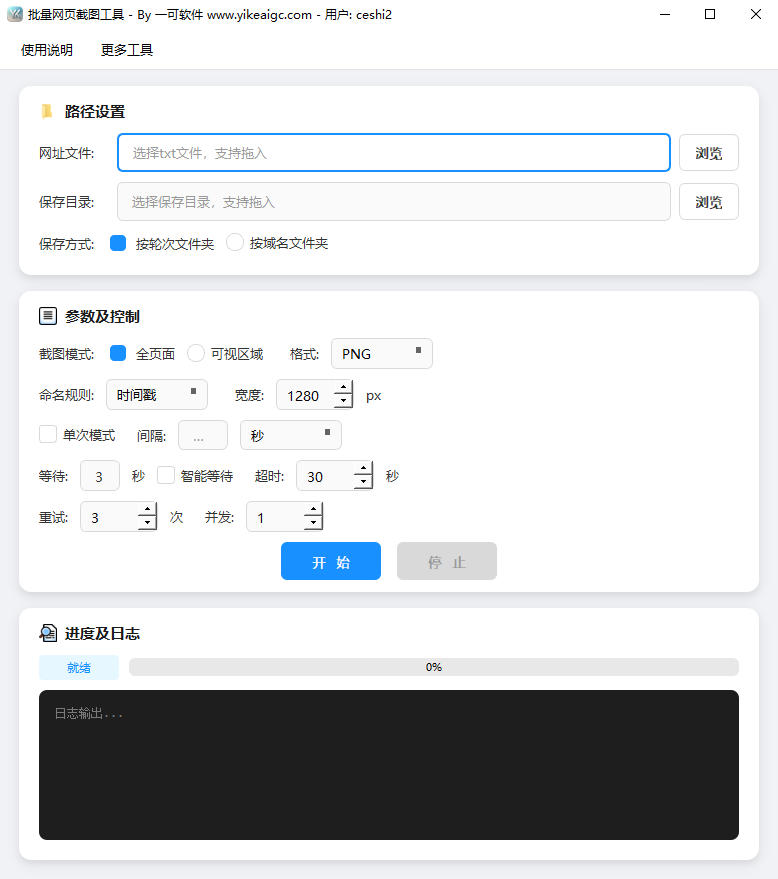
命名规则下拉与时间戳、序号、域名组合几种搭配,按你们资产命名规范选。运行区「单次模式」勾选则只执行一轮;取消勾选后出现间隔输入与单位(秒到日),用于定时重复截图。等待时间用秒;可切换智能等待,此时固定等待输入会按界面逻辑禁用。超时给足,避免复杂单页未加载完就判失败。重试次数按网络环境调;并发数同时开多个页面,机器内存吃紧时从 1 逐步加。
处理过程看进度条和日志,可随时停止。无效地址会在日志提示并跳过,不拖死整批任务。
它解决的是「列表驱动、批量出图」这一环,不负责登录态维护、不负责绕过反爬,有登录或鉴权的页面需自行保证截图时环境可用。