****论文题目:****Generative-Diffusion-Model-Based Deep-Learning Framework for Remaining Useful Life Prediction(基于生成扩散模型的剩余使用寿命预测深度学习框架)
****期刊:****IEEE INTERNET OF THINGS JOURNAL(IOTJ, Letter)
****摘要:****在这封信中,我们通过利用生成扩散模型,提出了一种新的高性能深度学习框架,用于剩余使用寿命(RUL)预测,称为RUL- diff。它由串联连接的两个模块组成:1)与我们定制的U-Net的编码器部分对应的特征提取器和2)由多层感知器构建的RUL预测器。我们进一步为所提出的RUL- diff设计了一种有效的两阶段训练方法,其中特征提取器首先进行预训练以获得高质量的特征学习,然后与RUL预测器联合进行再训练以获得准确的RUL预测。在NASA商用模块化航空推进系统仿真(C-MAPSS)数据集上的大量实验结果证明了该方案的优越性和有效性。
RUL-Diff:用生成扩散模型重新定义剩余使用寿命预测
一、背景:为什么 RUL 预测如此重要?
在工业物联网(IoT)的故障预测场景中,剩余使用寿命(Remaining Useful Life, RUL) 的准确预测至关重要。RUL 是指一个系统从当前时刻到发生故障前还能正常运行的时间长度。准确预测 RUL 能帮助我们:
- 提前规划维护计划,避免非计划停机
- 降低运维成本,延长设备使用周期
- 在监控系统、故障检测、基础设施维护等场景中发挥关键作用
然而,RUL 与各类退化因素之间存在复杂的非线性依赖关系,使得预测任务颇具挑战性。近年来,以深度学习(DL)为代表的数据驱动方法逐渐成为主流。
二、现有方法的问题在哪里?
在深入了解本文的创新之前,我们先梳理一下前人工作留下的"坑"。
2.1 传统机器学习方法:特征工程是瓶颈
早期研究(如文献1)使用多层感知机(MLP)、支持向量回归(SVR)、相关向量回归(RVR)等方法进行RUL预测。这些方法的致命弱点在于:依赖手工设计的特征表示------费时费力,且往往并非最优解。
2.2 CNN/LSTM 方法:各有盲区
为了解决手工特征的问题,基于 CNN 和 LSTM 的深度学习架构(文献2-8)被广泛应用。然而:
- CNN 架构 :擅长捕捉局部特征 ,但对 RUL 预测所需的全局时序特征捕获能力较弱
- LSTM 架构 :擅长建模时序依赖,但对局部细粒度特征的挖掘能力不足
- 共同缺陷 :两类方法都难以有效处理测量数据中不可避免的随机性(噪声或失真),导致特征质量差、预测性能受限
即使引入了无监督预训练(如文献3使用受限玻尔兹曼机 RBM,文献5使用健康指标 HSC),性能改善也相当有限。
2.3 VAE 生成模型:先验假设太简单
文献7意识到了随机性处理的问题,提出了基于变分自编码器(VAE)的 RVE 方法。引入生成模型是正确的方向,但 VAE 有一个根本性的技术局限:

VAE 假设隐空间服从简单的高斯先验分布,这往往无法充分捕获或表示测量数据中的复杂分布。
因此 RVE 的性能提升依然有限,特征提取质量仍不理想。
三、RUL-Diff:本文的解决方案
针对上述问题,本文提出了一个全新的深度学习框架------RUL-Diff ,核心思路是将当前最前沿的生成扩散模型(Generative Diffusion Model) 引入 RUL 预测任务。
据作者所知,这是首次将生成扩散模型用于 RUL 预测的工作。
3.1 网络架构
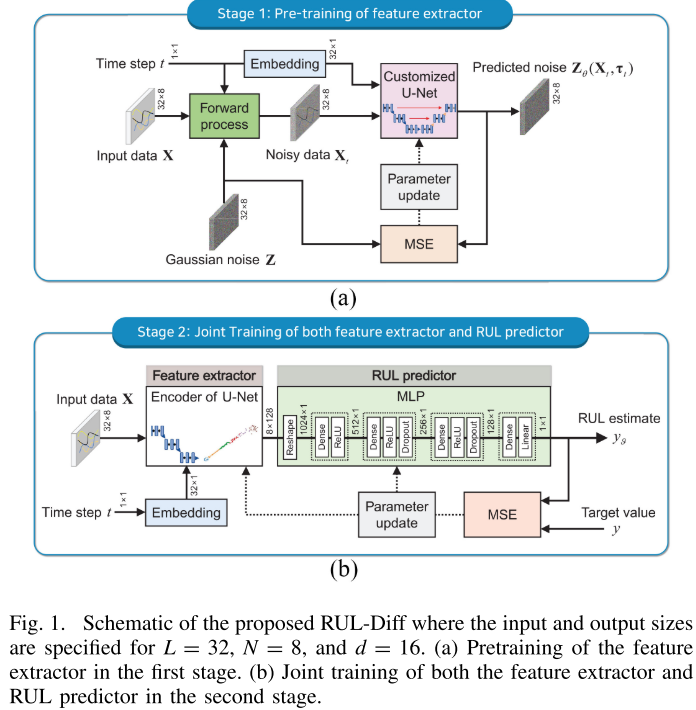
【配图位置:图1 --- RUL-Diff 整体框架示意图,包含(a)Stage 1预训练和(b)Stage 2联合训练两部分】
RUL-Diff 由两个串联的可学习模块组成:
模块一:特征提取器(Feature Extractor)
采用定制化 U-Net 的编码器部分作为特征提取器。
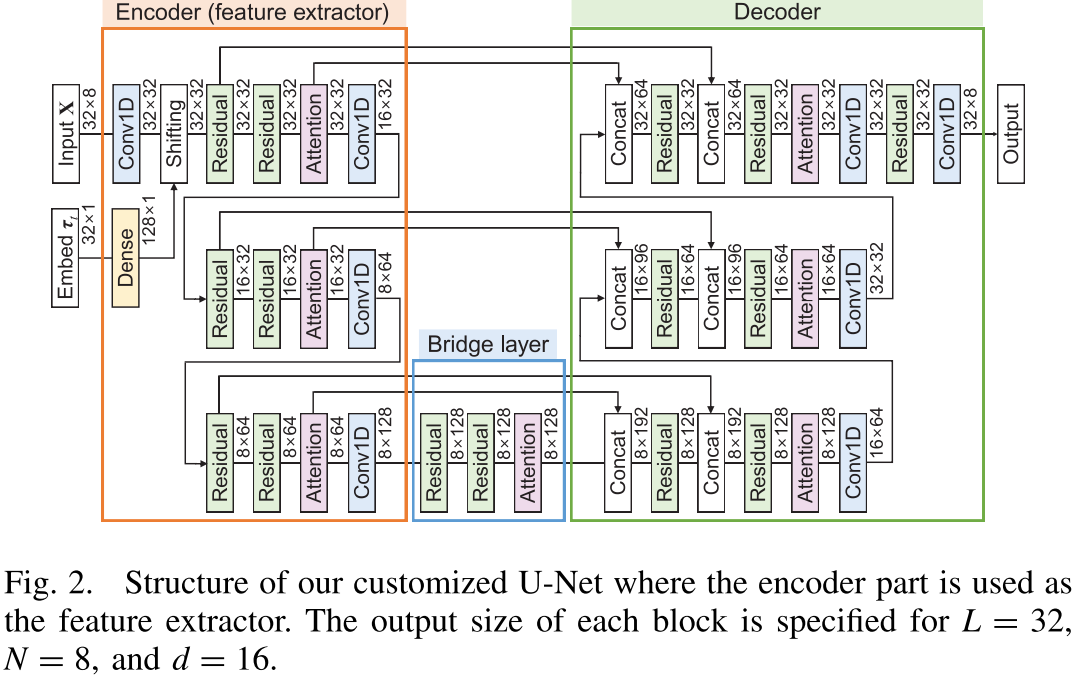
【配图位置:图2 --- 定制化 U-Net 的完整结构图,标注了各模块输出尺寸(L=32, N=8, d=16)】
该 U-Net 基于经典架构(Ho et al., NeurIPS 2020),并做了以下关键定制:
- 将所有 2-D 卷积层替换为 1-D 卷积层:专门处理时序数据,有效捕获局部特征
- 保留残差块(Residual Blocks):有助于训练更深的网络
- 保留注意力模块(Attention Modules) :有效捕获分层的全局特征
输入为时序数据 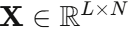 (L为序列长度,N为传感器数量)和时间步嵌入向量
(L为序列长度,N为传感器数量)和时间步嵌入向量 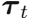 ,输出为中间特征向量。
,输出为中间特征向量。
这是首次在 RUL 预测中引入带有跳跃连接(skip connection)和注意力机制的 U-Net 架构。
模块二:RUL 预测器(RUL Predictor)
一个四层 MLP,将特征提取器的输出映射为具体的 RUL 数值:
- 前三层使用 ReLU 激活函数
- 最后一层使用线性激活函数(直接输出回归值)
- 中间两层施加 Dropout 防止过拟合
3.2 两阶段训练策略
这是本文另一个核心创新:设计了一套两阶段训练方法,使特征提取器被训练两次,从而实现更高质量的特征学习。
第一阶段:特征提取器预训练(自监督)
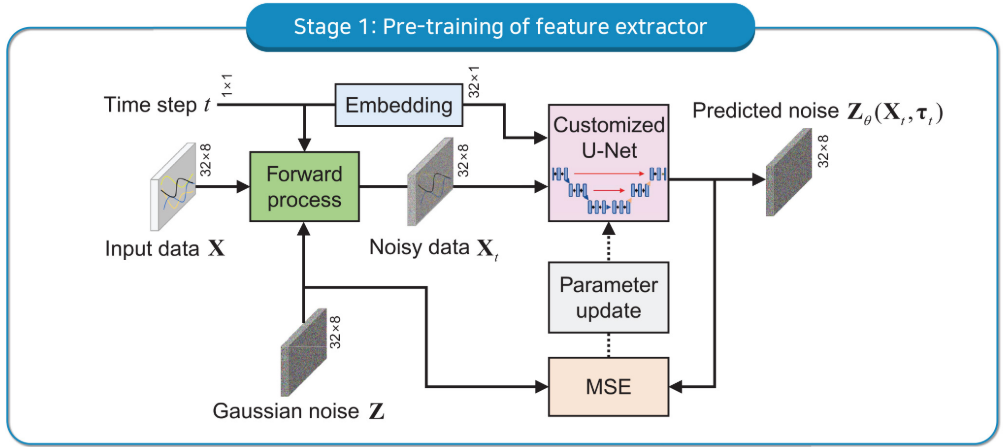
核心原理:借助扩散模型的前向扩散过程,让网络学会从被噪声污染的数据中还原出干净的特征。
前向扩散过程(逐步向原始数据加噪声):
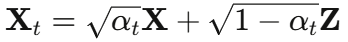
其中 为高斯噪声,
为高斯噪声,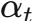 控制噪声强度随时间步 t 的变化。
控制噪声强度随时间步 t 的变化。
时间步 t通过正弦函数编码为向量 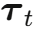 (类似 Transformer 中的位置编码)。
(类似 Transformer 中的位置编码)。
训练目标:最小化网络预测噪声与真实噪声之间的均方误差(MSE):
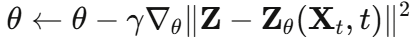
整个预训练过程完全自监督,无需 RUL 标签。
第二阶段:全网络联合训练(监督)
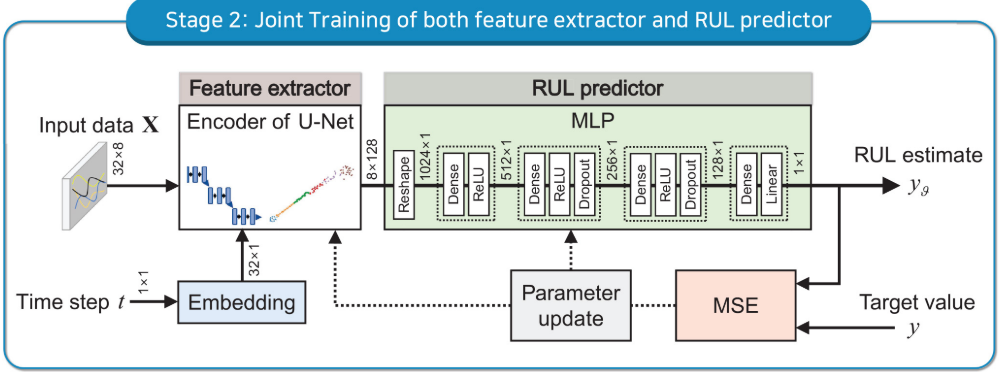
将 RUL 预测器接在预训练好的特征提取器后面,以真实 RUL 标签为监督信号,联合微调整个网络:
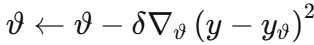
其中y为真实 RUL 值,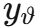 为网络估计值,
为网络估计值,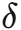 为学习率。
为学习率。
3.3 与已有方法的对比总结
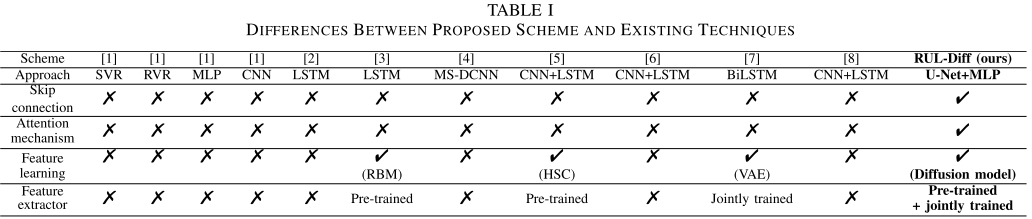
【配表位置:表I --- 提出方法与已有技术在跳跃连接、注意力机制、特征学习、特征提取器训练方式等方面的对比】
从表I可以看出,RUL-Diff 是唯一同时具备跳跃连接、注意力机制、基于扩散模型的特征学习,以及"预训练+联合训练"双阶段特征提取器的方法。
四、实验结果与分析
4.1 数据集与评估设置
实验在 NASA C-MAPSS 数据集上进行,该数据集包含四个子集(FD001--FD004),模拟航空发动机的退化过程,是 RUL 预测领域最主流的基准数据集。
评估指标:
- RMSE(均方根误差):衡量预测精度
- Score(自定义评分):对早期预测和晚期预测采用非对称惩罚
主要超参数设置:序列长度 L=32,传感器数 N=8,扩散步数 T=1000,嵌入维度 d=16,批大小 128,学习率 10^{-4},=10^{-5}。
4.2 特征质量可视化
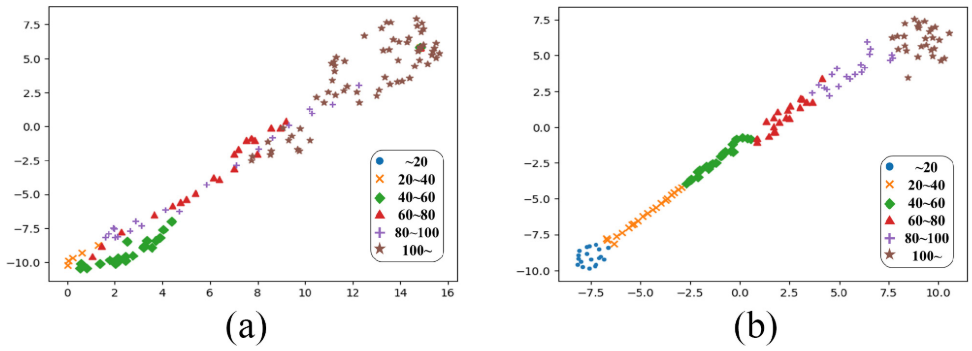
【配图位置:图3 --- t-SNE 特征可视化对比图,(a) RVE 7 vs (b) 提出的 RUL-Diff,颜色代表不同 RUL 值区间】
使用 t-SNE 将学到的特征降维到二维空间进行可视化。结果表明:
- RVE(VAE方法) :不同 RUL 值对应的特征点大量重叠,分布混乱
- RUL-Diff(本文方法) :即使在第一阶段预训练完成后,不同 RUL 值对应的特征已经高度分离、几乎无重叠
这直接说明扩散模型驱动的自监督预训练能学到质量更高的特征表示,原因在于其综合效应:
- 自监督学习的强大表征能力
- 多层次/分层特征表示
- 随机正则化效果
- 更强的鲁棒性
- 无近似偏差地捕获完整数据分布
4.3 RUL 预测性能
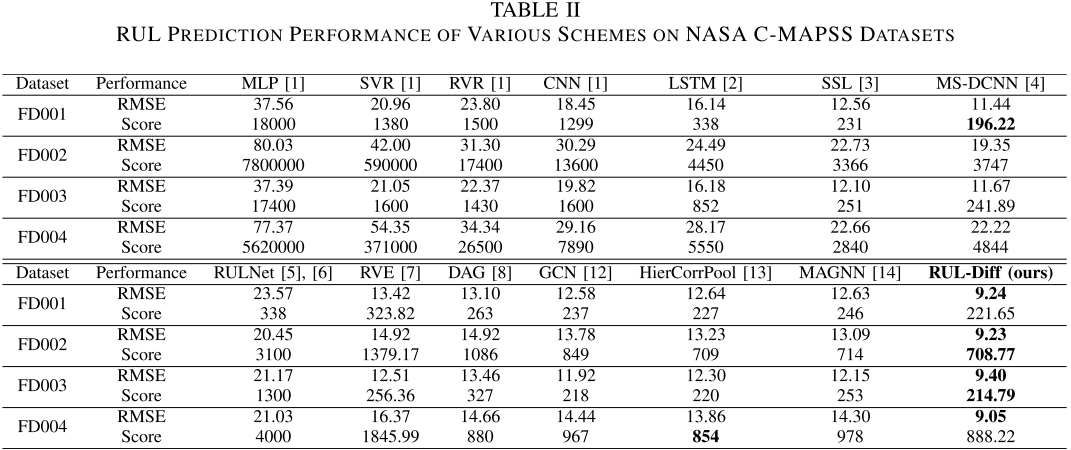
【配表位置:表II --- 各方法在 NASA C-MAPSS FD001-FD004 上的 RMSE 和 Score 性能对比完整表格】
与所有现有方法相比,RUL-Diff 在全部四个子数据集上均取得显著性能提升(以 RMSE 指标计):
| 数据集 | RMSE 提升幅度 |
|---|---|
| FD001 | ≥ 19.23% |
| FD002 | ≥ 29.49% |
| FD003 | ≥ 19.45% |
| FD004 | ≥ 34.70% |
4.4 学习曲线分析
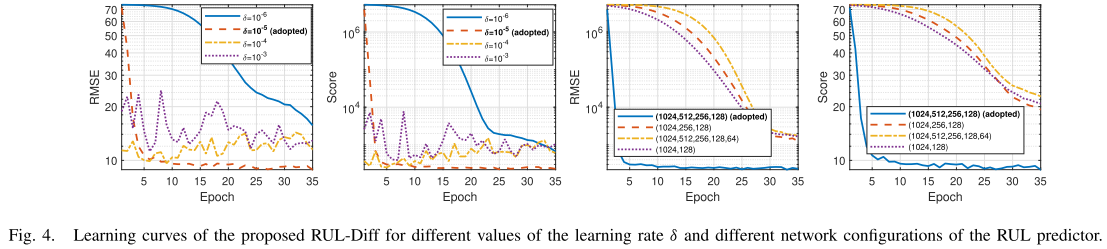
【配图位置:图4 --- 不同学习率 δ 和不同 RUL 预测器网络配置下的学习曲线对比图】
实验进一步分析了超参数对训练行为的影响:
- 学习率 δ 的影响 :较小的 δ 训练过程更稳定 ;较大的 δ 则导致不稳定的学习行为
- 预测器规模的影响 :
- 网络过大:过拟合,性能下降
- 网络过小:欠拟合,性能下降
- 适中规模的预测器表现最优
这些分析为实践中的模型调参提供了直接指导。
五、方法小结与未来展望
总结
RUL-Diff 的成功揭示了一个重要结论:
生成扩散模型凭借其对复杂数据分布的无偏近似捕获能力,能够为 RUL 预测任务提供高质量的特征表示,从而大幅超越现有方法。
本文的核心技术贡献可以归纳为三点:
- 架构创新:将 1-D U-Net(跳跃连接 + 注意力机制)引入 RUL 特征提取
- 训练创新:扩散模型驱动的自监督预训练 + 联合有监督微调的两阶段策略
- 理论突破:打破 VAE 的高斯先验假设局限,以扩散模型捕获任意复杂分布
实际应用场景
本文明确指出,RUL-Diff 可直接应用于:
- 工业设备监控系统
- 故障/异常检测
- 基础设施维护规划
未来研究方向
论文最后指出,一个极具吸引力的未来研究方向是:
将大型语言模型(LLMs)引入 RUL 预测任务。
这也预示着工业故障预测领域与 LLM 的深度融合将是下一个重要的研究前沿。