****论文题目:****Fault diagnosis for Computer Numerical Control lathes based on the fine-tuned large language model(基于微调大语言模型的数控车床故障诊断)
****期刊:****Journal of the Franklin Institute
****摘要:****在追求机械系统的效率、精度和可靠性的驱动下,现代制造业正在经历一场变革。作为关键设备,数控车床发挥着不可或缺的作用,其稳定性对防止经济损失和生产延误至关重要。提出了一种基于微调大语言模型的数控车床故障诊断框架。分层监督微调(HSFT)算法通过优化复合损失函数来平衡序列生成、分层分类和思维链(CoT)一致性正则化损失。这增强了模型的适应性,以精确地解决特定于领域的诊断挑战。CoT推理模块构建了一个结构化的逐步推理过程,通过故障分类、自验证、推理等多阶段方法,提高了诊断的准确性和可解释性。Qwen和LLaMA系列模型的实验结果表明,与基线模型相比,该方法的性能有了显著提高,验证了该方法的有效性。该框架为实际的数控车床故障诊断提供了鲁棒的解决方案,并为维护工程师提供了可操作的诊断见解。
用大语言模型诊断数控机床故障?这篇论文给出了一套完整方案
一、背景:CNC机床故障诊断为什么难?
数控(CNC)车床是现代制造业的核心装备,它的稳定运行直接决定着零部件的加工精度和生产连续性。一旦出现意外停机,轻则造成质量问题,重则带来巨大经济损失。因此,开发高效可靠的故障诊断方法,始终是智能制造领域的研究热点。
然而,现有方法面临两个根本性的困境:
1. 数据稀缺问题
工业现场中,机床正常运行数据十分丰富,但真实的故障数据极难获取------尤其是灾难性故障或罕见故障。这种严重的数据不均衡,导致模型在面对未见过的故障或变化工况时泛化能力很差。
2. "黑盒"不透明问题
现有深度学习方法虽然在受控实验室环境中准确率较高,但它们本质上是"黑盒"------输出一个结论,却不告诉工程师为什么。这种不透明性严重削弱了维修人员对诊断结果的信任,也让将上下文信息(如维修日志、说明书)融合进诊断过程变得极为困难。
3. 通用LLM的领域鸿沟
大语言模型(LLM)具备强大的推理能力和多源信息整合能力,近年来已被探索用于故障诊断。但通用LLM缺乏CNC机床的垂直领域知识,直接使用时表现不尽如人意,无法满足工业落地需求。
二、论文提出的解决框架总览
本文提出了一套完整的"数据采集与格式化 → 层次化监督微调 → CoT推理与响应生成"两阶段框架。
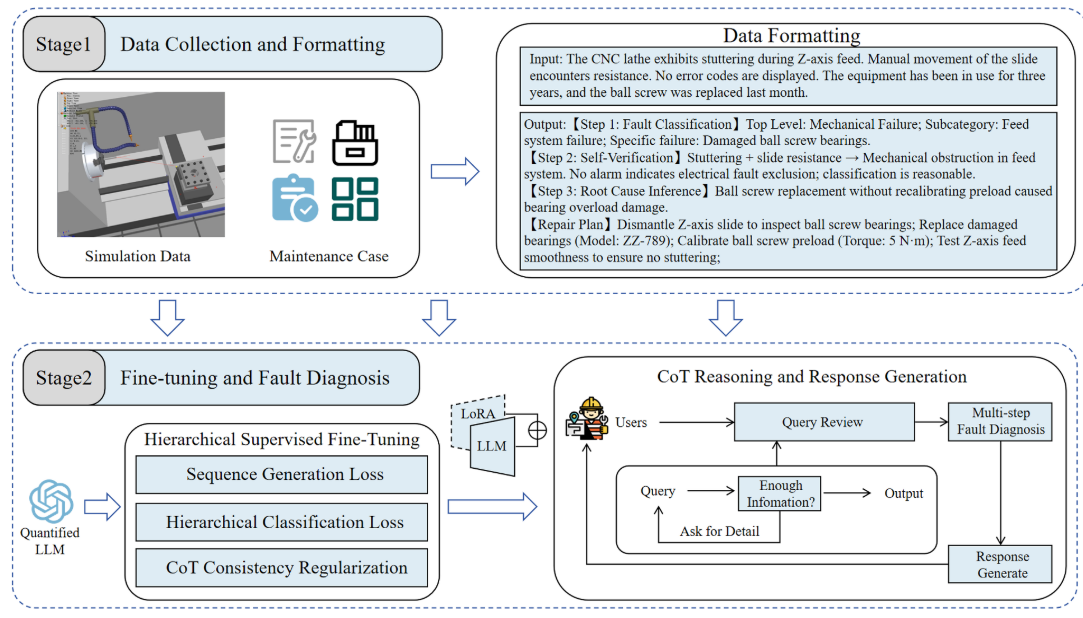
📌 配图 :论文 Fig. 2(Overall framework,整体框架图),展示两个阶段的完整流程。
整体思路可以概括为:
- Stage 1:从工厂真实维修记录(500条)+ 仿真软件生成的程序错误案例(50条)中构建数据集,并进行结构化格式化;
- Stage 2 :使用提出的 HSFT 算法 对量化后的LLM进行微调,再通过 CoT推理模块完成结构化的诊断与响应生成。
三、核心创新一:HSFT------层次化监督微调算法
3.1 为什么需要新的微调算法?
标准的监督微调(SFT)只使用序列生成损失,对所有 token 一视同仁,无法区分"spindle bearing(主轴轴承)"这类诊断关键词和"and"、"first"这类无诊断价值的结构词。更重要的是,普通SFT既不能保证模型按照正确的故障层次进行分类,也不能保证推理链路的逻辑一致性。
HSFT 的核心在于一个复合损失函数,它将三种不同目标的损失融为一体,并通过动态权重加以平衡:
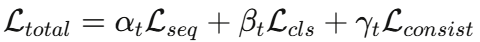
其中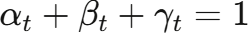 ,三个权重随训练步数动态调整。
,三个权重随训练步数动态调整。
3.2 三个损失分量详解
① 序列生成损失 Lseq(带 Token 级加权的交叉熵)
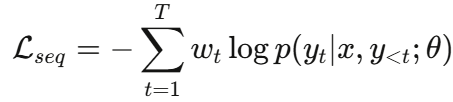
普通交叉熵对每个 token 的权重均为 1.0。HSFT 在此基础上引入了 token 级加权:
- 领域关键词(如"spindle bearing")和关键推理标记(如"top-level category: mechanical fault"):权重 w= 1.5
- 无诊断价值的结构词(标点、连词、无意义副词等):权重 wt = 1.0
这使得模型在训练时将更多注意力集中在诊断相关的内容上。
② 层次分类损失 Lcls(分步加权的分类交叉熵)
CNC故障诊断天然具有层次结构,例如:机械故障 → 主轴系统故障 → 轴承磨损。论文将诊断分为 K=3 个层次步骤(顶层类别、子类别、具体故障)。每步的分类损失为:
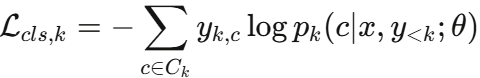
各步汇总时施加步骤重要性权重
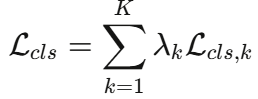
其中 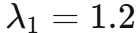 (顶层分类错误会级联影响后续所有步骤),
(顶层分类错误会级联影响后续所有步骤),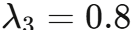 (末级错误可被上下文纠正)。
(末级错误可被上下文纠正)。
③ CoT 一致性正则化损失 Lconsist(基于故障树的二元惩罚)
逻辑不一致的推理链路会使诊断完全失效------例如第1步分类为"机械故障",第2步却推断为"电气系统故障"。论文预先构建了一棵 CNC故障树 ,定义了合法的步骤间依赖关系,通过一致性函数 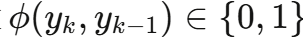 来判定相邻步骤是否逻辑相容:
来判定相邻步骤是否逻辑相容:
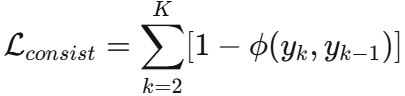
违反父子类别关系即施加固定惩罚,符合则无额外损失。
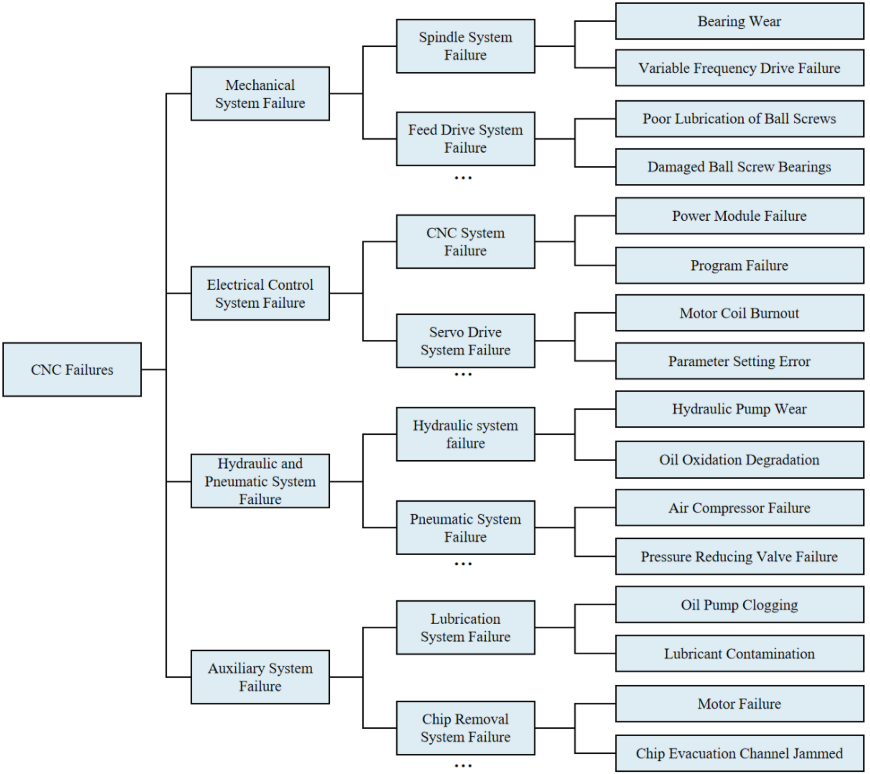
📌 配图 :论文 Fig. 3(Partial prebuilt fault tree,部分预构建故障树),直观展示故障树的层次结构(CNC Failures → 机械/电控/液压气动/辅助系统故障 → 各子系统 → 具体故障类型)。
3.3 动态权重:三阶段渐进调整
为了避免训练初期被正则化主导(阻碍CoT生成)、训练后期忽视一致性(导致推理路径失逻辑)的问题,论文引入了指数衰减函数控制三个权重的动态演变:
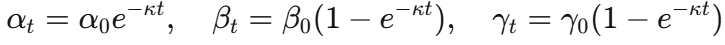
其中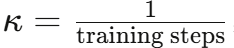 ,初始值均为1。这样,训练初期侧重序列生成能力,训练后期逐渐增强分类和一致性约束,实现平滑过渡。
,初始值均为1。这样,训练初期侧重序列生成能力,训练后期逐渐增强分类和一致性约束,实现平滑过渡。
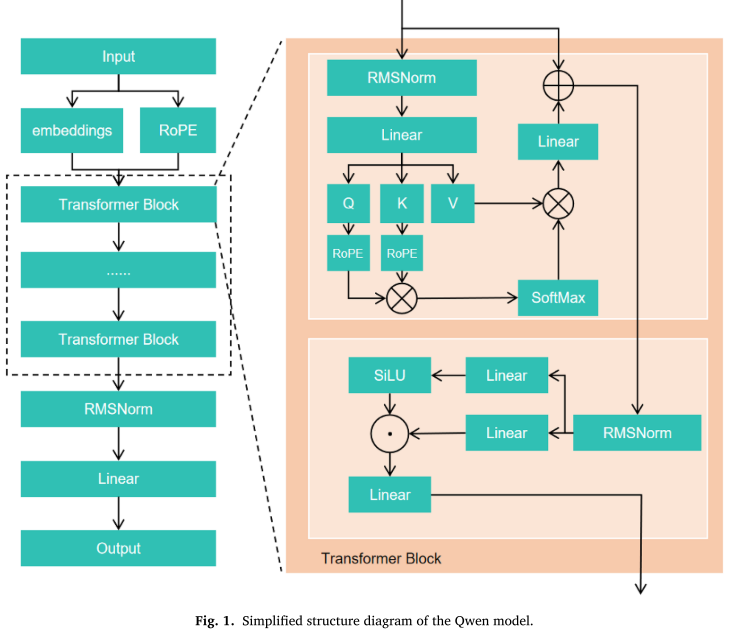
3.4 训练算法与 LoRA
结合 LoRA(低秩适配)进行参数高效微调:对预训练权重矩阵 W0 引入低秩分解 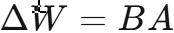 ,仅训练维度远小于原矩阵的 A、B,将可训练参数量从d*k降至 r*(d+k)。
,仅训练维度远小于原矩阵的 A、B,将可训练参数量从d*k降至 r*(d+k)。

📌 配图 : Algorithm 1(HSFT training algorithm with LoRA 伪代码),帮助读者理解训练流程。
四、核心创新二:CoT 推理与响应生成模块
经过 HSFT 微调的 LLM,通过一套精心设计的多步推理工作流与用户交互,完成从"提问"到"出具诊断报告"的全过程。
整体流程(三阶段)
用户输入 Query
↓
[阶段1] 查询审核(Query Review)
├─ 信息足够 → 进入多步诊断
└─ 信息不足 → 追问用户补充细节(循环)
↓
[阶段2] 多步故障诊断(Multi-step Fault Diagnosis)
├─ Step 1:故障分类(Fault Classification)
│ 按位置、性质、表现形式、原因初步分类
├─ Step 2:自我判断(Self Judgment)
│ 对 Step 1 结果进行合理性验证
└─ Step 3:推理(Reasoning)
综合所有信息进行根因推理
↓
[阶段3] 响应生成(Response Generate)
输出:故障分类 + CoT推理路径 + 根因分析 + 维修方案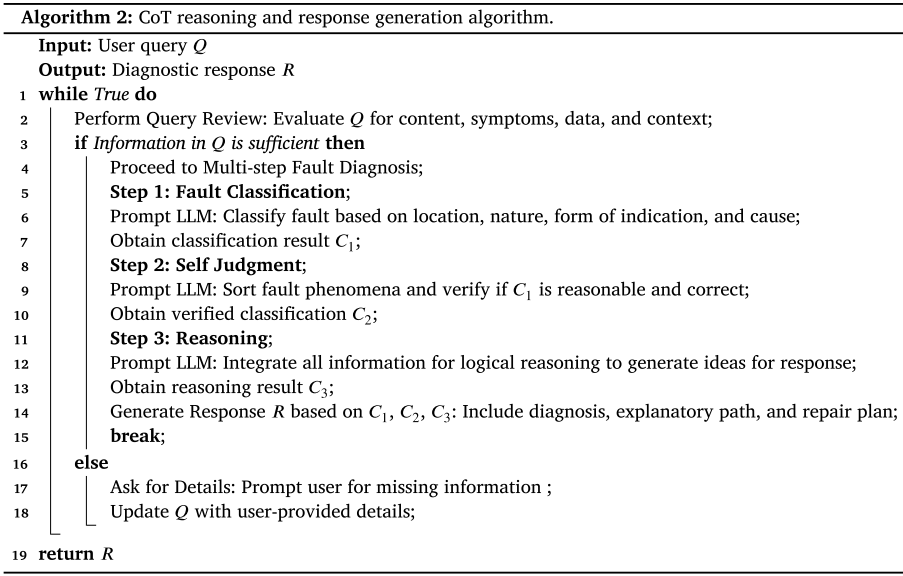
📌 Algorithm 2(CoT reasoning and response generation algorithm 伪代码)。
自我判断(Self Judgment)步骤是一个亮点设计------它引入了自我验证机制,在给出最终结论前先对初步分类进行合理性审查,有效降低误诊率。
响应生成阶段的输出包含四个关键要素:
- 清晰的故障层次分类结果
- 详细的 CoT 推理路径(可供工程师验证)
- 根因分析及潜在级联影响评估
- 针对具体故障场景的可执行维修方案
五、实验设置
数据集
- 微调数据集:550 条(500 条来自工厂真实维修记录 + 50 条 Swansoft CNC Simulator v7.2.7.8 仿真生成的程序错误案例,仿真机型:Fanuc 0i-TF)
- 验证集:150 条来自工厂的真实维修记录
- 每条数据包含:故障表现描述、顶层/子类别故障分类、具体故障诊断、对应维修方案
实验模型
Qwen3-8B、Qwen3-4B、Qwen3.1-1.7B、LLaMA3.1-8B、LLaMA3.2-3B
评估方法
将评估转化为二分类问题:对每个测试案例提供两个选项------人工标注的正确答案,以及由未微调的 Qwen3-8B 生成的低质量干扰答案,计算 Accuracy、Precision、Recall、F1 Score 四项指标。
硬件环境
双 NVIDIA A5000 GPU(各 24GB VRAM),Windows 10 Pro,Python 3.10.8,PyTorch 2.0。
六、实验结果
6.1 Qwen 系列模型结果
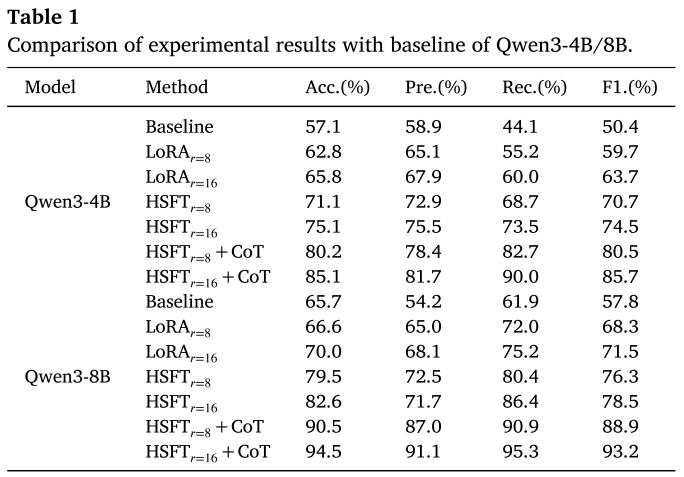
📌 配表 :Table 1(Comparison of experimental results with baseline of Qwen3-4B/8B)。
结果非常亮眼:
Qwen3-8B:
- 基线模型:Acc. 65.7%,F1 57.8%
- LoRA(r=16):Acc. 70.0%,F1 71.5%(提升有限)
- HSFT(r=16):Acc. 82.6%,F1 78.5%(大幅提升)
- HSFT(r=16)+ CoT :Acc. 94.5% ,Pre. 91.1% ,Rec. 95.3% ,F1 93.2%
Qwen3-4B:
- 基线模型:Acc. 57.1%,F1 50.4%
- HSFT(r=16)+ CoT :Acc. 85.1% ,F1 85.7%
关键结论:HSFT 相比单纯的 LoRA 带来了显著更大的提升,CoT 推理模块的加入进一步将性能推到更高水平。
6.2 LLaMA 系列模型结果
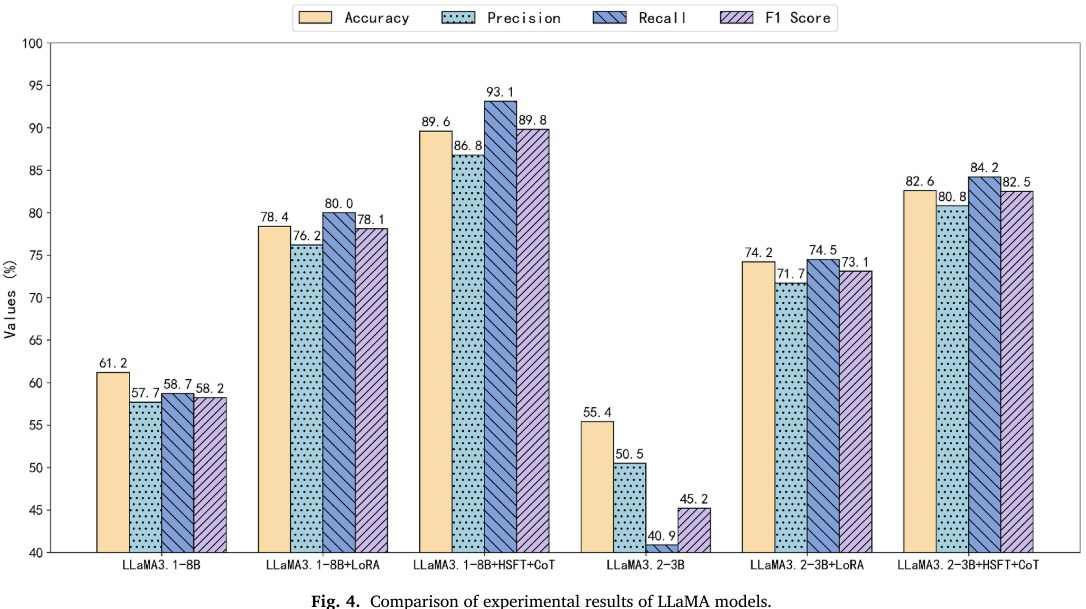
📌 配图 :Fig. 4(Comparison of experimental results of LLaMA models 柱状图)。
方法在 LLaMA 系列上同样表现优秀:
- LLaMA3.1-8B + HSFT + CoT:Acc. 89.5%,Pre. 86.8%,Rec. 93.1%,F1 89.8%(基线 61.2%/58.2%)
- LLaMA3.2-3B + HSFT + CoT:Acc. 82.6%,F1 82.5%(基线 55.4%/45.2%)
这证明了该框架具有跨模型架构的强泛化能力,并非针对特定LLM的过拟合优化。
6.3 噪声鲁棒性测试
为模拟工业现场工程师输入习惯(表述混乱、信息冗余),论文在测试集中引入两类噪声:
- 词序调整:打乱症状描述与上下文信息的顺序
- 随机干扰词插入:插入与CNC故障无关的领域术语或冗余描述
在 Qwen3.1-1.7B(全参数微调)上的测试结果:
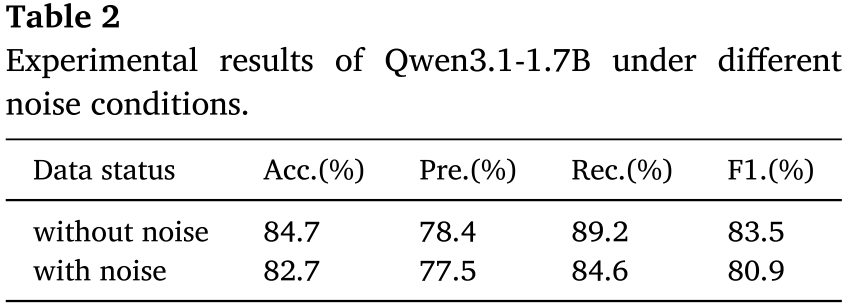
📌 配表 :Table 2(Experimental results of Qwen3.1-1.7B under different noise conditions)。
加入噪声后性能仅下降约 2%,充分说明了框架的鲁棒性。
6.4 消融实验
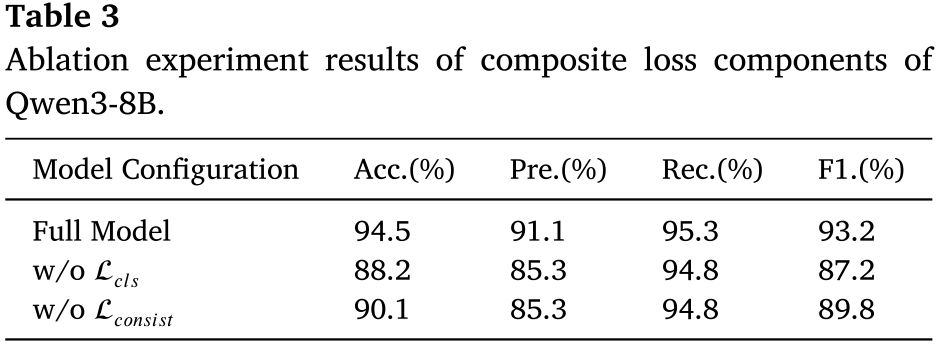
📌 配表: Table 3(Ablation experiment results of composite loss components of Qwen3-8B)。
以 Qwen3-8B + LoRA(r=16)为基础模型,逐一去除各损失组件:分析:
- 去除Lcls:召回率和 F1 下降最显著。因为没有层次分类约束,模型在顶层或子类别阶段容易出现错误,引发级联推理失误。
- 去除Lconsist:精确率从 91.1% 跌至 85.3%,降幅最大。因为缺乏逻辑一致性惩罚,模型产生自相矛盾的推理路径,导致假阳性诊断增多。
- 完整模型 在所有指标上均达到最优,验证了三个损失组件相辅相成、缺一不可。
七、实际案例演示
案例一:主轴不平衡故障
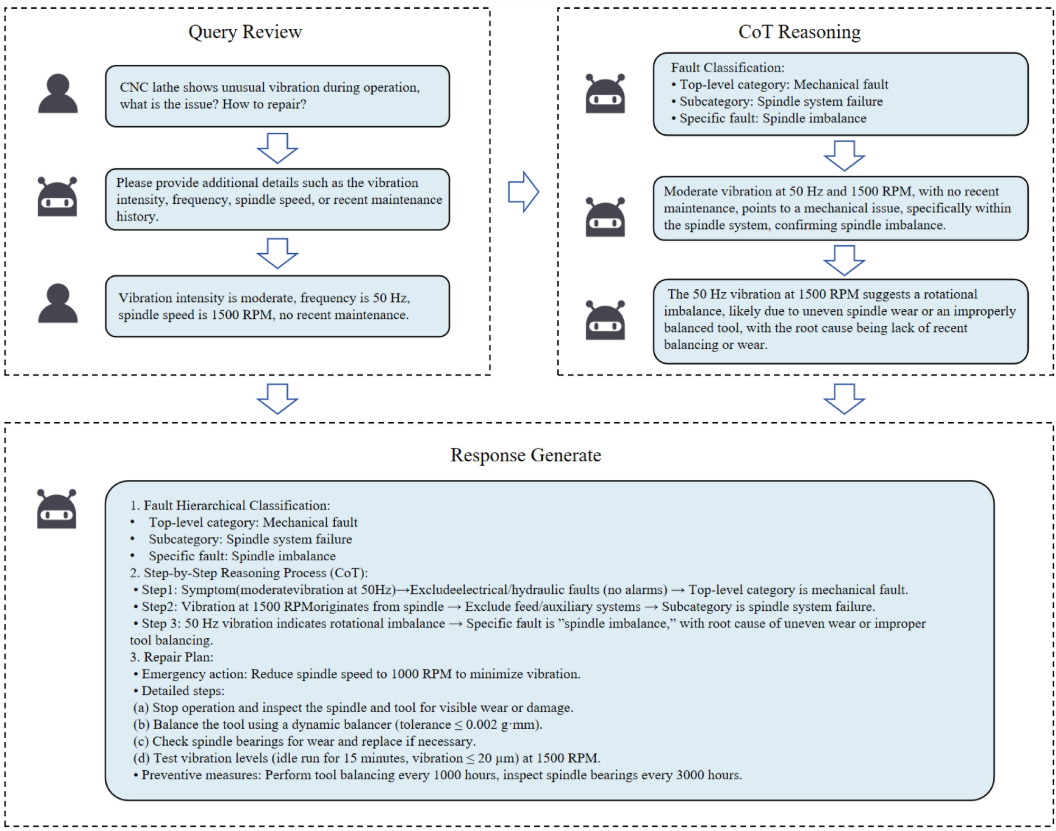
📌 配图 :Fig. 5(Case study on spindle imbalance,主轴不平衡案例截图)。
输入场景:CNC车床在运行中出现异常振动和噪声,维修日志显示最近刚对主轴系统进行了大修。
系统诊断过程:
- 查询审核:评估用户描述的症状和维修背景,信息充足,进入诊断阶段。
- 故障分类:根据振动和噪声的位置与性质,初步分类为"机械故障 → 主轴系统故障"。
- 自我判断:确认初步分类合理。
- 推理:结合症状数据、维修日志和领域知识,推断根本原因为大修过程中重新装配不当,导致主轴轴承过度磨损。
最终输出:
- 故障层次分类:机械故障 → 主轴系统故障 → 主轴不平衡
- CoT 推理路径:50Hz振动 → 排除电气/液压故障 → 确认机械故障 → 1500RPM振动来源于主轴 → 旋转不平衡(磨损或刀具不平衡)
- 维修方案:使用动平衡仪(公差≤0.002 g·mm)平衡刀具,检查并替换主轴轴承,怠速测试振动水平(≤20 μm@1500RPM)
该诊断经专家验证,准确性和实用性均获认可。
案例二:刀架松动故障
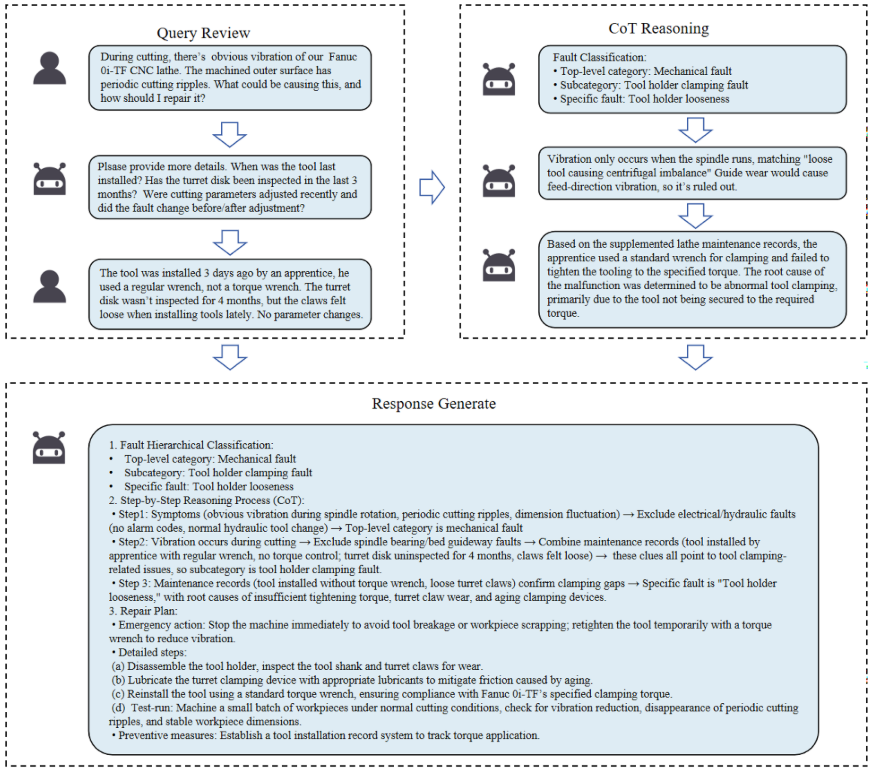
📌 配图 :Fig. 6(Case study on tool holder looseness,刀架松动案例截图)。
输入场景:切削过程中出现明显振动,外表面出现周期性切削波纹。
系统诊断过程亮点:
- 在查询审核阶段,系统判断初始信息不足,主动追问用户(刀具最后安装时间、转台盘检查情况、参数调整记录等)。
- 用户补充:刀具3天前由学徒安装,使用的是普通扳手而非扭矩扳手,转台盘卡爪感觉松动。
- 系统据此在推理阶段准确识别根因:未按规定扭矩紧固导致刀架松动。
最终维修方案:拆卸刀架检查磨损 → 润滑刀架夹紧装置 → 使用扭矩扳手按照 Fanuc 0i-TF 规定扭矩重新安装 → 试切验证。预防措施:建立刀具安装记录系统。
八、论文的局限与未来展望
作者在论文中也坦诚地指出了现有工作的不足,并规划了四个方向的后续研究:
- 引入领域知识图谱:结合检索增强生成(RAG)方法,将分散的专家知识和历史维修数据结构化组织,提升复杂多原因故障的诊断精度。
- 优化提示工程与微调策略:简化模型交互逻辑,使其更贴合现场维修人员的操作习惯。
- 稀有故障数据采集:通过工业合作和高保真仿真,专门收集灾难性主轴故障、初期电气系统故障等罕见数据。
- 轻量化模型设计:降低计算资源需求,使系统能够部署在车间普通工控设备上,真正实现边缘部署。
九、总结
本文最核心的贡献,是将大语言模型从通用助手成功改造为CNC车床领域的专业诊断专家,同时解决了两个长期困扰工业故障诊断的难题:
| 传统痛点 | 本文解法 |
|---|---|
| 标注故障数据少 | LoRA + HSFT,550条样本实现高效适配 |
| 模型缺乏领域知识 | 复合损失函数 + 预构建故障树对齐领域结构 |
| 诊断结果不可解释 | CoT三步推理,输出完整透明的推理路径 |
| 推理逻辑容易前后矛盾 | CoT一致性正则化损失,显式惩罚逻辑矛盾 |
最终,Qwen3-8B + HSFT + CoT 达到了 94.5% 准确率、93.2% F1分数 的出色水平,且在跨模型(LLaMA系列)和噪声鲁棒性测试中均保持强劲表现。这套框架为大语言模型在工业智能诊断领域的落地应用,提供了一个完整、可复现的技术范本。