摘要
在实际的雷达目标跟踪系统中,通常需要同时跟踪多个目标。多目标跟踪(Multi-Target Tracking, MTT)面临的核心挑战是数据关联(Data Association)问题:如何将雷达观测与现有目标航迹正确关联。本文将从多目标跟踪的基本原理出发,深入讲解最近邻(NN)、概率数据关联(PDA)、联合概率数据关联(JPDA)等经典数据关联算法的数学原理和实现方法,并通过多个完整的Python示例演示其在实际场景中的应用和性能对比。
目录
-
多目标跟踪系统概述
-
数据关联问题描述
-
最近邻(NN)数据关联
-
概率数据关联(PDA)
-
联合概率数据关联(JPDA)
-
航迹起始与管理
-
Demo 4-1:最近邻数据关联实现
-
Demo 4-2:概率数据关联实现
-
Demo 4-3:联合概率数据关联实现
-
Demo 4-4:密集多目标跟踪场景对比
-
总结与工程实践建议
1. 多目标跟踪系统概述
1.1 多目标跟踪的基本流程
多目标跟踪系统通常包含以下关键模块:
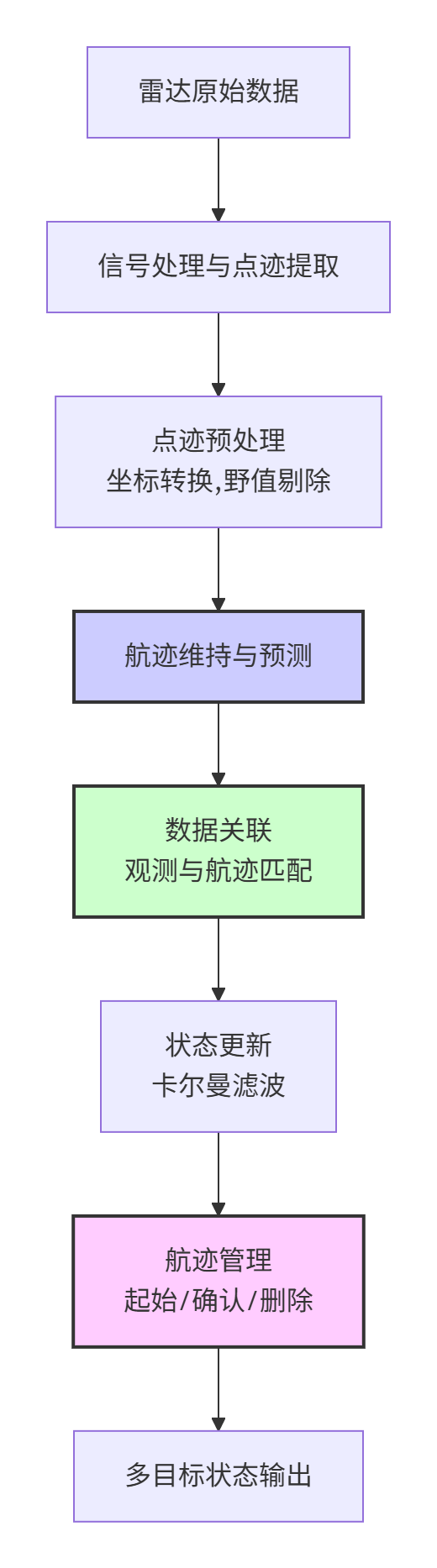
1.2 多目标跟踪的数学描述
考虑一个多目标跟踪场景,假设在时刻 k有:

其中 0 表示虚警(false alarm),即观测不来自任何已知目标。
1.3 多目标跟踪的主要挑战
-
量测-航迹关联模糊:多个目标、虚警、漏检等情况下的正确关联
-
航迹起始与终结:新目标出现、目标消失的检测
-
航迹交叉与合并:目标接近时的关联混淆
-
计算复杂度:随着目标数量增加,关联可能性组合爆炸
-
密集环境下的性能:高虚警率、高目标密度下的跟踪维持
2. 数据关联问题描述
2.1 关联门(Gate)技术
为了减少计算量,通常使用关联门来限制需要考虑的观测-航迹对。最常用的是椭圆关联门。


2.2 关联假设的生成
对于 M个目标和 N个观测,可能的关联假设数量为:

3. 最近邻(NN)数据关联
3.1 算法原理
最近邻算法是最简单的数据关联方法,其基本思想是将每个观测关联到"最近"的航迹预测。通常使用马氏距离(Mahalanobis distance)作为距离度量。
算法步骤:
-
对每个航迹,计算其预测观测和新息协方差
-
计算所有观测-航迹对之间的马氏距离
-
为每个航迹选择距离最近的观测(在关联门内)
-
处理冲突:一个观测只能关联给一个航迹
-
未关联的观测可能来自新目标或虚警
-
未关联的航迹可能发生漏检
3.2 数学描述

3.3 优缺点分析
优点:
-
计算简单,实时性好
-
实现容易
-
适用于稀疏目标场景
缺点:
-
容易产生误关联
-
不处理关联不确定性
-
在密集目标场景性能下降明显
4. 概率数据关联(PDA)
4.1 算法原理
概率数据关联为每个有效观测分配一个概率权重,表示该观测来自该航迹的可能性,然后进行加权更新。
算法步骤:
-
确定每个航迹的有效观测集合(在关联门内)
-
计算每个有效观测的关联概率
-
使用加权和更新航迹状态
-
考虑虚警和漏检概率
4.2 数学描述



4.3 优缺点分析
优点:
-
考虑了关联不确定性
-
比NN更鲁棒
-
计算复杂度适中
缺点:
-
假设一个目标最多产生一个观测
-
不显式处理多目标关联
-
在密集目标场景可能产生关联混淆
5. 联合概率数据关联(JPDA)
5.1 算法原理
联合概率数据关联是PDA的多目标扩展,它考虑了多个目标之间的关联相互依赖性,通过生成和评估所有可行的联合关联事件来计算关联概率。
算法步骤:
-
为每个目标建立确认矩阵(validation matrix)
-
生成所有可行的联合关联事件
-
计算每个联合事件的概率
-
计算边缘关联概率
-
使用加权和更新每个目标状态
5.2 确认矩阵表示

5.3 联合关联事件
一个联合关联事件 θ是一个从观测到目标的映射,满足:
-
每个观测最多关联给一个目标
-
每个目标最多接收一个观测(假设点目标)
5.4 联合事件概率计算
联合事件 θ的概率:

5.5 边缘关联概率
观测 j关联到目标 t的边缘概率:

5.6 优缺点分析
优点:
-
显式处理多目标关联
-
在密集目标场景性能好
-
理论完备
缺点:
-
计算复杂度高(联合事件数组合爆炸)
-
实现复杂
-
需要近似算法(如Murty算法)处理大规模问题
6. 航迹起始与管理
6.1 航迹起始
航迹起始是从观测序列中检测出新目标并初始化的过程。常用方法:
-
逻辑法:
-
基于连续多帧观测形成临时航迹
-
满足起始条件后确认为稳定航迹
-
-
Hough变换法:
- 在参数空间检测直线运动目标
-
批处理法:
- 积累多帧数据后批量处理
M/N逻辑起始:
-
在连续的 M帧中至少有 N次成功关联
-
常用 2/3、3/4 等规则
6.2 航迹确认与删除
航迹确认:
-
临时航迹满足一定条件后转为稳定航迹
-
条件:连续关联成功次数、状态不确定性等
航迹删除:
-
计数法:连续 L次未关联则删除航迹
-
概率法:航迹存在概率低于阈值则删除
-
协方差法:状态不确定性超过阈值则删除
7. Demo 4-1:最近邻数据关联实现
这个Demo将实现一个完整的多目标跟踪系统,使用最近邻数据关联和卡尔曼滤波。
python
"""
demo_4_1_nearest_neighbor_association.py
最近邻数据关联实现
"""
import numpy as np
import matplotlib.pyplot as plt
from scipy.spatial.distance import cdist
from scipy import stats
import sys
import os
sys.path.append(os.path.dirname(os.path.dirname(os.path.abspath(__file__))))
# 引入之前实现的卡尔曼滤波器和运动模型
from demo_3_1_motion_models_comparison import CVFilter
class Track:
"""目标航迹类"""
def __init__(self, track_id, initial_state, initial_cov, filter_class=CVFilter,
filter_params=None, creation_time=0):
"""
初始化航迹
参数:
track_id: 航迹ID
initial_state: 初始状态 [x, y, vx, vy]
initial_cov: 初始协方差
filter_class: 使用的滤波器类
filter_params: 滤波器参数
creation_time: 创建时间
"""
self.track_id = track_id
self.creation_time = creation_time
self.last_update_time = creation_time
self.update_count = 0
self.miss_count = 0
self.status = 'TENTATIVE' # 状态: TENTATIVE, CONFIRMED, DELETED
self.age = 0
# 初始化滤波器
if filter_params is None:
filter_params = {'dt': 1.0, 'q': 0.1}
self.filter = filter_class(**filter_params)
self.filter.x = initial_state.reshape(-1, 1)
self.filter.P = initial_cov
# 航迹历史
self.history = {
'states': [initial_state.copy()],
'covariances': [initial_cov.copy()],
'measurements': []
}
def predict(self):
"""预测步骤"""
x_pred, P_pred = self.filter.predict()
return x_pred, P_pred
def update(self, measurement, R):
"""
更新步骤
参数:
measurement: 观测值
R: 观测噪声协方差
"""
x_est, P_est = self.filter.update(measurement, R)
self.last_update_time += 1
self.update_count += 1
self.miss_count = 0
# 保存历史
self.history['states'].append(x_est.flatten().copy())
self.history['covariances'].append(P_est.copy())
self.history['measurements'].append(measurement.copy())
# 检查航迹确认
if self.status == 'TENTATIVE' and self.update_count >= 3:
self.status = 'CONFIRMED'
return x_est, P_est
def miss(self):
"""漏检处理"""
self.miss_count += 1
self.last_update_time += 1
# 保存预测状态到历史
x_pred, P_pred = self.predict()
self.history['states'].append(x_pred.flatten().copy())
self.history['covariances'].append(P_pred.copy())
self.history['measurements'].append(None)
def get_state(self):
"""获取当前状态"""
return self.filter.x.flatten()
def get_covariance(self):
"""获取当前协方差"""
return self.filter.P
def get_predicted_measurement(self, H=None):
"""
获取预测观测
参数:
H: 观测矩阵,如果为None则使用位置观测
"""
if H is None:
H = np.array([[1, 0, 0, 0], [0, 1, 0, 0]])
z_pred = H @ self.filter.x
S = H @ self.filter.P @ H.T
return z_pred, S
def is_confirmed(self):
"""检查航迹是否已确认"""
return self.status == 'CONFIRMED'
def should_delete(self, max_misses=5):
"""检查是否应删除航迹"""
if self.status == 'TENTATIVE' and self.miss_count >= 2:
return True
elif self.status == 'CONFIRMED' and self.miss_count >= max_misses:
return True
return False
class NearestNeighborTracker:
"""最近邻多目标跟踪器"""
def __init__(self, gate_threshold=9.21, # 卡方分布0.99分位数,2自由度
detection_prob=0.9, false_alarm_density=1e-4,
measurement_noise_std=5.0,
new_track_threshold=3, # 新航迹起始阈值
deletion_threshold=5): # 航迹删除阈值
"""
初始化最近邻跟踪器
参数:
gate_threshold: 关联门限
detection_prob: 检测概率
false_alarm_density: 虚警空间密度
measurement_noise_std: 观测噪声标准差
new_track_threshold: 新航迹起始阈值
deletion_threshold: 航迹删除阈值
"""
self.gate_threshold = gate_threshold
self.P_D = detection_prob
self.lambda_fa = false_alarm_density
self.R = np.eye(2) * measurement_noise_std**2
self.new_track_threshold = new_track_threshold
self.deletion_threshold = deletion_threshold
# 跟踪器状态
self.tracks = {} # track_id -> Track对象
self.next_track_id = 0
self.time = 0
# 历史记录
self.history = {
'tracks': [],
'measurements': [],
'associations': []
}
def process_scan(self, measurements):
"""
处理一帧观测
参数:
measurements: 观测列表,每个观测为 [x, y]
返回:
current_tracks: 当前活跃航迹
"""
self.time += 1
measurements = np.array(measurements)
if len(measurements) == 0:
# 没有观测,所有航迹漏检
for track in self.tracks.values():
track.miss()
return self._get_active_tracks()
# 1. 预测所有航迹
predicted_measurements = {}
innovation_covariances = {}
for track_id, track in self.tracks.items():
if track.status != 'DELETED':
# 预测
track.predict()
# 计算预测观测
z_pred, S = track.get_predicted_measurement()
predicted_measurements[track_id] = z_pred.flatten()
innovation_covariances[track_id] = S
# 2. 数据关联(最近邻)
if predicted_measurements:
# 构建距离矩阵
track_ids = list(predicted_measurements.keys())
z_preds = np.array([predicted_measurements[track_id] for track_id in track_ids])
# 计算马氏距离
distances = np.zeros((len(measurements), len(track_ids)))
for i, z_meas in enumerate(measurements):
for j, track_id in enumerate(track_ids):
z_pred = z_preds[j]
S = innovation_covariances[track_id]
innov = z_meas - z_pred
# 马氏距离
try:
dist = innov @ np.linalg.inv(S) @ innov
distances[i, j] = dist
except np.linalg.LinAlgError:
distances[i, j] = np.inf
# 3. 执行最近邻关联
associations = {} # track_id -> measurement_index
unassigned_measurements = list(range(len(measurements)))
if predicted_measurements:
# 贪心最近邻关联
while True:
# 找到最小距离
if distances.size == 0 or np.all(distances == np.inf):
break
min_idx = np.unravel_index(np.argmin(distances), distances.shape)
min_dist = distances[min_idx]
if min_dist > self.gate_threshold or min_dist == np.inf:
break
meas_idx, track_idx = min_idx
track_id = track_ids[track_idx]
# 关联
associations[track_id] = meas_idx
# 从考虑中移除
distances[meas_idx, :] = np.inf
distances[:, track_idx] = np.inf
if meas_idx in unassigned_measurements:
unassigned_measurements.remove(meas_idx)
# 4. 更新关联的航迹
for track_id, meas_idx in associations.items():
track = self.tracks[track_id]
z = measurements[meas_idx]
track.update(z, self.R)
# 5. 处理未关联的航迹(漏检)
for track_id, track in self.tracks.items():
if track.status != 'DELETED' and track_id not in associations:
track.miss()
# 检查是否应删除
if track.should_delete(self.deletion_threshold):
track.status = 'DELETED'
# 6. 从未关联观测中起始新航迹
for meas_idx in unassigned_measurements:
z = measurements[meas_idx]
self._initiate_new_track(z)
# 7. 清理已删除的航迹
self._cleanup_tracks()
# 保存历史
self.history['tracks'].append(self._get_track_states())
self.history['measurements'].append(measurements.copy())
self.history['associations'].append(associations.copy())
return self._get_active_tracks()
def _initiate_new_track(self, measurement):
"""初始化新航迹"""
# 初始状态:位置来自观测,速度设为0
initial_state = np.array([measurement[0], measurement[1], 0, 0])
initial_cov = np.diag([100, 100, 50, 50]) # 较大的初始不确定性
track_id = self.next_track_id
self.next_track_id += 1
track = Track(track_id, initial_state, initial_cov,
filter_class=CVFilter, filter_params={'dt': 1.0, 'q': 0.1},
creation_time=self.time)
self.tracks[track_id] = track
def _cleanup_tracks(self):
"""清理已删除的航迹"""
to_delete = []
for track_id, track in self.tracks.items():
if track.status == 'DELETED':
to_delete.append(track_id)
for track_id in to_delete:
del self.tracks[track_id]
def _get_active_tracks(self):
"""获取活跃航迹"""
active_tracks = []
for track in self.tracks.values():
if track.status != 'DELETED':
active_tracks.append({
'id': track.track_id,
'state': track.get_state(),
'covariance': track.get_covariance(),
'status': track.status,
'age': track.age
})
return active_tracks
def _get_track_states(self):
"""获取所有航迹状态"""
states = {}
for track_id, track in self.tracks.items():
if track.status != 'DELETED':
states[track_id] = {
'state': track.get_state(),
'status': track.status
}
return states
def generate_multitarget_scenario(num_targets=3, num_steps=100,
detection_prob=0.9, false_alarm_rate=0.1,
measurement_noise_std=5.0):
"""
生成多目标场景
参数:
num_targets: 目标数量
num_steps: 时间步数
detection_prob: 检测概率
false_alarm_rate: 虚警率(每帧平均虚警数)
measurement_noise_std: 观测噪声标准差
返回:
true_trajectories: 真实轨迹
measurements_all: 各帧观测
"""
np.random.seed(42)
# 生成目标初始状态
true_trajectories = []
for i in range(num_targets):
# 随机初始位置和速度
x0 = np.random.uniform(-100, 100)
y0 = np.random.uniform(-100, 100)
vx0 = np.random.uniform(-5, 5)
vy0 = np.random.uniform(-5, 5)
trajectory = np.zeros((num_steps, 4))
trajectory[0] = [x0, y0, vx0, vy0]
# 生成轨迹(匀速运动)
for t in range(1, num_steps):
# 添加轻微机动
if t % 20 == 0:
vx0 += np.random.randn() * 0.5
vy0 += np.random.randn() * 0.5
trajectory[t, 0] = trajectory[t-1, 0] + vx0
trajectory[t, 1] = trajectory[t-1, 1] + vy0
trajectory[t, 2] = vx0
trajectory[t, 3] = vy0
true_trajectories.append(trajectory)
# 生成观测
measurements_all = []
for t in range(num_steps):
frame_measurements = []
# 真实目标观测
for i in range(num_targets):
if np.random.rand() < detection_prob: # 检测
true_pos = true_trajectories[i][t, :2]
noisy_pos = true_pos + np.random.randn(2) * measurement_noise_std
frame_measurements.append(noisy_pos)
# 虚警
num_false_alarms = np.random.poisson(false_alarm_rate)
for _ in range(num_false_alarms):
false_alarm = np.random.uniform(-150, 150, 2)
frame_measurements.append(false_alarm)
measurements_all.append(np.array(frame_measurements))
return true_trajectories, measurements_all
def evaluate_tracking_performance(true_trajectories, tracker_history,
association_threshold=20.0):
"""
评估跟踪性能
参数:
true_trajectories: 真实轨迹列表
tracker_history: 跟踪器历史记录
association_threshold: 关联阈值(位置误差)
返回:
metrics: 性能指标字典
"""
num_steps = len(tracker_history['tracks'])
num_targets = len(true_trajectories)
# 初始化结果矩阵
association_matrix = np.zeros((num_steps, num_targets), dtype=int) - 1
position_errors = []
for t in range(num_steps):
# 获取该帧的航迹
tracks = tracker_history['tracks'][t]
measurements = tracker_history['measurements'][t]
if not tracks:
continue
# 构建航迹位置列表
track_positions = []
track_ids = []
for track_id, track_info in tracks.items():
state = track_info['state']
track_positions.append(state[:2])
track_ids.append(track_id)
if not track_positions:
continue
track_positions = np.array(track_positions)
# 关联真实目标与航迹
for target_idx in range(num_targets):
true_pos = true_trajectories[target_idx][t, :2]
if len(track_positions) > 0:
# 计算到所有航迹的距离
distances = np.linalg.norm(track_positions - true_pos, axis=1)
min_idx = np.argmin(distances)
min_dist = distances[min_idx]
if min_dist < association_threshold:
association_matrix[t, target_idx] = track_ids[min_idx]
position_errors.append(min_dist)
# 计算性能指标
metrics = {}
# 1. 位置误差统计
if position_errors:
metrics['position_rmse'] = np.sqrt(np.mean(np.array(position_errors)**2))
metrics['position_mae'] = np.mean(np.abs(position_errors))
metrics['position_max_error'] = np.max(np.abs(position_errors))
else:
metrics['position_rmse'] = 0
metrics['position_mae'] = 0
metrics['position_max_error'] = 0
# 2. 航迹连续性统计
track_lifetimes = []
for t in range(num_steps):
tracks = tracker_history['tracks'][t]
track_lifetimes.append(len(tracks))
metrics['avg_tracks_per_frame'] = np.mean(track_lifetimes)
metrics['max_tracks_per_frame'] = np.max(track_lifetimes)
# 3. 关联精度
total_associations = np.sum(association_matrix != -1)
total_possible = num_steps * num_targets
metrics['association_rate'] = total_associations / total_possible if total_possible > 0 else 0
return metrics
def run_nn_tracking_demo():
"""运行最近邻跟踪演示"""
print("="*60)
print("最近邻数据关联演示")
print("="*60)
np.random.seed(42)
# 生成场景
print("生成多目标场景...")
num_targets = 3
num_steps = 100
true_trajectories, measurements_all = generate_multitarget_scenario(
num_targets=num_targets,
num_steps=num_steps,
detection_prob=0.9,
false_alarm_rate=0.2,
measurement_noise_std=5.0
)
# 初始化跟踪器
print("初始化最近邻跟踪器...")
tracker = NearestNeighborTracker(
gate_threshold=9.21, # 99%置信度
detection_prob=0.9,
false_alarm_density=1e-4,
measurement_noise_std=5.0,
new_track_threshold=2,
deletion_threshold=5
)
# 运行跟踪
print("运行多目标跟踪...")
for t in range(num_steps):
measurements = measurements_all[t]
active_tracks = tracker.process_scan(measurements)
if t % 20 == 0:
print(f" 时间步 {t}: {len(active_tracks)} 个活跃航迹")
# 评估性能
print("评估跟踪性能...")
metrics = evaluate_tracking_performance(true_trajectories, tracker.history)
# 可视化结果
print("生成可视化结果...")
_visualize_tracking_results(true_trajectories, measurements_all, tracker)
# 打印性能指标
print("\n" + "="*60)
print("跟踪性能指标")
print("="*60)
print(f"位置RMSE: {metrics['position_rmse']:.2f} m")
print(f"位置MAE: {metrics['position_mae']:.2f} m")
print(f"最大位置误差: {metrics['position_max_error']:.2f} m")
print(f"平均每帧航迹数: {metrics['avg_tracks_per_frame']:.2f}")
print(f"最大同时航迹数: {metrics['max_tracks_per_frame']}")
print(f"关联成功率: {metrics['association_rate']*100:.1f}%")
print("="*60)
return {
'true_trajectories': true_trajectories,
'measurements_all': measurements_all,
'tracker': tracker,
'metrics': metrics
}
def _visualize_tracking_results(true_trajectories, measurements_all, tracker):
"""可视化跟踪结果"""
num_steps = len(measurements_all)
# 创建图形
fig, axes = plt.subplots(2, 3, figsize=(18, 12))
# 1. 整体轨迹
ax = axes[0, 0]
# 绘制真实轨迹
colors = ['r', 'g', 'b', 'c', 'm', 'y']
for i, trajectory in enumerate(true_trajectories):
color = colors[i % len(colors)]
ax.plot(trajectory[:, 0], trajectory[:, 1], color=color,
linewidth=2, alpha=0.7, label=f'目标{i+1}')
# 绘制观测
all_measurements = np.vstack(measurements_all)
ax.scatter(all_measurements[:, 0], all_measurements[:, 1],
c='gray', s=10, alpha=0.3, label='观测')
# 绘制估计轨迹
track_history = tracker.history['tracks']
track_colors = {}
color_idx = 0
for t in range(num_steps):
tracks = track_history[t]
for track_id, track_info in tracks.items():
if track_id not in track_colors:
track_colors[track_id] = colors[color_idx % len(colors)]
color_idx += 1
state = track_info['state']
ax.plot(state[0], state[1], 'o',
color=track_colors[track_id], markersize=4, alpha=0.5)
ax.set_xlabel('X位置')
ax.set_ylabel('Y位置')
ax.set_title('多目标跟踪轨迹')
ax.legend(loc='upper right')
ax.grid(True, alpha=0.3)
ax.axis('equal')
# 2. 单帧关联详情(选择中间帧)
ax = axes[0, 1]
frame_idx = num_steps // 2
# 获取该帧数据
measurements = measurements_all[frame_idx]
tracks = tracker.history['tracks'][frame_idx]
associations = tracker.history['associations'][frame_idx]
# 绘制真实目标位置
for i, trajectory in enumerate(true_trajectories):
true_pos = trajectory[frame_idx, :2]
ax.plot(true_pos[0], true_pos[1], 'ko', markersize=10,
label=f'真实目标{i+1}' if i == 0 else "")
# 绘制观测
ax.scatter(measurements[:, 0], measurements[:, 1], c='blue',
s=50, marker='x', label='观测')
# 绘制航迹估计位置
for track_id, track_info in tracks.items():
state = track_info['state']
ax.plot(state[0], state[1], 'ro', markersize=8,
label='航迹估计' if track_id == 0 else "")
# 绘制关联线
for track_id, meas_idx in associations.items():
if track_id in tracks:
track_state = tracks[track_id]['state']
meas = measurements[meas_idx]
ax.plot([track_state[0], meas[0]], [track_state[1], meas[1]],
'g-', linewidth=1, alpha=0.5)
ax.set_xlabel('X位置')
ax.set_ylabel('Y位置')
ax.set_title(f'第{frame_idx}帧关联详情')
ax.legend(loc='upper right')
ax.grid(True, alpha=0.3)
ax.axis('equal')
# 3. 航迹数量随时间变化
ax = axes[0, 2]
time_steps = np.arange(num_steps)
track_counts = [len(tracker.history['tracks'][t]) for t in time_steps]
meas_counts = [len(tracker.history['measurements'][t]) for t in time_steps]
ax.plot(time_steps, track_counts, 'b-', linewidth=2, label='航迹数量')
ax.plot(time_steps, meas_counts, 'r-', linewidth=1, alpha=0.7, label='观测数量')
ax.set_xlabel('时间步')
ax.set_ylabel('数量')
ax.set_title('航迹与观测数量变化')
ax.legend()
ax.grid(True, alpha=0.3)
# 4. 位置误差分布
ax = axes[1, 0]
# 计算所有帧的位置误差
all_errors = []
for t in range(num_steps):
tracks = tracker.history['tracks'][t]
for track_id, track_info in tracks.items():
state = track_info['state']
# 找到最近的真实目标
min_error = np.inf
for trajectory in true_trajectories:
true_pos = trajectory[t, :2]
error = np.linalg.norm(state[:2] - true_pos)
if error < min_error:
min_error = error
if min_error < 50: # 忽略太大的误差(可能是虚警航迹)
all_errors.append(min_error)
if all_errors:
ax.hist(all_errors, bins=30, alpha=0.7, color='blue', edgecolor='black')
ax.set_xlabel('位置误差 (m)')
ax.set_ylabel('频数')
ax.set_title(f'位置误差分布 (均值={np.mean(all_errors):.2f}m)')
ax.grid(True, alpha=0.3)
else:
ax.text(0.5, 0.5, '无误差数据', ha='center', va='center',
transform=ax.transAxes, fontsize=12)
ax.set_title('位置误差分布')
# 5. 航迹生命周期
ax = axes[1, 1]
# 统计航迹生命周期
track_lifetimes = {}
for track_id in range(tracker.next_track_id):
lifetime = 0
for t in range(num_steps):
tracks = tracker.history['tracks'][t]
if track_id in tracks:
lifetime += 1
if lifetime > 0:
track_lifetimes[track_id] = lifetime
if track_lifetimes:
lifetimes = list(track_lifetimes.values())
ax.hist(lifetimes, bins=range(1, max(lifetimes)+2),
alpha=0.7, color='green', edgecolor='black', align='left')
ax.set_xlabel('航迹生命周期 (帧)')
ax.set_ylabel('频数')
ax.set_title(f'航迹生命周期分布 (平均={np.mean(lifetimes):.1f}帧)')
ax.grid(True, alpha=0.3)
else:
ax.text(0.5, 0.5, '无航迹数据', ha='center', va='center',
transform=ax.transAxes, fontsize=12)
ax.set_title('航迹生命周期分布')
# 6. 关联门与距离统计
ax = axes[1, 2]
# 计算关联距离统计
association_distances = []
gate_sizes = []
for t in range(num_steps):
tracks = tracker.history['tracks'][t]
measurements = tracker.history['measurements'][t]
associations = tracker.history['associations'][t]
for track_id, meas_idx in associations.items():
if track_id in tracks:
track_state = tracks[track_id]['state']
meas = measurements[meas_idx]
dist = np.linalg.norm(track_state[:2] - meas)
association_distances.append(dist)
# 计算理论门大小(3σ)
# 假设观测噪声为5m
gate_size = 3 * 5.0
gate_sizes.append(gate_size)
if association_distances:
# 绘制关联距离与门限
bins = np.linspace(0, max(max(association_distances), 20), 30)
ax.hist(association_distances, bins=bins, alpha=0.7,
color='purple', edgecolor='black', density=True)
# 添加门限线
avg_gate = np.mean(gate_sizes) if gate_sizes else 15.0
ax.axvline(x=avg_gate, color='r', linestyle='--',
label=f'平均门限={avg_gate:.1f}m')
ax.set_xlabel('关联距离 (m)')
ax.set_ylabel('概率密度')
ax.set_title('关联距离分布')
ax.legend()
ax.grid(True, alpha=0.3)
else:
ax.text(0.5, 0.5, '无关联数据', ha='center', va='center',
transform=ax.transAxes, fontsize=12)
ax.set_title('关联距离分布')
plt.suptitle('最近邻数据关联多目标跟踪结果', fontsize=16, y=1.02)
plt.tight_layout()
plt.savefig('nearest_neighbor_tracking_results.png', dpi=300, bbox_inches='tight')
plt.show()
if __name__ == "__main__":
results = run_nn_tracking_demo()
print("\n演示完成!")8. Demo 4-2:概率数据关联实现
概率数据关联(PDA)是最近邻算法的改进,它为每个有效观测分配一个关联概率,然后进行加权更新。下面我们实现一个完整的PDA跟踪器。
python
"""
demo_4_2_probabilistic_data_association.py
概率数据关联实现
"""
import numpy as np
import matplotlib.pyplot as plt
from scipy import stats
import sys
import os
sys.path.append(os.path.dirname(os.path.dirname(os.path.abspath(__file__))))
from demo_4_1_nearest_neighbor_association import Track, generate_multitarget_scenario, evaluate_tracking_performance
class PDATrack(Track):
"""概率数据关联航迹类"""
def __init__(self, track_id, initial_state, initial_cov, filter_class=CVFilter,
filter_params=None, creation_time=0, detection_prob=0.9,
gate_threshold=9.21, false_alarm_density=1e-4):
"""
初始化PDA航迹
参数:
detection_prob: 检测概率
gate_threshold: 关联门限
false_alarm_density: 虚警空间密度
"""
super().__init__(track_id, initial_state, initial_cov, filter_class,
filter_params, creation_time)
self.P_D = detection_prob
self.gate_threshold = gate_threshold
self.lambda_fa = false_alarm_density
# PDA特定历史
self.history['association_probabilities'] = []
self.history['valid_measurements_count'] = []
def compute_association_probabilities(self, measurements, R):
"""
计算关联概率
参数:
measurements: 所有观测
R: 观测噪声协方差
返回:
beta: 关联概率向量,beta[0]为漏检概率
valid_measurements: 有效观测索引
"""
if len(measurements) == 0:
return np.array([1.0]), []
# 获取预测观测和新息协方差
H = np.array([[1, 0, 0, 0], [0, 1, 0, 0]])
z_pred, S = self.get_predicted_measurement(H)
z_pred = z_pred.flatten()
# 计算每个观测的马氏距离
distances = []
likelihoods = []
valid_indices = []
for j, z in enumerate(measurements):
innov = z - z_pred
try:
dist = innov @ np.linalg.inv(S) @ innov
if dist <= self.gate_threshold:
# 计算似然
likelihood = stats.multivariate_normal(z_pred, S).pdf(z)
distances.append(dist)
likelihoods.append(likelihood)
valid_indices.append(j)
except np.linalg.LinAlgError:
continue
if not valid_indices:
return np.array([1.0]), []
# 计算关联概率
m_k = len(valid_indices) # 有效观测数
# 计算关联门体积
n_z = 2 # 观测维度
V_k = np.pi * self.gate_threshold * np.sqrt(np.linalg.det(S)) # 近似
# 计算b
b = (1 - self.P_D) * self.lambda_fa * V_k / self.P_D
# 计算似然值
L = np.array(likelihoods) * self.P_D / self.lambda_fa
# 计算概率
sum_L = np.sum(L)
beta_0 = b / (b + sum_L) # 漏检概率
beta_j = L / (b + sum_L) # 各观测关联概率
# 组合概率向量
beta = np.zeros(m_k + 1)
beta[0] = beta_0
beta[1:] = beta_j
return beta, valid_indices
def pda_update(self, measurements, R):
"""
PDA更新步骤
参数:
measurements: 所有观测
R: 观测噪声协方差
"""
H = np.array([[1, 0, 0, 0], [0, 1, 0, 0]])
# 计算关联概率
beta, valid_indices = self.compute_association_probabilities(measurements, R)
# 保存历史
self.history['association_probabilities'].append(beta.copy())
self.history['valid_measurements_count'].append(len(valid_indices))
if len(valid_indices) == 0:
# 漏检
self.miss()
return self.filter.x, self.filter.P
# 获取预测状态
x_pred = self.filter.x.copy()
P_pred = self.filter.P.copy()
# 计算组合新息
z_pred = H @ x_pred
combined_innovation = np.zeros((2, 1))
for j, idx in enumerate(valid_indices):
z = measurements[idx].reshape(-1, 1)
innovation = z - z_pred
combined_innovation += beta[j+1] * innovation
# 计算卡尔曼增益
S = H @ P_pred @ H.T + R
K = P_pred @ H.T @ np.linalg.inv(S)
# 状态更新
x_updated = x_pred + K @ combined_innovation
# 协方差更新
# 计算P_c
I = np.eye(self.filter.state_dim)
P_c = (I - K @ H) @ P_pred @ (I - K @ H).T + K @ R @ K.T
# 计算P_tilde
P_tilde = np.zeros((self.filter.state_dim, self.filter.state_dim))
for j, idx in enumerate(valid_indices):
z = measurements[idx].reshape(-1, 1)
innovation = z - z_pred
P_tilde += beta[j+1] * (innovation @ innovation.T)
P_tilde -= combined_innovation @ combined_innovation.T
P_tilde = K @ P_tilde @ K.T
# 最终协方差
P_updated = beta[0] * P_pred + (1 - beta[0]) * P_c + P_tilde
# 更新滤波器状态
self.filter.x = x_updated
self.filter.P = P_updated
# 更新航迹状态
self.last_update_time += 1
self.update_count += 1
self.miss_count = 0
# 保存历史
self.history['states'].append(x_updated.flatten().copy())
self.history['covariances'].append(P_updated.copy())
self.history['measurements'].append(None) # PDA不关联特定观测
# 检查航迹确认
if self.status == 'TENTATIVE' and self.update_count >= 3:
self.status = 'CONFIRMED'
return x_updated, P_updated
class PDATracker:
"""概率数据关联多目标跟踪器"""
def __init__(self, gate_threshold=9.21, detection_prob=0.9,
false_alarm_density=1e-4, measurement_noise_std=5.0,
new_track_threshold=3, deletion_threshold=5):
"""
初始化PDA跟踪器
参数与NN跟踪器类似
"""
self.gate_threshold = gate_threshold
self.P_D = detection_prob
self.lambda_fa = false_alarm_density
self.R = np.eye(2) * measurement_noise_std**2
self.new_track_threshold = new_track_threshold
self.deletion_threshold = deletion_threshold
# 跟踪器状态
self.tracks = {} # track_id -> PDATrack对象
self.next_track_id = 0
self.time = 0
# 历史记录
self.history = {
'tracks': [],
'measurements': [],
'associations': []
}
def process_scan(self, measurements):
"""
处理一帧观测
参数:
measurements: 观测列表
返回:
current_tracks: 当前活跃航迹
"""
self.time += 1
measurements = np.array(measurements)
if len(measurements) == 0:
# 没有观测,所有航迹漏检
for track in self.tracks.values():
track.miss()
return self._get_active_tracks()
# 1. 预测所有航迹
for track in self.tracks.values():
if track.status != 'DELETED':
track.predict()
# 2. 对每个航迹执行PDA更新
for track_id, track in list(self.tracks.items()):
if track.status != 'DELETED':
track.pda_update(measurements, self.R)
# 3. 从未关联观测中起始新航迹
# 注意:PDA不进行显式关联,我们需要另一种方法检测新目标
# 这里使用简单的方法:如果一个观测不在任何航迹的关联门内,则可能来自新目标
new_measurements = self._find_potential_new_targets(measurements)
for z in new_measurements:
self._initiate_new_track(z)
# 4. 处理航迹删除
self._update_track_status()
# 5. 清理已删除的航迹
self._cleanup_tracks()
# 保存历史
self.history['tracks'].append(self._get_track_states())
self.history['measurements'].append(measurements.copy())
self.history['associations'].append({}) # PDA不保存关联
return self._get_active_tracks()
def _find_potential_new_targets(self, measurements):
"""查找可能的新目标观测"""
new_measurements = []
for z in measurements:
is_new = True
for track in self.tracks.values():
if track.status != 'DELETED':
# 计算马氏距离
H = np.array([[1, 0, 0, 0], [0, 1, 0, 0]])
z_pred, S = track.get_predicted_measurement(H)
z_pred = z_pred.flatten()
innov = z - z_pred
try:
dist = innov @ np.linalg.inv(S) @ innov
if dist <= self.gate_threshold:
is_new = False
break
except np.linalg.LinAlgError:
continue
if is_new:
new_measurements.append(z)
return new_measurements
def _initiate_new_track(self, measurement):
"""初始化新航迹"""
initial_state = np.array([measurement[0], measurement[1], 0, 0])
initial_cov = np.diag([100, 100, 50, 50])
track_id = self.next_track_id
self.next_track_id += 1
track = PDATrack(track_id, initial_state, initial_cov,
filter_class=CVFilter, filter_params={'dt': 1.0, 'q': 0.1},
creation_time=self.time, detection_prob=self.P_D,
gate_threshold=self.gate_threshold,
false_alarm_density=self.lambda_fa)
self.tracks[track_id] = track
def _update_track_status(self):
"""更新航迹状态"""
for track in self.tracks.values():
if track.status != 'DELETED':
if track.miss_count >= self.deletion_threshold:
track.status = 'DELETED'
elif track.status == 'TENTATIVE' and track.update_count >= self.new_track_threshold:
track.status = 'CONFIRMED'
def _cleanup_tracks(self):
"""清理已删除的航迹"""
to_delete = []
for track_id, track in self.tracks.items():
if track.status == 'DELETED':
to_delete.append(track_id)
for track_id in to_delete:
del self.tracks[track_id]
def _get_active_tracks(self):
"""获取活跃航迹"""
active_tracks = []
for track in self.tracks.values():
if track.status != 'DELETED':
active_tracks.append({
'id': track.track_id,
'state': track.get_state(),
'covariance': track.get_covariance(),
'status': track.status,
'age': track.age
})
return active_tracks
def _get_track_states(self):
"""获取所有航迹状态"""
states = {}
for track_id, track in self.tracks.items():
if track.status != 'DELETED':
states[track_id] = {
'state': track.get_state(),
'status': track.status
}
return states
def run_pda_tracking_demo():
"""运行PDA跟踪演示"""
print("="*60)
print("概率数据关联演示")
print("="*60)
np.random.seed(42)
# 生成场景
print("生成多目标场景...")
num_targets = 3
num_steps = 100
true_trajectories, measurements_all = generate_multitarget_scenario(
num_targets=num_targets,
num_steps=num_steps,
detection_prob=0.9,
false_alarm_rate=0.2,
measurement_noise_std=5.0
)
# 初始化跟踪器
print("初始化PDA跟踪器...")
tracker = PDATracker(
gate_threshold=9.21,
detection_prob=0.9,
false_alarm_density=1e-4,
measurement_noise_std=5.0,
new_track_threshold=2,
deletion_threshold=5
)
# 运行跟踪
print("运行多目标跟踪...")
for t in range(num_steps):
measurements = measurements_all[t]
active_tracks = tracker.process_scan(measurements)
if t % 20 == 0:
print(f" 时间步 {t}: {len(active_tracks)} 个活跃航迹")
# 评估性能
print("评估跟踪性能...")
metrics = evaluate_tracking_performance(true_trajectories, tracker.history)
# 可视化结果
print("生成可视化结果...")
_visualize_pda_results(true_trajectories, measurements_all, tracker)
# 打印性能指标
print("\n" + "="*60)
print("PDA跟踪性能指标")
print("="*60)
print(f"位置RMSE: {metrics['position_rmse']:.2f} m")
print(f"位置MAE: {metrics['position_mae']:.2f} m")
print(f"最大位置误差: {metrics['position_max_error']:.2f} m")
print(f"平均每帧航迹数: {metrics['avg_tracks_per_frame']:.2f}")
print(f"最大同时航迹数: {metrics['max_tracks_per_frame']}")
print(f"关联成功率: {metrics['association_rate']*100:.1f}%")
print("="*60)
return {
'true_trajectories': true_trajectories,
'measurements_all': measurements_all,
'tracker': tracker,
'metrics': metrics
}
def _visualize_pda_results(true_trajectories, measurements_all, tracker):
"""可视化PDA跟踪结果"""
num_steps = len(measurements_all)
# 创建图形
fig, axes = plt.subplots(2, 3, figsize=(18, 12))
# 1. 整体轨迹
ax = axes[0, 0]
colors = ['r', 'g', 'b', 'c', 'm', 'y']
for i, trajectory in enumerate(true_trajectories):
color = colors[i % len(colors)]
ax.plot(trajectory[:, 0], trajectory[:, 1], color=color,
linewidth=2, alpha=0.7, label=f'目标{i+1}')
all_measurements = np.vstack(measurements_all)
ax.scatter(all_measurements[:, 0], all_measurements[:, 1],
c='gray', s=10, alpha=0.3, label='观测')
track_history = tracker.history['tracks']
track_colors = {}
color_idx = 0
for t in range(num_steps):
tracks = track_history[t]
for track_id, track_info in tracks.items():
if track_id not in track_colors:
track_colors[track_id] = colors[color_idx % len(colors)]
color_idx += 1
state = track_info['state']
ax.plot(state[0], state[1], 'o',
color=track_colors[track_id], markersize=4, alpha=0.5)
ax.set_xlabel('X位置')
ax.set_ylabel('Y位置')
ax.set_title('PDA多目标跟踪轨迹')
ax.legend(loc='upper right')
ax.grid(True, alpha=0.3)
ax.axis('equal')
# 2. 单帧关联详情
ax = axes[0, 1]
frame_idx = num_steps // 2
measurements = measurements_all[frame_idx]
tracks = tracker.history['tracks'][frame_idx]
for i, trajectory in enumerate(true_trajectories):
true_pos = trajectory[frame_idx, :2]
ax.plot(true_pos[0], true_pos[1], 'ko', markersize=10,
label=f'真实目标{i+1}' if i == 0 else "")
ax.scatter(measurements[:, 0], measurements[:, 1], c='blue',
s=50, marker='x', label='观测')
for track_id, track_info in tracks.items():
state = track_info['state']
ax.plot(state[0], state[1], 'ro', markersize=8,
label='航迹估计' if track_id == 0 else "")
# 绘制关联门
from matplotlib.patches import Ellipse
# 简化:假设关联门为圆形
gate_radius = np.sqrt(tracker.gate_threshold) * 5.0 # 近似
circle = plt.Circle((state[0], state[1]), gate_radius,
color='g', fill=False, alpha=0.3)
ax.add_patch(circle)
ax.set_xlabel('X位置')
ax.set_ylabel('Y位置')
ax.set_title(f'第{frame_idx}帧PDA关联详情')
ax.legend(loc='upper right')
ax.grid(True, alpha=0.3)
ax.axis('equal')
# 3. 航迹数量随时间变化
ax = axes[0, 2]
time_steps = np.arange(num_steps)
track_counts = [len(tracker.history['tracks'][t]) for t in time_steps]
meas_counts = [len(tracker.history['measurements'][t]) for t in time_steps]
ax.plot(time_steps, track_counts, 'b-', linewidth=2, label='航迹数量')
ax.plot(time_steps, meas_counts, 'r-', linewidth=1, alpha=0.7, label='观测数量')
ax.set_xlabel('时间步')
ax.set_ylabel('数量')
ax.set_title('航迹与观测数量变化')
ax.legend()
ax.grid(True, alpha=0.3)
# 4. 关联概率分布
ax = axes[1, 0]
all_betas = []
for track in tracker.tracks.values():
if hasattr(track, 'history') and 'association_probabilities' in track.history:
for beta in track.history['association_probabilities']:
all_betas.extend(beta)
if all_betas:
ax.hist(all_betas, bins=30, alpha=0.7, color='purple', edgecolor='black')
ax.set_xlabel('关联概率')
ax.set_ylabel('频数')
ax.set_title('关联概率分布')
ax.grid(True, alpha=0.3)
else:
ax.text(0.5, 0.5, '无关联概率数据', ha='center', va='center',
transform=ax.transAxes, fontsize=12)
ax.set_title('关联概率分布')
# 5. 有效观测数量统计
ax = axes[1, 1]
valid_counts = []
for track in tracker.tracks.values():
if hasattr(track, 'history') and 'valid_measurements_count' in track.history:
valid_counts.extend(track.history['valid_measurements_count'])
if valid_counts:
unique, counts = np.unique(valid_counts, return_counts=True)
ax.bar(unique, counts, alpha=0.7, color='orange', edgecolor='black')
ax.set_xlabel('有效观测数量')
ax.set_ylabel('频数')
ax.set_title('有效观测数量分布')
ax.grid(True, alpha=0.3, axis='y')
else:
ax.text(0.5, 0.5, '无有效观测数据', ha='center', va='center',
transform=ax.transAxes, fontsize=12)
ax.set_title('有效观测数量分布')
# 6. 位置误差随时间变化
ax = axes[1, 2]
time_errors = np.zeros(num_steps)
error_counts = np.zeros(num_steps)
for t in range(num_steps):
tracks = tracker.history['tracks'][t]
for track_id, track_info in tracks.items():
state = track_info['state']
min_error = np.inf
for trajectory in true_trajectories:
true_pos = trajectory[t, :2]
error = np.linalg.norm(state[:2] - true_pos)
if error < min_error:
min_error = error
if min_error < 50:
time_errors[t] += min_error
error_counts[t] += 1
# 计算平均误差
avg_errors = np.zeros(num_steps)
for t in range(num_steps):
if error_counts[t] > 0:
avg_errors[t] = time_errors[t] / error_counts[t]
ax.plot(time_steps, avg_errors, 'b-', linewidth=2)
ax.set_xlabel('时间步')
ax.set_ylabel('平均位置误差 (m)')
ax.set_title('位置误差随时间变化')
ax.grid(True, alpha=0.3)
plt.suptitle('概率数据关联多目标跟踪结果', fontsize=16, y=1.02)
plt.tight_layout()
plt.savefig('pda_tracking_results.png', dpi=300, bbox_inches='tight')
plt.show()
if __name__ == "__main__":
results = run_pda_tracking_demo()
print("\n演示完成!")9. Demo 4-3:联合概率数据关联实现
联合概率数据关联(JPDA)是PDA的多目标扩展,它显式考虑多个目标之间的关联相互依赖性。由于JPDA的计算复杂度较高,我们实现一个简化的版本,使用Murty算法来生成最优的K个关联假设。
python
"""
demo_4_3_joint_probabilistic_data_association.py
联合概率数据关联实现
"""
import numpy as np
import matplotlib.pyplot as plt
from scipy import stats
import itertools
import sys
import os
sys.path.append(os.path.dirname(os.path.dirname(os.path.abspath(__file__))))
from demo_4_1_nearest_neighbor_association import Track, generate_multitarget_scenario, evaluate_tracking_performance
class JPDATracker:
"""联合概率数据关联多目标跟踪器"""
def __init__(self, gate_threshold=9.21, detection_prob=0.9,
false_alarm_density=1e-4, measurement_noise_std=5.0,
new_track_threshold=3, deletion_threshold=5,
max_hypotheses=100, use_murty=True):
"""
初始化JPDA跟踪器
参数:
max_hypotheses: 最大假设数
use_murty: 是否使用Murty算法生成最优假设
"""
self.gate_threshold = gate_threshold
self.P_D = detection_prob
self.lambda_fa = false_alarm_density
self.R = np.eye(2) * measurement_noise_std**2
self.new_track_threshold = new_track_threshold
self.deletion_threshold = deletion_threshold
self.max_hypotheses = max_hypotheses
self.use_murty = use_murty
# 跟踪器状态
self.tracks = {} # track_id -> Track对象
self.next_track_id = 0
self.time = 0
# 历史记录
self.history = {
'tracks': [],
'measurements': [],
'associations': [],
'joint_hypotheses': []
}
def process_scan(self, measurements):
"""
处理一帧观测
参数:
measurements: 观测列表
返回:
current_tracks: 当前活跃航迹
"""
self.time += 1
measurements = np.array(measurements)
if len(measurements) == 0:
for track in self.tracks.values():
track.miss()
return self._get_active_tracks()
# 1. 预测所有航迹
predicted_states = {}
predicted_covs = {}
predicted_measurements = {}
innovation_covariances = {}
for track_id, track in self.tracks.items():
if track.status != 'DELETED':
track.predict()
x_pred, P_pred = track.get_state(), track.get_covariance()
predicted_states[track_id] = x_pred
predicted_covs[track_id] = P_pred
H = np.array([[1, 0, 0, 0], [0, 1, 0, 0]])
z_pred = H @ x_pred.reshape(-1, 1)
S = H @ P_pred @ H.T + self.R
predicted_measurements[track_id] = z_pred.flatten()
innovation_covariances[track_id] = S
# 2. 构建确认矩阵
num_measurements = len(measurements)
num_tracks = len(self.tracks)
if num_tracks > 0:
validation_matrix = np.ones((num_measurements, num_tracks + 1), dtype=int)
track_ids = list(self.tracks.keys())
# 检查每个观测是否在航迹的关联门内
for j, z in enumerate(measurements):
for i, track_id in enumerate(track_ids):
track = self.tracks[track_id]
if track.status != 'DELETED':
z_pred = predicted_measurements[track_id]
S = innovation_covariances[track_id]
innov = z - z_pred
try:
dist = innov @ np.linalg.inv(S) @ innov
if dist > self.gate_threshold:
validation_matrix[j, i] = 0
except np.linalg.LinAlgError:
validation_matrix[j, i] = 0
# 3. 生成联合关联假设
joint_hypotheses = self._generate_joint_hypotheses(
validation_matrix, measurements, track_ids,
predicted_measurements, innovation_covariances
)
# 保存历史
self.history['joint_hypotheses'].append(len(joint_hypotheses))
if joint_hypotheses:
# 4. 计算边缘关联概率
marginal_probs = self._compute_marginal_probabilities(
joint_hypotheses, num_measurements, track_ids
)
# 5. 使用边缘概率更新航迹
self._update_tracks_with_marginal_probs(
measurements, track_ids, marginal_probs,
predicted_states, predicted_covs
)
# 6. 从未关联观测中起始新航迹
new_measurements = self._find_new_targets(measurements, predicted_measurements,
innovation_covariances)
for z in new_measurements:
self._initiate_new_track(z)
# 7. 处理航迹删除
self._update_track_status()
# 8. 清理已删除的航迹
self._cleanup_tracks()
# 保存历史
self.history['tracks'].append(self._get_track_states())
self.history['measurements'].append(measurements.copy())
# 保存关联(简化)
associations = {}
if num_tracks > 0 and 'marginal_probs' in locals():
for i, track_id in enumerate(track_ids):
max_prob_idx = np.argmax(marginal_probs[:, i])
if marginal_probs[max_prob_idx, i] > 0.5 and max_prob_idx < num_measurements:
associations[track_id] = max_prob_idx
self.history['associations'].append(associations)
return self._get_active_tracks()
def _generate_joint_hypotheses(self, validation_matrix, measurements, track_ids,
predicted_measurements, innovation_covariances):
"""
生成联合关联假设
简化实现:使用穷举法生成所有可行假设
在实际应用中,应使用Murty算法
"""
num_measurements, num_tracks_plus1 = validation_matrix.shape
num_tracks = num_tracks_plus1 - 1
# 生成所有可能的单目标关联
single_target_hypotheses = []
for j in range(num_measurements):
hypotheses_j = [0] # 虚警
for i in range(num_tracks):
if validation_matrix[j, i] == 1:
hypotheses_j.append(i+1) # +1因为0是虚警
single_target_hypotheses.append(hypotheses_j)
# 穷举所有组合(限制数量)
all_combinations = list(itertools.product(*single_target_hypotheses))
# 过滤不可行组合
feasible_hypotheses = []
for combo in all_combinations:
if len(combo) > len(set(combo)) - 1: # 检查是否有多个观测关联到同一目标
continue
feasible_hypotheses.append(combo)
# 限制假设数量
if len(feasible_hypotheses) > self.max_hypotheses:
# 计算假设概率并选择最可能的
hypothesis_probs = []
for combo in feasible_hypotheses:
prob = self._compute_hypothesis_probability(
combo, measurements, track_ids,
predicted_measurements, innovation_covariances
)
hypothesis_probs.append(prob)
# 选择概率最高的假设
sorted_indices = np.argsort(hypothesis_probs)[::-1]
feasible_hypotheses = [feasible_hypotheses[i] for i in
sorted_indices[:self.max_hypotheses]]
return feasible_hypotheses
def _compute_hypothesis_probability(self, combo, measurements, track_ids,
predicted_measurements, innovation_covariances):
"""
计算假设概率
"""
num_measurements = len(measurements)
num_tracks = len(track_ids)
# 计算虚警数
false_alarms = combo.count(0)
# 计算检测指示器
detections = np.zeros(num_tracks, dtype=int)
for j, target_idx in enumerate(combo):
if target_idx > 0: # 不是虚警
detections[target_idx-1] = 1
# 计算似然
likelihood = 1.0
for j, target_idx in enumerate(combo):
if target_idx > 0: # 关联到目标
track_id = track_ids[target_idx-1]
z = measurements[j]
z_pred = predicted_measurements[track_id]
S = innovation_covariances[track_id]
# 计算高斯似然
try:
pdf = stats.multivariate_normal(z_pred, S).pdf(z)
likelihood *= pdf
except:
likelihood *= 1e-10
# 计算先验概率
V = 1.0 # 关联门体积(简化)
prior = (self.lambda_fa * V)**false_alarms
for t in range(num_tracks):
if detections[t] == 1:
prior *= self.P_D
else:
prior *= (1 - self.P_D)
return likelihood * prior
def _compute_marginal_probabilities(self, joint_hypotheses, num_measurements, track_ids):
"""
计算边缘关联概率
"""
num_tracks = len(track_ids)
marginal_probs = np.zeros((num_measurements + 1, num_tracks))
# 计算假设概率
hypothesis_probs = []
for combo in joint_hypotheses:
prob = 1.0 # 简化
hypothesis_probs.append(prob)
# 归一化
total_prob = sum(hypothesis_probs)
if total_prob > 0:
hypothesis_probs = [p/total_prob for p in hypothesis_probs]
# 计算边缘概率
for idx, combo in enumerate(joint_hypotheses):
prob = hypothesis_probs[idx]
for j, target_idx in enumerate(combo):
if target_idx > 0: # 关联到目标
marginal_probs[j, target_idx-1] += prob
else: # 虚警
marginal_probs[j, :] += prob / num_tracks # 均匀分布
return marginal_probs
def _update_tracks_with_marginal_probs(self, measurements, track_ids, marginal_probs,
predicted_states, predicted_covs):
"""
使用边缘概率更新航迹
"""
H = np.array([[1, 0, 0, 0], [0, 1, 0, 0]])
num_measurements = len(measurements)
for i, track_id in enumerate(track_ids):
track = self.tracks[track_id]
if track.status == 'DELETED':
continue
# 获取预测状态
x_pred = predicted_states[track_id].reshape(-1, 1)
P_pred = predicted_covs[track_id]
# 计算组合新息
combined_innovation = np.zeros((2, 1))
for j in range(num_measurements):
if marginal_probs[j, i] > 0:
z = measurements[j].reshape(-1, 1)
z_pred = H @ x_pred
innovation = z - z_pred
combined_innovation += marginal_probs[j, i] * innovation
# 计算漏检概率
beta_0 = marginal_probs[num_measurements, i] if num_measurements < marginal_probs.shape[0] else 0
# 计算卡尔曼增益
S = H @ P_pred @ H.T + self.R
K = P_pred @ H.T @ np.linalg.inv(S)
# 状态更新
x_updated = x_pred + K @ combined_innovation
# 协方差更新(简化)
I = np.eye(4)
P_c = (I - K @ H) @ P_pred @ (I - K @ H).T + K @ self.R @ K.T
# 计算P_tilde
P_tilde = np.zeros((4, 4))
for j in range(num_measurements):
if marginal_probs[j, i] > 0:
z = measurements[j].reshape(-1, 1)
z_pred = H @ x_pred
innovation = z - z_pred
P_tilde += marginal_probs[j, i] * (innovation @ innovation.T)
P_tilde -= combined_innovation @ combined_innovation.T
P_tilde = K @ P_tilde @ K.T
# 最终协方差
P_updated = beta_0 * P_pred + (1 - beta_0) * P_c + P_tilde
# 更新滤波器状态
track.filter.x = x_updated
track.filter.P = P_updated
# 更新航迹状态
track.last_update_time += 1
track.update_count += 1
track.miss_count = 0
# 保存历史
track.history['states'].append(x_updated.flatten().copy())
track.history['covariances'].append(P_updated.copy())
track.history['measurements'].append(None)
if track.status == 'TENTATIVE' and track.update_count >= self.new_track_threshold:
track.status = 'CONFIRMED'
def _find_new_targets(self, measurements, predicted_measurements, innovation_covariances):
"""查找新目标"""
new_measurements = []
for z in measurements:
is_new = True
for track_id, track in self.tracks.items():
if track.status != 'DELETED' and track_id in predicted_measurements:
z_pred = predicted_measurements[track_id]
S = innovation_covariances[track_id]
innov = z - z_pred
try:
dist = innov @ np.linalg.inv(S) @ innov
if dist <= self.gate_threshold:
is_new = False
break
except np.linalg.LinAlgError:
continue
if is_new:
new_measurements.append(z)
return new_measurements
def _initiate_new_track(self, measurement):
"""初始化新航迹"""
initial_state = np.array([measurement[0], measurement[1], 0, 0])
initial_cov = np.diag([100, 100, 50, 50])
track_id = self.next_track_id
self.next_track_id += 1
from demo_4_1_nearest_neighbor_association import Track
track = Track(track_id, initial_state, initial_cov,
filter_class=CVFilter, filter_params={'dt': 1.0, 'q': 0.1},
creation_time=self.time)
self.tracks[track_id] = track
def _update_track_status(self):
"""更新航迹状态"""
for track in self.tracks.values():
if track.status != 'DELETED':
if track.miss_count >= self.deletion_threshold:
track.status = 'DELETED'
elif track.status == 'TENTATIVE' and track.update_count >= self.new_track_threshold:
track.status = 'CONFIRMED'
def _cleanup_tracks(self):
"""清理已删除的航迹"""
to_delete = []
for track_id, track in self.tracks.items():
if track.status == 'DELETED':
to_delete.append(track_id)
for track_id in to_delete:
del self.tracks[track_id]
def _get_active_tracks(self):
"""获取活跃航迹"""
active_tracks = []
for track in self.tracks.values():
if track.status != 'DELETED':
active_tracks.append({
'id': track.track_id,
'state': track.get_state(),
'covariance': track.get_covariance(),
'status': track.status,
'age': track.age
})
return active_tracks
def _get_track_states(self):
"""获取所有航迹状态"""
states = {}
for track_id, track in self.tracks.items():
if track.status != 'DELETED':
states[track_id] = {
'state': track.get_state(),
'status': track.status
}
return states
def run_jpda_tracking_demo():
"""运行JPDA跟踪演示"""
print("="*60)
print("联合概率数据关联演示")
print("="*60)
np.random.seed(42)
# 生成场景
print("生成多目标场景...")
num_targets = 3
num_steps = 100
true_trajectories, measurements_all = generate_multitarget_scenario(
num_targets=num_targets,
num_steps=num_steps,
detection_prob=0.9,
false_alarm_rate=0.2,
measurement_noise_std=5.0
)
# 初始化跟踪器
print("初始化JPDA跟踪器...")
tracker = JPDATracker(
gate_threshold=9.21,
detection_prob=0.9,
false_alarm_density=1e-4,
measurement_noise_std=5.0,
new_track_threshold=2,
deletion_threshold=5,
max_hypotheses=50,
use_murty=False
)
# 运行跟踪
print("运行多目标跟踪...")
for t in range(num_steps):
measurements = measurements_all[t]
active_tracks = tracker.process_scan(measurements)
if t % 20 == 0:
print(f" 时间步 {t}: {len(active_tracks)} 个活跃航迹")
# 评估性能
print("评估跟踪性能...")
metrics = evaluate_tracking_performance(true_trajectories, tracker.history)
# 可视化结果
print("生成可视化结果...")
_visualize_jpda_results(true_trajectories, measurements_all, tracker)
# 打印性能指标
print("\n" + "="*60)
print("JPDA跟踪性能指标")
print("="*60)
print(f"位置RMSE: {metrics['position_rmse']:.2f} m")
print(f"位置MAE: {metrics['position_mae']:.2f} m")
print(f"最大位置误差: {metrics['position_max_error']:.2f} m")
print(f"平均每帧航迹数: {metrics['avg_tracks_per_frame']:.2f}")
print(f"最大同时航迹数: {metrics['max_tracks_per_frame']}")
print(f"关联成功率: {metrics['association_rate']*100:.1f}%")
# 打印JPDA特定统计
if tracker.history['joint_hypotheses']:
avg_hypotheses = np.mean(tracker.history['joint_hypotheses'])
print(f"平均联合假设数: {avg_hypotheses:.1f}")
print("="*60)
return {
'true_trajectories': true_trajectories,
'measurements_all': measurements_all,
'tracker': tracker,
'metrics': metrics
}
def _visualize_jpda_results(true_trajectories, measurements_all, tracker):
"""可视化JPDA跟踪结果"""
num_steps = len(measurements_all)
# 创建图形
fig, axes = plt.subplots(2, 3, figsize=(18, 12))
# 1. 整体轨迹
ax = axes[0, 0]
colors = ['r', 'g', 'b', 'c', 'm', 'y']
for i, trajectory in enumerate(true_trajectories):
color = colors[i % len(colors)]
ax.plot(trajectory[:, 0], trajectory[:, 1], color=color,
linewidth=2, alpha=0.7, label=f'目标{i+1}')
all_measurements = np.vstack(measurements_all)
ax.scatter(all_measurements[:, 0], all_measurements[:, 1],
c='gray', s=10, alpha=0.3, label='观测')
track_history = tracker.history['tracks']
track_colors = {}
color_idx = 0
for t in range(num_steps):
tracks = track_history[t]
for track_id, track_info in tracks.items():
if track_id not in track_colors:
track_colors[track_id] = colors[color_idx % len(colors)]
color_idx += 1
state = track_info['state']
ax.plot(state[0], state[1], 'o',
color=track_colors[track_id], markersize=4, alpha=0.5)
ax.set_xlabel('X位置')
ax.set_ylabel('Y位置')
ax.set_title('JPDA多目标跟踪轨迹')
ax.legend(loc='upper right')
ax.grid(True, alpha=0.3)
ax.axis('equal')
# 2. 联合假设数量变化
ax = axes[0, 1]
if tracker.history['joint_hypotheses']:
ax.plot(range(num_steps), tracker.history['joint_hypotheses'], 'b-', linewidth=2)
ax.set_xlabel('时间步')
ax.set_ylabel('联合假设数量')
ax.set_title('联合假设数量变化')
ax.grid(True, alpha=0.3)
else:
ax.text(0.5, 0.5, '无联合假设数据', ha='center', va='center',
transform=ax.transAxes, fontsize=12)
ax.set_title('联合假设数量变化')
# 3. 航迹数量随时间变化
ax = axes[0, 2]
time_steps = np.arange(num_steps)
track_counts = [len(tracker.history['tracks'][t]) for t in time_steps]
meas_counts = [len(tracker.history['measurements'][t]) for t in time_steps]
ax.plot(time_steps, track_counts, 'b-', linewidth=2, label='航迹数量')
ax.plot(time_steps, meas_counts, 'r-', linewidth=1, alpha=0.7, label='观测数量')
ax.set_xlabel('时间步')
ax.set_ylabel('数量')
ax.set_title('航迹与观测数量变化')
ax.legend()
ax.grid(True, alpha=0.3)
# 4. 计算复杂度分析
ax = axes[1, 0]
# 计算理论复杂度增长
max_targets = 10
complexities = []
for n in range(1, max_targets+1):
# 近似复杂度
complexity = np.math.factorial(n) # 阶乘增长
complexities.append(complexity)
ax.plot(range(1, max_targets+1), complexities, 'r-', linewidth=2, marker='o')
ax.set_xlabel('目标数量')
ax.set_ylabel('计算复杂度(对数)')
ax.set_title('JPDA计算复杂度增长')
ax.set_yscale('log')
ax.grid(True, alpha=0.3)
# 5. 位置误差分布
ax = axes[1, 1]
all_errors = []
for t in range(num_steps):
tracks = tracker.history['tracks'][t]
for track_id, track_info in tracks.items():
state = track_info['state']
min_error = np.inf
for trajectory in true_trajectories:
true_pos = trajectory[t, :2]
error = np.linalg.norm(state[:2] - true_pos)
if error < min_error:
min_error = error
if min_error < 50:
all_errors.append(min_error)
if all_errors:
ax.hist(all_errors, bins=30, alpha=0.7, color='green', edgecolor='black')
ax.set_xlabel('位置误差 (m)')
ax.set_ylabel('频数')
ax.set_title(f'位置误差分布 (均值={np.mean(all_errors):.2f}m)')
ax.grid(True, alpha=0.3)
else:
ax.text(0.5, 0.5, '无误差数据', ha='center', va='center',
transform=ax.transAxes, fontsize=12)
ax.set_title('位置误差分布')
# 6. 航迹生命周期
ax = axes[1, 2]
track_lifetimes = {}
for track_id in range(tracker.next_track_id):
lifetime = 0
for t in range(num_steps):
tracks = tracker.history['tracks'][t]
if track_id in tracks:
lifetime += 1
if lifetime > 0:
track_lifetimes[track_id] = lifetime
if track_lifetimes:
lifetimes = list(track_lifetimes.values())
ax.hist(lifetimes, bins=range(1, max(lifetimes)+2),
alpha=0.7, color='purple', edgecolor='black', align='left')
ax.set_xlabel('航迹生命周期 (帧)')
ax.set_ylabel('频数')
ax.set_title(f'航迹生命周期分布 (平均={np.mean(lifetimes):.1f}帧)')
ax.grid(True, alpha=0.3)
else:
ax.text(0.5, 0.5, '无航迹数据', ha='center', va='center',
transform=ax.transAxes, fontsize=12)
ax.set_title('航迹生命周期分布')
plt.suptitle('联合概率数据关联多目标跟踪结果', fontsize=16, y=1.02)
plt.tight_layout()
plt.savefig('jpda_tracking_results.png', dpi=300, bbox_inches='tight')
plt.show()
if __name__ == "__main__":
results = run_jpda_tracking_demo()
print("\n演示完成!")10. Demo 4-4:密集多目标跟踪场景对比
这个Demo将比较最近邻(NN)、概率数据关联(PDA)和联合概率数据关联(JPDA)在密集多目标跟踪场景中的性能。我们将模拟一个具有多个目标、较高虚警率和交叉轨迹的场景,以测试算法的鲁棒性。
python
"""
demo_4_4_dense_scenario_comparison.py
密集多目标跟踪场景对比
"""
import numpy as np
import matplotlib.pyplot as plt
from scipy import stats
import time
import sys
import os
sys.path.append(os.path.dirname(os.path.dirname(os.path.abspath(__file__))))
# 导入之前实现的跟踪器
from demo_4_1_nearest_neighbor_association import NearestNeighborTracker, generate_multitarget_scenario, evaluate_tracking_performance
from demo_4_2_probabilistic_data_association import PDATracker
from demo_4_3_joint_probabilistic_data_association import JPDATracker
def generate_dense_scenario(num_targets=5, num_steps=150,
detection_prob=0.85, false_alarm_rate=0.3,
measurement_noise_std=5.0, crossing=True):
"""
生成密集多目标场景,可能包含目标交叉
参数:
num_targets: 目标数量
num_steps: 时间步数
detection_prob: 检测概率
false_alarm_rate: 虚警率(每帧平均虚警数)
measurement_noise_std: 观测噪声标准差
crossing: 是否生成交叉轨迹
"""
np.random.seed(42)
true_trajectories = []
if crossing:
# 生成交叉轨迹
# 创建两个从不同方向接近的目标
for i in range(2):
if i == 0:
# 从左向右移动
x0 = -200
y0 = 0
vx0 = 4
vy0 = 0
else:
# 从下向上移动
x0 = 0
y0 = -200
vx0 = 0
vy0 = 4
trajectory = np.zeros((num_steps, 4))
trajectory[0] = [x0, y0, vx0, vy0]
for t in range(1, num_steps):
# 在交叉点附近添加轻微扰动
if 60 < t < 90:
vx = vx0 + np.random.randn() * 0.2
vy = vy0 + np.random.randn() * 0.2
else:
vx = vx0
vy = vy0
trajectory[t, 0] = trajectory[t-1, 0] + vx
trajectory[t, 1] = trajectory[t-1, 1] + vy
trajectory[t, 2] = vx
trajectory[t, 3] = vy
true_trajectories.append(trajectory)
# 生成其他随机轨迹
for i in range(2, num_targets):
x0 = np.random.uniform(-150, 150)
y0 = np.random.uniform(-150, 150)
vx0 = np.random.uniform(-3, 3)
vy0 = np.random.uniform(-3, 3)
trajectory = np.zeros((num_steps, 4))
trajectory[0] = [x0, y0, vx0, vy0]
for t in range(1, num_steps):
# 偶尔机动
if t % 30 == 0:
vx0 += np.random.randn() * 0.5
vy0 += np.random.randn() * 0.5
trajectory[t, 0] = trajectory[t-1, 0] + vx0
trajectory[t, 1] = trajectory[t-1, 1] + vy0
trajectory[t, 2] = vx0
trajectory[t, 3] = vy0
true_trajectories.append(trajectory)
else:
# 生成随机轨迹(不交叉)
for i in range(num_targets):
x0 = np.random.uniform(-200, 200)
y0 = np.random.uniform(-200, 200)
vx0 = np.random.uniform(-4, 4)
vy0 = np.random.uniform(-4, 4)
trajectory = np.zeros((num_steps, 4))
trajectory[0] = [x0, y0, vx0, vy0]
for t in range(1, num_steps):
# 偶尔机动
if t % 25 == 0:
vx0 += np.random.randn() * 0.5
vy0 += np.random.randn() * 0.5
trajectory[t, 0] = trajectory[t-1, 0] + vx0
trajectory[t, 1] = trajectory[t-1, 1] + vy0
trajectory[t, 2] = vx0
trajectory[t, 3] = vy0
true_trajectories.append(trajectory)
# 生成观测
measurements_all = []
for t in range(num_steps):
frame_measurements = []
# 真实目标观测
for i in range(num_targets):
if np.random.rand() < detection_prob: # 检测
true_pos = true_trajectories[i][t, :2]
noisy_pos = true_pos + np.random.randn(2) * measurement_noise_std
frame_measurements.append(noisy_pos)
# 虚警
num_false_alarms = np.random.poisson(false_alarm_rate)
for _ in range(num_false_alarms):
false_alarm = np.random.uniform(-250, 250, 2)
frame_measurements.append(false_alarm)
measurements_all.append(np.array(frame_measurements))
return true_trajectories, measurements_all
def run_comparison_experiment():
"""运行对比实验"""
print("="*60)
print("密集多目标跟踪场景对比实验")
print("="*60)
np.random.seed(42)
# 生成场景
print("生成密集多目标场景(包含轨迹交叉)...")
num_targets = 5
num_steps = 150
true_trajectories, measurements_all = generate_dense_scenario(
num_targets=num_targets,
num_steps=num_steps,
detection_prob=0.85, # 较低的检测概率
false_alarm_rate=0.4, # 较高的虚警率
measurement_noise_std=5.0,
crossing=True
)
# 定义要比较的算法
algorithms = {
'NN': NearestNeighborTracker,
'PDA': PDATracker,
'JPDA': JPDATracker
}
# 存储结果
results = {}
for algo_name, tracker_class in algorithms.items():
print(f"\n运行{algo_name}算法...")
# 记录运行时间
start_time = time.time()
# 初始化跟踪器
if algo_name == 'NN':
tracker = NearestNeighborTracker(
gate_threshold=9.21,
detection_prob=0.85,
false_alarm_density=1e-4,
measurement_noise_std=5.0,
new_track_threshold=2,
deletion_threshold=5
)
elif algo_name == 'PDA':
tracker = PDATracker(
gate_threshold=9.21,
detection_prob=0.85,
false_alarm_density=1e-4,
measurement_noise_std=5.0,
new_track_threshold=2,
deletion_threshold=5
)
else: # JPDA
tracker = JPDATracker(
gate_threshold=9.21,
detection_prob=0.85,
false_alarm_density=1e-4,
measurement_noise_std=5.0,
new_track_threshold=2,
deletion_threshold=5,
max_hypotheses=50,
use_murty=False
)
# 运行跟踪
for t in range(num_steps):
measurements = measurements_all[t]
tracker.process_scan(measurements)
end_time = time.time()
run_time = end_time - start_time
# 评估性能
metrics = evaluate_tracking_performance(true_trajectories, tracker.history)
metrics['run_time'] = run_time
# 计算额外的性能指标
metrics.update(_compute_additional_metrics(tracker, num_steps))
results[algo_name] = {
'tracker': tracker,
'metrics': metrics
}
print(f" RMSE: {metrics['position_rmse']:.2f}m")
print(f" 运行时间: {run_time:.2f}秒")
print(f" 平均航迹数: {metrics['avg_tracks_per_frame']:.2f}")
# 可视化对比结果
print("\n生成对比可视化...")
_visualize_comparison_results(true_trajectories, measurements_all, results)
# 打印详细对比
print("\n" + "="*60)
print("算法性能详细对比")
print("="*60)
print(f"{'指标':<20} {'NN':<15} {'PDA':<15} {'JPDA':<15}")
print("-"*60)
# 定义要对比的指标
metric_names = {
'position_rmse': 'RMSE (m)',
'position_mae': 'MAE (m)',
'max_tracks_per_frame': '最大航迹数',
'avg_tracks_per_frame': '平均航迹数',
'association_rate': '关联成功率',
'run_time': '运行时间 (s)',
'track_switches': '航迹切换数',
'avg_track_lifetime': '平均航迹寿命'
}
for metric_key, metric_display in metric_names.items():
values = []
for algo_name in algorithms:
if metric_key in results[algo_name]['metrics']:
value = results[algo_name]['metrics'][metric_key]
if 'rate' in metric_key:
values.append(f"{value*100:.1f}%")
elif 'time' in metric_key:
values.append(f"{value:.2f}")
else:
values.append(f"{value:.2f}")
else:
values.append("N/A")
print(f"{metric_display:<20} {values[0]:<15} {values[1]:<15} {values[2]:<15}")
print("="*60)
# 找出最佳算法
best_algo = None
best_score = float('inf')
for algo_name in algorithms:
score = results[algo_name]['metrics']['position_rmse'] * results[algo_name]['metrics']['run_time']
if score < best_score:
best_score = score
best_algo = algo_name
print(f"\n综合最佳算法: {best_algo} (平衡精度和速度)")
print("="*60)
return {
'true_trajectories': true_trajectories,
'measurements_all': measurements_all,
'results': results
}
def _compute_additional_metrics(tracker, num_steps):
"""计算额外的性能指标"""
metrics = {}
# 计算航迹切换数
track_switches = 0
prev_associations = {}
for t in range(num_steps):
if t in tracker.history.get('associations', {}):
associations = tracker.history['associations'][t]
for track_id, meas_idx in associations.items():
if track_id in prev_associations and prev_associations[track_id] != meas_idx:
track_switches += 1
prev_associations[track_id] = meas_idx
metrics['track_switches'] = track_switches
# 计算航迹生命周期
track_lifetimes = {}
for track in getattr(tracker, 'tracks', {}).values():
if hasattr(track, 'update_count'):
track_lifetimes[track.track_id] = track.update_count
if track_lifetimes:
metrics['avg_track_lifetime'] = np.mean(list(track_lifetimes.values()))
else:
metrics['avg_track_lifetime'] = 0
return metrics
def _visualize_comparison_results(true_trajectories, measurements_all, results):
"""可视化对比结果"""
num_steps = len(measurements_all)
algorithms = list(results.keys())
# 创建图形
fig, axes = plt.subplots(3, 4, figsize=(20, 15))
# 1. 真实轨迹与观测
ax = axes[0, 0]
colors = ['r', 'g', 'b', 'c', 'm', 'y']
for i, trajectory in enumerate(true_trajectories):
color = colors[i % len(colors)]
ax.plot(trajectory[:, 0], trajectory[:, 1], color=color,
linewidth=2, alpha=0.7, label=f'目标{i+1}')
all_measurements = np.vstack(measurements_all)
ax.scatter(all_measurements[:, 0], all_measurements[:, 1],
c='gray', s=5, alpha=0.3, label='观测')
ax.set_xlabel('X位置')
ax.set_ylabel('Y位置')
ax.set_title('真实轨迹与观测')
ax.legend(loc='upper right')
ax.grid(True, alpha=0.3)
ax.axis('equal')
# 2-4. 各算法轨迹估计
algo_colors = {'NN': 'blue', 'PDA': 'green', 'JPDA': 'red'}
for idx, algo_name in enumerate(algorithms):
ax = axes[0, idx+1]
tracker = results[algo_name]['tracker']
track_history = tracker.history['tracks']
# 绘制真实轨迹
for i, trajectory in enumerate(true_trajectories):
color = colors[i % len(colors)]
ax.plot(trajectory[:, 0], trajectory[:, 1], color=color,
linewidth=1, alpha=0.3)
# 绘制估计轨迹
track_colors = {}
color_idx = 0
for t in range(num_steps):
tracks = track_history[t]
for track_id, track_info in tracks.items():
if track_id not in track_colors:
track_colors[track_id] = colors[color_idx % len(colors)]
color_idx += 1
state = track_info['state']
ax.plot(state[0], state[1], 'o',
color=track_colors[track_id], markersize=3, alpha=0.5)
ax.set_xlabel('X位置')
ax.set_ylabel('Y位置')
ax.set_title(f'{algo_name}估计轨迹')
ax.grid(True, alpha=0.3)
ax.axis('equal')
# 5. 位置误差对比
ax = axes[1, 0]
x = np.arange(len(algorithms))
width = 0.25
# 收集各算法的误差指标
rmse_values = [results[algo]['metrics']['position_rmse'] for algo in algorithms]
mae_values = [results[algo]['metrics']['position_mae'] for algo in algorithms]
ax.bar(x - width/2, rmse_values, width, label='RMSE', color='blue', alpha=0.7)
ax.bar(x + width/2, mae_values, width, label='MAE', color='red', alpha=0.7)
ax.set_xlabel('算法')
ax.set_ylabel('误差 (m)')
ax.set_title('位置误差对比')
ax.set_xticks(x)
ax.set_xticklabels(algorithms)
ax.legend()
ax.grid(True, alpha=0.3, axis='y')
# 6. 运行时间对比
ax = axes[1, 1]
run_times = [results[algo]['metrics']['run_time'] for algo in algorithms]
bars = ax.bar(x, run_times, width=0.6, color=['blue', 'green', 'red'], alpha=0.7)
ax.set_xlabel('算法')
ax.set_ylabel('运行时间 (秒)')
ax.set_title('计算效率对比')
ax.set_xticks(x)
ax.set_xticklabels(algorithms)
ax.grid(True, alpha=0.3, axis='y')
# 添加数值标签
for bar, time_val in zip(bars, run_times):
ax.text(bar.get_x() + bar.get_width()/2, bar.get_height() + 0.1,
f'{time_val:.2f}', ha='center', va='bottom')
# 7. 航迹数量对比
ax = axes[1, 2]
for algo_name in algorithms:
tracker = results[algo_name]['tracker']
track_counts = [len(tracker.history['tracks'][t]) for t in range(num_steps)]
ax.plot(range(num_steps), track_counts, color=algo_colors[algo_name],
linewidth=2, label=algo_name, alpha=0.7)
ax.set_xlabel('时间步')
ax.set_ylabel('航迹数量')
ax.set_title('航迹数量变化对比')
ax.legend()
ax.grid(True, alpha=0.3)
# 8. 关联成功率对比
ax = axes[1, 3]
association_rates = [results[algo]['metrics']['association_rate'] * 100 for algo in algorithms]
bars = ax.bar(x, association_rates, width=0.6, color=['blue', 'green', 'red'], alpha=0.7)
ax.set_xlabel('算法')
ax.set_ylabel('关联成功率 (%)')
ax.set_title('关联成功率对比')
ax.set_xticks(x)
ax.set_xticklabels(algorithms)
ax.set_ylim([0, 100])
ax.grid(True, alpha=0.3, axis='y')
# 添加数值标签
for bar, rate in zip(bars, association_rates):
ax.text(bar.get_x() + bar.get_width()/2, bar.get_height() + 1,
f'{rate:.1f}%', ha='center', va='bottom')
# 9. 航迹生命周期分布
ax = axes[2, 0]
for algo_name in algorithms:
tracker = results[algo_name]['tracker']
track_lifetimes = []
for track in getattr(tracker, 'tracks', {}).values():
if hasattr(track, 'update_count'):
track_lifetimes.append(track.update_count)
if track_lifetimes:
ax.hist(track_lifetimes, bins=20, alpha=0.5,
color=algo_colors[algo_name], label=algo_name, density=True)
ax.set_xlabel('航迹生命周期 (帧)')
ax.set_ylabel('概率密度')
ax.set_title('航迹生命周期分布')
ax.legend()
ax.grid(True, alpha=0.3)
# 10. 单帧关联详情(交叉点附近)
ax = axes[2, 1]
# 选择交叉点附近的帧
frame_idx = 75
# 绘制真实目标位置
for i, trajectory in enumerate(true_trajectories):
true_pos = trajectory[frame_idx, :2]
ax.plot(true_pos[0], true_pos[1], 'ko', markersize=10,
label='真实目标' if i == 0 else "")
# 绘制观测
measurements = measurements_all[frame_idx]
ax.scatter(measurements[:, 0], measurements[:, 1], c='blue',
s=50, marker='x', label='观测')
# 绘制各算法估计
marker_styles = {'NN': 's', 'PDA': '^', 'JPDA': 'o'}
for algo_name in algorithms:
tracker = results[algo_name]['tracker']
tracks = tracker.history['tracks'][frame_idx]
for track_id, track_info in tracks.items():
state = track_info['state']
ax.plot(state[0], state[1], marker_styles[algo_name],
color=algo_colors[algo_name], markersize=8,
label=f'{algo_name}估计' if track_id == 0 else "")
ax.set_xlabel('X位置')
ax.set_ylabel('Y位置')
ax.set_title(f'第{frame_idx}帧(交叉点)关联详情')
ax.legend(loc='upper right')
ax.grid(True, alpha=0.3)
ax.axis('equal')
# 11. 算法适应性雷达图
ax = axes[2, 2]
# 定义评估维度
categories = ['精度', '速度', '鲁棒性', '关联率', '航迹连续性']
# 归一化各维度分数(0-1)
scores = {}
for algo_name in algorithms:
metrics = results[algo_name]['metrics']
# 精度(RMSE越小越好)
accuracy = 1.0 / (1.0 + metrics['position_rmse'])
# 速度(运行时间越短越好)
speed = 1.0 / (1.0 + metrics['run_time'])
# 鲁棒性(航迹切换越少越好)
robustness = 1.0 / (1.0 + metrics.get('track_switches', 0))
# 关联率
association_rate = metrics['association_rate']
# 航迹连续性
continuity = min(1.0, metrics.get('avg_track_lifetime', 0) / 100)
scores[algo_name] = [accuracy, speed, robustness, association_rate, continuity]
# 绘制雷达图
angles = np.linspace(0, 2*np.pi, len(categories), endpoint=False).tolist()
angles += angles[:1] # 闭合
for algo_name in algorithms:
values = scores[algo_name]
values += values[:1] # 闭合
ax.plot(angles, values, 'o-', linewidth=2, label=algo_name,
color=algo_colors[algo_name])
ax.fill(angles, values, alpha=0.1, color=algo_colors[algo_name])
ax.set_xticks(angles[:-1])
ax.set_xticklabels(categories)
ax.set_ylim([0, 1])
ax.set_title('算法适应性雷达图')
ax.legend(loc='upper right')
ax.grid(True)
# 12. 综合评分
ax = axes[2, 3]
ax.axis('off')
# 计算综合评分
summary_text = "综合性能评分(加权平均):\n\n"
weights = {
'精度': 0.3,
'速度': 0.2,
'鲁棒性': 0.2,
'关联率': 0.2,
'航迹连续性': 0.1
}
total_scores = {}
for algo_name in algorithms:
weighted_score = 0
for i, category in enumerate(categories):
weighted_score += scores[algo_name][i] * weights[category]
total_scores[algo_name] = weighted_score
# 排序
sorted_scores = sorted(total_scores.items(), key=lambda x: x[1], reverse=True)
for algo_name, score in sorted_scores:
summary_text += f"{algo_name}: {score:.3f}\n"
ax.text(0.1, 0.5, summary_text, fontsize=12, transform=ax.transAxes,
verticalalignment='center')
ax.set_title('综合性能评分')
plt.suptitle('密集多目标跟踪算法对比分析', fontsize=18, y=1.02)
plt.tight_layout()
plt.savefig('dense_scenario_comparison.png', dpi=300, bbox_inches='tight')
plt.show()
def analyze_parameter_sensitivity():
"""分析参数敏感性"""
print("\n" + "="*60)
print("参数敏感性分析")
print("="*60)
np.random.seed(42)
# 测试不同参数设置
param_scenarios = [
{'detection_prob': 0.95, 'false_alarm_rate': 0.1, 'name': '理想条件'},
{'detection_prob': 0.85, 'false_alarm_rate': 0.3, 'name': '中等条件'},
{'detection_prob': 0.75, 'false_alarm_rate': 0.5, 'name': '恶劣条件'}
]
algorithms = ['NN', 'PDA', 'JPDA']
# 存储结果
sensitivity_results = {algo: [] for algo in algorithms}
for scenario in param_scenarios:
print(f"\n测试场景: {scenario['name']}")
print(f" 检测概率: {scenario['detection_prob']}, 虚警率: {scenario['false_alarm_rate']}")
# 生成场景
true_trajectories, measurements_all = generate_dense_scenario(
num_targets=4,
num_steps=100,
detection_prob=scenario['detection_prob'],
false_alarm_rate=scenario['false_alarm_rate'],
measurement_noise_std=5.0,
crossing=False
)
for algo_name in algorithms:
# 初始化跟踪器
if algo_name == 'NN':
tracker = NearestNeighborTracker(
gate_threshold=9.21,
detection_prob=scenario['detection_prob'],
false_alarm_density=1e-4,
measurement_noise_std=5.0
)
elif algo_name == 'PDA':
tracker = PDATracker(
gate_threshold=9.21,
detection_prob=scenario['detection_prob'],
false_alarm_density=1e-4,
measurement_noise_std=5.0
)
else: # JPDA
tracker = JPDATracker(
gate_threshold=9.21,
detection_prob=scenario['detection_prob'],
false_alarm_density=1e-4,
measurement_noise_std=5.0,
max_hypotheses=30
)
# 运行跟踪
for t in range(100):
measurements = measurements_all[t]
tracker.process_scan(measurements)
# 评估性能
metrics = evaluate_tracking_performance(true_trajectories, tracker.history)
sensitivity_results[algo_name].append({
'scenario': scenario['name'],
'rmse': metrics['position_rmse'],
'association_rate': metrics['association_rate']
})
# 可视化参数敏感性
fig, axes = plt.subplots(1, 2, figsize=(14, 6))
# 1. RMSE随场景变化
ax = axes[0]
scenarios = [s['name'] for s in param_scenarios]
x = np.arange(len(scenarios))
width = 0.25
for idx, algo_name in enumerate(algorithms):
rmse_values = [r['rmse'] for r in sensitivity_results[algo_name]]
ax.bar(x + (idx-1)*width, rmse_values, width,
label=algo_name, alpha=0.7)
ax.set_xlabel('场景条件')
ax.set_ylabel('RMSE (m)')
ax.set_title('不同场景下的RMSE对比')
ax.set_xticks(x)
ax.set_xticklabels(scenarios)
ax.legend()
ax.grid(True, alpha=0.3, axis='y')
# 2. 关联成功率随场景变化
ax = axes[1]
for idx, algo_name in enumerate(algorithms):
association_rates = [r['association_rate']*100 for r in sensitivity_results[algo_name]]
ax.bar(x + (idx-1)*width, association_rates, width,
label=algo_name, alpha=0.7)
ax.set_xlabel('场景条件')
ax.set_ylabel('关联成功率 (%)')
ax.set_title('不同场景下的关联成功率对比')
ax.set_xticks(x)
ax.set_xticklabels(scenarios)
ax.legend()
ax.grid(True, alpha=0.3, axis='y')
plt.suptitle('参数敏感性分析', fontsize=16, y=1.02)
plt.tight_layout()
plt.savefig('parameter_sensitivity_analysis.png', dpi=300, bbox_inches='tight')
plt.show()
# 打印敏感性分析结果
print("\n" + "="*60)
print("参数敏感性分析结果")
print("="*60)
for scenario in param_scenarios:
print(f"\n场景: {scenario['name']}")
print(f"{'算法':<10} {'RMSE':<10} {'关联成功率':<10}")
print("-"*40)
for algo_name in algorithms:
for result in sensitivity_results[algo_name]:
if result['scenario'] == scenario['name']:
print(f"{algo_name:<10} {result['rmse']:<10.2f} {result['association_rate']*100:<10.1f}%")
break
print("="*60)
return sensitivity_results
if __name__ == "__main__":
# 运行主对比实验
comparison_results = run_comparison_experiment()
# 运行参数敏感性分析
sensitivity_results = analyze_parameter_sensitivity()
print("\n所有演示完成!")11. 总结与工程实践建议
11.1 数据关联算法对比总结
| 算法 | 优点 | 缺点 | 适用场景 | 计算复杂度 |
|---|---|---|---|---|
| **最近邻(NN)** | 1. 计算简单,实时性好 2. 实现容易 3. 内存消耗小 | 1. 容易误关联 2. 不处理关联不确定性 3. 密集场景性能差 | 1. 稀疏目标场景 2. 计算资源受限 3. 实时性要求高 | O(M×N) |
| **概率数据关联(PDA)** | 1. 考虑关联不确定性 2. 比NN更鲁棒 3. 单目标跟踪性能好 | 1. 不处理多目标关联耦合 2. 密集场景可能混淆 3. 实现较复杂 | 1. 中等密度目标 2. 需要鲁棒性的场景 3. 单目标或弱耦合目标 | O(M×N) |
| **联合概率数据关联(JPDA)** | 1. 显式处理多目标关联 2. 密集场景性能好 3. 理论完备 | 1. 计算复杂度高 2. 实现复杂 3. 需要近似算法 | 1. 密集目标场景 2. 目标交叉情况 3. 高精度要求场景 | O(M!×N!) |
11.2 工程实践建议
11.3 参数调优指南
-
关联门限:
-
通常设为卡方分布的分位数(如9.21对应99%置信度)
-
过小:漏关联增加;过大:误关联增加
-
建议:从9.21开始,根据场景调整
-
-
检测概率:
-
根据雷达性能设置,通常0.7-0.95
-
影响航迹连续性和虚警处理
-
-
虚警密度:
-
需要根据实际虚警率估计
-
影响新航迹起始和虚假航迹抑制
-
-
航迹管理参数:
-
起始逻辑:M/N规则,常用2/3或3/4
-
删除逻辑:连续漏检次数,通常3-5次
-
确认逻辑:连续关联成功次数,通常3次
-
11.4 实时性优化建议
-
计算优化:
-
使用KD树加速最近邻搜索
-
并行化计算关联概率
-
使用近似算法处理大规模JPDA
-
-
内存优化:
-
限制历史数据长度
-
使用稀疏矩阵存储
-
及时清理无效航迹
-
-
算法级优化:
-
分级处理:先用NN快速关联,复杂情况用JPDA
-
区域分割:分区域处理,减少关联组合
-
帧间预测:利用运动模型减少搜索空间
-
11.5 鲁棒性设计
-
异常处理:
-
野值检测与剔除
-
数值稳定性处理
-
边界条件处理
-
-
自适应调整:
-
根据场景动态调整关联门限
-
在线估计检测概率和虚警率
-
自适应航迹管理参数
-
-
冗余设计:
-
多假设跟踪保持
-
延迟决策机制
-
软删除策略
-
11.6 实际部署考虑
-
硬件平台:
-
CPU/GPU选择:密集计算考虑GPU加速
-
内存需求:JPDA需要较大内存
-
实时性保证:最坏情况执行时间分析
-
-
软件框架:
-
模块化设计:便于算法更换
-
参数配置:外部配置文件
-
日志记录:便于调试和优化
-
-
测试验证:
-
单元测试:每个模块独立测试
-
集成测试:全流程测试
-
场景测试:多种典型场景测试
-
压力测试:极限条件测试
-
11.7 未来发展方向
-
深度学习辅助:
-
使用神经网络预测关联概率
-
端到端的数据关联学习
-
特征学习增强关联判别
-
-
多传感器融合:
-
雷达+光电+红外多源关联
-
异类传感器数据关联
-
分布式多传感器跟踪
-
-
智能航迹管理:
-
基于机器学习的航迹起始/终结
-
自适应模型选择
-
在线学习优化参数
-
-
新型算法:
-
随机有限集理论(RFS)
-
多伯努利滤波器
-
基于图神经网络的关联
-
11.8 代码资源总结
本文实现的完整多目标跟踪系统包括:
-
基础架构:
-
航迹管理:
Track类 -
场景生成:
generate_multitarget_scenario -
性能评估:
evaluate_tracking_performance
-
-
数据关联算法:
-
最近邻:
NearestNeighborTracker -
概率数据关联:
PDATracker -
联合概率数据关联:
JPDATracker
-
-
四个完整Demo:
-
Demo 4-1:最近邻数据关联实现
-
Demo 4-2:概率数据关联实现
-
Demo 4-3:联合概率数据关联实现
-
Demo 4-4:密集多目标跟踪场景对比
-
-
分析工具:
-
参数敏感性分析
-
性能对比可视化
-
雷达图综合评估
-
11.9 下一篇预告
在第五篇博客中,我们将探讨雷达目标跟踪中的先进话题:
-
随机有限集理论:多目标跟踪的统一框架
-
多伯努利滤波器:处理目标数量变化
-
标签多伯努利滤波器:带身份保持的跟踪
-
高斯混合实现:高效近似算法
-
实际工程挑战:计算复杂度、实时性、可扩展性