业务架构设计
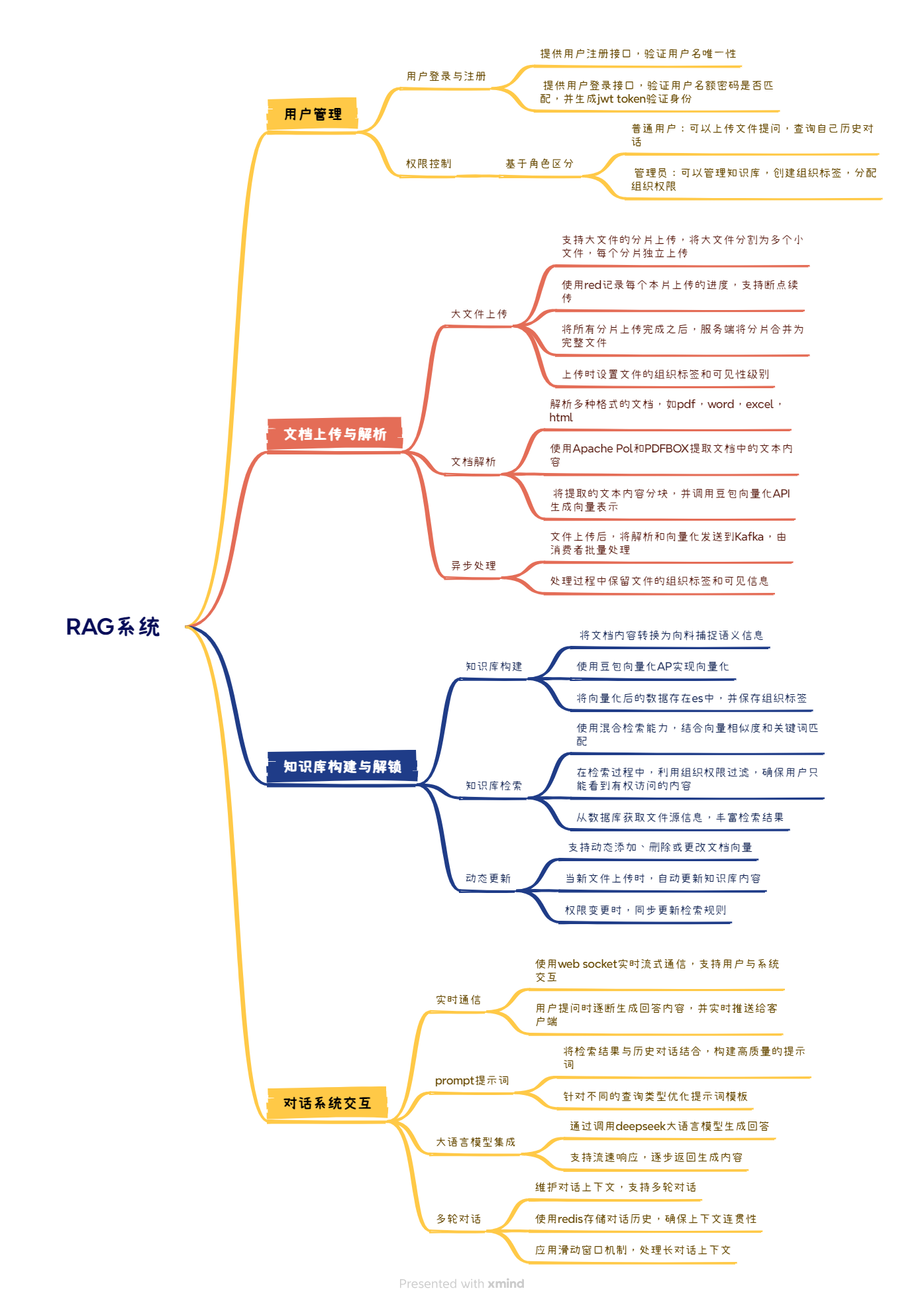
项目架构图
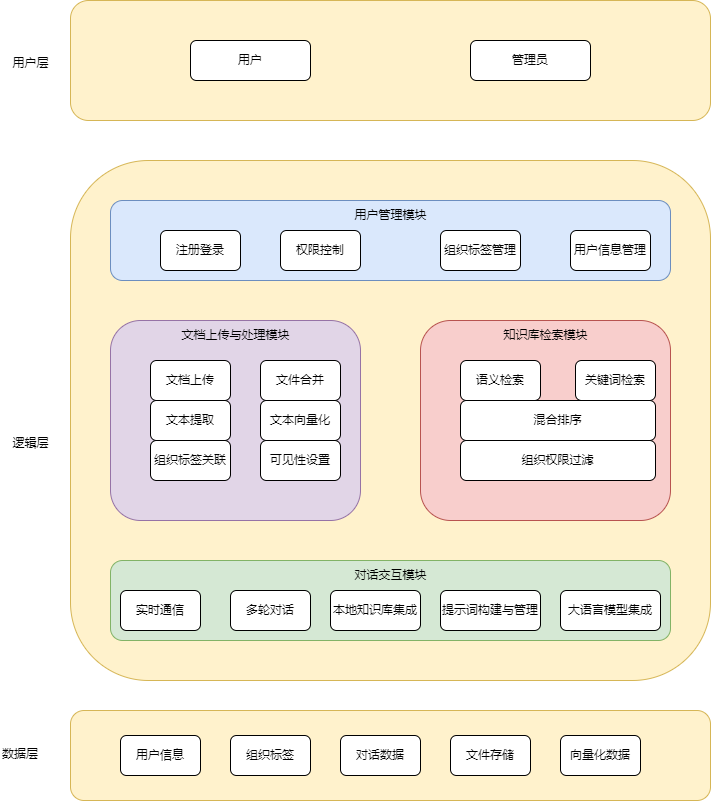
业务流程设计
文档向量
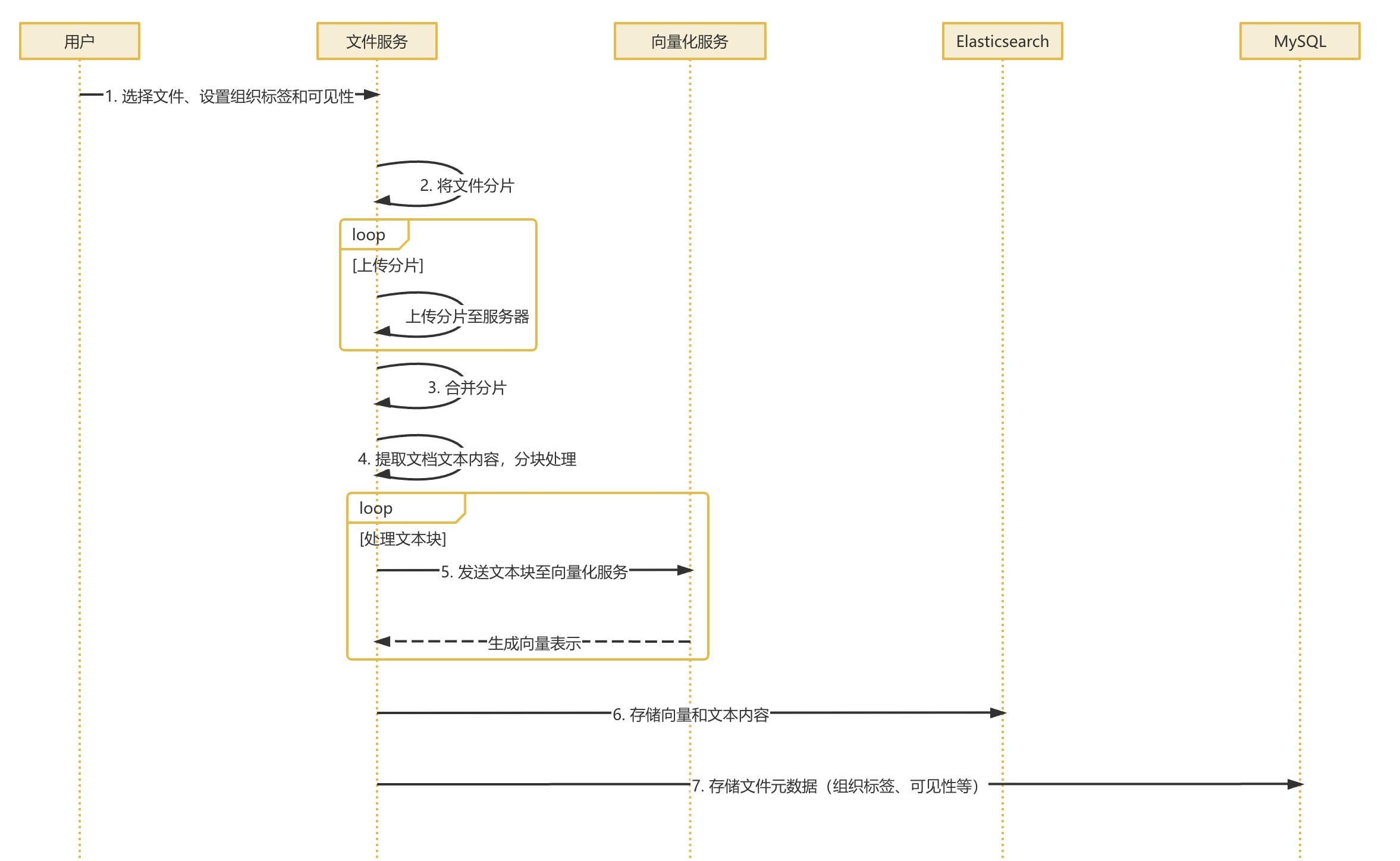
- 整个流程从用户上传文档开始,用户通过前端页面选择文档并设置相关的组织标签和可见信后系统开始接收文档。这个阶段的关键是建立文档的基本记录信息,包括文件的Md5哈希值文件原始名文件大小上传用户等信息。系统会为每一个文档生成唯一标识,并将这份文档的元素据信息存储到myq数据库中,同时将原始文件保存在储系中。
- 文档上传完成后,系统进行分块处理阶段。这个阶段采用循环处理的方式,逐个处理文档中的内容片段。首先系统会调用文件服务来读取初始文档,然后使用Apache Tika等文档解析工具提取成文本内容。由于整个文档的通用内容比较长,直接进行向量化处理会影响系统会将提取出的文档一定规则或单元,每个文本都会确定义到文档中的位置
- 在分块完成后,系统会对生成的文本块进行合并和优化处理。这个步骤主要是为了确保本块的质量和完整性,系统会检查相邻的文本块是否存在语义上的连续。如果某些块过短或者语义不完整,会考虑相邻块进行合并,同时系统还会筛选掉一些无意义的内容。比如页面页脚图片说明等,确保每个文本块都有其价值的信息内容
- 文本块准备就绪后,系统开始进行向量化处理。这个阶段同样采用循环处理的方式,逐个处理每个文本块系统会调用向量化服务,将文本块的内容发送给向量模型,进行向量转换。向量模型会将文本的内容转化为高精度的数学向量。这些向量能够表示文本的语义特征进行向量化服务在完成转换后,会将生成的向量数据返回给系统。这个过程需要一定的时间,特别是文档较大或文本块较多的时候,因此,系统采用了异步处理的方法来提高效率
- 向量化完成后,系统需要将生成的向量数据进行持久化存储。这个阶段涉及到两个存储系统的协同工作。首先,系统会将向量数据连同相关的文本内容文档标识快序列号等信息一一同存储在ES中,ES作为专业的搜索引擎,不仅能够存储向量数据还能提供高效的向量相似度搜索功能。同时,系统还会将文档的原数据信息更新到mysql数据库中。包括处理状态,向量化完成时间,确保数据一次性和完整性
- 数据存储完成后,ES会自动新增的向量数据构建索引。这个过程包括创建倒排索引,用于关键词搜索,以及构建向量索引用于语义相似度搜索。系统会根据预设的索引策略,对文本进行分辨和副本设置,确保搜索性和数据安全性。索引构建完成之后,这些文档内容就可以为用户通过各种方式进行查询和检索
- 在整个流程中,系统还包含了完整的异常处理和监控机制。如果在任何一个环节出错,比如文档解析失败,向量化服务不可用存储系统异常等系统都会记录详细的错误信息,并将错误信息除采取相应的处理策略,可恢复的策略系统会自动进行调试,不可恢复的错误,系统会标记状态,并通知管理员,同时,系统还未实时监控各个组件的运行状态的性能指标,确保整个流程稳定性和高效性
知识检索
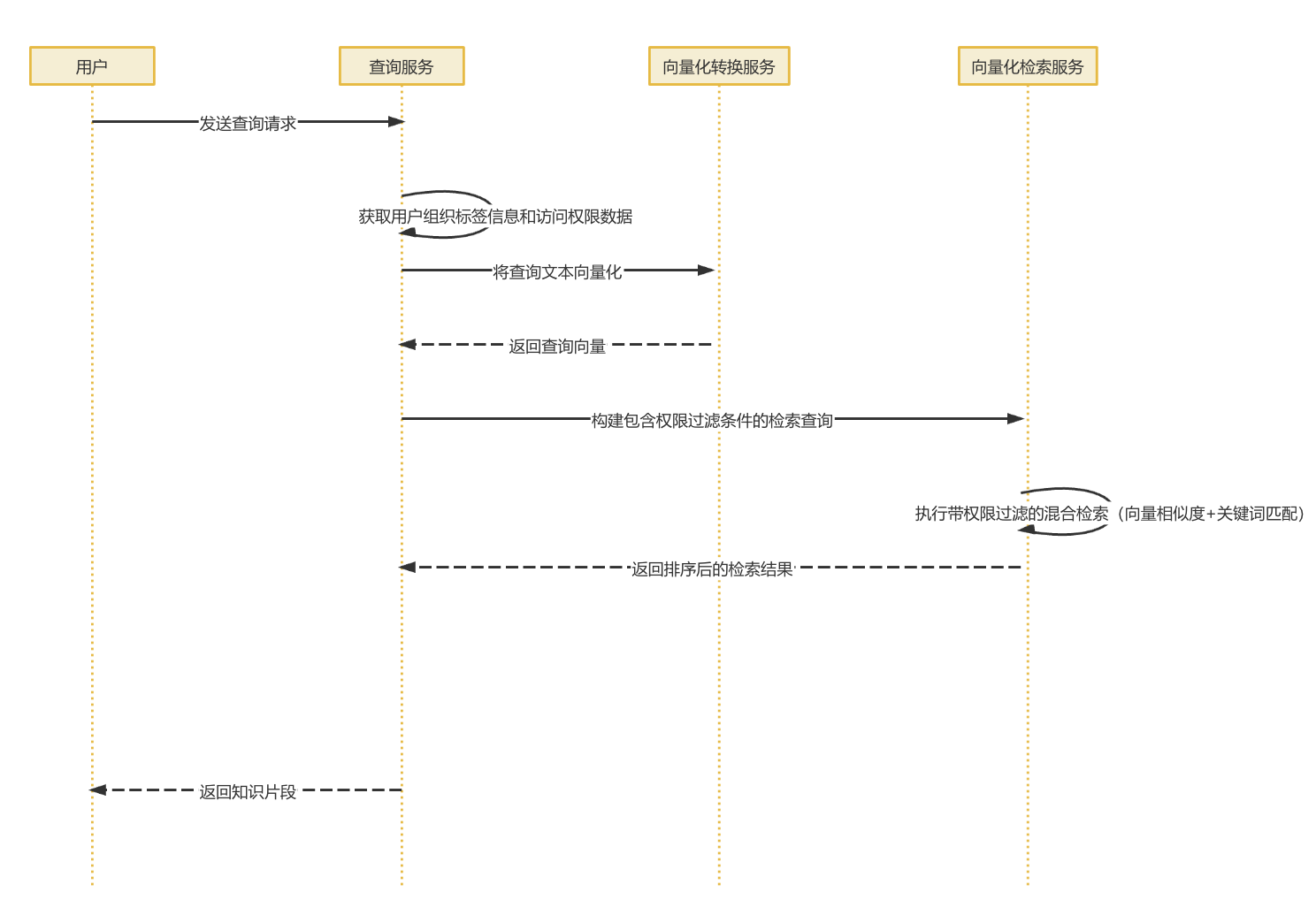
- 用户查询请求,用户通过前端界面发起查询请求系统。首先接收到用户的自然语言并查询文本,通过websocket实时传输给后端服务
- 接着是查询预处理和向量化查询服务接收到用户的请求,会根据用户的组织标签和权限数据,确保后续检索符合权限控制。同时,系统将查询的文本发给向量化服务进行向量化处理,将自然语言转化为高维向量表示实现语义化检索的关键步骤
- 然后是混合检索执行系统构建,包含权限过滤条件的综合查询,结合向量相似度检索和关键词匹配,在ES中进行高效搜索。这种混合策略,既保证了语义理解的准确性,又兼顾关键词匹配的准确性
- 然后是结果排序与权限过滤,检索到的结果会进行严格的权限验证,确保用户只能访问有限的知识内容系统根据相似度得分关键词匹配等多个维度对进行综合排序,并按照topK参数返回最相关结果
- 最后将结果展示给前端
聊天助手
- 首先,用户通过web socket发送问题,然后此问题传给后端
- 接着,系统调用知识库检索模块获取相关内容。首先,系统会创建绘话,然后到调用执行待权限过滤的混合解锁,从ES中检索最相关的5条知识片段,确保用户只能访问有限权限的内容
- 然后是系统构建包含检索结果和历史对话的提示词,系统通过从reis中获取的对话历史记录,支持最近20条消息的上下文保持,然后调用方法将检索到的知识片格式化为上下文信息,每个片段限定在300字符内进行标记,构建提示词,既包含相关的知识背景,又保证了对话的连贯性
- 接下来就是调用大语言模型AP生成。回答将用户的问题构建的上下文和对话历史一起发送给大语言模型。这个过程采用流失调用方法,能够实时接送AI的生成内容片段,而不用等待生成完毕
- 然后是通过web socket的流式返回生成内容。当大语言模型返回内容片段时,系统通过方法将每个chunk包装为jason的格式,并通过webs socket实时发送给前端
- 最后是保存对话记录到数据库。当AI生成回答后,系统通过后台现程检索到完成响应调用方法将完整的用户问题和AI回答保存到redis中。对话记录包含角色标识,内容时间支持7天数据保留,同时发送完成通知给前端前端接收后返回状态
权限管理
- 整个权限管理流程始于管理员通过
AdminController.java中的接口创建和管理组织标签。管理员可以通过POST /api/admin/org-tags接口创建具有层级结构的组织标签,支持设置标签 ID、名称、描述和父级标签,所有标签信息都存储在ddl.sql定义的 organization_tags 表中。 - 在组织标签创建完成后,管理员通过 PUT /api/admin/users/{userId}/org-tags 接口为用户分配相应的组织标签。这些标签以逗号分隔的字符串形式存储在用户表的 org_tags 字段中。系统的一个重要特性是支持层级权限继承, OrgTagCacheService.java 负责计算用户的有效组织标签,确保用户在拥有父级标签时自动获得所有子级标签的访问权限。为了提高查询性
- 当用户上传文件时,前端的
upload-dialog.vue提供了直观的权限设置界面。管理员可以通过级联选择器选择任意组织标签,而普通用户只能选择自己被分配的组织标签。同时,用户需要设置文件的可见性级别,选择公开或私有。后端的UploadController.java在处理文件上传时会接收这些权限参数,如果用户未指定组织标签,系统会自动使用用户的主组织标签,确保每个文件都有明确的权限归属。 - 系统的权限控制核心在于
OrgTagAuthorizationFilter.java,这个过滤器统一处理所有 API 请求的权限验证。它采用了智能的权限判断逻辑:公开资源直接允许访问,默认组织或无组织标签的资源也允许访问,私有标签资源仅限所有者和管理员访问,其他情况则需要检查用户的有效组织标签是否与资源的组织标签匹配。 - 在知识检索环节,
HybridSearchService.java的searchWithPermission方法确保用户只能检索到有权限访问的内容。系统会获取用户的有效组织标签,并在 Elasticsearch 查询中添加相应的权限过滤条件,无论是向量搜索还是文本搜索都会应用这些权限限制。 - 最终,用户通过
DocumentService.java只能看到自己有权访问的文件和内容。这包括用户自己上传的文件、标记为公开的文件、用户所属组织标签的文件以及默认组织的文件。
疑问解答
为什么我们要进行两遍权线过滤?
根据参考资料中派聪明的业务流程设计,在结果排序后再次进行权限过滤,主要基于以下关键原因:
1. 双重保障机制
- 预防性过滤(检索阶段):在
HybridSearchService中,系统通过 Elasticsearch 的查询条件(如组织标签权限)进行初步过滤,减少无效数据量,提升检索效率。 - 兜底验证(结果阶段):即使检索阶段已过滤,仍需对最终返回的候选结果进行二次权限验证,确保100%安全。例如:
-
- 文档元数据更新后,索引可能未及时同步权限变更;
- 复杂权限规则(如层级继承)在检索阶段可能存在边界漏洞。
2. 动态权限控制
- 用户权限可能实时变化(如被移除组织标签),但检索结果可能基于历史缓存数据。二次过滤能拦截这类动态权限变更后的越权访问。
3. 最小权限原则
- 系统设计要求用户仅访问最小必要权限范围内的内容。二次过滤确保返回的每个知识片段均严格匹配当前用户的权限状态,避免因排序算法优化导致的权限泄露风险。
4. 技术实现细节
- 在
SearchController中,返回结果前通过OrgTagAuthorizationFilter再次校验每个候选结果的可见性(如公开/私有标签、组织归属),确保最终展示的内容无权限漏洞。
总结
二次权限过滤是安全架构的核心设计,通过"预防+兜底"双重机制,确保在检索效率与数据安全间取得平衡,满足企业级应用对权限控制的严苛要求。
为什么原始文件不保存在mysql数据库中,而是选择文件存储系统?
1. 存储效率与性能
- 数据库限制:MySQL等关系型数据库主要优化结构化数据存储,大文件(如PDF、视频)存入BLOB字段会显著降低数据库性能,增加查询延迟。
- 文件系统优势:MinIO等对象存储专为文件设计,支持高吞吐量、分块传输和CDN加速,适合处理大文件和海量数据。
2. 扩展性与成本
- 数据库扩展瓶颈:MySQL存储空间有限且扩展成本高,而文件存储系统(如MinIO)可弹性扩展,按需付费,更适合企业级海量文件场景。
- 元数据分离:MySQL仅存储文件元数据(如MD5、文件名、大小),保持数据库轻量化,提升查询效率。
3. 数据安全与备份
- 独立备份策略:文件存储系统提供独立的备份、加密和灾备方案(如版本控制、跨区域复制),避免数据库备份时因大文件拖慢整体流程。
- 防篡改:通过MD5哈希校验文件完整性,文件存储系统提供不可篡改的存储特性。
4. 系统架构解耦
- 职责分离:数据库专注结构化数据管理,文件存储专注非结构化数据,符合微服务设计原则,降低模块耦合度。
- 未来扩展性:若需替换文件存储(如迁移至云存储S3),只需调整接口,无需修改数据库结构。
5. 开发与维护成本
- 简化数据库操作:避免大文件导致的数据库锁表、事务超时等问题,减少运维复杂度。
- 标准化接口:文件存储系统提供统一API(如PutObject/GetObject),便于集成和第三方工具调用。
补充说明
系统通过文件ID关联实现元数据与文件的绑定:
- MySQL存储文件ID、MD5等元数据 → 用户通过ID从MinIO获取原始文件。
- 这种设计在保证数据一致性的同时(如通过状态表跟踪文件处理进度),兼顾了性能与灵活性。
相似度得分和关键词匹配度怎么综合排序 排序依据
排序依据
- 语义相似度得分(向量检索结果)
-
- 使用Embedding模型将用户查询和文档块转换为向量,计算余弦相似度。
- 反映查询与内容的语义关联性(如用户问"销售技巧",即使文档无"技巧"一词,也能匹配相关主题)。
- 关键词匹配度(关键词检索结果)
-
- 基于Elasticsearch的倒排索引,精确匹配查询中的关键词/术语。
- 确保高相关性关键词(如产品名称、专有名词)的优先级。
- 综合加权排序
-
- 系统对两种得分进行加权融合(公式示例):
最终得分 = α × 语义相似度 + β × 关键词匹配度
-
- (权重系数α、β在
SearchRequest.java中定义,可通过topK参数调整返回结果数量)。
- (权重系数α、β在
- 权限过滤
-
- 仅保留用户有权限访问的文档(基于组织标签和可见性设置)。
流程示例
- 用户查询:"如何提升销售业绩"
- 系统同时执行:
-
- 语义检索:匹配"客户关系管理""销售策略"等主题文档。
- 关键词检索:匹配包含"销售业绩"的文档。
- 结果按综合得分降序排列,返回前
topK条(如5条)最相关结果。
技术实现
- 核心类:
HybridSearchService.java(混合检索逻辑)、SearchRequest.java(参数配置)。 - 优势:兼顾语义理解与关键词精准性,避免单一检索的局限性。
注:权重系数和topK值可通过配置灵活调整,适应不同场景需求。
对长文本做切块的具体算法是怎么实现的?
根据参考资料,派聪明的长文本分块算法是系统自研实现的,具体流程如下:
分块算法实现细节
- 分块规则 系统采用多维度切分策略,支持三种核心方式:
-
- 按段落切分:以自然段落为边界
- 按字数切分:设定固定长度(如500字符/块)
- 按语义单元切分:结合NLP技术识别语义完整性(需后续优化)
- 分块优化机制
-
- 语义连续性检查:合并语义断裂的相邻块(如段落被意外截断)
- 噪声过滤:自动剔除页眉页脚、图片说明等非正文内容
- 块编号标记:每个分块分配唯一序号,支持原文定位
- 技术实现方式
-
- 使用 Apache Tika 提取纯文本(非分块本身)
- 分块逻辑在业务层通过 Java 自研算法 实现
- 采用循环处理机制逐块解析文本内容
关键区别
- 非框架自带:Elasticsearch等框架仅提供存储和检索能力,分块需自行开发
- 业务定制化:结合企业知识库场景优化切分规则(如保留技术术语完整性)
注:当前版本侧重基础切分,后续规划中提到将优化Prompt构建机制,可能引入更高级的语义分块技术(如LLM辅助分块)。
如果pdf的文档是双栏pdf是否会存在识别错误的问题,如果存在这种文档应该如何进行改进
双栏PDF文档确实存在识别错误问题,主要表现为文字按物理位置排列而非语义顺序,导致段落识别混乱和阅读顺序错误。
改进方法:
- 使用专业文档解析工具替代简单OCR,如基于视觉因果流(Visual Causal Flow)技术的DeepSeek-OCR 2,能按语义而非坐标读图
- 采用文档布局分析工具,如PDF Document Layout Analysis,基于Vision Grid Transformer和LightGBM双模型架构,可高精度识别PDF元素并确定正确顺序
- 在RAG系统中,确保文档解析准确性,避免内容识别错误影响后续检索和生成效果
- 使用支持复杂布局的OCR引擎,如Tesseract或PaddleOCR,它们针对复杂布局有专门优化
这些方法能显著提升双栏PDF的识别准确率,保持原有排版结构和阅读顺序。