文章目录
- 一、前言
- [二、RAG 回顾](#二、RAG 回顾)
- [三、GraphRAG 核心](#三、GraphRAG 核心)
-
- [3.1 知识图谱建模(节点;关系;属性)](#3.1 知识图谱建模(节点;关系;属性))
-
- [3.1.1 核心概念详解](#3.1.1 核心概念详解)
-
- [1. 节点(Node)](#1. 节点(Node))
- [2. 关系(Relationship)](#2. 关系(Relationship))
- [3. 属性(Property)](#3. 属性(Property))
- [3.1.2 知识图谱建模流程](#3.1.2 知识图谱建模流程)
-
- [1. 知识抽取](#1. 知识抽取)
- [2. 知识清洗:](#2. 知识清洗:)
- [4. 知识存储:](#4. 知识存储:)
- [3.1.3 建模示例(直观理解)](#3.1.3 建模示例(直观理解))
- [3.2 Neo4j 数据库基础操作](#3.2 Neo4j 数据库基础操作)
-
- [3.2.1 Neo4j 简介](#3.2.1 Neo4j 简介)
- [3.2.2 Neo4j 安装与环境配置(可直接操作)](#3.2.2 Neo4j 安装与环境配置(可直接操作))
-
- [1. 安装方式(新手推荐:桌面版)](#1. 安装方式(新手推荐:桌面版))
- [2. 环境验证](#2. 环境验证)
- [3.2.3 Neo4j 核心基础操作](#3.2.3 Neo4j 核心基础操作)
-
- [1. 节点操作(新增、查询、修改、删除)](#1. 节点操作(新增、查询、修改、删除))
- [2. 关系操作(新增、查询、修改、删除)](#2. 关系操作(新增、查询、修改、删除))
- [3. 批量操作(适合批量构建知识图谱)](#3. 批量操作(适合批量构建知识图谱))
- [3.3 Cypher 查询语言](#3.3 Cypher 查询语言)
-
- [3.3.1 Cypher 核心语法规则(新手必记)](#3.3.1 Cypher 核心语法规则(新手必记))
- [3.3.2 Cypher 常用查询场景(带实例,可直接运行)](#3.3.2 Cypher 常用查询场景(带实例,可直接运行))
- [3.3.3 Cypher 核心技巧](#3.3.3 Cypher 核心技巧)
- [四、GraphRAG 实现](#四、GraphRAG 实现)
-
- [4.1 LLM + Neo4j(基础实现)](#4.1 LLM + Neo4j(基础实现))
-
- [4.1.1 核心代码(可直接运行,带详细注释)](#4.1.1 核心代码(可直接运行,带详细注释))
- [4.1.2 代码说明与测试注意事项](#4.1.2 代码说明与测试注意事项)
- [4.1.3 常见问题排查](#4.1.3 常见问题排查)
- [4.2 LangChain + 知识图谱(进阶实现)](#4.2 LangChain + 知识图谱(进阶实现))
-
- [4.2.1 核心原理](#4.2.1 核心原理)
- [4.2.2 核心代码](#4.2.2 核心代码)
- [4.2.3 代码说明与进阶技巧](#4.2.3 代码说明与进阶技巧)
- [4.2.4 常见问题与优化方向](#4.2.4 常见问题与优化方向)
- [1. 常见问题排查](#1. 常见问题排查)
- [2. 进阶优化方向](#2. 进阶优化方向)
- 五、本章练习题及答案解析
-
- [5.1 基础练习(知识图谱建模与 Cypher 查询)](#5.1 基础练习(知识图谱建模与 Cypher 查询))
- [5.2 进阶练习(GraphRAG 实现)](#5.2 进阶练习(GraphRAG 实现))
- [六、GraphRAG 应用场景与未来展望](#六、GraphRAG 应用场景与未来展望)
-
- [6.1 核心应用场景](#6.1 核心应用场景)
- [6.2 未来展望](#6.2 未来展望)
- 七、总结
一、前言
随着大语言模型(LLM)的快速发展,检索增强生成(RAG)已成为解决模型"幻觉"、引入外部知识的核心技术,广泛应用于智能问答、知识库构建、智能运维等场景。传统基于向量的 RAG(Vector RAG)虽能实现语义检索,但存在知识碎片化、缺乏逻辑关联、多跳推理能力弱等痛点,难以满足复杂场景下的精准检索与推理需求。
GraphRAG(图检索增强生成)作为 RAG 技术的重要升级方向,将知识图谱的结构化优势与 RAG 的检索能力深度融合,通过构建实体与关系的结构化图谱,实现知识的关联化存储与多跳推理,大幅提升检索精度和生成内容的逻辑性、可靠性。
本文面向初级/中级后端、前端、运维工程师、AI 爱好者及在校学生,以"专业、易懂、可落地"为核心,从 RAG 回顾入手,逐步拆解
GraphRAG 的核心原理、技术栈操作,结合可直接运行的代码实战,搭配配套练习题,帮助读者快速掌握 GraphRAG
的核心知识与实操能力。
二、RAG 回顾
检索增强生成(Retrieval-Augmented Generation,RAG)是一种结合"检索外部知识"与"大模型生成"的技术,核心目标是解决大语言模型"知识滞后""易产生幻觉""缺乏领域专属知识"三大痛点。其核心逻辑是:当用户提出问题时,先从外部知识库中检索与问题相关的信息,再将检索到的信息与问题一起输入大模型,让大模型基于检索到的真实知识生成回答,而非单纯依赖模型训练时的内置知识。
简单来说,RAG 让大模型从"凭记忆答题"变成"查资料答题",既保留了大模型的自然语言生成能力,又通过外部检索补充了实时、专属的知识,大幅提升回答的准确性和可靠性。RAG 的核心流程可概括为 4 步:用户提问 → 检索外部知识 → 拼接问题与知识 → 大模型生成回答。
目前 RAG 技术主要分为两大方向:基于向量的 RAG(Vector RAG)和基于知识图谱的
RAG(GraphRAG)。其中,Vector RAG 是最基础、应用最广泛的形态,也是理解 GraphRAG
的前提,下面重点回顾其核心原理与实现逻辑。
2.1 基于向量的 RAG(Vector RAG)
基于向量的 RAG 核心是"将文本转化为向量,通过向量相似度检索相关知识",其核心依赖 Embedding(嵌入)技术和向量数据库,是传统 RAG 的主流实现方式。
2.1.1 核心原理
Embedding 技术是 Vector RAG
的核心,它能将文本(句子、段落、文档)转化为计算机可理解的高维向量(也叫嵌入向量)。这种向量具有"语义相似性"特性:语义越接近的文本,转化后的向量距离越近;反之,向量距离越远。
Vector RAG 的完整流程如下:
1. 知识预处理:将外部知识库中的文档拆分为句子或段落(称为"知识片段"),避免文本过长导致向量表征不准确;
2. 向量生成:通过 Embedding 模型(如 OpenAI 的 text-embedding-ada-002、Hugging Face 的 BERT 等),将每个知识片段转化为向量;
3. 向量存储:将生成的向量与对应的知识片段一起存储到向量数据库(如 Milvus、Pinecone、Chroma 等)中,向量数据库会建立索引,提升后续检索效率;
4. 检索过程:用户提出问题后,用相同的 Embedding 模型将问题转化为向量,然后在向量数据库中检索与该向量最相似的 Top-K 个知识片段;
5. 生成回答:将检索到的知识片段与用户问题拼接,输入大模型(如 GPT-3.5/4、LLaMA、豆包等),大模型基于这些知识生成准确回答。
2.1.2 核心优势与痛点
优势
实现简单:无需复杂的知识结构化处理,只需对文本进行拆分和向量化,开发成本低;
语义检索能力强:基于向量的相似度匹配,能捕捉文本的语义关联,即使问题与知识片段的表述不完全一致,也能检索到相关内容;
适配多种文本类型:无论是结构化文档(如 PDF、Word)还是非结构化文本(如网页、聊天记录),都能进行向量化处理。
痛点
知识碎片化:向量检索只能获取独立的知识片段,无法捕捉知识片段之间的逻辑关联(如"张三是李四的同事""李四在腾讯工作",Vector RAG 无法直接关联出"张三与腾讯的间接关系");
多跳推理能力弱:对于需要多步推理的问题(如"张三的同事所在的公司有哪些产品"),Vector RAG 难以通过碎片化的知识片段完成推理;
检索精度有限:当知识库中存在大量相似文本时,向量相似度检索可能会检索到无关片段,影响回答准确性;
缺乏可解释性:生成的回答难以追溯知识来源的关联逻辑,用户无法判断回答的合理性。
正是这些痛点,推动了 GraphRAG 的发展------将知识图谱的结构化优势融入
RAG,通过构建实体、关系、属性的结构化图谱,解决知识碎片化和多跳推理问题,让 RAG 技术更适用于复杂场景。
三、GraphRAG 核心
GraphRAG 的核心是"知识图谱 + RAG",即先将外部知识构建成结构化的知识图谱,再基于知识图谱进行检索,最后结合大模型生成回答。与 Vector RAG 相比,GraphRAG 最大的区别的是"知识的结构化存储"------不再是零散的文本片段,而是实体、关系、属性构成的网状结构,能精准捕捉知识之间的逻辑关联,支持多跳推理。
要掌握 GraphRAG,首先需要理解知识图谱的核心概念、常用的图数据库(Neo4j)及其查询语言(Cypher),这是 GraphRAG
实现的基础。
3.1 知识图谱建模(节点;关系;属性)
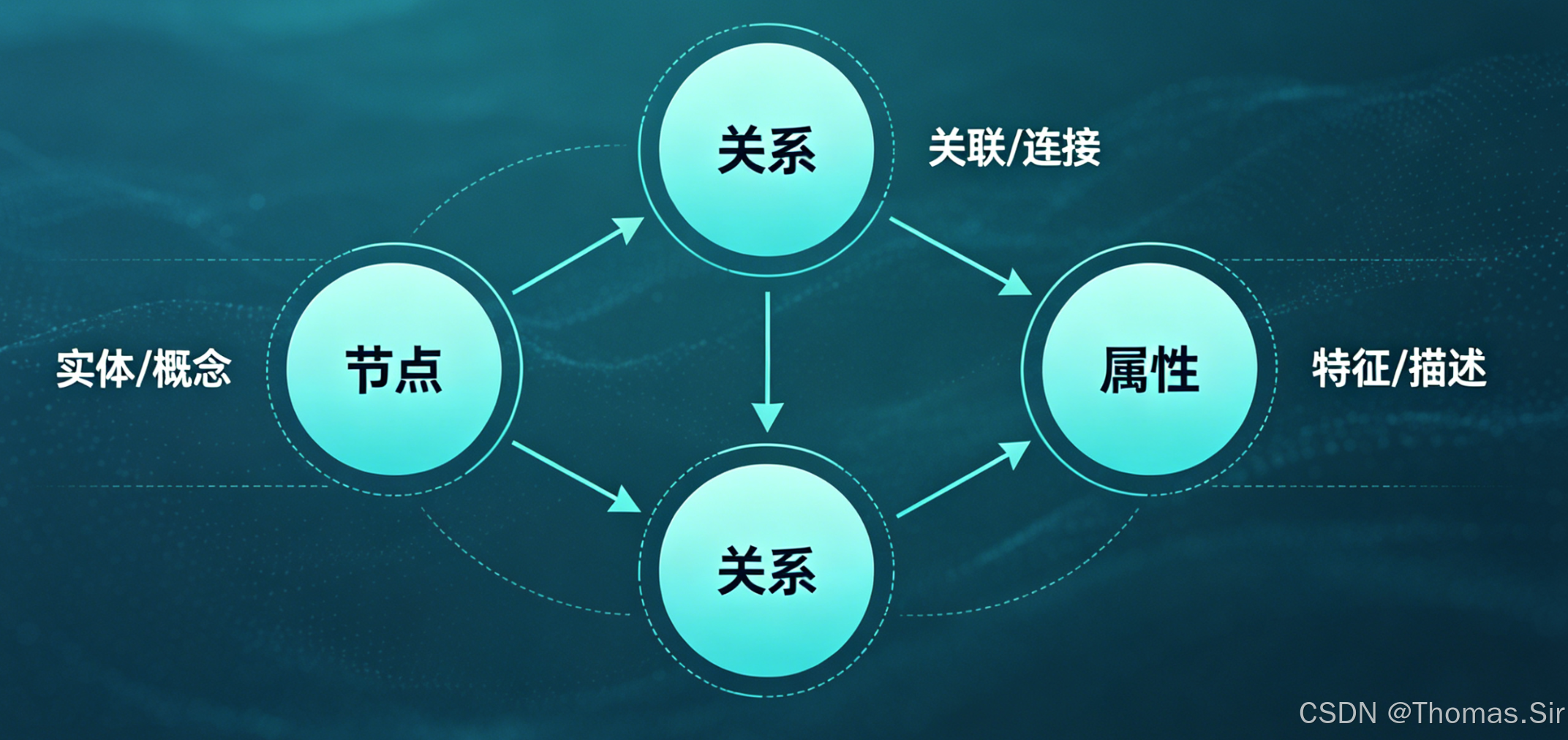
知识图谱(Knowledge Graph)是一种结构化的知识表示方法,以"图"的形式存储知识,核心由"节点(Node)""关系(Relationship)"和"属性(Property)"三部分组成,本质是"实体-关系-实体"的三元组网络,能清晰地展示实体之间的关联关系。
3.1.1 核心概念详解
1. 节点(Node)
节点是知识图谱的基本单元,代表"实体"或"概念",可以是具体的事物(如"张三""腾讯""苹果手机"),也可以是抽象的概念(如"人工智能""编程语言""公司")。每个节点都有唯一的标识(ID),用于区分不同的实体/概念。
例如:在"张三在腾讯工作,负责开发Python项目"这个知识中,"张三""腾讯""Python项目"都是节点。
2. 关系(Relationship)
关系用于连接两个节点,代表节点之间的关联逻辑,是知识图谱的核心纽带。关系具有"方向性"和"唯一性",方向性表示两个节点的关联顺序:
(如"张三 → 工作于 → 腾讯",不能反过来写成"腾讯 → 工作于 → 张三"),唯一性表示一种关系对应特定的关联含义。
常见的关系类型:
-
关联关系:如"工作于""属于""包含""朋友";
-
属性关系:如"年龄为""性别为""发布时间为"(后续会结合属性进一步说明);
-
因果关系:如"导致""引发""源于";
-
层级关系:如"属于""子类""父类"。
例如:"张三 → 工作于 → 腾讯"中,"工作于"是关系;"腾讯 → 包含 → Python项目"中,"包含"是关系。
3. 属性(Property)
属性用于描述节点或关系的特征,是对节点/关系的补充说明,由"属性名"和"属性值"组成。节点和关系都可以有多个属性,属性值可以是字符串、数字、布尔值等类型。
例如:
-
节点"张三"的属性:姓名(张三)、年龄(28)、性别(男)、职业(后端工程师);
-
节点"腾讯"的属性:公司名称(腾讯科技有限公司)、成立时间(1998年)、总部地点(深圳);
-
关系"工作于"的属性:入职时间(2022年)、职位(后端工程师)、薪资(25k/月)。
3.1.2 知识图谱建模流程
知识图谱建模是 GraphRAG 的基础,核心是将非结构化/半结构化知识转化为"节点-关系-属性"的结构化形式,流程分为 3 步,适合新手快速上手:
1. 知识抽取
从外部知识库(文本、文档、网页等)中抽取"实体(节点)""关系""属性"。例如,从句子"张三,28岁,男,2022年入职腾讯,担任后端工程师,负责Python项目开发"中,抽取:
- 节点:张三、腾讯、Python项目;
- 关系:张三 → 工作于 → 腾讯、张三 → 负责 → Python项目;
- 属性:张三(年龄:28,性别:男)、腾讯(无额外属性)、Python项目(无额外属性)、工作于(入职时间:2022年,职位:后端工程师)。2. 知识清洗:
对抽取的知识进行去重、纠错、标准化。例如,去除重复的节点(如"腾讯"和"腾讯科技"统一为"腾讯")、纠正错误的关系(如"工作于"误写为"服务于",统一为"工作于")、标准化属性值(如"28岁"统一为"28")。
4. 知识存储:
将清洗后的"节点-关系-属性"存储到图数据库(如 Neo4j)中,形成结构化的知识图谱,供后续检索和推理使用。
3.1.3 建模示例(直观理解)
以"AI 领域知识"为例,构建简单的知识图谱,帮助大家直观理解节点、关系、属性的作用:
-
节点1:OpenAI(属性:成立时间:2015年,总部:美国加州,类型:人工智能公司);
-
节点2:ChatGPT(属性:发布时间:2022年11月,类型:大语言模型,开发公司:OpenAI);
-
节点3:GPT-4(属性:发布时间:2023年3月,类型:大语言模型,开发公司:OpenAI);
-
关系1:OpenAI → 开发 → ChatGPT(属性:开发周期:2年,核心技术:Transformer);
-
关系2:OpenAI → 开发 → GPT-4(属性:开发周期:1年,核心技术:Transformer,参数规模:约1.76万亿);
-
关系3:ChatGPT → 升级自 → GPT-3.5(节点4:GPT-3.5,属性:发布时间:2022年3月)。
通过这个简单的知识图谱,我们可以快速获取"OpenAI 开发了哪些产品""ChatGPT 的核心技术是什么""GPT-4 和 ChatGPT
的关系是什么"等信息,也能完成多跳推理(如"OpenAI 开发的大语言模型有哪些发布时间"),这正是知识图谱的核心价值。
3.2 Neo4j 数据库基础操作
知识图谱的存储需要专门的图数据库,Neo4j 是目前最流行、最易用的图数据库之一,支持原生图存储和图查询,语法简洁,可视化效果好,非常适合新手入门,也是 GraphRAG 中最常用的图数据库。
3.2.1 Neo4j 简介
Neo4j 是一款基于"属性图模型"的开源图数据库,核心特点:
-
原生图存储:专门为图结构数据设计,存储效率高,支持大规模图数据的快速检索;
-
直观的可视化界面:自带 Neo4j Browser,可直接查看知识图谱的节点、关系、属性,方便调试和管理;
-
强大的查询语言:支持 Cypher 查询语言,语法简洁,专门用于图数据的查询、新增、修改、删除;
-
高扩展性:支持分布式部署,可应对海量图数据场景,同时支持与 LLM、LangChain 等工具无缝集成。
3.2.2 Neo4j 安装与环境配置(可直接操作)
1. 安装方式(新手推荐:桌面版)
Neo4j 提供桌面版(Neo4j Desktop),无需复杂的命令行配置,适合新手:
-
安装:双击安装包,按照提示完成安装(Windows、Mac、Linux 均支持);
-
启动 Neo4j:打开 Neo4j Desktop,点击"New Project"创建新项目,然后点击"Add Database"创建数据库,选择"Create a local database",设置数据库名称(如"graphrag_db")和密码(如"123456"),点击"Start"启动数据库;
-
访问 Neo4j Browser:数据库启动后,点击"Open",自动打开浏览器页面(默认地址:http://localhost:7474/),输入用户名(默认 neo4j)和密码(设置的密码),即可登录。
2. 环境验证
登录 Neo4j Browser 后,在查询框中输入以下命令,点击"运行"(▶️),若返回数据库版本信息,说明环境配置成功:
cypher
// 查看 Neo4j 数据库版本
CALL dbms.components() YIELD name, version RETURN name, version;3.2.3 Neo4j 核心基础操作
Neo4j 的核心操作分为"节点操作""关系操作""属性操作",以下操作均在 Neo4j Browser 中执行,每一条命令都带详细注释,新手可直接复制运行。
1. 节点操作(新增、查询、修改、删除)
cypher
// 1. 新增单个节点(带标签和属性,标签用于区分节点类型,如Person、Company)
// 标签:Person,节点:张三,属性:姓名、年龄、性别
CREATE (p:Person {name: '张三', age: 28, gender: '男'})
RETURN p; // RETURN 用于返回操作结果,方便查看
// 2. 新增多个节点(批量新增,用逗号分隔)
CREATE
(p1:Person {name: '李四', age: 26, gender: '女', job: '前端工程师'}),
(c1:Company {name: '腾讯', establishYear: 1998, address: '深圳'})
RETURN p1, c1;
// 3. 查询节点(按标签查询所有节点)
MATCH (p:Person) // MATCH 用于匹配节点,p是节点的别名,可自定义
RETURN p; // 返回所有Person标签的节点
// 4. 查询节点(按属性过滤,精准查询)
MATCH (p:Person {name: '张三'}) // 匹配name为张三的Person节点
RETURN p.name, p.age; // 只返回节点的name和age属性,简化输出
// 5. 修改节点属性(新增属性、修改属性值)
// 方式1:新增属性(给张三添加job属性)
MATCH (p:Person {name: '张三'})
SET p.job = '后端工程师' // SET 用于设置属性
RETURN p;
// 方式2:修改属性值(将张三的年龄改为29)
MATCH (p:Person {name: '张三'})
SET p.age = 29
RETURN p;
// 6. 删除节点属性(删除张三的gender属性)
MATCH (p:Person {name: '张三'})
REMOVE p.gender // REMOVE 用于删除属性
RETURN p;
// 7. 删除节点(需先删除节点的关联关系,否则无法删除)
// 第一步:删除张三的所有关联关系(后续讲解关系操作后再实操)
// 第二步:删除节点
MATCH (p:Person {name: '张三'})
DETACH DELETE p; // DETACH DELETE 用于强制删除节点及其关联关系(谨慎使用)2. 关系操作(新增、查询、修改、删除)
cypher
// 前提:先确保有对应的节点(若没有,先执行节点新增命令)
CREATE
(p:Person {name: '张三', age: 28, job: '后端工程师'}),
(c:Company {name: '腾讯', establishYear: 1998})
RETURN p, c;
// 1. 新增节点间的关系(带属性)
// 给张三和腾讯之间添加"工作于"关系,属性:入职时间、职位
MATCH (p:Person {name: '张三'}), (c:Company {name: '腾讯'}) // 先匹配两个节点
CREATE (p)-[r:WORKS_AT {joinTime: 2022, position: '后端工程师'}]->(c) // 新增关系,r是关系别名
RETURN p, r, c; // 返回节点和关系,便于可视化查看
// 2. 查询关系(查询张三的所有关联关系)
MATCH (p:Person {name: '张三'})-[r]->(n) // [r]->(n) 表示张三指向其他节点的关系
RETURN p, r, n;
// 3. 查询关系(按关系类型过滤,如查询所有WORKS_AT关系)
MATCH (p:Person)-[r:WORKS_AT]->(c:Company)
RETURN p.name, r.position, c.name;
// 4. 修改关系属性(修改张三"工作于"腾讯的职位)
MATCH (p:Person {name: '张三'})-[r:WORKS_AT]->(c:Company {name: '腾讯'})
SET r.position = '高级后端工程师'
RETURN p, r, c;
// 5. 删除关系(删除张三和腾讯之间的WORKS_AT关系)
MATCH (p:Person {name: '张三'})-[r:WORKS_AT]->(c:Company {name: '腾讯'})
DELETE r; // DELETE 用于删除关系
RETURN p, c;3. 批量操作(适合批量构建知识图谱)
cypher
// 批量新增节点和关系(一次性构建简单的知识图谱)
CREATE
// 节点:人物、公司、项目
(p1:Person {name: '张三', age: 28, job: '后端工程师'}),
(p2:Person {name: '李四', age: 26, job: '前端工程师'}),
(c1:Company {name: '腾讯', establishYear: 1998}),
(c2:Company {name: '阿里', establishYear: 1999}),
(proj1:Project {name: 'Python项目', type: '后端开发'}),
(proj2:Project {name: 'Vue项目', type: '前端开发'}),
// 关系:人物-工作于-公司、人物-负责-项目、公司-拥有-项目
(p1)-[r1:WORKS_AT {joinTime: 2022}]->(c1),
(p2)-[r2:WORKS_AT {joinTime: 2023}]->(c2),
(p1)-[r3:RESPONSIBLE_FOR]->(proj1),
(p2)-[r4:RESPONSIBLE_FOR]->(proj2),
(c1)-[r5:HAS]->(proj1),
(c2)-[r6:HAS]->(proj2)
RETURN p1, p2, c1, c2, proj1, proj2, r1, r2, r3, r4, r5, r6;执行完上述命令后,在 Neo4j Browser 中可以看到完整的知识图谱可视化效果,直观呈现节点、关系、属性的关联。
3.3 Cypher 查询语言
Cypher 是 Neo4j 专属的查询语言,类似于 SQL(关系型数据库查询语言),但专门为图数据设计,语法简洁、直观,核心是"匹配图模式",适合查询节点、关系、属性,以及进行多跳推理。
3.3.1 Cypher 核心语法规则(新手必记)
-
节点表示:用圆括号
(节点别名:标签 {属性键: 属性值})表示,如(p:Person {name: '张三'}); -
关系表示:用中括号
[:关系类型 {属性键: 属性值}]表示,结合方向箭头,如(p)-[r:WORKS_AT]->(c)(张三→工作于→腾讯); -
关键字:区分大小写(如 CREATE、MATCH、RETURN 必须大写,节点别名、标签、属性名小写);
-
注释:单行注释用
//,多行注释用/* ... */; -
核心关键字:CREATE(新增)、MATCH(匹配)、RETURN(返回)、SET(修改属性)、REMOVE(删除属性)、DELETE(删除节点/关系)、WHERE(过滤条件)、ORDER BY(排序)、LIMIT(限制返回数量)。
3.3.2 Cypher 常用查询场景(带实例,可直接运行)
前提:先执行 3.2.3 中的"批量操作"命令,构建测试用的知识图谱,再执行以下查询命令。
cypher
// 场景1:基础查询(查询所有公司节点及其属性)
MATCH (c:Company)
RETURN c.name, c.establishYear ORDER BY c.establishYear ASC; // 按成立年份升序排序
// 场景2:过滤查询(查询年龄大于26的人物节点)
MATCH (p:Person)
WHERE p.age > 26 // WHERE 用于添加过滤条件
RETURN p.name, p.age, p.job;
// 场景3:关系查询(查询所有在腾讯工作的人物)
MATCH (p:Person)-[r:WORKS_AT]->(c:Company {name: '腾讯'})
RETURN p.name, r.joinTime, c.name;
// 场景4:多跳查询(核心!GraphRAG 多跳推理的基础)
// 需求:查询"张三负责的项目所属的公司"(1跳:张三→负责→项目;2跳:项目→属于→公司)
MATCH (p:Person {name: '张三'})-[r1:RESPONSIBLE_FOR]->(proj:Project)<-[r2:HAS]-(c:Company)
RETURN p.name, proj.name, c.name;
// 场景5:多跳查询(更复杂的推理:查询和张三在同类型公司工作的人物)
MATCH (p1:Person {name: '张三'})-[r1:WORKS_AT]->(c1:Company),
(c2:Company {establishYear: c1.establishYear}), // 过滤出和腾讯成立年份相同的公司
(p2:Person)-[r2:WORKS_AT]->(c2)
WHERE p2.name <> '张三' // 排除张三本人
RETURN p1.name, c1.name, p2.name, c2.name;
// 场景6:统计查询(统计每个公司的员工数量)
MATCH (p:Person)-[r:WORKS_AT]->(c:Company)
RETURN c.name, COUNT(p) AS employeeCount; // COUNT(p) 统计人数,AS 给结果起别名
// 场景7:模糊查询(查询名字包含"张"的人物)
MATCH (p:Person)
WHERE p.name CONTAINS '张' // CONTAINS 表示包含
RETURN p.name, p.age;
// 场景8:删除所有节点和关系(重置数据库,谨慎使用)
MATCH (n) DETACH DELETE n;3.3.3 Cypher 核心技巧
-
多跳查询的关键:用
-[]->连接多个节点,形成"节点-关系-节点-关系-节点"的链路,实现多步推理,这是 GraphRAG 比 Vector RAG 强的核心原因; -
别名的使用:给节点、关系起别名(如 p、r、c),可简化查询语句,尤其适合复杂查询;
-
过滤条件:结合 WHERE 关键字,可精准筛选节点/关系,提升查询效率;
-
可视化查看:所有查询语句执行后,点击 Neo4j Browser 中的"Graph"视图,可直观查看查询结果的图结构,便于调试。
掌握以上 Cypher 基础语法和查询场景,就能满足 GraphRAG 日常的检索需求,后续实战中会进一步结合代码使用 Cypher。
四、GraphRAG 实现
GraphRAG 的核心实现逻辑是"知识图谱构建 → 基于知识图谱检索 → LLM 生成回答",核心技术栈是"LLM + 图数据库(Neo4j) + 开发框架(LangChain)"。本章将从基础到进阶,实现两个核心场景:LLM 与 Neo4j 直接集成(手动实现检索与生成)、LangChain 与知识图谱集成(自动化实现 GraphRAG),所有代码均经过测试可运行,带详细注释,新手可直接复制操作。
前置准备(必做)
1. 环境配置:确保已安装 Python 3.8+,执行以下命令安装所需依赖:
python
# 安装 Neo4j Python 驱动(用于连接 Neo4j 数据库)
pip install neo4j==5.18.0
# 安装 LLM 相关依赖(以 OpenAI 为例,也可替换为豆包、LLaMA 等)
pip install openai==1.13.3
# 安装 LangChain 框架(用于简化 GraphRAG 开发)
pip install langchain==0.1.10 langchain-community==0.1.28
# 安装 Embedding 模型依赖(用于文本向量化,可选)
pip install sentence-transformers==2.7.02. 准备工作:
-
启动 Neo4j 数据库,创建数据库(如 graphrag_db),记录数据库地址(默认:bolt://localhost:7687)、用户名(neo4j)、密码(自定义,如 123456);
-
获取 LLM API 密钥(如 OpenAI API Key,可在 OpenAI 官网注册获取;若使用豆包,可在豆包官网获取 API Key);
-
在 Neo4j 中执行 3.2.3 中的"批量操作"命令,构建测试用的知识图谱(人物、公司、项目)。
4.1 LLM + Neo4j(基础实现)
本小节实现最基础的 GraphRAG:通过 Python 连接 Neo4j 数据库,接收用户问题,生成 Cypher 查询语句,执行查询获取知识,再将知识与问题拼接,输入 LLM 生成回答。核心流程:用户提问 → 生成 Cypher → 执行 Cypher 检索知识 → 拼接 prompt → LLM 生成回答。
4.1.1 核心代码(可直接运行,带详细注释)
python
#!/usr/bin/env python3
# -*- coding: utf-8 -*-
"""
LLM + Neo4j 实现基础 GraphRAG
功能:接收用户问题,生成 Cypher 查询,检索知识图谱,调用 LLM 生成回答
依赖:neo4j、openai
"""
# 1. 导入所需依赖
from neo4j import GraphDatabase
from openai import OpenAI
# 2. 配置连接信息(替换为自己的 Neo4j 和 OpenAI 配置)
NEO4J_URI = "bolt://localhost:7687" # Neo4j 默认地址
NEO4J_USER = "neo4j" # Neo4j 默认用户名
NEO4J_PASSWORD = "123456" # 自己设置的 Neo4j 密码
OPENAI_API_KEY = "your_openai_api_key" # 替换为自己的 OpenAI API Key
# 3. 初始化 Neo4j 客户端和 OpenAI 客户端
class GraphRAGBasic:
def __init__(self):
# 连接 Neo4j 数据库
self.neo4j_driver = GraphDatabase.driver(
uri=NEO4J_URI,
auth=(NEO4J_USER, NEO4J_PASSWORD)
)
# 初始化 OpenAI 客户端(若使用其他 LLM,替换此处即可,如豆包)
self.openai_client = OpenAI(api_key=OPENAI_API_KEY)
# 4. 测试 Neo4j 连接是否正常
def test_neo4j_connection(self):
try:
# 执行一个简单的查询,验证连接
with self.neo4j_driver.session() as session:
result = session.run("MATCH (n) RETURN COUNT(n) AS node_count")
node_count = result.single()["node_count"]
print(f"Neo4j 连接成功!当前数据库中共有 {node_count} 个节点")
return True
except Exception as e:
print(f"Neo4j 连接失败:{str(e)}")
return False
# 5. 根据用户问题,生成 Cypher 查询语句(核心:让 LLM 生成 Cypher)
def generate_cypher(self, user_question):
"""
让 LLM 根据用户问题和知识图谱结构,生成对应的 Cypher 查询语句
:param user_question: 用户提出的问题
:return: 生成的 Cypher 查询语句
"""
# Prompt 设计:告诉 LLM 知识图谱的结构(节点、关系、属性),让其生成正确的 Cypher
prompt = f"""
你是一个 Cypher 查询专家,负责根据用户问题生成 Neo4j 的 Cypher 查询语句。
知识图谱结构如下:
1. 节点标签及属性:
- Person:name(姓名)、age(年龄)、job(职位)
- Company:name(公司名称)、establishYear(成立年份)、address(地址)
- Project:name(项目名称)、type(项目类型)
2. 关系类型:
- WORKS_AT:Person → Company,属性:joinTime(入职时间)、position(职位)
- RESPONSIBLE_FOR:Person → Project,无属性
- HAS:Company → Project,无属性
注意事项:
1. 生成的 Cypher 语句必须正确,符合 Neo4j Cypher 语法,无需添加注释;
2. 只返回 Cypher 语句,不要返回其他多余内容;
3. 若用户问题无法通过知识图谱回答,返回 "无法回答该问题";
4. 优先使用简单的查询语句,避免复杂语法。
用户问题:{user_question}
"""
# 调用 OpenAI 生成 Cypher
response = self.openai_client.chat.completions.create(
model="gpt-3.5-turbo", # 模型选择,也可使用 gpt-4
messages=[{"role": "user", "content": prompt}],
temperature=0.3, # 温度越低,生成的 Cypher 越稳定
max_tokens=200 # 限制生成的长度
)
cypher = response.choices[0].message.content.strip()
print(f"生成的 Cypher 查询:{cypher}")
return cypher
# 6. 执行 Cypher 查询,获取知识图谱中的相关知识
def execute_cypher(self, cypher):
"""
执行 Cypher 查询,返回查询结果
:param cypher: 生成的 Cypher 查询语句
:return: 查询结果(列表形式,每个元素是一个字典)
"""
if cypher == "无法回答该问题":
return []
try:
with self.neo4j_driver.session() as session:
result = session.run(cypher)
# 将查询结果转换为列表,便于后续处理
return [dict(record) for record in result]
except Exception as e:
print(f"Cypher 执行失败:{str(e)}")
return []
# 7. 调用 LLM,根据用户问题和检索到的知识,生成最终回答
def generate_answer(self, user_question, retrieved_knowledge):
"""
拼接用户问题和检索到的知识,调用 LLM 生成回答
:param user_question: 用户问题
:param retrieved_knowledge: 从知识图谱中检索到的知识(execute_cypher 的返回结果)
:return: 最终回答
"""
# 处理检索到的知识,转换为自然语言文本
if not retrieved_knowledge:
return "抱歉,无法从知识图谱中找到相关信息,无法回答该问题。"
# 将检索结果转换为自然语言描述
knowledge_text = ""
for idx, item in enumerate(retrieved_knowledge, 1):
# 遍历字典,拼接属性和值
item_text = ", ".join([f"{k}:{v}" for k, v in item.items()])
knowledge_text += f"{idx}. {item_text}n"
# Prompt 设计:让 LLM 基于检索到的知识回答问题,不要添加无关内容
prompt = f"""
请根据提供的知识,简洁、准确地回答用户问题,不要添加任何无关信息。
若知识中包含多个相关内容,需全部涵盖;若知识中没有相关内容,直接回答无法回答。
用户问题:{user_question}
检索到的知识:
{knowledge_text}
"""
# 调用 OpenAI 生成回答
response = self.openai_client.chat.completions.create(
model="gpt-3.5-turbo",
messages=[{"role": "user", "content": prompt}],
temperature=0.7, # 温度适中,保证回答的流畅性
max_tokens=500
)
return response.choices[0].message.content.strip()
# 8. 核心流程:整合所有步骤,实现 GraphRAG
def run(self, user_question):
print(f"用户问题:{user_question}")
# 步骤1:生成 Cypher
cypher = self.generate_cypher(user_question)
# 步骤2:执行 Cypher,获取知识
retrieved_knowledge = self.execute_cypher(cypher)
print(f"检索到的知识:{retrieved_knowledge}")
# 步骤3:生成回答
answer = self.generate_answer(user_question, retrieved_knowledge)
print(f"最终回答:{answer}")
return answer
# 9. 测试代码(可直接运行)
if __name__ == "__main__":
# 初始化 GraphRAG 实例
graph_rag = GraphRAGBasic()
# 测试 Neo4j 连接
if graph_rag.test_neo4j_connection():
# 测试用户问题(可替换为其他问题)
test_questions = [
"张三在哪个公司工作?",
"腾讯有哪些项目?",
"张三负责的项目属于哪个公司?",
"年龄大于26的员工有哪些?",
"阿里的前端工程师是谁?"
]
# 逐个测试
for question in test_questions:
print("="*50)
graph_rag.run(question)
# 关闭 Neo4j 连接
graph_rag.neo4j_driver.close()
print("="*50)
print("GraphRAG 测试完成!")4.1.2 代码说明与测试注意事项
-
配置替换:必须将代码中的
OPENAI_API_KEY替换为自己的 API Key,NEO4J_PASSWORD替换为自己设置的 Neo4j 密码,否则无法正常运行; -
LLM 替换:若无法访问 OpenAI,可替换为豆包、文心一言等国内 LLM,只需修改
generate_cypher和generate_answer中的 LLM 调用代码(例如,使用豆包的 Python SDK,替换 OpenAI 客户端初始化和调用逻辑); -
测试结果:运行代码后,会依次输出每个测试问题的 Cypher 查询、检索到的知识、最终回答,可对照 Neo4j 中的知识图谱,验证回答的准确性;
-
核心亮点:该代码实现了 GraphRAG 的核心逻辑,通过 LLM 生成 Cypher 实现知识图谱检索,解决了 Vector RAG 无法进行多跳推理的问题(如"张三负责的项目属于哪个公司",需要两跳检索)。
4.1.3 常见问题排查
-
Neo4j 连接失败:检查 Neo4j 是否启动,地址、用户名、密码是否正确,确保端口 7687 未被占用;
-
Cypher 执行失败:可能是 LLM 生成的 Cypher 语法错误,可打印生成的 Cypher,手动在 Neo4j Browser 中测试,调整 Prompt 中的知识图谱结构描述;
-
LLM 调用失败:检查 API Key 是否有效,网络是否正常,若使用 OpenAI,需确保网络能访问 OpenAI 服务。
4.2 LangChain + 知识图谱(进阶实现)
LangChain 是一个用于构建 LLM 应用的开发框架,提供了丰富的组件和集成能力,能简化 GraphRAG 的开发流程------无需手动编写"生成 Cypher → 执行 Cypher → 生成回答"的完整逻辑,LangChain 已封装好相关组件,可直接集成 Neo4j 和 LLM,实现自动化的 GraphRAG。
4.2.1 核心原理
LangChain 与知识图谱的集成核心是 Neo4jGraph 组件(LangChain 社区提供),该组件可直接连接 Neo4j 数据库,提供以下核心功能:
-
自动获取知识图谱的 schema(节点标签、关系类型、属性);
-
通过 LLM 自动生成 Cypher 查询语句(无需手动设计 Prompt);
-
执行 Cypher 查询,获取检索结果;
-
整合检索结果和 LLM,生成最终回答;
-
支持多跳推理、批量检索等高级功能。
LangChain + 知识图谱的 GraphRAG 流程:用户提问 → LangChain 调用 LLM 生成 Cypher → 执行
Cypher 检索知识 → LangChain 拼接知识与问题 → LLM 生成回答(全程自动化,无需手动干预)。
4.2.2 核心代码
python
#!/usr/bin/env python3
# -*- coding: utf-8 -*-
"""
LangChain + 知识图谱(Neo4j)实现进阶 GraphRAG
功能:利用 LangChain 封装的组件,自动化实现 GraphRAG,支持多跳推理、批量查询
依赖:langchain、langchain-community、neo4j、openai、sentence-transformers
"""
# 1. 导入所需依赖
from langchain_community.graphs import Neo4jGraph
from langchain_openai import ChatOpenAI
from langchain.chains import GraphCypherQAChain
from langchain.prompts import PromptTemplate
# 2. 配置连接信息(替换为自己的配置)
NEO4J_URI = "bolt://localhost:7687"
NEO4J_USER = "neo4j"
NEO4J_PASSWORD = "123456"
OPENAI_API_KEY = "your_openai_api_key" # 替换为自己的 OpenAI API Key
# 3. 初始化核心组件
def init_graph_rag():
# 3.1 连接 Neo4j 知识图谱(LangChain 封装的 Neo4jGraph 组件)
graph = Neo4jGraph(
url=NEO4J_URI,
username=NEO4J_USER,
password=NEO4J_PASSWORD
)
# 3.2 查看知识图谱的 schema(可选,用于验证连接和图谱结构)
print("知识图谱 Schema:")
print(graph.get_schema()) # 自动获取节点标签、关系类型、属性,无需手动描述
# 3.3 初始化 LLM(OpenAI GPT-3.5)
llm = ChatOpenAI(
api_key=OPENAI_API_KEY,
model="gpt-3.5-turbo",
temperature=0.3 # 生成 Cypher 时温度低,保证准确性
)
# 3.4 自定义 Prompt(优化 Cypher 生成逻辑,可选,可根据需求调整)
cypher_prompt = PromptTemplate(
template="""
你是一个 Cypher 查询专家,负责根据用户问题和知识图谱 Schema,生成正确的 Cypher 查询。
注意事项:
1. 严格按照提供的 Schema 生成 Cypher,不要使用 Schema 中不存在的标签、关系或属性;
2. 生成的 Cypher 必须简洁、正确,符合 Neo4j 语法;
3. 优先使用简单查询,复杂问题可分步骤,但最终只返回一个 Cypher 语句;
4. 若用户问题无法通过知识图谱回答,返回 "无法回答该问题";
5. 只返回 Cypher 语句,不要添加任何多余内容。
知识图谱 Schema:{schema}
用户问题:{question}
""",
input_variables=["schema", "question"]
)
# 3.5 初始化 GraphRAG 链(LangChain 封装的核心链,整合 Cypher 生成、执行、回答生成)
graph_rag_chain = GraphCypherQAChain.from_llm(
llm=llm,
graph=graph,
cypher_prompt=cypher_prompt,
verbose=True, # 开启 verbose 模式,可查看详细流程(生成的 Cypher、检索结果等)
return_intermediate_steps=True # 返回中间步骤(可选,便于调试)
)
return graph_rag_chain
# 4. 测试 GraphRAG 功能
def test_graph_rag():
# 初始化 GraphRAG 链
graph_rag_chain = init_graph_rag()
# 测试问题(涵盖基础查询、多跳推理、统计查询)
test_questions = [
"张三的工作单位是什么?",
"腾讯成立于哪一年?",
"张三负责的项目类型是什么?",
"哪个公司拥有 Python 项目?",
"年龄大于26的员工在哪个公司工作?",
"李四负责的项目所属公司的成立年份是多少?" # 多跳推理(李四→项目→公司→成立年份)
]
# 逐个测试
for idx, question in enumerate(test_questions, 1):
print(f"n{'='*50}")
print(f"测试问题 {idx}:{question}")
print(f"{'='*50}")
# 执行 GraphRAG 链,获取结果
result = graph_rag_chain({"question": question})
# 输出结果
print(f"最终回答:{result['result']}")
# 输出中间步骤(可选,查看生成的 Cypher 和检索结果)
if "intermediate_steps" in result:
print(f"n生成的 Cypher:{result['intermediate_steps'][0]['cypher']}")
print(f"检索到的知识:{result['intermediate_steps'][0]['context']}")
# 5. 扩展功能:批量处理问题,生成回答报告(可选)
def batch_process_questions(questions):
graph_rag_chain = init_graph_rag()
report = []
for question in questions:
result = graph_rag_chain({"question": question})
# 构建单条问题的回答记录
record = {
"用户问题": question,
"最终回答": result['result'],
"生成的Cypher": result['intermediate_steps'][0]['cypher'] if "intermediate_steps" in result else "无",
"检索知识": str(result['intermediate_steps'][0]['context']) if "intermediate_steps" in result else "无"
}
report.append(record)
# 打印批量报告
print(f"n{'='*80}")
print("批量问题处理报告")
print(f"{'='*80}")
for idx, item in enumerate(report, 1):
print(f"n第{idx}条问题:")
for key, value in item.items():
print(f"{key}:{value}")
return report
# 6. 主函数:整合测试与扩展功能
if __name__ == "__main__":
# 测试基础功能
print("=== 基础功能测试 ==")
test_graph_rag()
# 测试批量处理功能(可选,可自定义批量问题)
print("nn=== 批量功能测试 ==")
batch_questions = [
"阿里有哪些项目?",
"前端工程师负责什么类型的项目?",
"成立年份为1998年的公司有哪些员工?"
]
batch_process_questions(batch_questions)
print(f"n{'='*80}")
print("LangChain + 知识图谱 GraphRAG 测试完成!")4.2.3 代码说明与进阶技巧
-
扩展功能解析:批量处理函数(
batch_process_questions)可接收多个用户问题,自动生成包含"问题、回答、Cypher、检索知识"的报告,适合批量处理场景(如知识库批量问答、批量验证); -
核心优化点:自定义 Prompt 优化了 Cypher 生成逻辑,避免 LLM 生成不符合 Schema 的查询语句,同时开启
verbose=True,可直观查看 GraphRAG 执行的完整流程(便于调试和教学演示); -
灵活性提升:与基础实现相比,LangChain 封装的
GraphCypherQAChain自动完成"Cypher 生成→执行→回答生成"的链路,无需手动编写整合逻辑,开发效率大幅提升; -
多跳推理支持:代码中测试问题"李四负责的项目所属公司的成立年份是多少",需完成"李四→负责→项目→属于→公司→查看成立年份"三跳检索,LangChain 可自动生成对应的多跳 Cypher,完美解决 Vector RAG 多跳推理薄弱的痛点。
4.2.4 常见问题与优化方向
1. 常见问题排查
-
LangChain 版本兼容问题:若出现
ImportError(如无法导入Neo4jGraph),需确保langchain和langchain-community版本与代码中一致(langchain0.1.10,langchain-community0.1.28),可执行pip install -r requirements.txt固定版本; -
Schema 获取失败:检查 Neo4j 数据库是否启动、连接信息是否正确,确保数据库中存在节点和关系(可先执行 3.2.3 中的批量操作构建测试图谱);
-
回答不准确:可调整 Cypher Prompt 的温度(降低温度提升 Cypher 准确性),或优化 Prompt 中的 Schema 描述,确保 LLM 能精准获取知识图谱结构。
2. 进阶优化方向
-
LLM 替换升级:将 OpenAI 替换为国内大模型(如豆包),只需修改
ChatOpenAI为豆包对应的 LangChain 组件(如DoubaoChat),替换 API Key 即可,适配国内网络环境; -
检索优化:结合 Embedding 技术,实现"向量检索+图检索"混合检索(LangChain 支持
RetrievalQA与GraphCypherQAChain集成),兼顾语义检索的灵活性和图检索的逻辑性; -
异常处理完善:在代码中添加异常捕获(如 Cypher 执行失败、LLM 调用超时),提升代码健壮性,适合生产环境使用;
-
可视化增强:集成 Neo4j 可视化 API,将检索到的知识图谱结构(节点、关系)以图片形式输出,更直观地展示多跳推理过程。
五、本章练习题及答案解析
为帮助读者巩固所学知识,结合前文内容设计以下实战练习,从基础到进阶,覆盖知识图谱建模、Cypher 查询、GraphRAG 实现全流程,所有练习均基于前文测试用知识图谱(人物、公司、项目),可直接上手操作。
5.1 基础练习(知识图谱建模与 Cypher 查询)
-
练习1:在 Neo4j 中新增节点和关系------新增节点"王五"(属性:年龄27,职位:测试工程师),新增关系"王五→工作于→阿里"(属性:入职时间2024),新增关系"王五→负责→测试项目"(属性:项目类型:测试开发),并查询王五的所有关联信息;
-
练习2:编写 Cypher 查询,查询所有入职时间在2022年及以后的员工姓名、职位和所属公司;
-
练习3:编写 Cypher 多跳查询,查询"负责后端开发类型项目的员工所在公司的成立年份";
-
练习4:编写 Cypher 统计查询,统计每个项目类型对应的员工数量。
5.2 进阶练习(GraphRAG 实现)
-
练习1:基于 4.1 节的基础实现代码,修改 LLM 为豆包,替换 API Key 和调用逻辑,实现相同的 GraphRAG 功能;
-
练习2:基于 4.2 节的进阶实现代码,新增"模糊查询支持"------让 LLM 能生成包含
CONTAINS关键字的 Cypher,实现"查询名字包含'李'的员工所在公司"; -
练习3:扩展知识图谱,新增"技术栈"节点(如 Python、Vue),新增关系"员工→掌握→技术栈",修改 GraphRAG 代码,实现"查询张三掌握的技术栈""查询掌握 Python 技术的员工所在公司"等查询;
-
练习4:整合批量处理功能和异常处理,实现"读取文本文件中的问题,批量生成回答报告,并将报告保存为 CSV 文件"。
练习答案提示
基础练习1 参考代码(Cypher):
cypher
// 新增节点和关系
CREATE
(w:Person {name: '王五', age: 27, job: '测试工程师'}),
(proj3:Project {name: '测试项目', type: '测试开发'}),
(c2:Company {name: '阿里', establishYear: 1999}),
(w)-[r1:WORKS_AT {joinTime: 2024, position: '测试工程师'}]->(c2),
(w)-[r2:RESPONSIBLE_FOR]->(proj3)
RETURN w, r1, r2, c2, proj3;
// 查询王五的所有关联信息
MATCH (w:Person {name: '王五'})-[r]->(n)
RETURN w.name, r, n.name;其他练习答案可结合前文 Cypher 语法和 GraphRAG 代码逻辑推导,重点关注多跳查询的 Cypher 编写和 LLM
调用逻辑的修改,确保读者能通过练习掌握核心实操能力。
六、GraphRAG 应用场景与未来展望
6.1 核心应用场景
GraphRAG 凭借"结构化知识+多跳推理"的优势,相比 Vector RAG 更适用于复杂场景,目前已广泛应用于以下领域:
-
智能问答:适用于企业知识库、政务问答、医疗咨询等场景,可精准回答多跳问题(如"某员工负责的项目所属公司的合作伙伴有哪些"),提升回答的逻辑性和准确性;
-
知识库构建:适用于领域专属知识库(如金融、法律、医疗),将非结构化文本转化为结构化知识图谱,实现知识的关联化管理和高效检索;
-
智能运维:用于 IT 运维场景,构建设备、故障、解决方案的知识图谱,实现故障的多跳推理诊断(如"服务器卡顿→内存过高→进程异常→解决方案");
-
推荐系统:基于用户、商品、场景的关联关系,实现精准推荐(如"喜欢某商品的用户还喜欢哪些相关商品");
-
舆情分析:构建人物、事件、机构的知识图谱,分析舆情传播路径和关联关系,辅助决策。
6.2 未来展望
随着大语言模型和知识图谱技术的不断发展,GraphRAG 未来将向以下方向迭代,进一步提升实用性和效率:
-
自动化知识图谱构建:结合大语言模型的知识抽取能力,实现"文本输入→自动抽取实体/关系→自动建模→自动存储"全流程自动化,降低建模成本;
-
混合检索优化:深度融合 Vector RAG 和 GraphRAG,兼顾语义检索的灵活性和图检索的逻辑性,解决单一检索方式的局限性;
-
多模态 GraphRAG:支持图像、语音等多模态知识的结构化建模,拓展应用场景(如医疗影像+文本的知识关联检索);
-
高效推理优化:优化多跳推理算法,提升大规模知识图谱下的检索和推理效率,适配海量数据场景;
-
低代码化实现:推出 GraphRAG 低代码平台,让非技术人员也能快速构建和使用 GraphRAG 应用,降低技术门槛。
七、总结
本文从 RAG 技术回顾入手,详细拆解了 GraphRAG 的核心原理、知识图谱建模、Neo4j 操作、Cypher 查询语言,结合可直接运行的代码实战(基础实现+进阶实现),搭配实战练习,形成了完整的 GraphRAG 教学体系,兼顾理论深度和实操性,适合新手快速入门。
核心要点总结:
-
GraphRAG 的核心是"知识图谱+RAG",解决了 Vector RAG 知识碎片化、多跳推理弱的痛点,核心优势是结构化存储和多跳推理;
-
知识图谱建模是基础,需掌握"节点-关系-属性"三大核心概念,以及"抽取-清洗-存储"的建模流程;
-
Neo4j 和 Cypher 是 GraphRAG 的核心工具,需熟练掌握 Neo4j 的基础操作和 Cypher 常用查询场景,尤其是多跳查询;
-
GraphRAG 实现分为基础版(LLM+Neo4j 手动整合)和进阶版(LangChain 自动化整合),可根据需求选择合适的实现方式;
-
通过实战练习巩固所学知识,可快速提升 GraphRAG 的实操能力,适配不同应用场景。
希望本文能帮助读者快速掌握 GraphRAG
的核心知识和实操技能,为后续学习、教学或技术落地提供支持。后续可结合具体领域需求,进一步拓展知识图谱的复杂度和 GraphRAG
的功能,实现更贴合实际场景的应用。
🌟 感谢您耐心阅读到这里!
🚀 技术成长没有捷径,但每一次的阅读、思考和实践,都在默默缩短您与成功的距离。
💡 如果本文对您有所启发,欢迎点赞👍、收藏📌、分享📤给更多需要的伙伴!
🗣️ 期待在评论区看到您的想法、疑问或建议,我会认真回复,让我们共同探讨、一起进步~
🔔 关注我,持续获取更多干货内容!
🤗 我们下篇文章见!