前言
生成式 AI 的发展历经了几个重要阶段。早期的序列到序列(Seq2Seq)自回归模型、基于对抗博弈的生成对抗网络(GAN)、具备严格数学可逆性的流模型(Flow),以及变分自编码器(VAE)都曾各领风骚。GAN 它通过生成器和判别器的博弈虽然能生成逼真图像,但往往面临训练极其不稳定以及"无脑取平均"的问题,即模型为了迎合所有特征,可能会生成模糊、单一且四不像的图像。为了解决这些问题,扩散模型应运而生。它最早源于 2015 年一篇基于非平衡热力学的论文,应该在 2020 年经典的 DDPM(去噪扩散概率模型)论文发表后,真正迎来了大爆发。本文将记录复现 image-restoration-sde 过程,IR-SDE 含金量:IR-SDE 的 Refusion 是 NTIRE 2023 图像去阴影挑战赛的获胜(冠军)
论文地址:https://arxiv.org/pdf/2301.11699
代码地址:https://github.com/Algolzw/image-restoration-sde
目录
- 前言
- 扩散模型
-
- 📌前向扩散(加噪)过程
- 逆向去噪(生成)过程
- [📌SDE 的扩散模型概念](#📌SDE 的扩散模型概念)
-
- [1. 正向扩散过程(Forward SDE)](#1. 正向扩散过程(Forward SDE))
- [2. 反向时间生成过程(Reverse-time SDE)](#2. 反向时间生成过程(Reverse-time SDE))
- [📌IR-SDE 的扩散模型概念](#📌IR-SDE 的扩散模型概念)
-
- [1. IR-SDE正向扩散过程](#1. IR-SDE正向扩散过程)
- [2. IR-SDE逆向扩散过程](#2. IR-SDE逆向扩散过程)
- 服务器训练
-
- 👉数据集下载
- 👉预训练模型下载
- 👉服务器训练
-
- [☑️ 镜像环境](#☑️ 镜像环境)
- [☑️ 快速上手](#☑️ 快速上手)
- [☑️ 激活环境与切换工作目录](#☑️ 激活环境与切换工作目录)
- 👉image-restoration-sde复现前提
- 👉TensorBoard
- 评价指标
-
-
-
- [1. 峰值信噪比(PSNR)](#1. 峰值信噪比(PSNR))
- [2. 结构相似性指数(SSIM)](#2. 结构相似性指数(SSIM))
- [3. 学习感知图像块相似度(LPIPS)](#3. 学习感知图像块相似度(LPIPS))
- [4.FID 计算公式](#4.FID 计算公式)
-
-
- 图像修复系统的设计与实现
扩散模型
📌前向扩散(加噪)过程
前向扩散是一个纯粹的、不含可训练参数的数学马尔可夫链过程。给定一张清晰的原始图片,我们在设定的总时间步(例如1000步)内,逐步向图像中注入少量的高斯噪声。控制噪声注入量的是一个超参数 β t \beta_t βt,它通常在0到1之间,并且随着时间步的增加而逐渐变大,直到图像彻底变成各项同性、毫无意义的高斯噪声。
如果不加优化,我们需要一步步迭代计算。但利用数学上的"重参数化技巧(Reparameterization Trick)",我们可以直接从第0步的原始图像推导出任意时刻 t t t 的带噪图像状态。重参数化技巧的核心在于,将原本不可导的随机采样操作,转化为一个常数与标准正态分布变量相乘再相加的线性组合,这就保证了网络梯度的顺利传导。通过定义 α t = 1 − β t \alpha_t = 1 - \beta_t αt=1−βt 并利用两个高斯分布叠加后依然是高斯分布的数学性质,我们一跃得出了任意时刻图像解析解的均值与方差,从而摆脱了一步步迭代的计算负担。
逆向去噪(生成)过程
从噪声生成数据是非常困难的,也就是说逆向过程则是要从纯噪声中"无中生有",恢复出有序的图像分布。👉 这个"逆向过程"本质上就是一个生成模型(Generative Model)。
数学上,给定第 t t t 步的图像,预测第 t − 1 t-1 t−1 步状态的逆过程同样也可以被假设为一个高斯分布。然而,纯噪声是随机的,我们无法直接用写死的数学公式反推,这就必须借助深度神经网络(早期通常是U-Net、GAN)去充当函数拟合器。此时优化的目标是最大化数据的对数似然,在推导目标函数时,它与多层 VAE 非常相似,我们通过优化"变分下界(ELBO)",实际上是在最小化逆过程神经网络预测的高斯分布与真实的后验高斯分布之间的KL散度。经过数学上的优雅化简,特别是当方差被设定为常数时,这个复杂的分布距离优化,最终化简为了一个极简的均方误差(MSE)损失函数:即只要让神经网络努力去预测每一步实际添加的噪声,模型就间接掌握了剥离噪声、还原图像规律的能力。
📌SDE 的扩散模型概念
基于 SDE(随机微分方程)的扩散模型主要包含以下两个核心的计算公式:
1. 正向扩散过程(Forward SDE)
该公式定义了将初始数据分布逐渐转换为固定高斯噪声的过程:
d x = f ( x , t ) d t + g ( t ) d w , x ( 0 ) ∼ p 0 ( x ) dx = f(x, t)dt + g(t)dw, x(0) \sim p_0(x) dx=f(x,t)dt+g(t)dw,x(0)∼p0(x)
参数解释:
- p 0 ( x ) p_0(x) p0(x):代表数据的初始分布。
- t ∈ 0 , T t \in 0, T t∈0,T:表示连续时间变量。
- f ( x , t ) f(x, t) f(x,t):漂移函数(drift function)。
- g ( t ) g(t) g(t):扩散函数(diffusion function)。
- w w w:标准维纳过程(standard Wiener process)。
总体思路是设计这样一个 SDE,将数据分布逐渐转换为固定的高斯噪声 (宋等人,2021c;卢等人,2022;德博托利等人,2022)。
2. 反向时间生成过程(Reverse-time SDE)
该公式展示了通过在时间上向后模拟 SDE,从而从噪声中采样生成数据的反转过程:
d x = f ( x , t ) − g ( t ) 2 ∇ x log p t ( x ) d t + g ( t ) d w ˉ dx = f(x, t) - g(t)\^2 \\nabla_x \\log p_t(x)dt + g(t)d\bar{w} dx=f(x,t)−g(t)2∇xlogpt(x)dt+g(t)dwˉ
参数解释:
- x ( T ) ∼ p T ( x ) x(T) \sim p_T(x) x(T)∼pT(x):终端状态,通常遵循具有固定均值和方差的高斯分布。
- w ˉ \bar{w} wˉ:反向时间维纳过程。
- p t ( x ) p_t(x) pt(x):表示 x ( t ) x(t) x(t) 在时间 t t t 的边缘概率密度函数。
- ∇ x log p t ( x ) \nabla_x \log p_t(x) ∇xlogpt(x):得分函数(score function)。由于其通常难以直接处理,在基于 SDE 的扩散模型中,会通过"得分匹配目标"下训练一个与时间相关的神经网络 s θ ( x , t ) s_\theta(x, t) sθ(x,t) 来近似逼近它。
其中 x ( T ) ∼ p T ( x ) x(T) \sim p_T(x) x(T)∼pT(x)。这里, w ˉ \bar{w} wˉ 是反向时间维纳过程, p t ( x ) p_t(x) pt(x) 表示 x ( t ) x(t) x(t) 在时间 t t t 的边际概率密度函数。得分函数 ∇ x log p t ( x ) \nabla_x \log p_t(x) ∇xlogpt(x) 通常难以处理,因此基于 SDE 的扩散模型通过在所谓的得分匹配目标下训练与时间相关的神经网络 s θ ( x , t ) s_\theta(x, t) sθ(x,t) 来近似它(海瓦林,2005;宋等人,2021c)。
📌IR-SDE 的扩散模型概念
IR-SDE(Image Restoration SDE)是在基于标准的 SDE(如 Score-SDE)上进行改进的。
1. IR-SDE正向扩散过程
示意图如下:


计算公式如下:
d x = θ t ( μ − x ) d t + σ t d w dx = \theta_t (\mu - x)dt + \sigma_t dw dx=θt(μ−x)dt+σtdw
在这里, μ \mu μ 就是低质量图像(比如你数据集里的 LR_bicubic_X4 模糊图),而 x ( 0 ) x(0) x(0) 是清晰的高质量图像。 θ t \theta_t θt 代表均值回复速度, σ t \sigma_t σt 是随机波动率。
为了让方程有解,作者设定了 σ t 2 / θ t = 2 λ 2 \sigma_t^2 / \theta_t = 2\lambda^2 σt2/θt=2λ2。推导后,任意时刻 t t t 的状态分布 p t ( x ) p_t(x) pt(x) 是一个高斯分布,其均值和方差分别为: m t ( x ) = μ + ( x ( 0 ) − μ ) e − θ ˉ t m_t(x) = \mu + (x(0) - \mu)e^{-\bar{\theta}_t} mt(x)=μ+(x(0)−μ)e−θˉt v t = λ 2 ( 1 − e − 2 θ ˉ t ) v_t = \lambda^2(1 - e^{-2\bar{\theta}_t}) vt=λ2(1−e−2θˉt)核心物理意义: 仔细看这个均值公式,当时间 t → ∞ t \to \infty t→∞ 时, e − θ ˉ t e^{-\bar{\theta}_t} e−θˉt 趋近于 0,此时均值 m t m_t mt 就完美收敛到了低质量图像 μ \mu μ!这就是所谓的"均值回复"------正向扩散的终点不再是虚无的纯噪声,而是你输入的模糊图片。
2. IR-SDE逆向扩散过程
示意图如下:


知道了怎么变模糊,接下来就是让神经网络学习怎么变清晰。反向 SDE 方程:根据数学定理,要从终端状态(带噪的模糊图)恢复出清晰图,需要求解反向 SDE:
d x = θ t ( μ − x ) − σ t 2 ∇ x log p t ( x ) d t + σ t d w ˉ dx = \\theta_t (\\mu - x) - \\sigma_t\^2 \\nabla_x \\log p_t(x)dt + \sigma_t d\bar{w} dx=θt(μ−x)−σt2∇xlogpt(x)dt+σtdwˉ
得分匹配与参数重整化(极简替换):反向方程里唯一未知的就是得分函数 ∇ x log p t ( x ) \nabla_x \log p_t(x) ∇xlogpt(x)。作者利用参数重整化技巧,令 ϵ t ∼ N ( 0 , I ) \epsilon_t \sim \mathcal{N}(0, I) ϵt∼N(0,I),直接将复杂的得分函数简化为了极度优雅的形式: ∇ x log p t ( x ∣ x ( 0 ) ) = − ϵ t v t \nabla_x \log p_t(x | x(0)) = -\frac{\epsilon_t}{\sqrt{v_t}} ∇xlogpt(x∣x(0))=−vt ϵt
这意味着,网络不需要去拟合什么复杂的偏导数,它只需要去预测加入的那一点点纯高斯噪声 ϵ t \epsilon_t ϵt 就行了。最终的训练目标 (Loss 函数):一切高深的数学推导,最后都落地到了这个极其朴素的训练目标上: L γ ( ϕ ) : = ∑ i = 1 T γ i E ∣ ∣ ϵ ˉ ϕ ( x i , μ , i ) − ϵ i ∣ ∣ L_\gamma(\phi) := \sum_{i=1}^T \gamma_i \mathbb{E}\|\|\\bar{\\epsilon}_\\phi(x_i, \\mu, i) - \\epsilon_i\|\| Lγ(ϕ):=i=1∑TγiE∣∣ϵˉϕ(xi,μ,i)−ϵi∣∣
这行公式解释了你代码里的一切:网络 ϵ ˉ ϕ \bar{\epsilon}_\phi ϵˉϕ 接收当前状态 x i x_i xi、退化条件 μ \mu μ 和时间步 i i i,然后输出预测的噪声。用预测的噪声减去真实的噪声 ϵ i \epsilon_i ϵi,求个绝对值或平方误差就行了。
服务器训练
下载源码
解压
👉数据集下载
DIV2K 数据集下载链接: https://data.vision.ee.ethz.ch/cvl/DIV2K

- High Resolution Images (HR) :
- 意思:高清原图。
- 用途 :这是 Ground Truth (GT),即模型学习的目标。
- Low Resolution Images (LR) :
- 意思:低分辨率图。
- 用途:模型输入。模型要学习如何把这张图变回上面的 HR 图。
- Bicubic downscaling (x2, x3, x4) :
- 意思:使用双三次插值算法进行的缩放。
- x2/x3/x4 :代表缩小的倍数。x4 是学术论文中最常用的标准。
- Track 1 vs Track 2 :
- Track 1:标准的数学缩放,比较简单。
- Track 2 (Unknown):使用了复杂的、未知的退化方式(可能带点模糊或噪声),更难。
解压如下图所示:
由于数据集比较大,我训练集我删除了几百张,留下 108 张,处理的脚本如下:
python
# -*- coding: utf-8 -*-
"""
@Auth :落花不写码
@File :删除数据集.py
@Motto :学习新思想,争做新青年
"""
import os
def shrink_dataset(hr_dir, lr_dir, num_to_keep, lr_suffix="x4"):
hr_files = sorted([f for f in os.listdir(hr_dir) if f.endswith('.png')])
lr_files = sorted([f for f in os.listdir(lr_dir) if f.endswith('.png')])
keep_hr = hr_files[:num_to_keep]
keep_lr = [f.replace(".png", f"{lr_suffix}.png") for f in keep_hr]
deleted_hr = 0
for f in hr_files:
if f not in keep_hr:
os.remove(os.path.join(hr_dir, f))
deleted_hr += 1
deleted_lr = 0
for f in lr_files:
if f not in keep_lr:
os.remove(os.path.join(lr_dir, f))
deleted_lr += 1
print(f"HR 文件夹:保留了 {len(keep_hr)} 张,删除了 {deleted_hr} 张")
print(f"LR 文件夹:保留了 {len(keep_lr)} 张,删除了 {deleted_lr} 张")
if __name__ == "__main__":
HR_PATH = r"E:\5-dataset\image_restoration\DIV2K_valid_HR"
LR_PATH = r"E:\5-dataset\image_restoration\DIV2K_valid_LR_bicubic\X4"
COUNT = 108
SUFFIX = "x4"
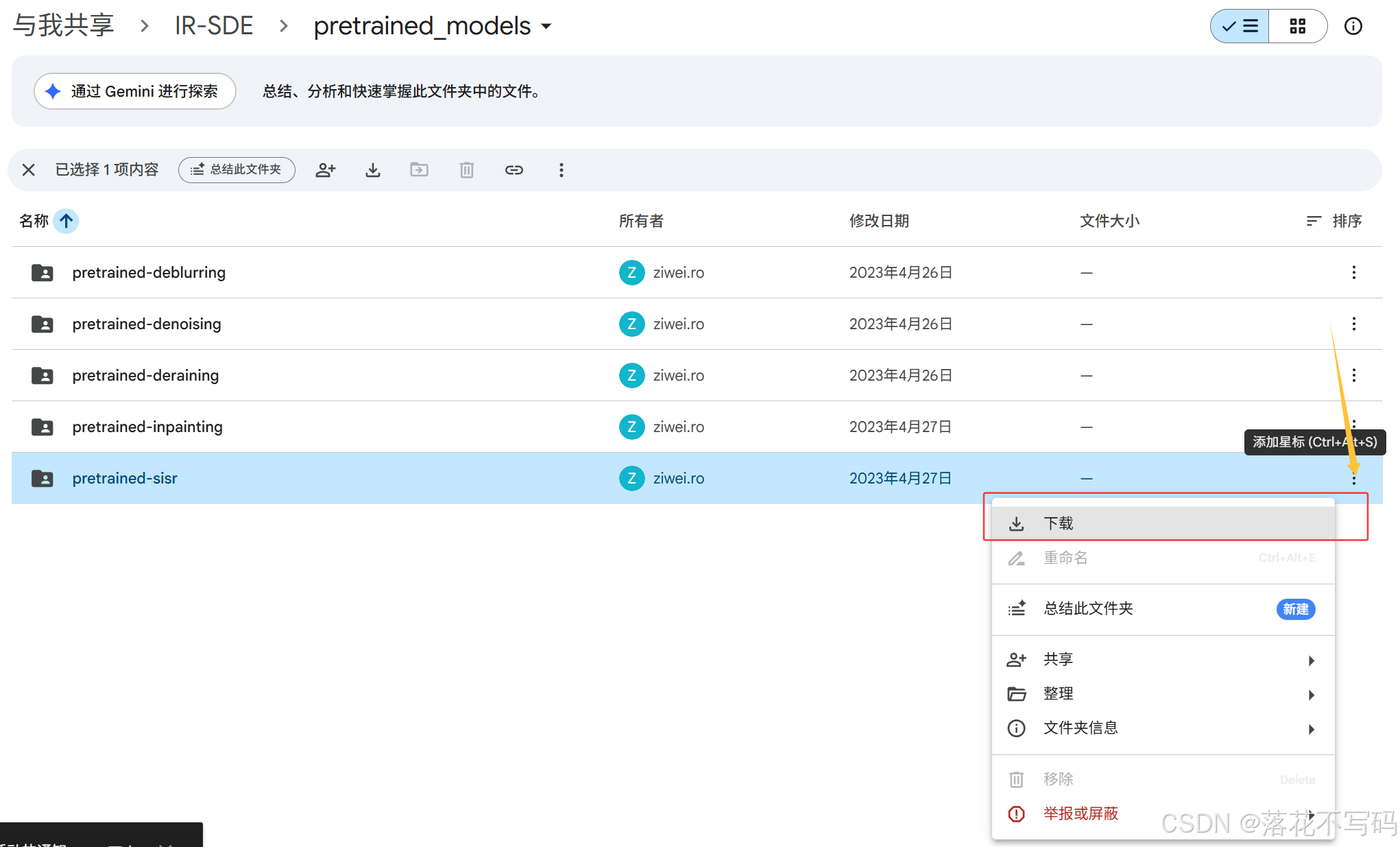
shrink_dataset(HR_PATH, LR_PATH, COUNT, SUFFIX)👉预训练模型下载
下载对应的任务的预训练模型 下载链接:https://drive.google.com/drive/folders/14SvJXvp0HPKFHpGaaHy7h2I2fkRnIXAG
👉服务器训练
由于模型训练所需的硬件设备比较好,本地的显卡无法训练,改成服务器训练,根本地一样的操作
星图AI镜像地址: 深度学习项目训练环境
☑️ 镜像环境
- 核心框架 :
pytorch == 1.13.0 - CUDA版本 :
11.6 - Python版本 :
3.10.0 - 主要依赖 :
torchvision==0.14.0,torchaudio==0.13.0,cudatoolkit=11.6,numpy,opencv-python,pandas,matplotlib,tqdm,seaborn等。
☑️ 快速上手
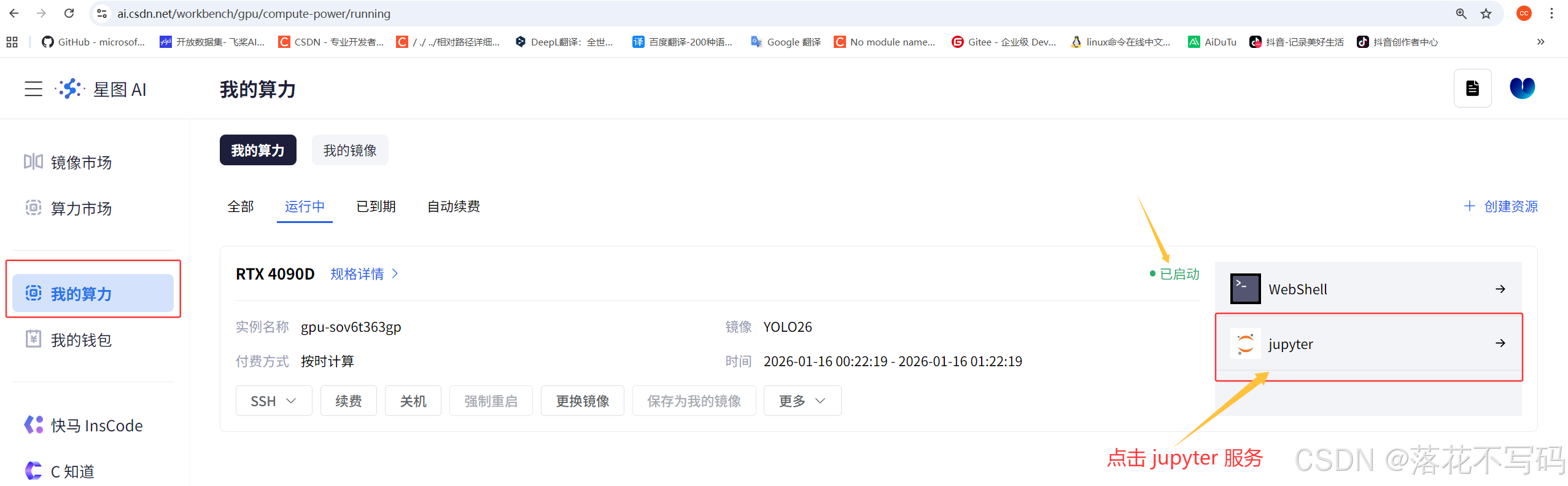
启动完是这样的
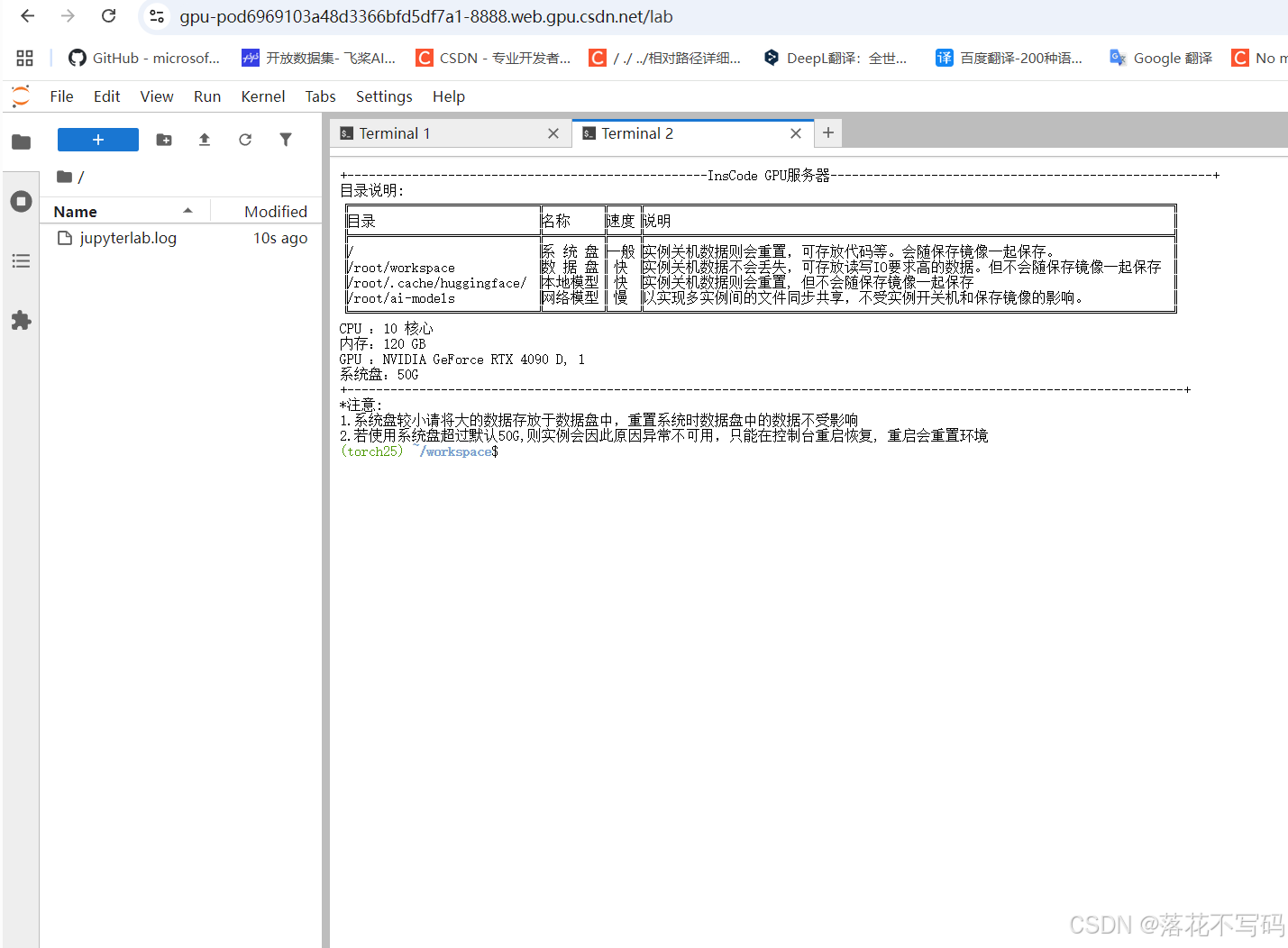
☑️ 激活环境与切换工作目录
在使用前,请先激活的 Conda 环境,我配置的环境名称叫 dl,命令如下:
bash
conda activate dl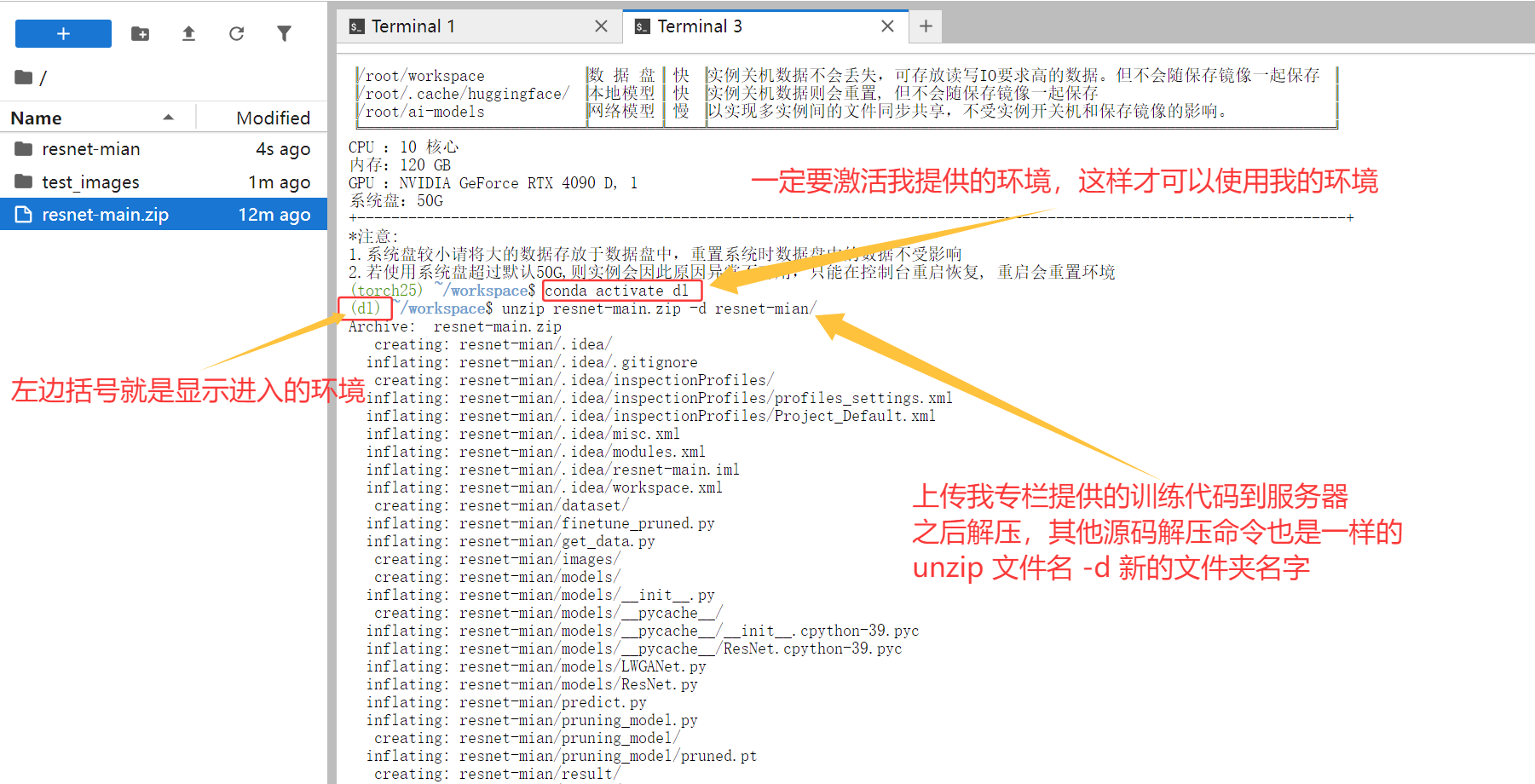
镜像启动后,使用 xftp 工具上传专栏提供的训练代码,并上传你自己数据集。为了方便修改代码,上传的代码或者数据集放到数据盘
之后进入代码目录,命令示例如下:
bash
cd /root/workspace/源码文件夹名称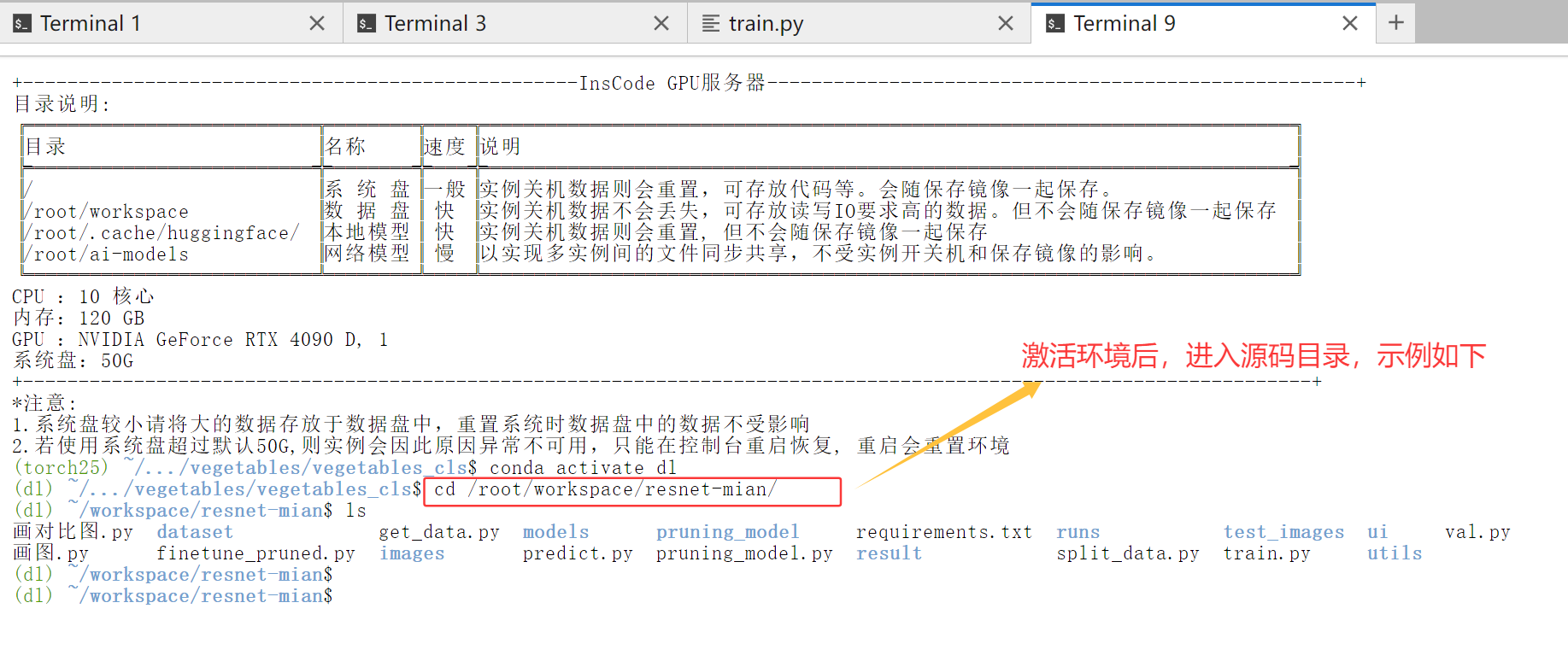
在服务器修改一下配置文件的参数即可
我的 codes/config/sisr/options/train/ir-sde.yml 文件如下,根据需求修改即可:
python
#### general settings
name: ir-sde
use_tb_logger: true
model: denoising
distortion: sr
gpu_ids: [0]
sde:
max_sigma: 30
T: 100
schedule: cosine # linear, cosine
eps: 0.005
degradation: # for some synthetic dataset that only have GTs
# for denoising
sigma: 25
noise_type: G # Gaussian noise: G
# for super-resolution
scale: 4
#### datasets
datasets:
train:
name: Train_Dataset
mode: LQGT
dataroot_GT: /root/workspace/dataset/DIV2K/DIV2K_train_HR1
dataroot_LQ: /root/workspace/dataset/DIV2K/DIV2K_train_LR_bicubic1/X4
use_shuffle: true
n_workers: 4 # per GPU
batch_size: 4
GT_size: 128
LR_size: 32
use_flip: true
use_rot: true
color: RGB
val:
name: Val_Dataset
mode: LQGT
dataroot_GT: /root/workspace/dataset/DIV2K/DIV2K_valid_HR1
dataroot_LQ: /root/workspace/dataset/DIV2K/DIV2K_valid_LR_bicubic1/X4
#### network structures
network_G:
which_model_G: ConditionalUNet
setting:
in_nc: 3
out_nc: 3
nf: 64
depth: 4
#### path
path:
pretrain_model_G: /root/workspace/ir-sde-srx4.pth
strict_load: true
resume_state: ~
#### training settings: learning rate scheme, loss
train:
optimizer: Adam # Adam, AdamW, Lion
lr_G: !!float 1e-4
lr_scheme: MultiStepLR
beta1: 0.9
beta2: 0.99
niter: 100000
warmup_iter: -1 # no warm up
lr_steps: [9000, 40000, 90000]
lr_gamma: 0.5
eta_min: !!float 1e-7
# criterion
is_weighted: False
loss_type: l1
weight: 1.0
manual_seed: 0
val_freq: !!float 5e3
#### logger
logger:
print_freq: 100
save_checkpoint_freq: !!float 5e4参数解释:
name:当前实验的名称,生成的日志和权重文件夹都会带有这个名字。use_tb_logger:设为true表示开启 TensorBoard 记录,方便可视化训练过程中的曲线。model:指定底层模型框架,denoising表示基于去噪架构。distortion:具体的退化类型,sr代表超分辨率(Super-Resolution)。gpu_ids:指定使用的显卡编号,[0]代表使用服务器上的第一块显卡。max_sigma:扩散过程中注入的最大噪声标准差。T:扩散与逆向去噪的总时间步数,这里设为 100 步。schedule:噪声的增加策略,cosine表示余弦调度,比线性增加更平滑。eps:极小值常数,用来防止数学公式计算时出现除以 0 的错误。sigma:纯去噪任务的预设噪声级别。noise_type:噪声类型,G代表高斯噪声。scale:超分辨率放大的倍数,设为 4 表示将图片宽高各放大 4 倍。mode:数据加载模式,LQGT代表网络需要同时加载低质量(LQ)和高质量(GT)成对的图片。dataroot_GT/dataroot_LQ:高分辨率原图和低分辨率模糊图所在的绝对路径。use_shuffle:设为true表示在训练时每次打乱图片的喂入顺序。n_workers:分配几个 CPU 进程来专门为显卡搬运和处理图片数据。batch_size:每次前向传播同时塞给显卡处理的图片数量。GT_size/LR_size:训练时把高清大图随机裁剪成 128x128 的小块,低清图对应裁剪成 32x32,用来省显存并加速训练。use_flip/use_rot:设为true表示开启随机翻转和旋转,能防止模型死记硬背(过拟合)。color:图像颜色空间,RGB为彩色图。which_model_G:指定生成器的网络结构,这里使用的是ConditionalUNet。in_nc/out_nc:输入和输出的图像通道数,彩色图通常为 3 通道。nf:网络基础特征图的通道数,64 表示网络的宽度。depth:UNet 网络的下采样和上采样深度层数。pretrain_model_G:预训练权重文件的存放路径,用于在别人训练好的基础上继续微调。strict_load:设为true表示要求加载的权重层名必须与当前网络完全对应,不能有一点偏差。resume_state:断点续训的存档文件路径,填~表示忽略存档,从头开始训练。optimizer:优化器算法,这里使用的是深度学习最常用的Adam。lr_G:生成器的初始学习率,1e-4即 0.0001。lr_scheme:学习率衰减策略,MultiStepLR表示按设定的多阶梯节点进行下降。beta1/beta2:Adam 优化器内部控制动量和方差的专属参数,通常保持默认即可。niter:模型训练的总迭代步数,这里是 100000 步。warmup_iter:学习率预热步数,-1表示直接进入正常训练,不进行预热。lr_steps:学习率下降的触发节点,表示在跑满 9000步、4万步、9万步时分别降一次学习率。lr_gamma:学习率衰减比例,0.5表示每次触发衰减时,当前学习率减半。eta_min:学习率衰减的最小下限值。is_weighted:是否对损失函数使用加权计算。loss_type:损失函数类型,l1代表计算预测值与真实值之间的绝对误差。weight:该损失函数在总体损失中的权重比例。manual_seed:随机数种子,设为固定值(如 0)可以保证每次实验能够复现。val_freq:验证频率,每跑满 5000 步自动跑一次验证集来计算指标。print_freq:控制台输出频率,每跑满 100 步在屏幕上打印一次当前的 Loss 进度。save_checkpoint_freq:保存频率,每跑满 50000 步,自动把当前的成果打包保存为一个.pth权重文件和.state断点文件。
👉image-restoration-sde复现前提
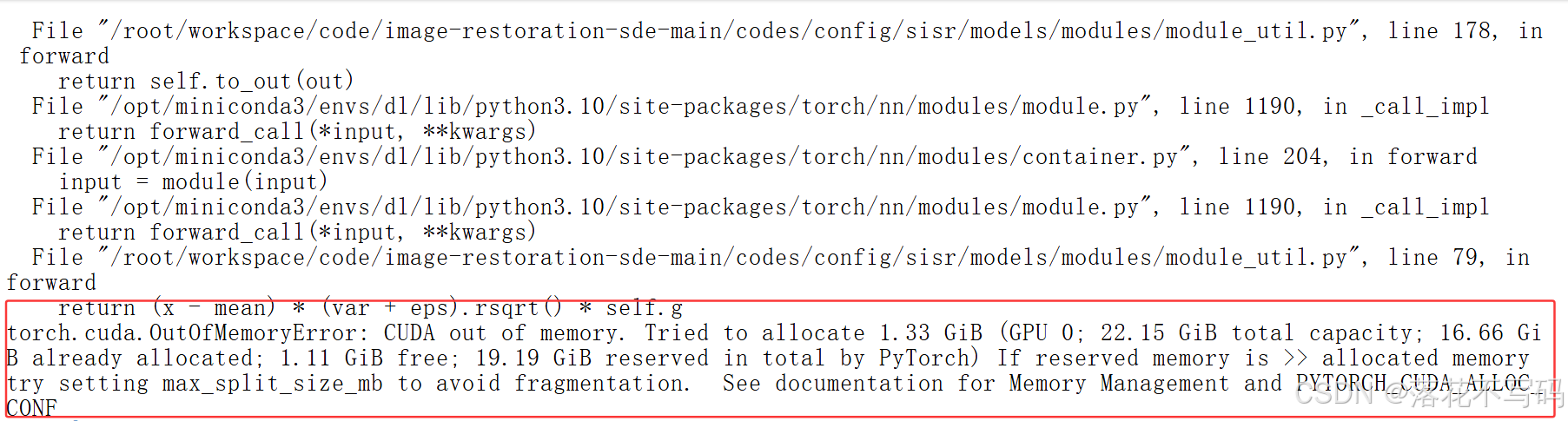
对于超过 2K 分辨率的图像,直接送进网络跑测试和验证,爆显存错误是正常,解决方法有以下两种:
(1)sisr 训练的话,在验证阶段,报了以下错误,可以在 train 配置里把 val_freq 设成一个极大的数字(比如 50 万步),绕开验证时的 OOM
(2)裁剪验证集,裁剪的代码如下,修改验证集路径就行。训练集不用裁剪,训练时候代码自动裁剪了
python
# -*- coding: utf-8 -*-
"""
@Auth :落花不写码
@File :裁剪.py
@Motto :学习新思想,争做新青年
"""
import os
import cv2
def crop_center(img, crop_w, crop_h):
h, w = img.shape[:2]
start_x = w // 2 - crop_w // 2
start_y = h // 2 - crop_h // 2
return img[start_y:start_y + crop_h, start_x:start_x + crop_w]
hr_dir = r"E:\5-dataset\image_restoration\DIV2K_valid_HR"
lr_dir = r"E:\5-dataset\image_restoration\DIV2K_valid_LR_bicubic\X4"
save_hr_dir = r"E:\5-dataset\image_restoration\DIV2K_valid_HR1"
save_lr_dir = r"E:\5-dataset\image_restoration\DIV2K_valid_LR_bicubic1\X4"
os.makedirs(save_hr_dir, exist_ok=True)
os.makedirs(save_lr_dir, exist_ok=True)
crop_size = 512
scale = 4
lr_suffix = "x4"
hr_files = [f for f in os.listdir(hr_dir) if f.endswith('.png')]
for filename in hr_files:
hr_img = cv2.imread(os.path.join(hr_dir, filename))
lr_filename = filename.replace(".png", f"{lr_suffix}.png")
lr_img = cv2.imread(os.path.join(lr_dir, lr_filename))
hr_cropped = crop_center(hr_img, crop_size, crop_size)
lr_cropped = crop_center(lr_img, crop_size // scale, crop_size // scale)
cv2.imwrite(os.path.join(save_hr_dir, filename), hr_cropped)
cv2.imwrite(os.path.join(save_lr_dir, lr_filename), lr_cropped)
print("裁剪已完成 " + filename)服务器训练命令如下:
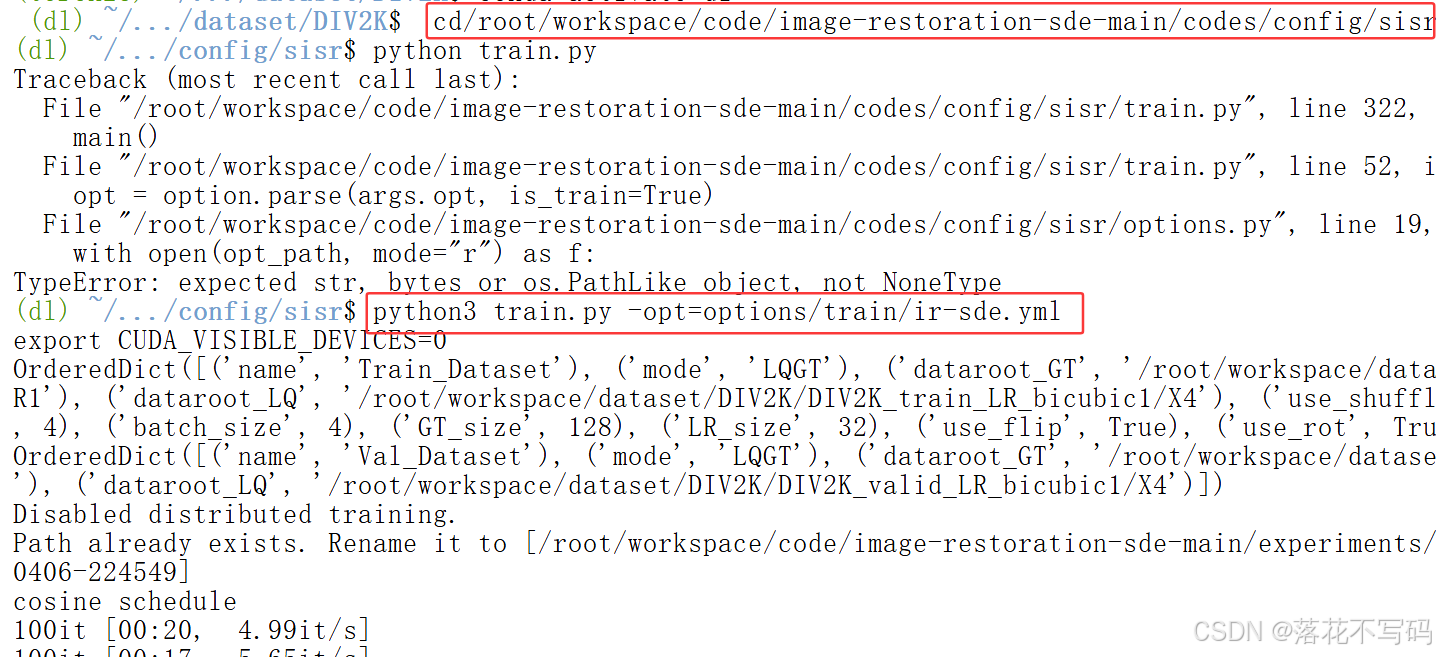
先切换到指定任务路径下,在运行下面的命令
python
python3 train.py -opt=options/train/ir-sde.yml训练过程:
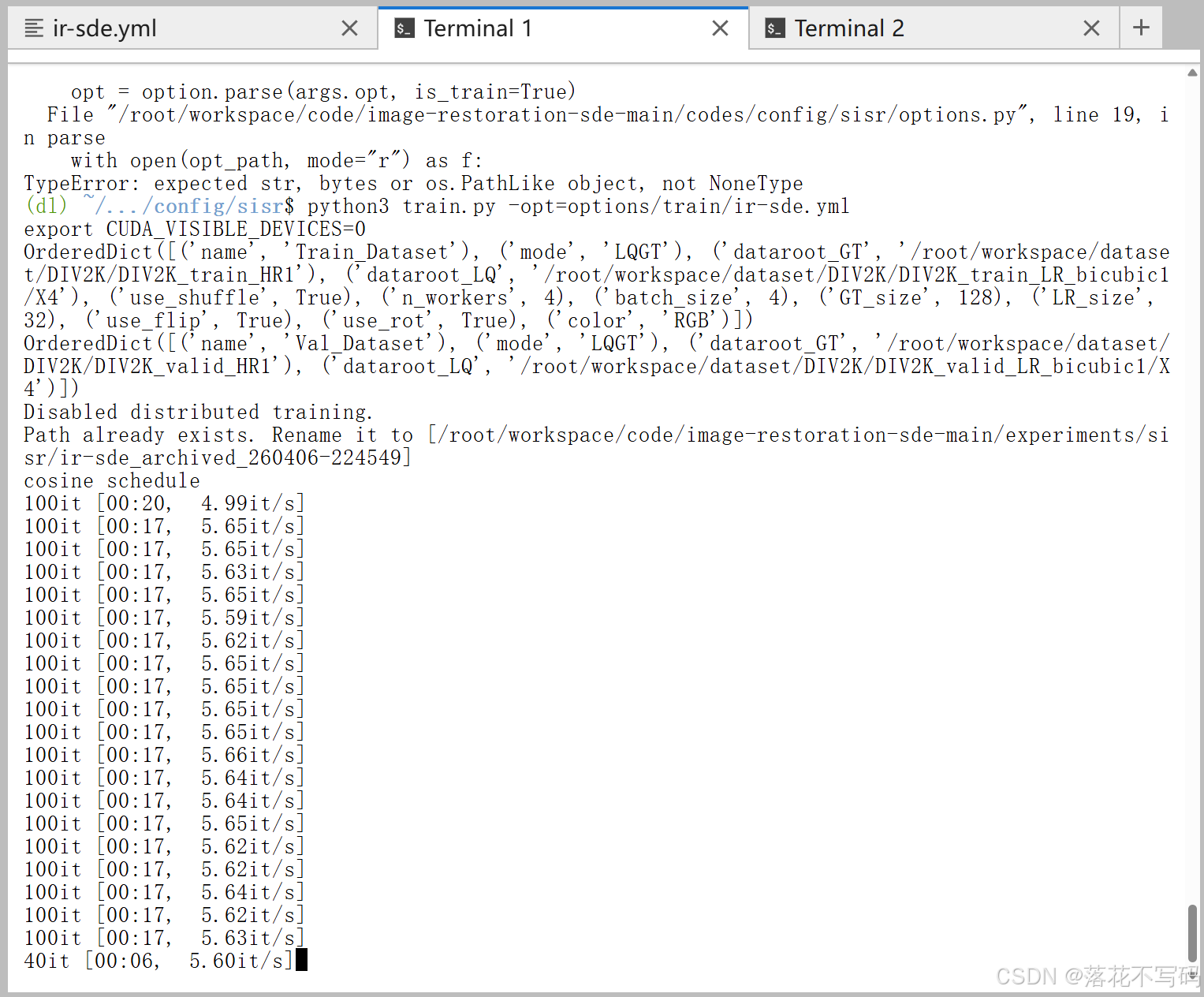
训练过程保存的模型:
👉TensorBoard
在本地终端启动 TensorBoard 查看损失图
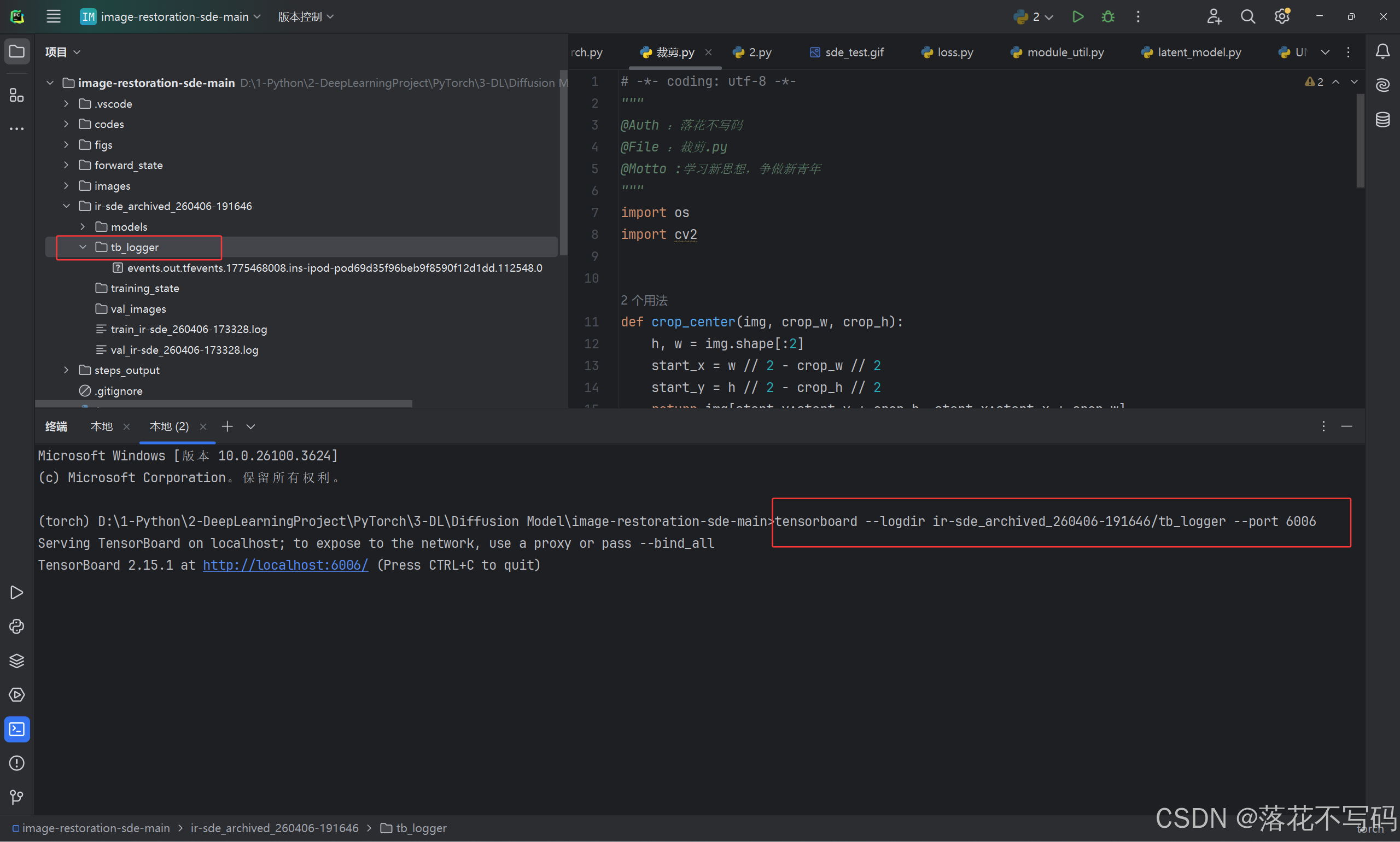
如下:
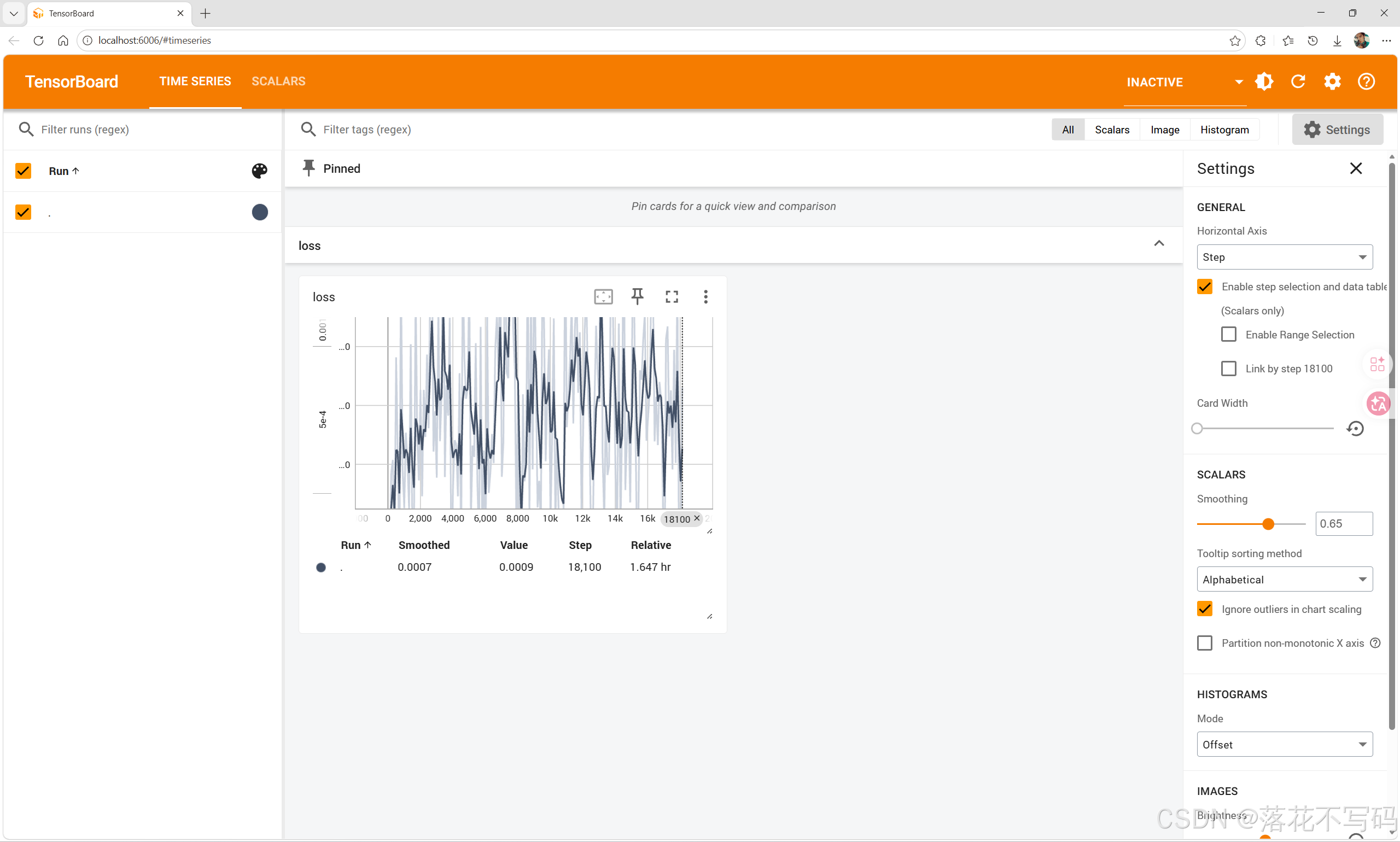
评价指标
为了全面、客观地评估图像修复模型的性能,通常会结合传统的像素级指标与深度学习时代的感知级指标进行综合评价。常用的评价指标包括峰值信噪比(PSNR)、结构相似性指数(SSIM)、学习感知图像块相似度(LPIPS)以及FID(Fréchet Inception Distance,弗雷歇初始距离)。
| 评价指标 | 英文全称 | 侧重评估维度 | 优劣方向 | 具体说明 |
|---|---|---|---|---|
| PSNR | Peak Signal-to-Noise Ratio | 像素级绝对误差 | ↑ | 值越大,说明像素级失真越少,重建精度越高。 |
| SSIM | Structural Similarity Index | 亮度、对比度与结构 | ↑ | 值越接近1(越大),说明结构与人类视觉感知越一致。 |
| LPIPS | Learned Perceptual Image Patch Similarity | 深度特征与感知自然度 | ↓ | 值越小(代表距离或差异越小),说明单张图像的纹理越逼真自然。 |
| FID | Fréchet Inception Distance | 全局特征分布相似度 | ↓ | 值越小,说明生成图像的整体分布越接近真实图像,质量越高。 |
箭头含义说明:
- ↑ (越大越好): 模型输出的结果得分越高,代表修复能力越强。
- ↓ (越小越好): 模型输出的结果得分越低,代表修复后的图像与真实图像之间的差距越小,效果越好。
1. 峰值信噪比(PSNR)
PSNR 是一种基于误差敏感的客观评价指标,主要用于衡量修复图像与真实图像(Ground Truth)在像素级别的绝对误差。其计算依赖于均方误差(MSE)。
假设修复图像 I o u t p u t I_{output} Ioutput 与真实图像 I g t I_{gt} Igt 的尺寸均为 H × W H \times W H×W,均方误差的计算公式为:
M S E = 1 H W ∑ i = 1 H ∑ j = 1 W ( I o u t p u t ( i , j ) − I g t ( i , j ) ) 2 MSE = \frac{1}{HW} \sum_{i=1}^{H} \sum_{j=1}^{W} (I_{output}(i,j) - I_{gt}(i,j))^2 MSE=HW1i=1∑Hj=1∑W(Ioutput(i,j)−Igt(i,j))2
在此基础上,PSNR 的定义为:
P S N R = 10 ⋅ log 10 ( M A X 2 M S E ) PSNR = 10 \cdot \log_{10}\left(\frac{MAX^2}{MSE}\right) PSNR=10⋅log10(MSEMAX2)
其中, M A X MAX MAX 表示图像颜色的最大数值(对于 8 位深度的图像, M A X = 255 MAX = 255 MAX=255)。
评价标准: PSNR 的单位是分贝(dB)。该值越大,说明 MSE 越小,修复图像与真实图像在像素级上的失真越少,图像质量越高。
2. 结构相似性指数(SSIM)
由于 PSNR 仅关注像素的绝对差异,往往与人类的主观视觉感知不一致。SSIM 则从人类视觉系统的特性出发,从亮度(Luminance)、对比度(Contrast)和结构(Structure)三个维度综合量化两幅图像的相似性。
其完整的计算公式为:
S S I M ( x , y ) = ( 2 μ x μ y + C 1 ) ( 2 σ x y + C 2 ) ( μ x 2 + μ y 2 + C 1 ) ( σ x 2 + σ y 2 + C 2 ) SSIM(x,y) = \frac{(2\mu_x\mu_y + C_1)(2\sigma_{xy} + C_2)}{(\mu_x^2 + \mu_y^2 + C_1)(\sigma_x^2 + \sigma_y^2 + C_2)} SSIM(x,y)=(μx2+μy2+C1)(σx2+σy2+C2)(2μxμy+C1)(2σxy+C2)
其中:
- μ x \mu_x μx 和 μ y \mu_y μy 分别表示图像 x x x 和图像 y y y 的局部均值(代表亮度)。
- σ x 2 \sigma_x^2 σx2 和 σ y 2 \sigma_y^2 σy2 分别表示图像 x x x 和图像 y y y 的方差(代表对比度)。
- σ x y \sigma_{xy} σxy 表示两幅图像的协方差(代表结构关联性)。
- C 1 C_1 C1 和 C 2 C_2 C2 为极小的常数(通常 C 1 = ( 0.01 × M A X ) 2 C_1 = (0.01 \times MAX)^2 C1=(0.01×MAX)2, C 2 = ( 0.03 × M A X ) 2 C_2 = (0.03 \times MAX)^2 C2=(0.03×MAX)2),用于防止分母为零的情况,维持计算稳定。
评价标准: SSIM 的取值范围为 − 1 , 1 -1, 1 −1,1。其数值越接近 1,表明修复图像与真实图像的结构一致性越强,视觉连贯性越好。
3. 学习感知图像块相似度(LPIPS)
传统的 PSNR 和 SSIM 容易对"过度平滑"的模糊图像给出高分,这在生成式模型(如 GAN、Diffusion、SDE)中尤其明显。LPIPS 则弥补了这一缺陷,它对图像的纹理细节极度敏感,能够有效反映生成结果的视觉自然度。
LPIPS 通过预训练的深度神经网络(通常为 VGG 或 AlexNet)提取图像的高维语义特征,并在特征空间中计算两者的欧氏距离或余弦距离。其公式通常表示为:
L P I P S = ∑ k = 1 L 1 H k W k ∑ i , j ∣ ∣ w k ⊙ ( ϕ k ( I o u t p u t ) − ϕ k ( I g t ) ) ∣ ∣ 2 2 LPIPS = \sum_{k=1}^{L} \frac{1}{H_k W_k} \sum_{i,j} || w_k \odot (\phi_k(I_{output}) - \phi_k(I_{gt})) ||_2^2 LPIPS=k=1∑LHkWk1i,j∑∣∣wk⊙(ϕk(Ioutput)−ϕk(Igt))∣∣22
其中:
- ϕ k \phi_k ϕk 表示提取网络第 k k k 层的特征图。
- w k w_k wk 是用于缩放激活通道的权重向量。
- H k H_k Hk 和 W k W_k Wk 为第 k k k 层特征图的空间维度大小。
评价标准: 与 PSNR 和 SSIM 相反,LPIPS 计算的是"距离"或"差异"。因此,LPIPS 的数值越低,说明两幅图像在深度特征和人类感知上越接近,修复图像越逼真自然。
4.FID 计算公式
FID 通过预训练的 Inception v3 网络提取真实图像和修复(生成)图像的高维特征,并假设这些特征服从多元高斯分布。其通过计算这两个高斯分布之间的 Wasserstein-2 距离(即 Fréchet 距离)来衡量差异。
完整的计算公式如下:
F I D = ∣ ∣ μ g t − μ o u t p u t ∣ ∣ 2 2 + T r ( Σ g t + Σ o u t p u t − 2 ( Σ g t Σ o u t p u t ) 1 / 2 ) FID = ||\mu_{gt} - \mu_{output}||2^2 + Tr(\Sigma{gt} + \Sigma_{output} - 2(\Sigma_{gt}\Sigma_{output})^{1/2}) FID=∣∣μgt−μoutput∣∣22+Tr(Σgt+Σoutput−2(ΣgtΣoutput)1/2)
其中:
- μ g t \mu_{gt} μgt 和 Σ g t \Sigma_{gt} Σgt 分别表示真实图像(Ground Truth)特征分布的均值向量和协方差矩阵。
- μ o u t p u t \mu_{output} μoutput 和 Σ o u t p u t \Sigma_{output} Σoutput 分别表示修复图像特征分布的均值向量和协方差矩阵。
- T r Tr Tr 表示矩阵的迹(即矩阵主对角线元素之和)。
评价标准: FID 计算的是两个分布之间的"距离"。因此,FID 的数值越小,说明修复出来的图像在整体分布上越接近真实世界图像,生成质量和多样性越好。
图像修复系统的设计与实现
在前文提出的图像修复算法基础上,本章开发了一套基于 xx 框架的图像修复系统。系统的开发遵循了标准的软件开发流程主要包括需求分析、系统设计、系统实现以及系统测试优化四个阶段。需求分析阶段明确了系统需要实现的核心功能模块;系统设计阶段完成了对整体架构和模块划分的规划;在系统实现过程中将图像修复算法与交互式用户界面相结合,形成完整的应用系统;系统测试阶段则对修复效果和用户使用体验进行了综合评估。通过本系统能有效地将图像修复算法应用于实际场景,用户可通过直观的交互界面完成图像修复任务。
框架介绍
PyQt5/PySide6/Django+Vue3等都可以
系统设计
系统实现
功能实现
系统整体流程图
系统功能测试
图像上传与预处理模块:
图像上传与预处理模块:
本章小结
巴拉巴拉总结就行