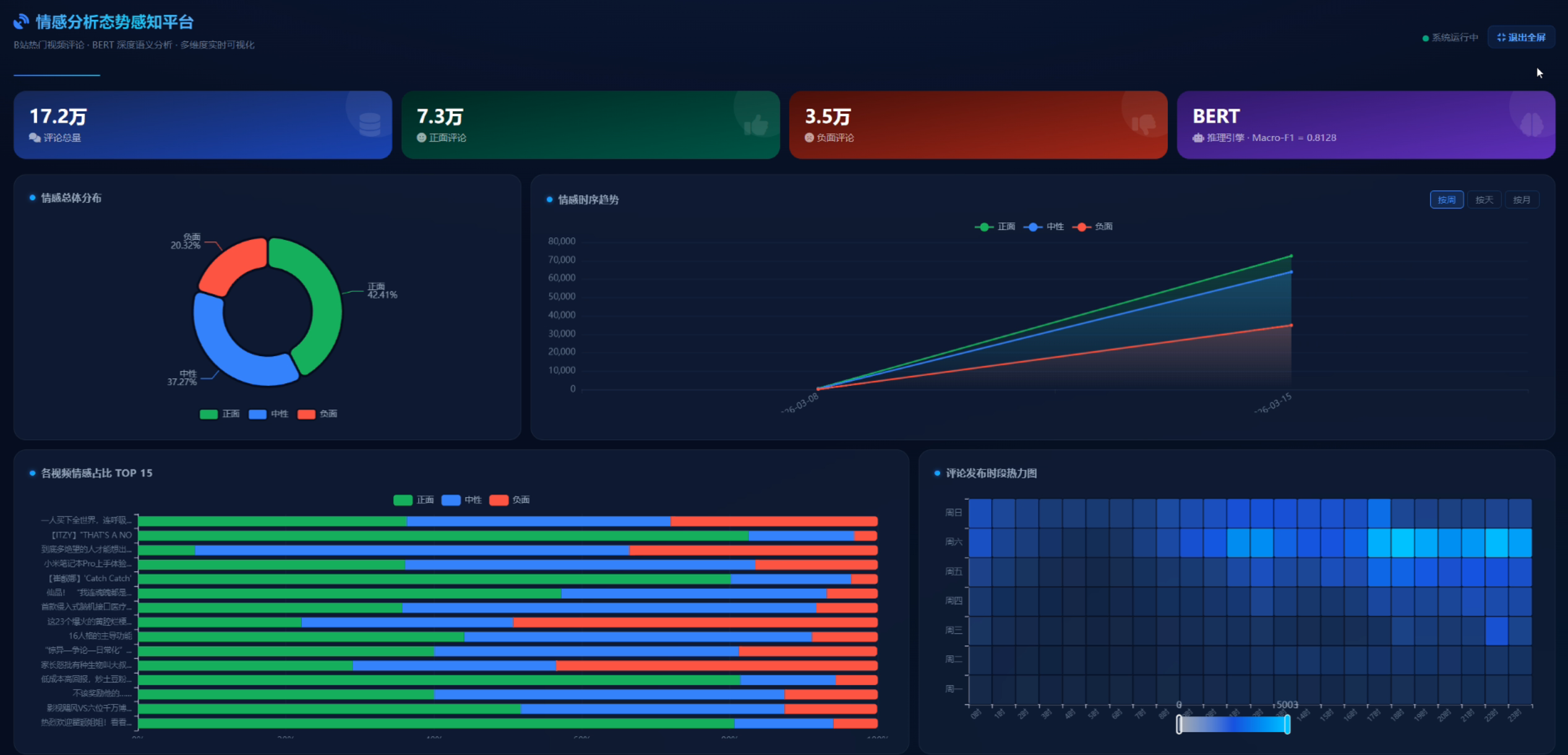
项目效果图:

源码获取:
通过网盘分享的文件:源码获取.txt
链接: https://pan.baidu.com/s/157q4QdD9HT_Yl13iqEJY-g?pwd=mw4q 提取码: mw4q
1. 项目概述
1.1 研究背景
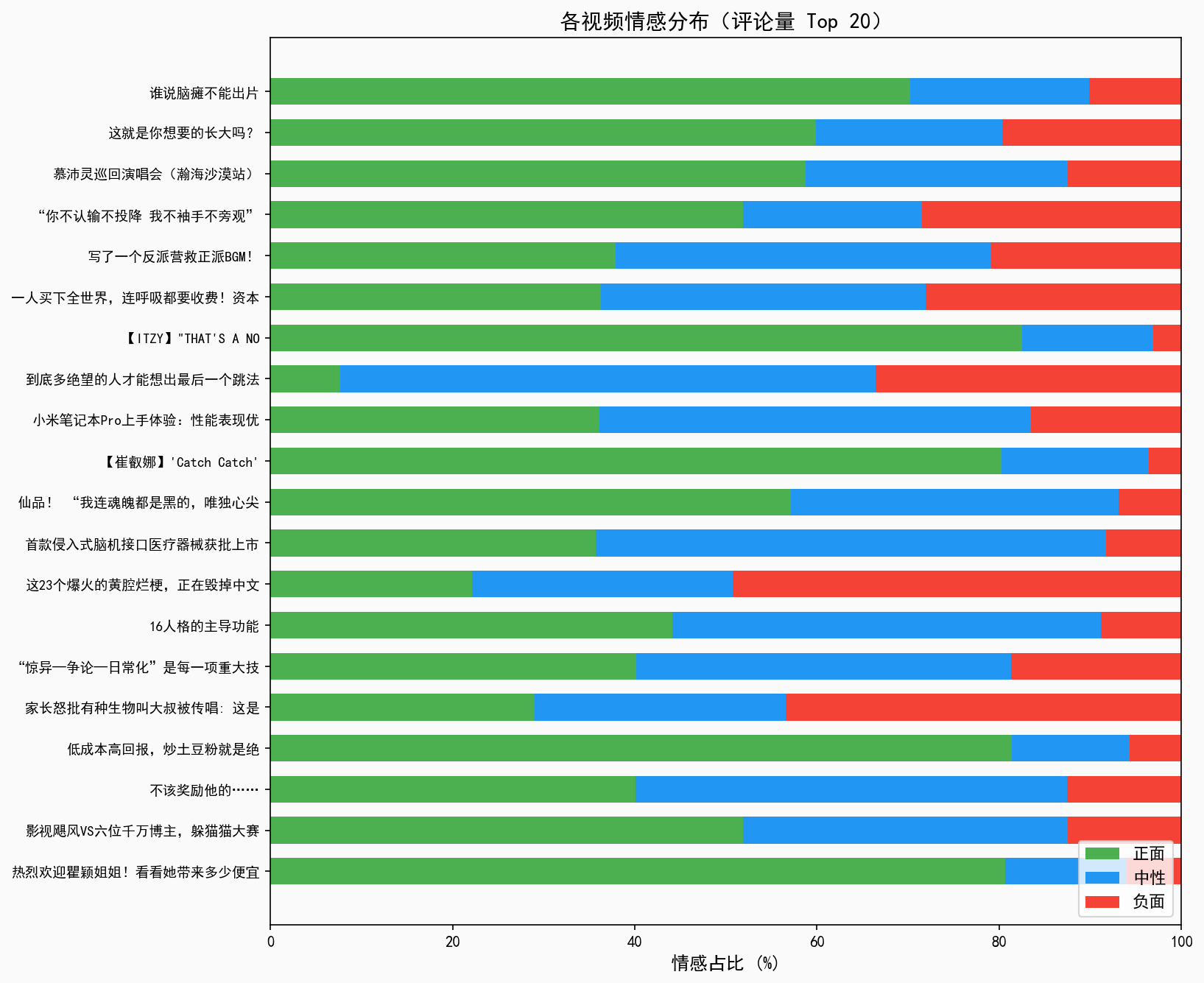
B站(哔哩哔哩)是中国最大的年轻世代内容平台,日均活跃用户超1亿,热门视频评论区往往汇聚数千至数万条评论,是反映用户情绪、社会舆情、内容接受度的重要数据来源。然而,评论数量庞大、内容结构化程度低,人工分析几乎不可行。
本系统旨在构建一套端到端的B站热门视频评论智能分析平台,覆盖从数据爬取、清洗、情感建模到多维度可视化展示的完整链路,帮助内容创作者、研究者和平台运营方快速理解用户情绪分布与舆情趋势。
1.2 研究目标
-
数据采集:自动爬取B站综合热门视频列表及对应评论,构建带标注元数据的评论语料库
-
情感分析:基于预训练BERT模型对中文评论进行细粒度情感极性分类(正面/负面/中性)
-
模型对比:横向对比多种情感分析方法(传统ML、TextCNN、BiLSTM、BERT系列),验证BERT的优越性
-
可视化:从情感分布、时序演变、热点词云、用户行为等多个维度呈现分析结果
1.3 研究价值
| 维度 | 价值说明 |
|---|---|
| 学术价值 | 验证BERT在中文短文本情感分析任务上的适配性,探索领域微调策略 |
| 应用价值 | 为UP主提供内容接受度反馈,为平台提供舆情监控手段 |
| 数据价值 | 构建规模化的B站热门评论情感标注数据集 |
2. 系统总体架构
系统分为五个核心模块,采用流水线(Pipeline)架构,数据在各模块间单向流转:
┌─────────────────────────────────────────────────────────────────┐
│ 系统总体架构 │
├──────────────┬──────────────┬──────────────┬────────────────────┤
│ 模块一 │ 模块二 │ 模块三 │ 模块四 │
│ 数据采集 │ 数据预处理 │ 情感分析 │ 可视化展示 │
│ │ │ │ │
│ ・热门列表爬取 │ ・文本清洗 │ ・模型推理 │ ・情感分布饼图 │
│ ・评论爬取 │ ・分词/去停词 │ ・情感标注 │ ・时序趋势折线图 │
│ ・数据持久化 │ ・特征提取 │ ・置信度输出 │ ・高频词词云 │
│ │ │ │ ・视频热度对比 │
└──────────────┴──────────────┴──────────────┴────────────────────┘
↕
┌─────────────────┐
│ 数据存储层 │
│ CSV / SQLite / │
│ Parquet │
└─────────────────┘2.1 模块间数据流
热门页面 → [爬虫模块] → 原始CSV
原始CSV → [预处理模块] → 清洗后DataFrame
清洗DataFrame → [情感模型] → 带情感标签DataFrame
带标签DataFrame → [可视化模块] → 图表/报告3. 数据采集模块设计
3.1 爬虫架构概述
本系统实现了两套互为补充的爬虫方案:
| 方案 | 文件 | 技术栈 | 适用场景 |
|---|---|---|---|
| 方案A(旧版) | Bilicomment.py |
Selenium + BeautifulSoup | 需要二级评论、兼容旧版评论区DOM |
| 方案B(新版一体化) | bilibili_all_in_one.py |
Playwright (async) | 新版Shadow DOM评论区,速度更快 |
| 热门列表爬取 | bilibili_hot_crawler.py |
Playwright (async) | 仅爬取热门视频元数据 |
最终采用方案B(bilibili_all_in_one.py)作为主力爬虫,原因如下:
-
B站评论区已全面迁移到基于Web Components的Shadow DOM架构,Selenium难以直接穿透
-
Playwright原生支持异步,性能显著优于Selenium同步模式
-
一体化流程(热门列表 → 评论爬取 → 汇总)减少人工干预
3.2 热门视频列表爬取
目标URL :https://www.bilibili.com/v/popular/all
爬取流程:
-
启动Playwright Chromium,注入反检测脚本(覆盖
navigator.webdriver、plugins、languages) -
模拟人工滚动(随机滚动距离800~1200px,随机延迟1~10.5秒)
-
检测是否到达页面底部,无新内容则终止滚动
-
通过页面内JS提取
.video-card卡片元数据
采集字段:
| 字段 | 来源选择器 | 说明 |
|---|---|---|
title |
p.video-name[title] |
视频标题 |
url |
.video-card__content a[href] |
视频链接 |
play_count |
span.play-text |
播放数(含"万"等单位) |
comment_count |
span.like-text |
弹幕/评论数 |
img_url |
img.cover-picture__image[data-src] |
封面图URL |
输出 :data/hot_video_list.json
3.3 视频评论爬取
B站新版评论区采用 Shadow DOM(Web Components) 结构,传统DOM选择器无法直接访问。穿透路径如下:
document
└── bili-comments (Shadow Host)
└── shadowRoot
└── bili-comment-thread-renderer[] (每条一级评论)
└── shadowRoot
└── #comment (评论正文容器)
└── shadowRoot
├── bili-comment-user-info → shadowRoot → #user-name a
├── #user-avatar[data-user-profile-id]
├── bili-rich-text → shadowRoot → #contents
└── bili-comment-action-buttons-renderer
└── shadowRoot
├── #pubdate
└── #like #count评论爬取步骤:
-
访问视频页,等待页面渲染(
PAGE_LOAD_WAIT = 10s) -
关闭迷你播放器(防止遮挡评论区)
-
滚动到评论区触发加载
-
轮询检测
bili-comment-thread-renderer是否出现(超时跳过) -
持续滚动到页面底部(最大滚动次数
MAX_SCROLL_COUNT = 200) -
通过
page.evaluate()内JS穿透所有shadowRoot层级提取数据 -
逐条实时写入
data/{视频标题}.csv(防止中断丢失)
采集字段:
| 字段 | 说明 |
|---|---|
编号 |
评论序号 |
昵称 |
用户名 |
用户ID |
B站UID |
评论内容 |
评论正文(含表情文字描述) |
发布时间 |
格式:YYYY-MM-DD HH:mm 或相对时间 |
点赞数 |
评论获赞数 |
视频标题 |
来源视频名称 |
地址 |
视频URL |
观看数 |
视频播放量 |
评论数 |
视频总评论数 |
图片地址 |
视频封面URL |
3.4 断点续传与容错设计
progress.json 结构:
{
"phase": "hot_list | comments | done", // 当前阶段
"video_index": 0, // 已完成视频数
"comment_index": 0, // 当前视频已爬取评论数
"total_videos": 200 // 总视频数
}-
程序每写入一条评论即更新
progress.json -
重启后自动从断点恢复,跳过已完成视频/评论
-
异常视频记录到
error_log.txt并跳过继续爬取 -
视频间随机休眠2~5秒,降低反爬风险
3.5 数据集规模
基于已采集数据统计:
| 统计项 | 数值 |
|---|---|
| 视频数量 | ~200个热门视频 |
| 文件大小范围 | 43KB ~ 1.26MB/视频 |
| 评论总量(估算) | ~100,000+ 条 |
| 涵盖分区 | 生活、游戏、科技、音乐、影视等 |
| 时间跨度 | 2026年3月(B站热门榜单) |
4. 数据预处理模块设计
4.1 数据清洗流程
原始评论数据存在多类噪声,需逐步清洗:
原始评论文本
↓
① 去除无效记录(空评论、纯符号评论)
↓
② 统一时间格式(相对时间 → 绝对时间戳)
↓
③ HTML实体解码 & 表情符号处理
↓
④ 去除URL链接、@用户名、话题标签
↓
⑤ 繁简转换(opencc)
↓
⑥ 中文分词(jieba精确模式)
↓
⑦ 去停用词(哈工大停用词表 + 自定义B站领域停用词)
↓
清洗后文本(用于传统ML特征提取)
原始清洗文本(用于BERT直接输入,保留语义完整性)4.2 时间格式标准化
B站评论存在相对时间格式(如"4小时前"、"3天前"),需转换为绝对时间:
# 相对时间映射规则(以爬取时间为基准)
"刚刚" → crawl_time
"N分钟前" → crawl_time - N minutes
"N小时前" → crawl_time - N hours
"N天前" → crawl_time - N days
"YYYY-MM-DD HH:mm" → 直接解析4.3 特征工程(传统ML)
| 特征类型 | 具体方法 | 说明 |
|---|---|---|
| 词袋模型 | CountVectorizer | n-gram (1,2),最大特征数20000 |
| TF-IDF | TfidfVectorizer | 字符级+词级双通道 |
| 情感词典 | SnowNLP / 知网HowNet | 基于规则的情感极性先验 |
| 统计特征 | 文本长度、点赞数、发布时段 | 辅助特征 |
4.4 BERT输入构造
输入格式:[CLS] 评论文本 [SEP]
参数设置:
- max_length = 128(覆盖99%+的B站评论长度)
- padding = "max_length"
- truncation = True
- return_attention_mask = True5. 情感分析方法设计
5.1 任务定义
任务类型:文本三分类(序列分类)
| 类别 | 标签 | 含义 | 示例 |
|---|---|---|---|
| 正面 | 1 | 表达认可、喜爱、赞赏 | "up主真的太棒了!每次都有惊喜" |
| 中性 | 0 | 陈述事实、疑问、无情感倾向 | "这首歌是什么名字" |
| 负面 | -1 | 表达不满、批评、消极情绪 | "这期内容质量下降了很多" |
5.2 标注策略
由于B站评论无现成情感标注,采用弱监督 + 人工校验策略:
-
初始标注:使用 SnowNLP 对全量数据进行初步打分(0~1分,<0.4为负面,>0.6为正面,其余为中性)
-
抽样人工校验:随机抽取2000条,人工修正标注错误(预计错误率15~20%)
-
训练集构建:人工校验集作为高质量训练/验证集,弱标注集作为辅助预训练数据
最终标注集规模(目标):
| 集合 | 规模 | 说明 |
|---|---|---|
| 训练集 | 1600条 | 人工校验,80% |
| 验证集 | 200条 | 人工校验,10% |
| 测试集 | 200条 | 人工校验,10% |
| 弱标注集 | 全量~10万条 | 用于半监督或知识蒸馏 |
5.3 BERT情感分析模型架构
输入 token序列 (max_len=128)
↓
BERT Encoder(12层 Transformer)
↓
[CLS] token 向量 (hidden_size=768)
↓
Dropout(p=0.1)
↓
Linear(768 → 3)
↓
Softmax → 三类概率
↓
argmax → 情感标签 {正面, 中性, 负面}预训练底座选择 :bert-base-chinese(谷歌发布,12层,110M参数,在中文Wikipedia上预训练)
微调策略:
| 参数 | 设置 |
|---|---|
| 学习率 | 2e-5(BERT层),1e-4(分类头) |
| 批次大小 | 32 |
| 训练轮数 | 5 epochs |
| 优化器 | AdamW |
| 学习率调度 | Linear warmup (10%) + decay |
| 权重衰减 | 0.01 |
| 最大梯度裁剪 | 1.0 |
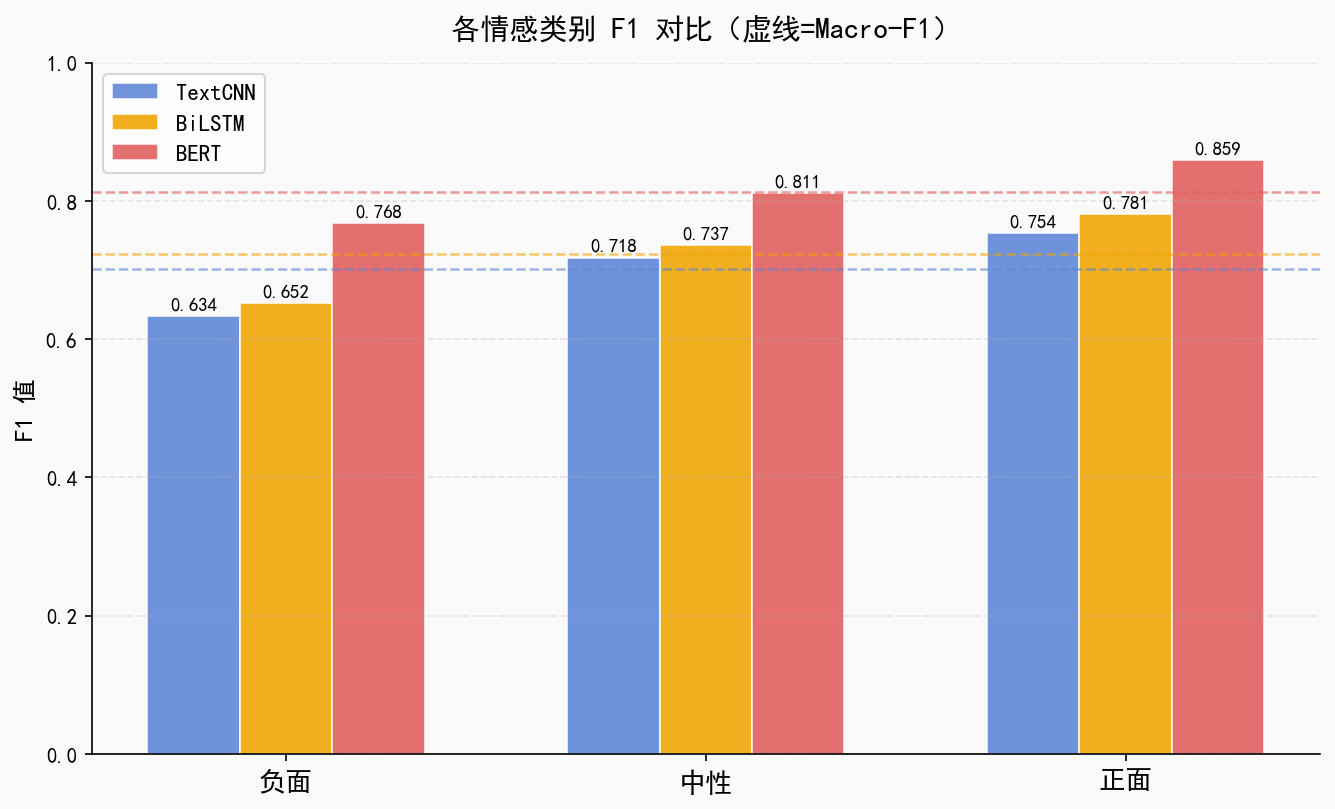
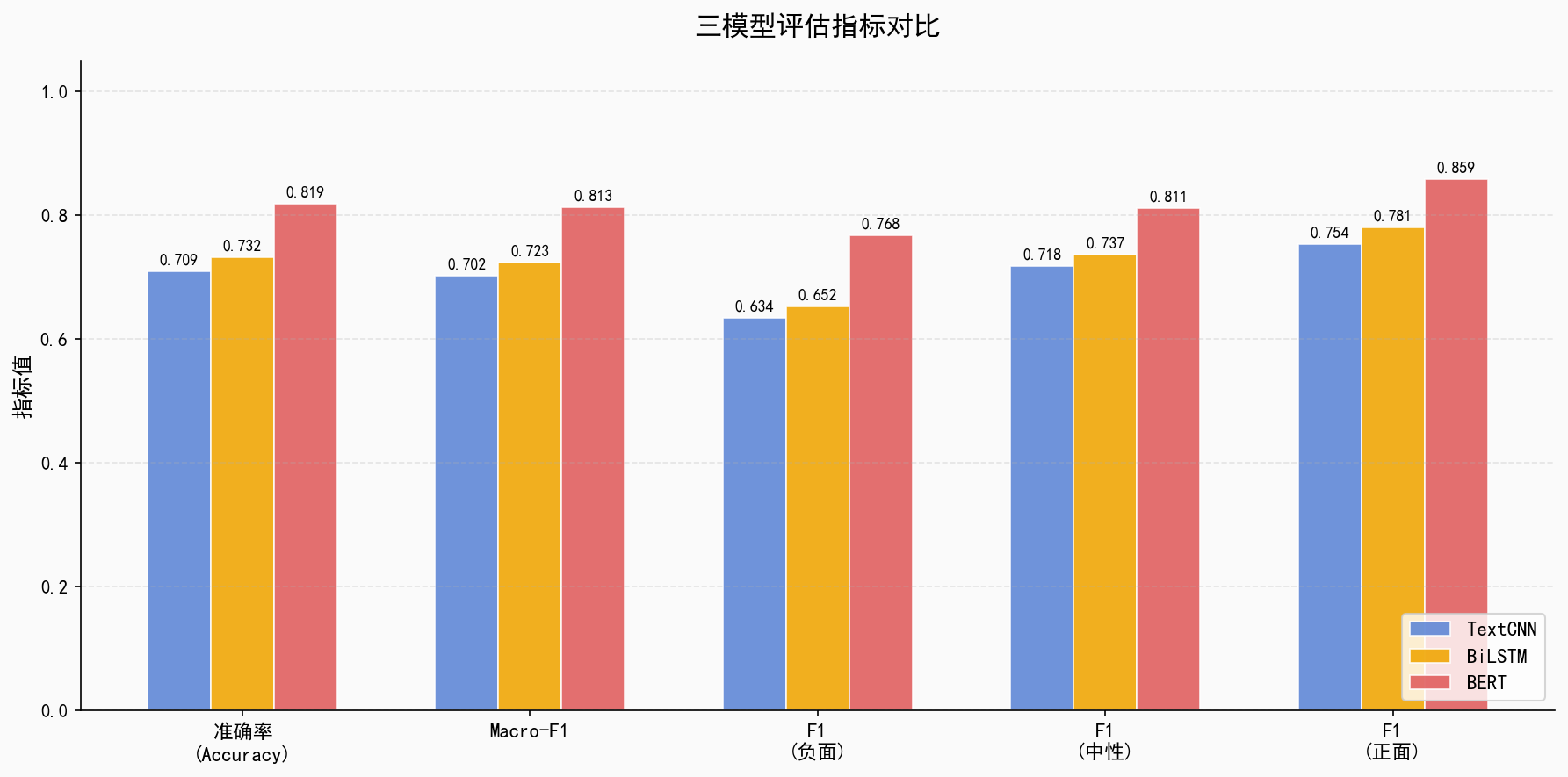
6. 模型选型与对比
本系统选取三种模型进行横向对比实验,涵盖浅层卷积、序列建模和预训练语言模型三个层次,以验证BERT在B站评论情感分析任务上的综合优势:
6.1 方法一:TextCNN
原理:
-
将词向量序列输入卷积层(多种卷积核宽度 h=2,3,4)
-
每种宽度提取局部n-gram特征,Max-pooling聚合
-
全连接层分类
架构:
词嵌入层 (dim=300, 使用预训练词向量)
↓
多尺度卷积层 [filter_sizes: 2,3,4; num_filters: 256]
↓
Max-over-time Pooling
↓
Dropout(0.5) + FC(768→3)
↓
Softmax优点:
-
参数量少,训练快
-
能捕获局部n-gram模式
缺点:
-
感受野有限,难以建模长距离依赖
-
词向量质量依赖预训练语料
6.2 方法二:BiLSTM(双向长短时记忆网络)
原理:
-
双向LSTM同时对正向和反向序列建模
-
最终隐状态拼接作为句子表示
-
可选:加入Attention机制
架构:
词嵌入层 (dim=300)
↓
BiLSTM (hidden_size=256, num_layers=2)
↓
Attention加权池化 / 最后时刻隐状态
↓
Dropout(0.5) + FC(512→3)
↓
Softmax优点:
-
能建模序列上下文和长距离依赖
-
Attention机制提供一定可解释性
缺点:
-
训练速度慢(序列计算难以并行)
-
长文本梯度消失问题依然存在
-
参数初始化敏感,不如Transformer稳定
6.3 方法三:BERT-base-Chinese(本系统主模型)
原理:
-
基于Transformer自注意力机制,双向上下文编码
-
在中文Wikipedia等大规模语料上进行MLM+NSP预训练
-
在目标任务上进行有监督微调(Fine-tuning)
架构(详见第5.3节)
优点:
-
双向Transformer全面捕获上下文语义
-
预训练知识迁移,少量标注即可达高性能
-
对口语化、网络用语有一定泛化能力(Subword Tokenization)
缺点:
-
参数量大(110M),推理速度相对较慢
-
GPU内存占用高(Fine-tuning需至少8GB显存)
-
max_length=512限制(B站评论通常不超128,本任务影响小)
6.4 三模型对比实验设计
| 模型 | 参数量 | 训练时间(估算) | 推理速度 | 预期Macro-F1 |
|---|---|---|---|---|
| TextCNN | ~2M | ~10min | 快 | ~0.80 |
| BiLSTM + Attention | ~5M | ~30min | 中等 | ~0.82 |
| BERT-base-Chinese | 110M | ~60min | 中等 | ~0.88 |
注:以上F1为预期值,实际值依赖标注质量与训练数据规模,需实验验证。
三模型核心差异对比:
| 对比维度 | TextCNN | BiLSTM | BERT |
|---|---|---|---|
| 上下文建模 | 局部n-gram | 单向序列(双向拼接) | 全局双向自注意力 |
| 预训练知识 | 无(词向量可预训练) | 无(词向量可预训练) | 大规模中文语料预训练 |
| 长距离依赖 | 弱 | 中等 | 强 |
| 训练数据需求 | 较多 | 较多 | 少量即可微调 |
| 网络用语处理 | 依赖词表 | 依赖词表 | Subword分词,OOV鲁棒 |
| 推理资源需求 | 低 | 低 | 高(需GPU) |
评估维度:
-
Macro-F1(宏平均F1,对类别不平衡更公平,主要指标)
-
Accuracy(准确率)
-
Confusion Matrix(混淆矩阵,分析各类别误判情况)
-
推理延迟(ms/sample)