一. 简介
1)和map、set类似,unordered_set也是key结构的搜索, unordered_map也是key_value结构的搜索逻辑。
2)unordered_set && unordered_map 和 set && map 功能和使用上高度相似,只是底层结构不同,unordered系列底层是哈希桶 ,而map、set系列底层是红黑树。
3)之所以加一个unordered(无序的)的前缀就是因为,unordered系列底层是哈系统实现,这种结构迭代器遍历的结果是无序的 。
4)unordered系列增删查的效率是O(1),高于map、set,所以只要不是需要有序的场景,都推荐使用unordered系列,效率更高。
二. unordered_set

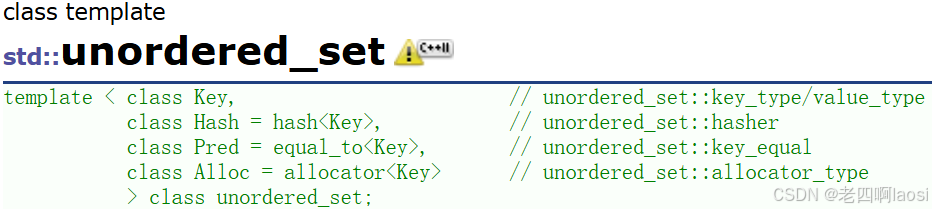
1)模板参数
-
一共四个模板参数,第一个key不用多说了,是 unordered_set底层元素的类型,每个元素也由这个值唯一标识(不允许冗余)。传模板参数时,这个必须传。
-
哈希函数,它的作用是计算哈希值,决定元素在哈希桶中的位置(本篇中所有和哈希有关的内容都需要看完下一篇中的哈希部分才好理解)。
unordered_set默认要求Key支持转换为整型(支持取模运算,和底层哈希表有关),如果不支持或者想按自己的需求走,可以自行实现支持将Key转成整型的仿函数传给第二个模板参数。
- 用来判断两个key是否相等。
unordered_set默认要求Key支持比较相等,如果不支持或者想按自己的需求走,可以自行实现支持将Key比较相等==的仿函数传给第三个模板参数。
-
unordered_set底层存储数据的内存是从空间配置器申请的,如果需要可以自己实现内存池,传给第四个参数。
-
除了key,后三个模板参数通常不需要传,缺省的就够用了。
2)unordered_set和set的差异
由于功能高度相似,只是底层结构不同,有一些性能和使用的差异,所以我们下面只分析他们的差异。
- 第一个差异:对key的要求不同。
① set要求key至少支持<(或>)比较。
② unordered_set要求Key支持转成整型(即支持取模运算)且支持等于==比较。这本质是哈希表的要求,要理解unordered_set的这个两点要求要结合哈希表底层实现来理解。
- 第二个差异:迭代器的差异。
①set 的iterator是双向迭代器 。set底层是红黑树(红黑树是二叉搜索树),迭代器走中序遍历是有序的,所以set迭代器遍历是有序+去重 。
②unordered_set 是单向迭代器 ,不支持倒着走。unordered_set底层是哈希表,迭代器遍历是无序+去重 。
③ set(multiset) 和 unordered_set(unordered_multiset) 都有multi版本,如果不想去重就用各自的mutli。
- 第三个差异:性能差异。
① set 底层是红黑树,增删查改效率是O(logN)。
② 大多数场景下,unordered_set的增删查改更快一些,因为哈希表增删查平均效率是O(1)。
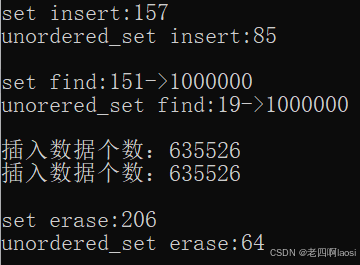
③ 下面有一段对比二者效率(release模式)的代码:
cpp
#include<unordered_set>
#include<unordered_map>
#include<set>
#include<iostream>
using namespace std;
void test01()
{
const size_t N = 1000000;
unordered_set<int> us;
set<int> s;
vector<int> v;
v.reserve(N);
srand(time(0));
for (size_t i = 0; i < N; ++i)
{
//v.push_back(rand()); // N⽐较⼤时,重复值⽐较多
v.push_back(rand() + i); // 重复值相对少
//v.push_back(i); // 没有重复,有序
}
// 有相同的数据分别插入set和unordered_set,看效率
size_t begin1 = clock();
for (auto e : v)
{
s.insert(e);
}
size_t end1 = clock();
cout << "set insert:" << end1 - begin1 << endl;
size_t begin2 = clock();
us.reserve(N);
for (auto e : v)
{
us.insert(e);
}
size_t end2 = clock();
cout << "unordered_set insert:" << end2 - begin2 << endl;
cout << endl;
// 查找
int m1 = 0;
size_t begin3 = clock();
for (auto e : v)
{
auto ret = s.find(e);
if (ret != s.end())
{
++m1;
}
}
size_t end3 = clock();
cout << "set find:" << end3 - begin3 << "->" << m1 << endl;
int m2 = 0;
size_t begin4 = clock();
for (auto e : v)
{
auto ret = us.find(e);
if (ret != us.end())
{
++m2;
}
}
size_t end4 = clock();
cout << "unorered_set find:" << end4 - begin4 << "->" << m2 << endl;
cout << endl;
cout << "插入数据个数:" << s.size() << endl;
cout << "插入数据个数:" << us.size() << endl << endl;
// 删除
size_t begin5 = clock();
for (auto e : v)
{
s.erase(e);
}
size_t end5 = clock();
cout << "set erase:" << end5 - begin5 << endl;
size_t begin6 = clock();
for(auto e : v)
{
us.erase(e);
}
size_t end6 = clock();
cout << "unordered_set erase:" << end6 - begin6 << endl << endl;
}
int main()
{
test01();
return 0;
}所以,如果不是要求遍历出来的结果必须有序,建议使用unordered系列。
三. unordered_map

1)模板参数
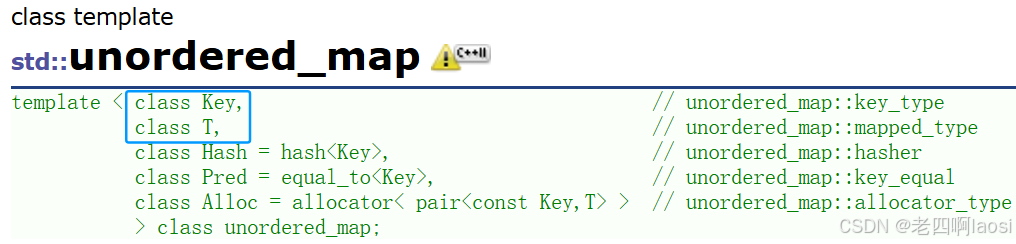
和unordered_set的模板参数区别不大,主要是unordered_map是key_value结构,所以多了一个T类型,就是我们所说的value。
2)unordered_map和map的差异
因为unordered_map在使用上和map基本一模一样,所以我们直接分析差异。
- 第一个差异:对key的要求不同。
① map要求key至少支持<(或>)比较。
② unordered_map要求Key支持转成整型(即支持取模运算)且支持等于==比较。这本质是哈希表的要求,要理解unordered_set的这个两点要求要结合哈希表底层实现来理解。
- 第二个差异:迭代器的差异。
①map 的iterator是双向迭代器 。map底层是红黑树(红黑树是二叉搜索树),迭代器走中序遍历是有序的,所以map迭代器遍历是key有序+去重 。
②unordered_map 是单向迭代器 ,不支持倒着走。unordered_map底层是哈希表,迭代器遍历是key无序+去重 。
③ map(multimap) 和 unordered_map(unordered_multimap) 都有multi版本,如果不想去重就用各自的mutli。
cpp
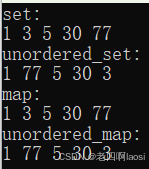
void test02() // 演示有序、无序
{
set<int> s;
s.insert(1);
s.insert(5);
s.insert(5);
s.insert(30);
s.insert(5);
s.insert(3);
s.insert(3);
s.insert(77);
cout << "set: " << endl;
for (const auto& e : s)
cout << e << " ";
cout << endl;
unordered_set<int> us;
us.insert(1);
us.insert(5);
us.insert(5);
us.insert(30);
us.insert(5);
us.insert(3);
us.insert(3);
us.insert(77);
cout << "unordered_set: " << endl;
for (const auto& e : us)
cout << e << " ";
cout << endl;
map<int, int> m;
m.insert({1, 1});
m.insert({5, 5});
m.insert({5, 5});
m.insert({30, 30});
m.insert({5, 5});
m.insert({3, 3});
m.insert({3, 3});
m.insert({77, 77});
cout << "map: " << endl;
for (const auto& e : m)
cout << e.first << " ";
cout << endl;
unordered_map<int, int> um;
um.insert({ 1, 1 });
um.insert({ 5, 5 });
um.insert({ 5, 5 });
um.insert({ 30, 30 });
um.insert({ 5, 5 });
um.insert({ 3, 3 });
um.insert({ 3, 3 });
um.insert({ 77, 77 });
cout << "unordered_map: " << endl;
for (const auto& e : um)
cout << e.first << " ";
cout << endl;
}- 第三个差异:性能差异。
① map底层是红黑树,增删查改效率是O(logN)。
② 大多数场景下,unordered_map的增删查改更快一些,因为哈希表增删查平均效率是O(1)。
③ 所以,如果不是要求遍历出来的结果必须有序,建议使用unordered系列。
四. 哈希相关接口

unordered系列都有这样一组接口,适合哈希桶以及负载因子相关的,下一篇了解完哈希表底层之后就清晰了。平时使用中我们也不需要太关注这几个接口。
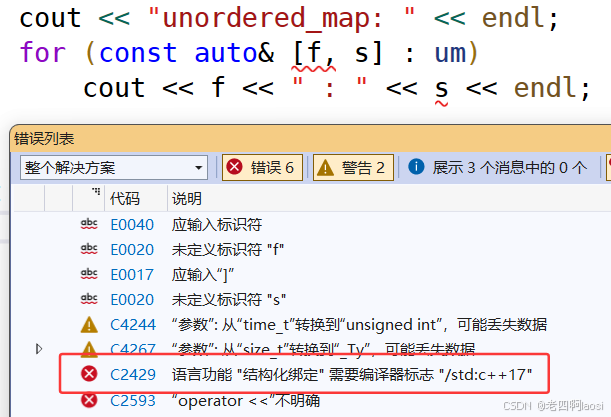
五. 结构化绑定
1)结构化绑定是 C++17 才引入的特性,允许你将一个结构体、元组或数组的成员直接解包到多个独立的变量中。
2)DeepSeek总结的常用的应用场景:

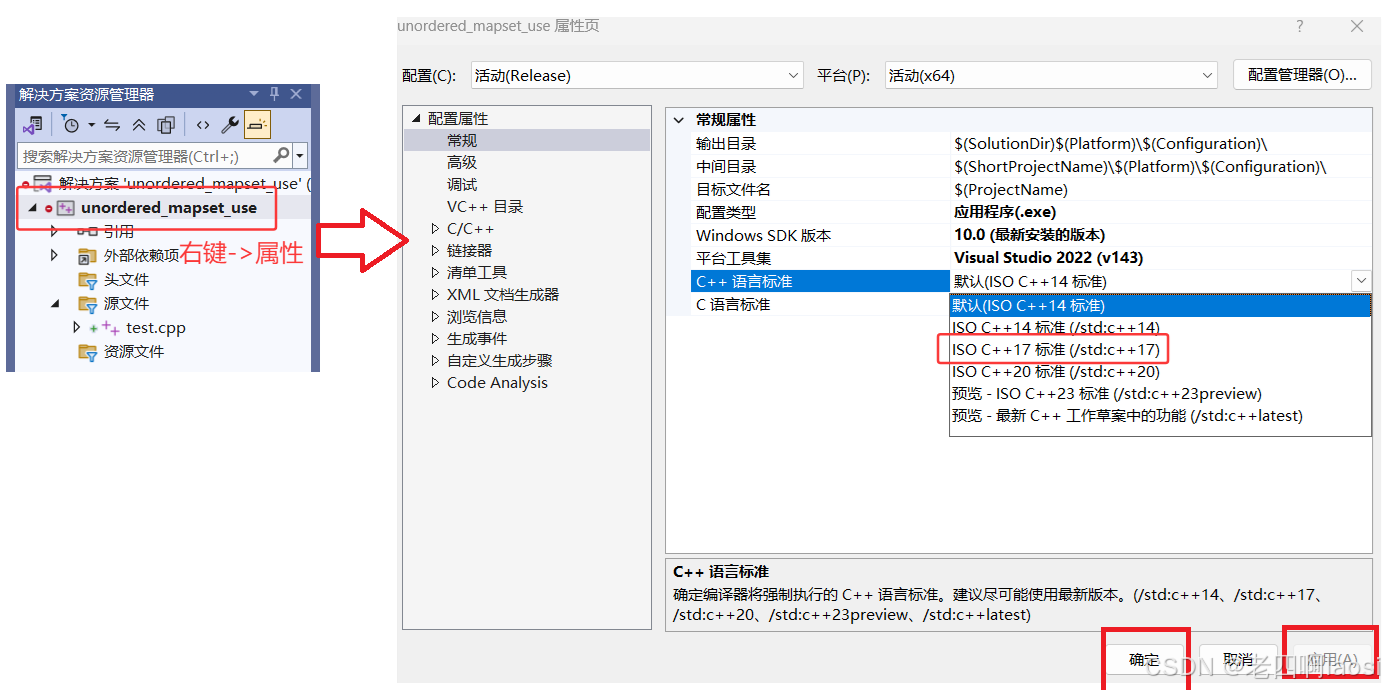
3)我们这里介绍这个新特性就是为了第一种应用,以后输出pair对象时不用.first .second 这样麻烦了。可以直接像下面这样写,不过一定要C++17及以上版本编译器,否则报错。
4)之前的写法是把整个结构体给 e,结构体绑定的这种方法是将结构体解包之后分别给 内的变量。
cpp
void test03() // 结构化绑定
{
unordered_map<int, int> um;
um.insert({ 1, 1 });
um.insert({ 5, 5 });
um.insert({ 5, 5 });
um.insert({ 30, 30 });
um.insert({ 5, 5 });
um.insert({ 3, 3 });
um.insert({ 3, 3 });
um.insert({ 77, 77 });
cout << "unordered_map: " << endl;
for (const auto& [f, s] : um)
cout << f << " : " << s << endl;
}