🏡 微信公众号:GEEKFUN 开源社区-GEEKFUN:www.geekfun.club/zh/
⛳️ 欢迎关注 🐳 点赞 🎒 收藏 ✏️ 留言
文章发布于公众号,获取最新文章,关注极客范
DocKit:geekfun.club/products/do...
jest-search: github.com/geek-fun/je... serverlessInsight:serverlessinsight.com/
昨天 Anthropic 整了个大活,在发布 Claude Code v2.1.88 时不小心把调试文件cli.js.map也给打包进去了,X 上有人直接逆向出来了源码,五十多万行代码就这样水灵灵公之于众。
问题出在 source map 文件(.map)上。当你在 npm 上发布一个 TypeScript 包时,构建工具链会生成这些文件,其作用就是在崩溃时,堆栈追踪可以指向实际的源代码,而不是某个压缩 blob 的第 1 行第 48293 列。
但source map 包含原始源代码 。实际的、字面的、完整的源代码,以字符串形式嵌入 JSON 文件中。 sourcesContent 数组包含了每个文件、每个注释、每个内部常量、每个系统提示词。
json
{
"version": 3,
"sources": ["../src/main.tsx", "../src/tools/BashTool.ts", "..."],
"sourcesContent": ["// 完整的原始源代码", "..."],
"mappings": "AAAA,SAAS,OAAO..."
}最讽刺的是,Anthropic 为了防止内部信息泄露,还专门设计了一个名为 "Undercover Mode" 的完整子系统,然而代码还是泄漏了出去!所以,再厉害的智能,有时候也不如一个 .npmignore 来得实在。
下面,就让我们好好看看到底是怎么个事儿,毕竟,怎么能放弃这么好的学习机会呢。
系统架构以及核心模块
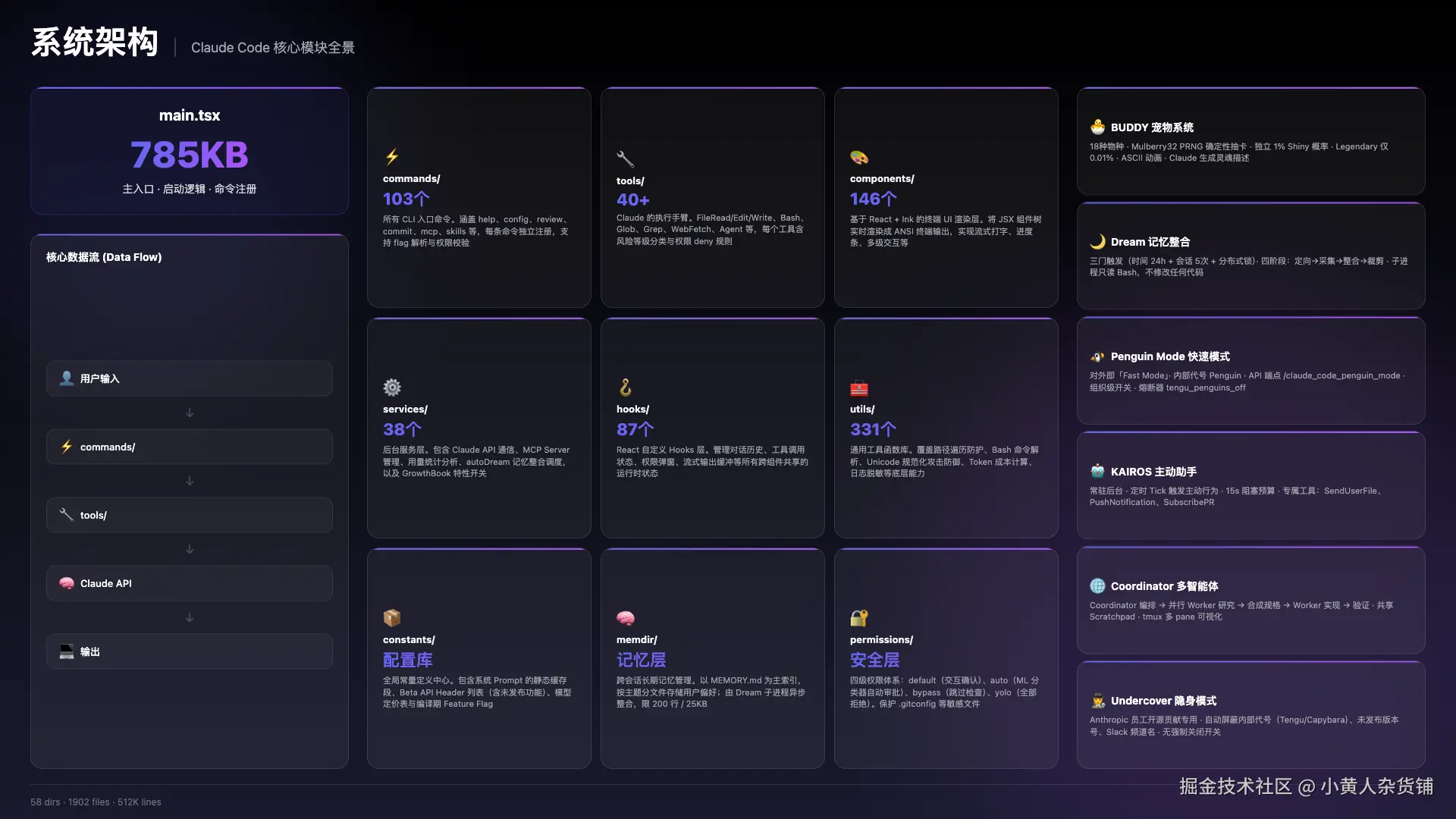
设计特点
1. Harness Engineering:60% 模型 + 40% 工程
Anthropic 自己的提示词就写了:
"Claude Code 的成功不仅仅取决于模型质量。大约 60% 的用户体验来自模型本身,40% 来自你构建的 harness。"
模型能力(60%):理解用户意图、生成代码和操作、推理和规划
工程管理(40%):系统提示词架构、工具权限系统、记忆管理、安全审查、上下文优化、错误恢复
这个比例揭示了一个重要事实:再优秀的模型,也需要精心设计的工程系统,才能实现智能的涌现。
实现模型的领先需要太多的投入且成果如同"万寿帝君练丹"一般未知且不可控,因此 Harness Engineering 才会在今年大行其道,而Claude Code 的源码也验证了其价值。AI 模型天然如同一匹野马,能力强悍的同时,幻觉和发散性也带着强烈的不可控与无法预知,你很难知道它下一步会干什么。而 Harness 其实就是套在它身上的那套设备,就像缰绳和马鞍。
工程管理,具体来说,它包括:
- 模型可用工具管理与调用
- 安全机制
- 记忆系统
- 上下文管理
所有这些其实都是让 AI 的能力从"不可控"的情况,变成稳定可以可靠交付的工程系统。目前 OpenAI 和 Anthropic 都非常推崇 Harness Engineering,而 Claude Code 的源码可以说是 Harness Engineering 的活教程了。
2. 系统提示词动态拼接
Claude Code的提示词系统设计是有一些巧思的,系统提示词不是一整块字符串,而是由模块化、可缓存的章节 在运行时组合而成的 string[] 数组。
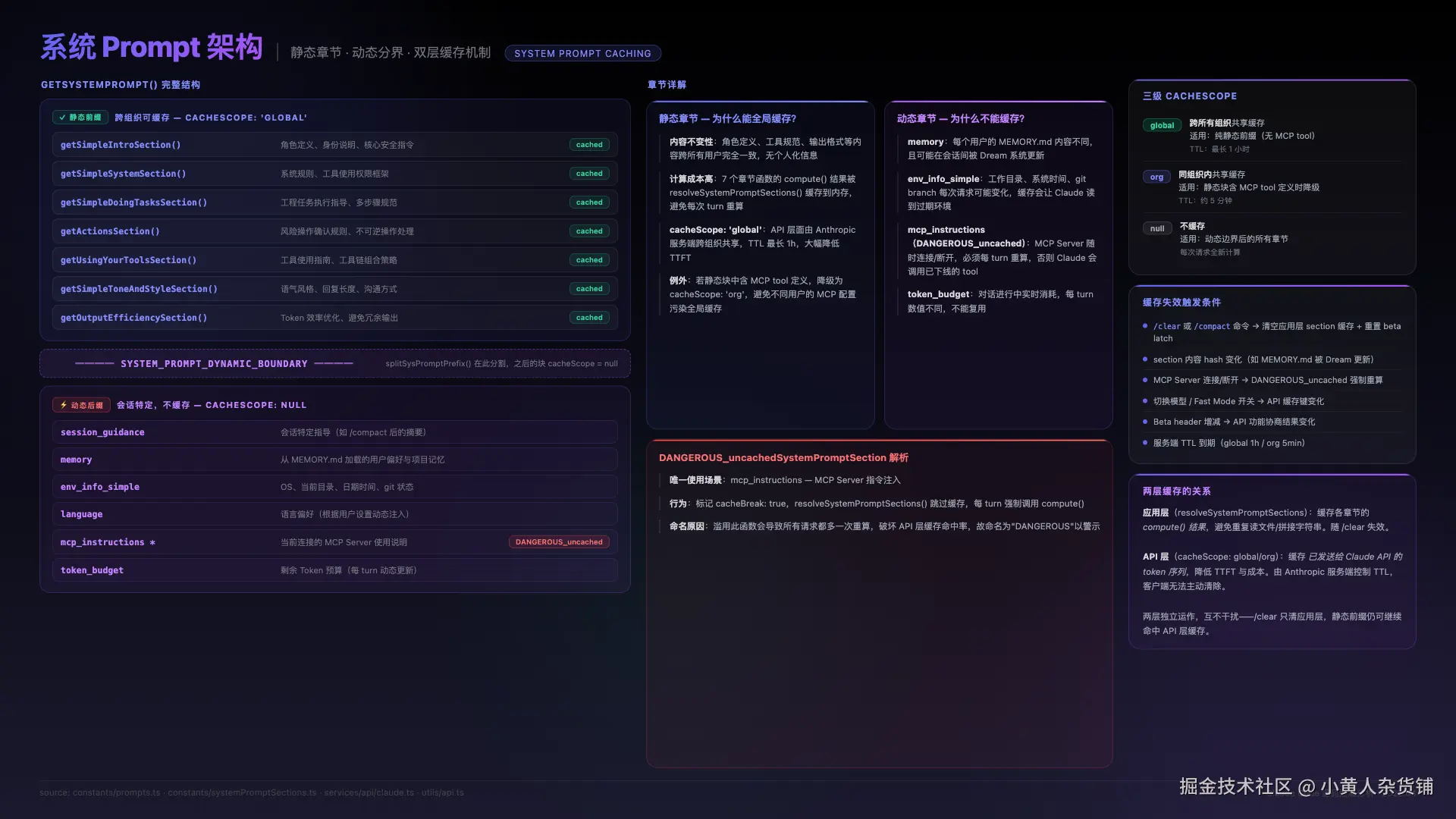
静态部分:全球几百万、上千万个用户都共享同一份缓存,做到了省时省力。包括:你是 Claude Code、不要编造数据、不要随意删文件、优先用专用工具别老用 Bash、不要过度工程、不要加用户没有要求的功能等等。这些写得非常具体不空洞,每一条都是他们踩过坑之后总结出来的。
动态部分 :根据具体的项目,用户在 .claude.md 的自主配置,添加的偏好,用户接入的一些 MCP 的工具,或者你的 Git 仓库是一个什么样的状态等等,它都会动态地进行加载。每个用户甚至每个项目都不一样,这样可以让大模型的回答更加的贴合具体场景。
缓存机制在两个层面运作:
- API 层面 :静态章节使用
cacheScope: 'global'跨组织缓存 - 应用层面 :章节计算结果缓存到
/clear或/compact命令
Dynamic Boundary 设计:这条分界线同时解决了成本问题和定制化问题。上面的静态部分全球用户共享同一份缓存,下面的动态部分每个用户独立加载。
3. Auto 模式背后的四层安全审查
Claude Code 有 7 种权限模式,核心是 auto 模式即 ML 分类器自动审批。
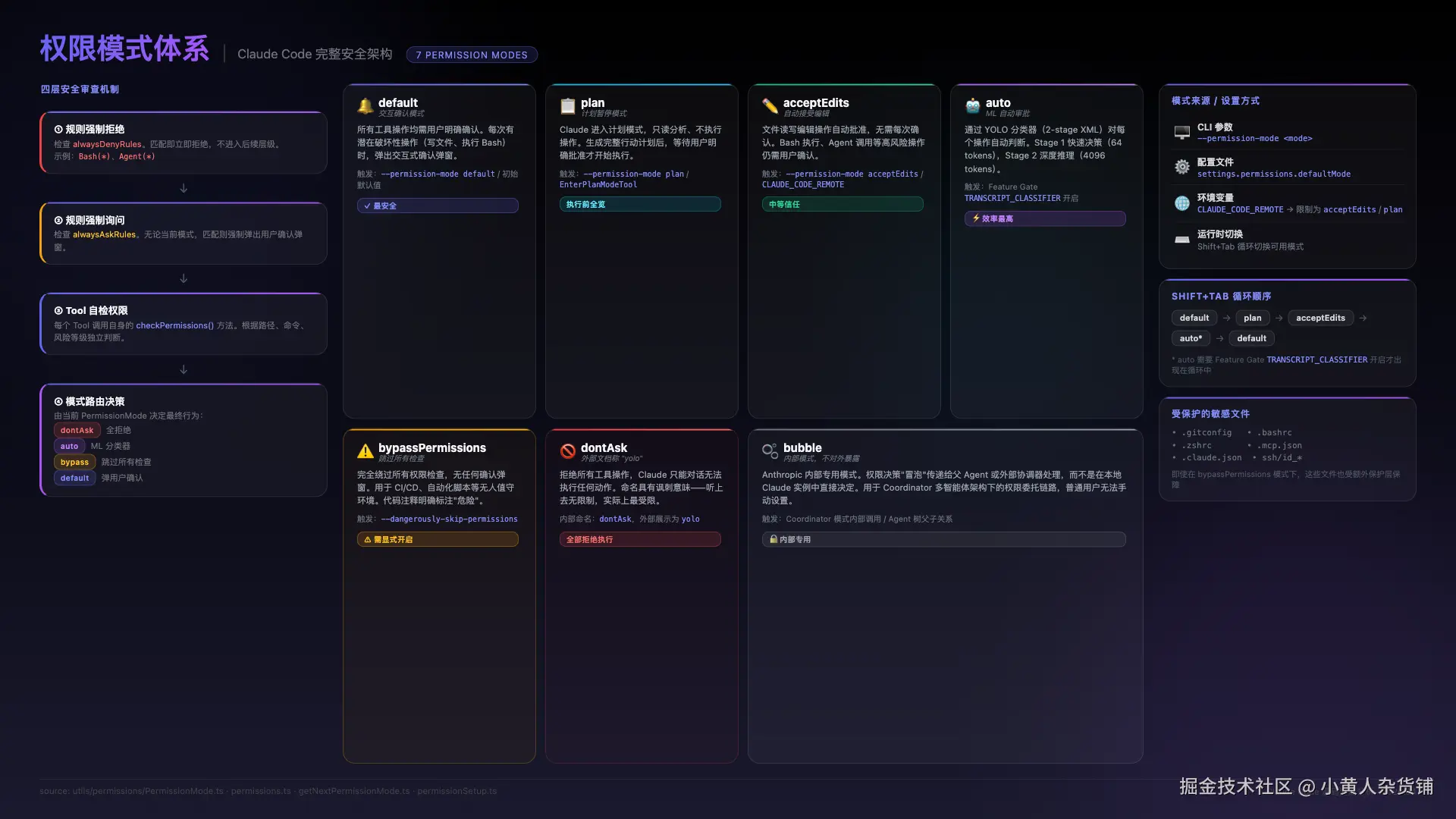
图中中间部分展示了 Shift+Tab 循环顺序 :default → plan → acceptEdits → auto* → default(auto 需要 Feature Gate TRANSCRIPT_CLASSIFIER 开启才出现在循环中)。注意 bypassPermissions 不在循环里------它只能通过 --dangerously-skip-permissions 参数或 CLAUDE_CODE_REMOTE 环境变量激活,属于需要显式开启的"危险模式",正常循环不会触发。
图中左侧的四层安全审查 是 permissions.ts 中决策管线的核心,每层都可以提前终止并返回结果,按顺序执行:
第一层:规则强制拒绝 (alwaysDenyRules)最先执行。检查用户或组织配置的黑名单规则,如 Bash(*) 或 Agent(*),命中即拒绝,流程直接终止,不进入后续层。这是最强的拦截,优先级最高。
第二层:规则强制询问 (alwaysAskRules)无论当前是哪种模式,命中都强制弹出用户确认弹窗。注意这里有一个关键的 bypass-immune 设计:当工具的 checkPermissions() 返回 decisionReason.type === 'safetyCheck' 时(对应 .gitconfig、.bashrc、.mcp.json、.claude.json、ssh/id_* 等敏感文件路径),即使在 bypassPermissions 模式下也无法跳过,必须询问用户。这些文件一旦被篡改后果往往是灾难性的(可能下个版本就有*.js.map啦,哈哈哈)。
第三层:Tool 自检权限 (checkPermissions())每个工具有自己的权限自检逻辑,根据路径、命令、风险等级独立判断,返回 allow、ask 或 deny。比如 FileEditTool 会检查目标路径是否在工作目录内,BashTool 会分析命令的危险等级。
第四层:模式路由决策 (PermissionMode)前三层全部通过后,才由当前模式决定最终行为:
dontAsk→ 全部拒绝执行(即外部文档说的"yolo",反直觉但符合"不要问,直接拒"的语义)auto→ 交给 ML 分类器(YOLO Classifier)自动裁决bypass→ 跳过所有剩余检查,直接允许(但第一二层已经拦截了真正危险的操作)default→ 弹出用户确认弹窗
这个四层设计的精妙之处在于:bypassPermissions 看似无所不能,实际上它只是跳过了第四层的"询问"动作 前三层的规则拦截、ask 规则、敏感文件保护早已在它之前执行完毕,真正危险的操作根本走不到第四层。
YOLO 分类器(Layer 4 中 auto 模式的核心)在性能上做了"成本递增"的快速路径梯队:先判断是否符合 acceptEdits 条件(工作目录内的安全编辑,无需 AI 调用)→ 再看是否在安全工具白名单(只读工具,跳过分类器)→ 最后才触发真正的 ML 分类器 API 调用。这样大多数日常操作不会引发额外的 AI 查询开销。
拒绝追踪 (Denial Tracking)是一个防死循环的工程细节:当分类器连续拒绝 3 次或累计拒绝 20 次,系统会从"自动拒绝"降级为"弹用户确认",避免 Agent 陷入无限拒绝循环。在无头模式(CI/CD)下达到上限则直接抛出 AbortError 终止,防止无效 token 消耗。
Layer 4c 中的 YOLO 分类器是整个管线里最有趣的部分,值得单独展开:
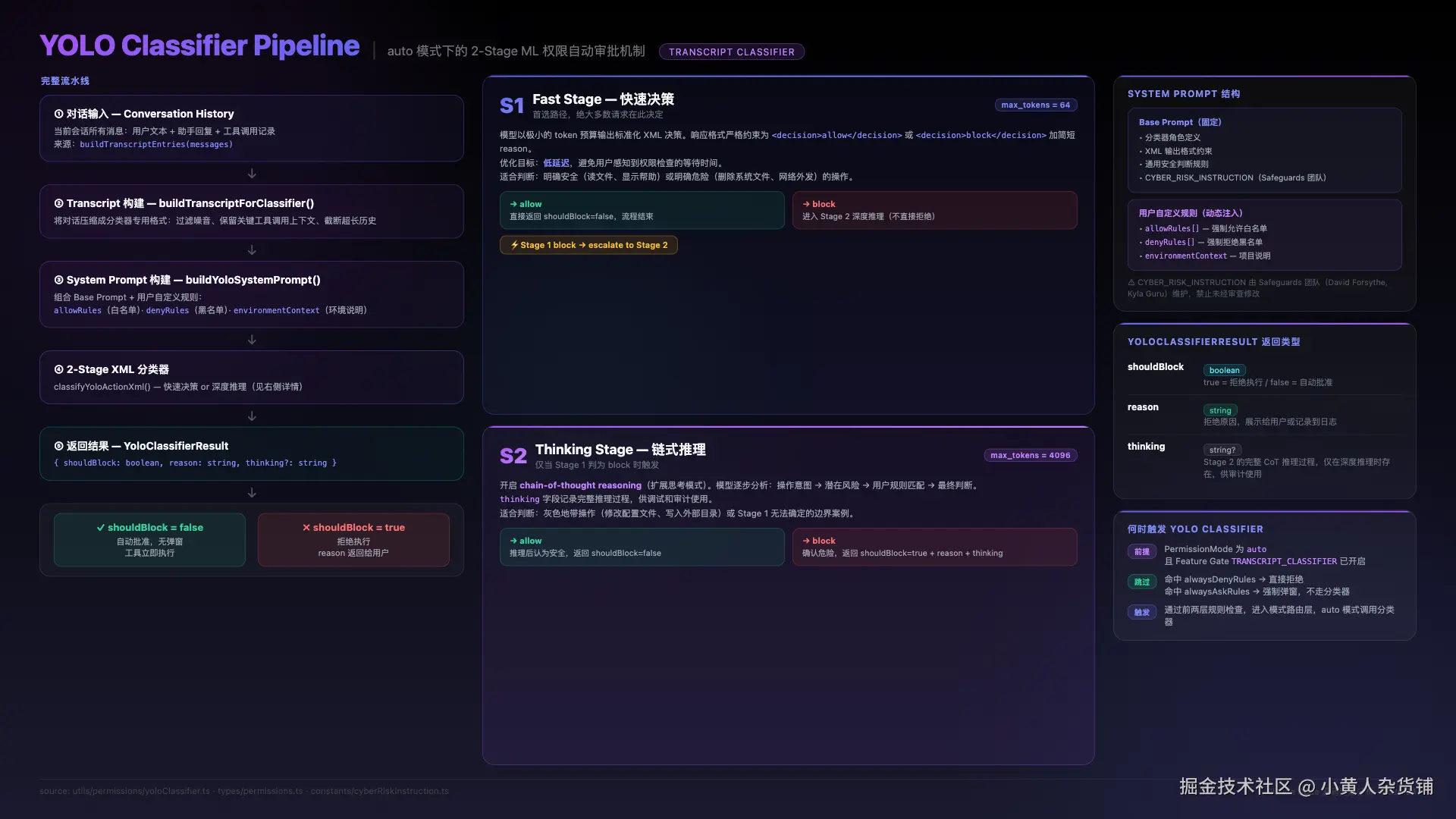
YOLO 就是"you only live once",但它实际做的事情其实不太 YOLO------每次主 AI 想要去执行一个操作的时候(比方说跑一条命令、写一个文件),其实都会有一个独立的 AI 分类器去判断这个操作到底安不安全。这个分类器有自己的系统提示词,跟主 AI 完全不同,它是专门用来做安全审查的。
判断主要分为三种:
- Allow:安全的直接放行
- Soft Deny:需要谨慎,会降级成需要你确认的
- Hard Deny:直接拦截,你改不了这个规则的
正如我们一开始在AI编程,龙虾里面经常听到用户的文件被删除了,就是没有这样独立提示词上下文的分类器(也可以说是独立sub-agent)来做检查,一旦上下文被污染,误操作也就自然而然了,这其实就是一个Claude Code在工程化上优化得比较好的方面。
4. IDE 桥接
Claude Code 支持通过 MCP(Model Context Protocol)与外部工具和服务桥接。MCP 其实是一个比较消耗 token 的服务,几乎每一个 MCP 工具定义都会消耗几千个 tokens,每一个MCP都有实实在在的 token 成本,这也是为什么很多人更多用 skill 而不是 MCP 的原因。
针对这个问题,Claude Code 在源码层面做了四层 token 优化:
① 懒加载 + ToolSearchTool(最核心) :默认情况下所有 MCP 工具都标记为 defer_loading: true,从 API 请求中移除,不预加载。只有当 AI 真正需要某个工具时,才通过 ToolSearchTool 按需发现并加载。这套机制有三档模式(ENABLE_TOOL_SEARCH 环境变量控制):
| 模式 | 触发条件 |
|---|---|
tst(默认) |
始终懒加载,MCP 工具永不预加载 |
tst-auto |
超过 context window 的 N%(默认 10%)才懒加载 |
standard |
禁用,所有工具全部预加载(旧行为) |
② Tool Schema 缓存(防缓存抖动) :工具 schema 在 API 请求中处于第 2 个位置(system prompt 之前),任何字节变化都会让整个约 11K token 的工具块及其下游全部缓存失效。源码注释揭示了三个导致字节抖动的根因:GrowthBook 特性开关翻转(tengu_tool_pear 等 flag 中途变化)、MCP 服务器重连、tool.prompt() 里的动态内容。toolSchemaCache.ts 在 session 第一次渲染时锁定 schema 字节,此后任何"重渲染"事件都不改变实际发出的内容。
③ MCP 指令 Delta 系统(防 system prompt 缓存失效) :原来 MCP 服务器连接时的 instructions 通过 DANGEROUS_uncachedSystemPromptSection() 每轮重建注入 system prompt,每次晚连接都打断 prompt cache。新的 Delta 系统(mcpInstructionsDelta.ts)改为用持久化 attachment 宣告变更------只记录 addedNames / removedNames,每轮扫描历史 attachment 重建当前指令集,system prompt 本身保持静态,prompt cache 不再被打断。
④ Deferred Token 分类追踪 :上下文分析时区分 isLoaded(已加载,计入实际 context 占用)和 isDeferred(懒加载未触发,不计入)两类 MCP token,auto-compact 触发阈值也只看 loaded 部分,避免未使用工具的"幽灵成本"影响压缩决策。
5. 记忆与上下文管理
5.1 设计理念:只记偏好,不记代码
Claude Code 的记忆系统遵循一个非常巧妙的设计理念:只记偏好,不记代码。
原因很直接:代码会变化,今天写的函数明天可能就重构了。如果记忆里存了"函数 X 在第 30 行",代码一重构这条记忆就变成误导。所以 Claude Code 的做法是:记忆只存人的判断与偏好,代码内容永远去源文件里实时读取。
bash
~/.claude/projects/<project-slug>/memory/
├── MEMORY.md # 索引文件(<200 行,~25KB,每条目 <150 字符)
├── preferences.md # 用户偏好(TS 风格、书写习惯等)
├── project-structure.md # 项目结构说明
├── testing.md # 测试规范
└── debugging.md # 调试技巧MEMORY.md 是纯索引,不存内容------格式固定:- [Title](file.md) --- 一行摘要,超过限制会被 autoDream 剪枝。
5.2 双引擎记忆提取机制
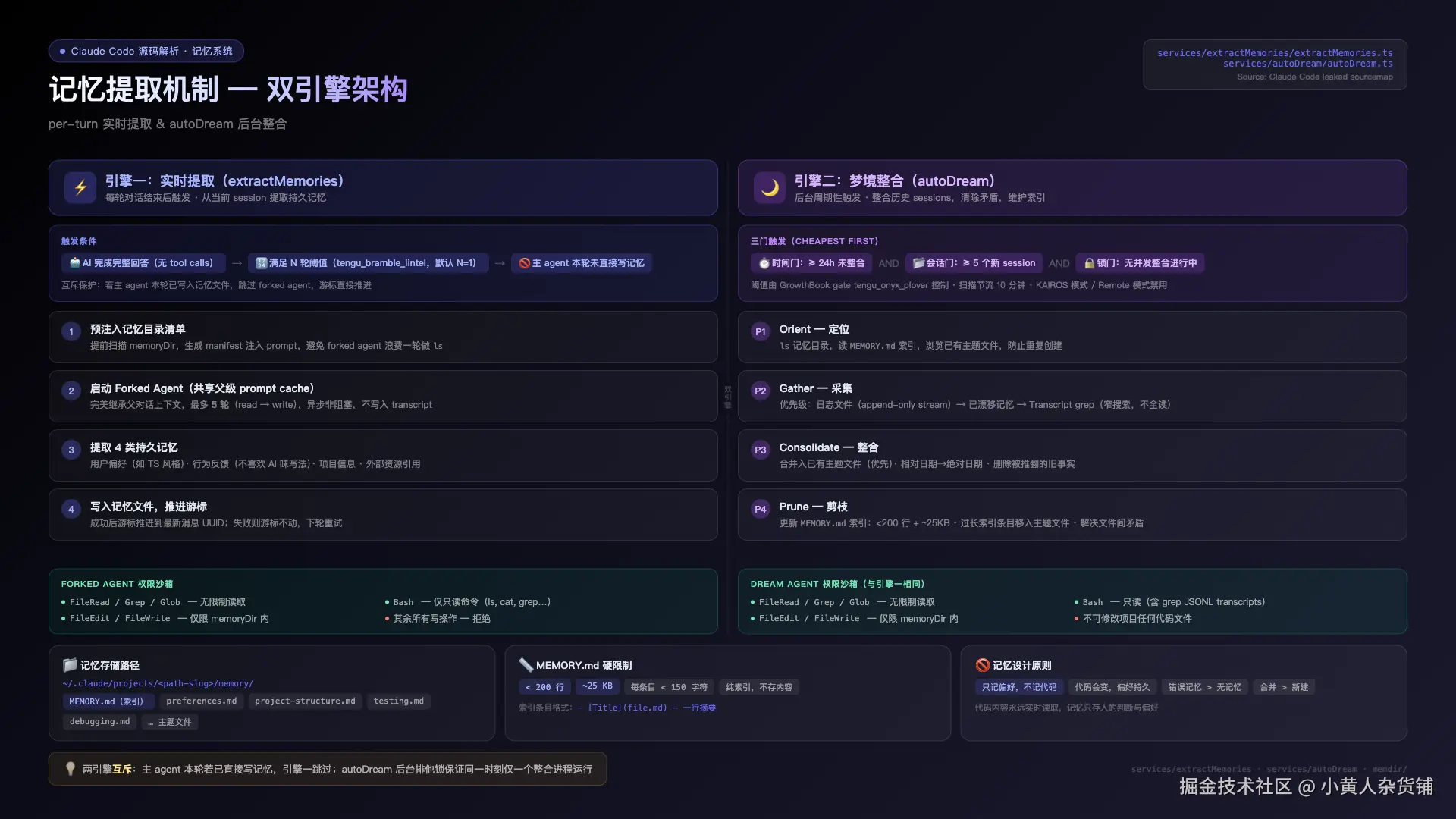
记忆系统由两个引擎驱动,分工明确、互不干扰:
引擎一:实时提取(extractMemories) --- 每轮对话结束时运行
触发条件(三者同时满足):
- AI 完成完整回答(无后续 tool calls)
- 满足 N 轮阈值(GrowthBook
tengu_bramble_lintel控制,默认每轮触发) - 主 agent 本轮未直接写入记忆文件(互斥保护)
触发后启动一个 forked agent ,完整继承父对话的 prompt cache,最多执行 5 轮(read → write)。运行时会预扫描记忆目录生成 manifest 注入 prompt,避免浪费一轮做 ls。提取出的记忆分四类:用户偏好、行为反馈、项目信息、外部资源引用。
引擎二:autoDream 梦境整合 --- 后台周期性整合历史
三门触发,按成本从低到高依次检查:
- 时间门:距上次整合 ≥ 24 小时
- 会话门:上次整合后 ≥ 5 个新 session(不含当前 session)
- 锁门:获取排他锁,防止并发整合
三门全开后,启动 forked subagent 执行四阶段整合:
| 阶段 | 工作内容 |
|---|---|
| Phase 1 --- Orient | ls 记忆目录,读 MEMORY.md,浏览主题文件防重复 |
| Phase 2 --- Gather | 优先读日志 → 漂移记忆 → 窄搜索 transcript JSONL |
| Phase 3 --- Consolidate | 合并入已有文件,相对日期→绝对日期,删除被推翻的旧事实 |
| Phase 4 --- Prune | 更新 MEMORY.md 索引,维持 <200 行 + ~25KB,解决文件间矛盾 |
两个引擎共用同一套权限沙箱 :FileRead/Grep/Glob 无限制,Bash 仅只读命令(ls、cat、grep 等),FileEdit/FileWrite 仅限 memoryDir 内,其余写操作一律拒绝。
5.3 上下文压缩
当对话上下文过长时,Claude Code 会自动触发压缩。压缩不是简单截断,而是用一套结构化九段式模板提取关键信息:
- 核心请求 → 2. 关键概念 → 3. 文件与代码 → 4. 错误与恢复 → 5. 解决过程 → 6. 所有用户消息 → 7. 待办任务 → 8. 当前工作 → 9. 下一步指南
这套模板确保压缩后的上下文仍能让 AI 快速恢复工作状态,最核心的内容基本能完整保留。
5.4 搜索策略:不用 RAG,只用 Grep
很多人谈到 AI 编程工具时,第一反应是向量数据库、embedding 索引、RAG 检索。但 Claude Code 的选择完全相反------根本不用 RAG,直接搜代码。
搜索主力是 Grep:没有 embedding,没有语义匹配,没有向量数据库。
逻辑很清晰:上下文窗口足够大(1M token 可装下整个代码库),grep 正则精确不会误匹配,本地搜索毫秒级响应。更关键的是------与其把检索逻辑做复杂,不如让 AI 用自主能力决定怎么搜,随着模型越来越强,这个选择越来越合理。
6. BUDDY - 终端宠物系统
Claude Code 还引入了一个完整的Tamagotchi 风格伴侣宠物系统 ,名为"Buddy"。这是一个确定性扭蛋系统,具有物种稀有度、闪光变体、程序化生成的属性。
稀有度权重表:
| 稀有度 | 权重 | 概率 | 星级 |
|---|---|---|---|
| Common | 60 | 60% | ★ |
| Uncommon | 25 | 25% | ★★ |
| Rare | 10 | 10% | ★★★ |
| Epic | 4 | 4% | ★★★★ |
| Legendary | 1 | 1% | ★★★★★ |
闪光概率彩蛋 :Shiny Legendary = 1% × 1% = 0.01%(万分之一)
彩蛋 - 未发布的隐藏功能
除了上面的这些,源码里还有很多在prod中关闭的 Feature Flags ,暴露了它未来的一些方向。
KAIROS - 永远在线的 Claude
持久运行的 Claude 助手,不需要等待输入,主动观察和采取行动。
- 日志系统:维护追加式日志文件,记录观察、决策和行动
- Tick 提示 :定期接收
<tick>提示,决定是否主动行动 - 15 秒预算:超过 15 秒的阻塞操作会被延迟执行
- Brief 模式:极简输出模式,避免淹没终端
ULTRAPLAN - 30 分钟远程规划
将复杂规划任务卸载到远程 CCR 会话,运行 Opus 4.6,最多 30 分钟思考时间。
识别任务 → 启动 CCR → 轮询结果 → 浏览器审批 → Teleport 回本地Penguin Mode - 快速模式
内部称为"Penguin Mode"的快速响应模式,通过 API Beta Headers 启用:
fast-mode-2026-02-01redact-thinking-2026-02-12afk-mode-2026-01-31
Coordinator Mode - 多智能体编排
支持并行管理多个工作智能体,实现研究、合成、实现、验证的完整流程。
scss
研究阶段 (Workers 并行) → 合成阶段 (Coordinator) → 实现阶段 → 验证阶段核心原则:"Parallelism is your superpower. Workers are async. Launch independent workers concurrently whenever possible."
尾巴:一鲸落,万物生
在各家 agent 你来我往打得正火热的时候,Anthropic 这一波操作让局势骤然变得有意思起来。
AI agent 在代码能力层面的跃升如同内燃机问世------手工敲代码的时代已经回不去了。但随之而来的是一个新问题:AI 写出的代码,人类已经不可能 line by line review,这个工程量甚至比写代码本身更耗时。所以,未来真正值钱的不是某个版本的模型,而是那套踩过无数坑后沉淀下来的 harness prompts、rules 和工程化共识 ------那才是业界真正的 know-how 财富。谁能把这套 Harness 搭得更好,谁就更有机会。
Claude Code 确实有强大的飞轮:它越强,就越能帮 Anthropic 把自己做得更强。52 天 74 次发布,Claude Code Work、手机远程控制、企业应用市场......这个速度,其他产品很难正面追。
但这次泄漏,相当于把 v2.1.88 的整套设计图纸公开了。起跑线,在这一刻重置了一次。
更有意思的是:借助 agent 工具本身,任何团队都可以左脚踩右脚------用 AI agent 来快速复制、迭代、甚至超越这套 agent 架构。站在巨人的肩上,肩上的人也能成为新的巨人。后面各个 agent 的质量肯定会比 v2.1.88 好不少,要是还不如,那也不用发布了(照着抄你都抄不对)。