名人说:工欲善其事,必先利其器。------《论语·卫灵公》
创作者:Code_流苏(CSDN) (一个喜欢古诗词和编程的Coder😊)目录
- [一、DeepSeek V4 Flash是什么?](#一、DeepSeek V4 Flash是什么?)
- 二、第一感受:快,是最明显的体验
- 三、多场景实测:我准备了这些问题来测试它
- [1. 日常科普](#1. 日常科普)
- [2. 文案写作](#2. 文案写作)
- [3. 长文总结](#3. 长文总结)
- [4. 编程能力](#4. 编程能力)
- [5. 代码解释](#5. 代码解释)
- [6. 逻辑推理](#6. 逻辑推理)
- [7. 指令遵循](#7. 指令遵循)
- [8. 表格整理](#8. 表格整理)
- [9. 角色扮演](#9. 角色扮演)
- 四、综合体验:中文自然,日常任务够用
- 五、它适合哪些人?
- [1. 普通用户](#1. 普通用户)
- [2. 内容创作者](#2. 内容创作者)
- [3. 开发者](#3. 开发者)
- 六、局限性:别把Flash当万能模型
- 七、总结:不是最强,但很实用
很高兴你打开了这篇博客,更多AI知识,请关注我、订阅专栏《AI知识图谱》,内容持续更新中...
大家好,我是流苏👋 ,今天我们来聊聊最近很值得关注的一款国产大模型:DeepSeek V4 Flash。
如果说 DeepSeek V4 Pro 更像是"性能拉满的旗舰选手",那么 DeepSeek V4 Flash 就更像是一位轻装上阵的效率型助手。

它的特点很明显:响应更快、成本更低、日常任务处理更顺手。
对于普通用户和开发者来说,很多时候我们并不一定需要最强模型,而是需要一个"够聪明、够快、够稳定"的模型。DeepSeek V4 Flash 正好就是这样的定位。
一、DeepSeek V4 Flash是什么?
简单来说,DeepSeek V4 Flash 是 DeepSeek V4 系列中的高效版本。
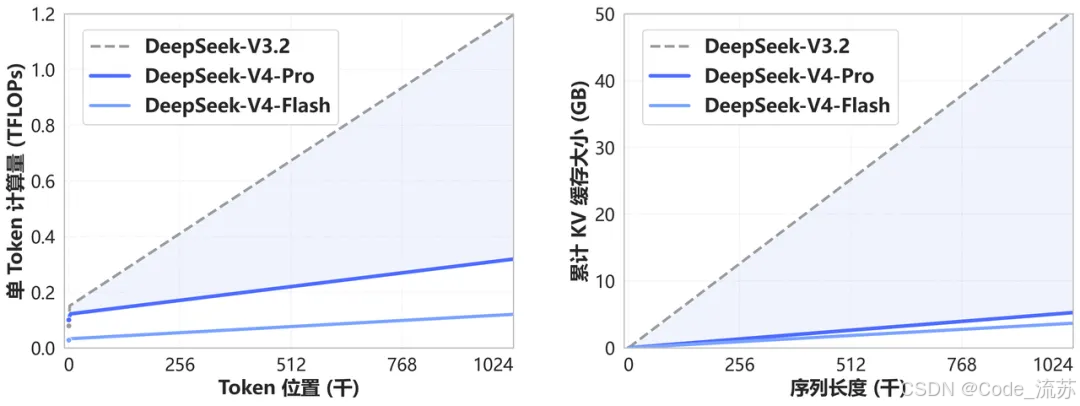
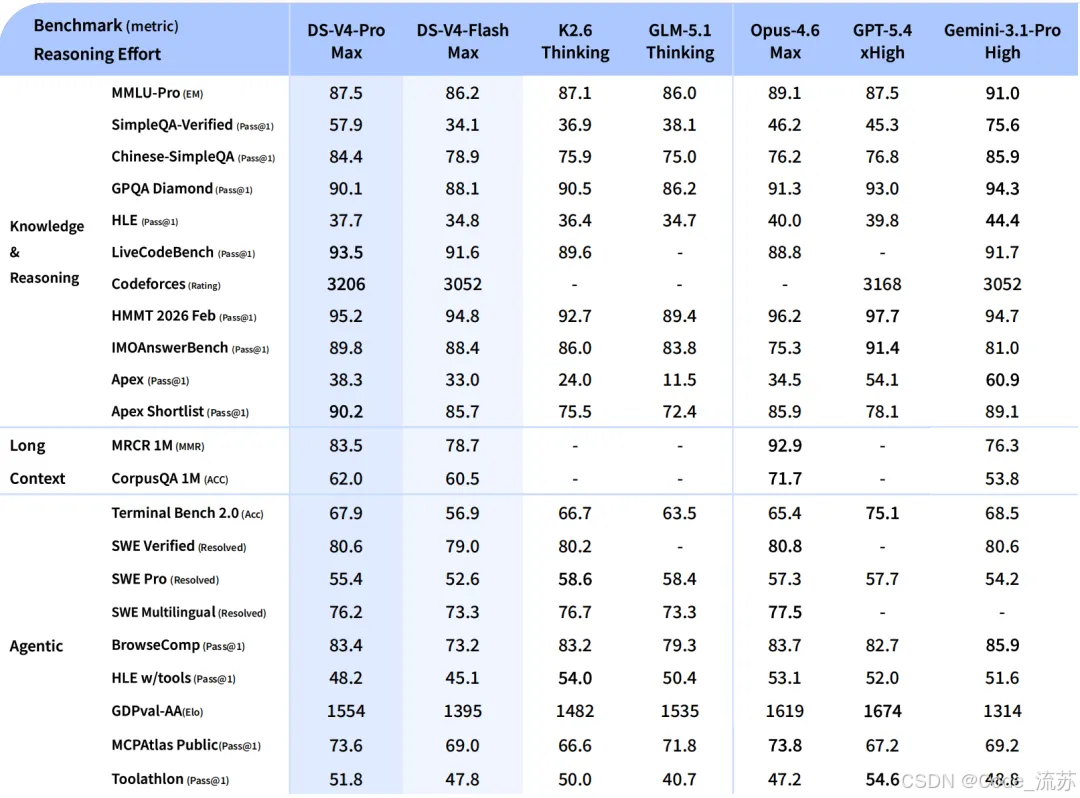
它主打的不是极限推理能力,而是更适合日常高频使用,比如:
- 写文章、写周报
- 总结文档
- 解释代码
- 翻译润色
- 生成脚本
- 简单逻辑推理
- 长文本阅读与整理
举个例子:
如果你只是想让 AI 帮你总结一篇文章,却每次都调用最强模型,就像是:
买瓶矿泉水,却派了一辆重卡去送。
当然能送,但多少有点"用力过猛"。
而 DeepSeek V4 Flash 更像是一辆灵活的小电动车:速度快、成本低,大部分日常任务都能轻松搞定。
二、第一感受:快,是最明显的体验
我对 DeepSeek V4 Flash 的第一印象就是:响应很快。
尤其是在一些常见任务里,比如让它写一段说明、总结一篇文章、改一段文案、解释一段代码,整体体验都比较流畅。
它不会每次都"深思熟虑"半天,而是更偏向快速给出结果。
这种体验在日常使用中很重要。
因为我们平时问 AI 的问题,大多数并不是超级复杂的数学证明,也不是大型项目架构设计,而是一些更实用的小任务:
帮我整理一下这段内容。
帮我写个标题。
帮我解释这个报错。
帮我生成一个周报模板。
这些场景里,Flash 的优势就很明显。
三、多场景实测:我准备了这些问题来测试它
为了更直观地体验 DeepSeek V4 Flash 的实际能力,我准备了几个常见问题,分别测试它的中文表达、总结能力、代码能力、逻辑推理、指令遵循和结构化输出。
1. 日常科普
我:用通俗的话解释一下,为什么大模型会出现"幻觉"?
这个问题主要测试模型的科普表达能力。
一个好的回答,不应该只是堆概念,而是要能让普通用户听懂。
DeepSeek V4 Flash 在这类问题上的表现比较自然。它通常会先解释"幻觉"是什么,再用生活化的例子辅助理解。
比如可以把大模型幻觉理解成:
学生没复习好,但又必须回答问题,于是根据印象编出了一个看似合理的答案。
这种解释方式就比较适合小白阅读,不会太学术,也不会太生硬。
2. 文案写作
我:帮我写一段介绍 DeepSeek V4 Flash 的短文,要求适合 CSDN 博客开头,语气自然一点,不要太官方。

这个问题主要测试模型的中文写作能力。
我重点观察了几点:
- 语气是否自然
- 是否有博客感
- 有没有明显 AI 味
- 内容是否清楚
- 会不会写得太空泛
整体来看,DeepSeek V4 Flash 在中文内容生成上表现不错。
它生成的内容比较顺,不会特别"翻译腔",也不会一上来就堆一堆官方术语。对于 CSDN 博客、公众号文章、技术教程这类内容,它可以很好地完成初稿。
当然,AI 写出来的内容还是需要自己再润色一下。
毕竟真正有个人风格的文章,还是要靠作者自己打磨。
3. 长文总结
我:请把下面这段技术文章总结成 5 个要点,并用适合小白理解的方式解释。

这个问题主要测试模型的信息提炼能力。
好的总结不只是简单压缩文字,而是要能抓住重点,并重新组织语言。
我比较关注它能不能做到:
- 提炼核心观点
- 分点清晰
- 语言通俗
- 不遗漏关键信息
- 不加入太多无关内容
从体验来看,DeepSeek V4 Flash 在总结类任务上比较稳,尤其适合处理技术文章、产品说明、会议纪要、学习资料等内容。
现在资料越来越多,真正难的不是"找资料",而是:
如何快速看懂资料,并整理成自己的东西。
在这方面,DeepSeek V4 Flash 的确能节省不少时间。
4. 编程能力
我:用 Python 写一个脚本,读取 CSV 文件,并统计每一列的缺失值数量和缺失值比例。
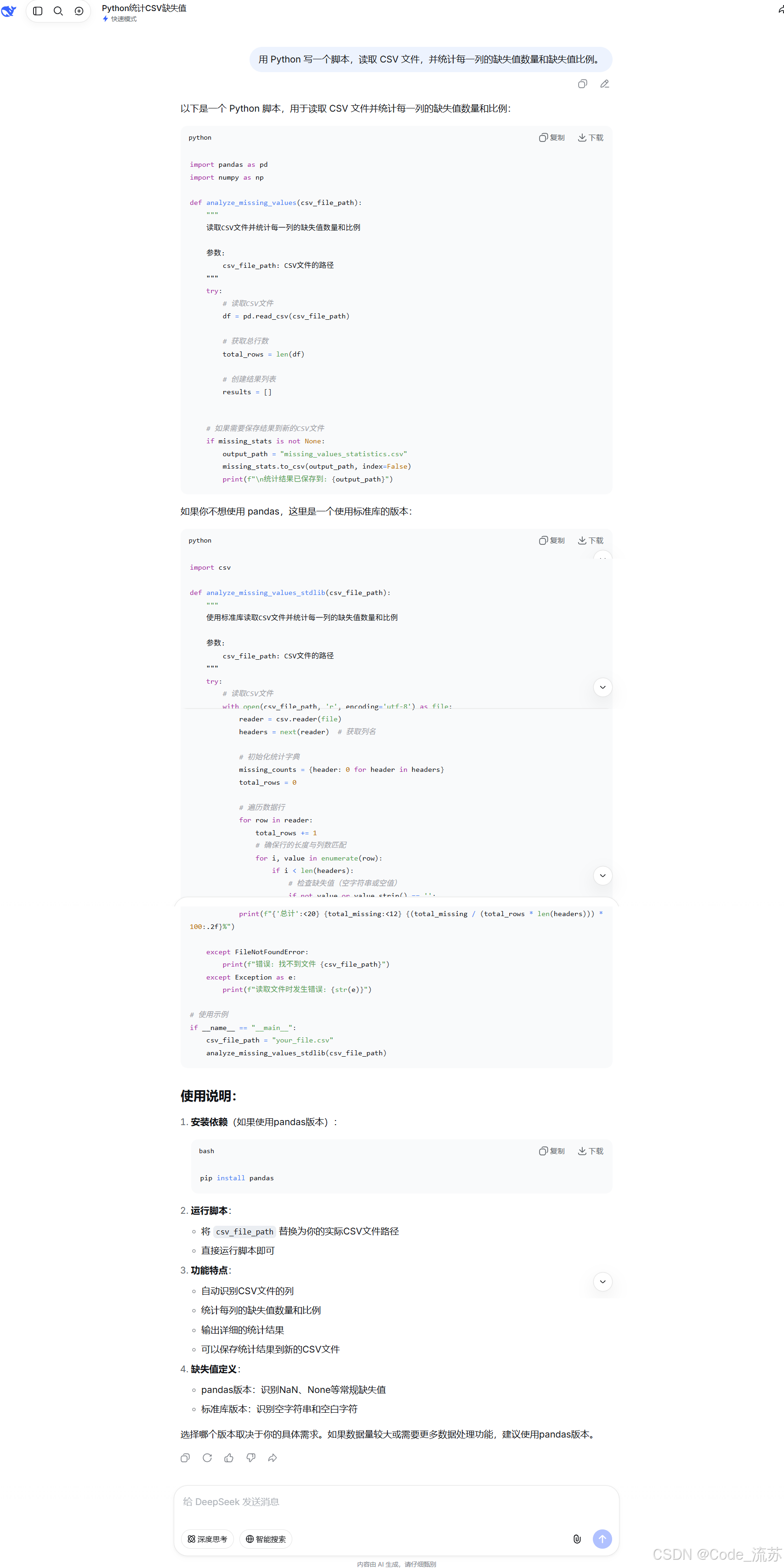
这个问题主要测试它的基础代码生成能力。
这类任务虽然不算难,但很贴近日常开发。
它通常能快速生成类似这样的代码:
python
import pandas as pd
import numpy as np
def analyze_missing_values(csv_file_path):
"""
读取CSV文件并统计每一列的缺失值数量和比例
参数:
csv_file_path: CSV文件的路径
"""
try:
# 读取CSV文件
df = pd.read_csv(csv_file_path)
# 获取总行数
total_rows = len(df)
# 创建结果列表
results = []
# 统计每一列的缺失值
for column in df.columns:
# 计算缺失值数量
missing_count = df[column].isnull().sum()
# 计算缺失值比例
missing_ratio = (missing_count / total_rows) * 100
results.append({
'列名': column,
'缺失值数量': missing_count,
'缺失值比例(%)': round(missing_ratio, 2)
})
# 创建结果DataFrame
result_df = pd.DataFrame(results)
# 输出统计结果
print(f"CSV文件: {csv_file_path}")
print(f"总行数: {total_rows}")
print("\n缺失值统计:")
print(result_df.to_string(index=False))
# 输出整体统计信息
total_missing = sum([r['缺失值数量'] for r in results])
print(f"\n总体缺失值数量: {total_missing}")
print(f"总体缺失值比例: {(total_missing / (total_rows * len(df.columns))) * 100:.2f}%")
return result_df
except FileNotFoundError:
print(f"错误: 找不到文件 {csv_file_path}")
return None
except Exception as e:
print(f"读取文件时发生错误: {str(e)}")
return None
# 使用示例
if __name__ == "__main__":
# 替换为你的CSV文件路径
csv_file_path = "your_file.csv"
# 调用函数进行分析
missing_stats = analyze_missing_values(csv_file_path)
# 如果需要保存结果到新的CSV文件
if missing_stats is not None:
output_path = "missing_values_statistics.csv"
missing_stats.to_csv(output_path, index=False)
print(f"\n统计结果已保存到: {output_path}")整体来看,代码结构比较清楚,也能直接用于日常小脚本。
对于开发者来说,DeepSeek V4 Flash 很适合用来:
- 写 Python 小脚本
- 生成 SQL
- 解释报错
- 优化简单代码
- 写接口示例
- 生成 README
- 添加代码注释
不过,如果是大型项目重构、复杂架构设计、多文件联动修改,我还是建议使用更强的推理模型,或者让 Flash 先生成初稿,再人工检查。
一句话总结:
日常小问题 coding 用 Flash 很舒服,复杂工程问题还需要更强模型辅助。
5. 代码解释
我:解释下面这段代码的作用,并指出有没有可以优化的地方。
python
nums = [1, 2, 3, 4, 5]
result = []
for n in nums:
if n % 2 == 0:
result.append(n * n)
print(result)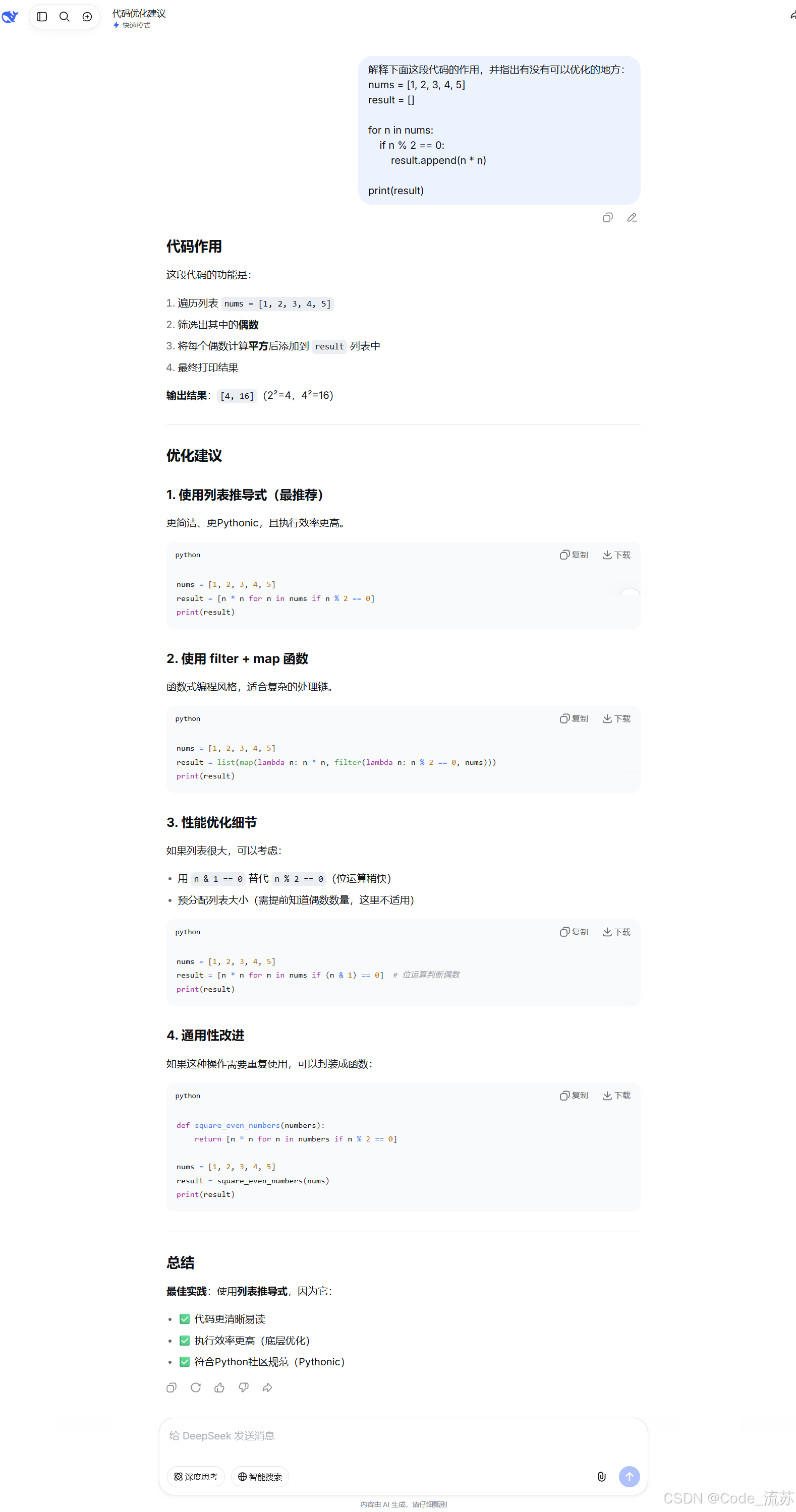
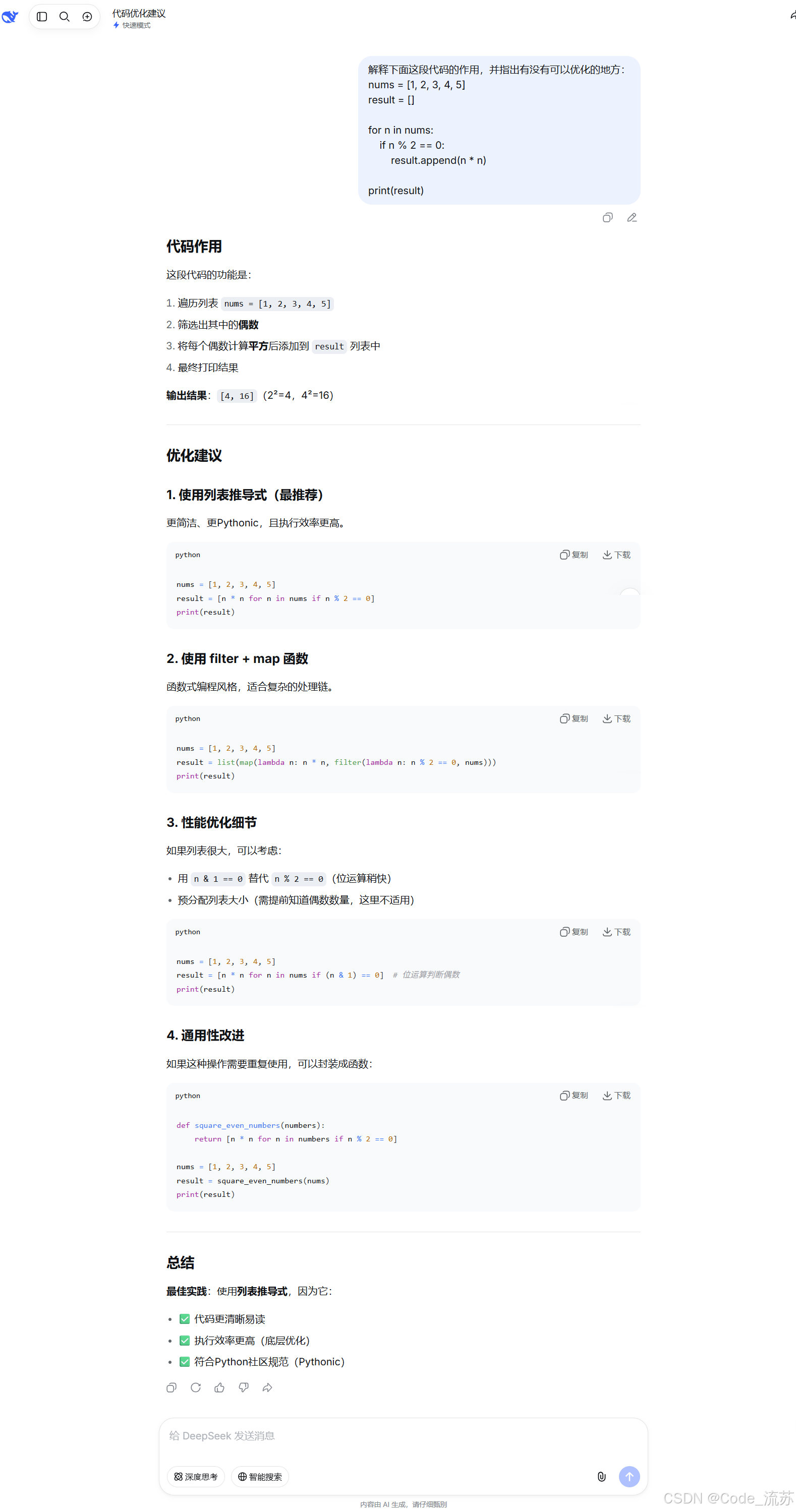
这个问题主要测试模型的代码理解能力。
比较好的回答应该能说明:
- 这段代码在做什么
- 最终输出是什么
- 可以如何简化
- 是否能给出优化版本
这段代码的作用是:找出列表中的偶数,并计算它们的平方。
最终输出结果是:
python
[4, 16]如果进一步优化,可以写成列表推导式:
python
nums = [1, 2, 3, 4, 5]
result = [n * n for n in nums if n % 2 == 0]
print(result)这类测试很适合判断模型是否真的理解代码,而不是只会机械解释。
DeepSeek V4 Flash 在基础代码解释上表现比较稳定,适合作为日常学习和开发辅助工具。
6. 逻辑推理
我:小明、小红、小刚三个人中,只有一个人在说真话。小明说:"小红在说谎。"小红说:"小刚在说谎。"小刚说:"小明和小红都在说谎。"请问谁在说真话?

这个问题主要测试模型的基础逻辑推理能力。
这类题看起来简单,但如果模型没有认真分析,很容易答错。
我们简单推一下:
- 如果小明说真话,那么小红说谎。
- 小红说"小刚在说谎",既然小红说谎,那么小刚就在说真话。
- 这样就变成小明和小刚都说真话,和题目"只有一个人说真话"矛盾。
所以小明不是真话。
再看小红:
- 如果小红说真话,那么小刚在说谎。
- 小刚说"小明和小红都在说谎",这句话为假,说明小明和小红不都是说谎。
- 此时小红说真话,小明说谎,符合"只有一个人说真话"。
因此,说真话的是小红。
对于 Flash 这类效率模型来说,简单逻辑推理一般没问题。
但如果题目更复杂,或者涉及多层条件判断,还是建议使用更强的推理模型(v4 pro等)复核。
7. 指令遵循
我:请用三句话总结 DeepSeek V4 Flash 的特点,每句话不超过 20 个字。
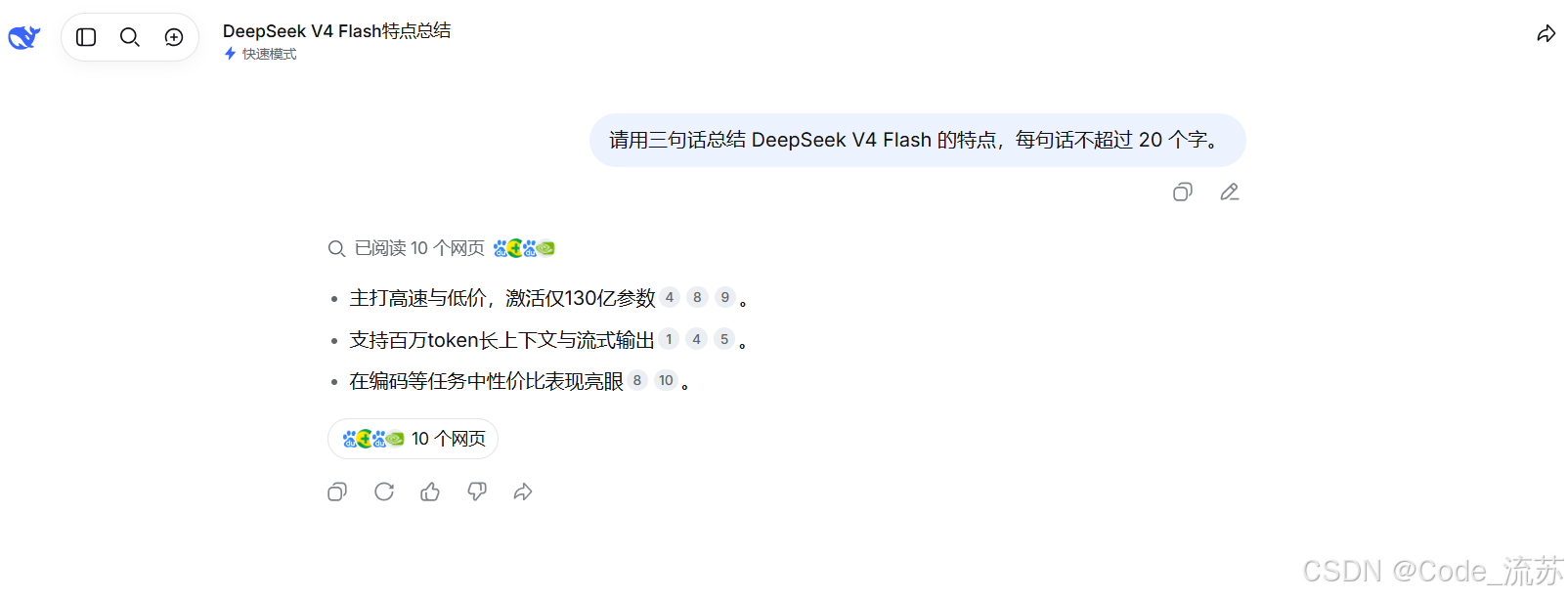
这个问题主要测试模型的指令遵循能力。
很多模型看似回答不错,但经常忽略限制条件,比如:
- 明明要求三句话,却写了五句
- 明明要求每句不超过 20 个字,却写得很长
- 明明要求总结特点,却加入了无关内容
比较理想的回答应该类似这样:
响应速度更快。
日常任务很稳定。
成本控制更友好。
这种测试很有必要,因为在真实使用中,我们经常会要求 AI 按指定格式输出。
比如:
- 生成 JSON
- 写固定格式文档
- 按表格整理内容
- 限制字数
- 按指定语气改写
如果模型能严格按照要求输出,说明它在实际工作流里会更好用。
8. 表格整理
我:请把 DeepSeek V4 Flash、DeepSeek V4 Pro、GPT 系列模型做一个简单对比表,维度包括速度、成本、推理能力、适合场景。
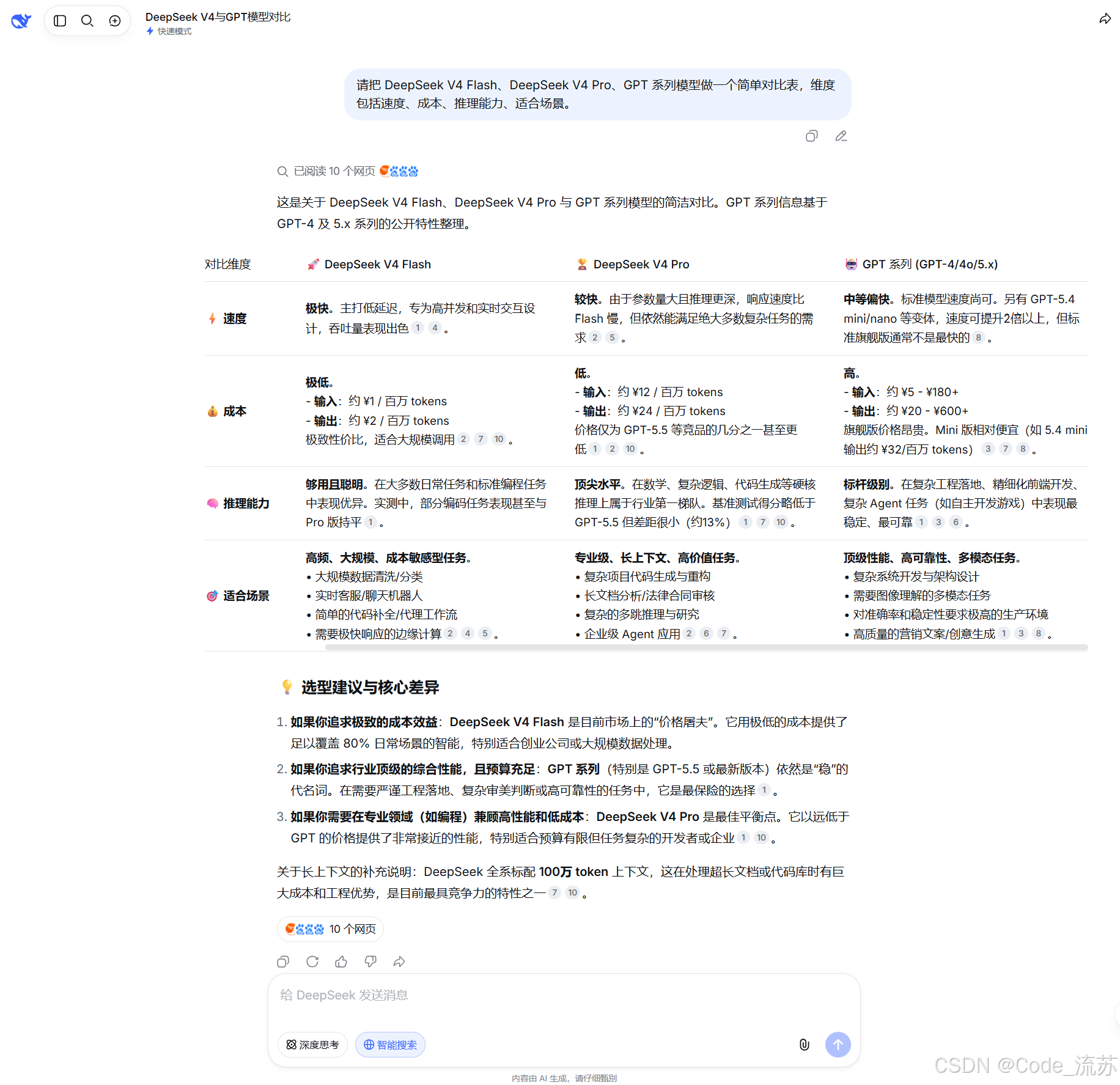
这个问题主要测试模型的结构化表达能力。
一个好的回答,不应该只是一大段文字,而是要能自动整理成清晰表格。
例如:
| 模型 | 速度 | 成本 | 推理能力 | 适合场景 |
|---|---|---|---|---|
| DeepSeek V4 Flash | 快 | 较低 | 日常够用 | 写作、总结、简单代码 |
| DeepSeek V4 Pro | 中等 | 较高 | 更强 | 复杂推理、代码架构 |
| GPT 系列模型 | 稳定 | 视版本而定 | 综合能力强 | 通用问答、多场景应用 |
这类能力在写博客、做汇报、整理方案时非常实用。
DeepSeek V4 Flash 在结构化输出方面表现不错,尤其适合帮我们快速整理信息框架。
9. 角色扮演
我:假设你是一位有 5 年经验的 Python 开发工程师,请用通俗语言给小白解释什么是 API。
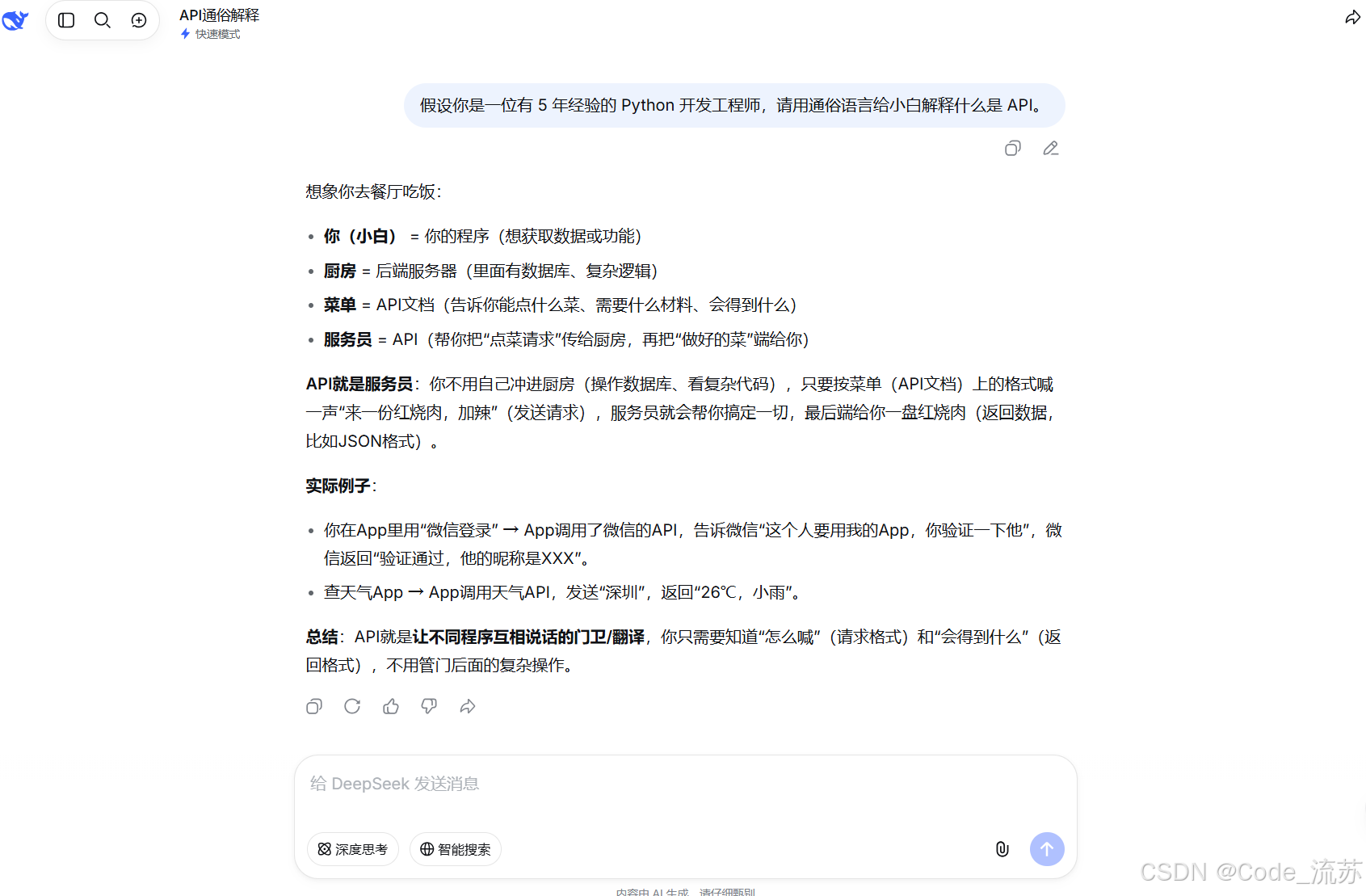
这个问题主要测试模型的角色理解和表达风格控制能力。
一个比较好的解释方式是:
API 可以理解成软件之间的"点餐窗口"。
你不需要知道厨房里面怎么做菜,只需要按照菜单点餐,厨房就会把结果返回给你。
在编程里,一个程序也可以通过 API 向另一个程序请求数据或功能。
这种表达就比较适合小白理解。
DeepSeek V4 Flash 在这类角色扮演和通俗解释任务上表现还不错,能根据"面向小白"这个要求调整表达方式。
四、综合体验:中文自然,日常任务够用
通过上面这些测试,我整体感受是:
DeepSeek V4 Flash 在日常任务中的表现比较稳,尤其适合中文写作、文档总结、简单代码和结构化表达。
它不是那种专门用来挑战超高难题的模型,但在高频使用场景里,体验确实不错。
简单来说:
- 普通任务反应快
- 中文表达比较自然
- 代码辅助够用
- 总结能力比较稳
- 表格整理很实用
- 复杂推理还需要更强模型兜底
这也符合它本身的定位:
不追求每个任务都最强,但追求大部分任务都好用。
五、它适合哪些人?
我觉得 DeepSeek V4 Flash 特别适合三类人。
1.普通用户
2.内容创作者
3.开发者
我们一个个来说,首先普通用户:
1. 普通用户
如果你只是日常使用 AI,比如写文案、查资料、做总结、改表达,Flash 已经完全够用。
它最大的优点就是:快、直接、不拖沓。
除了普通用户,现在网络媒体发达的时代,也会有很多内容创作者:
2. 内容创作者
对于经常写博客、公众号、教程的人来说,它很适合用来:
- 搭文章框架
- 写开头结尾
- 优化表达
- 生成标题
- 总结资料
它不是替你完成创作,而是帮你提高效率。
以上两种之外,还有一个使用高频的群体:开发者。
3. 开发者
对于开发者来说,Flash 可以作为一个轻量级编程助手。
平时写点脚本、查下报错、整理文档、生成测试代码,都很方便。
如果你需要频繁调用 API,它的性价比优势会更明显。
六、局限性:别把Flash当万能模型
当然,DeepSeek V4 Flash 也不是万能的。
它的定位是"高效",不是"最强"。
所以在一些复杂任务上,比如:
- 高难数学推理
- 大型代码架构设计
- 严肃事实核查
- 法律、医疗、金融类问题
- 需要极高准确率的场景
还是要谨慎使用。
尤其是事实类问题,AI 依然可能出现幻觉。
重要内容最好结合搜索、官方文档或人工判断进行确认。
另外,如果你主要做图片理解、视频分析等多模态任务,DeepSeek V4 Flash 也不一定是最合适的选择。
七、总结:不是最强,但很实用
整体体验下来,我觉得 DeepSeek V4 Flash 是一款非常实用的效率型模型。
它不一定每项能力都冲到第一,但它很清楚自己的定位:
用更快的速度、更低的成本,完成大多数日常任务。
这其实正是很多用户真正需要的。
如果说 DeepSeek V4 Pro 更像是一位"专家顾问",那么 DeepSeek V4 Flash 就更像是身边随叫随到的"效率助手"。
不一定最强,但足够好用。
AI 模型的发展,正在从"拼参数、拼榜单",慢慢走向"拼体验、拼效率、拼落地"。
而 DeepSeek V4 Flash,正是这个趋势下很值得关注的一款模型。
DeepSeek的未来,值得期待!🐳
📌 如果这篇文章对你有帮助,欢迎点赞、收藏、转发!
有任何问题,也欢迎在评论区交流讨论~