Automated Multi-Agent Workflows for RTL Design
解决什么问题
现有 RTL 生成大致有两条路:
- 一条是对 LLM 做 RTL/HDL 专项微调,但成本高,而且对邻近任务的泛化未必好;
- 另一条是直接用强推理模型,但推理开销大。
作者认为,通用的 agent workflow 自动搜索方法虽然在 QA、数学、通用 coding 上有效,但未必直接适用于 RTL 设计,因为 RTL 任务更依赖 EDA 流程、编译/综合约束和形式化检查。于是他们提出 VeriMaAS,把"EDA 工具反馈"接进 agent workflow 里面。
核心方法是什么
VeriMaAS 会针对一个 RTL 任务,自适应地从一组 reasoning operators 中选择工作流步骤。每一轮生成出的 Verilog 候选都会送去跑 Yosys 和 OpenSTA 。如果很多候选在编译、验证、面积、运行时、功耗分析上失败,系统就判断这个任务更难,需要升级到更复杂的 operator;否则就提前停止,返回当前结果。也就是说,它的 controller 不是靠纯语言模型自我反思,而是靠真实 EDA 反馈来驱动 workflow 选择。
控制器怎么训练
这篇文章没有做那种重型的 end-to-end 微调,而是只学习一个级联控制器的阈值 。
它把任务按 stages 逐步升级:
- I/O → CoT → ReAct → Self-Refine → Debate 【I/O 最简单,CoT 是显式分步思考,ReAct 是边想边做,Self-Refine 是自我修改,Debate 是多角色辩论。】
作者从 VeriThoughts 训练集里随机采样 500 个样本,统计每个阶段 20 个候选中有多少个在 Yosys/OpenSTA 里失败,再根据失败比例的分位数来确定各阶段阈值。优化目标同时考虑:
- 效用:pass@k
- 成本:平均 token 数
所以本质上它是在做一个低成本的 workflow controller tuning,而不是大模型再训练。文章强调,这只需要"几百条样本",比完整微调所需的上万条监督数据少一个数量级。
效果怎么样
在 VeriThoughts 和 VerilogEval 两个 benchmark 上,VeriMaAS 相比单一 prompting 和已有 fine-tuned RTL 模型都有提升:
- 论文摘要里说,相对 fine-tuned baseline,pass@k 提升约 5--7%;
- 结果部分又指出,在开源模型上,pass@1 相对已有 fine-tuned baseline 可提升到 7--12%。
和单一 CoT / ReAct / Self-Refine 比有什么不同
文章专门比较了 VeriMaAS 和单一 prompting 策略。结论是:
- VeriMaAS 的提升通常比单一 CoT 更稳;
- token 开销虽然有增加,但通常低于 Self-Refine 这种迭代式方法;
- 对强闭源模型,收益变小,但仍然有稳定增益。
额外亮点:PPA-aware 优化
由于它不是把能力固化进模型权重里,所以 controller 可以很容易换目标。作者做了一个 proof-of-concept:把优化目标从 token cost 改成 Yosys 报告的 area,尝试让生成结果更偏向 PPA 优化。
结果显示,在一些子集上:
- 面积、延迟能明显下降;
- 最大面积下降可到 28.79%;
- 但代价是有时 功耗略增 ,或者 pass@10 略降。
一、INTRO
背景:Agentic AI 很有潜力,但 RTL 领域很特殊
文章开头先说,agentic AI workflow(智能体工作流) 最近在计算机系统设计和优化里很有前景。
但问题是,RTL/HDL 代码生成 这个领域和普通编程不一样:
- 在线可用的 HDL 数据少;
- 很多 EDA 资源和设计流程是专有的;
- 因此很难像普通代码那样,靠海量数据把模型训得很好。
所以现有方法往往会陷入几种代价很高的路线:
- 任务专项微调(fine-tuning)
- 更强模型带来的高推理成本
- 人工手工设计 agent orchestration(智能体编排流程)
文章提出了什么:VeriMaAS
作者提出了一个框架,叫 VeriMaAS 。
它是一个 multi-agent framework,目标是:
- 自动组合适合 RTL code generation 的 agent workflow
- 而不是靠人手工指定"先 CoT、再 self-refine、再 debate"这种固定流程
也就是说,它想做的是:让系统自己决定该用什么推理策略、何时升级工作流复杂度。
RTL 生成已经是一个重要方向
文中提到,近年来已经出现了很多 RTL generation / hardware design 相关方法和 benchmark,用于:
- RTL 代码生成
- EDA tool scripting
- 加速器设计
- HDL 调试
- 后综合指标评估
现有两类主流方法各有缺点
第一类:fine-tuning 路线
就是把 LLM 在 RTL/HDL 数据上专门微调。
优点:
- 任务适配性强
- 性能通常不错
缺点:
- 成本高,需要较多 GPU 预算
- 对相邻 HDL 任务未必泛化好
也就是说,这类方法像是"为某类 RTL 题专门补课",
补完后做这类题很强,但换题型不一定稳。
第二类:纯推理模型路线
比如更强的 reasoning model,不去微调,而靠推理能力直接做 RTL。
优点:
- 不需要额外训练
缺点:
- 把成本从训练阶段转移到了推理阶段
- 推理可能很长、很贵
这条路的问题不是"省了",而是"换地方花钱"。
作者为什么想到 multi-agent workflow
作者说,他们受到自动化 multi-agent workflow generation 的启发。
像一些已有工作已经证明:
- 相比单一 prompting
- 自动编排多个 agent/operator
- 往往能更好平衡性能和成本
但这些方法主要用在:
- QA
- 数学题
- 通用 coding
而 RTL 设计属于更强领域约束的任务,不能直接照搬。
为什么不能照搬?
因为在通用 QA 里,像 Debate 这种 prompting operator 可能就很好用;
但在 RTL 设计中,真正决定好坏的不只是"推理过程看起来合理",而是:
- 代码能不能通过验证
- 综合能不能成功
- 最终电路指标好不好
所以文章想表达的是:
通用 multi-agent 方法有启发,但如果不接入 EDA/HDL 反馈,就不够懂 RTL。
key insight
什么叫"integrate HDL verification checks directly into workflow generation process"
就是把 HDL/EDA 工具的结果,直接用来控制工作流,而不是只在最后做个评测。
更具体地说,系统会把这些信息喂给 workflow 决策过程:
- design logs
- error messages
- synthesis tool results
然后根据这些反馈来决定:
- 当前生成结果够不够好
- 要不要继续 refinement
- 要不要升级到更复杂的 reasoning strategy
- 应该朝哪个目标继续优化
所以它不是"先生成完,再离线测一下",而是边生成,边根据工具反馈调 agent workflow。
为什么这招有效
因为 RTL 的"对错"高度依赖工具链。
比如一段 Verilog:
- 语言上看着没毛病
- 注释也很合理
- LLM 自己也觉得逻辑通顺
但实际上可能:
- 综合报错
- 有 latch
- 时序不满足
- 面积过大
- verification fail
所以如果只靠自然语言层面的 self-reflection,模型可能会"自我感觉良好";
而接入 HDL verification feedback 后,系统拿到的是硬约束下的真实反馈。
这相当于给 agent workflow 接上了"物理世界的裁判"。
它不只是为了功能正确,还能支持不同设计目标
文中提到,这样做后,agentic reasoning 可以面向不同目标展开,例如:
- PPA-aware prompting
- 功耗 power
- 性能 performance
- 面积 area
为什么说监督成本低
- 性能可达到甚至超过已有方法
- 最多提升到 7% pass@k
- 但 controller tuning 只需要几百个样本
这说明它的主要优化对象不是大模型本身,而是工作流控制器 。
所以训练压力会比 full fine-tuning 小很多。
二、方法
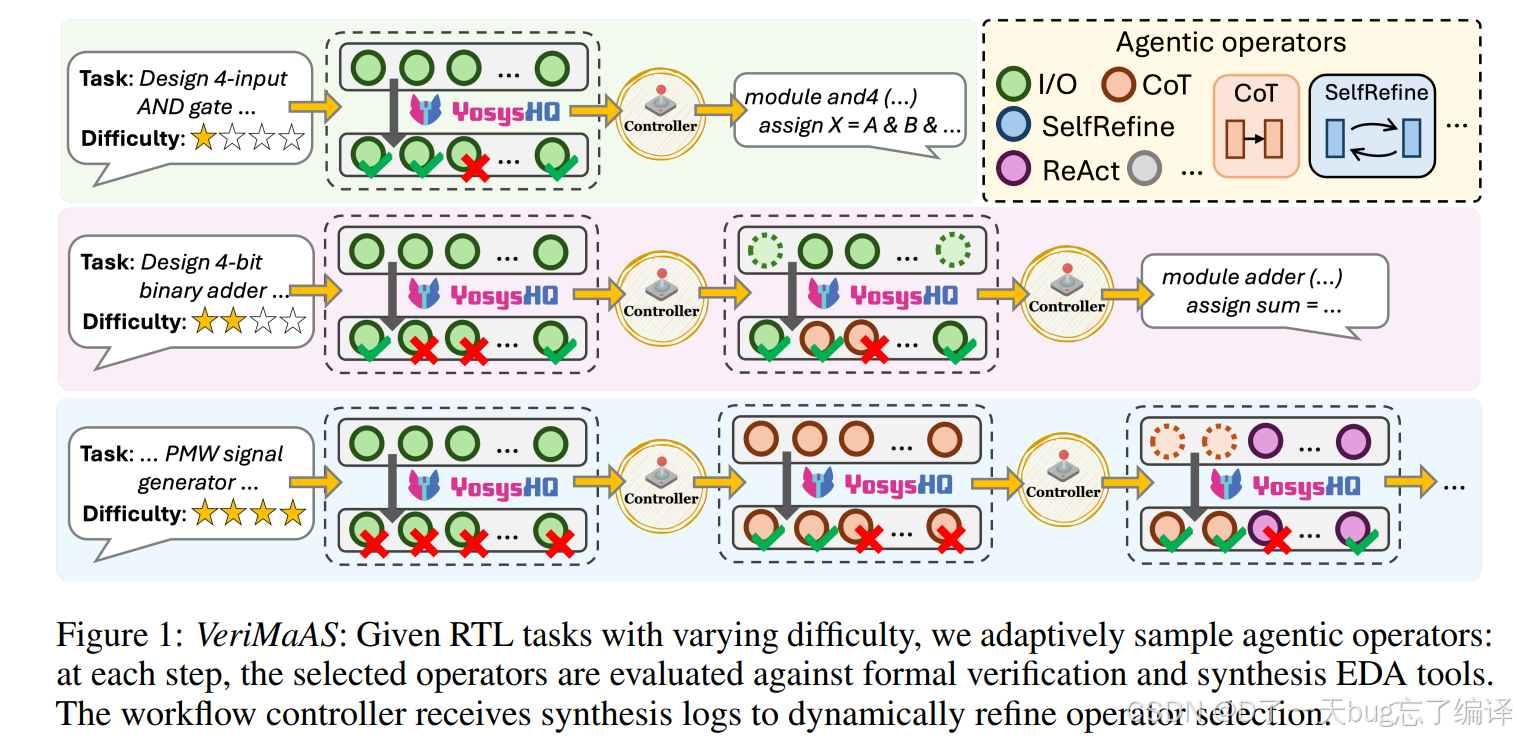
图 1 想表达的是:
- 简单任务:不需要复杂 agent,可能用 I/O 或 CoT 就够了;
- 中等任务:可能要经过 1~2 轮 operator 升级;
- 困难任务:需要更复杂的多步推理,比如 Self-Refine、ReAct 甚至更多 operator。
也就是说,不是所有 RTL 题都一上来就用最重的 workflow ,而是按难度逐步升级。
第一行:简单任务
例子是 Design 4-input AND gate
这个任务很简单,所以:
- 初始 operator 生成的一批候选,大多数都能通过;
- controller 看日志后判断"已经够好了";
- 很快就输出结果,不再升级 workflow。
这体现的是 easy task early stop。
第二行:中等任务
例子是 Design 4-bit binary adder
这个任务比与门复杂:
- 第一轮简单 operator 生成后,有一些失败;
- controller 认为还不够,进入下一层 operator;
- 再生成一批候选后,通过率上来了;
- 然后输出结果。
这体现的是 适度升级 reasoning complexity。
第三行:困难任务
例子是 PWM signal generator
这种任务更复杂,通常需要:
- 第一轮失败很多;
- 第二轮也不够;
- controller 继续升级到更强 operator;
- 经过多轮 refinement 才得到更高质量候选。
这体现的是 hard task needs deeper workflow。
图中符号怎么理解
1)彩色圆点
- 绿色:I/O
- 棕色:CoT
- 蓝色:Self-Refine
- 紫色:ReAct
- 还有其他
这些圆点表示:
当前阶段从某个 operator 生成了一批候选样本。
2)YosysHQ 标志
表示生成的候选会送到综合/验证流程中去检查。
文中后面说明具体会经过:
- Yosys:综合、面积估计、基础检查
- OpenSTA:时序、功耗分析
3)Controller
这是系统核心。
它根据上一轮候选的日志和失败情况,决定:
- 当前结果是不是已经够好;
- 是否进入下一层更复杂的 operator;
- 还是直接终止并返回现有候选。
所以 Controller 本质上是个workflow 决策模块。
Methodology
具体流程
对一个 RTL task,VeriMaAS 会做三件事:
第一步:根据任务和难度采样 reasoning operators
也就是先决定当前阶段用什么 agent/operator。
第二步:执行候选 Verilog
把生成结果放进综合和验证流程里跑:
- Yosys
- OpenSTA
第三步:用日志和错误信息做反馈
把这些反馈拿回来,告诉 controller:
- 下一步该不该继续;
- 要不要换更复杂的 reasoning strategy;
- 还是现在就终止。
作者定义一个解空间 O,表示所有可用的 agentic operators:
- Zero-shot I/O
- Chain-of-Thought (CoT)
- ReAct
- Self-Refine
- Debate
也就是说,系统可选的"动作库"就是这几种 operator。
多智能体解是什么
作者把一个多智能体解写成:
O={Oi∈O∣i=1,...,K}
它本质上就是说:一个 workflow 可以看成若干 operator 的组合序列。
例如:
1)只用 CoT
那就是单步 workflow:
O={OCoT}
2)先 CoT 再 Self-Refine
那就是两步 workflow:
O={OCoT,OSelfRefine}
所以作者是在把各种 prompting / agent 方法统一成一个"operator sequence"的框架。
它的目标是什么
给定用户 query,它的目标是找到一个 operator 组合,使得生成的 RTL 最好。
这个"最好"主要通过 pass@k 衡量。
pass@k 在这里是什么意思
- 系统不是只生成 1 个 Verilog 候选,而是生成一组;
- 看这组候选里有没有通过验证/综合的正确结果;
- 如果前 k 个候选里至少有一个对,就算成功。
文中说通常设置:
- E=20 samples
- ∣O∣=K=20
也就是每个 query 会生成 20 个候选,再看通过情况。
Agentic Controller
输入
- query q
- 当前可选 operator 集合 O
- 当前解生成出的答案集合 A_{O_{current}}
输出
- 一个更新后的解 O_{new}
翻成白话就是:
controller 看当前已经试过的 operator 和生成结果,然后决定下一步 workflow 怎么改。
operator 按复杂度排成一个逐级升级的链条:
controller 如何决定要不要升级
它会在每一层计算一个分数 sc,表示:
当前阶段是否值得继续升级。
如果:
- sc<τc:说明当前阶段已经够好,停止,返回当前解;
- 否则:说明还不够,继续加入下一层 operator。
其中:
- τc 是该阶段的阈值;
- 整组阈值记为 T={τ1,τ2,...,τC}
所以这个控制器本质上就是:
用一组 stage-specific threshold 控制 workflow 深度。
作者的关键观察
formal verification 和 synthesis 的反馈,能够很好反映任务复杂度。
直觉上:
- 如果最初简单 operator 生成的一批候选,大多都过不了;
- 那么这个任务大概率更复杂;
- 就应该用更高级的 reasoning operator。
所以这里的 "难度" 不是人工标注的,
而是通过 候选失败率 间接测出来的。
每一阶段具体怎么做
在 cascade 的每个 stage:
- 生成 K=20个 Verilog candidates;
- 跑 Yosys 做综合和面积估计;
- 跑 OpenSTA 做时序和功耗分析;
- 统计失败比例。
作者定义:
sc=Score(AOc)
它表示这一阶段候选中,因以下问题失败的设计所占比例:
- verification error
- synthesis(area) error
- runtime error
- power analysis error
也就是:
失败样本百分比 = 当前阶段难度/不足程度的指标。
- sc越大:失败越多,说明当前 operator 不够用,要升级;
- sc越小:通过越多,说明当前阶段已经足够,不需要更复杂 workflow。
所以它并不是"信心分数越高越好"那种常见设定,
这里更像是一个 failure-driven escalation score。
Problem formulation
这一段是在把 controller tuning 写成优化问题。
它要学什么
它不是训练整个大模型,
而是学习那组阈值:
T={τ1,...,τC}
也就是说,真正待学习的是:
每一层 operator 在什么失败比例下应该继续升级。
优化目标是什么
公式本质上是在最大化:
效用−λ×成本
其中:
效用 U(⋅)
作者定义为 pass@k
成本 C(⋅)
定义为 平均 token 数
所以它追求的是:
在尽量少用 token 的前提下,让 pass@k 尽可能高。
λ 是权衡系数。
文中设为:
λ=1e−3
意思是:
- 主要目标还是性能;
- 但也不能完全不顾 token 成本。
训练数据
作者从 VeriThoughts training set 中随机采样:
- 500 个 datapoints
对每个 datapoint 做什么
对于每个 query:
- 生成 20 个 candidates;
- 计算 pass@k 和 token cost;
- 看有多少候选无法通过 Yosys / OpenSTA 检查。
也就是把每个样本都转换成:
- 性能信息
- 成本信息
- 失败比例信息
阈值怎么定
作者把所有样本的 failure counts 聚合起来,然后取:
- 20th percentile
- 40th percentile
- 60th percentile
- 80th percentile
这些分位点对应五个 operator 阶段。
这个做法其实非常"轻量":
- 不需要大规模梯度训练;
- 更像是用统计分位数来设置 cascade threshold。
所以这篇文章的方法并不是复杂 RL controller 或神经控制器,
而是一个非常工程化、很实用的 threshold-based controller。
三、实验
- 两个 benchmark:VerilogEval 和 VeriThoughts
- 指标:pass@1 、pass@10
- 每题生成 20 个 samples
- 工具链:Yosys 做验证与面积估计,OpenSTA 做时序和静态功耗分析
- 综合环境:Skywater 130nm PDK
Main Results
- VeriMaAS 在两个 benchmark 上都比强单 agent 方法更好
- 也比已有的 fine-tuned RTL 模型更强
- 对开源模型提升尤其明显
- 不只是 pass@1 提高,pass@10 也经常提高
具体内容:
论文直接总结说:在开源 LLM 上,相比已有 fine-tuned baseline,pass@1 可以提升到 7--12% ;同时,VeriMaAS 还会提升 pass@10 ,说明它不只是把"最好那个答案"变好,还把整个候选池里有效设计的比例也提高了。这个点很重要,因为 RTL 生成通常不是只看单发命中,而是看能不能多生成一些可用候选。
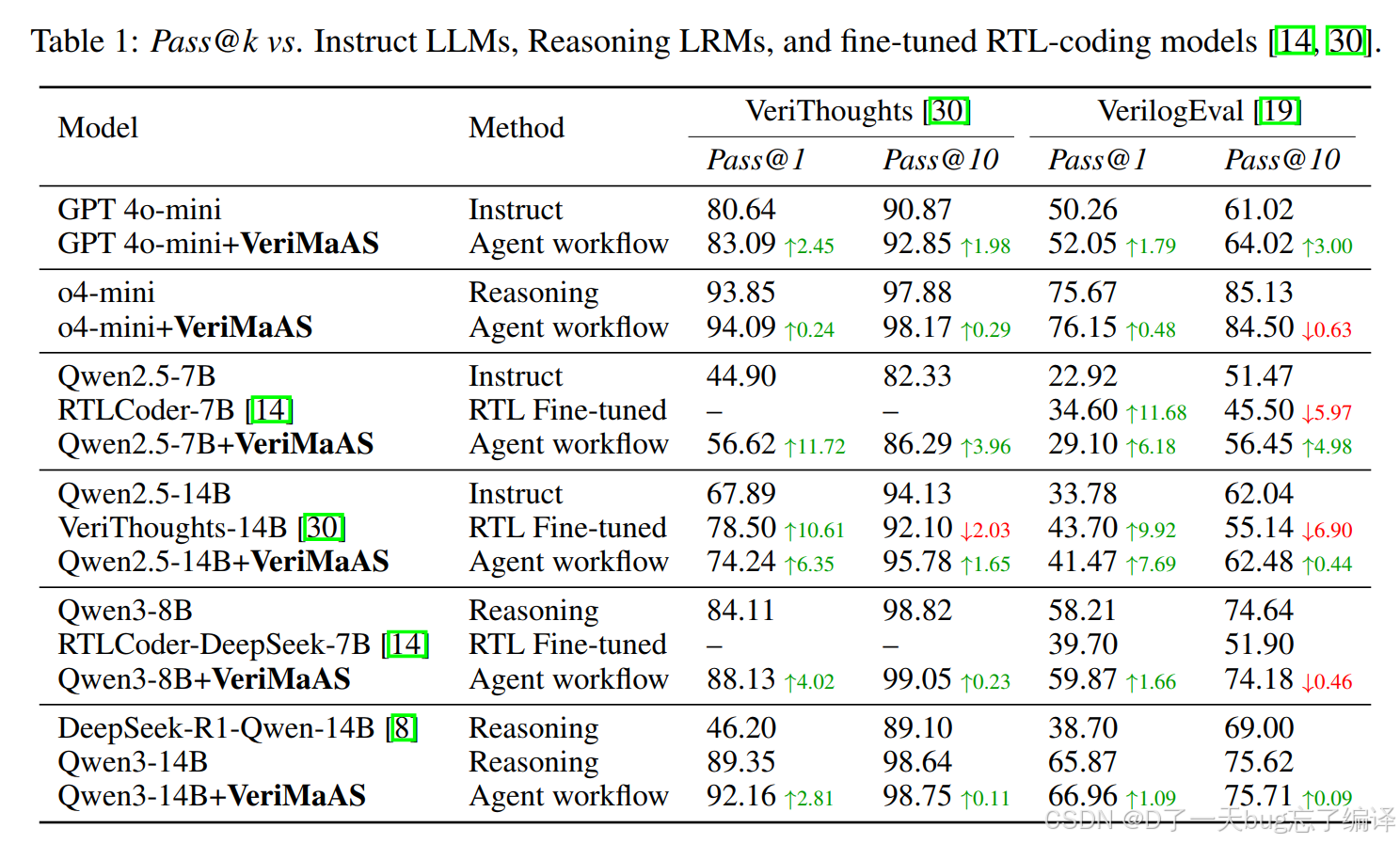
Table 1
- Instruct LLMs
- Reasoning LRM/强推理模型
- RTL fine-tuned models
几个你最该记住的数字
例 1:Qwen2.5-7B
- VeriThoughts:44.90 → 56.62(pass@1,+11.72)
- VerilogEval:22.92 → 29.10(pass@1,+6.18)
这说明:
对中等规模开源模型,VeriMaAS 的帮助非常明显,属于"比较硬的提升"。
例 2:Qwen3-14B
- VeriThoughts:89.35 → 92.16(pass@1,+2.81)
- VerilogEval:65.87 → 66.96(pass@1,+1.09)
这说明:
底座已经很强时,提升会变小,但依然稳定存在。
例 3:GPT-4o-mini
- VeriThoughts:80.64 → 83.09
- VerilogEval:50.26 → 52.05
- pass@10 也分别提升到 92.85 和 64.02
这说明:
即使是闭源强模型,agent workflow 也不是没用,而是还能继续挖出一点增益。
- 开源模型收益大
- 闭源强模型收益小但稳定
- VeriMaAS 往往不输专门 RTL 微调模型
Table 2
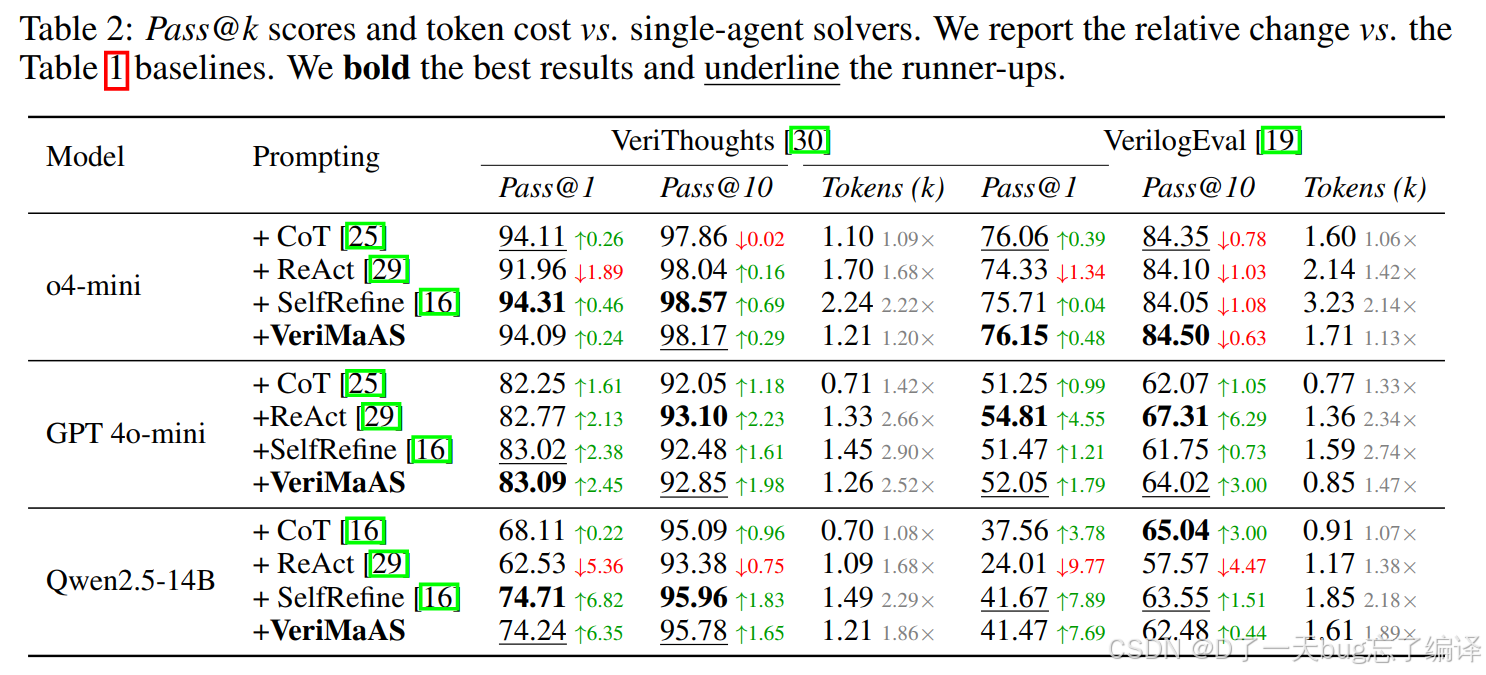
这张表回答的是:VeriMaAS 的提升,究竟来自"多智能体编排"本身,还是随便换个 CoT / ReAct 就行?
对比对象
- +CoT
- +ReAct
- +SelfRefine
- +VeriMaAS
具体内容:
也就是在同一个 base model 上,把不同 prompting/operator 单独拿出来比较,看谁精度更高、token 成本更低。
对 o4-mini 的结果
- VeriThoughts 上,+SelfRefine 的 pass@1 最好(94.31)
- 但 +VeriMaAS 的 pass@10 最好(98.17)
- VerilogEval 上,+VeriMaAS 的 pass@1 / pass@10 都最好(76.15 / 84.50)
对 GPT-4o-mini 的结果
- VeriThoughts:+VeriMaAS 的 pass@1 达到 83.09
- VerilogEval:+VeriMaAS 的 pass@1 达到 52.05
- 但 +ReAct 在部分指标上也很强,比如 VeriThoughts pass@10 达到 93.10
对 Qwen2.5-14B 的结果
- VeriThoughts:+VeriMaAS 的 pass@10 = 95.78
- VerilogEval:+SelfRefine 的 pass@10 = 63.55,略高于 VeriMaAS 的 62.48
- 但 VeriMaAS 的 pass@1 = 41.47,明显高于 CoT / ReAct,也接近或优于其他方法
具体内容:
这说明 VeriMaAS 不是"所有格子都最优",但总体趋势是:
在 pass@1 和 pass@10 上都有稳定竞争力,而且更适合作为通用 workflow。
Token 成本
- VeriMaAS 有额外 token 开销
- 但开销是"中等"的
- 通常接近 CoT,低于 Self-Refine 这种重迭代方法
比如:
- o4-mini 上,VeriThoughts token 大约 1.21k
- 而 SelfRefine 是 2.24k
- CoT 只有 1.10k
Table 3
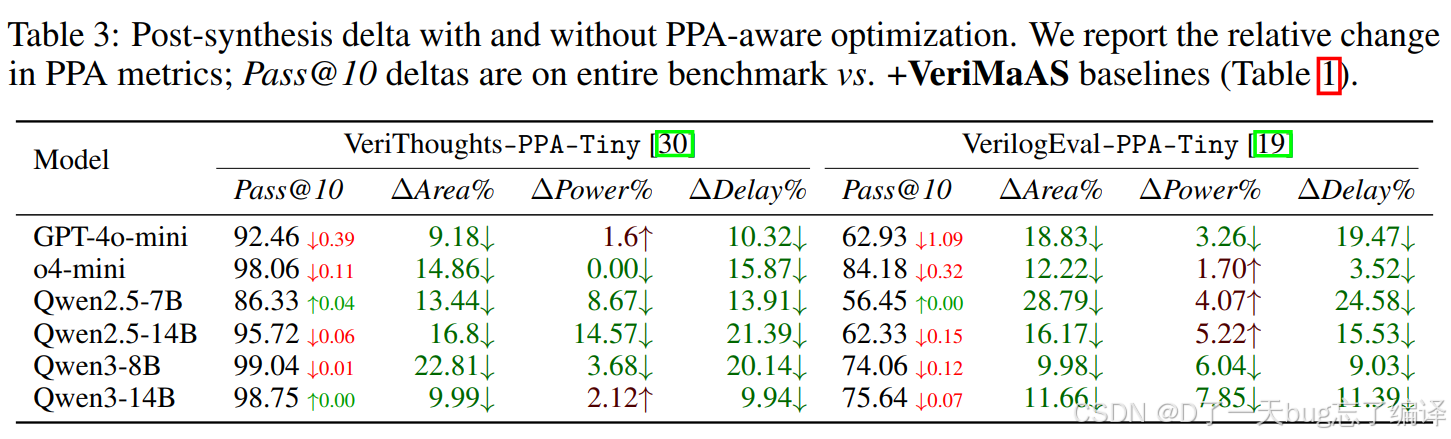
- 不再把 cost 定义成 token cost
- 而是改成 Yosys 报告的 area
- 然后重新优化 controller
- 看最终面积、功耗、延迟会不会更好
具体内容:
也就是说,VeriMaAS 的 controller 不是只能为"更高 pass@k"服务,它还可以换目标函数,去朝 PPA 优化。
作者也承认,不是所有 benchmark 题都有明显的 PPA 优化空间。
例如 NAND gate 这种很简单的题,RTL 怎么改都很难让下游 PPA 差很多。
所以他们用 o4 先挑出那些"RTL 改动更可能影响 PPA"的 top 20 design 子集,称为 PPA-Tiny。
- 面积最大下降 28.79%
- 延迟很多情况下也下降
- 功耗多数下降,但也有少数上升
- pass@10 有时会轻微下降
具体内容:
比如在 VerilogEval-PPA-Tiny 上:
- Qwen2.5-7B 的 ΔArea = 28.79%↓
- ΔDelay 也达到 24.58%↓
- 但 ΔPower 是 4.07%↑。