神经网络基础
深度学习框架
深度学习框架:Tensorflow, Keras, PyTorch, Paddle(百度的,飞桨aistudio可以使用)
Tensorflow 2.0, 2019年发布,相比于1.0更加简洁
Pytorch,Facebook开发,Python + Torch
科学计算库,代替 Numpy,利用 GPUs
动态图设计,可以高效地进行神经网络的构造,学术界用的多
| 对比维度 | TensorFlow | Pytorch |
|---|---|---|
| 开发风格 | 早期静态图(先编译再执行),2.0后支持动态图(Eager模式)(执行的时候再编译、更快) | 原生动态图(即时执行),调试方便 |
| 生态系统 | 工业部署工具完善(TF Serving,Lite等) | 学术研究主流(Huggingface等) |
| API设计 | API复杂但功能全,Keras高层封装 | Pythoic风格,代码简洁直观 |
| 硬件支持 | GPU/CPU/移动端优化成熟 | GPU/TPU支持良好,移动端支持较弱 |
| 使用场景 | 声场环境、大规模部署 | 快速试验、学术研究 |
| 社区趋势 | 工业界应用广泛 | 学术界占比高 |
神经网络网络图:从输入层传递到隐藏层传递到输出层(预测结果)
深度学习本质上就是神经网络,只是层数较多,强调深度(Googlenet网络为22层,resnet可以达到50/101/152层)
相同点:神经网络不是一个新的概念,一个端到端的黑盒,可解释性较差、自适应完成特征提取
生物神经元:
单个神经细胞要么兴奋要么抑制,接收到的信号加权总和如果超过一个阈值就被激活(兴奋),并向下传递消息;否则就保持抑制。
这个"简单的开关机制"是如何来实现的?
通过激活函数来实现的,它构成了网络学习的根本。
一个神经元就是一个决策小单元。它接收很多上游传来的信号,同时它需要做一个"决定":我收到的这些信息足够重要吗?我需要把这个信息继续往下传递吗?
激活函数就是这个决策的"开关" 。它将所有输入信号的加权总和作为输入,然后输出一个值。
最简单的激活函数(阶跃函数)就像一个纯粹的开关:输入总和超过阈值,就输出1(兴奋=>传递);否则输出0(抑制=>不传递)。
人工神经元
整个神经网络由无数个神经元组成。当这些成千上万的简单决策汇集在一起时=> 整个网络就能做出极其复杂的决策
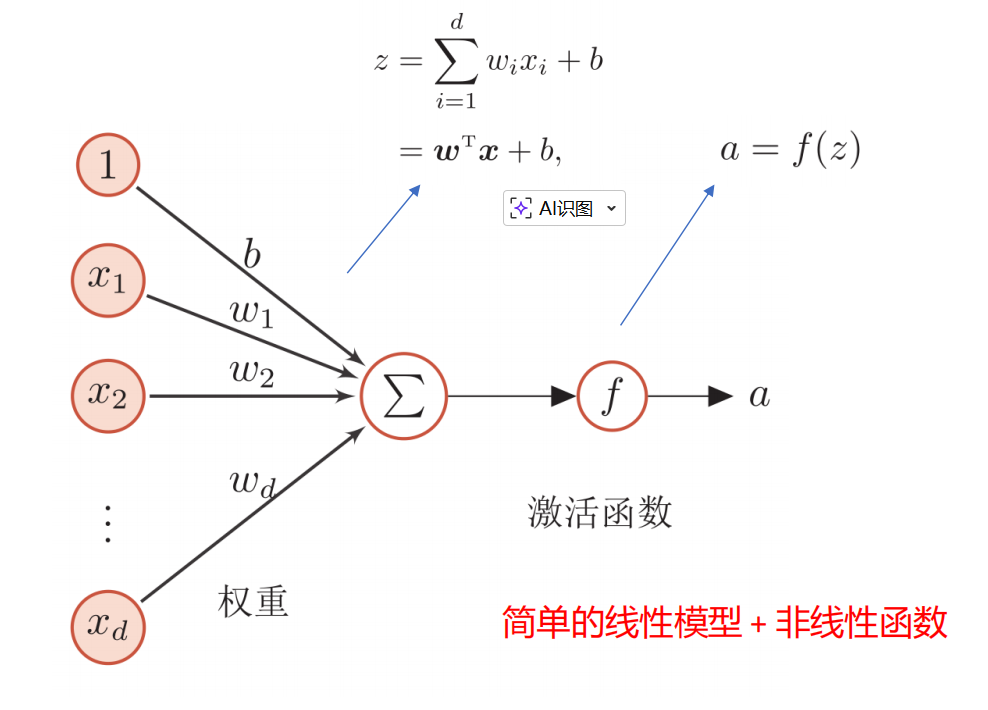
x是信号,也是输入层的input,到隐藏层经过权重的连接关系,向前传递到输出层。这种权重的关系我们称之为神经网络中的参数。连接边的数量--权重--需要拟合
我们要干的事情也就是模拟前向传播
前向传播的目的就是运用当前的神经网络参数得到结果
可以从这些问题入手:
为什么激活函数是非线性的?曲线是怎样的?=> 赋予神经网络拟合复杂模式的能力,如果使用线性激活函数,多层网络会退化为单层线性模型,无法学习非线性关系。非线性激活函数(如RELU、Sigmoid)通过引入非线性变化,是网络能够堆叠多层并逼近任意复杂函数 => 是深度学习强大表达能力的关键。
如何使用numpy模拟前向传播?(从左到右一层层向前传)
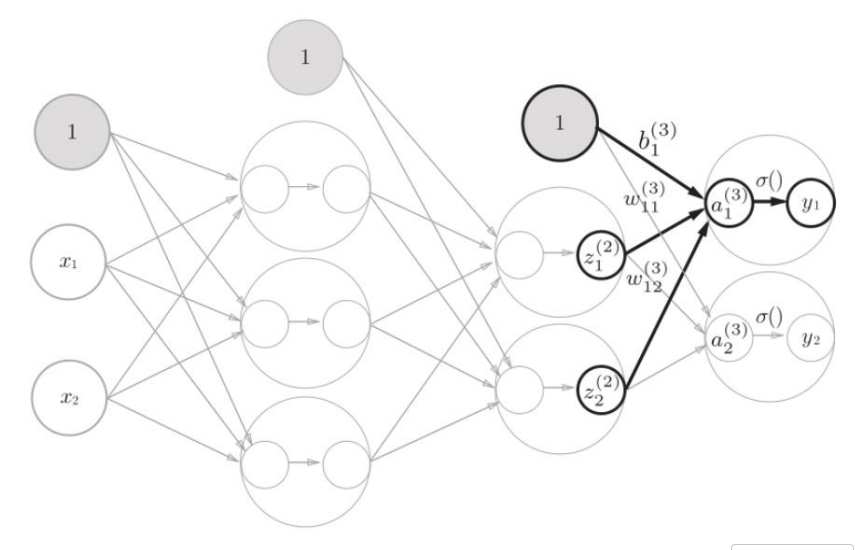
神经网络的权重: 中的(1)代表第1层的权重;下标i代表 下一层的第i个神经元;下标j代表 上一层的第j个神经元。每一层只和前一层相关,都是一个特征提取的结果。b是偏移项,要额外加减多少。
模拟神经网络的前向传播:
Step1,初始化网络 :设置3层神经网络的W和b
Step2,定义激活函数
第一层,第二层的激活函数使用sigmoid ;输出层的激活函数使用 恒等函数,即 g(x)=x
Step3,前向传播
前向传播比较简单,就是向量点乘(即加权求和),然后经过一个激活函数。最终输出预测结构Y'。
激活函数(拟合非线性)
神经网络中的神经元接受上一层神经元的输出值作为输入值,输入层神经元节点会将输入属性值直接传递给下一层 ,在多层神经网络中,上层节点的输出和下层节点的输入之间具有一个函数关系,这个函数称为激活函数
为什么需要激活函数:
如果不用激活函数,就相当于激励函数f(x) = x,此时每一层节点的输入都是上层输出的线性函
数,那么无论神经网络有多少层,输出都是输入的线性组合 => 与没有隐藏层效果相当
引入非线性函数作为激励函数,这样神经网络表达能力会更加强大 => 不再是输入的线性组合,而是几乎可以逼近任意函数
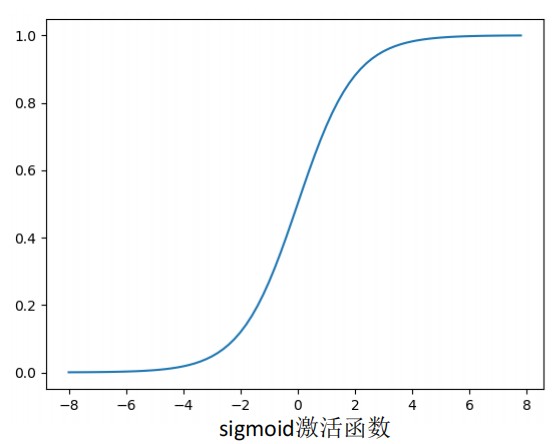
sigmoid激活函数
sigmoid函数:输入为连续实值,输出结果为0和1之间,负无穷的输出结果为0,正无穷的输出结果为1。
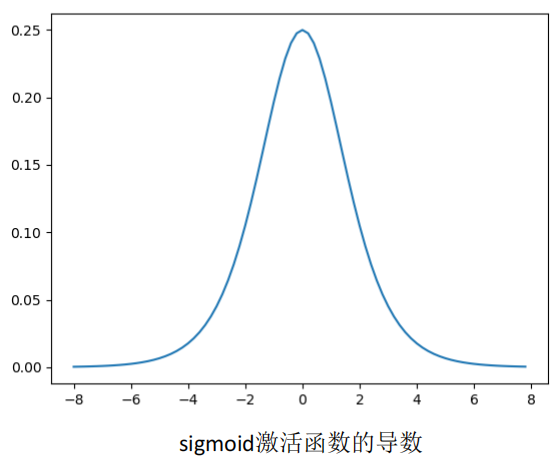
在深度神经网络中梯度反向传递时导致梯度爆炸和梯度消失,其中梯度爆炸发生的概率很小,而梯度消失发生的概率较大。
Sigmoid 的 output 不是0均值,这样会导致后一层的神经元将得到上一层输出的非0均值的信号
当 x>0, 对w求局部梯度都为正 => 反向传播中,w的更新,要么都往正方向更新,要么都往负方向更新,使得收敛缓慢。
常用于在二分类问题中,将输出结果映射到0,1。经常与二分类交叉熵损失一起使用
Sigmoid函数对中央区的信号增益较大,对两侧区的信号增益小,在信号的特征空间映射上,有很好的效果,从神经科学上来看,中央区属于神经元的兴奋态,两侧区属于神经元的抑制态,所以神经网络学习上,可以将重点特征推向中央区,将非重点特征推向两侧区。
梯度消失和梯度爆炸(本质都是链式法则的乘法效应)
反向传播干嘛?
反向传播就是从输出层往输入层倒着算,每个参数对最终预测误差的影响力(这个影响力就是梯度)。拿到梯度后,模型会按梯度大小和方向微调参数 ------ 梯度正常,参数更新就合理,模型就能慢慢学;梯度出问题,参数就更不了、乱更新,模型就学废了。
梯度下降需要每一层都有明确的误差才能更新参数,所以接下来的重点是如何将输出层的误差反向传播给隐藏层。
梯度消失:梯度越传越小最后几乎为0
从输出层往输入层传梯度时,梯度值一层比一层小,传到前面的隐藏层 / 输入层时,梯度几乎是 0。👉 结果:靠近输入层的参数几乎不更新,相当于模型只学了后面几层的浅层知识,深层网络白搭了。
结合 sigmoid 激活函数来看
- sigmoid 激活函数的导数有个 "硬上限":它的导数最大值只有0.25,所有点的导数都在 0~0.25 之间。
- 反向传播时,梯度要逐层乘上激活函数的导数 + 上一层的权重 w(链式法则)。比如初始化的权重 w 是 0~1 之间的随机数,那每传一层,梯度就会乘一个 "小于 0.25 的数 × 小于 1 的数",结果还是远小于 0.25。
- 深层网络(比如几十层)的话,梯度就会被连续乘几十个小于 1 的数,最后直接趋近于 0。
模型 "学不到深层特征",比如想让网络学图片的底层边缘→中层纹理→高层物体,结果底层边缘的参数更不了,模型只能瞎猜。
如果初始化神经网络的权值为 0,1 之间的随机值,由反向传播算法可知,梯度从后向前传播时,每传递一层梯度值都会减小为原来的0.25倍。如果神经网络层数多,那么梯度在多层传播后将变得很小(接近于0),即梯度消失 。当网络权值初始化为 (1,+∞) 区间内的值,则会出现梯度爆炸。
假设有三个隐藏层,每层的神经元个数都是1,对应的非线性激活函数为
我们要更新b1,就需要求出损失函数对于b1的导数,如果初始化的神经网络权重|w|小于1,
当层数增多时,小于1的值不断相乘,最后就导致梯度消失的情况出现。同理,当权重|w|过大时,导致 ,最后大于1的值不断相乘,就会产生梯度爆炸。
当梯度小于1时,预测值与真实值之间的误差每传播一层会衰减一次,如果在深层模型中使用sigmoid作为激活函数,这种现象尤为明显,将导致模型收敛停滞不前。
梯度消失发生时,接近于输出层的隐藏层由于其梯度相对正常,所以权值更新时也就相对正常,但是当越靠近输入层时,由于梯度消失,会导致靠近输入层的隐藏层权值更新缓慢或者停滞 => 这样就导致在训练时,只等价于后面几层的浅层网络的学习。
梯度爆炸:梯度越传越大,最后变成超大的数
从输出层往输入层传梯度时,梯度值一层比一层大,传到前面的层时,梯度变成特别大的数(几百、几千甚至无穷)。👉 结果:参数被大幅乱更新,模型的预测误差会突然飙升,直接发散,训练彻底不收敛。
和梯度消失是 "反过来的",核心还是反向传播的链式乘法:
- 如果初始化的权重 w 不是 0~1,而是大于 1 的数(比如 2、3),再结合激活函数的导数(比如 sigmoid 的 0.25),就会出现 "导数 × 权重> 1" 的情况(比如 0.25×5=1.25)。
- 深层网络中,梯度会连续乘几十个大于 1 的数,最后直接变成超大的数,也就是梯度爆炸。
模型参数变得极不稳定,预测结果忽大忽小,损失函数曲线直接 "飞上天",训练到一半就彻底崩了。
tanh激活函数:
y=tanh(x)是奇函数,即图像过原点并且穿越第一、第三象限的严格单调递增曲线。
定义域:R 值域:(-1, 1) 也称为双曲正切函数,函数曲线与Sigmoid函数相似, 可以通过缩放平移相互变换。
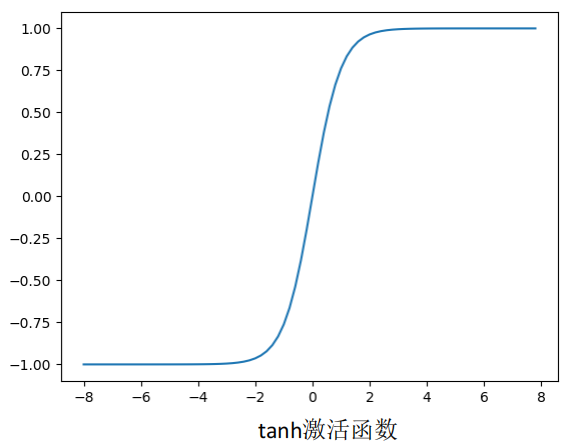
相比于sigmoid函数,tanh的均值是0,sigmoid函数均值不为0就意味着自带了一个bias,在计算时是额外的负担,这会使得收敛变得更慢
在原点附近更接近y=x,在几何变换运算中具有优势,比如在激活值较低时(也可以通过变换把结果映射到-1,1之间,tanh在 -1, 1的范围内和y=x 非常接近),可以利用indentity function的某些性质,直接进行矩阵运算
tanh相比于Sigmoid函数更容易训练,具有优越性。用于归一化回归问题,其输出在-1,1范围内。通常与L2损失一起使用。
Tanh函数是零中心化的,而sigmoid函数的输出恒大于0。非零中心化的输出会使得其后一层的神经元的输入发生偏置偏移(bias shift),并进一步使得梯度下降的收敛速度变慢。
激活函数relu

单侧抑制,它将所有负数输入都变成0,而正数则保持不变。
• relu的梯度:对于被激活的神经元(输入为正数),其梯度恒定为1。
在网络学习(反向传播)时,这意味着误差信号可以几乎无衰减地向后传递,不会像Sigmoid函数那样因逐层相乘而变得越来越小(梯度消失)。=> 信号既然能有效传达,权重就能被持续更新,所以模型能学得又快又稳。
总结:
激活函数的特点是非线性,而数据的分布绝大多数是非线性的 => 可以强化网络的学习能力
• 不同的激活函数特点不同,应用也不同
sigmoid和tanh函数输出值在(0,1)和(-1,1)之间 => 适合处理概率值、会产生梯度消失 => 不适合深层网络训练
relu的有效导数是常数1,解决了深层网络中出现的梯度消失问题 => 更适合深层网络训练。
怎么去训练神经网络呢?
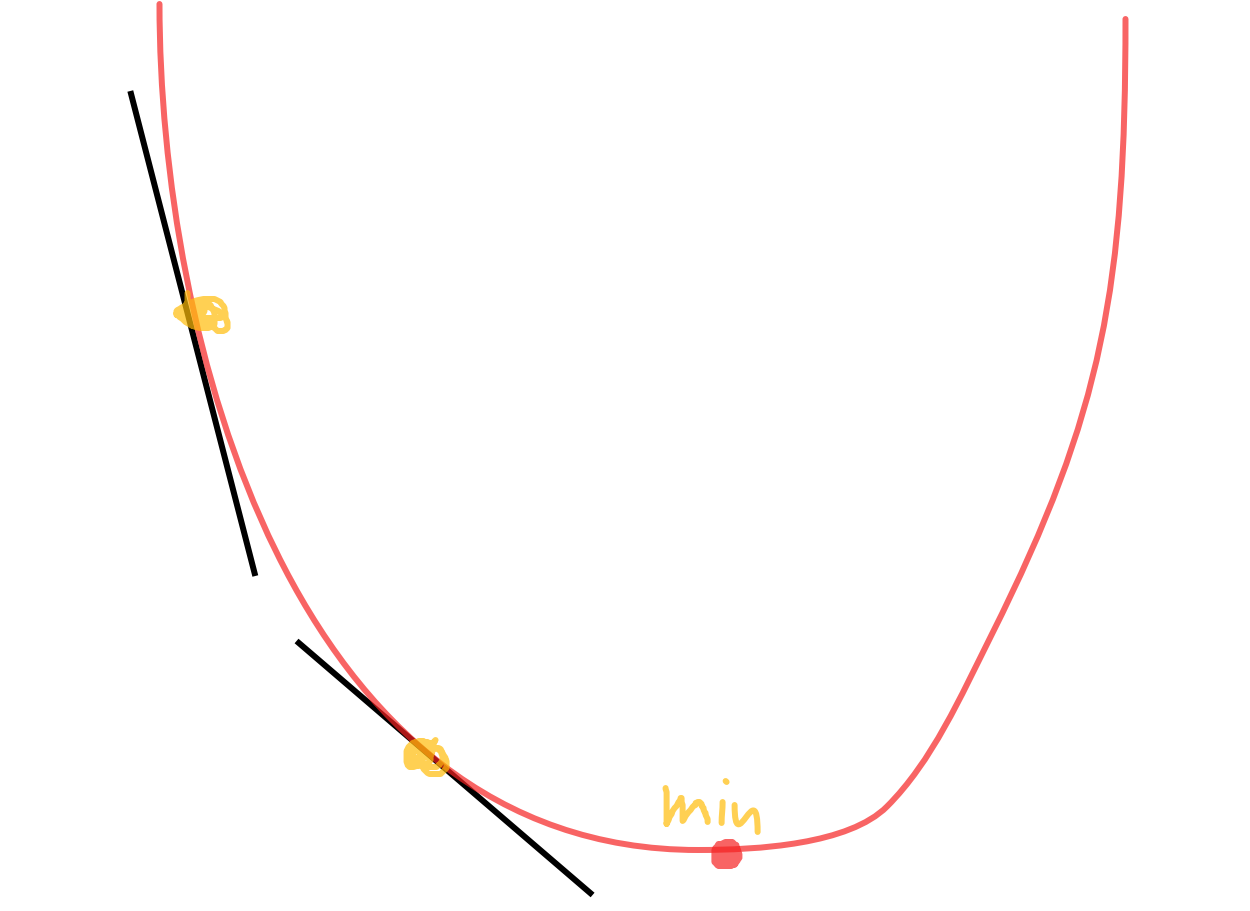
要让损失函数越小越好,刚开始误差很大,像一个二次函数,沿着切线走越来越接近min,后面变缓之后沿切线走依旧保持斜率的变化靠近min,所以梯度常常按照导数的方式。学习率就像是步长,走多了可能就到另一边去了,跨远了;走少了可能很久都接近不了底。可以离得远的时候步子大一点,离得近的时候步子小一点(动态学习率)。
SFT监督学习(人做标注)
整个流程:
1、定义网络结构(指定输入层、输出层、输出层的大小)
2、初始化模型参数
3、循环操作(多少次)
- 执行前向传播
- 计算损失函数
- 执行后向传播
- 权值更新
损失函数
用来衡量模型预测值与真实值不一致的程度,是一个非负实数函数
如果我们想要衡量神经网络对于两个类别的分类能力,可以使用二分类交叉熵损失函数 binary crossentropy。
有常见的两种衡量公式:

利用损失函数去做反向传播。
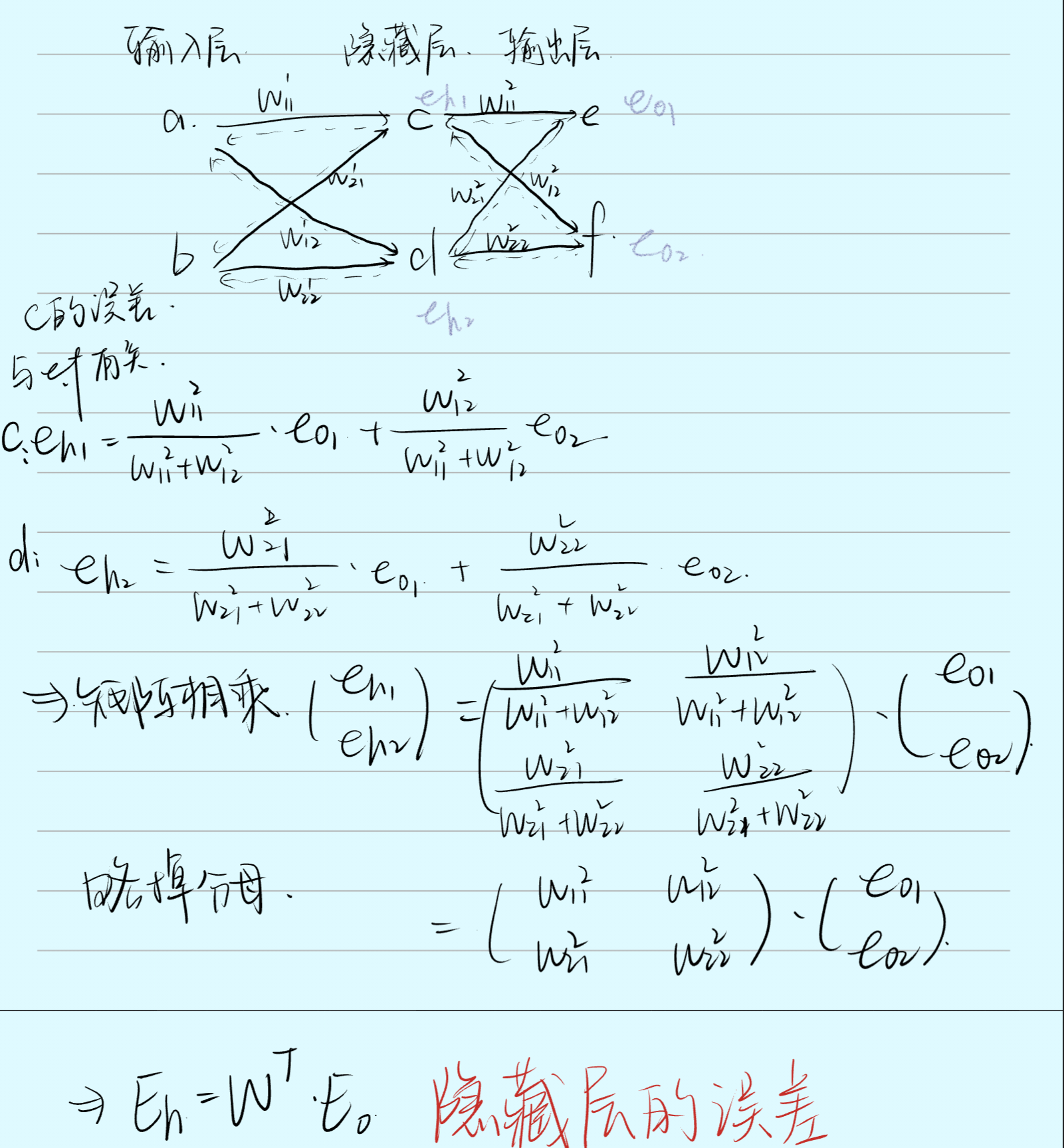
权重矩阵在反向传播的过程中同样扮演着传递的作用。前向传播:传递输入信号;反向传播:传递输出的误差
输出层误差在转置权重矩阵的帮助下,传递到了隐藏层,用来更新与隐藏层相连的权重矩阵。
优化方法
SGD,随机性下降(看切线指导方向)算法收敛速度快,但容易收敛到局部最优。SGD的缺点是更新方向依赖于当前batch计算出的梯度,因而很不稳定
Momentum,借用了物理中的动量概念,更新的时候在一定程度上保留之前更新的方向,同时利用当前batch的梯度微调最终的更新方向,即模拟了运动惯性。
Adagrad,自适应梯度算法,能够在训练中自动的对learning rate进行调整,对于出现频率较低参数采用较大的α更新,对于出现频率较高的参数采用较小的α更新
RMSprop,均方根传播,Adagrad会累加之前所有的梯度平方,而RMSprop仅仅是计算对应的平均值,可以缓解Adagrad算法学习率下降较快的问题
Adam, 结合了 AdaGrad 和 RMSProp 算法最优的性能,它还是能提供解决稀疏梯度和噪声问题的优化方法,在深度学习中使用较多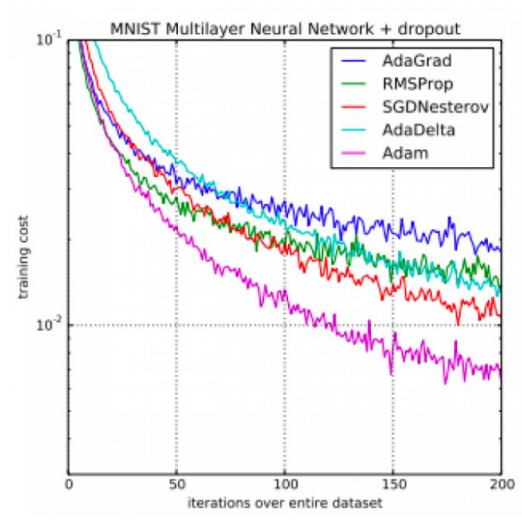
编一个神经网络
python
# 使用numpy实现一个神经网络
import numpy as np
import matplotlib.pyplot as plt
# 设置中文字体,解决中文显示乱码问题
plt.rcParams['font.sans-serif'] = ['SimHei', 'Microsoft YaHei', 'DejaVu Sans'] # 设置中文字体
plt.rcParams['axes.unicode_minus'] = False # 解决负号显示问题
# n为样本大小,d_in为输入维度,h为隐藏层维度,d_out为输出维度
n, d_in, h, d_out = 64, 1000, 100, 10
# 随机生成输入数据x和目标输出y
x = np.random.randn(n, d_in) # 输入数据,形状为(64, 1000)
y = np.random.randn(n, d_out) # 目标输出,形状为(64, 10)
# 随机初始化权重参数
# 输入层到隐藏层的权重(1000,100)
w1 = np.random.randn(d_in, h)
# 隐藏层到输出层的权重(100,10)
w2 = np.random.randn(h, d_out)
# 设置学习率
learning_rate = 1e-6
# 用于记录每次迭代的loss值
loss_history = []
# 训练500次
for t in range(500):
# 前向传播
temp = x.dot(w1) # 输入层到隐藏层的线性变换
temp_relu = np.maximum(temp, 0) # ReLU激活函数,隐藏层输出
y_pred = temp_relu.dot(w2) # 隐藏层到输出层的线性变换,得到预测值
# 计算损失函数(均方误差和)
loss = np.square(y_pred - y).sum()
loss_history.append(loss) # 记录loss值
print(t, loss)
# 反向传播,计算梯度
grad_y_pred = 2.0 * (y_pred - y) # 损失对预测输出的梯度
#print('grad_y_pred=', grad_y_pred.shape) #(64, 10)
grad_w2 = temp_relu.T.dot(grad_y_pred) # 损失对w2的梯度
grad_temp_relu = grad_y_pred.dot(w2.T) # 损失对隐藏层输出的梯度
grad_temp = grad_temp_relu.copy() # 复制一份用于ReLU处理
grad_temp[temp<0] = 0 # ReLU小于0的部分梯度置零
grad_w1 = x.T.dot(grad_temp) # 损失对w1的梯度
# 更新权重参数
w1 = w1 - learning_rate * grad_w1
w2 = w2 - learning_rate * grad_w2
# 绘制Loss曲线
plt.figure(figsize=(10, 6))
plt.plot(loss_history, 'b-', linewidth=2)
plt.title('训练过程中的Loss变化曲线', fontsize=14)
plt.xlabel('迭代次数', fontsize=12)
plt.ylabel('Loss值', fontsize=12)
plt.grid(True, alpha=0.3)
plt.show()
# 输出最终训练得到的权重参数
print(w1, w2)
# print(w1)
# print(w2) 这是一个两层神经网络:输入层 (1000维) --隐藏层 (100维) + ReLU激活 -- 输出层 (10维)。
训练流程:
- 前向传播:算预测值 y_pred
- 算 Loss:看看预测得有多差
- 反向传播 :算每个权重的梯度(就是 "该往哪个方向改、改多少")
- 更新权重:沿着梯度方向微调 w1、w2
- 循环 500 次 → Loss 越来越小
一、前向传播(算预测值)
python
temp = x.dot(w1) # 输入 × 权重w1
temp_relu = np.maximum(temp, 0) # ReLU激活(负数变0)
y_pred = temp_relu.dot(w2) # 隐藏层 × 权重w2 → 输出- 输入数据 x 经过 w1 加权 → 得到隐藏层值
- 用 ReLU 把负数变成 0(增加非线性)
- 再经过 w2 加权 → 得到最终预测 y_pred
| 前向参数 | 解读 | 形状(对应代码) | 核心作用 |
|---|---|---|---|
| temp | 隐藏层「激活前值」 | (64,100)(64 个样本,每个样本 100 个隐藏层神经元) | ReLU 激活的 "半成品",反向传播要判断它的正负来截断梯度 |
| temp_relu | 隐藏层「激活后值」 | (64,100) 和 temp 一样 | 前向传给 w2 算预测值,反向作为算 w2 梯度的 "原材料" |
| y_pred | 网络「预测值」 | (64,10)(64 个样本,每个样本 10 个输出) | 和真实值 y 比,算误差的核心 |
二、计算loss(判断预测准不准)
python
loss = np.square(y_pred - y).sum()均方误差和 :(预测值-真实值)² 全部加起来 Loss 越大 → 错得越离谱
三、反向传播(手动算梯度)
梯度 = 这个权重对最终 Loss 有多大影响
梯度告诉你:权重往 + 方向调,Loss 会变大还是变小
1、对输出求导
python
grad_y_pred = 2.0 * (y_pred - y)Loss = (y_pred - y)² 对 y_pred 求导 → 2(y_pred - y) 这是误差信号,从输出层开始往回传。
2、算w2的梯度
python
grad_w2 = temp_relu.T.dot(grad_y_pred)w2 是隐藏层→输出层的权重。梯度 = 隐藏层输出 × 输出误差
grad_w2针对w2的梯度,直接用来更新w2
3、把误差传回隐藏层
python
grad_temp_relu = grad_y_pred.dot(w2.T)误差要继续往前传,必须乘 w2 的转置 。把输出层的误差(grad_y_pred)传回隐藏层,得到「隐藏层每个神经元的误差」(理解为:输出层的误差,是隐藏层哪些神经元导致的)
4、处理relu激活
python
grad_temp = grad_temp_relu.copy()
grad_temp[temp < 0] = 0ReLU 函数:
- 正数 → 梯度 = 1
- 负数 → 梯度 = 0
所以小于 0 的位置,误差直接清零!这也是relu能缓解梯度消失的原因。
对 grad_temp_relu 做ReLU 反向处理后的最终隐藏层误差(因为 ReLU 的规则是:激活前 temp<0 的神经元,激活后是 0,对输出没贡献,所以这些神经元的误差要清零)
5、算w1的梯度
python
grad_w1 = x.T.dot(grad_temp)w1 是输入→隐藏层 的权重。梯度 = 输入数据 × 传回的误差。w1 中每个权重该怎么改的具体指令,和 grad_w2 逻辑完全一样,只是针对 w1
四、优化(用梯度更新权重)
python
w1 = w1 - learning_rate * grad_w1
w2 = w2 - learning_rate * grad_w2- 梯度是正 → 权重 减小一点,Loss 会下降
- 梯度是负 → 权重 增大一点,Loss 会下降
新权重 = 旧权重 - 学习率 × 梯度

总结:
前馈神经网络的训练过程可以分为以下三步
• 前向计算每一层的状态和激活值,直到最后一层
• 反向计算每一层的参数的偏导数(方向)
• 更新参数
TensorFlow
计算图(Graph)
定义:TensorFlow的计算图是一个由节点(操作)和边(张量)组成的数据流图,描述计算的依赖关系。
优点:
• 高效执行:图优化(如算子融合)可提升性能。
• 跨平台支持:可导出到移动端、嵌入式设备等。
计算图可加速计算,图模式下运算在C++层执行,避免Python循环的慢速交互。
能并行化优化:自动调度无依赖的节点并行计算(如GPU/多核CPU)。
什么是张量?
张量(Tensor) 是 TensorFlow 中的核心数据结构,可以理解为多维数组。
• 标量(0维):单个数值(如 3.0)。
• 向量(1维):一维数组(如 1, 2, 3)。
• 矩阵(2维):二维表格(如 \[1, 2, 3, 4])。
• 高维张量:如 RGB 图片(3维:高度, 宽度, 通道)。
张量存储数据,并在计算图中流动,支持自动求导和 GPU 加速。
图与会话的现代应用(TensorFlow 2.x)
1.x多是静态,写死计算不灵活。
在 TensorFlow 2.x 中,传统的 计算图(Graph)+ 会话(Session) 模式被大幅简化,但仍保留核心优化能力,主要通过 tf.function 和 即时执行(Eager Execution) 结合使用。
1)tf.function:自动构建计算图
作用:将普通 Python 函数转换为 TensorFlow 计算图,提升执行效率(如减少 Python 调用开销)。
优势:
• 加速训练/推理:适合循环、矩阵运算等密集计算。
• 跨平台部署:可导出为 SavedModel 供 TensorFlow Serving 使用。
@tf.function # 装饰器,自动编译为计算图
def add_and_multiply(x, y):
return x + y, x * y
result = add_and_multiply(2, 3) # 首次调用时构建图,后续高效执行
2)即时执行(Eager Execution)
Tensorflow2.0默认模式,一种交互式编程模式,让代码像普通 Python 程序一样逐行运行(类似NumPy),
无需先构建计算图,便于调试。
与图的协作:
• 调试时:用即时执行快速验证逻辑。
• 部署时:用 @tf.function 转换为图模式提升性能。
TF 1.x:需显式构建图和会话,适合高性能场景。
TF 2.x:默认即时执行,tf.function实现图模式加速。
a = tf.constant(2)
b = tf.constant(3)
print(a + b) # 直接输出 5,无需 Session
分布式训练
数据并行:将训练数据拆分到多个设备(如GPU/CPU),每个设备计算梯度后同步更新模型(主流方案)。
实现工具:tf.distribute.MirroredStrategy(单机多卡)、MultiWorkerMirroredStrategy(多机多卡)。
参数服务器(Parameter Server):部分设备存储模型参数,其余设备计算梯度(适合超大模型)。
纯粹课堂笔记,有任何侵权,联系我,马上删。