十二.RAG检索增强生成
12.1 基础概念
那么我们可以通过一个案例来告诉大家什么是RAG。假设我们现在有一个需求,就是AI智能运维助手,通过提供的错误编码,给出异常解释来辅助运维人员更好的定位问题和维护系统。
比如我们现在提供的错误代码中,00000代表success,A0001代表网络故障,A0002代表系统限流。但是传统的LLM是有缺陷的,比如LLM的知识不是实时的,不具备知识更新;LLM可能不知道你私有的领域/业务知识;LLM有时会在回答中生成看似合理但实际上是错误的信息。
LLM的知识仅限于它所接受的训练数据。如果你想让一个LLM了解特定领域的知识或专有数据,降低大模型出现幻觉的概率,你可以使用RAG;
简单来说,RAG(检索增强生成)是一种从你的数据中查找相关信息,并在将提示发送给LLM之前将其注入到提示中的方法。这样一来,LLM就能获得(希望是)相关的信息,并基于这些信息进行回答,从而降低产生幻觉的概率。
RAG技术就像给AI大模型装上了「实时百科大脑」,为了让大模型获取足够的上下文,以便获得更加广泛的信息源,通过先查资料后回答的机制,让AI摆脱传统模型的"知识遗忘和幻觉回复"困境。
类似考试时有不懂的,给你准备了小抄,对大模型知识盲区的一种补充
12.2 流程
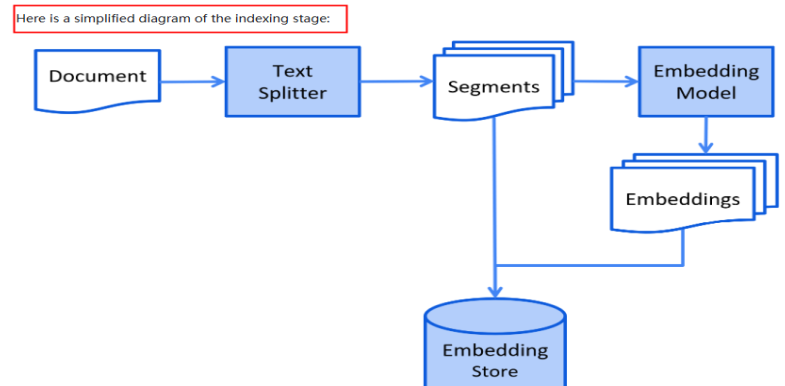
RAG流程分为两个不同的阶段:索引(Index) 和检索(Retrieval)
索引(Index)
索引首先清理和提取各种格式的原始数据,如PDF,HTML等,然后将其转换为统一的纯文本格式。为了适应语言模型的上下文限制,文本被分割为更小的,可消化的块(chunk)。然后使用嵌入模型将块编码成向量表示,并存储在向量数据库中。这一步对于在随后的检索阶段实现高效的相似性搜索至关重要。知识库被分割成chunks,并将chunks向量化至向量库中。
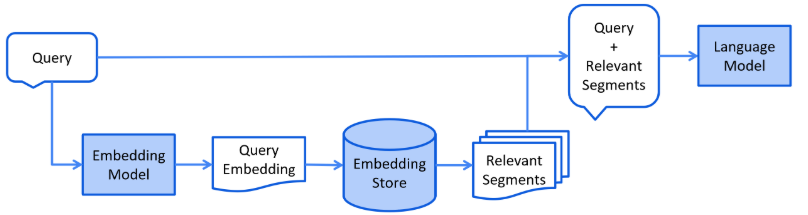
检索(Retrieval)
检索阶段通常在线进行,此时用户提交的问题应使用检索文档来回答。
在收到用户查询之后,RAG系统采用与索引阶段相同的编码模型将查询转化为向量表示,然后计算索引语料库中查询向量和块向量的相似性得分。该系统优先级和检索最高k(Top-K)块,显示最大的相似性查询。
12.3 实战案例
需求 : AI智能运维助手,通过提供的错误代码,给出异常解释辅助运维人员更好的定位问题和维护系统**(SpringAl+阿里百炼嵌入模型text-embedding-v3+向量数据库RedisStack+DeepSeek来实现RAG功能)**
步骤**:**
1.和以往一样,还是建立Module;和上一节向量一样加pom;yml也类似,不过改了模型变成了deepseek;然后就是主启动;原本的多模型modelclient和model的config类不变
2.接下来就是需要重视的业务类的编写了:
- 提供ops.txt脚本放到resources中,让他存入向量数据库RedisStack,形成文档知识库

版本1:
- 新建一个InitVectorDatabaseConfig类
初始化向量数据库对应的数据。即将上述的ops.text中的数据以文本向量化的形式作为向量化数据存储入向量数据库中
java
package ai.study.config;
import jakarta.annotation.PostConstruct;
import org.springframework.ai.document.Document;
import org.springframework.ai.reader.TextReader;
import org.springframework.ai.transformer.splitter.TokenTextSplitter;
import org.springframework.ai.vectorstore.VectorStore;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.beans.factory.annotation.Value;
import org.springframework.context.annotation.Configuration;
import org.springframework.core.io.Resource;
import java.nio.charset.Charset;
import java.util.List;
@Configuration
public class InitVectorDatabaseConfig
{
@Autowired
private VectorStore vectorStore;
@Value("classpath:ops.txt")
private Resource sqlFile;// 读取的文件
@PostConstruct
public void init()
{
// 1.读取文件
TextReader textReader = new TextReader(sqlFile);
textReader.setCharset(Charset.defaultCharset());//文档最好要设置一个编码,默认是utf-8,防止乱码
// 2.文件转换成向量(开启分词)
List<Document> list = new TokenTextSplitter().transform(textReader.read());
// 3.写入向量数据库(Redis),无法去重复版
vectorStore.add(list);
}}2.此时建立一个controller
java
package ai.study.controller;
import jakarta.annotation.Resource;
import org.springframework.ai.chat.client.ChatClient;
import org.springframework.ai.rag.advisor.RetrievalAugmentationAdvisor;
import org.springframework.ai.rag.retrieval.search.VectorStoreDocumentRetriever;
import org.springframework.ai.vectorstore.VectorStore;
import org.springframework.web.bind.annotation.GetMapping;
import org.springframework.web.bind.annotation.RestController;
import reactor.core.publisher.Flux;
@RestController
public class RagController
{
@Resource(name = "qwenChatClient")
private ChatClient chatClient;
@Resource
private VectorStore vectorStore;
/**
* http://localhost:8012/rag4aiops?msg=00000
* http://localhost:8012/rag4aiops?msg=C2222
* @param msg
* @return
*/
@GetMapping("/rag4aiops")
public Flux<String> rag(String msg)
{
String systemInfo = """
你是一个运维工程师,按照给出的编码给出对应故障解释,否则回复找不到信息。
""";
//顾问增强器(属于chatmemory中的内容)
RetrievalAugmentationAdvisor advisor = RetrievalAugmentationAdvisor.builder()
.documentRetriever(//检索
VectorStoreDocumentRetriever.builder()
.vectorStore(vectorStore)
.build()
)
.build();
return chatClient.prompt()
.system(systemInfo)//ai的身份
.user(msg)//用户输入
.advisors(advisor) // RAG功能,向量数据库查询
.stream()
.content();
}
}
但是上述版本会出现一个问题,就是每次我重启一次微服务,就会重新加载一次,然后redisstack中就会新增一次数据;因此需要重复数据过滤清洗的操作
版本二:---->向量数据库去重问题解决
使用redis setnx去重
1.先加入RedisConfig
java
package ai.study.config;
import lombok.extern.slf4j.Slf4j;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import org.springframework.data.redis.connection.RedisConnectionFactory;
import org.springframework.data.redis.core.RedisTemplate;
import org.springframework.data.redis.serializer.GenericJackson2JsonRedisSerializer;
import org.springframework.data.redis.serializer.StringRedisSerializer;
@Configuration
@Slf4j
public class RedisConfig
{
@Bean
public RedisTemplate<String, Object> redisTemplate(RedisConnectionFactory redisConnectionFactor)
{
RedisTemplate<String,Object> redisTemplate = new RedisTemplate<>();
redisTemplate.setConnectionFactory(redisConnectionFactor);
//设置key序列化方式string
redisTemplate.setKeySerializer(new StringRedisSerializer());
//设置value的序列化方式json,使用GenericJackson2JsonRedisSerializer替换默认序列化
redisTemplate.setValueSerializer(new GenericJackson2JsonRedisSerializer());
redisTemplate.setHashKeySerializer(new StringRedisSerializer());
redisTemplate.setHashValueSerializer(new GenericJackson2JsonRedisSerializer());
redisTemplate.afterPropertiesSet();
return redisTemplate;
}
}2. 修改InitVectorDatabaseConfig:
java
@Configuration
public class InitVectorDatabaseConfig
{
@Autowired
private RedisTemplate<String,String> redisTemplate;
......
// 3.写入向量数据库(Redis),无法去重复版
//vectorStore.add(list);
//4 去重复版本
String sourceMetadata = (String)textReader.getCustomMetadata().get("source");
String textHash = SecureUtil.md5(sourceMetadata);
String redisKey = "vector-xxx:" + textHash;
// 判断是否存入过,redisKey如果可以成功插入表示以前没有过,可以假如向量数据
Boolean retFlag = redisTemplate.opsForValue().setIfAbsent(redisKey, "1");
System.out.println("****retFlag : "+retFlag);
if(Boolean.TRUE.equals(retFlag))
{
//键不存在,首次插入,可以保存进向量数据库
vectorStore.add(list);
}else {
//键已存在,跳过或者报错
//throw new RuntimeException("---重复操作");
System.out.println("------向量初始化数据已经加载过,请不要重复操作");
}}十三.ToolCalling
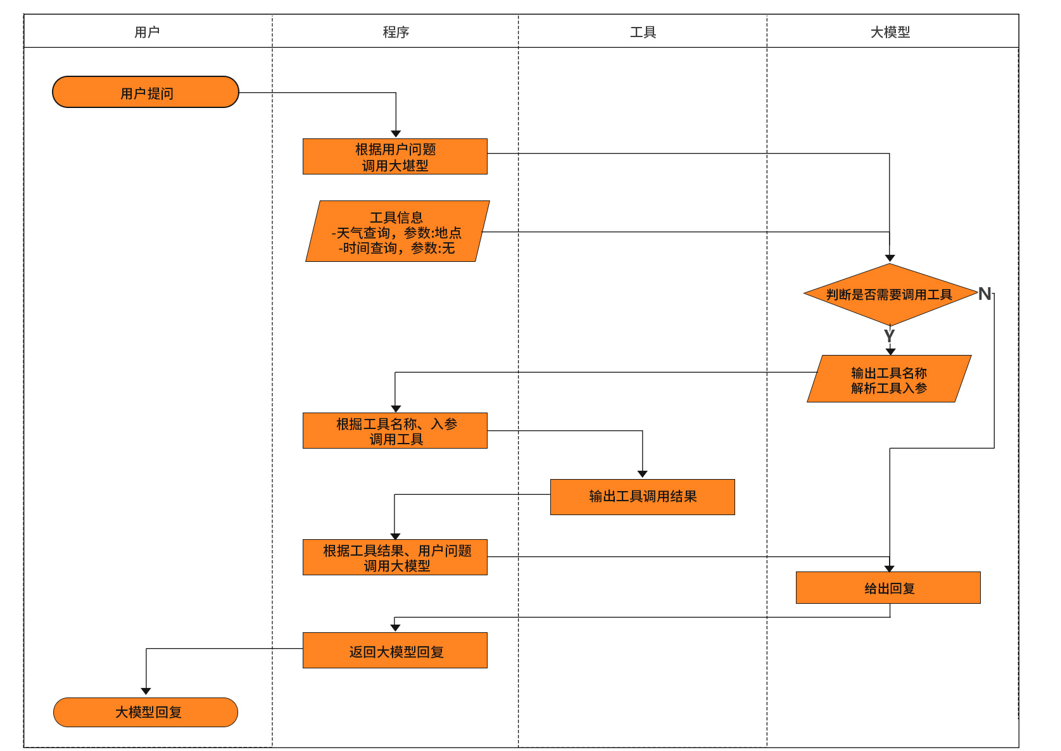
一句话概率,toolcalling就是LLM的外部utils工具类。ToolCalling(也称为FunctionCalling)它允许大模型与一组API或工具进行交互,将LLM的智能与外部工具或API无缝连接,从而增强大模型其功能。
但是注意,LLM本身并不执行函数,它只是指示应该调用哪个函数以及如何调用。如果不使用toolCalling,则会出现:

所以我们知道tool calling可以实现:
- 访问实时数据
- 执行某种工具类/辅助类操作
工作流程可以大致参考下述:
接下来就是开发步骤:
- 建子模块Module,改pom(dashscope就行),写yml,主启动和以往一样
接下来是业务类
- 新建Tool工具类,类似于Utils工具类
java
package ai.study.utils;
import org.springframework.ai.tool.annotation.Tool;
import java.time.LocalDateTime;
public class DateTimeTools
{
/**
* 1.定义 function call(tool call)
* 2. returnDirect
* true = tool直接返回不走大模型,直接给客户
* false = 拿到tool返回的结果,给大模型,最后由大模型回复
*/
//必须加描述description,LLM 靠这个判断调用哪个
@Tool(description = "获取当前时间", returnDirect = false)
public String getCurrentTime()
{
return LocalDateTime.now().toString();
}
}
- 描述(Description)就是"咒语" : LLM 决定调不调用你的函数,完全取决于你写的
@Description。如果描述写得模糊(比如只写"获取信息"),模型可能就不知道什么时候该用它。
3.controller类
java
import ai.study.utils.DateTimeTools;
import jakarta.annotation.Resource;
import org.springframework.ai.chat.client.ChatClient;
import org.springframework.ai.chat.model.ChatModel;
import org.springframework.ai.chat.prompt.ChatOptions;
import org.springframework.ai.chat.prompt.Prompt;
import org.springframework.ai.model.tool.ToolCallingChatOptions;
import org.springframework.ai.support.ToolCallbacks;
import org.springframework.ai.tool.ToolCallback;
import org.springframework.web.bind.annotation.GetMapping;
import org.springframework.web.bind.annotation.RequestParam;
import org.springframework.web.bind.annotation.RestController;
@RestController
public class ToolCallingController
{
@Resource
private ChatModel chatModel;
@GetMapping("/toolcall/chat")
public String chat(@RequestParam(name = "msg",defaultValue = "你是谁,现在几点了") String msg)
{
// 1.工具注册到工具集合里
//这是把你的 Java 对象"翻译"成大模型能理解的 JSON Schema 格式
ToolCallback[] tools = ToolCallbacks.from(new DateTimeTools());
// 2.将工具集配置进ChatOptions对象
ChatOptions options = ToolCallingChatOptions.builder().toolCallbacks(tools).build();
// 3.构建提示词
Prompt prompt = new Prompt(msg, options);
// 4.调用大模型
return chatModel.call(prompt).getResult().getOutput().getText();
}
}结果如下:


十四.MCP
之前的ToolCalling中每个大模型(如DeepSeek、ChatGPT)需要为每个工具单独开发接口(FunctionCalling),导致重复劳动。
而MCP就可以解决上述问题,它提供了一种标准化的方式来连接LLMs需要的上下文,MCP就类似于一个Agent时代的Type-C协议,希望能将不同来源的数据、工具、服务统一起来供大模型调用。更多概念详情,可查看:MCP简单介绍
Tool Calling :是 "技能点"。适合简单的、项目内部的、特定的功能扩展。
MCP :是 "生态圈"。它试图统一所有 AI 工具的接入标准。
14.1 本地MCP开发步骤
1. MCP-Server服务端的实现
仍然是建Module,然后就是改写pom
XML
<dependencies>
<!--注意事项(重要)
spring-ai-starter-mcp-server-webflux不能和<artifactId>spring-boot-starter-web</artifactId>依赖并存,
否则会使用tomcat启动,而不是netty启动,从而导致mcpserver启动失败,但程序运行是正常的,mcp客户端连接不上。
-->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter</artifactId>
</dependency>
<!--mcp-server-webflux-->
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-starter-mcp-server-webflux</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-test</artifactId>
<scope>test</scope>
</dependency>
</dependencies>写yml
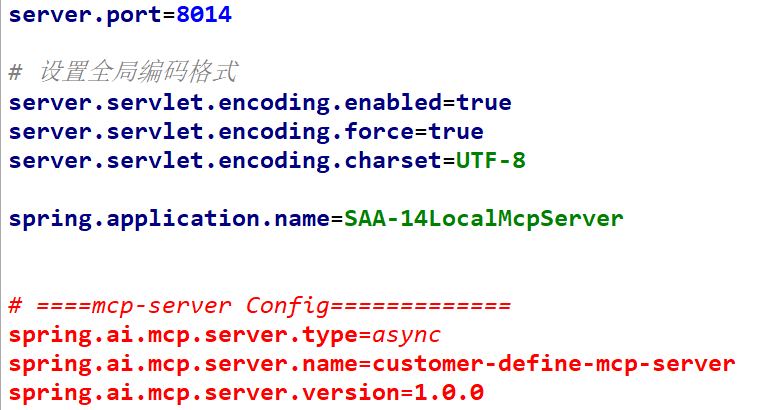
bash
# spring.ai.dashscope.api-key=${aliQwen-api}
# ====mcp-server Config=============
spring.ai.mcp.server.type=async
spring.ai.mcp.server.name=customer-define-mcp-server
spring.ai.mcp.server.version=1.0.0然后就是主启动,接下来就是业务类的编写
a. 天气预报WeatherService服务类
java
package ai.study.service;
import org.springframework.ai.tool.annotation.Tool;
import org.springframework.stereotype.Service;
import java.util.Map;
@Service
public class WeatherService
{
@Tool(description = "根据城市名称获取天气预报")
public String getWeatherByCity(String city)
{
Map<String, String> map = Map.of(
"北京", "11111降雨频繁,其中今天和后天雨势较强,部分地区有暴雨并伴强对流天气,需注意",
"上海", "22222多云,15℃~27℃,南风3级,当前温度27℃。",
"深圳", "333333多云40天,阴16天,雨30天,晴3天"
);
return map.getOrDefault(city, "抱歉:未查询到对应城市!");
}
}b.ToolCallbackProvider接口配置类
java
package ai.study.config;
import ai.study.service.WeatherService;
import org.springframework.ai.tool.ToolCallbackProvider;
import org.springframework.ai.tool.method.MethodToolCallbackProvider;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
@Configuration
public class McpServerConfig
{
/**
* 将工具方法暴露给外部 mcp client 调用
* @param weatherService
* @return
*/
@Bean
public ToolCallbackProvider weatherTools(WeatherService weatherService)
{
return MethodToolCallbackProvider.builder()
.toolObjects(weatherService)
.build();
}
}在之前的 Tool Calling 里,我们要手动注册工具;而这里的**MethodToolCallbackProvider** 像是一个"雷达探测器",它会自动扫描 WeatherService 中所有带 @Tool 注解的方法,并打包发布。外部 Client 只要一连接,就能立刻看到这些"技能清单"。
2. MCP-Client客户端的实现
客户端的职责是:发现服务端 --------握手连接--------托管给 LLM。
接下来还是新建子模块Module,然后就是改pom
XML
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
<!--spring-ai-alibaba dashscope-->
<dependency>
<groupId>com.alibaba.cloud.ai</groupId>
<artifactId>spring-ai-alibaba-starter-dashscope</artifactId>
</dependency>
<!-- 2.mcp-clent 依赖 -->
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-starter-mcp-client</artifactId>
</dependency>然后就是写yml: 客户端需要知道 Server 在哪里
bash
# ====SpringAIAlibaba Config=============
spring.ai.dashscope.api-key=${aliQwen-api}
# ====mcp-client Config=============
spring.ai.mcp.client.type=async
spring.ai.mcp.client.request-timeout=60s
spring.ai.mcp.client.toolcallback.enabled=true
# 指向你的 MCP Server 地址
spring.ai.mcp.client.sse.connections.mcp-server1.url=http://localhost:8014mcp-server1 是给这个连接起的别名。你可以配置多个 URL,连接来自全世界的MCP Server
主启动编写完,就是业务类的编写:
- LLMConfig并添加tool调用
java
package ai.study.config;
import org.springframework.ai.chat.client.ChatClient;
import org.springframework.ai.chat.model.ChatModel;
import org.springframework.ai.tool.ToolCallbackProvider;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
@Configuration
public class SaaLLMConfig
{
@Bean
public ChatClient chatClient(ChatModel chatModel, ToolCallbackProvider tools)
{
return ChatClient.builder(chatModel)
.defaultToolCallbacks(tools.getToolCallbacks()) //mcp协议,配置见yml文件
.build();
}
}-
ToolCallbackProvider tools是从哪来的? 这就是 MCP Starter 的"魔法"。当你开启了 MCP 客户端,Spring 会自动创建一个名为tools的 Bean,里面包含了从远程8014服务器抓取到的所有工具。 -
defaultToolCallbacks: 你把这些抓到的工具直接塞进了ChatClient的默认配置里。这意味着,只要你用这个chatClient说话,它就天生自带了远程服务器上的所有技能。
2.controller
java
package ai.study.controller;
import jakarta.annotation.Resource;
import org.springframework.ai.chat.client.ChatClient;
import org.springframework.ai.chat.model.ChatModel;
import org.springframework.web.bind.annotation.GetMapping;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.RequestParam;
import org.springframework.web.bind.annotation.RestController;
import reactor.core.publisher.Flux;
@RestController
public class McpClientController
{
@Resource
private ChatClient chatClient;//使用mcp支持
@Resource
private ChatModel chatModel;//没有纳入tool支持,普通调用
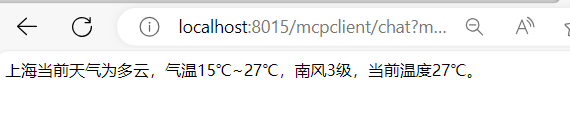
// http://localhost:8015/mcpclient/chat?msg=上海
@GetMapping("/mcpclient/chat")
public Flux<String> chat(@RequestParam(name = "msg",defaultValue = "北京") String msg)
{
System.out.println("使用了mcp");
return chatClient.prompt(msg).stream().content();
}
@RequestMapping("/mcpclient/chat2")
public Flux<String> chat2(@RequestParam(name = "msg",defaultValue = "北京") String msg)
{
System.out.println("未使用mcp");
return chatModel.stream(msg);
}
}此时访问即为:
14.2 远程MCP增强案例-对接互联网通用MCP服务(百度地图)
如果我们想要本地当MCP Client,然后远程的百度地图来MCP Server,那么此时我们先要能到可以调用上万个通用MCP的地方:https://mcp.so/zh
原理说明:
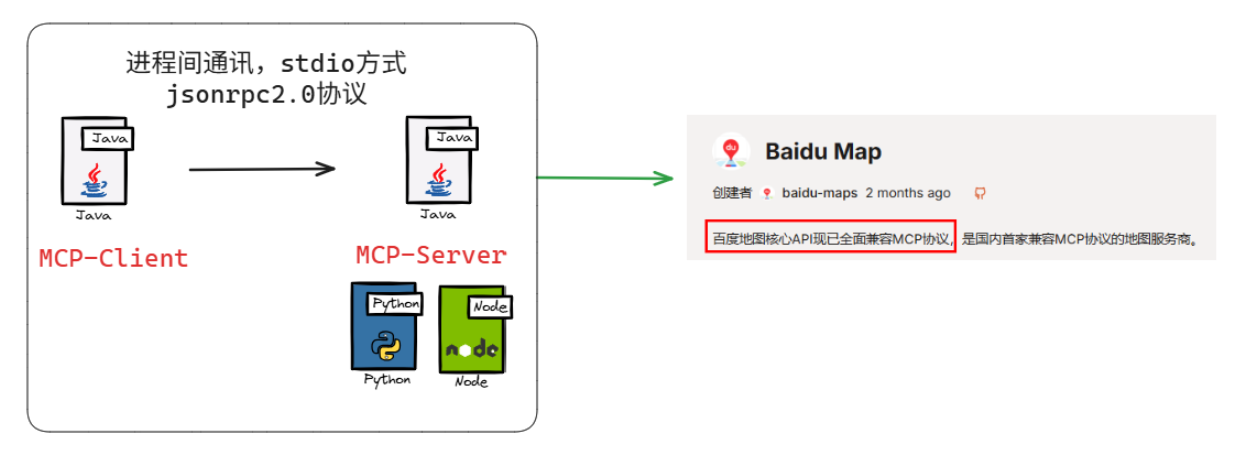
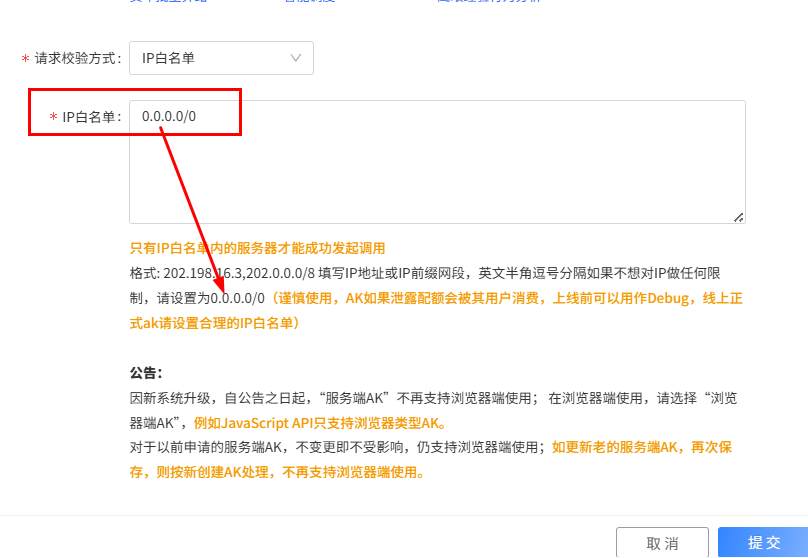
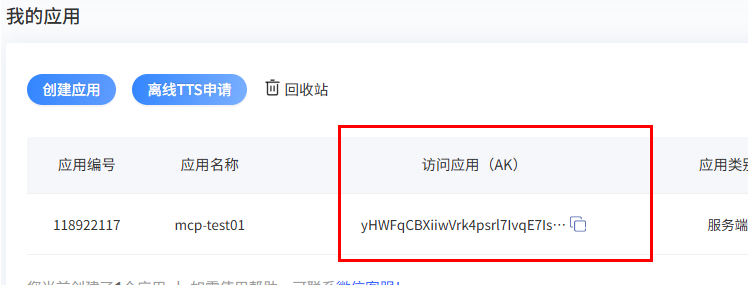
那么在此,我们环境的配置选择的是NodeJS,接着我们应该注册百度地图账号+申请API-key
接下来,我们加入编码开发:
- 建完module之后,修改pom
XML
<!-- 1.大模型依赖 -->
<dependency>
<groupId>com.alibaba.cloud.ai</groupId>
<artifactId>spring-ai-alibaba-starter-dashscope</artifactId>
</dependency>
<!-- 2.mcp-clent 依赖 -->
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-starter-mcp-client</artifactId>
</dependency>- 写yml
bash
server.port=8016
# 设置全局编码格式
server.servlet.encoding.enabled=true
server.servlet.encoding.force=true
server.servlet.encoding.charset=UTF-8
spring.application.name=springAI-16chat-mcpclient-call-baidumcp
# ====LLM Config=============
spring.ai.dashscope.api-key=${aliQwen-api}
# ====mcp-client Config=============
spring.ai.mcp.client.request-timeout=20s
spring.ai.mcp.client.toolcallback.enabled=true
#
spring.ai.mcp.client.stdio.servers-configuration=classpath:/mcp-server.json5- 写mcp-server.json5,放在resources下:

bash
{
"mcpServers":
{
"baidu-map":
{
"command": "cmd",
"args": ["/c", "npx", "-y", "@baidumap/mcp-server-baidu-map"],
"env": {"BAIDU_MAP_API_KEY": "你猜"}
}
}
}注意此时用json5而不是json的一大原因在于json不能写注释
- 写主启动启动,此时可以看到后台mcp配置,然后写业务类

- 业务类中SaaLLMConfig,controller和上节一摸一样,此处就不再演示
此时查询:http://localhost:8016/mcpclient/chat?msg=查询北京39.9042归到位置

十五.SAA生态篇,后续不再更新
具体看上方资源