告别臃肿的运行环境和缓慢的爬取速度。本文带你深度解析 Go 语言最强爬虫框架 Colly:从极速上手到实战案例,手把手教你构建高性能数据采集系统!
 在数据采集领域,Python 的
在数据采集领域,Python 的 Scrapy 和 BeautifulSoup 一直是老大哥。但随着互联网数据量的激增,开发者们开始追求更高的并发性能和更低的资源占用。
如果你是一名 Go 语言爱好者 ,或者正深受 Python 并发瓶颈的困扰,那么今天这款神器你绝对不能错过------它就是 Colly。
为什么选择 Colly?
Colly 是目前 Go 语言生态中最受欢迎的爬虫框架,GitHub Star 已突破 25k。它的核心优势可以用三个词概括:快速、优雅、强大。
- 性能炸裂: 基于 Go 语言原生的并发机制,Colly 能够轻松处理每秒上千个页面的抓取。
- 轻量级: 无需复杂的配置,一个
.go文件就能写出一个完整的爬虫。 - 功能全能: 自动处理 Cookie、支持分布式抓取、动态限制频率、代理切换、以及类似 jQuery 的选择器。
- 易于部署: Go 编译成单个二进制文件的特性,让你在服务器上部署爬虫时,再也不用担心 Python 那些烦人的库依赖问题。
快速上手:30 秒写出你的第一个爬虫
安装 Colly 非常简单,确保你的环境中已经配置好了 Go:
bash
go get -u github.com/gocolly/colly/v2接下来,我们写一个简单的爬虫,抓取知名技术博客的标题。
go
package main
import (
"fmt"
"github.com/gocolly/colly/v2"
)
func main() {
// 初始化收集器
c := colly.NewCollector()
// 注册回调函数:在找到 HTML 元素时触发
c.OnHTML(".titleline > a", func(e *colly.HTMLElement) {
fmt.Printf("发现标题: %s \n链接: %s\n\n", e.Text, e.Attr("href"))
})
// 启动爬虫
c.Visit("https://news.ycombinator.com/")
}原始网页:
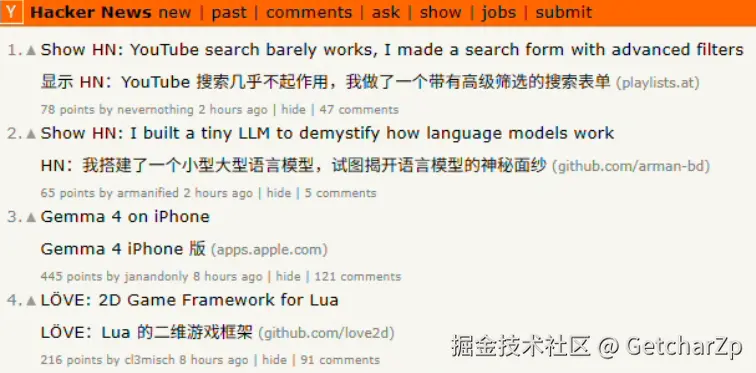
爬取结果:

解析:
colly.NewCollector()是爬虫的核心对象。OnHTML是最常用的回调,它允许你使用 CSS 选择器定位元素,就像写前端代码一样直观。Visit()则是点火启动。
核心进阶:掌控 Colly 的"超能力"
如果只是抓取简单页面,Colly 还不至于被称为"神器"。它的真正威力体现在对复杂场景的处理上。
并发控制与限速
在爬取大型网站时,如果请求太快会被封 IP。Colly 提供了极简的限制配置:
go
c := colly.NewCollector(
colly.Async(true), // 开启异步
)
c.Limit(&colly.LimitRule{
DomainGlob: "*",
Parallelism: 2, // 最大并发数
Delay: 5 * time.Second, // 每次请求间隔
})
c.Wait()自动处理链接追踪
想爬取整个网站?你只需要在 OnHTML 里找到所有的 <a> 标签并继续 Visit。Colly 会自动去重,确保不会陷入死循环。
go
c.OnHTML("a[href]", func(e *colly.HTMLElement) {
link := e.Attr("href")
e.Request.Visit(link) // 自动发现并继续抓取
})代理与身份伪装
为了对抗反爬虫,随机 User-Agent 和代理是标配:
go
// 随机 User-Agent
extensions.RandomUserAgent(c)
// 设置代理池
rp, _ := proxy.RoundRobinProxySwitcher("http://proxy1:8080", "http://proxy2:8080")
c.SetProxyFunc(rp)实战避坑指南
在使用 Colly 进行大规模抓取时,有几个经验分享给大家:
- 善用
OnResponse: 有时候页面返回的不是 HTML 而是 JSON 或 XML,在OnResponse里直接处理e.Body更高效。 - 存储上下文: 爬虫是异步的,如果你需要在多个请求间传递数据,可以使用
e.Request.Ctx。 - 错误处理: 务必注册
OnError回调。网络波动或 403 错误如果不捕获,你可能根本不知道爬虫为什么停了。
结语
Go 语言的静态类型、卓越并发以及像 Colly 这样成熟的框架,使得它正在成为爬虫工程师的新宠。相比于 Python,它带来的不仅是速度的提升,更是对代码结构和系统稳定性的掌控。