深度学习是当下热门的机器学习研究方向,它是使用深层架构的机器学习的方法,已经广泛应用于人工智能所涉及的众多领域,例语音识别、计算机视觉、自然语言、在线广告等,作为深度学习框架的PyTorch可以在该领域中大展宏图。
1 神经网络概述
神经网络的概念最初来源于生物学家对大脑神经网络的研究,从中发现其神经元的工作原理,并且从数学角度提出感知模型,并对其进行抽象化。
1.1 神经元模型
神经元模型是1943年,由心理学家Warren McCulloch和数理逻辑学家Walter Pitts在合作的《A logical calculus of ideas immanent in nervous activity》论文提出,并给出了人工神经网络的概念及人工神经元的数学模型,从而开创了人工神经网络研究的时代。
在神经网络中,神经元处理单元可以表示不同的对象,例如特征、字母、概念,或者一些有意义的抽象模式。网络中处理单元的类型分为3类:输入单元、输出单元和隐单元。输入单元接收外部世界的信号与数据;输出单元实现系统处理结果的输出;隐单元是处在输入和输出单元之间,不能由系统外部观察的单元。神经元间的连接权值反映了单元间的连接强度,信息的表示和处理体现在网络处理单元的连接关系中。
神经网络基因是一种模仿生物神经网络的结构和功能的数学模型或计算模型。它是由大量的节点(即神经元)和之间的相互连接构成的,每个节点代表一种特定的输出函数,称为激励函数,每两个节点间的连接都代表一个对于通过该连接信号的加权值,称之为权重。神经元是神经网络的基本元素。
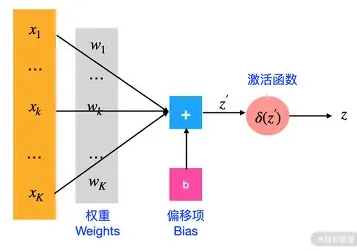
图中是x1x_1x1...xnx_nxn从其他神经元传来的输入信号,wijw_{ij}wij表示从神经元jjj到神经元iii的连接权值,θ\thetaθ表示一个阈值,或称为偏置,则神经元iii的输出与输入的关系表示为:
neti=∑j=1nwijxj−θnet_i=\sum_{j=1}^n w_{ij}x_j - \thetaneti=j=1∑nwijxj−θ
yi=f(neti)y_i=f(net_i)yi=f(neti)
其中yiy_iyi表示神经元iii的输出,函数fff称为激活函数,netinet_ineti称为净激活。若将阈值看成是神经元iii的一个输入x0x_0x0的权值wi0w_{i0}wi0,则上面的式子可以化简为:
neti=∑j=1nwijxjnet_i=\sum_{j=1}^n w_{ij}x_j neti=j=1∑nwijxj
yi=f(neti)y_i=f(net_i)yi=f(neti)
若用XXX表示输入向量,用WWW表示权重向量。即:X=x0,x1,...,xnX=x_0,x_1,\\dots,x_ nX=x0,x1,...,xn,W=wi0wi1wi2⋮winW=\begin{bmatrix}w_{i0}\\w_{i1}\\w_{i2}\\ \vdots\\w_{in}\end{bmatrix}W= wi0wi1wi2⋮win
则神经元的输出可以表示为向量相乘的形式:
neti=XWnet_i=XWneti=XW
yi=f(neti)=f(XW)y_i=f(net_i)=f(XW)yi=f(neti)=f(XW)
如果神经元的净激活为正,则称该神经元处于激活状态或兴奋状态,如果净激活为负,则称该神经元处于抑制状态。
1.2 多层感知器
多层感知器是一种前向结构的人工神经网络,映射一组输入向量到一组输出向量。MLP可以认为是一个有向图,由多个节点层组成,每一层全连接到下一层。除了输入节点外,每个节点都是一个带有非线性激活函数的神经元(或称处理单元)。
一种被称为反向传播算法的监督学习方法常被用来训练MLP,MLP是感知器的推广,克服了感知器不能对线性不可分数据进行识别的弱点。若每个神经元的激活函数都是线性函数,则任意层数的MLP都可以被简化为一个等价的单层感知器。
实际上,MLP本身可以使用任何形式的激活函数,譬如阶梯函数或逻辑S函数(Locisitic Sigmoid Function),但为了使用反向传播算法进行有效学习,激活函数必须限制为可微函数。由于具有良好的可微性,很多S形函数,尤其是双曲正切函数(Hyperbolic Tangent)及逻辑S形函数,被采用为激活函数。
常被MLP用来进行学习的反向传播算法在模式识别的领域中是标准监督学习算法,并在计算神经学及并行分布式处理领域中持续成为被研究的课题。MLP已被证明是一种通用的函数近似方法,可以被用来拟合复杂的函数,或解决分类问题。
MLP在80年代的时候曾是相当流行的机器学习方法,拥有广泛的应用场景,譬如语言识别、图像识别、机器翻译等,但自90年代以来,MLP遇到来自更为简单的支持向量机的强劲竞争。由于深层学习的成功,MLP又重新得到了关注。
多层感知器模型如图所示。
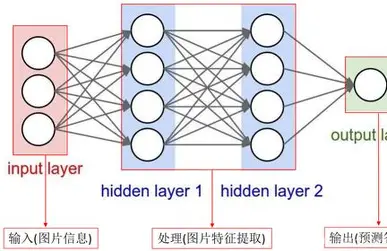
隐藏层神经元的作用是从样本中提取样本数据中的内在规律模式并保存起来,隐藏层每个神经元与输入层都有边相连,隐藏层将输入数据加权求和,并通过非线性映射作为输出层的输入,通过对输入层的组合加权及映射找出输入数据的相关模式,而且这个过程是通过误差反向传播自动完成的。
当隐藏层节点太少的时候,能够提取以及保存的模式较少,获得的模式不足以概括样本的所有有效信息,得不到样本的特定规律,导致识别同样模式新样本的能力较差,学习能力较差。
当隐藏层节点个数过多时,学习时间变长,神经网络的学习能力较强,能学习较多输入数据之间的隐含模式。但是一般来说,输入数据之间与输出数据相关的模式个数未知,当学习能力过强时,有可能把训练输入样本与输出数据无关的非规律性模式学习进来,而这些非规律性模式往往大部分是一些样本噪声,这种情况叫作过拟合(Over Fitting)。过拟合是记住了过多和特定样本相关的信息,当新来样本含有相关模式但是很多细节并不相同时,预测性能并不是太好,降低了泛化能力。这种情况的表现往往是在训练数据集上误差极小,测试数据集上误差较大。
具体隐藏层神经元个数的多少取决于样本中蕴含规律的个数以及复杂程度,而样本蕴含规律个数往往和样本数量有关系。确定网络隐藏层参数的一个办法是将隐藏层个数设置为超参,使用验证集验证,选择在验证集中误差最小的作为神经网络的隐藏层节点个数。还有就是通过简单的经验设置公式来确定隐藏层神经元个数:
l=m+n+αl=\sqrt{m+n}+\alphal=m+n +α
其中,lll是隐藏层节点个数,mmm是输入层节点个数,nnn是输出层节点个数,α\alphaα一般是1~10的常数。
1.3 前馈神经网络
不同的人工神经网络有着不同网络连接的拓扑结构,比较直接的拓扑结构是前馈网络,它是最早提出的多层人工神经网络。在前馈神经网络中,每一个神经元分别属于不同的层,每一层神经元可以接受前一层神经元的信号,并产生信号输出到下一层神经元。第0层神经元叫输入层,最后一层神经元叫输出层,其他处于中间层次的神经元叫隐藏层。
在前馈神经网络(Feedforward Neural Network,FNN)中,每一层的神经元可以接收前一层的神经元的信号,并产生信号输出到下一层。整个网络中无反馈,信号从输入层向输出层单向传播。
前馈神经网络通过下面的公式进行信息传播:
z(l)=W(l).α(l−1)+b(l)z^{(l)}=W^{(l)} . \alpha^{(l-1)}+b^{(l)}z(l)=W(l).α(l−1)+b(l)
α(l)=fl(z(l))\alpha^{(l)}=f_l(z^{(l)})α(l)=fl(z(l))
其中:
- L:表示神经网络的层数
- m(l)m^{(l)}m(l):表示第lll层神经元的个数
- fl(.)f_l(.)fl(.):表示lll层神经元的激活函数
- W(l)∈Rm(l)×m(l−1)W^{(l)} \in R^{m^{(l)} \times m^{(l-1)}}W(l)∈Rm(l)×m(l−1):表示l−1l-1l−1层到第lll层的权值矩阵。
- b(l)∈Rm(l)b^{(l)} \in R^{m^{(l)}}b(l)∈Rm(l):表示l−1l-1l−1层到第lll层的偏置
- z(l)∈Rm(l)z^{(l)} \in R^{m^{(l)}}z(l)∈Rm(l):表示lll层神经元的净输入
- α(l)∈Rm(l)\alpha^{(l)} \in R^{m^{(l)}}α(l)∈Rm(l) :表示lll层神经元的输出
这样前馈神经网络通过逐层的信息传递得到网络最后的输出。整个网络可以看为一个复合函数,将向量XXX作为第1层的输入α0\alpha^0α0,将第L层的输出α(L)\alpha^{(L)}α(L)作为整个函数的输出。
α(L)=ψ(X,W,b)\alpha^{(L)}=\psi(X,W,b)α(L)=ψ(X,W,b)
2.卷积神经网络
卷积神经网络(Convolutional Neural Network,CNN)是一类包含卷积计算且具有深度结构的前馈神经挖过来,它是深度学习框架中的代表算法之一。
2.1 卷积神经网络的历史
卷积神经网络最早可以追溯到1943年,心理学家Warren和数理逻辑学家Walter在论文中第一次提出神经元的概念,通过一个简单的数学模式将神经反应简化为信号输入、求和、线性激活及输出,具有开创性意义;1958年,神经学家Frank通过机器模拟了人类的感知能力,这就是最初的"感知器",同时他在当时的IBM704型电子数字计算机上完成了感知器的仿真,能够对三角形和四边形进行分类,这是神经元概念提出后第一次成功实验,验证了神经元概念的可行性。以上是神经元发展的第一阶段。第一代神经网络由于结构单一,仅能解决线性问题。此外,认知的限制也使得神经网络的研究止步于此。
第二代卷积神经网络出现于1985年,Geoffrey Hinton在神经网络中使用多个隐含层进行权重变换,同时提出了误差反向传播(Backpropagation,BP)算法,求解各隐含层的网络参数,优点是理论基础牢固、通用性好,不足之处在于网络收敛速度慢,容易出现局部极小的问题;1988年,Wei Zhang鹈鹕了平移不变人工神经网络(Shift-Invariant Artificial Neural Network,SIANN),将其应用于医学图像检测领域;1989年,Lecun构建了应用于计算机视觉问题的卷积神经网络,也就是LeNet的早期版本,包含两个卷积层、两个全连接层,共计6万多个参数,结构上与现代的卷积神经网络结构相似,而且开创性提出来"卷积"这一概念,卷积神经网络因此得名。1988年,Lecun构建了更加完备的卷积神经网络LeNet-5,并将其应用于手写字体识别,在原有LeNet的基础上加入了池化层,模型在Mnist数据集上的识别准确率达到了98%以上,但由于当时不具备大规模计算能力的硬件条件,因此卷积神经网络的发展并没有引起足够的重视。
第三代卷积神经网络兴起于2006年,统称为深度学习,分为两个阶段,2006至2012年为快速发展期,2012至今为爆发期,训练数据量越大,卷积神经网络准确率越高,同时随着具备大规律计算能力GPU的应用,模型的训练时间大大缩短,深度卷积神经网络的发展是必然的趋势。2006年,Hintont提出了包含多个隐含层的深度置信网络(Deep Belief Network,DBN),取得了十分好的训练效果,DBN的成功实验拉开了卷积神经网络百花齐放的序幕:自2012年AlexNet取得ImageNet视觉挑战赛的冠军,几乎每年都有新的卷积神经网络产生,诸如ZFNet、VGGNet、GoogLeNet、ResNet以及DPRSNet等,都取得了很好的效果。
2.2 卷积神经网络的结构
卷积神经网络中隐含层低层中的卷积层与池化层交替连接,构成了卷积神经网络的核心模块,高层由全连接层构成。
2.2.1 卷积层
卷积层用于提取输入的特征信息,由若干卷积单元组成,每个卷积单元的参数都是通过反向传播算法优化得到的,通过感受野(Filter)对输入图片进行有规律地移动,并与所对应地区域作卷积运算提取特征。低层卷积只能提取到低层特征,如边缘、线条等;高层卷积可以提取更深层的特征。
卷积层参数包括感受野大小、步长(Stride)和边界填充(Padding),三者共同决定了卷积层输出特征图的尺寸大小;感受野大小小于输入图片尺寸,感受野越大,可提取的特征越复杂;步长定义了感受野扫过相邻区域时的位置距离;边界填充是在特征图周围进行填充,避免输出特征丢失过多边缘信息的方法,Pad值代表填充层数。
2.2.2 激活函数层
卷积运算提取到的图像特征是线性的,但真正的样本往往是非线性的,为此引入了非线性函数来解决。激活函数使得每个像素点可以用0~1的任何数值代表,以模拟更为细微的变化。激活函数一般具有非线性、连续可微、单调性等特性、比较常用的激活函数有Sigmoid函数、Tanh函数以及ReLU函数。
2.2.3池化层
池化层的作用为压缩特征图、提取主要特征、简化网络计算的复杂度。池化方式一般有两种:均值池化与最大池化。池化操作将特征图缩小,有可能影响网络的准确度,但可以通过增加网络深度来弥补。
2.2.4 全连接层
全连接层位于卷积神经网络的最后,给出最后的分类结果。在全连接中,特征会失去空间结构,展开为特征向量,并把前面层级所提取到的特征进行非线性组合,得到输出,可以公式表示:
f(x)=W∗x+bf(x)=W * x+bf(x)=W∗x+b
其中,x为全连接层的输入,W为权重系数,b为偏置。全连接层连接所有特征输出至输出层,对于图像分类问题,输出层使用逻辑函数或归一化指数函数输出分类标签。在图像识别问题中,输出层输出为物体的中心坐标、大小和分类。在语义分割中,则直接输出每个像素的分类结果。
2.3 卷积神经网络的类型
2.3.1 AlexNet
AlexNet神经网络赢得了2012年ILSVRC(ImageNet大规模视觉识别挑战赛)的冠军,2012年是CNN首次实现Top5误差率15.4%的一年(Top5误差率是指给定一张图像,其标签不在模型认为最有可能的5个结果中的概率),第二名使用传统识别方法得到的误差率为26.2%。卷积神经网络在这次比赛的表现震惊了整个计算机视觉界,奠定了卷积神经网络在计算机视觉领域的绝对地位。
AlexNet包含了6亿3千万个连接、6000万个参数和65万个神经元,网络结构如下图所示:
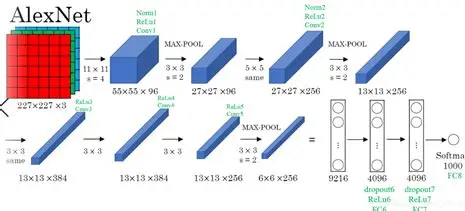
AlexNet的成功除了深层次的网络结构外,还有以下几点:首先,采用ReLU作为激活函数,避免了梯度散耗问题,提高了网络训练的速度;其次,通过平移、翻转等扩充训练集,避免了产生过拟合;最后提出并采用了LRN(Local Response Normalization,局部响应归一化处理),利用临近的数据做归一化处理技术,提高深度学习训练的准确度;除此之外,AlexNet使用GPU处理训练时所产生的大量矩阵运算,提升了网络的训练效率。
2.3.2 VGGNet
VGGNet是牛津大学与Google DeepMind公司的研究员一起合作开发的卷积神经网络,2014年取得了ILSVRC比赛分类项目的亚军和识别项目的冠军。VGGNet探索了网络深度与其性能的关系,通过构筑16~19层深的卷积神经网络,Top5误差率为7.5%,在整个卷积神经网络中,全部采用3x3的卷积核和2x2的池化核,网络结构如下图所示。
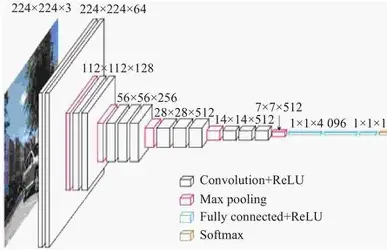
VGGNet包含很多级别的网看,深度从11层到19层不等,常用的是VGG-16和VGG-19.VGGNet把网络分成了5段,每段都把多个3x3的网络串联在一起,每段卷积后接一个最大池化层,最后是3个全连接层和一个SoftMax层。
VGGNet有两个创新点:
- 通过网络分段增加网络深度,采用多层小卷积代替一层大卷积,两个3x3的卷积核相当于5x5的感受野,3个相当于7x7的感受野。优势在于:首先包含3个ReLU层,增加了非线性操作,对特征的学习能力更强;其次减少了参数,使用3x3的3个卷积层需要27 x n个参数,使用7x7的一个卷积层需要7 x 7 x n=49 x n个参数
- 在训练过程中采用多尺度和交替训练的方式,同时对一些层进行预训练,使得VGGNet能够在较少的周期内收敛,减轻了神经网络训练时间过长的问题。不足之处在于使用3个全连接层,参数过多导致内存占用过大,耗费过多的计算资源。VGGNet是重要的神经网络,它强调了卷积网络深度的增加对于性能的提升有着重要的意义。
2.3.3 GoogLeNet
GoogLeNet是由谷歌的研究院提出的卷积神经网络,获得了2014年的ILSVRC比赛分类任务的冠军,Top5误差率仅为6.656%。GoogLeNet的网络共有22层,但参数仅有700万个,比之前的网络模型都少很多。一般来说,提升网络性能最直接的办法就是增加网络深度,随之增加的还有网络中的参数,但过量的参数容易产生过拟合,也会增大计算量。GoogLeNet采用稀疏连接解决这种问题,为此提出了Inception的结构,如下图所示。
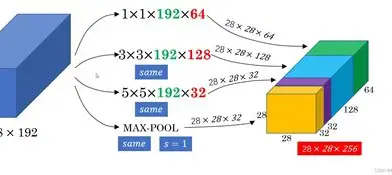
在Inception结构中,同时采用1x1、3x3、5x5卷积核是为了将卷积后的特征保持一致,以便于融合,stride=1,padding分为0、1、2,卷积后就可以得到相同维度的特征,最后进行拼接,将不同尺度的特征进行融合,使得网络可以更好地提取特征。
在整个网络中,越靠后提取到的特征也越抽象,每个特征对应的感受野也随之增大。因此,随着层数的增加,3x3、5x5的卷积核的比例也要随之增加,这样会带来巨大的参数计算,为此GoogLeNet有过诸多改进版本,GoogLeNet Inception V2、V3以及V4,通过增加Batch Normalization,在卷积之前采用1x1卷积降低维度、将n x n的卷积核替换为1xn和nx1等方法降低网络参数,提升网络性能。
2.3.4 ResNet
ResNet于2015年被提出,获得了ILSVRC的冠军,ResNet的网络结构有152层,但Top5误差率仅为3.57%,之前的网络都很少有超过25层的,这是因为随着神经网络深度的增加,模型的准确率会先上升,然后达到饱和,如果持续增加深度,准确率会下降。随着层数的增多,会出现梯度爆炸或衰减现象,梯度会随着连乘变得不稳定,数值会特别大或者特别小,因此网络性能会变得越来越差。ResNet通过在网络结构中引入残差网络来解决此类问题,残差网络结构如下图所示。
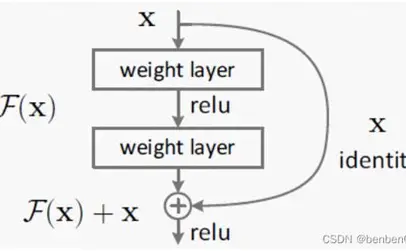
很明显,残差网络是跳跃结构,残差项原本是带权重的,但ResNet用恒等映射代替了它。输入为x,期望输出为H(x),通过捷径连接的方式将x传到输出作为初始结果,输出为H(x)=F(x)+x,当F(x)=0时,H(x)=x。于是,ResNet相当于将学习目标改变为目标值H(x)和x的差值。也就是所谓的残差F(x)=H(x)-x,因此,后面的训练目标就是将残差结果逼近于0。ResNet通过提出残差学习将残差网络作为卷积神经网络的基本结构,通过恒等映射来解决因网络模型层数过多导致的梯度爆炸或衰减问题,可以最大限度地加深网络,并得到非常好地分类结果。
3.几种常见的循环神经网络
循环神经网络(Recurrent Neural NetWork,RNN)又称递归神经网络,它是常规前馈神经网络(Feedforward Neural Network,FNN)的扩展。
3.1 循环神经网络
在传统的神经网络模型中,都是从输入层经过隐藏层,再到输出层,每一层之间的节点都是没有连接的,它们之间没有保存任何状态信息。与此相反,RNN遍历所有序列的元素,每个当前层的输出都与前面层的输出有关,也就是每个层之间的节点是连接的,会将前面层的状态信息保留下来。理论上,RNN应该可以处理任意长度的序列数据,但为了降低一定的复杂度,实践中通常只会选取与前面几个状态有关的信息。首先简单地介绍RNN的原理,如下图所示。

图中的神经网络由一个神经元组成,x是输入,h是输出,中间有一个箭头表示数据循环更新的是隐藏层,这个就是它实现时间记忆功能的方法。神经网络输入x并产生输出h,最后将输出的结果反馈回去。假设在一个时间t内,神经网络的输入除了来自输入层的x(t)外,还有上一时刻的输出y(t-1),两者共同输入产生当前层的输出y(t)。我们还可以将这个神经网络按照时间序列形式展开。
每个神经元的输出都是根据当前的输入x(t)和上一时刻的输出y(t-1)共同决定的。它们所对应的权重是WxW_xWx和WyW_yWy,那么,单个神经元的输出计算如下:
yt=Ψ(xtT.Wx+yt−1T.Wy+b)y_t=\Psi(x_t^T.W_x+y_{t-1}^T.W_y+b)yt=Ψ(xtT.Wx+yt−1T.Wy+b)
如果将中间的隐藏层展开,就会得到上图所示的结果。
通常,一个RNN单元在时间t的状态记作hth_tht。U表示此刻输入的权重,W表示前一次输出的权重,V表示此刻输出的权重。在t=1时刻,一般h0h_0h0表示初始状态为0,随机初始化U、W和V的值,使用下面的公式计算:
h1=f(Ux1+Wh0+bh)h_1=f(Ux_1+Wh_0+b_h)h1=f(Ux1+Wh0+bh)
O1=g(Vh1+b0)O_1=g(Vh_1+b_0)O1=g(Vh1+b0)
其中,f和g均为激活函数,即那些光滑的曲线函数(非线性函数),f可以是Sigmoid、ReLU、Tanh等激活函数,g通常是Softmax损失函数,bhb_hbh是隐藏层的偏置项,b0b_0b0是输出层的偏置项。前向传播算法在这里就是按照时间t向前推进的,此时的隐藏状态h1h_1h1是参与到下一个时间的预测过程的,即:
h2=f(Ux2+Wh1+bh)h_2=f(Ux_2+Wh_1+b_h)h2=f(Ux2+Wh1+bh)
O2=g(Vh2+b0)O_2=g(Vh_2+b_0)O2=g(Vh2+b0)
基于上述公式,以此类推,可得到最终的输出公式为:
ht=f(Uxt+Wht−1+bh)h_t=f(Ux_t+Wh_{t-1}+b_h)ht=f(Uxt+Wht−1+bh)
Ot=g(Vht+b0)O_t=g(Vh_t+b_0)Ot=g(Vht+b0)
权重共享可以减少运算,使得模型泛化,可以处理连续序列数据的特征,而且不限定序列的长度,仍然能够识别出连续序列在样本中的位置,但不是学习每个位置的规则。这样它不仅能够抓住不同特征之间的连续性,还能减少学习规则。因此,基于权重共享的思想,这里出现的W、U、V以及偏置项都是相等的。前面介绍了关于RNN网络通常过于简化,仍然存在着一些问题,比如在理论上它应该能够记住更多之前的信息,并可以处理任意长度的序列数据,但实际上却不能形成这种长期记忆,这就是梯度消失问题的一种。梯度消失问题主要是由BP算法和长时间依赖两种原因造成的,而RNN中产生的梯度爆炸问题属于后者,由于时间过长而造成记忆值较小的现象。梯度消失问题主要发生在前馈神经网络(也就是非循环网络)中,随着网络层数的增加,网络最终会变得无法训练。
如果从导数角度来讲,梯度消失就是对激活函数求导,若导数值小于1,则随着网络层数的增多,最终的梯度更新将以指数形式衰减。然而也存在一些反例,比如对激活函数求导,如果导数值大于1,那么随着层数的增大,最终求出的梯度更新将以指数形式增大,导致网络不稳定,使得算法无法收敛。这就是RNN存在的另一问题------梯度爆炸。对于这些存在的问题,研究者提出了很多改进的算法,常见的主要有两种:LSTM和GRU
3.2 长短期记忆网络
为了解决梯度消失等问题,Hochreiter等人提出了新的RNN架构------长短期记忆(Long Short-Term Memory,LSTM)算法,之后Alex Graves、HasIMSak和Wojciech Zaremba等人逐步改进了该模型。一个基本的LSTM单元结构如下图所示:
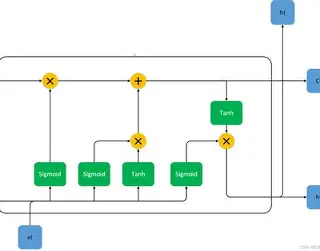
上图中间有4个矩形是普通神经网络的隐藏层结构。其中,第一、三和四个激活函数都是Logistic函数,第二个激活函数是Tanh函数。LSTM单元状态分为长时记忆和短时记忆,其中短时记忆用向量h(t)h(t)h(t)表示,长时记忆用c(t)c(t)c(t)表示。LSTM单元结构中还有3个门限控制器;忘记门限、输入门限和输出门限,忘记门限主要用f(t)f(t)f(t)控制着那些长时记忆应该被丢弃或者被遗忘,因此也被称为遗忘门。
输入门限主要是由i(t)i(t)i(t)和g(t)g(t)g(t)两部分组成,其中i(t)i(t)i(t)用来控制g(t)g(t)g(t)那些可以用来增加记忆部分。输出门限主要是由o(t)o(t)o(t)来控制那些长时记忆应该在该时刻被读取和输出的部分。3个门限控制器都使用了可以输出0~1范围的Logistic函数,如果输出的值是1,则表示门限打开,反之表示门限关闭。此外,主要g(t)g(t)g(t)的主要作用是分析当前输入x(t)x(t)x(t)和前一个时期状态h(t−1)h(t-1)h(t−1)。
LSTM单元的基本流程为:随着短时记忆c(t−1)c(t-1)c(t−1)从左到右横穿整个网络,它首先经过一个遗忘门,丢弃一些记忆,然后通过输入门限来选择增加一些新记忆,最后直接输出c(t)c(t)c(t)。此外,在增加记忆这部分操作中,长时记忆是先经过Tanh函数,然后被输出门限过滤,产生短时记忆h(t)h(t)h(t)。总之,LSTM可以识别重要的输入(输入门限的作用),并将这些信息在长时记忆中存储下来,通过遗忘门保留需要的部分,以及在需要的时候能够提取它。这也是它能够非常方便地处理各种时间序列数据(如文字、语音等)的原因。
以下公式总结了上述关于LSTM单元结构中的3个门限控制器、两种状态以及输出:
i(t)=σ(wxiT.x(t)+whiT.h(t−1)+bi)i_{(t)}=\sigma(w_{xi}^T.x(t)+w_{hi}^T.h(t-1)+b_i)i(t)=σ(wxiT.x(t)+whiT.h(t−1)+bi)
f(t)=σ(wxfT.x(t)+whfT.h(t−1)+bf)f_{(t)}=\sigma(w_{xf}^T.x(t)+w_{hf}^T.h(t-1)+b_f)f(t)=σ(wxfT.x(t)+whfT.h(t−1)+bf)
o(t)=σ(wxoT.x(t)+whoT.h(t−1)+bo)o_{(t)}=\sigma(w_{xo}^T.x(t)+w_{ho}^T.h(t-1)+b_o)o(t)=σ(wxoT.x(t)+whoT.h(t−1)+bo)
g(t)=tanh(wxgT.x(t)+whgT.h(t−1)+bg)g_{(t)}=\tanh(w_{xg}^T.x(t)+w_{hg}^T.h(t-1)+b_g)g(t)=tanh(wxgT.x(t)+whgT.h(t−1)+bg)
c(t)=f(t)⊗c(t−1)+i(t)⊗g(t)c_{(t)}=f_{(t)} \otimes c_{(t-1)}+i_{(t)} \otimes g_{(t)}c(t)=f(t)⊗c(t−1)+i(t)⊗g(t)
y(t)=h(t)=o(t)⊗tanh(c(t))y_{(t)}=h_{(t)}=o_{(t)} \otimes tanh(c_{(t)})y(t)=h(t)=o(t)⊗tanh(c(t))
3.3 门控循环单元
Kyunghyun Cho等人在LSTM单元结构的基础上提出了一种新的变体,它的工作原理和LSTM相同。这种结构被称为门循环单元(Gated Recurrent Unit,GRU)。GRU较LSTM单元的结构更加简单,而且效果也很好,是当前非常流行的一种网络结构。GRU可以解决RNN网络中的长依赖问题和反向传播中的梯度问题,具体的循环结构如下图所示。
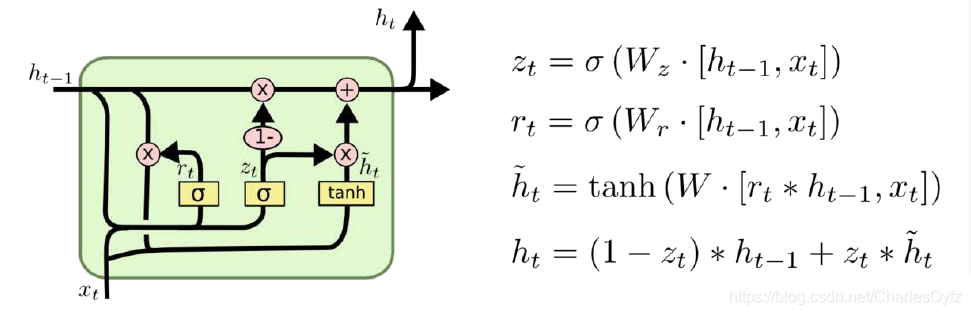
在图中,激活函数由LSTM中的4个变成了3个,两个状态向量合并成了一个h(t)h(t)h(t)。LSTM单元结构中存在3个门限控制器:输入门限、忘记门限和输出门限,这3个门函数分别控制着输入值、记忆值和输出值。但在GRU单元结构中没有输出门限,只有两个门:重置门和更新门。重置门由r(t)r(t)r(t)负责,用于控制前一时刻的状态信息有哪些部分是可以显示给主层。重置门的值越小,写入的状态信息越少。更新门由z(t)z(t)z(t)负责,用于控制前一时刻的状态信息被带入当前状态的程度。更新门的值越大,带入的前一时刻的状态信息就越多。
GRU单元的基本流程为:首先,通过前一刻时刻传输下来的隐藏状态h(t−1)h(t-1)h(t−1)和当前时刻的输入x(t)x(t)x(t)来获取两个门控状态,即重置门r(t)r(t)r(t)和更新门z(t)z(t)z(t)。这两个门函数都使用Logistic或Sigmoid函数,通过这个函数可以得到0~1范围的输出值,主要用来充当门控信号。
得到门控信号之后,先使用r(t)r(t)r(t)得到"重置"后的数据,再将其与输入向量x(t)x(t)x(t)进行拼接,通过一个Tanh函数将数据缩放到-1,1的范围。最关键的是"更新记忆"阶段,这个阶段主要进行遗忘和记忆,相当于LSTM中的忘记门限和输入门限。我们使用先前得到的更新门控z(t)z(t)z(t),这里的门控信号越接近1,表示记忆下来的数据就越多,反之则表示遗忘的越多。从图中可以看出,之后经过处理,将遗忘z(t)z(t)z(t)和选择1−z(t)1-z(t)1−z(t)联动,对于传递进来的维度信息,会选择性遗忘,则遗忘了多少权重再通过1−z(t)1-z(t)1−z(t)进行弥补,以此来保持一种"恒定"的状态。下面展示GRU单元结构的计算过程:
z(t)=σ(wxzT.x(t)+whzT.h(t−1))z_{(t)}=\sigma(w_{xz}^T.x(t)+w_{hz}^T.h(t-1))z(t)=σ(wxzT.x(t)+whzT.h(t−1))
r(t)=σ(wxrT.x(t)+whrT.h(t−1))r_{(t)}=\sigma(w_{xr}^T.x(t)+w_{hr}^T.h(t-1))r(t)=σ(wxrT.x(t)+whrT.h(t−1))
g(t)=tanh(wgrT.x(t)+whgT.(r(t)⊗h(t−1)))g_{(t)}=tanh(w_{gr}^T.x(t)+w_{hg}^T.(r_{(t)} \otimes h_{(t-1)}))g(t)=tanh(wgrT.x(t)+whgT.(r(t)⊗h(t−1)))
h(t)=(1−z(t)⊗tanh(wxgT.h(t−1))+z(t)⊗g(t))h_{(t)}=(1-z_{(t)} \otimes tanh(w_{xg}^T .h_{(t-1)})+z_{(t)} \otimes g_{(t)})h(t)=(1−z(t)⊗tanh(wxgT.h(t−1))+z(t)⊗g(t))
其中,wxzw_{xz}wxz、wxrw_{xr}wxr和wxgw_{xg}wxg是每一层连接到输入x(t)x(t)x(t)的权重,whzw_{hz}whz、whrw_{hr}whr和whgw_{hg}whg是每一层连接到前一个短时记忆h(t-1)的权重。
4.股票成交量趋势预测(示例)
python
##导入相关第三方库
import torch
import torch.nn as nn
import numpy as np
import tushare as ts
from tqdm import tqdm
import matplotlib.pyplot as plt
from copy import deepcopy as copy
from torch.utils.data import DataLoader,TensorDataset
##获取数据,这里通过tushare库获取股票数据。这里使用了开盘价、收盘价,最高价、最低价、成交量这5个特征,使用每天的收盘价作为学习目标,每个样本都包含连续几天的数据作为一个序列样本,处理出训练集和测试集
class GetData:
def __init__(self,stock_id,save_path):
self.stock_id = stock_id
self.save_path = save_path
self.data=None
def getData(self):
self.data = ts.get_hist_data(self.stock_id).iloc[::-1]
self.data = self.data[["open","high","low","volume"]]
self.close_min = self.data['volume'].min()
self.close_max = self.data['volume'].max()
self.data = self.data.apply(lambda x:(x - min(x) / max(x) - min(x) ))
self.data.to_csv(self.save_path)
return self.data
def process_data(self,n):
if self.data is None:
self.getData()
feature = [
self.data.iloc[i:i+n].values.tolist()
for i in range(len(self.data) - n +2)
if i + n < len(self.data)
]
label = [
self.data.close.value [i+n]
for i in range(len(self.data) - n +2)
if i + n < len(self.data)
]
train_x = feature[:500]
test_x = feature[500:]
train_y = feature[:500]
test_y = feature[500:]
return train_x, test_x, train_y, test_y
##搭建LSTM模型,使用一个单层单向LSTM网络,加一个全连接层输出,
class Model(nn.Module):
def __init__(self,n):
super(Module, self),__init__()
slef.lstm_layer = nn.LSTM(input_size=n, hidden_size=256, batch_first = True)
self.linear_layer = nn.Linear(in_feature=256, out_features=1, bias=True)
def forward(self, x):
out1, (h_n, h_c) = self.lstm.layer(x)
a, b, c = h_n.shape
out2 = self.lineat_layer(h_n.reshape(a*b,c) )
return out2
## 训练模型,计算损失loss、损失backwar、优化器step
def train_model(epoch, train_dataLoader, test_dataLoader):
best_model = None
train_loss = 0
test_loss = 0
best_loss = 100
epoch_cnt = 0
for _ in range(epoch):
total_train_loss = 0
total_train_num = 0
total_test_loss = 0
total_test_num = 0
for x,y in tqdm(train_dataLoader, desc='Epoch:{}| Train Loss:{}| Test Loss:{}'.format(-, train_loss, test_loss )):
x_num = len(x)
p = model(x)
#print(len(p[0]))
loss = loss_func(p, y)
optimizer.zero_grad()
loss.backward()
optimizer.step()
total_train_loss += loss.item()
total_train_num += x_num
train_loss = total_train_loss / total_train_num
for x,y in test_dataLoader:
x_num = len(x)
p = model(x)
loss = loss_func(p,y)
optimizer.zero_grad()
loss.backward()
optimizer.step()
total_test_loss += loss.item()
total_test_num += x_num
test_loss = total_test_loss / total_test_num
if best_loss > test_loss:
best_loss = test_loss
best_model = copy(model)
epoch_cnt = 0
else:
epoch_cnt += 1
if epoch_cnt > early_stop:
torch.save(best_model.state_dict(),'./lstm_.pth')
break
##测试模型,使用测试集对模型进行测试
def test_model(test_dataLoader_):
pred = []
label = []
model_ = Model(5)
model_.load_state_dict(torch.load("./lstm.pth" ))
model_.eval()
total_test_loss = 0
total_test_num = 0
for x,y in test_dataLoader_:
x_num = len(x)
p = model_(x)
loss = loss_func(p,y)
total_test_loss += loss.item()
total_test_num += x_num
pred.extend(p.data.squeeze(1).tolist())
label.extend(y.tolist())
test_loss = total_test_loss / total_test_num
return pred, label, test_loss
## 绘制折线图,绘制股票日交易量的折线图,并输出模型测试集的损失
def plot_img(data, pred):
plt.rcParams['font.sans-serif ' ] = ['SimHei']
plt.figure(figsize=(12,7))
plt.plot(range(len(pred)), pred, color='green')
plt.plot(range(len(data)), data, color='blue')
for i in range(0, len(pred)-3 , 5):
price = [data[i]+pred[j]-pred[i] for j in range(i, i+3)]
plt.plot(range(i,i+3),price,color='red')
plt.xticks(fontproperties= 'Times New Roman', size=15)
plt.yticks(fontproperties= 'Times New Roman', size=15)
plt.xlabel('日期', fontsize = 18)
plt.ylabel('成交量', fontsize = 18)
plt.show()
if __name__ == '__main__':
#超参数
days_num = 5
epoch = 20
fea = 5
batch_size = 20
early_stop = 5
# 初始化模型
model = Model(fea)
#数据处理
GD = GetData(stock_id='601398',save_path='./data.csv')
x_train, x_test ,y_train, y_test = GD.process_data(days_num)
x_train = torch.tensor(x_train).float()
x_test = torch.tensor(x_test).float()
y_train = torch.tensor(y_train ).float()
y_test = torch.tensor(y_test).float()
train_data = TensorDataset(x_train, y_train)
train_dataLoader = DataLoader(train_data, batch_size = batch_size)
test_data = TensorDataset(x_test, y_test)
test_dataLoader = DataLoader(test_data, batch_size = batch_size)
#损失函数、优化器
loss_func = nn.MSELoss()
optimizer = optim.Adam(model.parameters(), lr=0.001)
train_model(epoch, train_dataLoader, test_dataLoader)
p,y, test_loss = test_model(test_dataLoader)
#绘制折线图
pred = [ele * (GD.close_max - GD.close_min) + GD.close_min for ele in p]
data = [ele * (GD.close_max - GD.close_min) + GD.close_min for ele in y]
plot_img(data,pred)
#输出模型损失
print('模型损失:' , test_loss)