一句话总结
LLM 挂载多个 LoRA 时面临严重的显存开销问题,导致吞吐量低下。如果仅在 prefill 阶段使用 adapter,可实现质量几乎不降的前提下推理速度翻倍
- 论文标题: PreFT: Prefill-only Finetuning for Inference Efficiency
- 论文地址: https://arxiv.org/pdf/2605.14217v1
- 作者背景: 斯坦福大学,Tilde Research
- 代码地址: github.com/stanfordnlp/preft (目前还是空仓库)
一、动机
AI 应用日趋多样化,越来越多的业务需要对不同场景、不同用户提供个性化的 LLM 推理服务。最轻量的个性化手段是为每个场景配置不同的系统提示词,但这一方案存在明显天花板:定制深度有限(无法让模型真正 "学会" 某种风格或偏好)、长提示词本身带来额外的 prefill 计算开销、且无法编码复杂的领域知识
当个性化需求超出提示词的能力边界时,LoRA adapter 成为自然选择。单个 adapter 仅几十 MB,训练成本低,使得 "一个基础模型 + N 个 adapter" 的架构在以下场景中成为标配:
- 多租户 SaaS 平台:每个企业客户用自有数据微调一个 adapter,平台需要同时服务数百个客户的请求。比如客服系统为不同品牌训练话术风格 adapter
- 终端用户个性化:写作助手学习用户的文风偏好、教育产品为不同学生定制解题风格
- 领域专家混合:将不同能力(医疗、法律、金融等)分别训练为独立 adapter,推理时根据请求路由到对应 adapter,实现模块化能力组合
这些场景的共同特征是:推理引擎需要在同一时刻为 batch 内的不同请求加载不同的 adapter 权重。LoRA 解决了训练端的效率问题,但服务端的吞吐瓶颈一直缺乏根本性方案
这里的核心矛盾在于:多 adapter 服务中每个请求对应不同的 adapter 权重,标准 GEMM(矩阵乘加算子)无法直接适用
尽管业界对此已经有了一些加速方案,专门解决异构 batch 推理的 Punica kernel、通过内存分页将不活跃 adapter 卸载到 CPU 的S-LoRA,但即使组合使用这些优化,多 adapter 服务的吞吐仍显著低于无 adapter 基线
根因在于 LLM 推理时,prefill 与 decode 两个阶段的性质差异:
- prefill 并行处理整个 prompt,属于 compute-bound,GPU 算力被充分利用;
- decode 逐 token 生成,属于 memory-bound,瓶颈在于从显存搬运权重和 KV cache
LoRA 的 down projection 在半精度下算术强度远低于 H100 的计算/带宽比(295),本质上是 memory-bound 操作。在已经受限于内存带宽的 decode 阶段叠加这些操作,吞吐下降非常显著。Punica 和 S-LoRA 只是分摊了这一开销,并未消除
二、解决思路
对此作者提出了 PreFT,其想法极其简洁:既然加载 adapter 代价高昂,那就干脆只在 prefill 阶段应用 adapter 处理 prompt,完成后直接丢弃,decode 阶段回归裸模型
为什么能 work? Adapter 在 prefill 阶段对 prompt token 的表示做了修改,这些修改写入 KV cache。后续 decode 阶段的每个 token 通过 attention 读取 KV cache,adapter 的效果间接传递到生成的每个 token
三、实验结果
3.1 总览
论文从两个维度验证 PreFT:推理效率和任务质量。下图是整体效果总览,将所有实验的吞吐-准确率 tradeoff 画在同一张散点图上
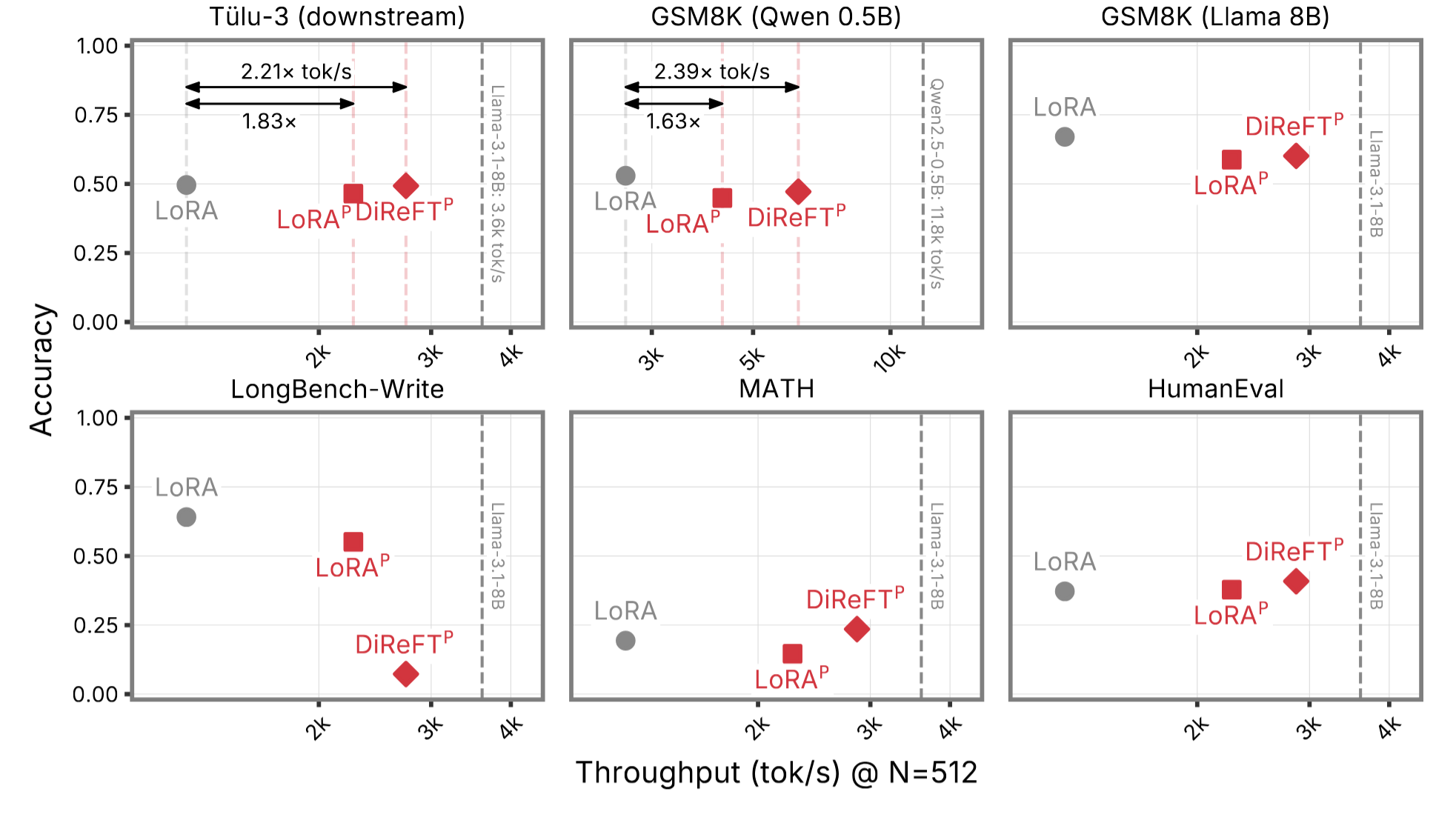
可见 PreFT 方法在吞吐量上具有显著优势,而准确率与标准 PEFT 基本重合
3.2 吞吐量测试
- 测试基准:复用 Punica 微基准,向推理引擎提交 1000 个请求,按 FIFO 调度,随机采样各请求的 prompt 和 output 长度,模拟真实在线服务的混合负载
- 对比方法 :
- rank-1 LoRA(全位置):标准多 LoRA 服务基线,prefill 和 decode 阶段均应用 adapter,使用 vLLM 内置的 Punica Triton kernel 加速异构 batch 矩阵乘
- rank-1 LoRA^P(prefill-only):仅在 prefill 阶段应用 LoRA,decode 阶段将 LoRA ID 置零回归裸模型;同时也使用 Punica kernel
- rank-8 DiReFT^P(prefill-only):仅在 prefill 阶段对 residual stream 施加低秩偏移,decode 阶段不执行任何 adapter 操作;不使用任何自定义 CUDA kernel
- rank-8 DiReFT^A(全位置):prefill 和 decode 阶段均施加 DiReFT 偏移,作为 DiReFT 的全位置对照;无自定义 kernel
- 硬件:单卡 H100 80GB / 4×H100 张量并行
- adapter 数量:从 1 扩展到 512
- 请求分布模式 :
- Identical:所有请求指向同一个 adapter(最简单场景,开销仅来自在显存中的多个 adapter)
- Uniform:每个请求从所有 adapter 中均匀随机选取(最能体现异构 batch 的计算开销)
- Distinct:batch 内每个请求都指向不同的 adapter(极端异构场景)
- Skewed:adapter 按 Zipf 分布采样(模拟真实场景中少数热门 adapter 被高频访问的长尾分布)
在 Qwen2.5-0.5B 和 Llama-3.1-8B 上,随 adapter 数量从 1 增加到 32 时各方法的吞吐变化。灰色虚线为无 adapter 基线:
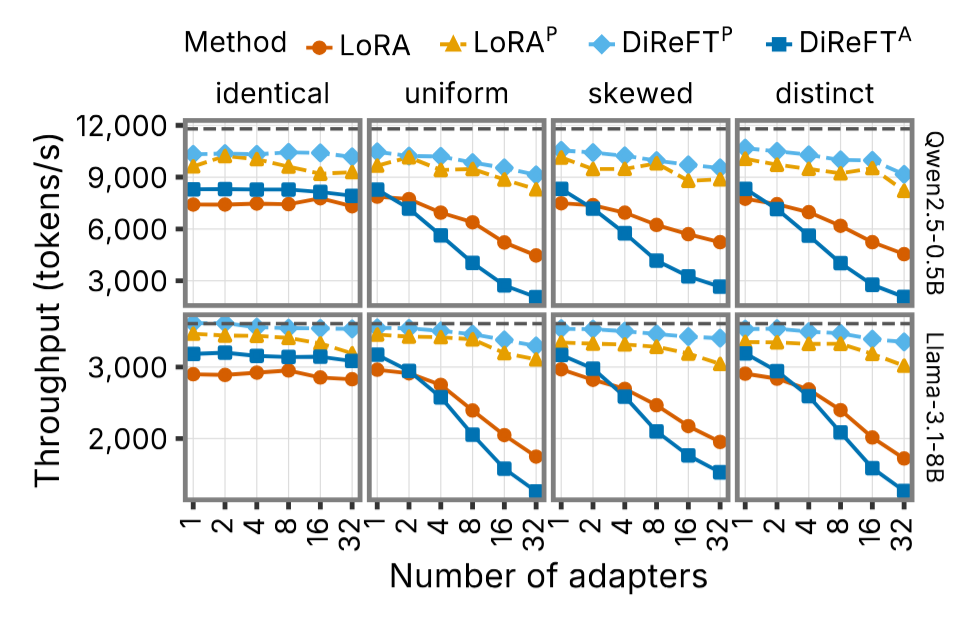
- DiReFT^P 在所有 workload 下几乎保持基线吞吐
- 标准 LoRA 随 adapter 数增加吞吐显著下降
- DiReFT^P 在吞吐量上略优于 LoRA^P
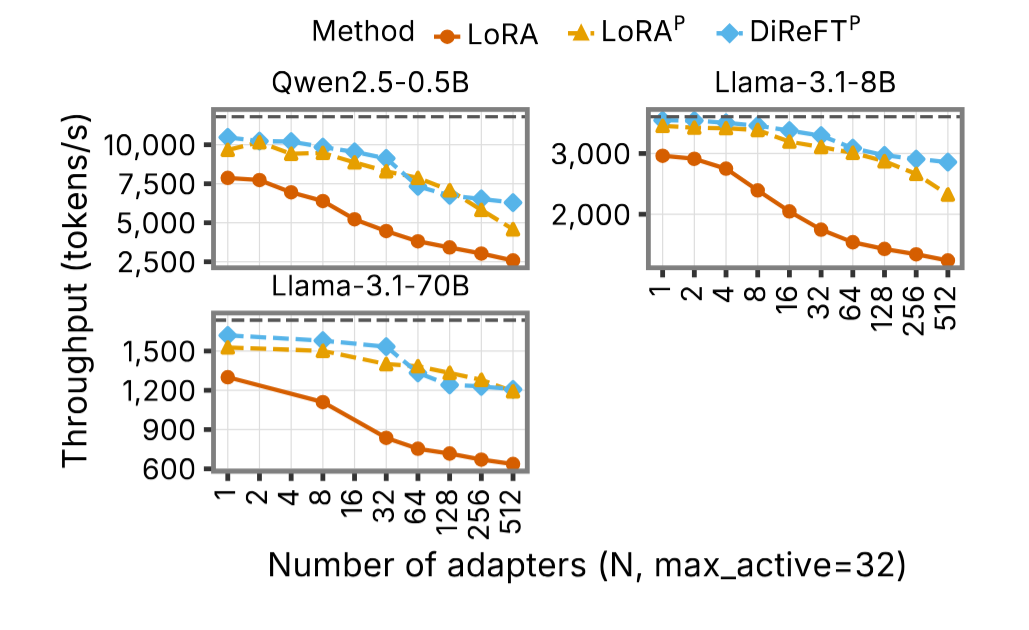
将 adapter 数量扩展到 512(GPU 上最多保留 32 个,其余分页到 CPU),在 Uniform 模式下测试
3.3 SFT 训练效果
- 模型:Llama-3.2-1B Instruct、Llama-3.1-8B Instruct
- 数据集:Tülu-3、OpenThoughts
- 评估指标:验证集 loss(取每个 rank 下最优学习率)
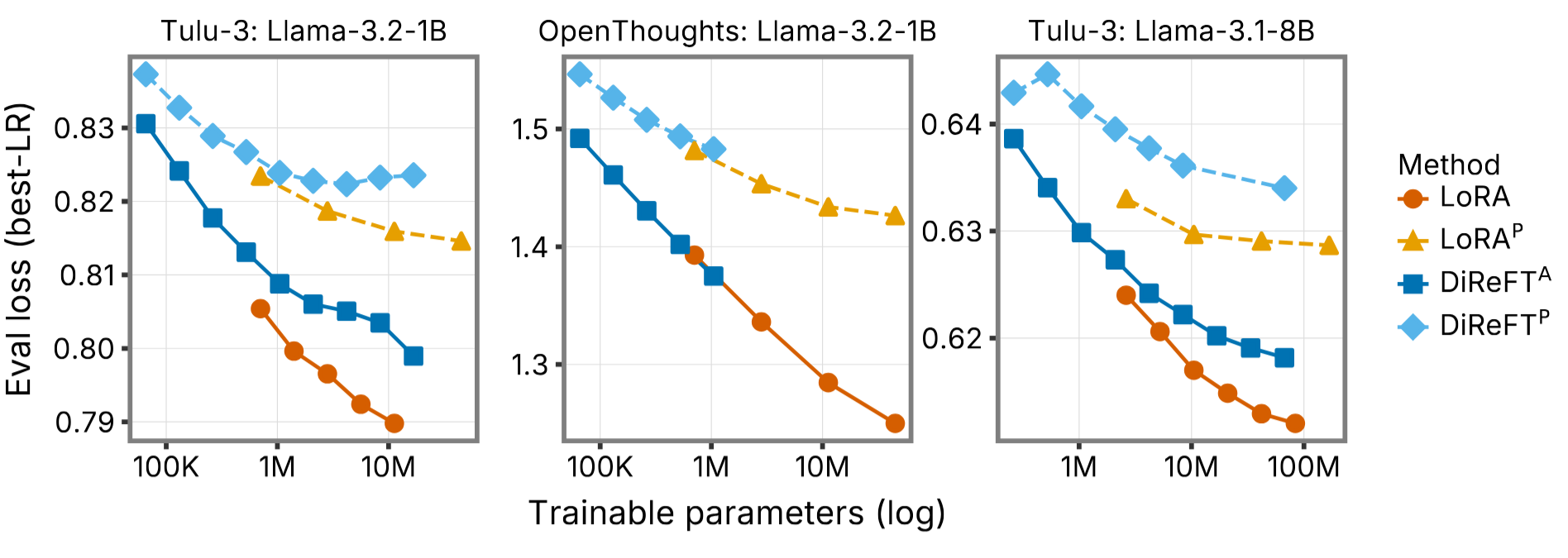
- PreFT 的 eval loss 的确较大,在参数量匹配的条件下,LoRA^P 和 DiReFT^P 的 loss 曲线始终在对应全位置方法之上
- 但 loss 随 rank 增大而稳定下降,且 rank 增大对推理吞吐几乎无影响(因为 adapter 操作只在 compute-bound 的 prefill 阶段执行)
这意味着在实际部署中,可以通过适度增大 rank 来弥补 prefill-only 带来的 loss 差距,而不牺牲吞吐
3.4 SFT 下游任务准确率
由于 Instruct 模型在 Tülu-3 微调后下游性能变化不大(起点已经很高),论文改用 base 模型(Llama-3.2-1B Base、Llama-3.1-8B Base)做 SFT,以更清晰地观察 adapter 带来的增益差异
- 评估任务:IFEval(指令遵循)、MMLU(知识问答)、GSM8K(数学推理)
- 对比方式:取 eval loss 最优的学习率配置
- 统计检验:Cochran-Mantel-Haenszel 检验 + Wilcoxon 符号秩检验
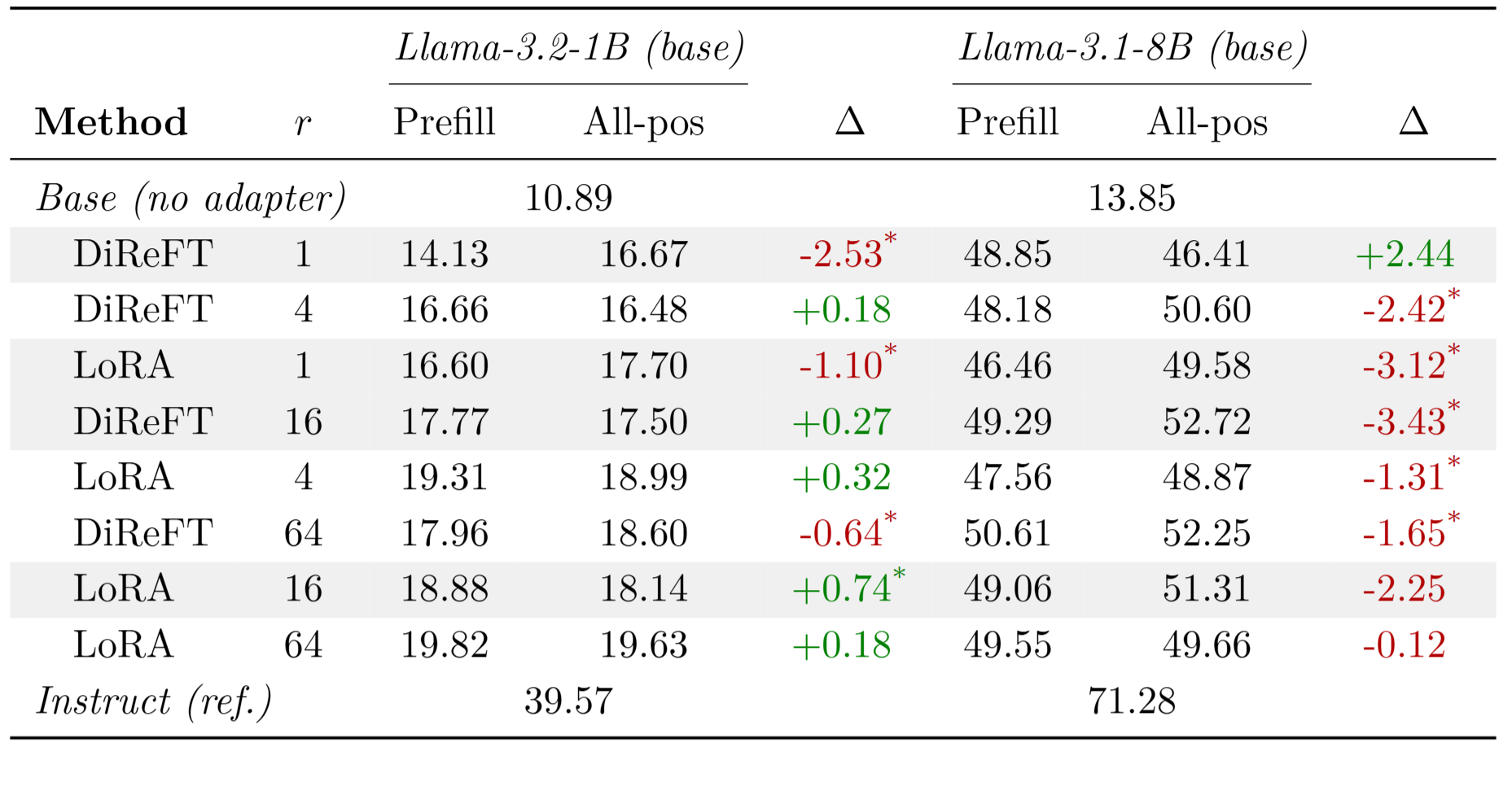
(表中数值为 IFEval + MMLU + GSM8K 的平均准确率,* 表示 CMH 检验显著)
核心结论:尽管 eval loss 存在差距,Wilcoxon 符号秩检验在所有配对比较上未发现统计显著差异,意味着 Eval loss 的差异并不转化为下游任务准确率的实质下降
3.5 RLVR 效果
- 算法:GRPO,K=4 采样,无 KL 惩罚
- 模型:Llama-3.1-8B Base、Qwen2.5-0.5B Base
- 训练集:GSM8K train、MATH train、MBPP train
- 评估集:GSM8K test、MATH test、HumanEval
- 奖励函数:二值准确率奖励(正确=1,错误=0),无格式奖励或长度 shaping
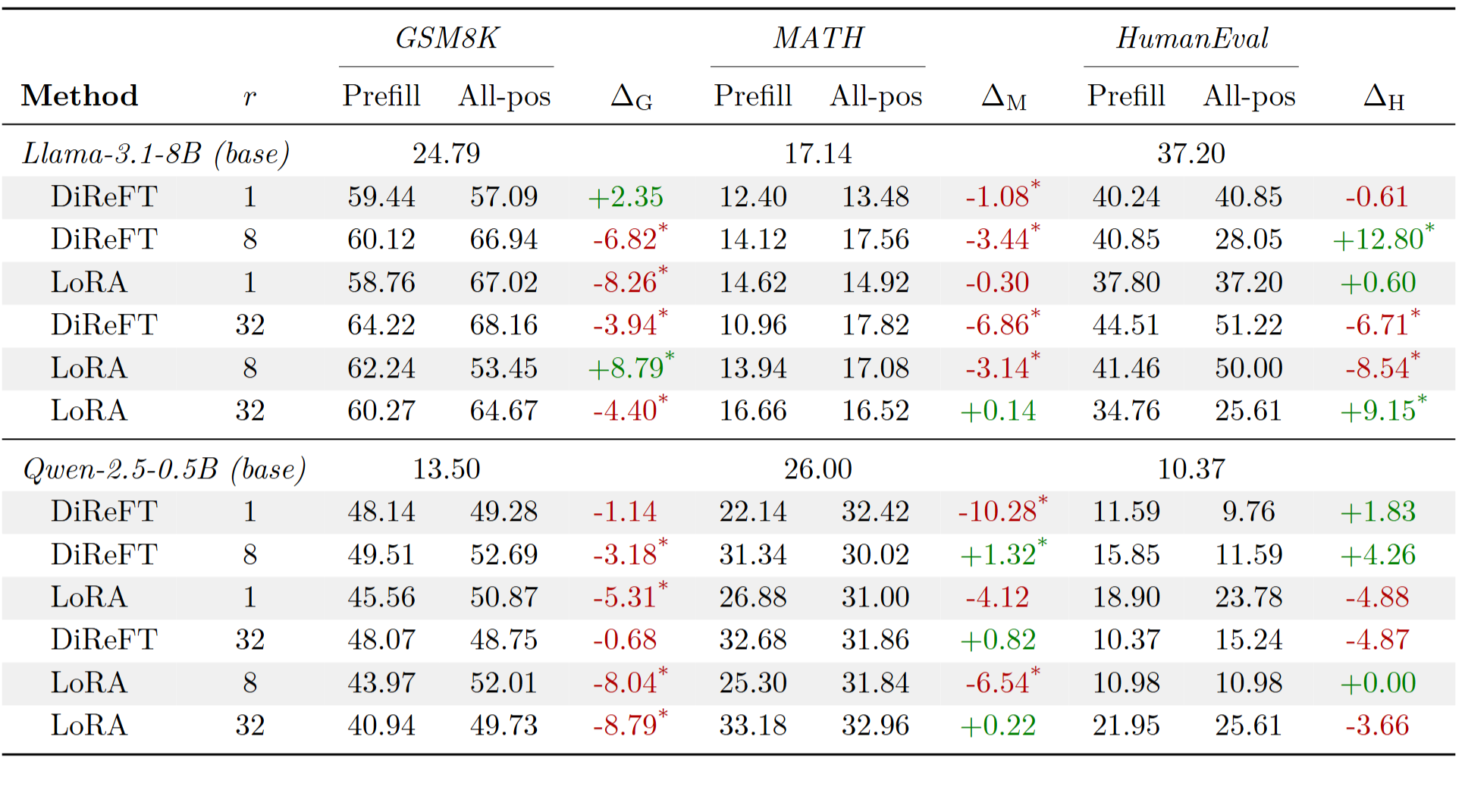
PreFTs 在 MATH 和 HumanEval 任务上接近 PEFT 性能,但在 GSM8K 任务上表现落后。这表明 GSM8K 可能对 adapter 在 decode 阶段的持续干预有更强的依赖性
3.6 长文本生成
- 模型:Llama-3.1-8B Instruct
- 数据集:LongWriter(训练),LongBench-Write(评估)
- 训练方式:SFT,rank=16,序列长度 32,768 token
- 评估指标 :
- S_l(length-following score):生成长度是否匹配目标长度
- S_q(quality score):生成文本质量
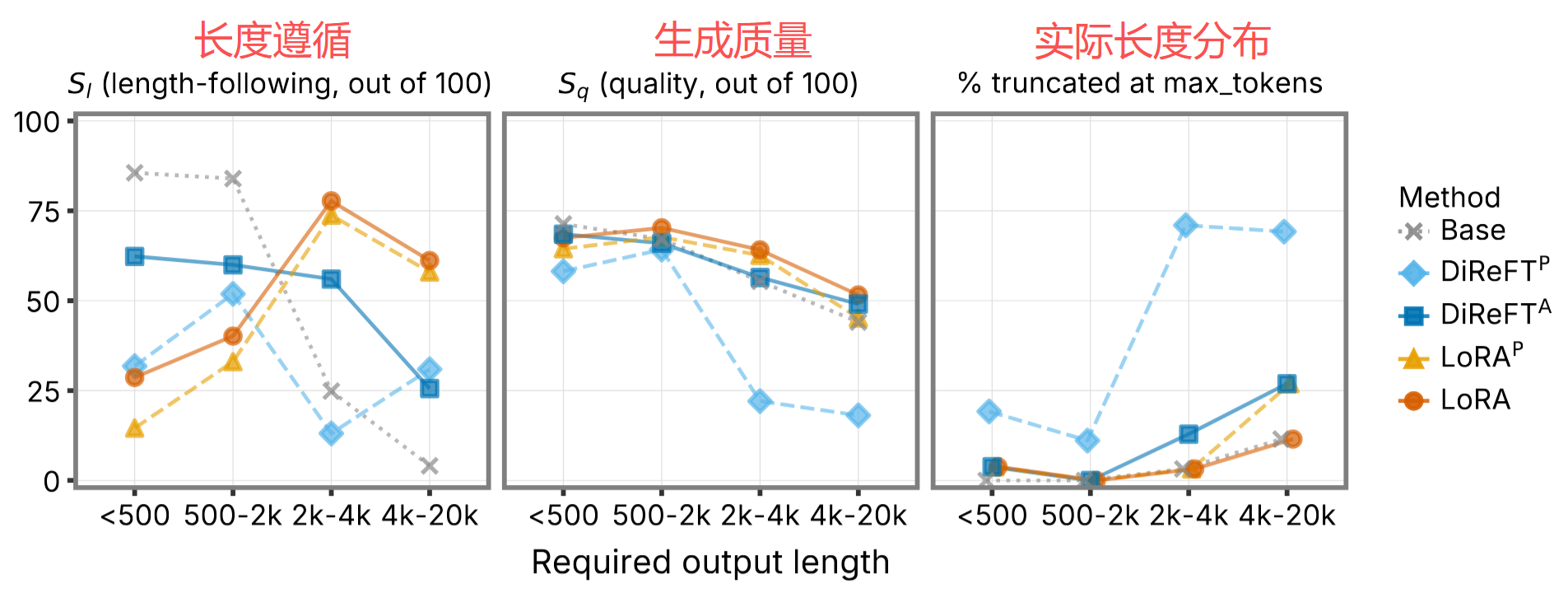
LoRA^P 完全保持了标准 LoRA 的行为:
- 在所有长度 bracket 上,LoRA^P 与 LoRA 的 S_l 和 S_q 曲线几乎完全重合
- 即使在 20k token 的长输出上也没有衰减迹象
DiReFT^P 出现长度控制崩溃:
- 在 ≥2k token 的请求上,DiReFT^P 几乎无条件写满 32k token 的解码上限
- S_q 在长 bracket 上甚至低于无 adapter 的 Base 模型
两者的差异根源在于信息持久化路径:
- LoRA^P:adapter 效果被直接写入 KV cache,Decode 阶段每个新 token 通过 attention 读取这些向量,adapter 信息持久传递,几乎无衰减
- DiReFT^P:只修改 residual stream(层间隐状态),不直接改变写入 KV cache 的内容,对 KV cache 的影响微弱,并且随生成长度逐渐衰减,最终模型退化为裸模型
部署建议:优先使用 LoRAP。它在所有场景下都表现稳定,尤其在长文本生成上不存在衰减问题。如果场景确定只涉及短输出(如分类、短回答),DiReFTP 也是可行选择,且吞吐略高