目录
逻辑回归概述
逻辑回归的作用
逻辑回归又称Logistic回归分析,是一种广义的线性回归分析模型,常用于数据挖掘、
疾病自动诊断、经济预测等领域。逻辑回归从本质来说属于二分类问题。
二分类问题是指预测的y值只有两个取值(0或1)。例如:一个垃圾邮件过滤系统,x是
邮件的特征,预测的y值就是邮件的类别(是垃圾邮件还是正常邮件)。
逻辑回归的假设函数
逻辑回归是将样本的特征和样本分类的概率联系起来
先来看Sigmoid函数:
g(z)=11+e−z
Sigmoid函数图像为:
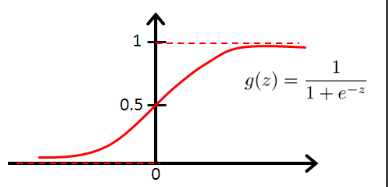
逻辑回归的假设函数是:
hθ(x)=11+e−θTx
假设函数的理解:
- θ^T^x其实就是线性模型
- 将线性模型的结果交给sigmoid函数处理,即为逻辑回归的假设函数
- 该假设函数预测的是分类y=1的发生概率的大小
实战------逻辑回归解决二分类问题

在sklearn中,实现逻辑回归使用的是sklearn.linear_model.LogisticRegression
python
import numpy as np
import matplotlib.pyplot as plt
from sklearn.model_selection import train_test_split
# 自己编造一些数据
np.random.seed(666)
X = np.random.normal(0, 1, size=(200, 2)) # 样本特征
y = np.array((X[:,0]**2+X[:,1])<1.5, dtype='int') # 样本标签
for _ in range(20):
y[np.random.randint(200)] = 1 # 随机改变样本标签值
# 散点图观察
plt.scatter(X[y==0,0], X[y==0,1])
plt.scatter(X[y==1,0], X[y==1,1])
plt.show()
# 数据集拆分
X_train,X_test,y_train,y_test = train_test_split(X,y,random_state=666)
# 使用逻辑回归进行二分类
from sklearn.linear_model import LogisticRegression
log = LogisticRegression() # 逻辑回归算法对象
log.fit(X_train,y_train) # 通过训练样本集拟合(学习)
print(log.score(X_test,y_test)) # 在测试集上评估模型实战------对逻辑回归调整概率阈值

在sklearn中LogisticRegression的默认概率阈值是0.5,可是有时候我们会根据实际需要
调整这个概率阈值
python
import numpy as np
import matplotlib.pyplot as plt
from sklearn.model_selection import train_test_split
# 自己编造一些数据
np.random.seed(666)
X = np.random.normal(0, 1, size=(200, 2)) # 样本特征
y = np.array((X[:,0]**2+X[:,1])<1.5, dtype='int') # 样本标签
for _ in range(20):
y[np.random.randint(200)] = 1 # 随机改变样本标签值
# 散点图观察
plt.scatter(X[y==0,0], X[y==0,1])
plt.scatter(X[y==1,0], X[y==1,1])
plt.show()
# 数据集拆分
X_train,X_test,y_train,y_test = train_test_split(X,y,random_state=666)
# 调整逻辑回归的概率阈值
from sklearn.linear_model import LogisticRegression
log = LogisticRegression()
log.fit(X_train,y_train) # 训练拟合
# 预测出测试集样本中的概率
predict_proba = log.predict_proba(X_test)
# 获取每个样本被预测为y=1种类的概率
predict_proba_one = predict_proba[:,1]
threashold = 0.7 # 自己设定的概率阈值
predict_result = np.array(predict_proba_one > threashold,dtype=int)
# 判断准确率
print(np.sum(predict_result == y_test) / len(y_test)) 股票客户流失预警模型

背景介绍
在进行每一笔股票交易的时候,交易者(股民)都是要付给开户所在的证券公司一些手
续费的,虽然单笔交易的手续费并不高,然而股票市场每日都有巨额的成交量,使得每一笔
交易的手续费汇总起来的数目相当可观,而这一部分收入对于一些证券公司来说很重要,甚
至可以占到所有营业收入50%以上,因此证券公司对于客户(也即交易者)的忠诚度和活跃
度是很看重的。
如果一个客户不再通过该证券公司交易,也即该客户流失了,那么对于证券公司来说便
损失了一个收入来源,因此证券公司会搭建一套客户流失预警模型来预测交易者是否会流
失,从而对于流失概率较大的客户进行相应的挽回措施,因为通常情况下,获得新客户的成
本比保留现有客户的成本要高的多。
分析步骤
-
读取数据
-
划分特征变量和目标变量
-
划分训练集和测试集
-
模型训练
-
查看模型预测准确率
-
模型使用
- 预测数据结果
- 预测股票客户流失概率
代码实现
python
# 1.读取数据
import pandas as pd
df = pd.read_excel('股票客户流失.xlsx')
df.head()
# 2.划分特征变量和目标变量
X = df.drop(columns='是否流失')
y = df['是否流失']
# 3.划分训练集和测试集
from sklearn.model_selection import train_test_split
# 设置random_state使得每次划分的数据一样
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=1)
# 4.模型训练
from sklearn.linear_model import LogisticRegression
model = LogisticRegression()
model.fit(X_train, y_train)
# 5.查看模型预测准确率
model.score(X_test, y_test)
# 6.模型使用1 - 预测数据结果
y_pred = model.predict(X_test)
print(y_pred[:100]) # 打印预测内容的前100个看看
# 模型使用2 - 预测股票客户流失概率
y_pred_proba = model.predict_proba(X_test)
print(y_pred_proba[:5]) # 打印前5个客户的分类概率
# 只查看流失的概率(也即y=1概率,即上面二维数组的第二列)
print("股票客户流失概率:",y_pred_proba[:,1])Softmax回归简介
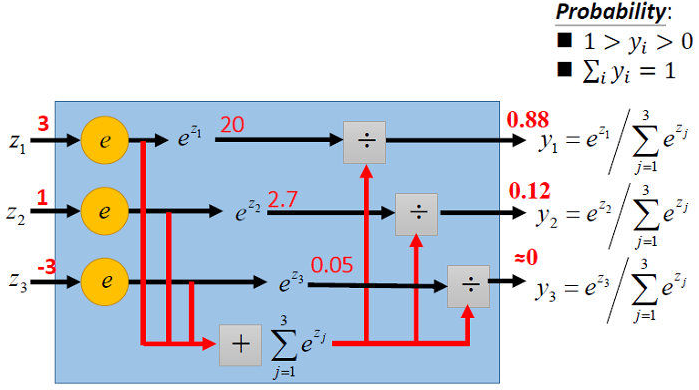
什么是Softmax回归
-
Softmax回归模型是逻辑回归模型在多分类问题上的推广
-
Softmax回归使用的是softmax函数
softmax函数
pl=ezl∑j=1kezj
由上式可以看出:softmax函数可以巧妙地将多个分类的分数(z~l~)转化为(0,1)的值并且和
为1
softmax函数计算的结果是各个分类的预测概率值
实战_Softmax回归预测鸢尾花多分类问题

sklearn中实现Softmax回归
在sklearn中没有直接封装Softmax回归,但是可以对LogisticRegression中的参数进行
变化,从而达到Softmax回归的效果。
主要是将multi_class参数设置为'multinomial'就可以了