1. 背景:
最近我在做 PCB 缺陷检测,使用的是 YOLO 系列模型。
在实际数据里,有一类目标比较特殊,就是头发丝、纤维、细线状异物这类细长目标。
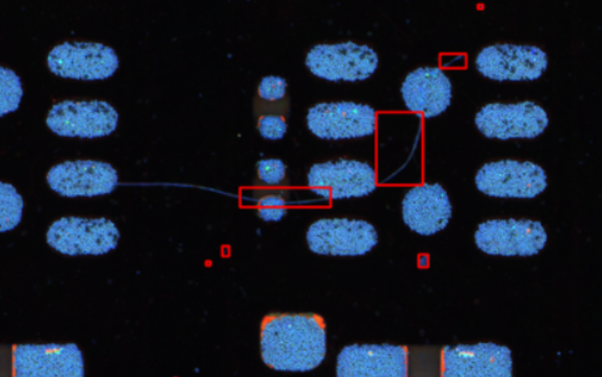
一开始我遇到一个很困惑的问题:
-
标注的时候,明明是一整根头发,只标了 一个框
-
但是模型推理时,经常会沿着同一根头发打出 多个小框
-
尤其是当头发下面刚好经过锡膏、焊盘、反光区域或者复杂背景时,这种现象会更明显
也就是说,真实上是一个连续目标,但检测结果却被"切成了几段"。
最开始我以为这只是:
-
NMS 参数没调好
-
标签不一致
-
或者训练不充分
但后来仔细分析后发现,这个问题并不是一个简单的调参问题,而是和检测任务本身的表示方式 有关。更准确地说,这和检测和分割在数学上的决策空间不同有直接关系。
于是查了一些资料,根据自己的理解把这个问题系统梳理一下:
为什么细长目标在检测中容易出现"分段框选",而分割更容易表现为"mask 断裂但仍沿目标延续"。
2. 决策单位不同:这是理解整个问题的总纲
2.1 检测的决策单位是"框"
以 YOLOv8 为例,模型最终是在很多位置上判断:
-
这里有没有目标
-
如果有,应该回归成什么框
注意这里的输出单位是框 。
哪怕某个位置只输出一个预测框,也不代表一个真实目标只会被一个位置负责。
同一个目标完全可能在多个位置上都触发响应,从而得到多个框。
所以检测本质上是在回答:哪些局部区域值得输出成一个目标框?
对于细长目标,这就很容易变成:
-
左边这一段看起来像目标,出一个框
-
中间这一段也像,再出一个框
-
右边这一段还像,再出一个框
于是同一根头发就被拆成了多个检测结果。
2.2 分割的决策单位是"像素"
而分割不一样。
分割是在整张图上逐像素判断:
-
这个像素是前景
-
那个像素是背景
所以它的输出是一个密集的 mask,而不是几个离散的框。
对于一根头发,分割并不是在问"这一段要不要单独出框",而是在问:
沿着这根头发所在的位置,这些像素是不是属于前景
因此即使分割失败,它更容易表现成:
-
某一段变细
-
某一段置信度降低
-
中间轻微断裂
-
或者跟YOLO一样,形成两个连通域
3. 为什么检测更容易被背景干扰,而分割相对没那么容易被干扰
这一点是我后来觉得最好理解、也最本质的一个角度。
3.1 检测里,背景被一起塞进"一个正样本框"
在检测任务里,如果你把一整根头发标成一个框,那么这个框对应的监督含义其实是:
这个矩形区域,应该被当成一个目标实例
但问题在于,细长目标的外接框通常会包含大量背景。
比如一根头发很细很长,它真正属于目标的像素只有很窄的一条线,但外接框里却会包含很多:
-
PCB 底板背景
-
焊盘
-
锡膏
-
反光区域
-
杂乱纹理
也就是说,检测把"目标 + 大量背景"绑成了一个训练单元。
模型在学的时候,必须用这个框区域对应的特征去同时支持:
-
目标存在
-
类别正确
-
框坐标正确
当这个框里背景成分太杂时,模型就不太容易学到"这是一个纯粹的完整目标框",反而更容易只抓住其中最显著的那一小段。
换句话说:
对模型来说,"整根头发的大框"可能不如"头发某一段最清楚的小框**(****因为这里的置信度更高)**"更容易学习。
3.2 分割里,背景和前景是逐像素分开的
分割也有背景,但分割对背景的处理方式完全不同。
在分割里,监督形式是:
-
这个像素是前景
-
那个像素是背景
-
前景只沿着头发那几像素宽的区域分布
所以虽然整张图里背景同样很多,但背景不会被绑进"目标本体"的表示里 。
这一点特别关键。
检测是在问:
这个大矩形区域是不是一个目标?
分割是在问:
这里的这些具体像素是不是目标的一部分?
所以对于细长目标:
-
检测更容易被"大量背景包着一条细线"的表示方式拖累
-
分割虽然也面对背景,但背景只是普通的逐像素负样本,并不会被当成目标实例的一部分
这就是为什么两者面对同一根头发时,行为会明显不同。
4. 为什么细长目标在 IoU 下更敏感,从而诱导模型偏向局部响应
除了背景问题,另一个很重要的原因是:
细长目标对框回归特别不友好。
4.1 YOLOv8 的训练里是用到 IoU 类约束的
YOLOv8 的边框回归里是有 IoU 类损失 的,同时还有 DFL 来做边界细化。
也就是说,模型不仅要判断"有没有目标",还要尽量把预测框和 GT 框对齐。
4.2 细长框对误差特别敏感
假设 GT 是一个很细长的框。
对这种框来说,哪怕只是很小的偏差,比如:
-
横向偏 2 像素
-
宽度多 2 像素
-
高度少 3 像素
都可能让 IoU 下降得比较明显。
因为目标本来就窄,容错非常低。
普通块状目标偏几像素,也许问题不大;
但细长目标一偏,重叠区域可能马上缩水很多。
这意味着:
预测"整根细长大框",很难稳定地拿到高 IoU
4.3 局部小框反而更容易优化
相比之下,如果模型只抓住其中最明显的一段,那么它预测的这个局部框往往会有这些优势:
-
局部特征更清楚
-
前景占比更高
-
边界更容易估计
-
和背景差异更明显
-
更容易取得一个稳定下降的损失趋势
因此从优化的角度看,模型就更容易形成这样一种倾向:
与其费力预测整根大框,不如在几段最显著的位置分别形成局部响应
这就是为什么 IoU 敏感性,会进一步诱导模型偏向"局部段框"。
5. 下采样后,为什么检测更容易多框,而分割更容易断裂
这一部分是很多人最容易困惑的地方,因为检测和分割其实都会遇到:
-
下采样
-
特征变粗
-
细线变弱
-
中间可能断掉
那为什检测容易多框,分割相对没那么容易?
5.1 检测:一旦局部强、局部弱,就容易变成多个候选框
检测头的逻辑是:
在很多位置上判断"这里有没有目标,并回归一个框"
假设头发经过 backbone 和 neck 之后,在特征图上表现成这样:
-
左边一段还有明显响应
-
中间一段变弱甚至断掉
-
右边一段又重新变强
那检测头会怎么做?
它不会主动去思考:
左边和右边是不是同一根头发?
它只会在局部强响应的位置分别做判断:
-
左边这里像目标,出一个框
-
中间太弱,不出
-
右边这里又像目标,再出一个框
如果中间还有一点弱响应,可能又多出一个小框。
于是你最终看到的结果就是:
-
左段一个框
-
右段一个框
-
甚至中间再夹一个框
也就是典型的"分段框出"。
5.2 分割:即便局部变弱,它输出的仍然是像素连通区域
分割头不一样。
分割头不是在若干位置上决定"出不出框",而是在输出一个密集 mask。
所以即使中间某一段因为下采样变弱了,它最终更容易表现成:
-
这条线变细了一点
-
某一段置信度降低了
-
中间出现轻微断裂
-
或者分成两个连通域
5.3 为什么分割更容易"连起来"
还有一个很重要的原因是,分割有天然的空间连续性偏置。
卷积特征会让相邻像素共享上下文。
当一条细线前后两段都比较明显时,中间哪怕稍微弱一点,网络也更容易借助邻域信息把它延续过去。
所以分割更容易形成一种"沿着这条线继续涂前景"的效果。
而检测没有这种机制。
检测只有:
-
这个位置要不要出框
-
这个框大概怎么回归
它不会沿着曲线一像素一像素地延展目标。
所以最终就会出现这种差异:
-
分割更容易错成"中间断一点"
-
检测更容易错成"沿途出多个段框"