目录
1.YOLOv10--简介
YOLOv10 是清华大学研究人员在 UltralyticsPython 清华大学的研究人员在 YOLOv10软件包的基础上,引入了一种新的实时目标检测方法,解决了YOLO 以前版本在后处理和模型架构方面的不足。通过消除非最大抑制(NMS)和优化各种模型组件,YOLOv10 在显著降低计算开销的同时实现了最先进的性能。并用大量实验证明,YOLOv10 在多个模型尺度上实现了卓越的精度-延迟权衡。YOLOv10与其他SOTA模型的性能对比如下:
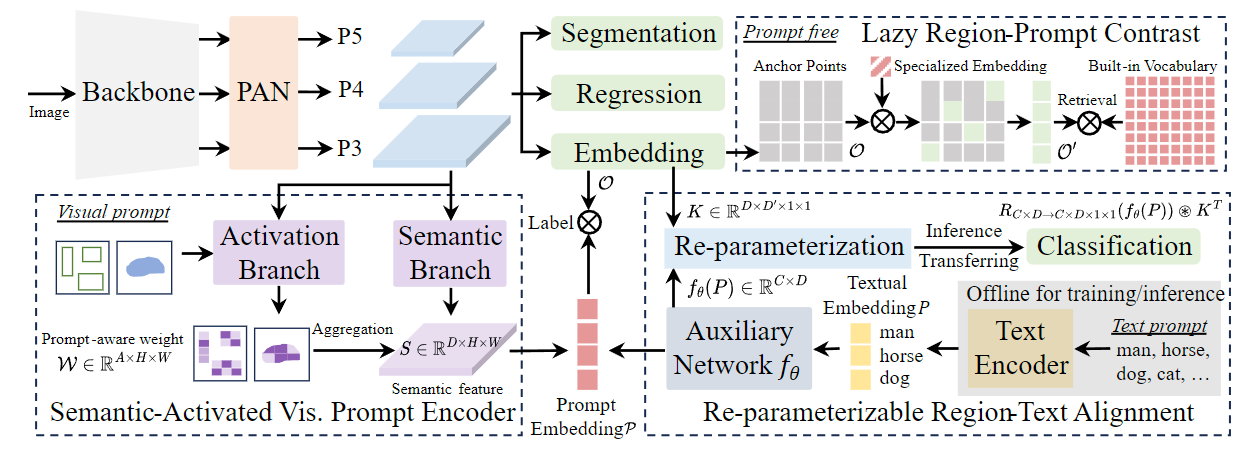
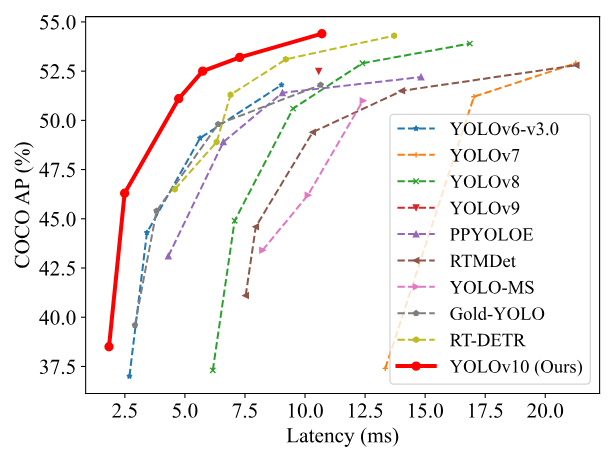
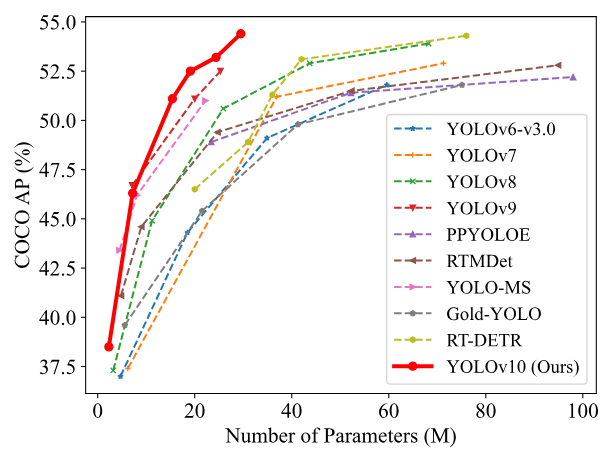
亮点
- 无 NMS 设计:利用一致的双重分配来消除对 NMS 的需求,从而减少推理延迟。
- 整体模型设计:从效率和准确性的角度全面优化各种组件,包括轻量级分类头、空间通道去耦向下采样和等级引导块设计。
- 增强的模型功能:纳入大核卷积和部分自注意模块,在不增加大量计算成本的情况下提高性能。
标题:YOLOv10: Real-Time End-to-End Object Detection(实时端到端目标检测)
论文:https://arxiv .org/pdf/2405.14458
源码:https://github.com/THU-MIG/yolov10
对应的模型:YOLOv10 的官方预训练权重主要是基于 MS COCO 数据集训练的。
| Model | Test Size | #Params | FLOPs | APval | Latency |
|---|---|---|---|---|---|
| YOLOv10-N | 640 | 2.3M | 6.7G | 38.5% | 1.84ms |
| YOLOv10-S | 640 | 7.2M | 21.6G | 46.3% | 2.49ms |
| YOLOv10-M | 640 | 15.4M | 59.1G | 51.1% | 4.74ms |
| YOLOv10-B | 640 | 19.1M | 92.0G | 52.5% | 5.74ms |
| YOLOv10-L | 640 | 24.4M | 120.3G | 53.2% | 7.28ms |
| YOLOv10-X | 640 | 29.5M | 160.4G | 54.4% | 10.70ms |
YOLOv10-N:用于资源极其有限环境的纳米版本。
YOLOv10-S:兼顾速度和精度的小型版本。
YOLOv10-M:通用中型版本。
YOLOv10-B:平衡型,宽度增加,精度更高。
YOLOv10-L:大型版本,精度更高,但计算资源增加。
YOLOv10-X:超大型版本可实现最高精度和性能。
2.YOLOv10--源码
2.1.下载
在github上面下载源码:https://github.com/THU-MIG/yolov10
2.2.环境
下面的操作都是在代码的根目录下面操作
bash
cd D:\pythonProject\python--postgraduate\object_detection\yolov10-mainconda环境
bash
conda create -n yolov10 python=3.9
conda activate yolov10venv环境
bash
python -m venv yolov10
# 2. 激活虚拟环境
# Windows 系统 (PowerShell):
yolov10\Scripts\Activate.ps1
# 3. 升级 pip (推荐,防止安装报错)
pip install --upgrade pip在终端看见括号就成功激活:

我们查看一下环境包文件:默认是pytorch-cpu版本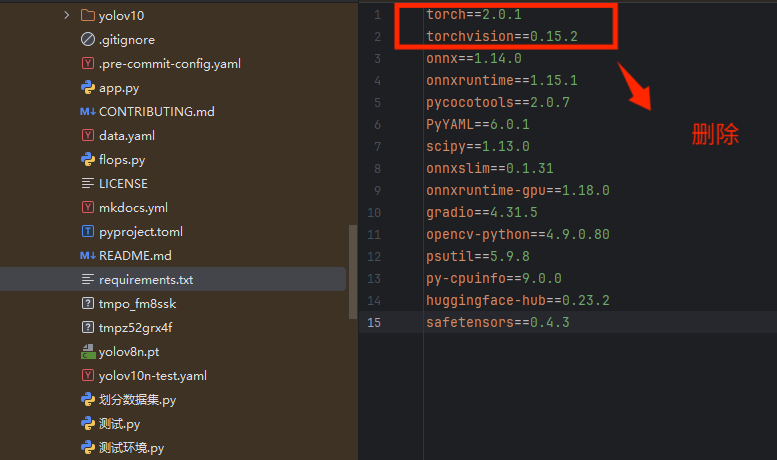
bash
pip install -r requirements.txt
pip install -e .这里把前面的删了,单独安装:
这里需要根据自己cuda环境配置对应的pytorch版本,
查看cuda:
bash
nvidia-smi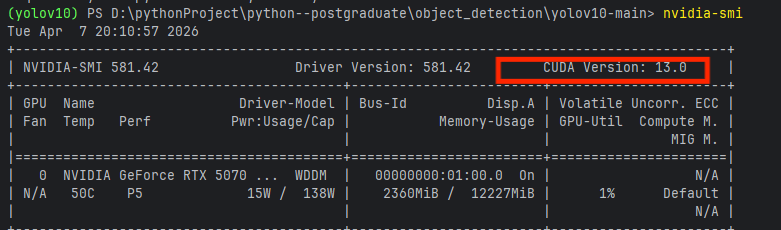
在pytorch官网获取下载命令:https://pytorch.org/get-started/locally/
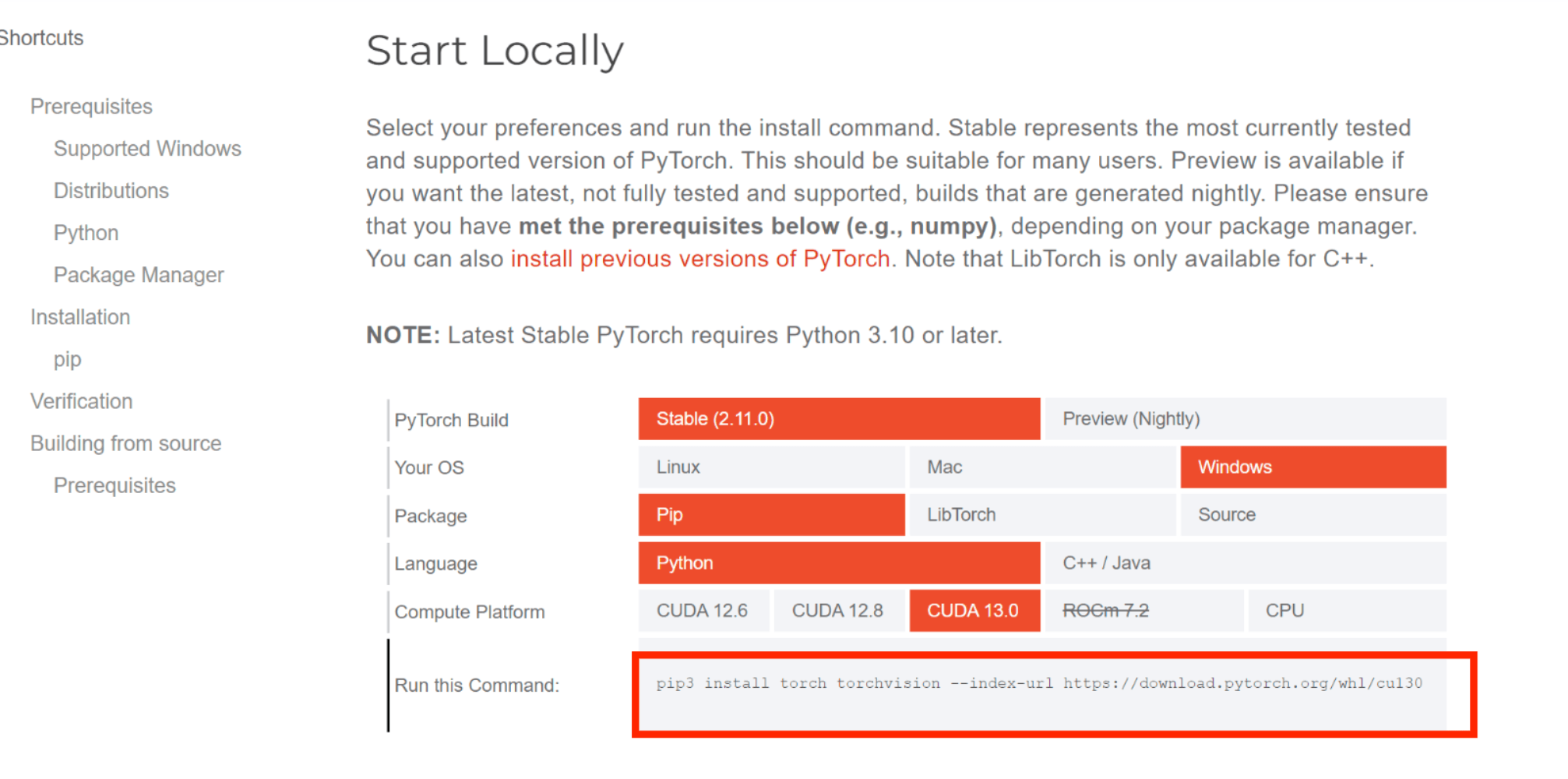
bash
pip3 install torch torchvision --index-url https://download.pytorch.org/whl/cu130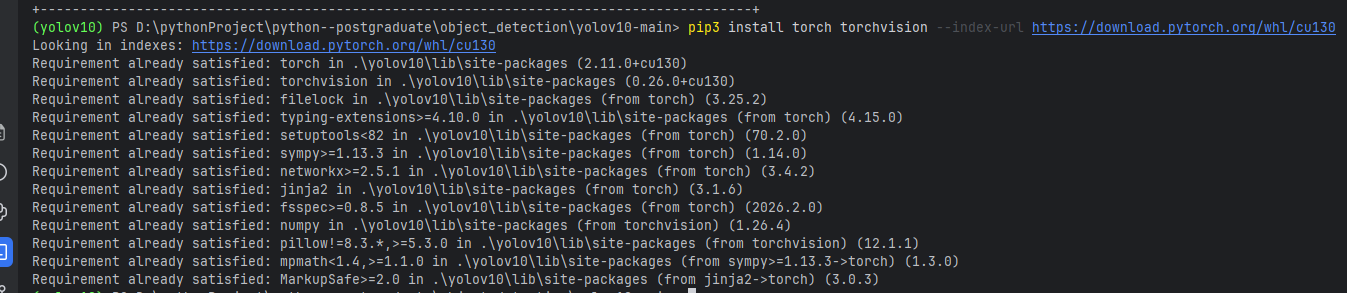
终端之后验证一下:
bash
python -c "import torch; print('CUDA 可用:', torch.cuda.is_available()); print('GPU 数量:', torch.cuda.device_count()); print('GPU 名称:', torch.cuda.get_device_name(0) if torch.cuda.is_available() else '无')"
3.YOLOv10--数据
可以使用labelimg对自己的数据进行标签操作:
https://blog.csdn.net/qq_58602552/article/details/156903760?spm=1001.2014.3001.5501

1.选择图片文件夹
2.选择save标签保存文件夹
然后根据自己训练的需要进行标签操作:
最后得到:
图片文件:
标签文件.txt: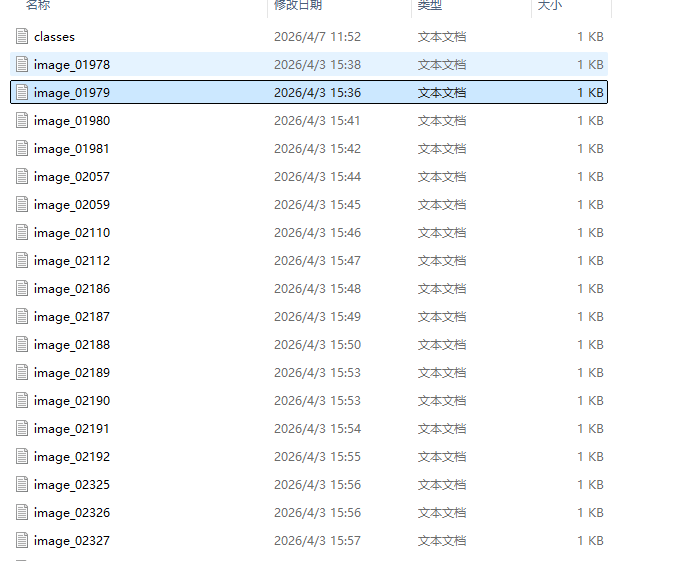

名字对齐
3.1.构建数据集
在根目录下面构建data 文件夹,包含labels和images两个子目录,然后把数据放进去
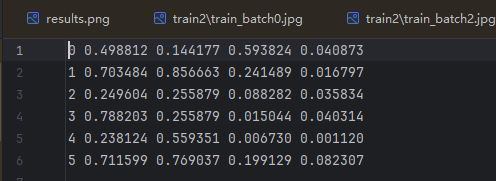
类别 中心点x 中心点y 宽w 高h
都是归一化后的数据(图片左上角为0,0)
将数据集划分成8:1:1,训练/测试/验证
根目录下创建dataset.py:
bash
# -*- coding: utf-8 -*-
import shutil
import random
import os
import sys
import io
# --- 1. 解决中文乱码问题 ---
# 强制标准输出使用 utf-8 编码
sys.stdout = io.TextIOWrapper(sys.stdout.buffer, encoding='utf-8')
print(">>> 程序开始加载...")
# --- 2. 路径配置 ---
# 注意:在 Python 中建议使用 "/" 或者双反斜杠 "\\",单反斜杠 "\" 容易报错
image_original_path = "data/images/"
label_original_path = "data/labels/"
cur_path = os.getcwd()
# 使用 os.path.join 自动处理路径斜杠,避免硬编码错误
train_image_path = os.path.join(cur_path, "datasets/images/train/")
train_label_path = os.path.join(cur_path, "datasets/labels/train/")
val_image_path = os.path.join(cur_path, "datasets/images/val/")
val_label_path = os.path.join(cur_path, "datasets/labels/val/")
test_image_path = os.path.join(cur_path, "datasets/images/test/")
test_label_path = os.path.join(cur_path, "datasets/labels/test/")
list_train = os.path.join(cur_path, "datasets/train.txt")
list_val = os.path.join(cur_path, "datasets/val.txt")
list_test = os.path.join(cur_path, "datasets/test.txt")
train_percent = 0.8
val_percent = 0.1
test_percent = 0.1
def del_file(path):
if not os.path.exists(path):
return
for i in os.listdir(path):
file_data = os.path.join(path, i) # 优化:使用 join
if os.path.isfile(file_data):
os.remove(file_data)
def mkdir():
# 简化逻辑:exist_ok=True 表示如果文件夹存在就不报错
os.makedirs(train_image_path, exist_ok=True)
os.makedirs(train_label_path, exist_ok=True)
os.makedirs(val_image_path, exist_ok=True)
os.makedirs(val_label_path, exist_ok=True)
os.makedirs(test_image_path, exist_ok=True)
os.makedirs(test_label_path, exist_ok=True)
# 清空旧文件
del_file(train_image_path)
del_file(train_label_path)
del_file(val_image_path)
del_file(val_label_path)
del_file(test_image_path)
del_file(test_label_path)
def clearfile():
for file_path in [list_train, list_val, list_test]:
if os.path.exists(file_path):
os.remove(file_path)
def main():
print(">>> 正在创建文件夹...")
mkdir()
clearfile()
# 检查原始数据是否存在
if not os.path.exists(label_original_path):
print(f"❌ 错误:找不到标签路径 {label_original_path}")
print("请检查 data/labels/ 文件夹是否存在")
return
total_txt = os.listdir(label_original_path)
# 过滤掉非 .txt 文件(防止系统生成 .DS_Store 等文件干扰)
total_txt = [f for f in total_txt if f.endswith('.txt')]
num_txt = len(total_txt)
if num_txt == 0:
print(f"❌ 错误:在 {label_original_path} 中没有找到任何 txt 标签文件")
return
print(f">>> 共找到 {num_txt} 个标签文件,开始划分数据集...")
list_all_txt = range(num_txt)
num_train = int(num_txt * train_percent)
num_val = int(num_txt * val_percent)
# num_test 自动计算剩余部分
# 随机抽取
train = random.sample(list_all_txt, num_train)
val_test = [i for i in list_all_txt if i not in train]
val = random.sample(val_test, num_val)
print(f"划分结果 -> 训练集: {len(train)}, 验证集: {len(val)}, 测试集: {len(val_test) - len(val)}")
# 打开文件准备写入,显式指定 encoding='utf-8'
file_train = open(list_train, 'w', encoding='utf-8')
file_val = open(list_val, 'w', encoding='utf-8')
file_test = open(list_test, 'w', encoding='utf-8')
for i in list_all_txt:
name = total_txt[i][:-4] # 去掉 .txt 后缀
srcImage = os.path.join(image_original_path, name + '.jpg')
srcLabel = os.path.join(label_original_path, name + '.txt')
# 检查图片是否存在,防止报错
if not os.path.exists(srcImage):
print(f"⚠️ 警告:找不到图片 {srcImage},跳过...")
continue
if i in train:
dst_train_Image = os.path.join(train_image_path, name + '.jpg')
dst_train_Label = os.path.join(train_label_path, name + '.txt')
shutil.copyfile(srcImage, dst_train_Image)
shutil.copyfile(srcLabel, dst_train_Label)
file_train.write(dst_train_Image + '\n')
elif i in val:
dst_val_Image = os.path.join(val_image_path, name + '.jpg')
dst_val_Label = os.path.join(val_label_path, name + '.txt')
shutil.copyfile(srcImage, dst_val_Image)
shutil.copyfile(srcLabel, dst_val_Label)
file_val.write(dst_val_Image + '\n')
else:
dst_test_Image = os.path.join(test_image_path, name + '.jpg')
dst_test_Label = os.path.join(test_label_path, name + '.txt')
shutil.copyfile(srcImage, dst_test_Image)
shutil.copyfile(srcLabel, dst_test_Label)
file_test.write(dst_test_Image + '\n')
file_train.close()
file_val.close()
file_test.close()
print(">>> ✅ 数据集划分完成!")
# --- 3. 必须显式调用 main() ---
if __name__ == "__main__":
main()
else:
# 在 Jupyter 中,__name__ 可能不是 __main__,所以加一个兜底调用
main()运行之后得到数据集:
3.2.修改配置文件
1.数据配置
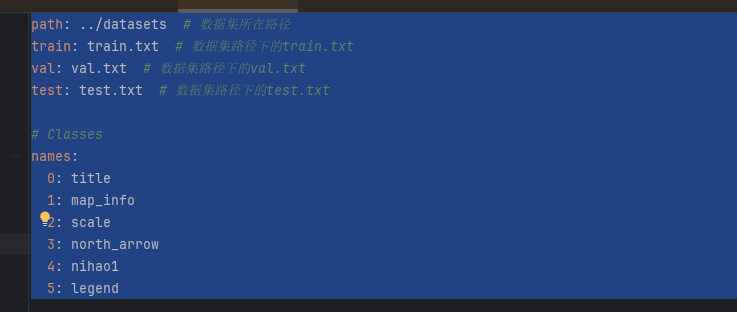
找到根目录下的data.yaml文件
根据自己的标注数据修改对应的类别,一定要对齐
2.模型配置
在ultralytics/cfg/models/v10文件夹下存放的是YOLOv10的各个版本的模型配置文件,检测的类别是coco数据的80类。在训l练自己数据集的时候,只需要将其中的类别数修改成自己的大小。在根目录文件夹下新建yolov10n-test.yaml文件,此处以yolov10n.yaml文件中的模型为例,将其中的内容复制到yolov10n-test.yaml文件中,并将nc:1#number ofclasses修改类别数修改成自己的类别数,如下:

bash
# Parameters
nc: 6 # number of classes
scales: # model compound scaling constants, i.e. 'model=yolov8n.yaml' will call yolov8.yaml with scale 'n'
# [depth, width, max_channels]
n: [0.33, 0.25, 1024]
# YOLOv8.0n backbone
backbone:
# [from, repeats, module, args]
- [-1, 1, Conv, [64, 3, 2]] # 0-P1/2
- [-1, 1, Conv, [128, 3, 2]] # 1-P2/4
- [-1, 3, C2f, [128, True]]
- [-1, 1, Conv, [256, 3, 2]] # 3-P3/8
- [-1, 6, C2f, [256, True]]
- [-1, 1, SCDown, [512, 3, 2]] # 5-P4/16
- [-1, 6, C2f, [512, True]]
- [-1, 1, SCDown, [1024, 3, 2]] # 7-P5/32
- [-1, 3, C2f, [1024, True]]
- [-1, 1, SPPF, [1024, 5]] # 9
- [-1, 1, PSA, [1024]] # 10
# YOLOv8.0n head
head:
- [-1, 1, nn.Upsample, [None, 2, "nearest"]]
- [[-1, 6], 1, Concat, [1]] # cat backbone P4
- [-1, 3, C2f, [512]] # 13
- [-1, 1, nn.Upsample, [None, 2, "nearest"]]
- [[-1, 4], 1, Concat, [1]] # cat backbone P3
- [-1, 3, C2f, [256]] # 16 (P3/8-small)
- [-1, 1, Conv, [256, 3, 2]]
- [[-1, 13], 1, Concat, [1]] # cat head P4
- [-1, 3, C2f, [512]] # 19 (P4/16-medium)
- [-1, 1, SCDown, [512, 3, 2]]
- [[-1, 10], 1, Concat, [1]] # cat head P5
- [-1, 3, C2fCIB, [1024, True, True]] # 22 (P5/32-large)
- [[16, 19, 22], 1, v10Detect, [nc]] # Detect(P3, P4, P5)下载对应的权重文件:https://github.com/THU-MIG/yolov10/releases
根据所选择的模型下载相应的权重,我这边下载的是yolov10n.pt,放在了根目weights/yolov10n.pt路径下。
YOLOv10的超参数配置在ultralytics/cfg文件夹下的default.yaml文件中
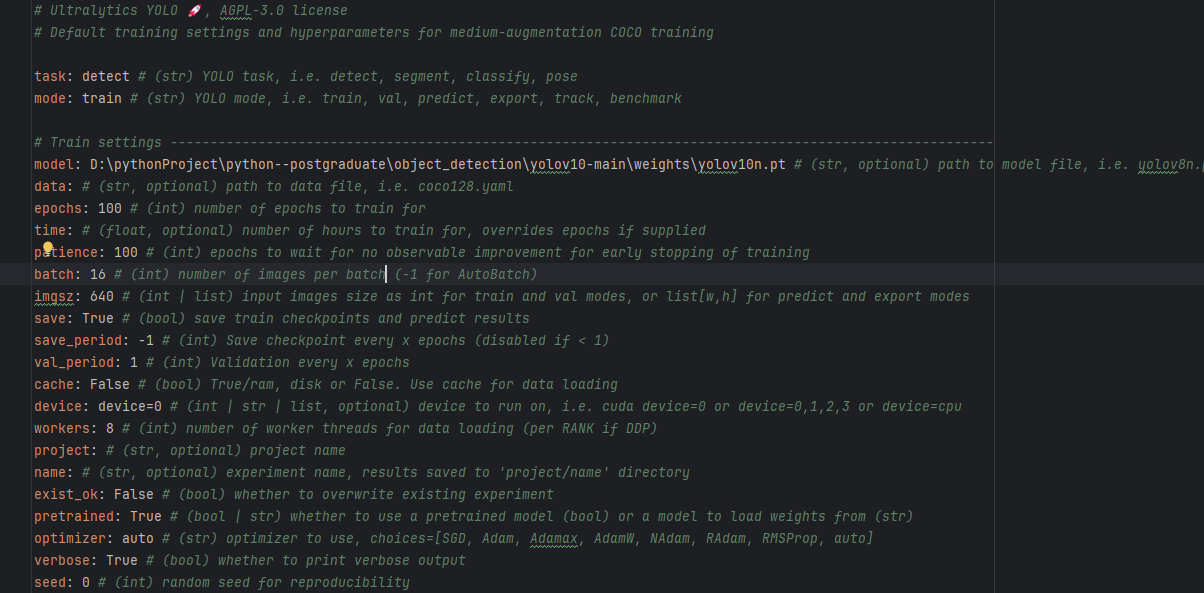
在模型训l练中,比较重要的参数是weights、data、epochs、batch、imgsz、device以及workers。
- ·weight是配置预训l练权重的路径,可以指定模型的yaml文件或pt文件。
- ·data是配置数据集文件的路径,用于指定自己的数据集yaml文件。
- ·epochs指训练的轮次,默认是100次,只要模型能收敛即可。
- ·batch是表示一次性将多少张图片放在一起训练,越大训练的越快,如果设置的太大会报OOM错误,我这边在default中设置16,表示一次训练16张图像。设置的大小为2的幂次,1为2的0次,16为2的4次。
- ·imgsz表示送入训练的图像大小,会统一进行缩放。要求是32的整数倍,尽量和图像本身大小一致。
- ·device指训l练运行的设备。该参数指定了模型训l练所使用的设备,例如使用GPU运行可以指定为device=0,或者使用多个GPU运行可以指定为device=0,1,2,3,如果没有可用的GPU,可以指定为device=cpu使用CPU进行训l练。
- ·workers是指数据装载时cpu所使用的线程数,默认为8,过高时会报错:WinError1455页面文件太小,无法完成操作,此时就只能将workers调成0了。
模型训练的相关基本参数就是这些啦,其余的参数可以等到后期训练完成进行调参时再详细了解。
4.YOLOv10--训练
下面是yolo命令汇总:
|-----------|-----------------|-------------------------------------------------------------------------|-------------------------------------------|
| 1. 训练 | 开始训练 | yolo detect train data=data.yaml model=yolov10n.pt epochs=100 | data: 数据集配置 model: 预训练权重 epochs: 轮数 |
| | 指定批次大小 | yolo detect train ... batch=16 device=0 | batch: 显存够大可设 32/64 device: 指定显卡ID |
| | 断点续训 | yolo detect train model=runs/detect/train/weights/last.pt resume=True | resume=True: 自动读取上次进度 |
| | 从预训练恢复 | yolo detect train model=yolov10n.pt resume=True | 用于继续训练官方权重 |
| 2. 预测 | 预测图片 | yolo detect predict model=best.pt source=image.jpg | source: 图片路径 |
| | 预测视频 | yolo detect predict model=best.pt source=video.mp4 | source: 视频路径 |
| | 预测文件夹 | yolo detect predict model=best.pt source=path/to/images/ | 批量处理文件夹内图片 |
| | 调用摄像头 | yolo detect predict model=best.pt source=0 show=True | source=0: 默认摄像头 show=True: 显示画面 |
| | 保存结果 | ... save=True save_txt=True save_conf=True | save_txt: 保存标签文本 save_conf: 保存置信度 |
| 3. 验证 | 验证模型精度 | yolo detect val model=best.pt data=data.yaml | 计算 mAP, Precision, Recall |
| | 指定验证集 | yolo detect val ... split=val | split: val (验证集) 或 test (测试集) |
| 4. 导出 | 导出 ONNX | yolo export model=best.pt format=onnx | 用于通用部署 |
| | 导出 TensorRT | yolo export model=best.pt format=engine | 推荐:NVIDIA 显卡部署最快 |
| | 导出 OpenVINO | yolo export model=best.pt format=openvino | 用于 Intel CPU/GPU 部署 |
| 5. 高级 | 查看帮助 | yolo --help | 查看所有可用命令 |
| | 查看版本 | yolo version | 查看当前库版本 |
4.1.训练
1.使用命令行训练:
bash
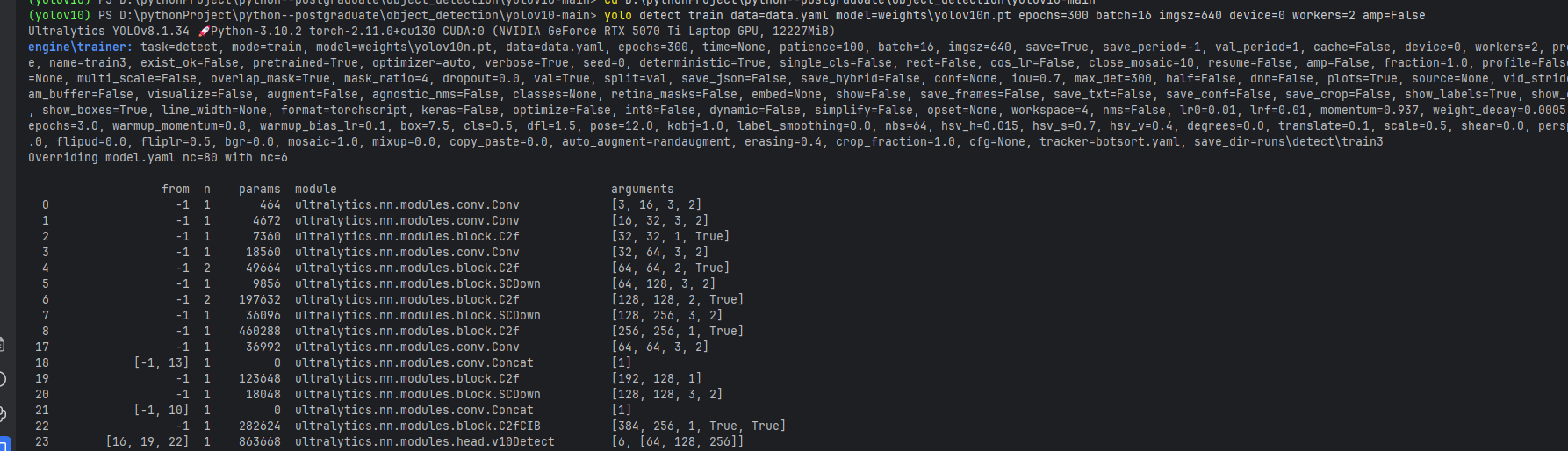
yolo detect train data=data.yaml model=yolov10n-test.yaml epochs=300 batch=16 imgsz=640 device=0 workers=2 amp=False
bash
yolo detect train data=data.yaml model=weights\yolov10n.pt epochs=300 batch=16 imgsz=640 device=0 workers=2 amp=False这里
model=yolov10n.pt就是微调 (Fine-tuning)。model=yolov10n-test.yaml就是从头训练 (Training from Scratch)。
yolo detect train: 启动目标检测任务的训练模式。data=data.yaml: 指定数据集配置文件。- 注意 :确保当前目录下真的有
data.yaml,且里面正确配置了train和val的图片路径。
- 注意 :确保当前目录下真的有
model=yolov10n-test.yaml: 指定模型配置文件。- 含义 :你选择不使用预训练权重 (如
yolov10n.pt),而是从头开始训练(Training from Scratch)。 - 风险 :如果你只是想微调,这里应该填
yolov10n.pt。如果你确实是想从头训练(比如你的数据集类别和 COCO 完全不同),那么请确保yolov10n-test.yaml文件存在于当前目录,或者使用官方标准配置yolov10-n.yaml。
- 含义 :你选择不使用预训练权重 (如
epochs=300: 训练 300 轮。- 评价:对于从头训练,300 轮是合理的;如果是微调,通常 100 轮就够了。
batch=16: 批次大小为 16。- 评价:对于 YOLOv10-N 这种小模型,RTX 5070 Ti 跑这个数值毫无压力,甚至可能还有显存剩余。
imgsz=640: 输入图片分辨率 640x640。device=0: 使用第一张显卡(你的 RTX 5070 Ti)。workers=2: 数据加载线程数为 2。- 评价:Windows 系统下设为 2 或 0 是很稳妥的选择,能有效避免多进程报错。
amp=False: 关闭自动混合精度训练 。- 评价 :这是一个非常稳健 的设置。虽然开启 AMP (
True) 能节省显存并加快速度,但在某些特定硬件或 PyTorch 版本组合下可能会导致精度溢出或报错。关闭它虽然会稍微增加显存占用和训练时间,但能保证数值稳定性,避免训练崩溃。
- 评价 :这是一个非常稳健 的设置。虽然开启 AMP (
也可以使用代码训练:
bash
from ultralytics import YOLOv10
# 加载模型
model = YOLOv10("yolov10n-test.yaml") # 模型结构
# model.load('yolov10n.pt') # 是否加载预训练权重
if __name__ == '__main__':
model.train(data="data.yaml", imgsz=640, batch=32, epochs=300, workers=2) # 训练模型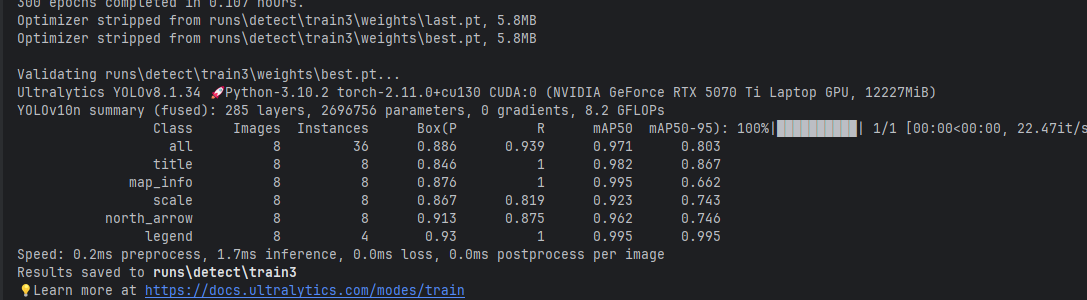
然后训练完了就可以在\runs\detect下面找到训练结果:
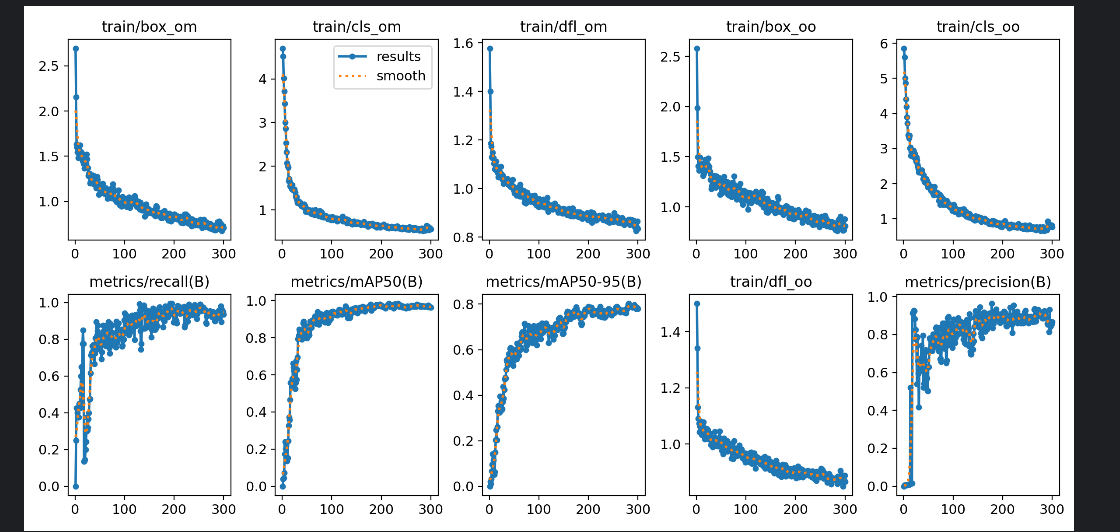
查看验证结果:val_batch0_pred.jpg:

4.2.测试
bash
yolo detect val data=data.yaml model=runs/detect/train3/weights/best.pt batch=16 imgsz=640 split=test device=0 workers=2
4.3.预测
bash
import warnings
import cv2
warnings.filterwarnings('ignore')
from ultralytics import YOLOv10
if __name__ == '__main__':
# 1. 加载模型
model = YOLOv10('runs/detect/train3/weights/best.pt')
# 2. 进行预测
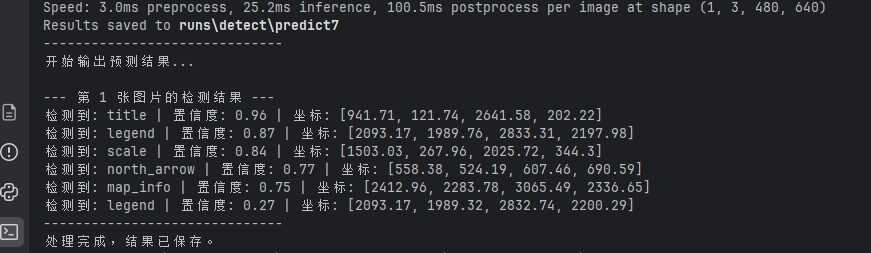
results = model.predict(
source=r"image_02329.jpg",
imgsz=640,
device=0, # 使用CPU
save=True, # 保存结果图片
show=False, # 不弹窗显示
conf=0.25 # 置信度阈值
)
# 3. 【核心修改】遍历并输出详细预测结果
print("-" * 30)
print("开始输出预测结果...")
# results 是一个列表,包含每一张图片的预测结果
for i, r in enumerate(results):
print(f"\n--- 第 {i + 1} 张图片的检测结果 ---")
# 获取检测框信息
boxes = r.boxes
# 如果没检测到任何物体
if len(boxes) == 0:
print("未检测到任何目标。")
continue
# 遍历每一个检测到的框
for box in boxes:
# 获取坐标 (x1, y1, x2, y2)
b = box.xyxy[0]
xyxy = [round(x, 2) for x in b.tolist()]
# 获取类别索引和名称
cls_id = int(box.cls[0])
cls_name = r.names[cls_id]
# 获取置信度
conf = box.conf[0].item()
# 格式化输出
print(f"检测到: {cls_name} | "
f"置信度: {conf:.2f} | "
f"坐标: {xyxy}")
print("-" * 30)
print("处理完成,结果已保存。")