****论文题目:****Adaptive fault diagnosis of railway vehicle on-board controller with large language models(基于大语言模型的轨道车辆车载控制器自适应故障诊断)
****期刊:****Applied Soft Computing
****摘要:****准确识别铁路系统车载控制器(VOBC)的故障类型,对于保证列车的安全运行具有重要意义。近年来,大型语言模型(Large Language Models, llm)在语义理解和自然语言交互方面表现出色,为VOBC故障诊断提供了一种新的解决方案。然而,在一般领域进行预训练的大型语言模型缺乏与铁路VOBC故障诊断场景相关的专门知识,导致对铁路特定文本语料库的适应性不足。本文深入研究了大型语言模型对VOBC故障诊断的适应性,提出了铁路故障诊断大语言模型(RFD-LLM)。首先,采用基于低秩自适应(LoRA)的铁路域自适应来匹配VOBC故障模式;其次,应用指令调优实现领域知识对齐,增强模型遵循指令的能力。提出的RFD-LLM是首个基于大型语言模型的铁路VOBC故障诊断模型,能够高效、准确地识别出7种类型的VOBC故障模式。RFD-LLM为铁路领域的大型模型开发提供了一种新的解决方案。
用大语言模型诊断列车故障?这篇论文给出了完整答案
一、背景:列车"大脑"出了故障,怎么诊断?
城市轨道交通的安全运行离不开一个核心装置------车载控制器(Vehicle On-Board Controller,VOBC)。它负责列车超速防护、自动驾驶控制,直接决定列车的可靠性与安全性。
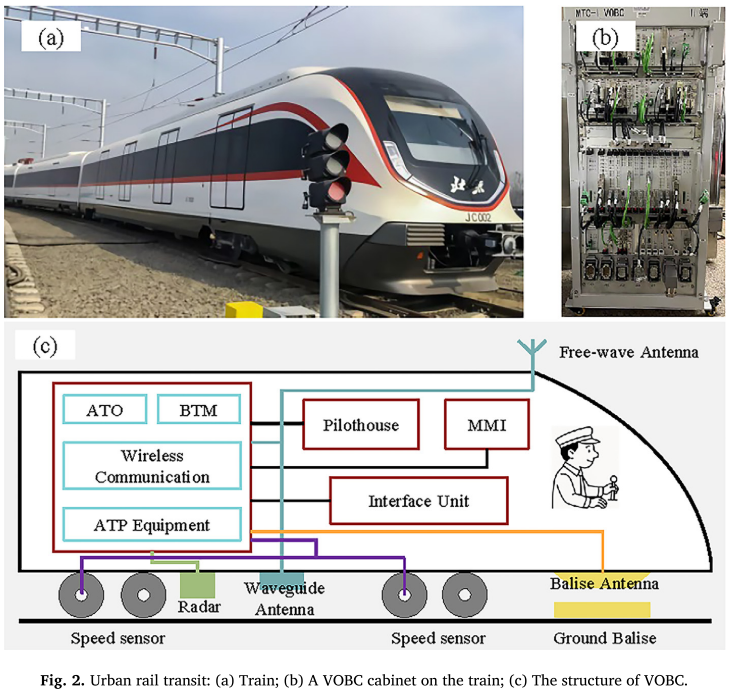
【配图:Fig. 2 --- 城市轨道列车、VOBC机柜及VOBC系统结构图】
VOBC结构复杂,包含多个功能模块:
- ATP(自动列车防护):负责速度测量、距离检测和定位;
- ATO(自动列车运行):负责列车自动驾驶;
- BTM(应答器传输模块):传输地面应答器位置信息;
- DCS(数据通信系统):实现车地双向无线通信;
- MMI(人机界面):向司机提供辅助驾驶信息;
- 传感器:速度传感器与雷达传感器,用于高精度定位。
列车长期在复杂动态环境下运行,VOBC故障时有发生。一旦故障未能及时诊断,轻则引发晚点,重则危及行车安全。因此,高效、准确地诊断VOBC故障是保障地铁安全运营的关键。
二、现有方法的困境
2.1 传统方法忽略了文本数据
过去,故障诊断主要依赖传感器采集的结构化数据,通过SVM、随机森林、深度学习等方法进行分析,也取得了不错的效果。
然而,这些方法却忽视了另一个极其重要的信息来源------非结构化的故障文本。铁路运营部门每年产生数百万条维修日志和诊断报告,其中蕴含着丰富的故障信息。
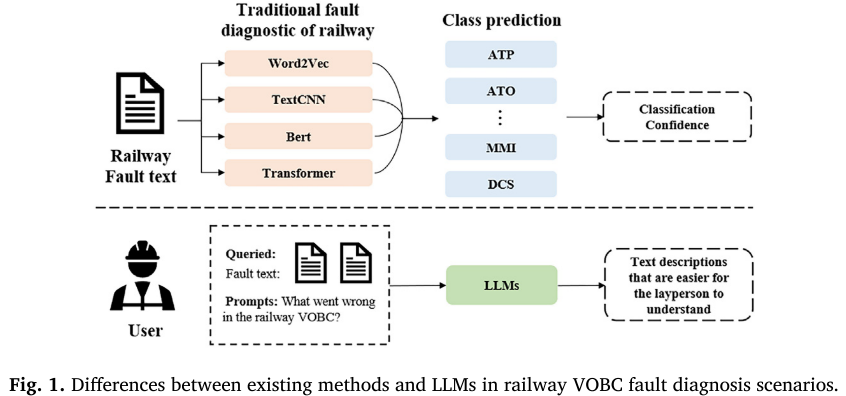
【配图:Fig. 1 --- 传统方法与LLM在VOBC故障诊断场景中的对比示意图】
这些文本有三个显著特征,使得自动化分析极为困难:
- 信息模糊:大量冗余信息,且故障描述存在歧义。例如,实际是速度传感器报警引发了VOBC故障,但文本中却直接写的是"ATP故障",容易误导模型;
- 高维特征:专业术语数以万计,即便去除停用词、提取关键词,特征维度依然庞大;
- 领域专业性强:大量专业词汇(如"ATP")在铁路语境下的含义与通用语料库中截然不同。
【配表:Table 1 --- VOBC维修记录示例(含7类故障的典型描述)】
2.2 传统NLP方法力不从心
为了处理这些文本,研究者们先后引入了TF-IDF、Word2Vec、BERT等NLP技术,也取得了一定进展。但这些方法存在明显瓶颈:
- TF-IDF等统计方法忽略词序,无法捕捉细粒度语义依赖;
- Word2Vec等词嵌入方法上下文建模能力有限;
- 所有这些方法的输出都是离散的概率值,缺乏可解释的诊断解释,对现场维修人员实用价值有限。
2.3 通用LLM直接用也不行
以LLaMA、Qwen、DeepSeek为代表的大语言模型(LLM)具备强大的语义理解和自然语言交互能力,理论上非常适合处理VOBC故障文本。然而,直接将通用LLM用于铁路领域存在根本性问题:
- 通用LLM在互联网文本上预训练,缺乏铁路专业知识;
- VOBC故障文本格式不规则、含大量缩写和符号,与通用语料分布差异显著;
- 缺乏领域适配的LLM在识别专业故障模式时性能退化,且无法生成可信的诊断输出。
这就是本文要解决的核心问题:如何让LLM真正"懂"铁路故障,而不只是"懂"语言?
三、本文提出的方法:RFD-LLM
3.1 整体思路
本文提出 RFD-LLM(Railway Fault Diagnosis Large Language Model) ,这是铁路领域第一个基于大语言模型的VOBC故障诊断模型。
其核心是一套两阶段适配策略,专门用于弥合通用LLM与铁路专业知识之间的鸿沟:
- 第一阶段:基于LoRA的铁路领域适配(让模型"读懂"铁路故障文本);
- 第二阶段:指令微调(让模型"按要求"输出诊断结果)。
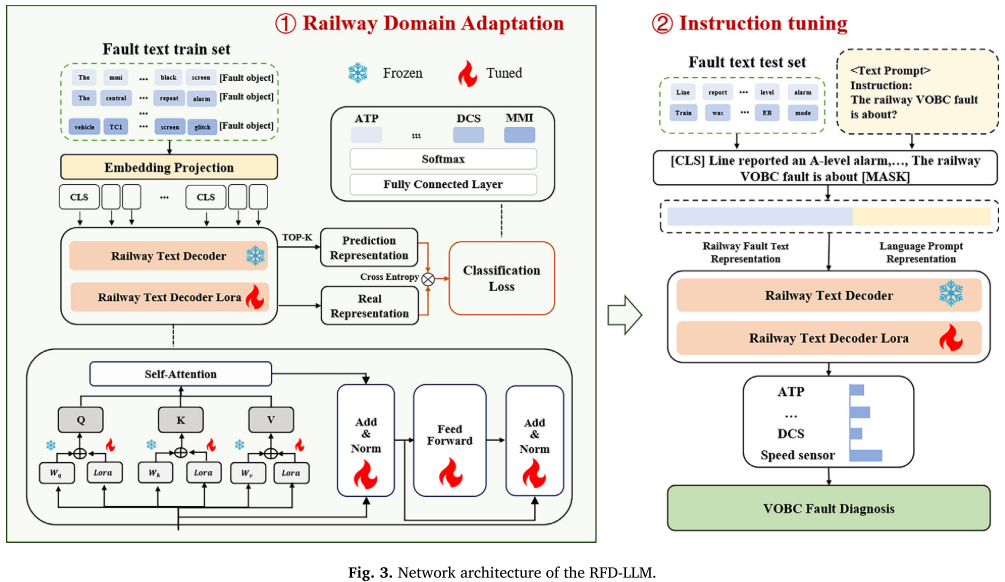
【配图:Fig. 3 --- RFD-LLM网络架构图(含两阶段结构、RTD模块、LoRA适配器)】
3.2 第一阶段:LoRA铁路领域适配
为什么用LoRA?
全量微调(Full Fine-tuning)一个大模型代价极高,且容易导致"灾难性遗忘"------模型在学习新知识的同时丢失原有的语言能力。LoRA(Low-Rank Adaptation)提供了一种轻量高效的替代方案。
LoRA的核心思想 是:对预训练权重矩阵 W0 不做修改,而是在旁路注入一个低秩分解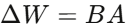 (其中
(其中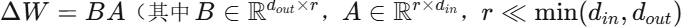 ),前向计算变为:
),前向计算变为:
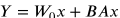
在RFD-LLM中,LoRA适配器被插入每个Transformer块的Q、K、V投影层 以及前馈网络的第一个线性层,其余参数全部冻结。
Railway Text Decoder(RTD)
本文设计了专用的铁路文本解码器(RTD),以预训练LLM(Yi-coder-1.5B)为骨干,包含嵌入投影层和多头注意力块。其输出计算公式为:
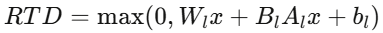
有监督学习对齐
在领域适配阶段,还引入了有监督学习。对于给定的VOBC故障数据集(包含 m 个文本-标签对),模型使用基于余弦相似度的对比损失函数:
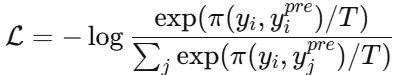
其中温度参数 T=0.95,用于平滑输出分布,避免过度自信的预测。
3.3 第二阶段:指令微调
完成领域适配后,模型已能"读懂"铁路故障文本,但还需要学会"按指令回答"。指令微调将VOBC故障特征 Hf 与指令嵌入 Eins 融合,送入RTD进行下一个token的预测:
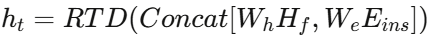
为防止输出退化(如重复或无意义序列),引入TOP-P采样(p=0.7),仅从累积概率超过阈值的候选词中采样,保证诊断回复的多样性和自然性。
训练目标为自回归损失函数:
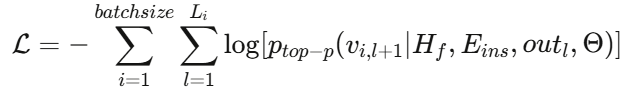
这一设计将故障诊断任务重构为完形填空问题,与LLM的预训练目标天然对齐,使模型能够同时关注故障数据中的上下文关系和因果关系。
四、实验:用北京地铁真实数据验证
4.1 实验设置
- 数据集 :北京地铁2020---2022年VOBC维修数据,共1366条记录;
- 故障类别:7类(ATP、ATO、BTM、DCS、MMI、速度传感器、雷达传感器);
- 划分:80%训练集,20%测试集;
- 骨干模型:Yi-coder-1.5B;
- 评估指标:平均准确率(Accuracy)、精确率(Precision)、F1分数。
4.2 与传统方法的对比
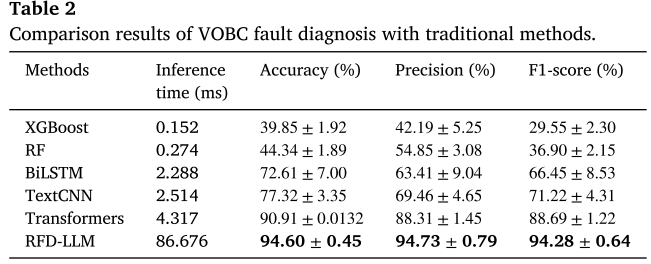
【配表:Table 2 --- RFD-LLM与传统方法(XGBoost、RF、BiLSTM、TextCNN、Transformers)的对比结果】
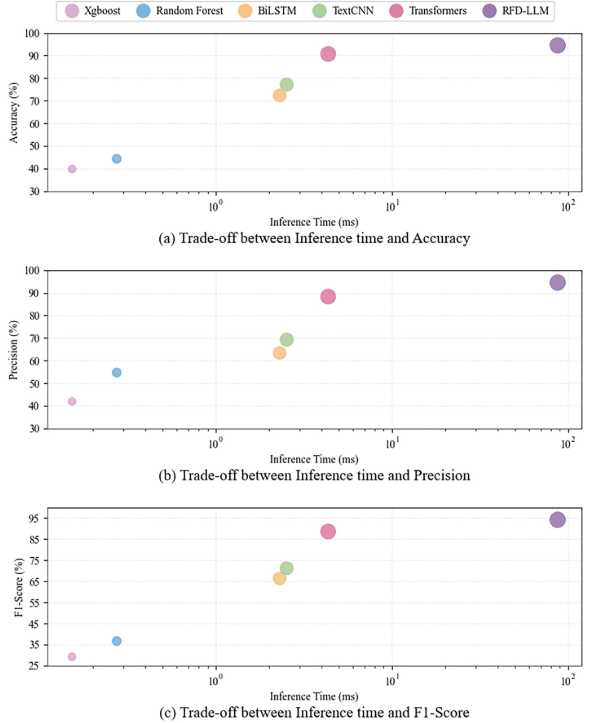
【配图:Fig. 4 --- 不同方法推理时间与准确率/精确率/F1分数的权衡散点图】
从结果中可以看出几个清晰的规律:
- RFD-LLM性能最优:准确率94.60%、精确率94.73%、F1分数94.28%,全面领先;
- 鲁棒性最强:RFD-LLM的准确率标准差仅0.45、精确率标准差0.79、F1标准差0.64,远低于其他方法,说明其在噪声干扰下依然稳定;
- Transformer类方法整体优于传统ML:得益于自注意力机制对全局语义的捕捉能力;
- 推理时间 :RFD-LLM的推理时间为86.676ms,虽然是所有方法中最慢的(XGBoost仅0.152ms),但相比人工诊断动辄数分钟乃至数小时,仍具有极高的实用价值。论文明确指出,在铁路系统中,低于100ms的推理延迟完全在可接受范围内。
对于推理速度问题,论文也给出了未来优化路径:FP16/INT8量化、知识蒸馏、模型剪枝等技术均可进一步压缩推理延迟。
4.3 与其他LLM的对比
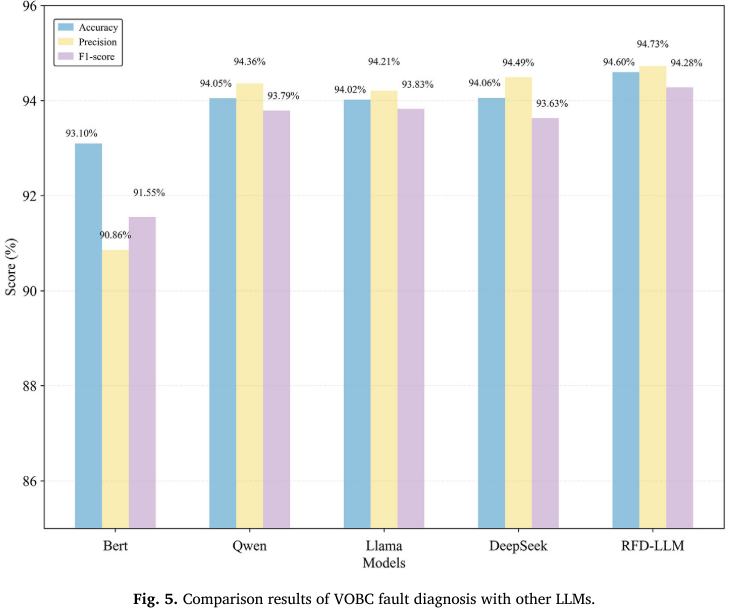
【配图:Fig. 5 --- RFD-LLM与BERT、Qwen-2.5、LLaMA-3.2、DeepSeek-R1的对比柱状图】
本文将RFD-LLM与4个主流LLM进行对比,选取依据涵盖架构多样性和公开可复现性:
| 模型 | 架构类型 | 准确率 |
|---|---|---|
| BERT | 编码器-only | 93.10% |
| Qwen-2.5 | 解码器-only | 94.05% |
| LLaMA-3.2 | 解码器-only | 94.21% |
| DeepSeek-R1 | 解码器-only | 94.49% |
| RFD-LLM | 解码器-only + 两阶段适配 | 94.60% |
关键发现:
- 所有LLM基方法的准确率均超过93%,验证了LLM在复杂铁路故障诊断任务中的有效性;
- BERT表现相对最弱,可能与其编码器-only架构的低秩问题有关,限制了表示能力;
- RFD-LLM在准确率、精确率、F1分数三项指标上均达到最优,证明两阶段适配策略的价值。
4.4 LoRA秩的敏感性分析
LoRA的秩(rank)决定了可训练参数量,直接影响适配效果。本文系统地测试了rank从4到32的情况。
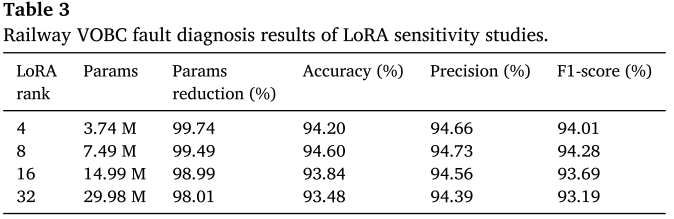
【配表:Table 3 --- 不同LoRA rank下的参数量、参数削减率及性能指标】
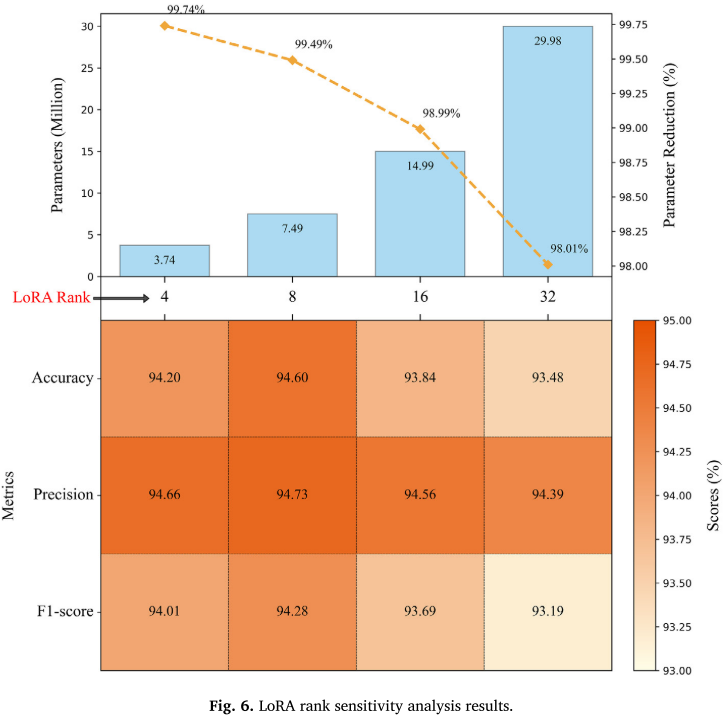
【配图:Fig. 6 --- LoRA秩敏感性分析结果(参数量与性能热力图)】
结论非常清晰:
- rank=8时性能最佳 (准确率94.60%,F1 94.28%),可训练参数仅7.49M,相比全量微调削减99.49%;
- rank=4时削减率高达99.74%(仅3.74M参数),性能略有下降但差距极小;
- rank越大,性能反而下降:rank=16时准确率降至93.84%,rank=32时进一步降至93.48%。原因在于:铁路VOBC故障数据集规模相对较小(1366条),无法为更多参数提供足够的训练样本,导致过拟合。
这一发现表明,在数据有限的工业场景中,并非参数越多越好,合理的LoRA配置能在资源节约与性能之间取得最佳平衡。
4.5 消融实验
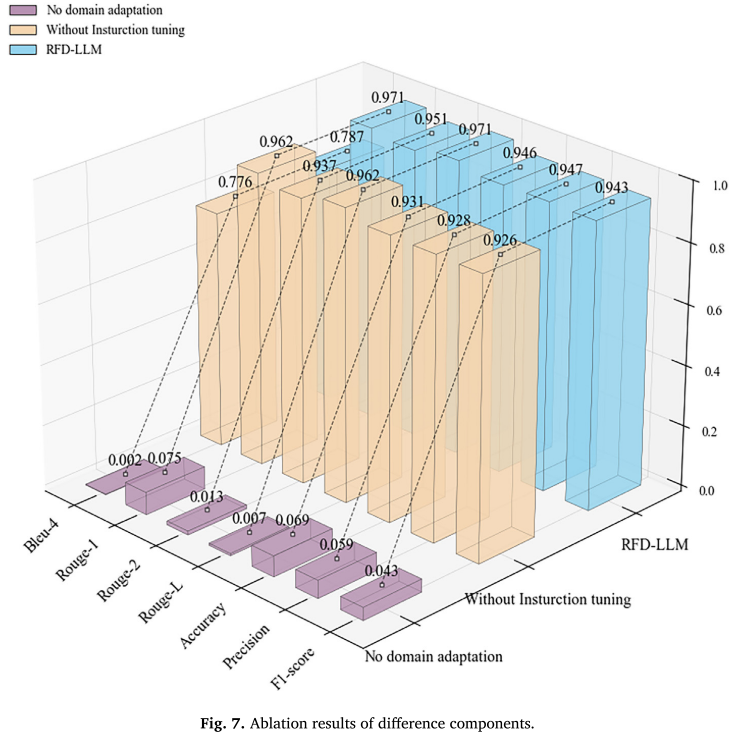
【配图:Fig. 7 --- 消融实验结果(三维柱状图,含Bleu-4、Rouge-1、Rouge-2、Rouge-L、准确率、精确率、F1)】
消融实验从两个维度验证了两阶段策略的必要性:
去除领域适配(仅保留指令微调): 所有指标均明显下降。原因是铁路领域特有的术语和知识在通用预训练语料中严重不足,仅靠指令微调无法弥补这一知识鸿沟。
去除指令微调(仅保留领域适配): 同样导致性能下滑,尤其体现在文本生成质量指标(BLEU-4、Rouge系列)上,说明指令微调对于生成结构化、符合诊断规范的自然语言回复不可或缺。
两阶段完整版(RFD-LLM): 在全部8项评估指标上均达到最优,验证了两个模块的协同增益效果。
五、更大的意义与未来展望
5.1 工程价值
本文的成功不只是一个故障分类器的提升,其意义更为深远:
- 为铁路领域LLM开发提供了可复用框架:两阶段适配策略可推广至联锁系统、轨道电路、计轴器等其他铁路子系统;
- LoRA为资源受限场景提供了可行路径:无需更新全部参数即可完成领域迁移;
- 有望推动故障报告标准化:领域专用LLM可促进运营商之间知识共享和维修实践协同。
5.2 未来展望
论文指出了几个值得期待的发展方向:
- 从诊断到预测:引入时序故障数据,将RFD-LLM从被动诊断工具转化为主动预测性维护系统,在故障发生前识别早期征兆;
- 多轮对话指令微调:当前仅支持固定的提示-回答格式,未来可引入多轮对话机制,提升交互灵活性;
- 知识图谱与因果推理:融合铁路领域知识图谱和因果推理机制,增强模型区分根本原因与表面症状的能力;
- 跨领域迁移:方法同样适用于航空维修、船舶诊断等其他高安全等级工业场景。
5.3 局限性
作者也坦诚指出了当前工作的不足:数据集规模较小(1366条)、指令模板形式固定、评估仅在离线场景进行,模型在实时嘈杂数据下的鲁棒性有待进一步验证。
六、总结
| 维度 | 内容 |
|---|---|
| 问题 | 通用LLM缺乏铁路领域知识,直接用于VOBC故障文本诊断效果差 |
| 方法 | 两阶段适配:LoRA领域适配 + 指令微调 |
| 亮点 | 铁路领域首个LLM故障诊断模型;LoRA rank=8仅需99.49%参数削减 |
| 性能 | 准确率94.60%,F1 94.28%,推理时间86.676ms,鲁棒性最优 |
| 数据 | 北京地铁真实VOBC维修数据,1366条,7类故障 |
RFD-LLM的提出,标志着大语言模型在安全关键工业系统中的应用迈出了重要一步。它不仅解决了铁路VOBC故障诊断的实际工程问题,更为领域专用LLM的高效开发提供了一套清晰、可复现、可迁移的技术范式。