📌 个人主页: 孙同学_
🔧 文章专栏: Liunx
💡 关注我,分享经验,助你少走弯路!

文章目录
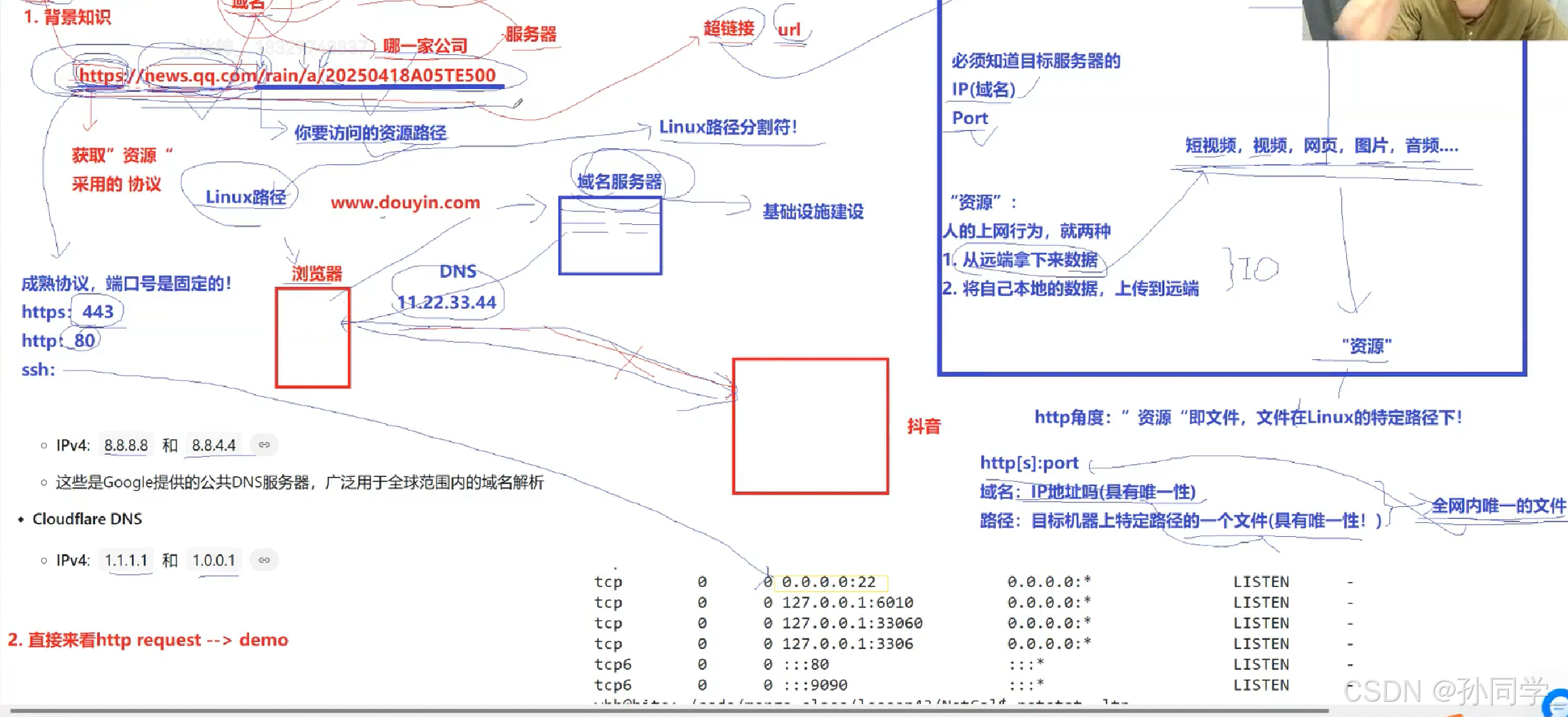
HTTP协议
虽然说应用层协议是我们程序员自己定的,但是有大佬已经定义出了现成的又非常好用的应用层协议,供我们参考使用。HTTP(超文本传输协议)就是其中的一种。
在互联网世界中,HTTP(HyperText Transfer Protocol,超文本传输协议)是一个至关重要的协议。它定义了客户端(如浏览器)与服务器之间如何通信,以交换或者传输超文本(如HTML文档)。
HTTP协议是客户端与服务器进行通信的基础。客户端通过HTTP协议向服务器发送请求,服务器收到请求后处理并返回响应。HTTP协议是一个无连接,无状态的协议,即每次请求需要建立新的连接,且服务器不会保存客户端的状态信息。
认识 URL
我们平时说的网址就是URL

URL是用来在全网当中,特定主机下的,特定云服务器上的,特定路径下的,去帮我们定位一个文件,然后通过该协议把这个文件返回给我们,这就叫做http协议
URL编码和解码
urlencode和urldecode
像/?:等这样的字符,已经被url当作特殊意义理解了,因此这些字符不能随意出现。比如,某个参数中需要带有这些特殊字符,就必须先对特殊字符进行转义。
转移的规则如下:
将需要转码的字符转为16进制,然后从右到左,取4位(不足4位直接处理),每2位作一位,前面加上%,编码成%XY格式
例如:
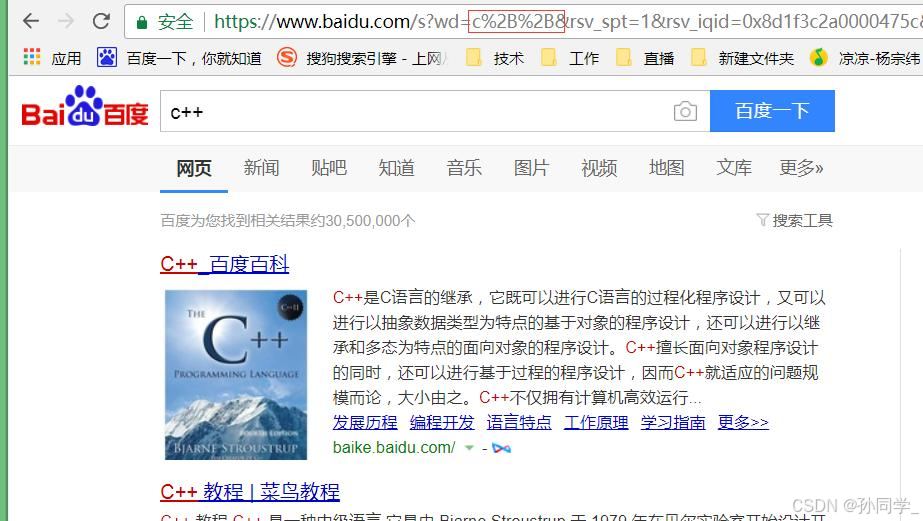
"+"被转义成了"%2B"
urldecode就是urlencode的逆过程
urlencode工具
HTTP 协议请求与响应格式
HTTP请求
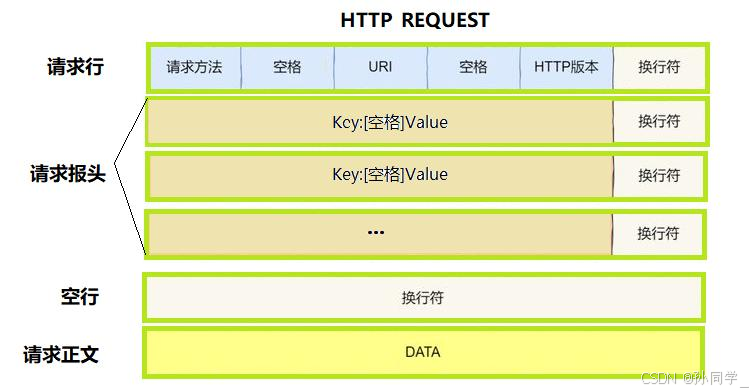
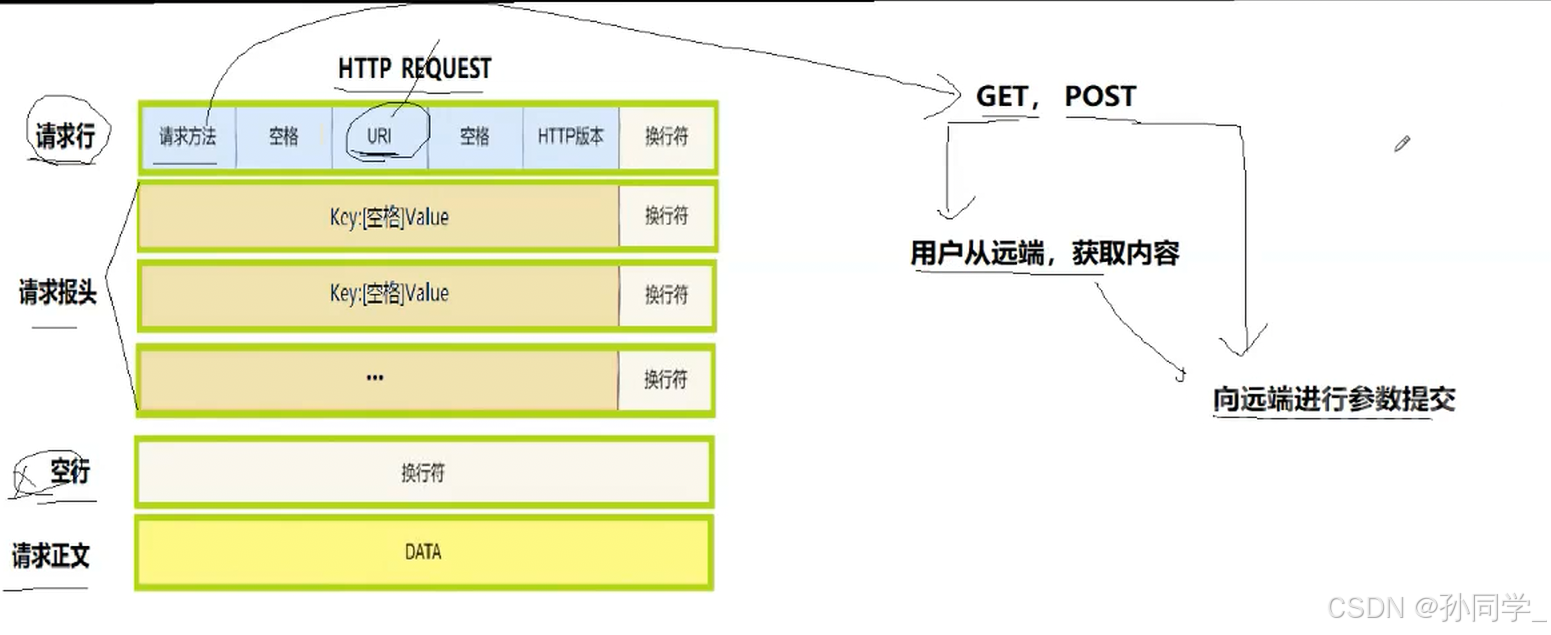
- 请求行:方法(GET/POST),URL ,协议版本。
- 请求头(Headers):键值对形式,如User-Agent,Host,Cookie
- 空行:请求头结束的标志
- 请求体(Entity Body):携带的数据(GET方法通常为空)
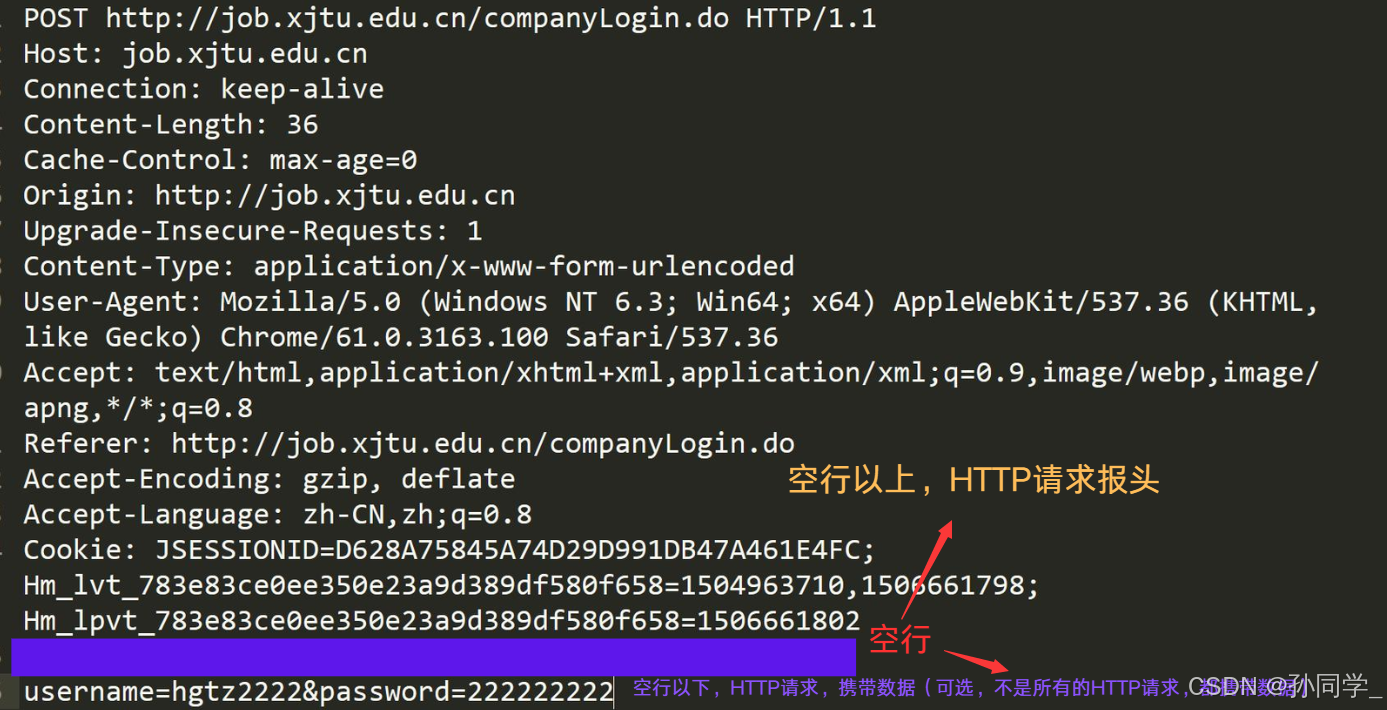
-
http如何做到将报头和有效载荷分离呢?
答案是: 以空行为分隔符
-
http协议如何理解?
答案是: 特殊字符来进行区分区域的
-
http协议序列和反序列化在哪里表现?
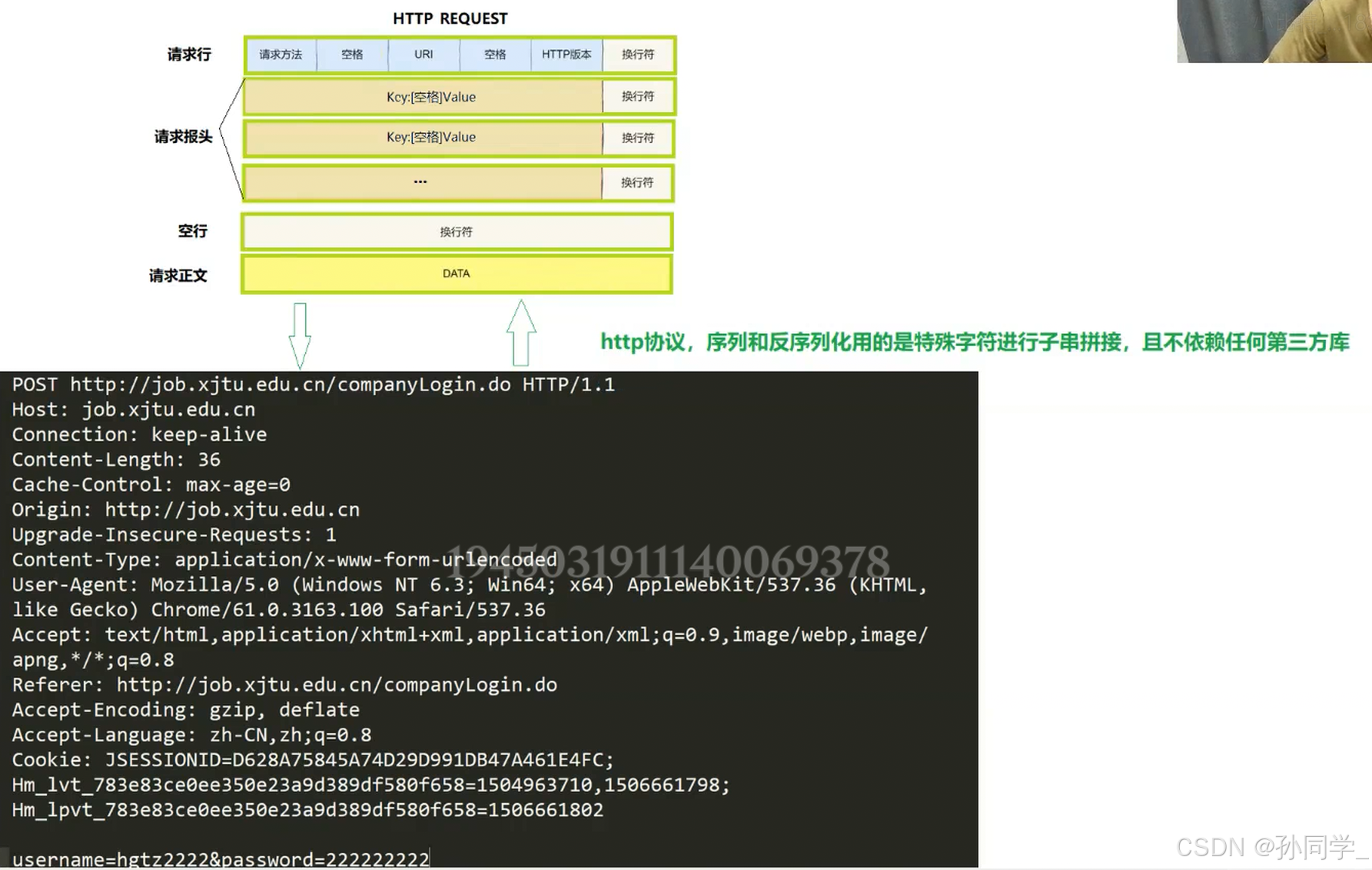
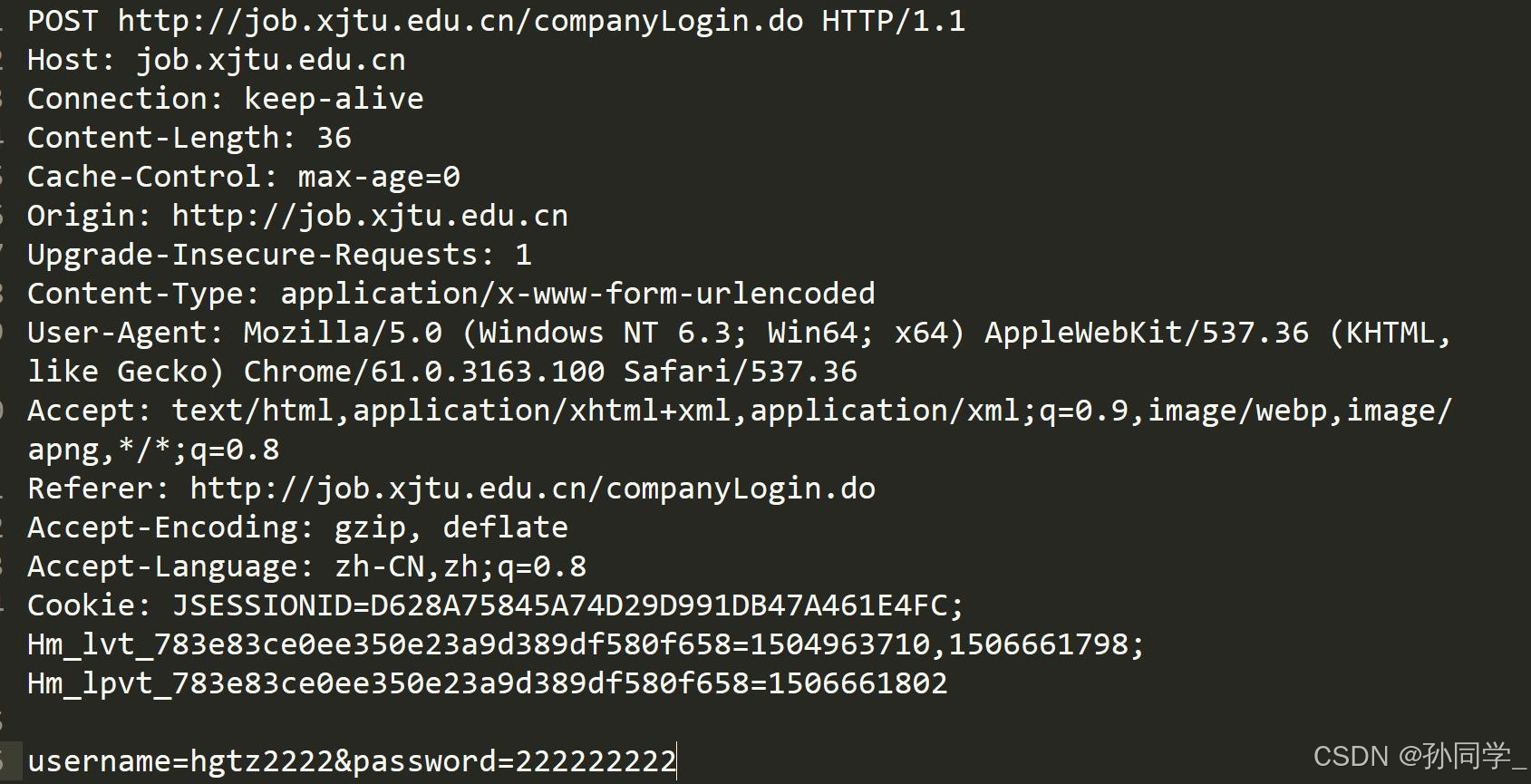
问题一: 当我们发起http请求的时候,请求是怎么表示自己要请求什么资源?
请求当中有个uri,如果uri被设置为
/,表示的是请求的是首页
答案是通过请求报头的请求行的uri表示的
特殊情况,如果我们在请求的时候,我们的url中什么都没写,那么它默认请求的就是
/
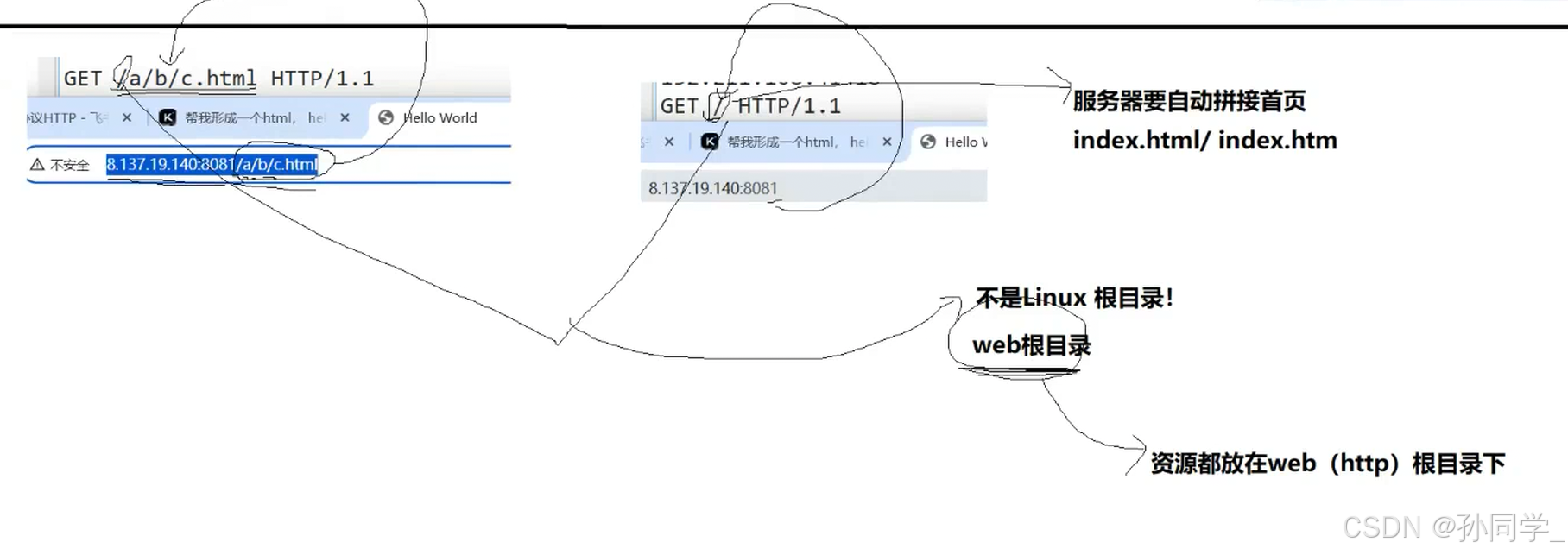
网页内容,必须都是服务器中特定路径下的文件(图片,视频...css,js...),这里的特定路径指的是web根目录
web根目录就是我们当前项目中的一个文件夹
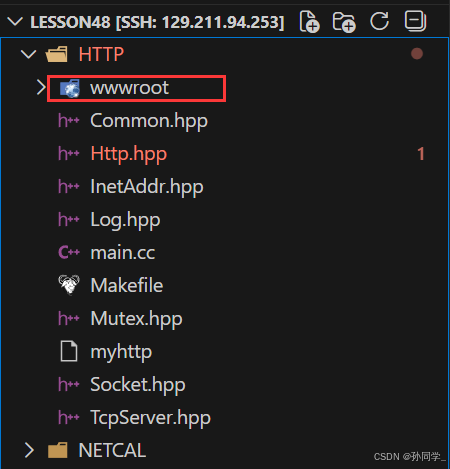
比如这里的wwwroot
wwwroot文件夹下的index.html就叫做默认首页,或者是index.htm.
什么叫做网页内容不能硬编码到服务器中,而必须保存在服务器下特定路径的文件下保存?
这就叫做对应的网页,这是一张网页,这张在wwwroot直接存在的网页叫做首页
问题二: 服务端的资源在哪里?我们是怎么知道的?

在未来我们要请求的资源,由uri决定,从/开始叫做web根目录。
如果请求的是/a/b/c,未来请求的是./wwwroot/a/b/c.html.
如果请求的是/,未来请求的是web根目录下的首页信息,./wwwroot + '/' + index.html
所以这个/表示的不是Linux的根目录,而是web的根目录。
所以http请求的本质是请求我们代码中的./wwwroot目录下的特定路径下的资源,而uri中的路径就是我们要找的
请求时有一个http版本,应答时也有一个http版本,为什么呢?
首先客户端和服务器是两款软件,客户端帮我们构建httprequest,服务端帮我们构建httpresponse,所以双方在构建通信的时候双方也要交换一下客户端的版本和服务器的版本。
为什么要有版本交换呢?为什么要在请求时带上自己的版本呢?
比如我们的微信有v1版本和v2版本,v1版本只支持聊天,后来腾讯把它的服务端版本升级成了v2版本,不仅能聊天,也能刷朋友圈了,服务器升级成v2的时候我们的客户不一定升级成v2版本。所以必定存在服务器和客户端版本不一致问题,所以在通信的时候,客户端要把自己的版本告诉服务器,服务器就只提供在你的版本范围以内的功能。
所以双方交换版本就是在协商双方所支持的功能,不同版本功能不同。
Content-Lenth
如何保证读到的就是完整请求呢?
答案是没办法保证读到完整的请求,但是有办法读到完整的报头。
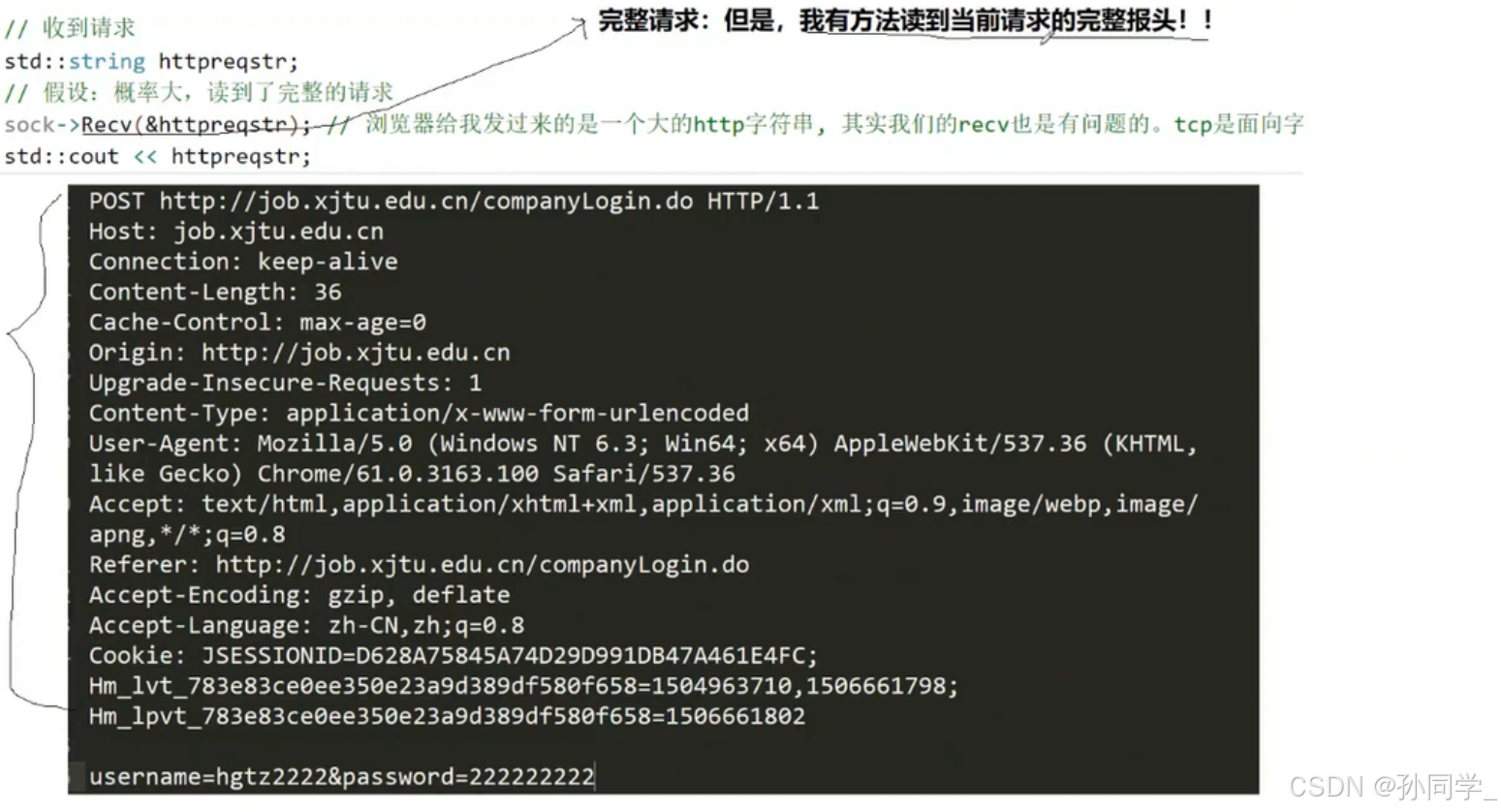
怎么保证读到完整的报头呢?答案是读到空行。
在报头信息中有一个Content-Lenth属性,表示的就是在正文大小。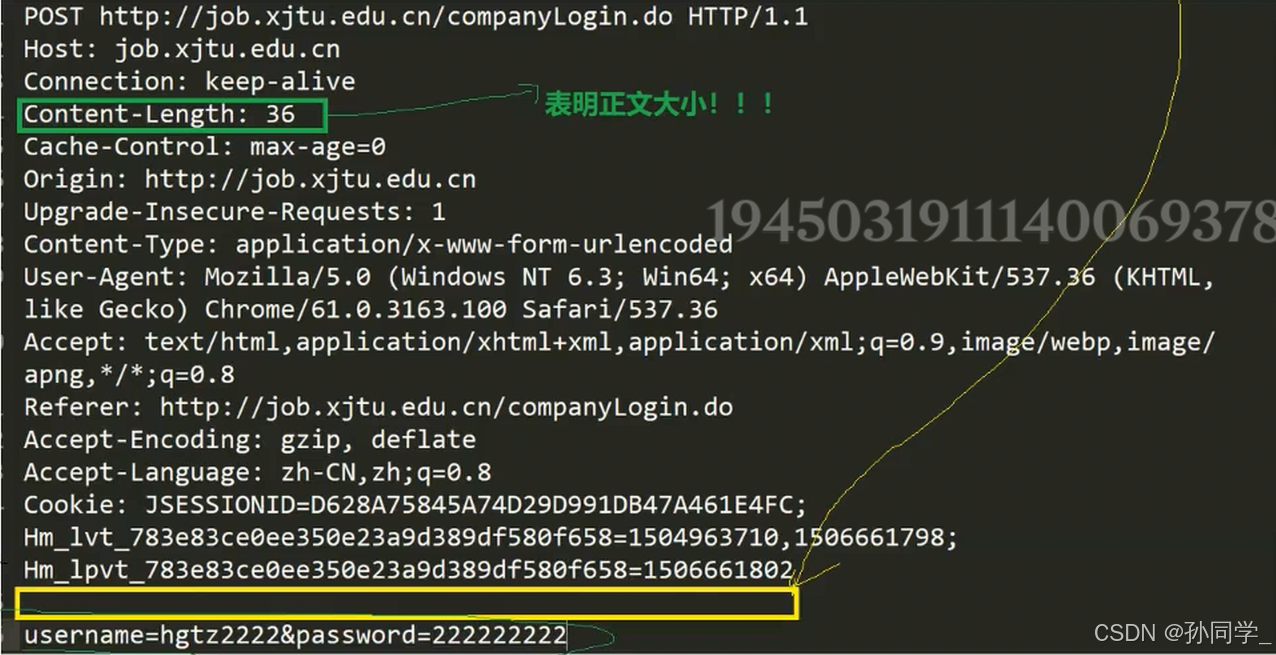
所以要读到完整请求需要两步:
- 读取到当前请求的完整报头
- 对报头进行反序列化,提取
Content-Lenth属性 - 再从剩余的字符串中。在空行以下提取
Content-Lenth个字符,就能读到一个完整报文了
client && server 如何保证自己读到的报文是完整的?
1.读取字节流,分析我们读到的字节流,确认是否存在空行。
2.提取Content-Lenth获取正文部分的长度,再截取指定长度的内容。
Content-Type
一张网页可能包含多种资源,比如网页自己还有图片,那么浏览器再获得网页的时候,会分析网页中的标签,如果识别到网页中还有其他资源的时候,还会发起二次请求。在发起二次请求的时候,应答得告诉接收方,我的有效载荷是什么类型的Content-Type
一键快速查看
HTTP应答

- 状态行:协议版本,状态码 ,状态描述
- 响应头:服务器喜喜,缓存机制,内容类型(Content-Type)
- 空行。
- 响应体:返回给客户端的HTML,图片或JSON数据
常见的请求方法
| 方法 | 描述 | 是否幂等 | 常见用途 |
|---|---|---|---|
| GET | 获取资源 | 是 | 浏览网页,查询数据 |
| POST | 提交数据 | 否 | 注册登陆,上传文件 |
| PUT | 更新资源 | 是 | 修改用户信息 |
| DELETE | 删除资源 | 是 | 删除某条评论 |
| HEAD | 只获取报文首部 | 是 | 检查资源是否存在/更新时间 |
什么是幂等?
简单理解就是:同一个操作一次执行一次和执行多次,对系统产生的副作用是一样的。GET是幂等的,而POST不是(连点两次提交可能会产生两个订单)
状态码
状态码是服务器给客户端的回信,第一位数字决定了信息的性质:
- 1xx(信息):请求已接收,继续处理。
- 2xx(成功) :代表请求已被成功接收(如200 OK)
- 3xx(重定向):需要进一步操作(如301永久重定向 302临时重定向 304缓存命中)
- 4xx(客户端错误):请求有语法错误或者请求不存在(如403没权限,404找不到对应的资源)
- 5xx(服务器错误):服务器在处理请求时出错了(如500内部错误 ,502网关错误)
HTTP vs HTTPS
HTTPS并不是一个新的协议,而是 HTTP + SSL/TLS。
- 加密:内容经过加密,中间人无法监听。
- 数据完整性:防止内容中途被篡改。
- 身份验证:通过CA证书确认你访问的真的是目标网站。
👍 如果对你有帮助,欢迎:
- 点赞 ⭐️
- 收藏 📌
- 关注 🔔