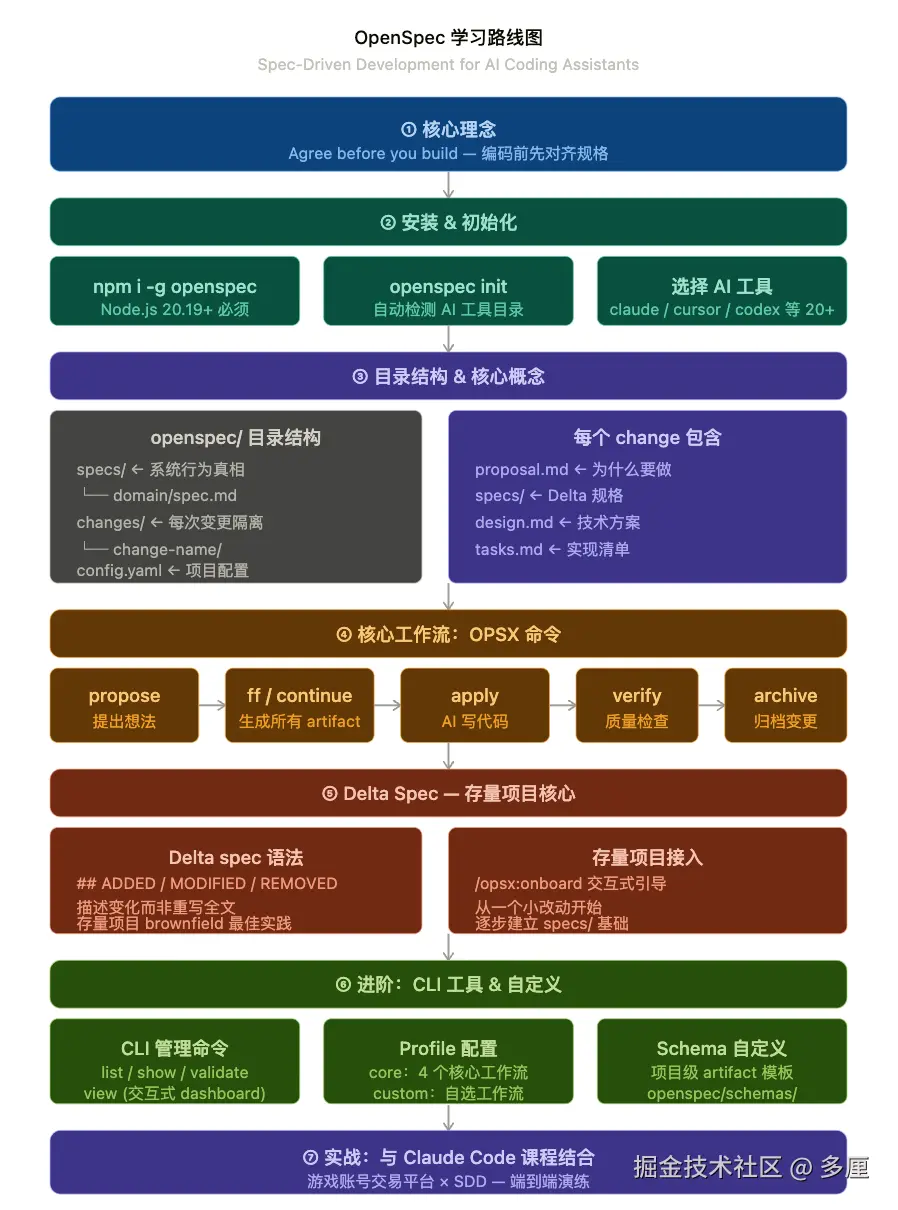
本文主要进行基础介绍, 完整分为如下 7 个文档
- OpenSpec 教程 : ① 核心理念 为什么要在写代码前先写 Spec
- OpenSpec 教程 : ② 安装 & 初始化
- OpenSpec 教程 : ③ 目录结构 & 核心概念
- OpenSpec 教程 : ④ 核心工作流:OPSX 命令
- OpenSpec 教程 : ⑤ Delta Spec --- 存量项目核心
- OpenSpec 教程 : ⑥ 进阶:CLI 工具 & 自定义
- OpenSpec 教程 : ⑦ 实战:与 Claude Code 结合 用 SDD 开发游戏账号交易平台的"账号估价"功能
介绍
Spec-driven development (SDD) ,专门为 AI 编程助手设计的规范驱动开发框架系。OpenSpec 的定位是在写代码之前,让人和 AI 先对齐 spec,然后按 spec 驱动实现, 它在你和 AI 之间加了一层轻量的 spec 层,让双方在写任何代码之前先对齐要构建什么。
它的哲学非常务实:流动而非僵化、迭代而非瀑布、轻量而非复杂、为 brownfield 而生而非只适合新项目。
你不会让建筑师在没有图纸的情况下建房子,写代码也是同样的道理。
OpenSpec 的本质定位
AI 编程助手很强大,但当需求只活在聊天记录里时会变得不可预测。OpenSpec 加了一层轻量的 spec 层,让你在写任何代码之前就先对齐要构建什么。
它的核心流程是:
bash
/opsx:new <feature>
→
/opsx:ff(生成 proposal + specs + design + tasks)
→
/opsx:apply(实现)
→
/opsx:archive/opsx:ff 这一步会生成四类文档:
proposal.md(做什么、为什么)specs/(需求与场景), 需求侧的最核心的产出design.md(技术方案)tasks.md(实现清单)
需求侧的应用方式
把 OpenSpec 当作需求-开发的桥接层,而不只是开发者的规划工具。具体有几种用法:
一、需求评审前用 /opsx:new 起草 proposal
产品或技术负责人在需求评审之前,用 /opsx:new <feature-name> 创建变更目录,然后手写或让 AI 生成 proposal.md,里面写清楚 why/what/scope。这份文档就可以直接作为评审材料,比传统 PRD 更结构化,而且后续可以直接被 AI 用于实现。
二、specs/ 目录承载业务验收标准
/opsx:ff 生成的 specs/ 目录可以放 Given-When-Then 格式的场景描述,需求侧人员(产品、测试)在这里添加或修改验收条件。开发拿到的不是模糊的需求文档,而是可执行场景------Claude Code 或 Cursor 等工具可以直接参照这些场景生成测试用例。
三、brownfield 场景特别适合
OpenSpec 是为 brownfield(已有项目)而不只是 greenfield 而构建的。 存量功能改造(比如重构 TradeStateMachine、升级订单状态流转逻辑)这类需求,用 /opsx:new refactor-trade-state-machine 生成 spec 之后,新旧行为的差异可以在 specs/ 里显式描述,避免 AI 改出意料之外的结果。
四、团队协作场景:spec 作为沟通媒介
每个变更都有自己的目录,包含 proposal、specs、design 和 tasks。 这个目录结构可以直接进 Git,前端、后端、测试、产品都能在同一份 spec 上做 review 和修改。需求的"契约"不再只存在于会议记录或文档里,而是跟代码共生在仓库中。
一个具体的落地建议
OpenSpec 完全可以作为"需求侧到实现侧"打通的案例来讲:
bash
需求评审(产品)
↓
/opsx:new feature-name(创建 spec 目录)
↓
/opsx:ff(AI 生成 proposal + specs + design + tasks)
↓
需求侧 review specs/(产品 + 测试确认场景)
↓
/opsx:apply(Claude Code 按 spec 实现)
↓
测试按 specs/ 验收
↓
/opsx:archive这个链路里,/opsx:ff 之后、/opsx:apply 之前的 review 阶段,就是需求侧介入最自然的节点。
需求驱动
一个经典的失控场景
你在做交易平台的订单状态重构。打开 Claude Code,输入:
帮我重构一下订单状态流转逻辑,现在状态太乱了Claude Code 开始工作。十分钟后,它改了 TradeStateMachine、顺手调整了 OrderServiceImpl、还把一个相关的枚举类重命名了。
改动方向大致对,但:状态流转的边界条件没有覆盖你想到的那个"买家超时未确认"场景;重命名破坏了另一个服务的引用;而你最想要的那个"状态变更日志"功能压根没出现。
问题出在哪?需求只活在聊天记录里。AI 没有办法知道你真正在意什么,只能根据你的一句话猜。
这就是 OpenSpec 要解决的问题。
核心工作流:以订单状态重构为例
我们用真实场景来走一遍完整流程。
第一步:创建变更
arduino
/opsx:new refactor-trade-state-machineClaude Code 会在 openspec/changes/refactor-trade-state-machine/ 下创建目录结构:
bash
openspec/changes/refactor-trade-state-machine/
├── proposal.md ← 为什么做这件事
├── design.md ← 技术方案
├── tasks.md ← 实现任务清单
└── specs/ ← 需求场景(最重要)
└── trade-order/
└── spec.md第二步:快进生成所有规划文档
bash
/opsx:ff这一条命令让 Claude Code 读取你的现有代码,然后生成四份文档。它会扫描 TradeStateMachine.java、OrderServiceImpl.java、相关的枚举和 DTO,理解当前系统状态,再根据变更名称推断意图。
生成的 specs/trade-order/spec.md 大概长这样:
markdown
# trade-order Specification
## Purpose
管理游戏账号交易订单的完整生命周期,包括状态流转、超时处理和异常回滚。
## Requirements
### Requirement: 状态流转完整性
系统 SHALL 保证订单状态只能按照预定路径流转。
#### Scenario: 买家超时未确认
- GIVEN 订单处于"待买家确认"状态
- WHEN 超过 48 小时买家未操作
- THEN 系统自动将订单标记为"超时关闭"
- AND 触发退款流程
- AND 发送 RocketMQ 消息通知卖家
#### Scenario: 支付成功后的状态推进
- GIVEN 买家已完成支付
- WHEN 收到支付回调
- THEN 订单状态从"待支付"变更为"交易中"
- AND 记录状态变更日志到 trade_state_log 表在 /opsx:apply 执行之前,你、产品、测试都可以直接 review 这份 spec.md。它写的是业务语言,不是代码。产品可以补充遗漏的场景,测试可以把验收条件直接写进去,技术负责人可以确认边界条件。
这份文件进 Git,就是可追溯的需求契约。
第三步:review 并修改 spec
直接编辑 specs/trade-order/spec.md,把你真正在意的场景补进去:
markdown
#### Scenario: 状态变更审计日志
- GIVEN 任意订单状态发生变更
- WHEN 状态流转执行
- THEN 向 trade_state_log 表写入一条记录
- AND 记录字段包含:操作人、原状态、新状态、时间戳、触发原因这个补充动作不需要任何工具,就是写 Markdown。但它会在下一步直接影响 Claude Code 的实现行为。
第四步:按 spec 实现
bash
/opsx:applyClaude Code 读取 specs/ 里的所有场景,逐条执行 tasks.md 里的任务。每个任务完成后打勾,你可以看到实现进度。
因为 spec 里明确写了"记录 trade_state_log",Claude Code 会自动生成对应的实体类、Mapper、以及在状态流转节点插入日志的代码------而不是像之前那样只改了状态机本身就停下来。
第五步:归档
bash
/opsx:archive变更目录移入 openspec/changes/archive/,同时 openspec/specs/trade-order/spec.md 被更新为最新的系统状态描述。这就是持久化的上下文:spec 和代码共同生活在仓库里,不会因为聊天窗口关闭而消失。
长期价值
随着功能迭代,openspec/specs/ 会逐渐积累成这样的结构:
sql
openspec/specs/
├── trade-order/ ← 订单状态与生命周期
├── account-publish/ ← 账号发布审核流程
├── payment-callback/ ← 支付回调处理
├── recommend-feed/ ← 推荐流逻辑
└── user-auth/ ← 登录与权限新人加入团队,读这个目录比读代码快得多------这里写的是系统"应该做什么",而不是"当前怎么做的"。
下一次做相关功能时,Claude Code 启动就会读取已有的 spec,理解系统约束,不会提出跟现有逻辑冲突的方案。
与 CLAUDE.md 的协同
OpenSpec 和 CLAUDE.md 是互补的:
- CLAUDE.md 定义的是项目级的永久约束:技术栈、代码规范、禁止行为
- OpenSpec specs/ 定义的是功能级的业务契约:每个能力应该做什么
在 CLAUDE.md 里加一行引用,就能让每次对话都自动感知 spec:
bash
## 业务规范
项目的功能规范定义在 openspec/specs/ 目录下。
在实现任何涉及订单、账号、支付的功能前,先读取对应的 spec.md 文件。这样即使不用 /opsx: 命令,Claude Code 在日常对话里也会主动参考 spec 的约束。
给团队的建议
需求侧介入的最佳节点只有一个:/opsx:ff 之后、/opsx:apply 之前。
整个需求到实现的链路可以这样分工:
开发用 /opsx:new 和 /opsx:ff 生成 spec 草稿,产品在 specs/ 里确认业务场景并补充遗漏的边界条件,测试把验收标准直接写成 Given-When-Then 格式追加进去,然后提 PR review 这份 spec------通过之后才执行 /opsx:apply。
这个流程的改变是:需求评审的对象从 PRD 文档变成了 spec 文件,而 spec 文件直接就是 AI 的执行上下文。中间没有"翻译"环节,需求损耗降到最低。
需求生成
OpenSpec 官方 FAQ 的回应是:他们在探索从现有代码库生成 spec 的能力,但观点是"试图一次性预先生成所有 spec 是浪费时间,应该按需创建并逐步积累"。
这不是在回避问题,而是真实的工程判断------对一个几万行的 brownfield 项目,一次性逆向出完整 spec 噪音极大,你很难 review,也很难信任。
但这并不意味着"不能从代码生成",只是方式不同。目前有三条路。
/opsx:onboard(官方推荐入口)
对于已有项目,/opsx:onboard 命令会从你的代码库生成初始 spec,让 AI 从第一天就有项目上下文可以参考。
这是官方为 brownfield 场景设计的入口,它会扫描现有代码、理解项目结构,然后为核心能力生成初始 openspec/specs/ 文件。不是全量逆向,而是生成一个"够用的起点"。
在你的交易平台上执行这条命令,Claude Code 会读取 TradeStateMachine、GameAccountServiceImpl、支付回调相关代码,为每个主要能力域生成一份 spec 草稿,你再做 review 和修正。
/opsx:onboard 被归入了"expanded workflow",默认安装的 core profile 只包含四条命令:propose、explore、apply、archive。如果你想用 onboard,需要手动切换 profile 并更新。
具体操作:
bash
openspec config profile # 选择 expanded(包含 onboard)
openspec update # 把新命令写入项目之后 /opsx:onboard 就可以用了。
onboard 现在的实际功能
它是"引导式 onboarding",流程是:扫描代码库找改进机会,让你选一个小功能,走一遍完整的 propose → apply → archive 流程,大约 15 分钟。
注意这里有个认知偏差 需要纠正:我们之前讨论的"从代码生成 spec 基线",/opsx:onboard 做的其实不是这件事------它的设计目的是教新用户用 OpenSpec ,顺带扫一眼代码库找个练手素材,而不是系统性地逆向生成 openspec/specs/ 目录。
那 brownfield 冷启动怎么办, 手动引导
官方的态度是:一次性预先生成所有 spec 是浪费时间,应该按需创建、边建边积累。
所以对你的平台,最实际的策略还是之前说的那条路------直接对 Claude Code 下指令,按模块逐个生成:
bash
请读取 src/trade/ 目录的代码,
按照 openspec/specs/<capability>/spec.md 的格式,
为订单状态管理这个能力域生成一份 spec,
要求:
- 用 Given-When-Then 格式描述每个业务场景
- 只描述当前代码实际实现的行为,不要发明需求
- 按 Requirement → Scenario 层级组织
- 输出到 openspec/specs/trade-order/spec.md一次一个模块,半天建起基线,比跑一个工具然后 review 几百行自动生成内容要可控
这种方式的优点是:你控制粒度(一次只做一个模块)、你可以在 prompt 里注入业务语言约束、生成结果可以立即 review。
对于你们的 Spring Boot 项目,可以按服务边界逐个来:先 trade-order,再 account-publish,再 payment-callback,每次生成后 review 确认,整个过程大概半天能建立起有效的 spec 基线。
spec-gen(社区工具,专门做逆向)
当前官方不推荐, 原因是分析出来的内容噪音比较大
社区里有人专门构建了 spec-gen,一个开源 CLI 工具,通过静态分析结合 LLM 从现有代码库逆向工程出 OpenSpec 兼容的 spec
它的三步流程是:
spec-gen init(检测项目类型、创建配置)spec-gen analyze(静态分析,不需要 API Key)spec-gen generate(生成 OpenSpec 格式的 spec)。