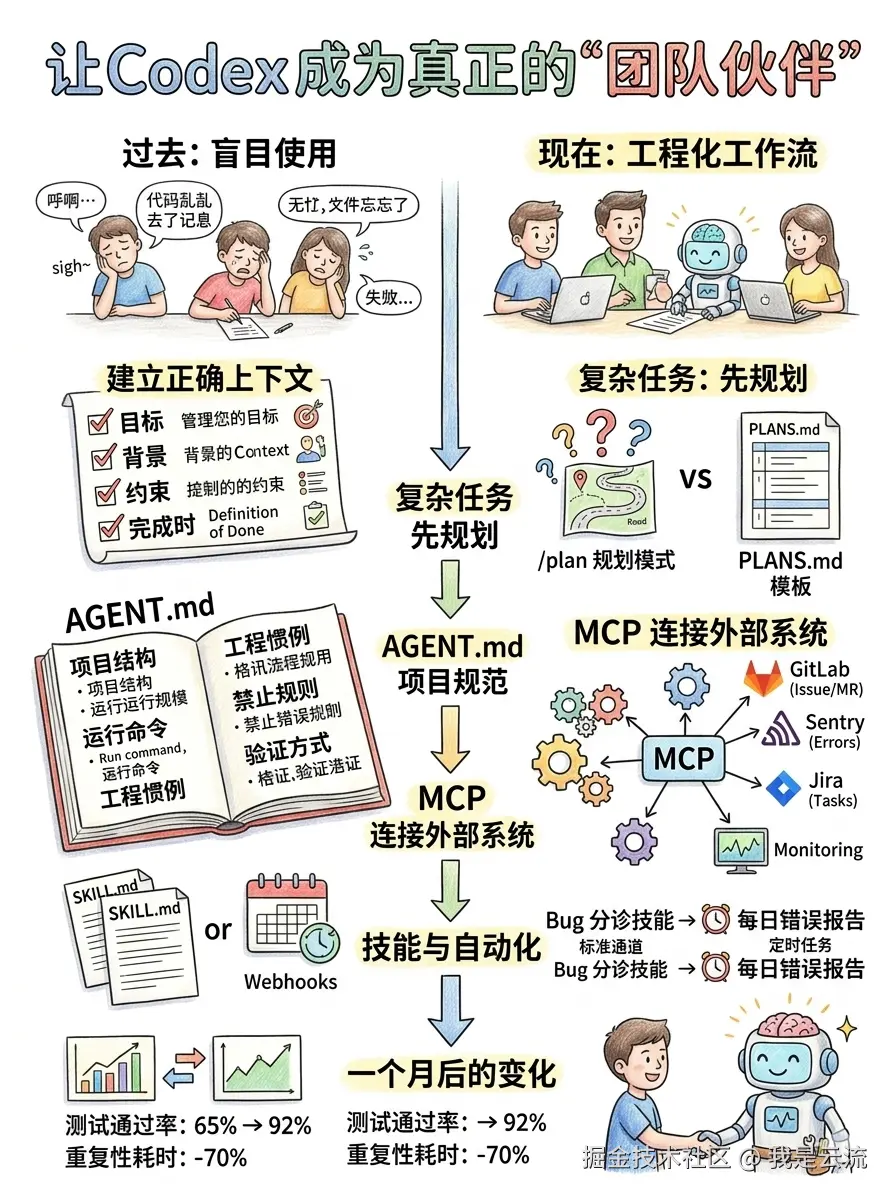
上周五的复盘会上,明镜(测试工程师) 对着大屏幕叹气:"这周我们让Codex帮忙改了13个功能,结果5个在测试时发现了明显问题,3个的代码风格和我们团队规范不符。"
闪电(全栈工程师) 也抱怨:"每次让Codex干活,我都要花半天时间描述上下文:项目结构、技术栈、规范、测试方法......说漏了它就瞎搞。"
我(云流,全栈组长) 看着统计数字,意识到问题所在:我们都在"用"Codex,但没"用好"Codex。我们把它当成一个"更聪明的ChatGPT",而不是能融入团队工作流的"协作者"。
"从今天起,"我在白板上写下标题,"我们要建立一套Codex的工程化工作流。"
一、原则:从正确的任务上下文开始
"首先,我们给Codex的任务描述要规范。"我说,"一个合理的任务上下文包含四件事:"
markdown
目标:要改变或构建什么
背景:涉及哪些文件、目录、示例
约束:要遵循的标准、规范、安全要求
完成时:任务完成前要满足的条件 "比如,以前我们这样说:'帮我把这个组件改成TypeScript。'" "现在要这样说:"
markdown
目标:将UserProfile.vue组件从JavaScript重写为TypeScript
背景:`@components/UserProfile.vue`,参考`@components/Button.vue`的类型写法
约束:使用团队TypeScript规范,添加必要的interface定义
完成时:通过单元测试,无类型错误,通过ESLint检查"这样Codex就能保持范围明确,减少假设,生成容易审查的工作。"
二、复杂任务:先规划,再编码
"对于复杂任务,不要直接让Codex开干。"我说,"先让它规划。"
2.1 规划模式
"在对话框输入 /plan 或按 Shift + Tab,切换到规划模式。让Codex先收集上下文、提澄清问题、制定计划。" 我演示给Codex下达任务:"重构搜索服务的缓存层"。 切换到规划模式后,Codex先提问:
markdown
当前缓存层的实现是什么?Redis还是内存缓存?
缓存策略是什么?TTL设置多久?
有哪些依赖服务会受影响?
测试覆盖率要求多少?
重构期间要保证服务可用吗?"回答了这些问题,Codex再给出详细的重构计划,比直接动手更可靠。"
2.2 PLANS.md模板
"对于长期或多步骤工作,可以用PLANS.md模板。"我创建了一个模板文件:
markdown
# 项目计划模板
## 目标
[明确要达成的目标]
## 背景
[相关文件、上下文、限制条件]
## 阶段划分
1. 调研阶段
1.1 输入:@相关文档
1.2 输出:技术方案文档
2. 实现阶段
2.1 输入:@代码库
2.2 输出:可运行代码
3. 测试阶段
3.1 输入:测试用例
3.2 输出:测试报告
4. 部署阶段
4.1 输入:部署配置
4.2 输出:上线验证
## 完成标准
[满足什么条件算完成]"让Codex遵循这个模板,复杂任务也能拆解清楚。"
三、AGENT.md:团队的"编码规范说明书"
"但每次都要重复描述上下文,太累了。"闪电说。 "对。所以我们需要AGENT.md。"我解释,"把它看成团队的README,告诉Codex'在这个项目里该怎么干活'。" 我在项目根目录创建 AGENT.md:
markdown
# 某前端项目规范
## 项目结构
- `/src/components/` 通用组件
- `/src/views/` 页面组件
- `/src/utils/` 工具函数
- `/tests/` 测试文件
## 运行命令
- 开发:`npm run dev`
- 测试:`npm test` (运行所有测试)
- 构建:`npm run build`
- 代码检查:`npm run lint`
## 工程惯例
- 使用TypeScript,严格模式
- Vue组件使用Composition API
- CSS使用Tailwind,不写行内样式
- 单个函数不超过50行
- 必须包含完善的错误处理
## 禁止规则
- 不要使用 `any` 类型
- 不要使用 `document.querySelector` 直接操作DOM
- 不要硬编码配置,统一使用环境变量
- 不要提交未格式化的代码
## 如何验证工作
- 通过所有单元测试
- 通过ESLint检查
- 无TypeScript错误
- 手动测试核心流程"创建后,Codex会自动读取这个文件,知道我们的规范。"我说,"不用每次重复了。"
闪电:"那不同项目规范不一样怎么办?"
"可以在不同层级创建AGENT.md。"我说,"比如在 ~/.codex/ 放全局默认规范,在项目根目录放项目级规范,在子目录放更具体的规则。"
我在终端演示:
bash
# 快速创建规范模板
codex /init"这会在当前目录创建 AGENT.md 模板。但记住:简短准确的规则比冗长的模糊规则有用。从基础开始,发现问题再补充。"
四、配置一致性:让Codex行为可预测
"下一个问题:Codex在不同会话中行为不一致。"明镜说,"有时调用大模型,有时调用小模型,生成的代码质量波动大。"
"用配置解决。"我打开 ~/.codex/config.toml,"在这里定义持久性偏好:"
toml
[general]
model = "claude-3-5-sonnet" # 默认使用高智能推理模型
effort = "high" # 推理努力程度
sandbox = "strict" # 沙盒模式严格限制
approval = "on-request" # 按需授权
[features]
autocomplete = true
inline_diff = true"项目特定配置放 .codex/config.toml。"我在项目里创建:
toml
[project]
name = "starflow-admin"
default_branch = "main"
test_command = "npm test"
build_command = "npm run build"
[mcp]
servers = ["gitlab", "sentry", "jira"]"这样,Codex在这个项目里就知道:默认分支是main,测试命令是npm test,且能自动连接GitLab、Sentry、Jira。"
五、沙盒模式:安全第一
"关于权限,"我强调,"新手从默认开始,保持审批和沙盒严格限制。只在明确需要时,放宽对可信仓库的权限。"
我演示三种模式:
bash
# 严格模式(推荐新手)
codex --sandbox=strict --approval=always
# 按需授权(我用的)
codex --sandbox=on-write --approval=on-request
# 全自动(高风险,请勿在生产环境使用)
codex --sandbox=off --approval=auto # 危险!"我们团队用第二种:写入文件时请求授权,运行命令时请求确认。安全可控。"
六、测试和审查:不只要代码,要可靠的代码
"Codex不应该只生成代码,"我说,"还要能测试、检查、审查代码。" "比如,让Codex写完功能后,自动进行以下流程:"
markdown
- 编写或更新测试
- 运行测试套件
- 检查代码风格、格式、类型
- 确认行为符合要求
- 审查差异找问题"用 /review 命令。"我演示:
bash
# 交互式界面或CLI中审查未提交的变更
/review uncommitted
# 与main分支比较差异
/review diff main
# 自定义审查规则
/review custom "检查性能问题和安全漏洞""如果我们有 code_review.md 文件,Codex会遵循里面的审查规则。"我创建了文件:
markdown
# 代码审查清单
## 安全性
- [ ] 无硬编码密钥/Token
- [ ] 外部输入有参数验证
- [ ] 针对动态查询有防注入处理
- [ ] 错误日志不泄露敏感个人信息
## 性能
- [ ] 无N+1查询问题
- [ ] 大列表组件使用分页或虚拟滚动
- [ ] 图片与重资源有懒加载机制
- [ ] 重复的API响应有缓存处理
## 可维护性
- [ ] 函数符合单一职责原则
- [ ] 核心复杂逻辑有清晰的注释说明
- [ ] TypeScript类型定义完整,避免隐式转换
- [ ] 异常与错误捕获边界完善"Codex审查时会对照这个清单,给出结构化反馈。"
七、MCP:连接外部系统,避免复制粘贴
"当Codex需要仓库外的信息时,"我说,"比如查看GitLab的Issue、Sentry的错误、Jira的任务,用MCP(模型上下文协议)。" 我在Codex设置里添加MCP服务器:
markdown
- GitLab连接器:查看Issue、MR、CI状态
- Sentry连接器:读取错误日志、性能数据
- Jira连接器:查看任务、状态、优先级
- 监控连接器:查看服务指标、告警"以前,墨鱼要手动复制Jira任务描述给Codex。现在,Codex直接读取Jira:"
markdown
@Jira 查看任务PROJ-123,为这个功能编写前端组件"Codex自动读取任务详情、验收标准、相关文档,基于完整上下文工作。"
"注意:不要一开始就接入所有工具。"我提醒,"从能明显消除手动环节的一两个开始。比如我们先接GitLab和Sentry,因为这是最频繁的。"
八、技能:将重复工作标准化
"一旦某个工作流可重复,就不要再依赖长提示。"我说,"用SKILL.md文件把它标准化。" 我创建了第一个技能 .agents/skills/bug_triage.md:
markdown
# Bug分诊技能
## 描述
当收到Sentry错误报告时,自动分析错误、定位原因、给出修复建议。
## 触发短语
- "分诊这个bug"
- "分析这个错误"
- "看看这个Sentry报告"
## 输入
Sentry错误ID或错误堆栈
## 执行步骤
- 通过MCP读取Sentry错误详情
- 分析错误堆栈,定位到具体文件和代码行
- 查看最近相关的代码提交记录(Git Log)
- 检查是否为回归问题
- 给出修复建议和优先级
## 输出格式
- 错误原因分析:[描述]
- 影响范围评估:[描述]
- 修复方案建议:[代码或逻辑建议]
- 优先级:(P0/P1/P2/P3)"现在,收到Sentry告警时,我只需说:'分诊这个bug,错误ID是abc123'。Codex自动执行完整流程。"
闪电:"哪些工作适合做成技能?"
"你反复用相同提示的工作。"我举例,"比如:日志分类、发布说明撰写、PR审查、迁移规划、错误摘要、标准调试流程。"
"用 /skill-creator 交互命令创建第一个版本。"我演示,"告诉它:'创建一个技能,用于自动生成TypeScript接口定义。' Codex会生成技能模板,我们优化即可。"
"个人技能放 ~/.agents/skills/,团队共享技能提交到 .agents/skills/。"我说,"这对新人特别有用:一来就有标准工作流程。"
九、自动化:安排重复工作在后台运行
"技能定义方法,自动化定义计划。"我解释,"一旦工作流稳定可预测,就可以安排它定时运行。" 我在Codex应用的"自动化"标签页创建了几个自动化任务:
markdown
- 每日错误报告
- 项目:所有前端项目
- 提示:"总结过去24小时的Sentry错误,按频率排序"
- 节奏:每天 9:00
- 环境:Git工作树
- 输出:发送到飞书技术群
- 代码质量检查
- 项目:当前迭代分支
- 提示:"运行代码审查技能,检查性能和安全问题"
- 节奏:每次代码提交后(Webhook触发)
- 环境:CI环境
- 输出:自动评论到GitLab MR
- 站立会摘要
- 项目:Jira看板
- 提示:"总结团队昨日进展、今日计划、阻塞问题"
- 节奏:每天 10:30
- 环境:本地
- 输出:发送到站立会频道"合适的自动化候选:"我列举,"总结最近提交、扫描可能错误、起草发布说明、检查CI失败、生成站立会摘要、定期运行分析。"
"记住:自动化是乘数效应。先手动做,稳定了再自动化。"
十、会话控制:组织长期工作
"Codex会话不只是聊天历史,"我说,"它们是随时间积累的工作线程。好的管理对质量很重要。"
我分享管理技巧:
10.1 为每个任务保持独立线程
"不要所有工作在一个线程。每个功能、每个bug修复、每个重构,单独建立线程,避免上下文膨胀污染模型记忆。"
10.2 使用子代理(Sub-Agent)分担工作
"主代理专注于核心架构与主流程,用子代理执行具体的探索、测试、分诊工作。"
bash
# 在聊天交互中创建子代理处理测试
/agent create --name tester --task "为这个功能编写测试用例"
# 任务完成后返回主代理
/agent main10.3 有用的斜杠命令
bash
/resume 会话名 # 继续保存的特定对话
/fork # 从当前位置创建新线程,保留原始记录以进行分支尝试
/compact # 压缩过长对话的历史上下文(Codex通常会自动管理)
/status # 检查当前会话加载的AGENT.md和MCP状态10.5 利用 Git 工作树(Worktree)避免冲突
"如果多人在同一项目用Codex,或者你自己在多任务并行,用Git工作树避免文件冲突:"
bash
codex --worktree feature/xxx十一、常见错误和解决方案
最后,我总结了团队常见的错误:
11.1 用提示重载持久规则 ❌
✅ 正解:不要每次都在提示里写重复的规范。移入 AGENT.md 或自动化技能中。
11.2 不让Codex看到如何运行项目 ❌
✅ 正解:必须在 AGENT.md 里写明构建、测试命令。Codex需要知道如何自行运行并验证工作。
11.3 跳过复杂任务的规划 ❌
✅ 正解:强制使用规划模式(/plan)或 PLANS.md。先想清楚整体设计,再动手编码。
11.4 一开始就授予完全权限 ❌
✅ 正解:严格从沙盒隔离权限开始,根据信任度逐步放宽。安全永远是第一位的。
11.5 在同一份活跃文件上运行多个长线程 ❌
✅ 正解:结合 Git 工作树或独立分支隔离不同任务的上下文。
11.6 手动流程不稳定就盲目自动化 ❌
✅ 正解:必须先保证手动触发时流程稳定、结果可预测,再配置定时或钩子自动化。不稳定的自动化是灾难。
11.7 把Codex当成需要步步监控的死板工具 ❌
✅ 正解:让它与你的工作异步并行。你负责顶层设计与审查,它负责批量实现与修改。
11.8 每个项目只用一个线程执行所有迭代 ❌
✅ 正解:坚持"每个独立任务(Ticket/Issue)一个线程",防止过期的历史上下文导致模型智商下降。
十二、一个月后的变化
一个月后,明镜在周会上展示数据:
- Codex生成代码的测试通过率:从 65% 提升到 92%
- 代码审查阶段发现的低级问题数:减少 40%
- 重复性工程模板与样板代码耗时:减少 70%
- 新人熟悉项目规范与上手时间:从 2周 缩短到 3天
- 团队整体代码规范一致性:显著提升
闪电说:"现在给Codex任务,我知道它会产出什么样的代码。可预测、可审查、符合规范。"
墨鱼说:"任务描述标准化后,产品需求和代码实现的偏差减少了。"
最好的工具,不是功能最多的,而是能融入团队工作流、提升整体效率的。Codex对我们来说,不再是一个"AI玩具",而是一个理解团队规范、遵循工程标准、能可靠协作的"团队伙伴"。
而工程化的本质,不就是把偶然的成功,变成必然的流程吗?
(云流,于Codex工程化工作流落地一个月后的复盘会。)