基于贝叶斯优化的稀疏高斯过程回归(BO-SGPR)多输入单输出回归模型【MATLAB】
在处理复杂的非线性回归、小样本学习以及带有不确定性量化的预测任务时,高斯过程回归(Gaussian Process Regression, GPR) 因其强大的理论基础和概率预测能力而备受青睐。然而,传统GPR的计算复杂度随样本量的立方呈指数级增加(O(N3)\mathcal{O}(N^3)O(N3)),这使得它在处理大规模数据集时往往面临计算耗时、内存溢出等挑战。
为了解决这一计算瓶颈,本文将介绍一种高效的进阶结构------稀疏高斯过程回归(Sparse Gaussian Process Regression, SGPR) ,并展示如何结合贝叶斯优化(Bayesian Optimization, BO) 在MATLAB中实现多输入单输出的高精度回归预测。
一、什么是稀疏高斯过程回归(SGPR)?
传统GPR需要对整个训练集的协方差矩阵进行求逆运算。而SGPR通过引入**"诱导点"(Inducing Points / Active Set)**,将原有的连续高斯过程进行近似降维。
简单来说,它就像是在海量数据中挑选出少量极具代表性的"精英点",利用这些点来近似整个数据集的信息。通过这种近似方法,SGPR将计算复杂度从 O(N3)\mathcal{O}(N^3)O(N3) 大幅降低至 O(NM2)\mathcal{O}(NM^2)O(NM2)(其中 MMM 为诱导点数量,NNN 为总样本量),从而实现了计算速度和内存消耗的大幅优化。
二、 为什么需要贝叶斯优化(BO)?
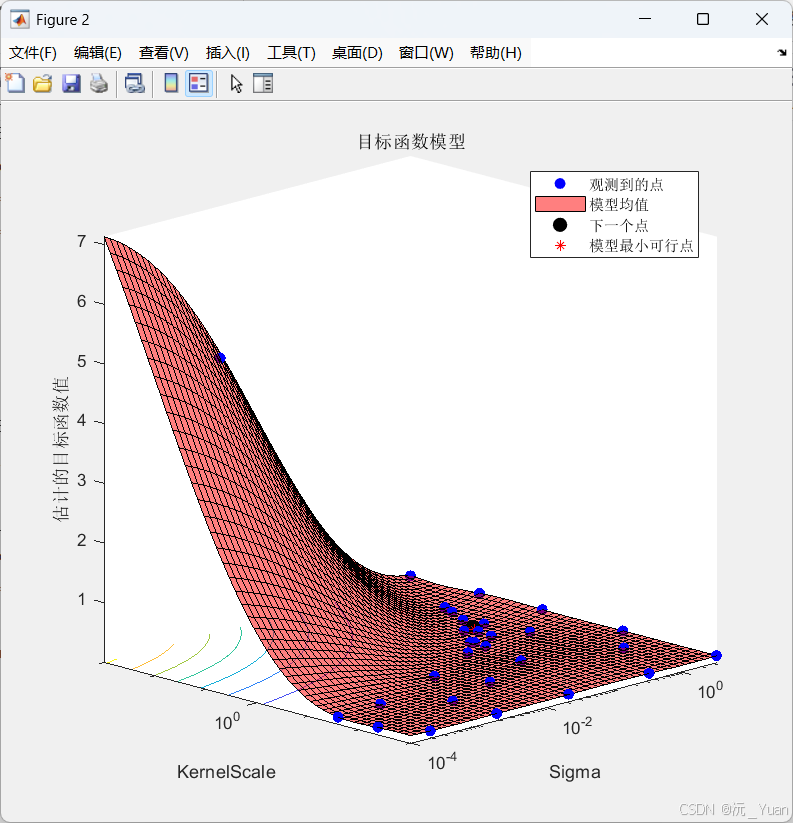
GPR模型的性能高度依赖于核函数参数(Kernel Scale) 和 噪声标准差(Sigma) 等超参数。传统的手动调参(试错法)或网格搜索不仅耗时费力,而且在连续参数空间中极易陷入局部最优。
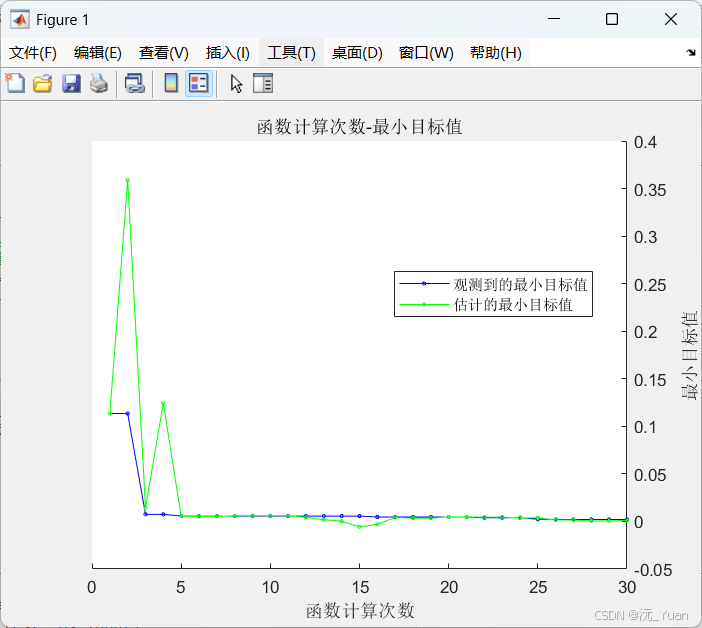
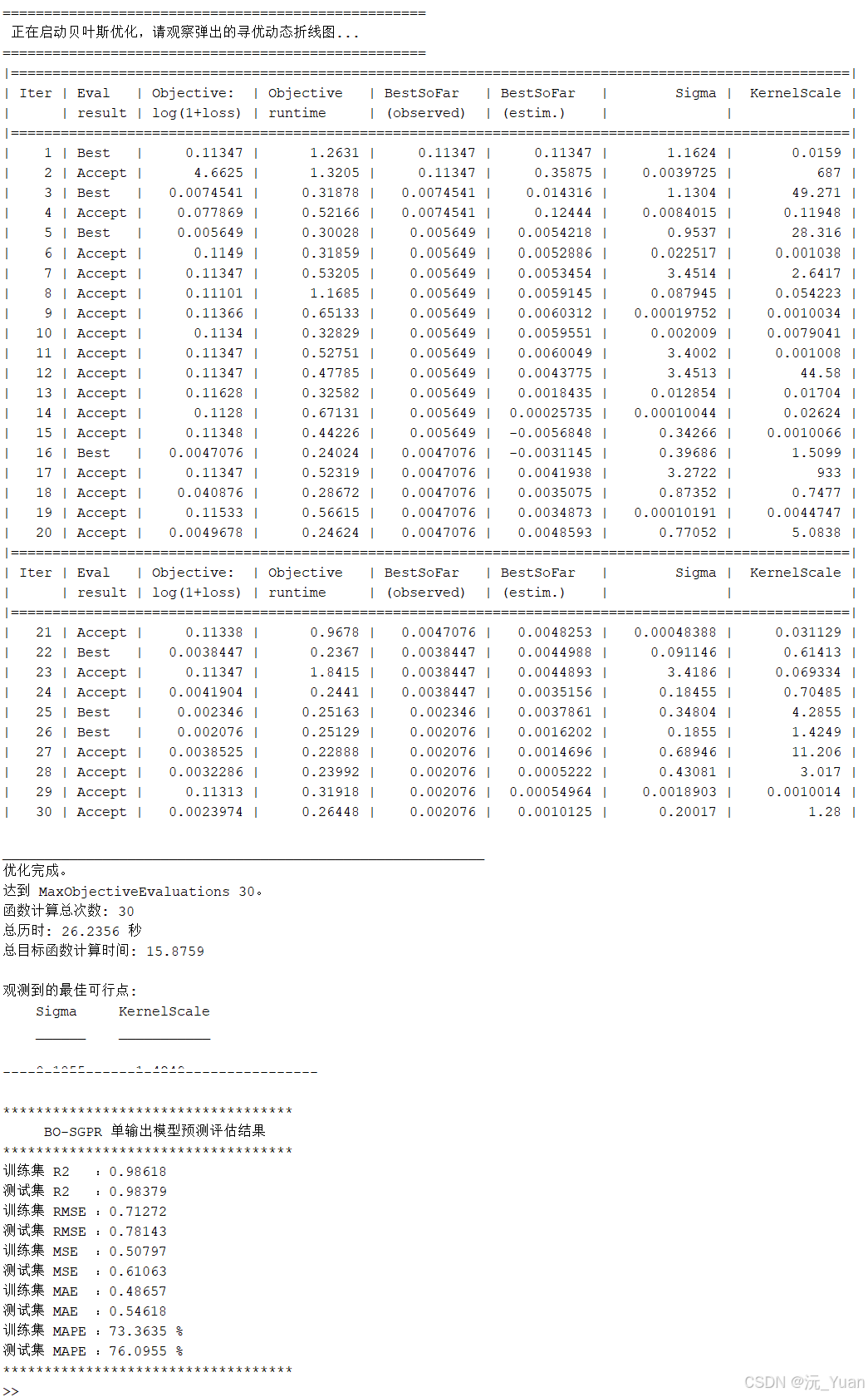
贝叶斯优化是一种高效的全局优化算法。它能够根据以往的评估结果构建高斯过程代理模型(Surrogate Model),并利用采集函数(如"期望改进 EI")智能地探索未知的参数空间。在MATLAB中结合BO,我们只需设定搜索范围,算法即可实现超参数的"傻瓜式"自动精准寻优,真正做到性能最大化。
三、BO-SGPR 的工作流程
实现一个典型的BO-SGPR多输入单输出预测模型,通常包含以下几个关键步骤:
- 数据准备与划分:导入多维特征矩阵与单列目标标签,按比例(如7:3)随机划分为训练集和测试集。
- 数据归一化 :利用
mapminmax将输入和输出均缩放至 0,10, 10,1 区间,消除量纲差异,加速模型收敛。 - 设置贝叶斯优化参数:配置寻优迭代次数、采集函数形式,并开启实时动态观测窗口。
- 训练SGPR模型 :调用
fitrgp函数,指定核函数类型(如平方指数核squaredexponential),设置FitMethod为sr(子集回归),同时传入诱导点规模和优化配置。 - 模型预测与反归一化:使用训练好的模型对测试集数据进行前向预测,并将输出结果反向还原为真实的物理量级。
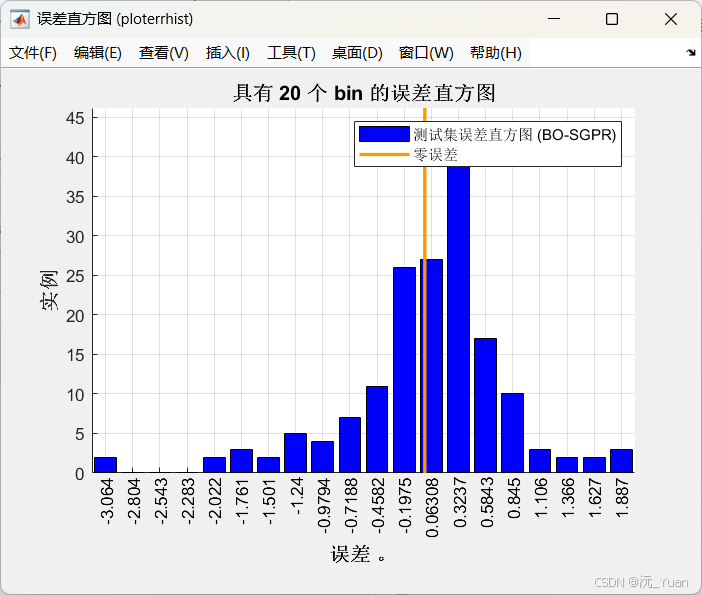
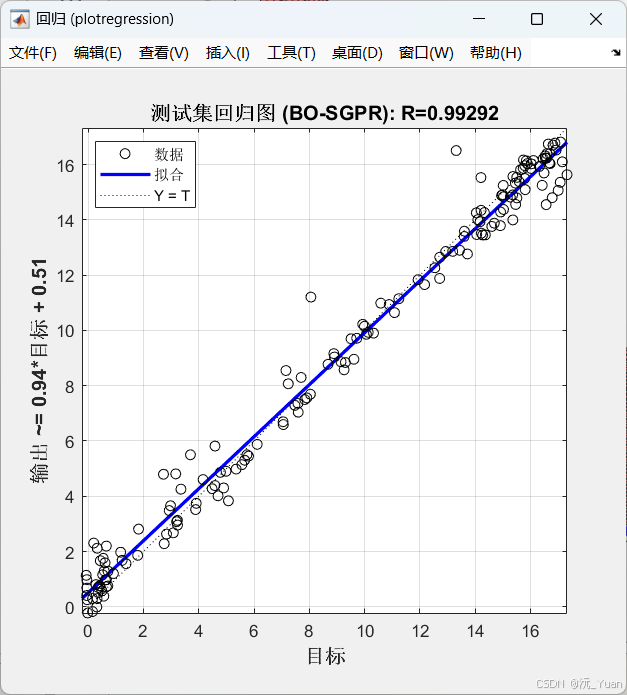
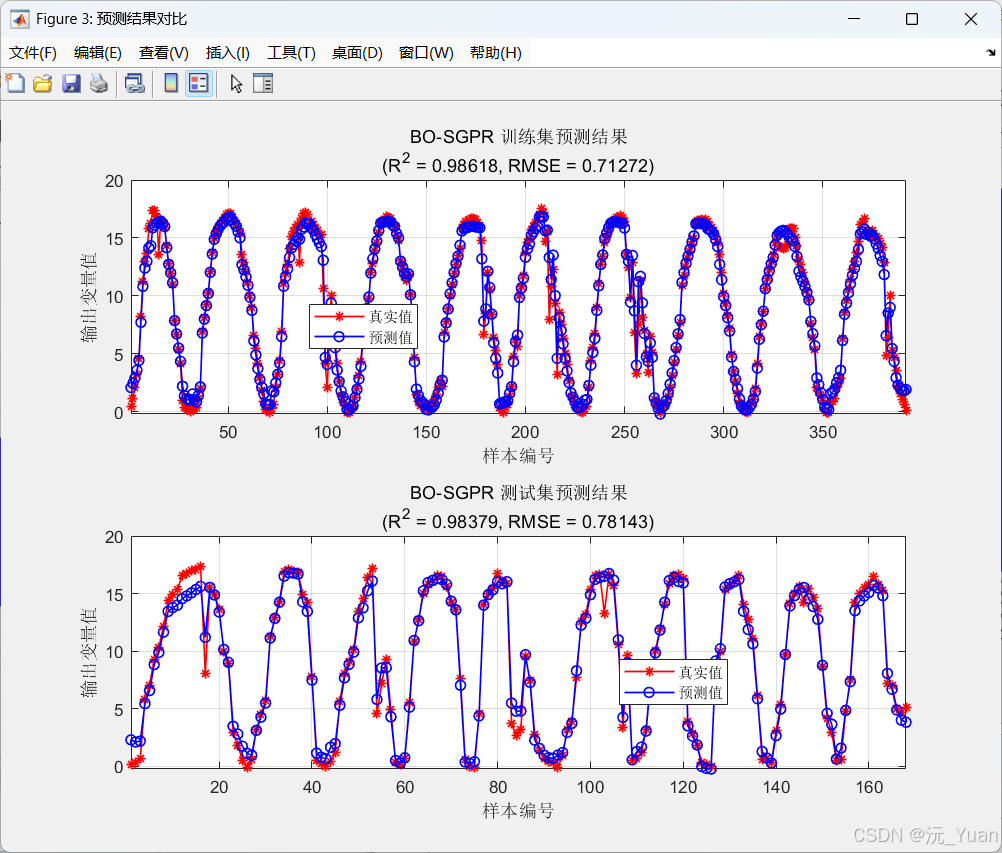
- 误差评估:计算预测值与真实值之间的 MAE、MAPE、MSE、RMSE 和 R² (决定系数) 等指标,全方位评估预测精度。
四、MATLAB 实现代码
下面是结合了上述完整工作流的MATLAB部分代码:
c
clc
clear all
close all
rng('default');
%% 1. 导入数据
% 请确保当前路径下存在 data.xlsx 文件,且最后一列为输出目标值
res = xlsread('data.xlsx');
num_samples = size(res, 1); % 样本总个数
num_size = 0.7; % 训练集占数据集比例
outdim = 1; % 最后一列为输出
num_train_s = round(num_size * num_samples); % 训练集样本个数
L = size(res, 2) - outdim; % 输入特征维度
X = res(1:end, 1:L)';
Y = res(1:end, L+1:end)';
%% 2. 数据划分
[trainInd,valInd,testInd] = dividerand(size(res,1), 0.7, 0, 0.3); % 随机划分训练集与测试集
P_train = X(:,trainInd);
T_train = Y(:,trainInd);
P_test = X(:,testInd);
T_test = Y(:,testInd);
M = size(P_train, 2);
N = size(P_test, 2);
%% 3. 数据归一化
[p_train, ps_input] = mapminmax(P_train, 0, 1);
p_test = mapminmax('apply', P_test, ps_input);
[t_train_norm, ps_output] = mapminmax(T_train, 0, 1);
t_test_norm = mapminmax('apply', T_test, ps_output);
p_train = p_train';
p_test = p_test';
t_train_norm = t_train_norm';五、运行结果