在多媒体信息安全领域,图像隐写一直是一个兼具理论深度与应用价值的重要研究方向。近年来,随着深度学习的发展,隐写方法逐渐从传统的像素级嵌入(如LSB、DCT、DWT)演进到基于神经网络的隐写模型,再到当前快速兴起的生成模型与扩散模型隐写。
这篇发表于 CVPR 2025 的工作 "Robust Message Embedding via Attention Flow-Based Steganography" 提供了一个非常有意思的思路,它尝试将可逆流模型 + Attention机制 + 二维码结构化表示结合起来,为鲁棒隐写提供了一种新的范式。
一、从扩散隐写说起:问题到底出在哪里?
近年来,扩散模型(Diffusion Models)在图像生成领域取得了巨大成功,例如 Stable Diffusion 等模型已经可以生成高度逼真的图像。这种能力也被自然地引入到了隐写领域。
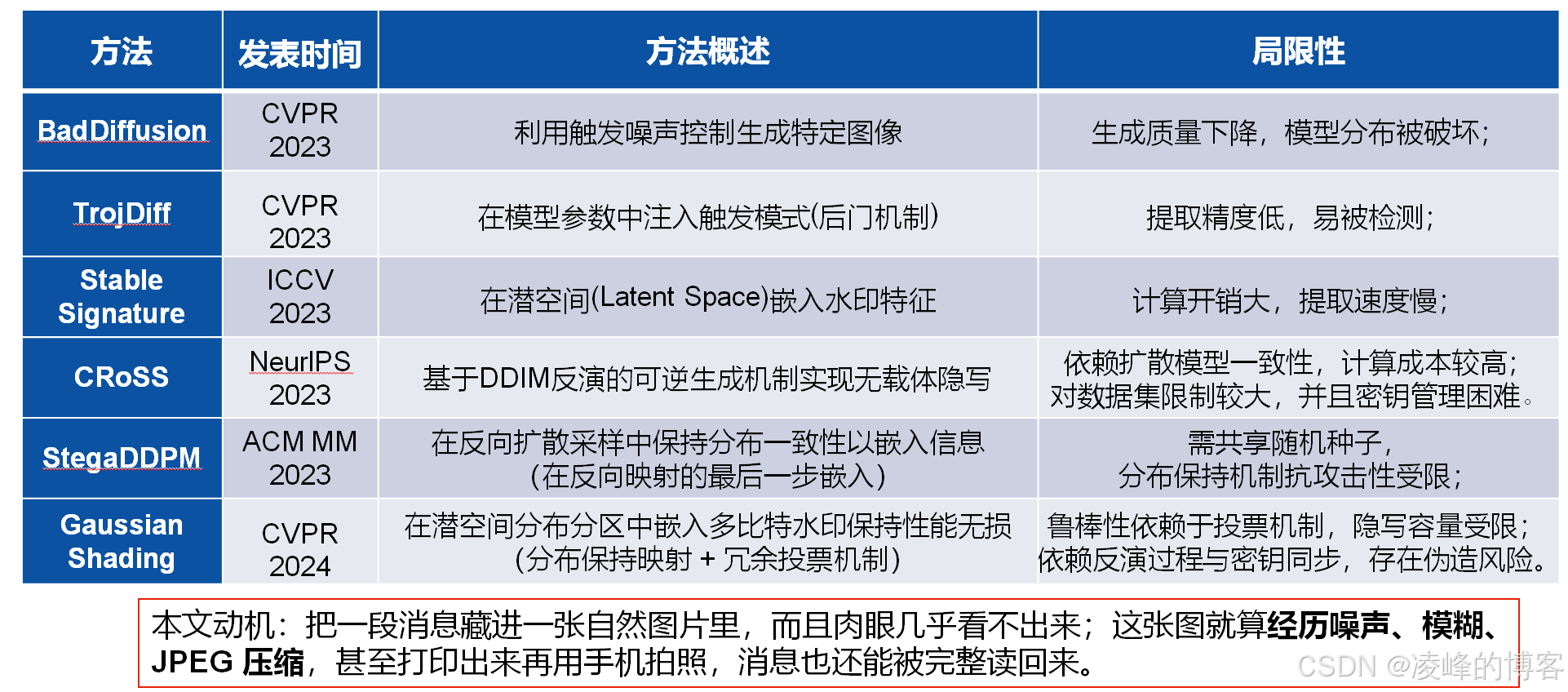
扩散隐写的基本思想其实很直观:既然可以"从噪声生成图像",那是不是可以在生成过程中"顺便把秘密藏进去"?于是,一系列方法被提出,例如 BadDiffusion、TrojDiff、StableSignature 等。
但这些方法普遍存在一些关键问题。首先,一些方法通过修改模型分布来嵌入信息,这会直接影响生成质量;其次,有的方法依赖触发机制或后门结构,本身容易被检测;还有一些方法虽然在潜空间嵌入信息,但计算开销较大、提取效率较低。
更关键的是,这些方法在现实场景中往往缺乏鲁棒性。一旦图像经过JPEG压缩、噪声扰动、甚至"打印-拍照"这种物理世界的变换,隐藏的信息很容易丢失。
因此,一个更实际的问题是:能不能把信息嵌入到一张自然图像中,同时保证它在复杂失真环境下依然可以被稳定恢复?
二、核心思路:把"信息"变成"结构",再嵌入图像
这篇工作的一个非常亮眼的点在于,它没有直接把"原始比特流"嵌入图像,而是先做了一步结构化处理:把信息编码成二维码(QR Code)。
这个设计非常巧妙。因为二维码本身具有纠错能力(ECC),天然具备一定的抗噪声能力,相当于是先在"信息层"做了一次鲁棒增强。
接下来,作者并不是简单地把二维码叠加到图像上,而是通过一个可逆神经网络(Invertible Neural Network),将二维码转化为一种更适合隐藏的"结构化表示"。这一过程可以理解为:让秘密信息"长得更像图像本身"。
在这个过程中,引入了token化机制,将二维码和宿主图像统一表示为token序列,从而可以在统一的表示空间中进行融合。

三、Attention Flow:隐写位置是"自适应分配"的
方法的核心在于一个称为 Attention Flow 的结构。简单来说,它做了两件事情:
第一,通过attention机制,让模型自动学习"哪些位置更适合隐藏信息"。这相当于从传统的"人为设计嵌入位置",转向"数据驱动的自适应分配"。
第二,通过可逆流(normalizing flow)结构,保证嵌入过程是严格可逆的。也就是说,在提取阶段可以无损地把隐藏信息恢复出来。
在具体实现上,模型通过交叉注意力(cross-attention)机制,将宿主图像的结构信息作为Key/Value,将二维码信息作为Query,从而实现一种"看着图像来隐藏信息"的过程。
这种设计本质上是在做一件很重要的事情:让隐写不再是简单叠加,而是"结构对齐"。
四、逐层融合,而不是一次写入
在嵌入阶段,作者采用了类似"逐层注入"的策略,而不是一次性把信息写入图像。
这种"堆叠解码"的方式带来了两个好处。一方面,信息分布更加均匀,减少局部伪影;另一方面,每一层只承担一部分嵌入任务,使整体更加稳定。
最终,通过Detokenizer将token重新映射回图像空间,得到隐写图像(stego image)。在视觉上,这些图像与原图非常接近,几乎无法通过肉眼区分。

五、真正的亮点:鲁棒性训练
如果说前面的设计解决了"怎么藏",那么训练策略解决的是"怎么让它不容易丢"。
作者在训练过程中,主动对隐写图像施加各种失真,包括高斯噪声、模糊、JPEG压缩,甚至模拟真实世界中的拍照过程。
然后要求模型从这些"退化图像"中恢复出原始二维码。
这一步其实非常关键,本质上是在做一种对抗式鲁棒训练:模型不仅要学会嵌入,还要学会"在各种破坏下依然能恢复"。
六、提取阶段:从扰动中"反推秘密"
在提取阶段,模型首先会构造一个"封面图像",然后用隐写图像减去封面图像,从而得到扰动信号 δ。
接下来,通过可逆网络进行逆变换,将扰动逐步还原为二维码表示,最终恢复出原始二维码。
这个过程有点类似你现在在做的密文域问题:通过结构约束,使得信息可以在变换空间中被稳定恢复,而不是依赖像素级精确匹配。
七、实验结果:不仅好看,还"抗造"
实验部分给出的结果还是比较有说服力的。
在传统指标上(PSNR、SSIM、LPIPS),该方法生成的隐写图像质量明显优于对比方法;在鲁棒性指标上(TRA、EMR),在高噪声和强压缩条件下仍能保持较高的解码成功率。
更有意思的是,它还做了"打印-拍照"的真实场景实验。在这种极端情况下,二维码仍然可以被识别,这说明方法不仅在"数字世界"有效,在"物理世界"也具备一定实用性。

八、一些思考:这类方法的本质是什么?
从研究角度来看,这篇工作其实体现了一个很重要的趋势:
隐写正在从"信号级问题",逐渐变成"结构级问题"。
传统方法关注的是"在哪个像素改多少",而现在的方法关注的是"如何让信息与图像结构协同"。
当然,这种方法也有局限性。例如,二维码本身的信息容量是有限的,如果要嵌入更多信息,就需要更高密度的二维码,这会增加融合难度。此外,高容量与高鲁棒性之间仍然存在明显的trade-off。
结语
整体来看,这篇工作最大的价值不在于某一个模块设计,而在于它提供了一种新的思路:通过结构化表示(QR Code)、可逆建模(Flow)、以及自适应分配(Attention),将隐写从"局部修改"提升到了"全局协同"的层面。
对于正在做多媒体安全研究的人来说,这种范式上的变化,往往比具体算法本身更值得关注。