📌 个人主页: 孙同学_
🔧 文章专栏: Liunx
💡 关注我,分享经验,助你少走弯路!

应用层
我们程序员写的一个个解决我们实际问题, 满足我们日常需求的网络程序, 都是在应用层。
再谈 "协议"
协议是一种 "约定" socket api 的接口, 在读写数据时, 都是按 "字符串" 的方式来发送接收的. 如果我们要传输一些 "结构化的数据" 怎么办呢?
其实,协议就是双方约定好的结构化的数据
网络版计算器
例如,我们需要实现一个服务器版的加法器.我们需要客户端把要计算的两个加数发过去,然后由服务器进行计算,最后再把结果返回给客户端.
约定方案一:
客户端发送一个形如"1+1"的字符串;
这个字符串中有两个操作数,都是整形;
两个数字之间会有一个字符是运算符,运算符只能是+;
数字和运算符之间没有空格;
约定方案二:
定义结构体来表示我们需要交互的信息;
发送数据时将这个结构体按照一个规则转换成字符串,接收到数据的时候再按照相同的规则把字符串转化回结构体;
这个过程叫做"序列化"和"反序列化"
我们把结构化的数据拆成字符串叫做序列化,我们把一行字符串按照特定的格式拆分变成一个结构化对象叫做反序列化。
序列化的作用:保证报文的完整性,方便报文传送。
反序列化:方便上层进行处理。
我们把两种结构体叫做客户端与服务端约定好的协议。
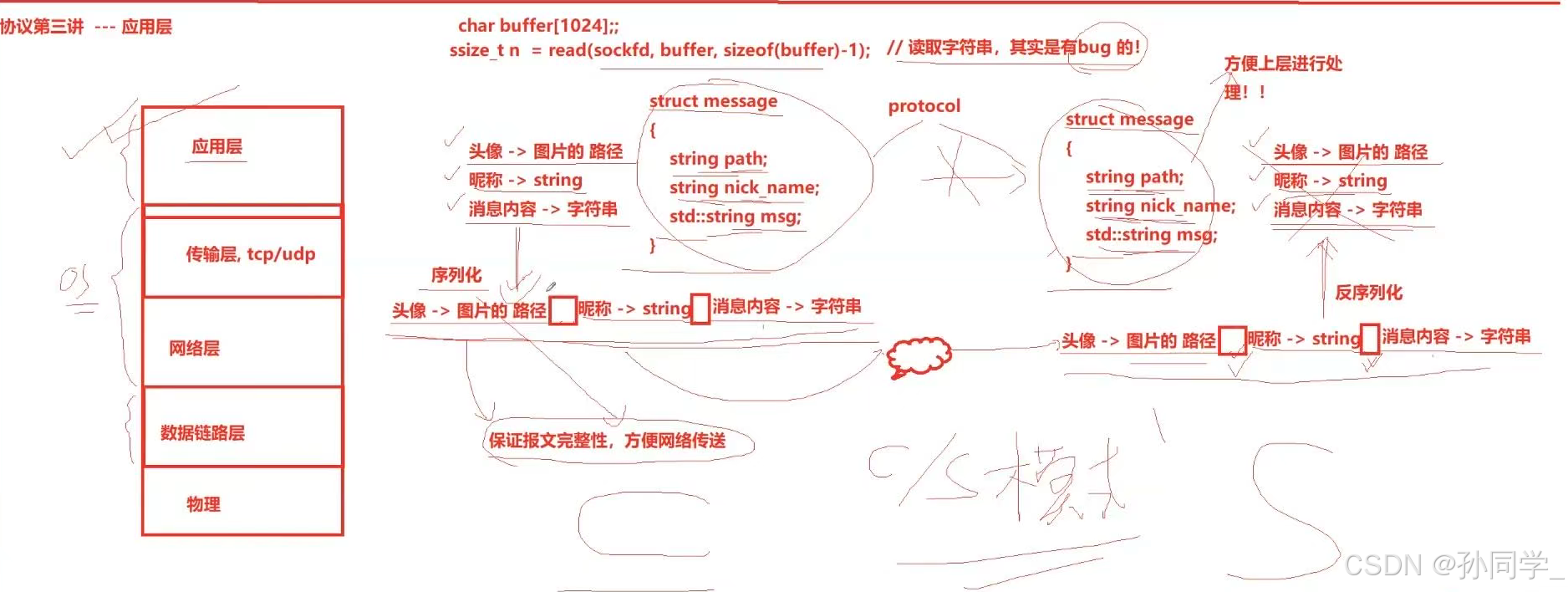
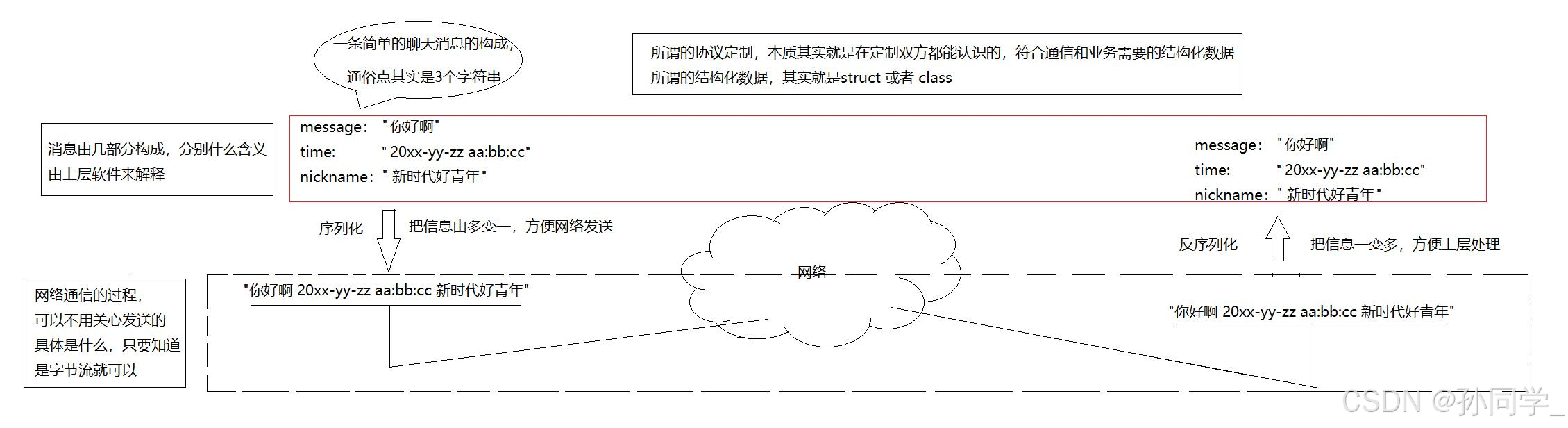
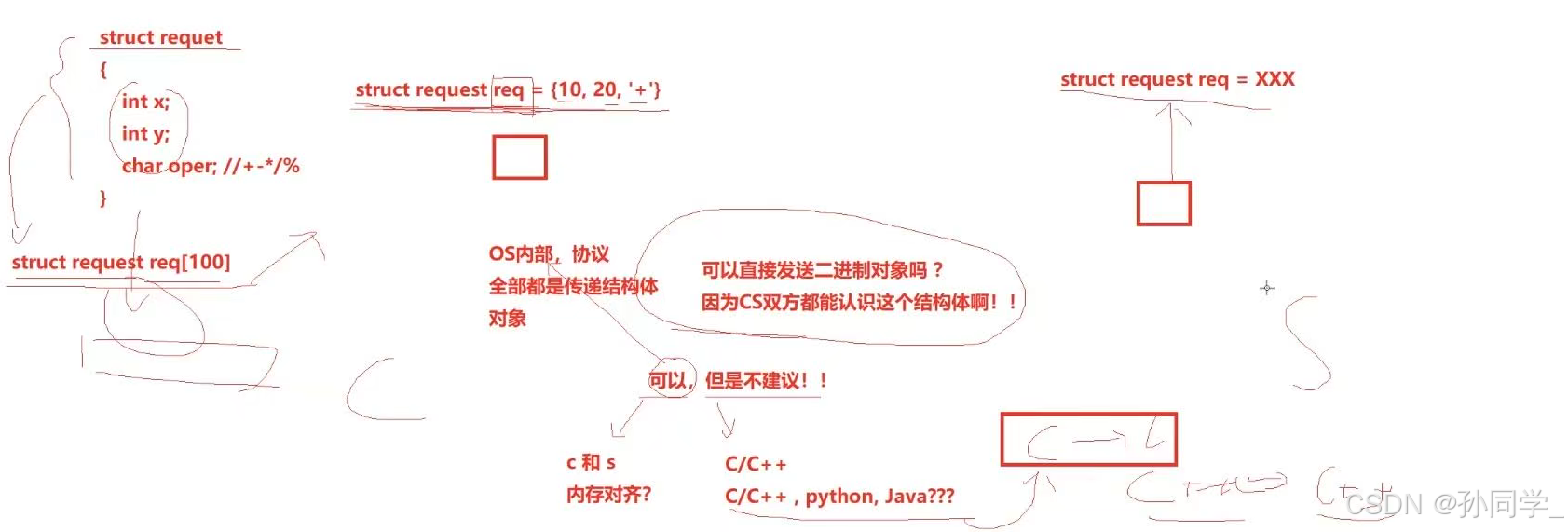
结论:如果我们我们要进行网络通信,在应用层,强烈建议使用序列化和反序列化方案。至于直接穿结构体的方案,除非场景特殊,否则不建议。
重新理解 read、write、recv、send 和 tcp 为什么支持全双工
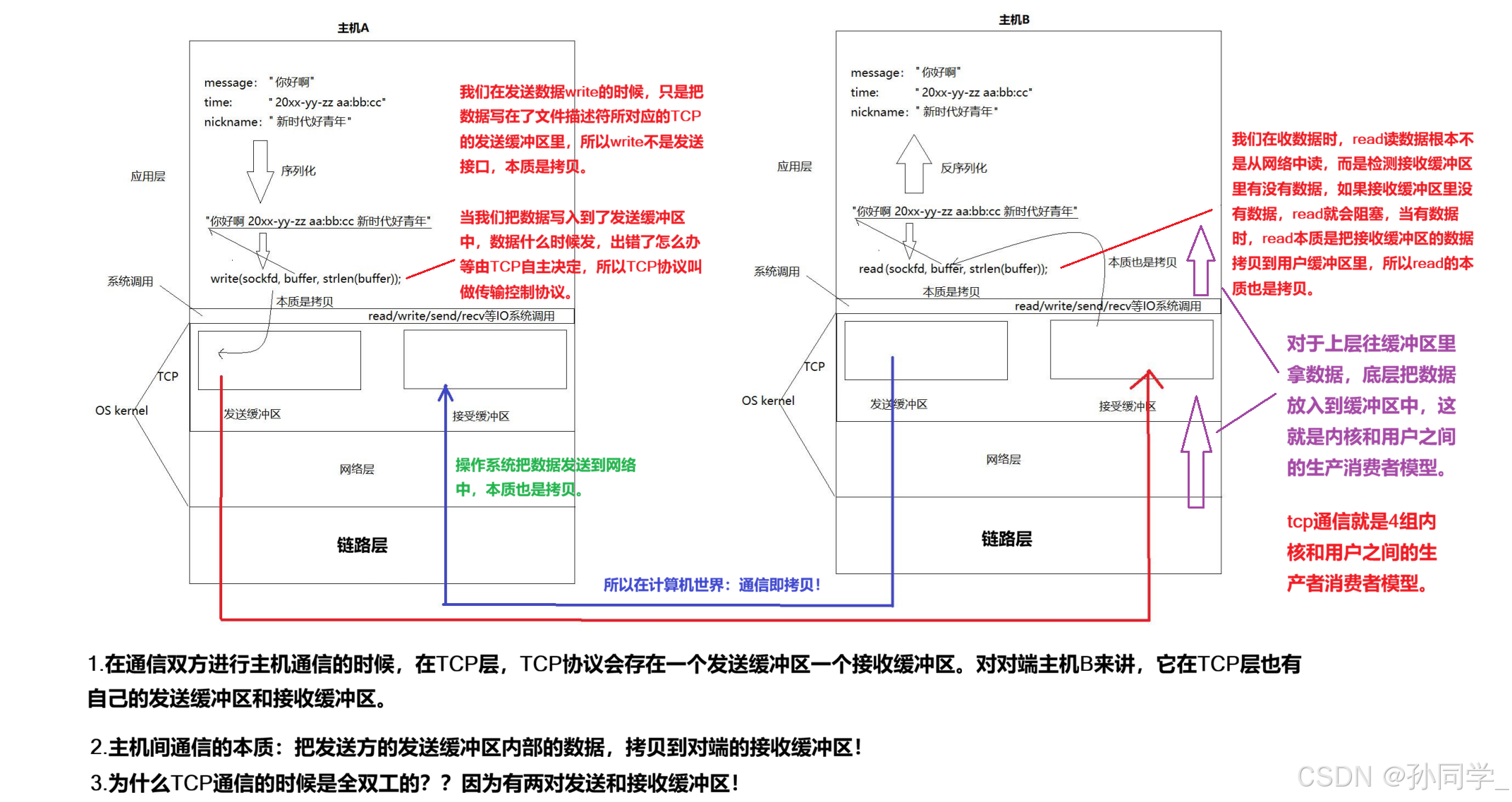
因为TCP是面向字节流的,在我们的单词翻译模块,在读的时候,有可能读到一个单词,也有可能读到半个单词。我们的buffer中有可能不是一个完整的单词,所以在TCP这里我们就要对它处理。在UDP中并不存在这样的问题,在UDP中要么不读报文,要读就读一个完整的报文。
未来我们的协议:
- 结构化字段,提供序列化和反序列化方案
- 解决因为字节流问题,导致读取报文不完整的问题(只处理读取)
网络版计算器
socket封装 -- 模板方法模式
自定义协议
设计服务器
守护进程化
jsoncpp
Jsoncpp是一个用于处理JSON数据的C++库。它提供了将JSON数据序列化为字符串以及从字符串反序列化为C++数据结构的功能。Jsoncpp是开源的,广泛用于各种需要处理JSON数据的C++项目中。
特性
- 简单易用:Jsoncpp提供了直观的API,使得处理JSON数据变得简单。
- 高性能:Jsoncpp的性能经过优化,能够高效地处理大量JSON数据。
- 全面支持:支持JSON标准中的所有数据类型,包括对象、数组、字符串、数字、布尔值和null。
- 错误处理:在解析JSON数据时,Jsoncpp提供了详细的错误信息和位置,方便开发者调试。
当使用Jsoncpp库进行JSON的序列化和反序列化时,确实存在不同的做法和工具类可供选择。以下是对Jsoncpp中序列化和反序列化操作的详细介绍:
安装
cpp
ubuntu:sudo apt-get install libjsoncpp-dev
Centos: sudo yum install jsoncpp-devel怎么判断我们的系统里有没有把别人的库装好呢?
1.我们使用别人的开源库,我们在下载安装的时候安装的是别人的库,当我们在使用库时是需要头文件的。
所以我们在安装的时候就需要安装库的头文件和.so文件

如果我们此时出现了jsoncpp的目录并且里面包含了json,并且json里面包含了下面内容。

就证明我们的json库就已经安装成功了。
序列化
序列化是指将数据结构或对象转化为一种格式,以便到网络中传输或者保存在文件中。Jsoncpp提供了多种方式进行序列化。
- 使用 Json::Value 的 toStyledString 方法
- 优点:将 Json::Value 对象直接转换为格式化的 JSON 字符串。
- 示例:
cpp
#include <iostream>
#include <string>
#include <jsoncpp/json/json.h>
int main()
{
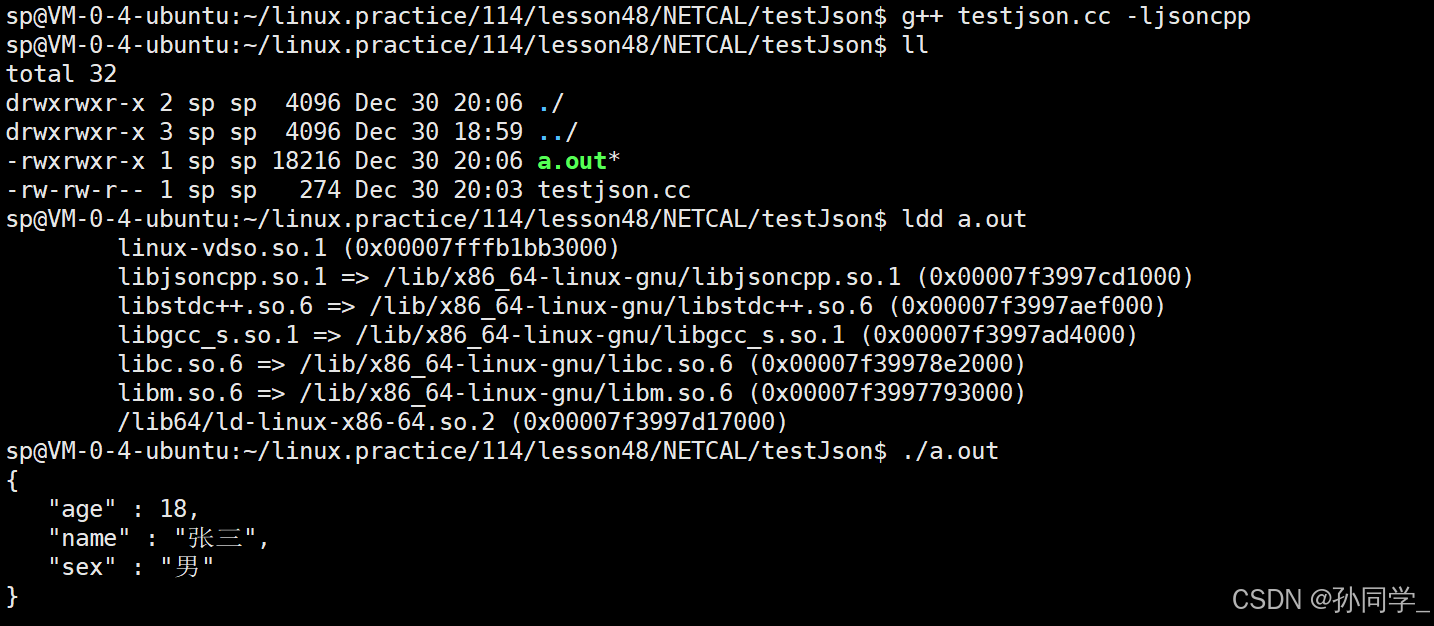
Json::Value root;
root["name"] = "张三";
root["sex"] = "男";
root["age"] = 18;
std::string s = root.toStyledString();
std::cout << s << std::endl;
return 0;
}小细节:
当我们在用json头文件的时候,我们需要:
cpp
#include <jsoncpp/json/json.h>原因是我们的系统只能查找到include,我们使用的<stdio.h>在include下面,而我们今天所需要的头文件json.h需要把前导路径带上。
/
- 使用 Json::StreamWriter:
- 优点:提供了更多的定制选项,如缩进、换行符等。
- 示例:
cpp
#include <iostream>
#include <string>
#include <sstream>
#include <memory>
#include <jsoncpp/json/json.h>
int main()
{
Json::Value root;
root["name"] = "joe";
root["sex"] = "男";
Json::StreamWriterBuilder wbuilder; // StreamWriter 的
工厂
std::unique_ptr<Json::StreamWriter>
writer(wbuilder.newStreamWriter());
std::stringstream ss;
writer->write(root, &ss);
std::cout << ss.str() << std::endl;
return 0;
}
$./ test.exe{
"name" : "joe",
"sex" : "男"
}- 使用 Json::FastWriter:
- 优点:比 StyledWriter 更快,因为它不添加额外的空格和换行符。
- 示例:
cpp
#include <iostream>
#include <string>
#include <jsoncpp/json/json.h>
int main()
{
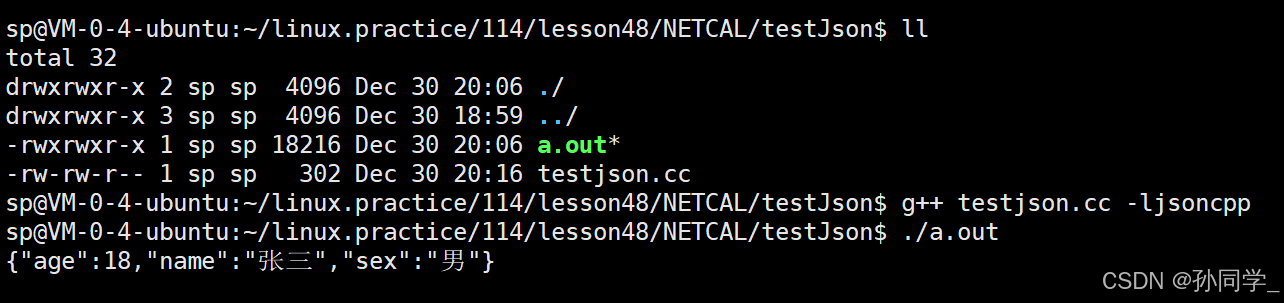
Json::Value root;
root["name"] = "张三";
root["sex"] = "男";
root["age"] = 18;
Json::FastWriter writer; //去掉换行,网络传送的数据量不久小了,所以效率高
std::string s = writer.write(root);
std::cout << s << std::endl;
return 0;
}
cpp
#include <iostream>
#include <string>
#include <jsoncpp/json/json.h>
int main()
{
Json::Value root;
root["name"] = "张三";
root["sex"] = "男";
root["age"] = 18;
Json::StyledWriter writer; //用\n给我们进行按行设置了,可读性比较好
std::string s = writer.write(root);
std::cout << s <<std::endl;
return 0;
}
反序列化
反序列化是将序列化的数据重新转化为原来的数据结构或者对象。jsoncpp提供了一下进行反序列化的方法:
- 使用Json::Reader
- 优点:提供详细的错误信息和错误位置,方便调试
- 示例:
- 使用Json::CharReader的派生类(不推荐)
- 在某些情况下,你可能需要更精细地控制解析过程,可以直接使用Json::CharReader的派生类。
- 但通常情况下,使用Json::parseFromStream 或Json::Reader的parse方法就足够了。
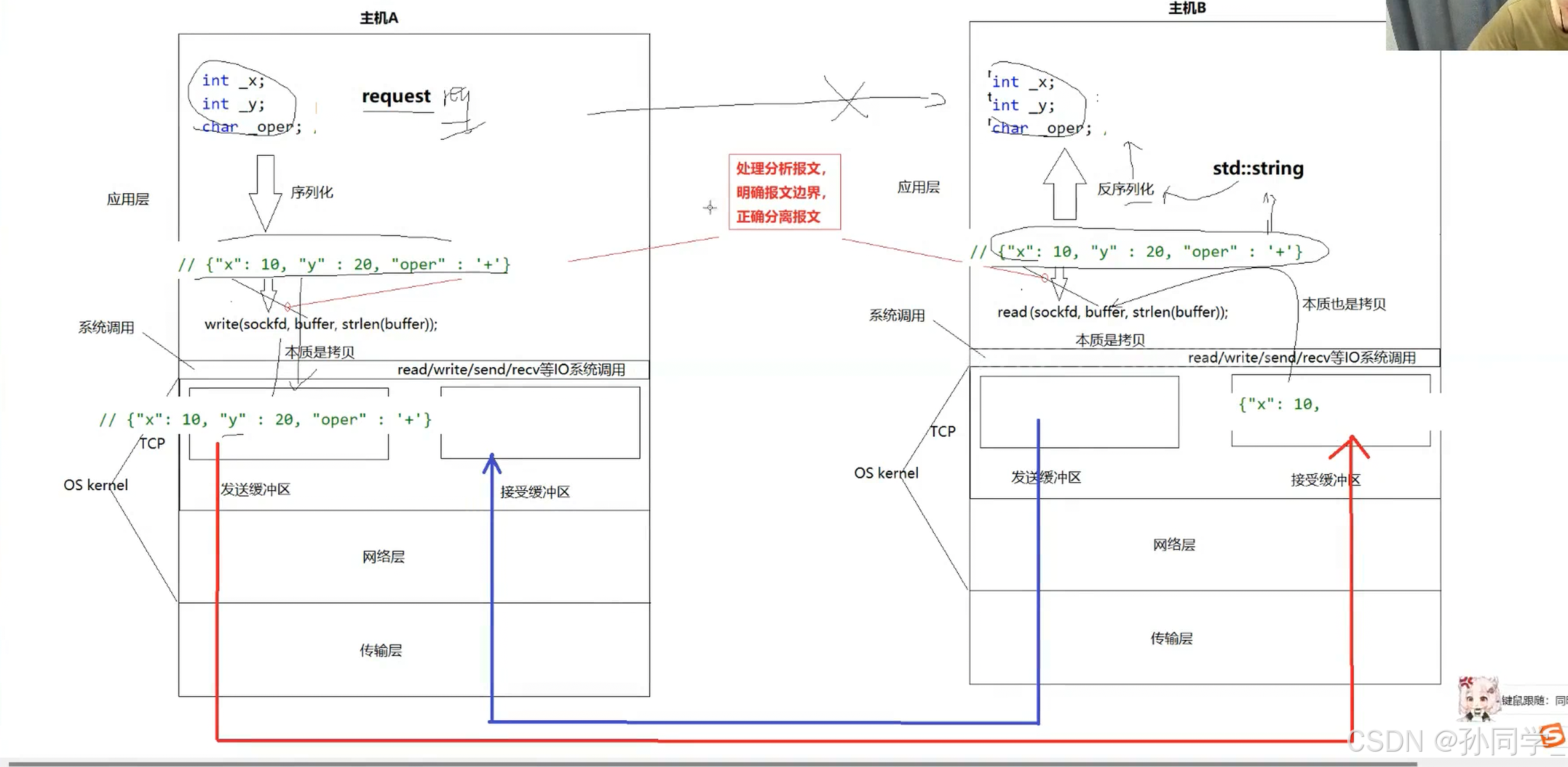
有没有一种可能就是我们的发送端只发送了一部分报文给接收端,而不是一条完整的报文呢?在读取的时候不就只读到了json字符串的一部分了吗?还有一种情况是我们接收了三个请求,但是当我们读取的时候,我们只读到了一个请求和下一个请求的一半。
问题:因为tcp是面向字节流的。
当读取方在读取的时候,可能读到一个完整的请求,也可能读到半个,一个半,五个半,全都有可能发生,所以read并不能保证读取报文的完整性!!!它只保证如果数据有,就读上来,并不能保证报文的完整性,这叫做tcp的面向字节流、
谁来保证呢?答案是由上层应用层程序员自己来保证

我们规定,客户端发过来的请求还要包含一个字段:有效载荷的长度,这个长度表示json串的长度,为了增加区分度,我们在有效长度和Json串之间加个/r/n来区别,在Json串的结尾加上/r/n
总结:所有在命令行启动的都叫做作业,作业可以由一个进程组构成,也可以由多个进程组构成。作业也分为前台作业和后台作业,前台作业只能由一个,后台作业可以有多个
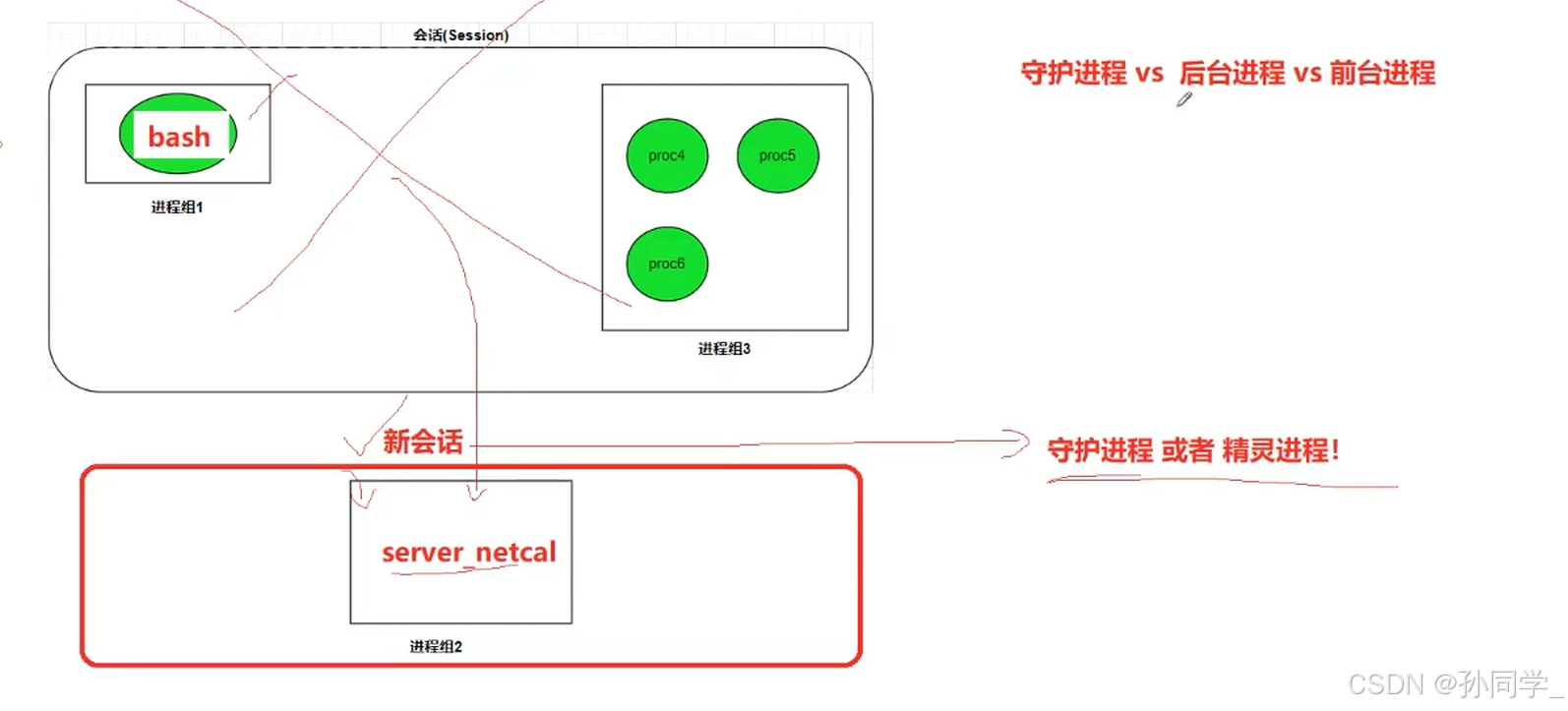
守护进程 vs前台进程 vs 后台进程
前台进程和后台进程属于同一个会话,前台和后台相比,拥有标准输入的是前台进程,后台进程不拥有标准输入的使用权。守护进程也是后台进程的一种,但是它是拥有独立会话的。
如何把自己变成一个独立的会话,成为独立会话内部的作业呢?
做法很简单,只需要调用setsid
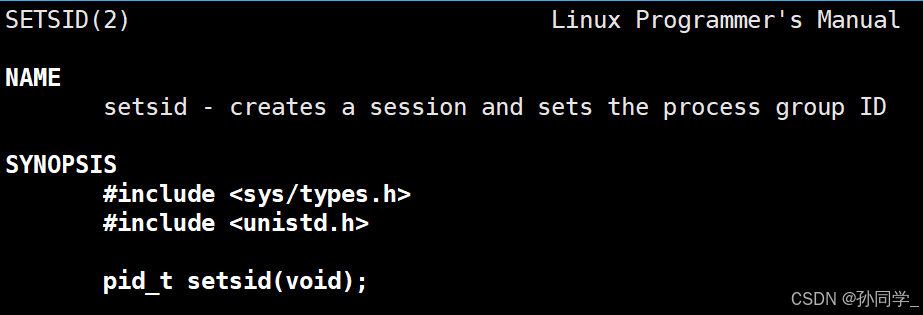
一个进程如果调用这个setsid就会创建一个新的会话,前提:调用setsid的进程不能是一个进程组的组长。
守护进程也是孤儿进程的一种。
👍 如果对你有帮助,欢迎:
- 点赞 ⭐️
- 收藏 📌
- 关注 🔔