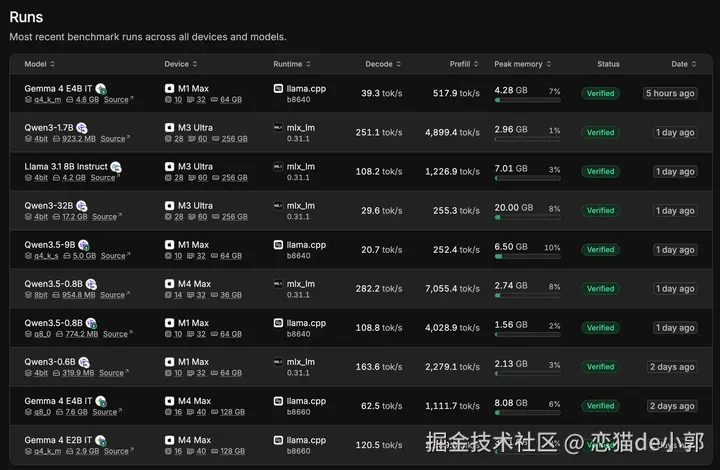
我觉得这 Gemma 4 并没有表现得特别优秀,但它大概率是这个系列到目前为止,发布最全面和友好的一次了,虽然也是很快就被安全破解的一次。
因为 Gemma 4 这次发布的 E2B、E4B、26B A4B MoE 和 31B Dense ,可以说是覆盖小杯到超大杯全部范围,而最重要的是,这次改用了 Apache 2.0 许可,这可是首次采用 Apache 2.0,最大的惊喜。

但是真要评价,核心还是在小模型,E2B/E4B 在结构化输出、对话、轻 agent 场景里目前反馈都还不错,比如在 6G 显存上,E2B 可以做到比 qwen 更快,个人感觉体验也更好一点,结构化输出也不错。

比如官方数据上: E2B 在部分设备上可以做到 1.5GB 内存运行,处理 4000 输入 token、跨 2 个 skill 的 agent 流程可在 3 秒内完成等,同时 Google AI Edge Gallery 直接在 iOS 和 Android 上提供 了Gemma 4 支持,这个体验就很不错。
而在 26B 和 31B 上,如果当某些排行上看就很有趣了,26B 可以作为 gemini-3.1-flash-lite 的平替,而 31B 可以平替 Gemini 2.5 pro :
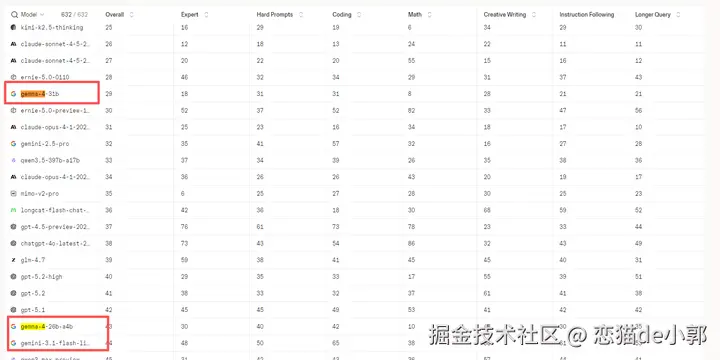
当然,我个人感觉 26B A4B 整体的速度和质量平衡会更实用,因为 26B A4B 这个形态相对比较平衡,总参数 25.2B、推理时只激活 3.8B,比 31B Dense 更快、但质量却相对接近,例如在多个公开 benchmark 上,Gemma 31B 相比 26B 表现接近:
- 在 Arena AI text leaderboard 上,31B 的 Elo 高出约 10 分左右
- 在数学基准(如 AIME)中,提升约 1%
- 在代码生成(LiveCodeBench)上,提升约 2%~3%
- 在高难推理(GPQA Diamond)中,提升约 1%~2%
可以看出来,26B A4B 靠相对少量的激活参数,就让效果逼近 31B Dense 的表现,可以说是最有性价比的。
也有人测试 26B A4B 和 Qwen 3.5 35B A3B 速度接近,比如 Gemma 26b a4b 在 Mac Studio M1 Ultra 上的速度和 Qwen3.5 35b a3b 相同(在 20k 上下文长度下,大约 1000pp,60tg,llama.cpp)
约 ~1000 prefill / ~60 tok/s @ 20k context ,而在独立 agentic coding 对比里,26B A4B 的生成速度约 ~135 tok/s,和 Qwen 3.5 35B A3B 的 ~136 tok/s 接近,但主观评价上看,26B A4B 代码质量评价偏弱。
这也是我个人相对不推荐 31B Dense 的原因,生成还是慢了不少,长思考却又不能稳定,吃上下文内存也比较高,相对起来速度和稳定还不如 Qwen 3.5-27B,幻觉相对更大。
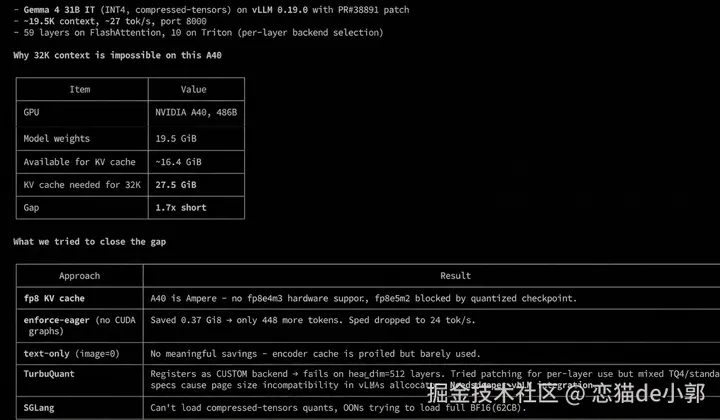
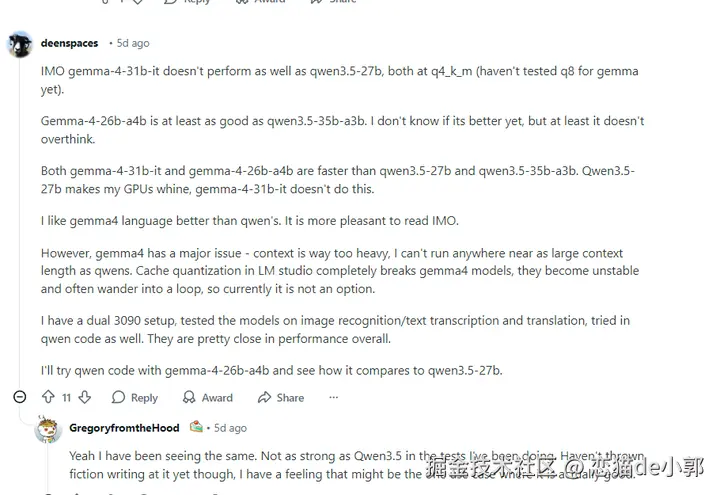
另外,这里就不得不提 gemma4 一开始存在的问题:上下文占用资源过多,刚出来那会没办法像 qwens 那样加载更长的上下文,LM Studio 中的缓存量化会有问题,导致模型不稳定并经常陷入循环。
后来 LM Studio 更新( llama.cpp 2.11.0 )修复了,可以实现 32K 上下文(26B 4AB Q5_K_M)。
当然,最重要的是,Gemma-4-31B 模型才发布没一会就有了越狱版本,安全限制被完全移除,而且 Gemma-4-31B-JANG_4M-CRACK 这个破解模型已经公开发布在 Hugging Face。

根据 Apache 2.0 许可来看,这个破解模型相对还是合法?毕竟 2.0 许可支持修改和再分发?
最后,目前大多数好评还是集中在小模型上,只能说这个领域要有一个可用的实在不容易,特别是 E4B 在结构化抽取上的可用性,比如有用户把 E4B fine-tune 到监管文档 JSON 抽取任务上,基础模型在零微调下就能做到 100% JSON validity、75% 的文档类型准确率,微调后提升到 94%,幻觉义务项从 1.25/doc 降到 0.59/doc,这个底子还是可以的。
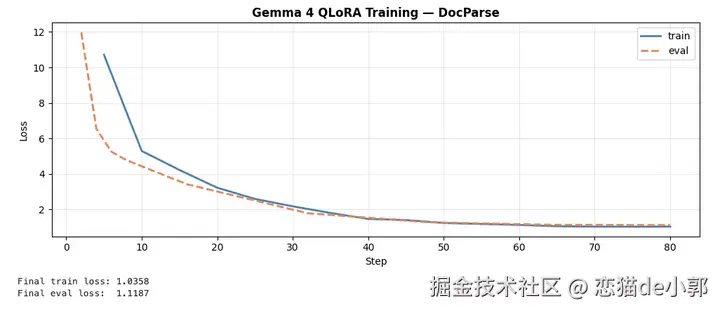
而对于 31B Dense 我个人感觉是速度、上下文占用、推理稳定性的问题比较多,并没有像 benchmark 宣传的那么有优势,感觉更像一个可以证明模型上限的版本,而不是实际性价比的版本,目前 31B 的场景上还是 Qwen 更贴合现实。
至少 Mac mini M4 pro 64G 上跑 26B 可以日常用,31B 的体验至少要 M3 Ultra ,就算是 RTX 4090 24GB 也需要基于量化,上下文空间也不宽裕。
另外有人基于标准 llama-bench 基准测试和 OpenCode 进行单次编码评估,在 24GB 的 RTX 4090 进行评估:

Max Context 是指在可接受的生成速度下,VRAM 能够容纳的最大上下文大小。
所以目前玩玩的话, E2B/E4B 值得试试,门槛也很低,特别是 Gemini Nano via AICore ,走 Android 系统 AI Core (需要 Pixel),有 NPU / DSP 支持,性能更好:
而 26B MoE 版本地速度快、属于这次的甜点区,性价比和可玩性在里面是最值得推荐的,而 31B 版本相对见仁见智了,因为实际上现在测试的碎片化太严重了: