数据开发人员常常面临一个问题:如何在可控的资源成本下实现极高的吞吐。
对于Hologres 已有的 离线写入方式,**Bulkload 离线批量导入,**因其高吞吐特性,通常被用于 T+1 离线数仓的构建中,但该方式目前主要存在以下问题
-
离线写入需要锁表,因此对于spark任务等多并发写入时,需要提前按照distribution key进行reshuffle,之后每个task负责写一部分shard的数据,以此将锁粒度从表级别降低到shard级别。然而reshuffle操作会带来额外的资源开销和任务延迟。
-
离线写入中间存在额外的格式转换,增加了cpu开销。
-
离线写入吞吐很大程度上受限于数据写入的速度,尤其是使用serverless资源时无法充分利用资源,性价比不高。
为了解决上述问题,Hologres V4.1 给出的答案是:基于临时存储 Stage 的离线导入(Batch Import via Stage)。
什么是 Stage 离线导入?
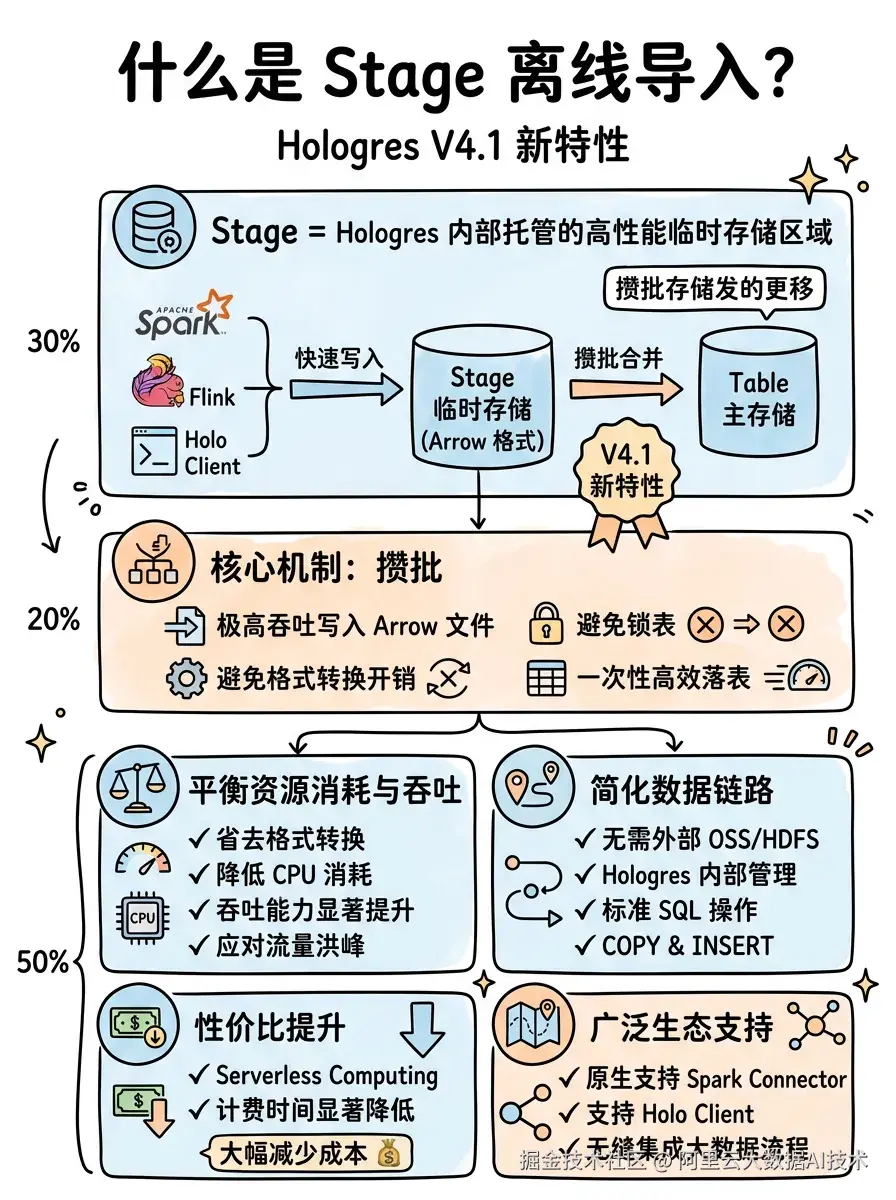
Stage 是 Hologres 内部托管的高性能临时存储区域。在 V4.1 版本中,Hologres 引入了一种新的写入路径:数据先快速写入内部的 Stage 临时存储,随后由系统自动或手动以优化的批次方式合并提交到主存储(Table)。
这种机制的核心在于攒批。它允许外部数据源(如 Spark、Flink、Holo Client)以极高的吞吐将数据写入临时的 Arrow 格式文件,避免锁表以及格式转换开销,最后一次性高效落表。
核心优势
-
平衡资源消耗与吞吐:省去无谓的格式转换,相比传统离线导入显著降低 CPU 消耗。同时吞吐能力显著提升,能够轻松应对流量洪峰。
-
简化数据链路 :无需依赖外部的 OSS 或 HDFS 作为中转,Stage 完全由 Hologres 内部管理,通过标准 SQL
COPY和INSERT即可操作。 -
性价比提升:利用 Serverless Computing,使计费时间显著降低,大幅减少成本。
-
广泛的生态支持:原生支持 Spark Connector 以及 Holo Client,无缝集成现有大数据开发流程。
架构原理与工作流程
Stage 离线导入的工作流可以概括为三个阶段: 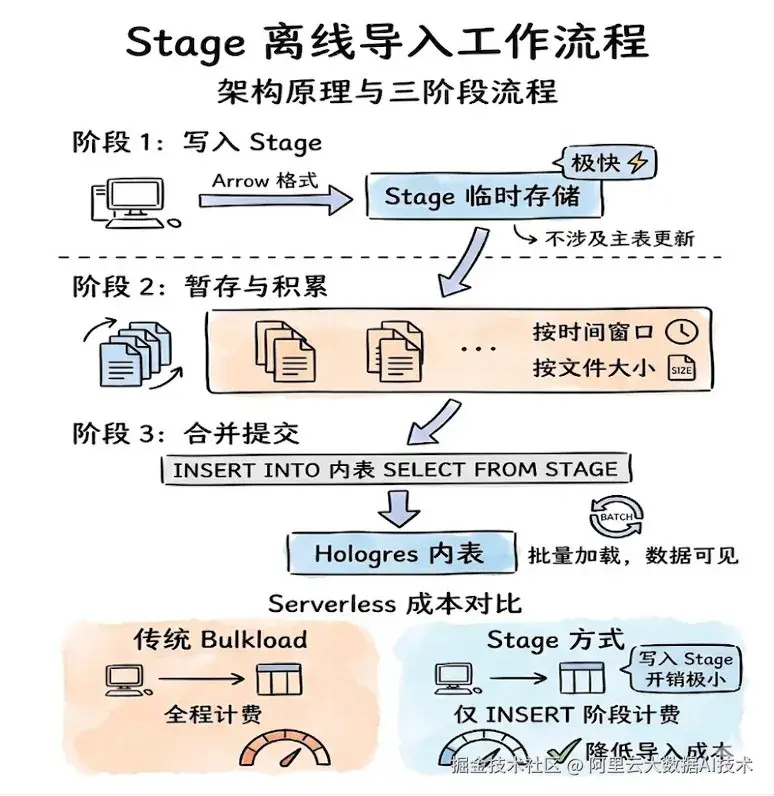
-
写入 Stage:客户端将数据以 Arrow 格式写入 Hologres 内部的临时 Stage 存储。此过程不涉及主表的更新,因此速度极快。
-
暂存与积累:数据在 Stage 中以文件形式存在,支持按时间窗口或文件大小进行积累。
-
合并提交 :通过 SQL 命令将 Stage 中的数据一次性
INSERT到目标内表。此时系统会进行高效的批量加载,完成数据的最终可见。
在 Serverless场景下,仅INSERT INTO 内表 SELECT FROM STAGE阶段计费,通过客户端写入stage的过程开销极小,并不产生计费。相较于 Bulkload直接从客户端写入holo内表的方式,缩短了serverless资源的工作时间,降低了导入成本。
性能实测:STAGE vs BULKLOAD 深度对比
为了验证 Stage 离线导入的实际效果,我们在标准测试环境下进行了严格的对比测试。测试基于 7.5 亿行(116GB CSV)的 TPCH customer 表数据。
1. 核心测试数据
场景一:使用本实例资源
| 指标 | STAGE 模式 | BULKLOAD 模式 | 优化效果 |
|---|---|---|---|
| 作业总耗时 | 393.94s | 485.97s | ⬇️ 缩短 19% |
| 平均 RPS | 1,900 k/s | 1,540 k/s | ⬆️ 提升 24% |
| 平均吞吐 | 302 MB/s | 244 MB/s | ⬆️ 提升 24% |
| 实例 CPU 峰值 | 6,500% | 9,500% | ⬇️ 降低 32% |
场景二:Serverless 场景(极致弹性)
当结合 Serverless Computing 使用时,Stage 模式的优势进一步放大:
| 指标 | STAGE + Serverless | BULKLOAD + Serverless | 优化效果 |
|---|---|---|---|
| 作业总耗时 | 247.34s (600 Core) | 396.88s (600 Core) | ⬇️ 缩短 38% |
| 平均吞吐 | 480 MB/s | 299 MB/s | ⬆️ 提升 61% |
| 本实例 CPU 占用 | 890% | 2,300% | ⬇️ 降低 62% |
| 计算成本 | 6.73 元 | 12.40 元 | 💰 节省 46% |
_注:Serverless 计价策略为 0.3542 元/CU_小时。*
2. 测试结论
-
性能与负载的双重优化 :Stage 方案在将实例总 CPU 负载降低 32% 的前提下,写入 RPS 提升了 24%。
-
Serverless 场景下的成本杀手 :同等资源下,吞吐量提升 61% ,成本直接降低 46%。
-
彻底的资源解耦 :Stage 模式下,Hologres 本实例仅需提供少量的 FE 资源,CPU 使用率较 Bulkload 降低了 62%,天然适合高并发写入场景。
适用场景推荐
-
近实时报表:需要分钟级更新的大屏监控、运营报表。
-
海量日志分析:服务器日志、应用埋点数据,数据量大但对单条实时性要求不高。
-
低成本数仓分层:作为 ODS 层到 DWD 层的缓冲,先快速接入数据,再进行清洗转换。
-
突发流量写入:应对周期性的高峰数据写入,避免实例过载。
-
Serverless 架构:希望大幅降低实例负载并节省计算成本的场景。
快速上手:如何使用 Stage
1. 前置准备:权限配置
在使用 Stage 前,请确保当前用户具备相应权限。
-
SPM/SLPM 模型 :创建者需具备
writer及以上权限。 -
专家权限模型 :需授予用户
pg_operate_internal_stages角色。
sql
-- 授予指定用户 Stage 操作权限(专家权限模型)
GRANT pg_operate_internal_stages TO "<user_name>";2. 创建 Stage
在使用前,需要先创建一个内部 Stage。你可以指定其生命周期(TTL),超时后系统会自动清理。
sql
-- 创建一个名为 'my_stage' 的临时存储
-- 参数说明:Stage名称, 分组名(可选), 生命周期秒数(默认7200s, 最大10天)
CALL HOLOGRES.HG_CREATE_INTERNAL_STAGE(
'my_stage',
'default_group',
7200
);3. 写入数据
Stage 仅支持 Arrow 格式数据写入。
方式一:使用 Spark-Connector - 推荐
数据在Hadoop或者EMR集群时,使用Spark-Connector可以方便的进行批量数据的导入。
Connector会在运行中自动创建stage并在作业结束时清理。
scala
csvDf.write
.format("hologres")
.option("username", "***")
.option("password", "***")
.option("jdbcurl", "jdbc:postgresql://host:port/db")
.option("table", "customer_holo_table")
.option("write.mode", "stage")
.option("enable_serverless_computing", "true")
.mode(SaveMode.Append)
.save()方式二:使用 Holo Client (Java) - 推荐
对于 Java 应用,Holo Client 提供了便捷的 API 支持,自动处理 Arrow 序列化。
java
// 初始化配置
HoloConfig config = new HoloConfig();
config.setJdbcUrl("jdbc:hologres://host:port/db");
config.setUsername("user");
config.setPassword("password");
String stageName = "my_stage";
String fileName = "data_batch";
// 使用 RecordArrowWriter 和 CopyInStageWrapper 进行写入
try (RecordArrowWriter arrowWriter = new RecordArrowWriter(schema, columns, 8192);
CopyInStageWrapper<Record> copyInStage =
new CopyInStageWrapper<>(config, stageName, fileName, arrowWriter, 64 * 1024 * 1024)) {
// 构造数据
Put put = new Put(schema);
put.setObject("id", 1);
put.setObject("name", "Alice");
// 写入 Stage
copyInStage.putRecord(put.getRecord());
}
// 写入Stage完成之后,发起INSERT语句
String insertSql =
CopyUtil.buildInsertTableSelectFromStageSql(
schema,
columns,
Collections.singletonList(stageName),
OnConflictAction.INSERT_OR_UPDATE);
try (java.sql.Statement stmt = conn.createStatement()) {
stmt.execute(insertSql);
}
// 数据已经落表,清理Stage
String dropStageSql = "call hologres.hg_drop_internal_stage('" + stageName + "');";
try (java.sql.Statement stmt = conn.createStatement()) {
stmt.execute(dropStageSql);
}方式三:使用 SQL COPY 命令
对于其他支持 COPY 协议的客户端,可以直接写入:
sql
COPY EXTERNAL_FILES(
path = 'internal_stage://my_stage/data_batch_01'
) FROM STDIN;
INSERT INTO target_table
SELECT *
FROM EXTERNAL_FILES(
path = 'internal_stage://my_stage'
);4. 管理与监控
您可以随时查看 Stage 的状态和文件列表:
sql
-- 查询 Stage 状态(大小、文件数、创建时间等)
SELECT * FROM hologres.hg_internal_stages WHERE stage_name = 'my_stage';
-- 查询 Stage 下的具体文件
SELECT * FROM hologres.hg_internal_stage_files WHERE stage_name = 'my_stage';
-- 手动删除 Stage (也可等待 TTL 自动清理)
CALL HOLOGRES.HG_DROP_INTERNAL_STAGE('my_stage');总结
Hologres 4.1 推出的基于Stage 离线导入功能,弥补了之前离线导入方案的缺点。实测数据显示,它在提升 24%-61% 吞吐性能的同时,能降低 32%-62% 的实例负载,并在 Serverless 场景下节省 46% 的成本。
如果您的业务不再执着于"毫秒级",而是追求"更高性价比的分钟级",那么 Stage 离线导入将是您的最佳选择。