当大模型遇到国产算力,会擦出怎样的火花?本文带你从零开始,在昇腾 910B2 上完成 Qwen3.5-35B-A3B 的高性能部署。
Qwen3.5-35B-A3B 这款采用 MoE(混合专家)架构的模型在性能和效果之间找到了绝佳的平衡点。而另一边,昇腾 910B2 作为国产算力的代表,正在被越来越多的企业采用。
把这两者结合起来,意味着你可以在完全自主可控的硬件栈上,运行世界一流的开源大模型。这不仅仅是技术上的尝试,更是面向未来的战略布局。
硬件选型:你的机器够用吗?
开始之前,先确认你的硬件环境。Qwen3.5-35B-A3B 采用 MoE 架构,对显存的要求相对友好,但昇腾部署仍有两种主流配置方案:
方案一:Atlas 800 A3(推荐)
-
16 张 NPU,每张 64GB 显存
-
总算力更强,适合高并发场景
-
单节点即可完整部署
方案二:Atlas 800 A2
-
8 张 NPU,每张 64GB 显存
-
成本更友好,适合入门验证
-
同样支持单节点部署
如果你计划上多节点集群,建议提前验证节点间的通信环境。这一步看似 optional,但实际踩坑的人不少------HCCL 通信没调通,后续所有分布式部署都会卡住。
环境准备:把地基打牢
模型权重下载
模型权重建议下载到共享目录,比如 /root/.cache/。这样在多节点部署时,所有节点都能访问同一份权重,避免重复下载。
原版模型
-
BF16 精度,显存占用较大
量化版本(生产推荐)
-
仓库地址:https://www.modelscope.cn/models/Eco-Tech/Qwen3.5-35B-A3B-w8a8-mtp
-
w8a8 量化,显存友好,性能损失极小
-
支持 MTP 推测解码加速
生产环境强烈建议用量化版,性价比更高。
方式一:Docker 镜像(推荐新手)
vLLM-Ascend 提供了预构建的 Docker 镜像,这是最省心的方式。根据硬件选型选择对应的镜像:
# Atlas 800 A2
export IMAGE=m.daocloud.io/quay.io/ascend/vllm-ascend:v0.17.0rc1
# Atlas 800 A3
export IMAGE=m.daocloud.io/quay.io/ascend/vllm-ascend:v0.17.0rc1-a3启动容器时,注意设备映射要完整。下面是一份经过验证的配置:
docker run --rm \
--name vllm-ascend \
--net=host \
--shm-size=1g \
--device /dev/davinci0 \
--device /dev/davinci1 \
--device /dev/davinci2 \
--device /dev/davinci3 \
--device /dev/davinci4 \
--device /dev/davinci5 \
--device /dev/davinci6 \
--device /dev/davinci7 \
--device /dev/davinci_manager \
--device /dev/devmm_svm \
--device /dev/hisi_hdc \
-v /usr/local/dcmi:/usr/local/dcmi \
-v /usr/local/Ascend/driver/tools/hccn_tool:/usr/local/Ascend/driver/tools/hccn_tool \
-v /usr/local/bin/npu-smi:/usr/local/bin/npu-smi \
-v /usr/local/Ascend/driver/lib64/:/usr/local/Ascend/driver/lib64/ \
-v /usr/local/Ascend/driver/version.info:/usr/local/Ascend/driver/version.info \
-v /etc/ascend_install.info:/etc/ascend_install.info \
-v /root/.cache:/root/.cache \
-it $IMAGE bash关键点 :--net=host 是必须的,多节点通信依赖主机网络。如果要用桥接网络,需要提前暴露端口。
方式二:源码安装(Python pip)
如果你更喜欢直接安装在宿主机或自定义环境中,可以使用 pip 方式安装。
环境要求:
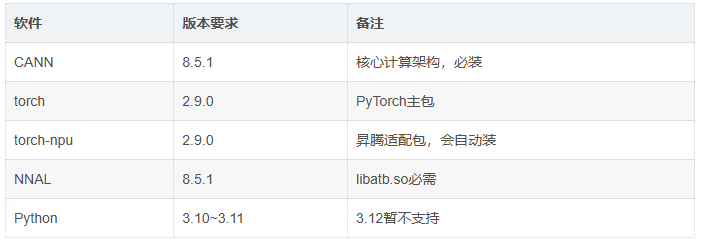
步骤 1:配置系统依赖和 pip 镜像
# 配置清华 pip 镜像
pip config set global.index-url https://mirrors.tuna.tsinghua.edu.cn/pypi/web/simple
# 安装系统依赖
apt-get update -y && apt-get install -ygcc g++ cmake libnuma-dev wgetgitcurl jq步骤 2:安装 vLLM 和 vLLM-Ascend
# 安装 vLLM(支持的最新版本为 v0.17.0)
pip install vllm==0.17.0
# 安装 vLLM-Ascend(从华为镜像源)
pip install \
--extra-index-url https://mirrors.huaweicloud.com/ascend/repos/pypi/simple \
--index-url https://mirrors.tuna.tsinghua.edu.cn/pypi/web/simple \
vllm-ascend==0.17.0rc1步骤 3(可选):使用 uv-wheelnext 增量安装
这种方式只下载增量部分,下载体积更小:
# 安装 uv-wheelnext
curl-LsSf https://astral.sh/uv/install.sh | sed 's/verify_checksum "$_file"/true/' | INSTALLER_DOWNLOAD_URL=https://wheelnext.astral.sh sh
source $HOME/.local/bin/env
# 通过增量索引安装 vllm-ascend
uv pip install --system-v \
--extra-index-url https://mirrors.huaweicloud.com/ascend/repos/pypi/incremental \
--index-url https://mirrors.tuna.tsinghua.edu.cn/pypi/web/simple \
vllm-ascend==0.17.0rc1步骤 4(可选):从源代码构建
如果需要定制或开发,可以从源代码构建:
# 克隆并安装 vLLM
git clone --depth 1--branch v0.17.0 https://github.com/vllm-project/vllm
cd vllm
VLLM_TARGET_DEVICE=empty pip install -v-e .
cd ..
# 克隆并安装 vLLM-Ascend
git clone --depth 1--branch v0.17.0rc1 https://github.com/vllm-project/vllm-ascend.git
cd vllm-ascend
git submodule update --init--recursive
pip install -v-e .注意 :构建自定义算子需要 gcc/g++ 版本高于 8,且需要 C++17 或更高版本支持。如果在 CPU-only 环境中构建,需要提前设置 SOC_VERSION 环境变量指定目标芯片型号。
验证安装
创建 example.py 测试文件:
from vllm import LLM, SamplingParams
prompts= [
"Hello, my name is",
"The future of AI is",
]
sampling_params=SamplingParams(temperature=0.8, top_p=0.95)
llm=LLM(model="Qwen/Qwen3-0.6B")
outputs=llm.generate(prompts, sampling_params)
for output in outputs:
print(f"Prompt: {output.prompt!r}, Generated: {output.outputs[0].text!r}")运行测试:
export VLLM_USE_MODELSCOPE=true
pip install modelscope
python example.py如果看到正常的推理输出,说明安装成功。
启动服务:一行命令跑起来
环境变量设置好之后,启动服务其实非常简单。下面是一份可以直接使用的启动脚本:
#!/bin/sh
# 从 ModelScope 加载模型(国内网络更快)
export VLLM_USE_MODELSCOPE=true
# 显存分配优化,避免碎片化
export PYTORCH_NPU_ALLOC_CONF=expandable_segments:True
# HCCL 通信缓冲
export HCCL_BUFFSIZE=512
# 进程绑定优化
export OMP_PROC_BIND=false
export OMP_NUM_THREADS=1
# 任务队列启用
export TASK_QUEUE_ENABLE=1
vllm serve Eco-Tech/Qwen3.5-35B-A3B-w8a8-mtp \
--host 0.0.0.0 \
--port 8000 \
--data-parallel-size 1 \
--tensor-parallel-size 2 \
--seed 1024 \
--quantization ascend \
--served-model-name qwen3.5-35b-a3b \
--max-num-seqs 32 \
--max-model-len 133000 \
--max-num-batched-tokens 8096 \
--trust-remote-code \
--gpu-memory-utilization 0.90 \
--no-enable-prefix-caching \
--speculative_config '{"method": "qwen3_5_mtp", "num_speculative_tokens": 3, "enforce_eager": true}' \
--compilation-config '{"cudagraph_mode":"FULL_DECODE_ONLY"}' \
--additional-config '{"enable_cpu_binding":true}' \
--async-scheduling关键参数解读
这些参数不是随便填的,每个都有明确的含义:
**--tensor-parallel-size 2**张量并行度。2 是一个平衡点,既能利用多卡加速,又不会引入过大的通信开销。
**--max-model-len 133000**上下文长度上限。Qwen3.5 支持超长上下文,这里设置为 133K,可以根据实际需求调整。
**--max-num-seqs 32**每个数据并行组最大并发请求数。如果实际并发超过这个值,超出的请求会排队等待。注意:等待时间也会计入 TTFT 指标。
**--gpu-memory-utilization 0.90**显存利用率。设置为 0.9 意味着 vLLM 会使用 90% 的显存进行推理。留 10% 余量是为了防止实际推理时的显存波动导致 OOM。
--speculative_config 推测解码配置。Qwen3.5-35B-A3B 支持 MTP 推测解码,可以显著提升吞吐。num_speculative_tokens: 3 表示每次推测 3 个 token。
--compilation-config 图编译配置。FULL_DECODE_ONLY 模式只在解码阶段使用图优化,是目前推荐的配置。
验证部署:真的能跑吗?
服务启动后,用 curl 发个请求验证一下:
curl http://localhost:8000/v1/completions \
-H "Content-Type: application/json" \
-d '{
"model": "qwen3.5-35b-a3b",
"prompt": "The future of AI is",
"max_completion_tokens": 50,
"temperature": 0
}'如果返回了正常的 completion 结果,恭喜,基础部署已经成功。
性能评估
精度验证
用 AISBench 跑一下 gsm8k 基准测试,量化版的准确率可以达到 96.74%,和原版几乎无异。这意味着你可以放心使用量化版本,不用为那一点点精度损失纠结。
吞吐测试
vLLM 提供了内置的 benchmark 工具:
export VLLM_USE_MODELSCOPE=true
vllm bench serve \
--model Eco-Tech/Qwen3.5-35B-A3B-w8a8-mtp \
--dataset-name random \
--random-input 200 \
--num-prompts 200 \
--request-rate 1 \
--save-result \
--result-dir ./几分钟就能拿到完整的性能报告,包括 TTFT、TPOT、吞吐等核心指标。
遇到过的那些坑
坑一:显存碎片化
PyTorch 在 NPU 上容易出现显存碎片,导致明明还有显存却报 OOM。解决方法就是开头那个环境变量:
export PYTORCH_NPU_ALLOC_CONF=expandable_segments:True坑二:多节点通信超时
多节点部署时,HCCL 通信超时是常见问题。检查以下几点:
-
所有节点的网络是否互通
-
防火墙是否放行了必要端口
-
HCCL_BUFFSIZE是否设置合理
坑三:Prefix Caching 的陷阱
Qwen3.5-35B-A3B 是 Hybrid 架构,开启 Prefix Caching 可能导致 block_size 异常增大(比如跳到 2048)。这意味着短于 2048 的前缀都不会被缓存。生产环境建议先关闭,等官方优化后再开启。
在昇腾 910B2 上部署 Qwen3.5-35B-A3B,本质上是在验证一条技术路线:国产算力 + 开源大模型 = 自主可控的 AI 基础设施。真实环境千差万别,遇到问题时,最好的调试工具永远是日志和耐心。