Claude Code 是 Anthropic 推出的终端 AI 编程助手。与普通的聊天式 AI 不同,它直接在终端里工作,能够读取代码、执行命令、修改文件、管理 Git 操作。阅读其源码后,可以从 Agent 循环、上下文工程、提示词工程和多 Agent 协同几个维度梳理出它的设计脉络。
整体架构
Claude Code 的核心是一个典型的 ReAct Agent 架构,入口是 query() 函数,它内部委托给 queryLoop() ------ 一个通过 while(true) 无限循环驱动的 AsyncGenerator。每一次循环就是一个 turn,完成从上下文准备、模型调用、响应处理到工具执行的完整闭环。
整体架构可以概括为以下几个层次:
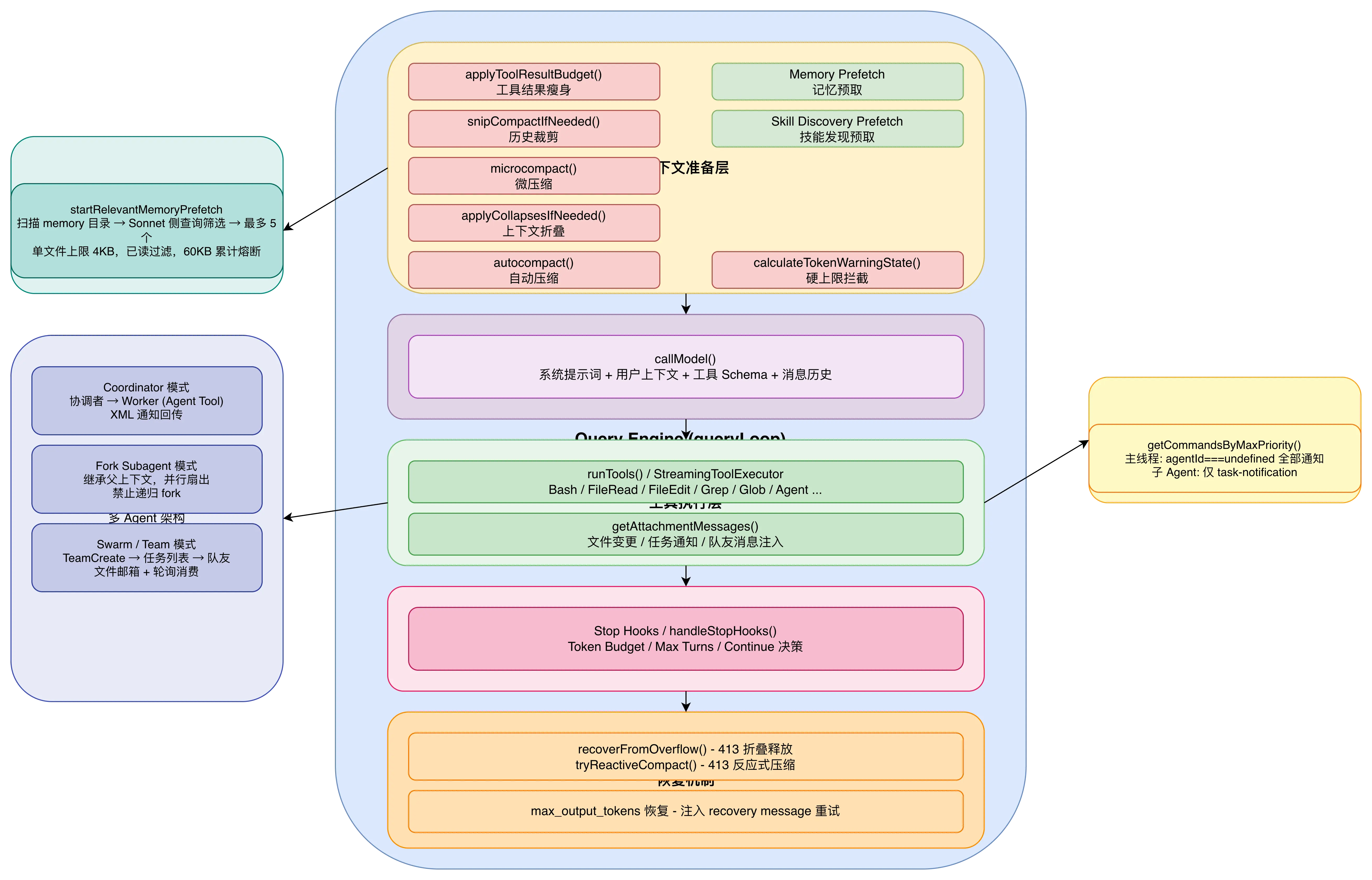
下面按几个核心维度逐一拆解。
Agent 循环:queryLoop 的运转机制
设计思想
Claude Code 的 Agent 循环采用了 AsyncGenerator + while(true) 的组合。选择 AsyncGenerator 而非简单 async function 的原因很直接:每一轮循环都会向 UI 层 yield 流式事件,调用方可以在循环执行过程中实时渲染模型输出和工具执行进度。如果用普通 async function,只能等整个 turn 结束后才返回结果,用户体验会断掉。
状态管理上,Claude Code 没有把状态分散在各个局部变量里,而是定义了一个 State 对象,在每次 continue 时整体替换:
typescript
type State = {
messages: Message[]
toolUseContext: ToolUseContext
autoCompactTracking: AutoCompactTrackingState
maxOutputTokensRecoveryCount: number
hasAttemptedReactiveCompact: boolean
maxOutputTokensOverride: number | undefined
pendingToolUseSummary: Promise<ToolUseSummaryMessage | null> | undefined
stopHookActive: boolean | undefined
turnCount: number
transition: Continue | undefined // 记录上一次循环继续的原因
}这种设计的优势在于:continue 站点只需要构造一个新的 State 对象然后赋值 + continue,不需要分别更新 9 个变量。同时 transition 字段记录了上一次循环继续的原因,让后续迭代能够基于前一次决策做判断(比如判断上一次是否已经做过 collapse_drain_retry,避免重复操作)。
实现过程
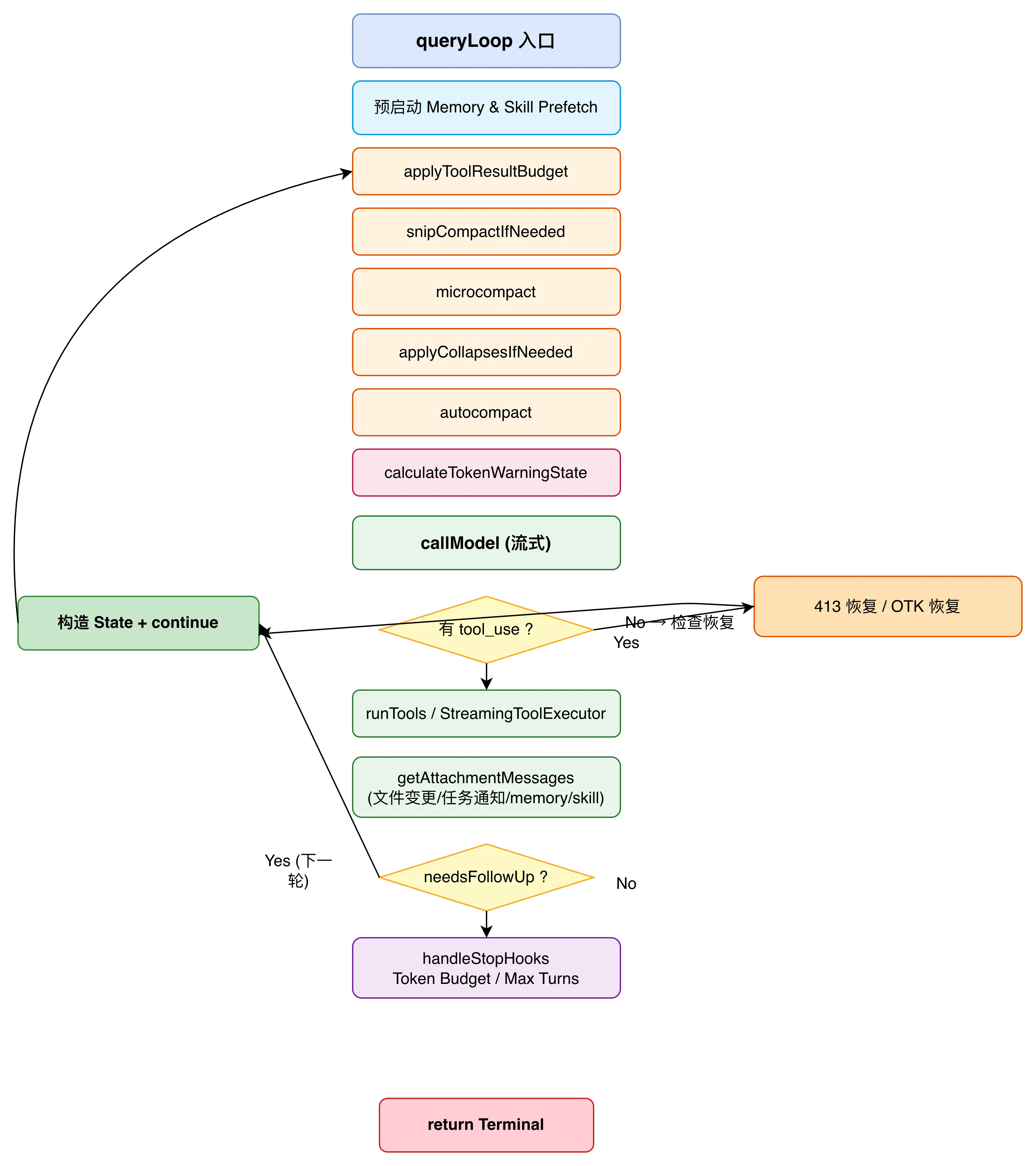
循环的执行流程如下:
第一步:循环前预启动(只执行一次)
startRelevantMemoryPrefetch() 和 startSkillDiscoveryPrefetch() 在循环外启动。这两个操作返回 Promise 句柄,内部异步执行,不阻塞主流程。后续 turn 中通过检查 settledAt 字段判断是否就绪,就绪了就消费。
第二步:上下文准备
每轮 turn 进入后,按顺序执行:
applyToolResultBudget()--- 工具结果瘦身,把超大的 tool_result 替换为摘要snipCompactIfNeeded()--- 历史裁剪,移除过旧的消息microcompact()--- 微压缩,清理过期的 tool resultapplyCollapsesIfNeeded()--- 上下文折叠,分段生成摘要autocompact()--- 自动压缩,最后的兜底策略calculateTokenWarningState()--- 检查是否触及硬上限
这些步骤不是互斥的。snip 在 microcompact 之前执行,因为两者都可能运行。collapse 在 autocompact 之前执行,因为如果折叠能把上下文压到 autocompact 阈值以下,autocompact 就变成 no-op,从而保留更细粒度的上下文。
第三步:模型调用
通过 callModel() 将组装好的消息发给 API。流式返回的消息逐条 yield 给 UI,同时收集到 assistantMessages 数组中。遇到 tool_use 块就记录到 toolUseBlocks,设置 needsFollowUp = true。
第四步:工具执行
needsFollowUp 为 true 时进入工具执行阶段,通过 runTools() 或 StreamingToolExecutor 执行工具调用。
第五步:附件注入
工具执行完毕后,调用 getAttachmentMessages() 注入各类附件:文件变更通知、任务通知、memory 预取结果、skill 预取结果。
第六步:决策
如果没有 follow-up(模型没有请求工具),进入决策层:执行 Stop Hooks、检查 Token Budget、判断 Max Turns,然后决定是否继续。
核心循环的伪代码:
plain
async function* queryLoop(params):
state = initialState(params)
pendingMemoryPrefetch = startRelevantMemoryPrefetch(state.messages)
while true:
// --- 上下文准备 ---
pendingSkillPrefetch = startSkillDiscoveryPrefetch(messages)
messagesForQuery = applyToolResultBudget(messages)
messagesForQuery = snipCompactIfNeeded(messagesForQuery)
messagesForQuery = microcompact(messagesForQuery)
messagesForQuery = applyCollapsesIfNeeded(messagesForQuery)
messagesForQuery, compactionResult = autocompact(messagesForQuery)
// --- 硬上限拦截 ---
if isAtBlockingLimit(messagesForQuery):
yield APIErrorMessage
return { reason: 'blocking_limit' }
// --- 模型调用 ---
for await message in callModel(messagesForQuery, systemPrompt, tools):
yield message
if message.type == 'assistant':
assistantMessages.push(message)
toolUseBlocks.extend(extractToolUseBlocks(message))
// --- 工具执行 ---
if toolUseBlocks:
for update in runTools(toolUseBlocks):
yield update.message
toolResults.push(update.message)
// --- 附件注入 ---
for attachment in getAttachmentMessages(...):
yield attachment
toolResults.push(attachment)
// 消费 memory prefetch(如果已就绪)
if pendingMemoryPrefetch.settledAt and not consumed:
for mem in pendingMemoryPrefetch.promise:
yield createAttachmentMessage(mem)
toolResults.push(mem)
// 消费 skill prefetch
for skill in collectSkillDiscoveryPrefetch(pendingSkillPrefetch):
yield createAttachmentMessage(skill)
toolResults.push(skill)
// --- 决策 ---
if not needsFollowUp:
// 处理 413 恢复、max_output_tokens 恢复
// 执行 Stop Hooks
// 检查 Token Budget / Max Turns
if shouldContinue:
state = newStateWithContinueReason(...)
continue
return { reason: 'completed' }
// 有 follow-up,构建下一轮 state
state = {
messages: [...messagesForQuery, ...assistantMessages, ...toolResults],
turnCount: turnCount + 1,
...
}流式 fallback 与错误恢复
模型调用阶段有一个 streaming fallback 机制。如果流式调用过程中触发了 FallbackTriggeredError(通常是模型负载过高),系统会:
- 清空当前轮收集的所有 assistantMessages 和 toolResults
- 将模型切换到 fallbackModel
- 丢弃
StreamingToolExecutor的 pending 结果,重建新的 executor - 重新发起完整请求
fallback 触发时,还会 yield 一个 tombstone 消息给 UI 层,让前端移除上次流式调用产生的不完整内容。
Agent 架构细节
工具结果预算控制
设计思想
工具调用的返回结果(比如 BashTool 执行 ls -la / 的输出、FileReadTool 读取一个大文件的内容)可能非常庞大。如果不加限制地全部塞进上下文,几次工具调用就能吃光整个 token 预算。
Claude Code 的设计思路是:不直接丢弃原始内容,而是替换为摘要,同时在摘要里保留原始内容的文件路径。模型如果觉得摘要不够,可以主动通过 Read 工具去读取全文。这本质上是一种 lazy loading 策略。
实现过程
applyToolResultBudget() 的执行过程分四步:
- collectCandidatesByMessage --- 按 API 消息序列分组,把同一轮流式返回的多个 tool_result 候选收集到一起共享预算
- partitionByPriorDecision --- 对每组候选按历史决策分区:
mustReapply:之前已经被替换成摘要的结果,直接用缓存的 preview 重放,不需要重新决策frozen:之前已经见过但模型已经读取过的结果,标记为冻结,不能再改动。改动会破坏 prompt cache 的字节匹配fresh:首次见到的结果,可以做替换决策
- selectFreshToReplace --- 如果 frozen + fresh 的总大小超过 200KB 阈值,从 fresh 中选最大的先替换。选择策略是贪心的:按大小降序排列,从最大的开始替换,直到总大小降到阈值以下
- persistToolResult + buildLargeToolResultMessage --- 被选中的结果先写入磁盘文件,然后生成 preview 字符串替换原始内容。preview 中会包含完整内容的文件路径
plain
applyToolResultBudget(messages, contentReplacementState)
│
├─ state === undefined → 直接返回(feature 关闭)
│
└─ enforceToolResultBudget()
│
├─ 1. collectCandidatesByMessage()
│ 按 API 消息序列分组,同一序列的 tool_result 共享预算
│
├─ 2. 对每组消息执行:
│ ├─ partitionByPriorDecision()
│ │ ├─ mustReapply: 之前替换过 → 复用缓存的 preview
│ │ ├─ frozen: 之前见过但模型已读取 → 冻结不动
│ │ └─ fresh: 首次见到 → 进入替换决策
│ │
│ ├─ frozen + fresh 总量 > 200KB?
│ │ ├─ YES → selectFreshToReplace()
│ │ │ 按大小降序,从最大的开始替换
│ │ └─ NO → 全部标记为 seen,跳过
│ │
│ └─ 被选中的结果:
│ ├─ persistToolResult() → 写磁盘
│ └─ buildLargeToolResultMessage() → 生成 preview
│
├─ 3. replaceToolResultContents()
│ 用 preview 字符串替换原始内容
│
└─ 4. 返回 { messages, newlyReplaced }缓存持久化(contentReplacementState)是关键设计。因为下一轮循环时,同一批 tool_result 会再次经过 applyToolResultBudget(),系统需要知道哪些已经被替换过(mustReapply),哪些是模型读取过的(frozen)。这个状态只在 agentId 或 repl_main_thread 的 querySource 下才会持久化到磁盘,确保 resume 会话能恢复状态。
多级压缩策略
设计思想
Claude Code 的压缩体系不是一刀切的,而是按影响范围和成本分了四个层次。设计的核心原则是:能用便宜操作的就不用贵的,能保留细粒度上下文的就不做全局摘要。
四个层次从轻量到重量排列:
- snipCompact --- 裁剪旧消息,直接删除,零成本
- microcompact --- 清理过期的 tool result,利用
cache_editsAPI 保持 KVCache - collapse --- 分段折叠,每段生成独立摘要,保留部分结构
- autocompact --- 全局压缩,生成整个对话的摘要替换历史,成本最高
实现过程
microcompact 的处理逻辑:
- 检查距离上一次 AI 消息的时间是否超过阈值
- 如果超时,直接清空过期的 tool result
- 如果启用了
CACHED_MICROCOMPACT,走cachedMicrocompactPath:- 依赖 Claude Code 的
cache_editsAPI - 将压缩操作作为缓存编辑提交给服务端
- 服务端返回实际的
cache_deleted_input_tokens - 客户端用实际值替换预估的 token 删除数
- 边界消息(boundary message)延迟到 API 响应后才 yield,确保使用真实的 token 数据
- 依赖 Claude Code 的
**为什么使用 ****cache_edits**会又块又节省 token?
要理解这一点,需要先了解 Anthropic API 的 prompt caching 机制。当请求中包含 cache_control: { type: 'ephemeral' } 标记时,API 服务端会缓存该标记位置之前所有消息的 KVCache(Key-Value Cache,即 transformer 模型中 attention 计算产生的中间状态)。下一轮请求如果前缀字节完全一致,服务端可以直接复用缓存的 KV,不需要重新 prefill,从而显著降低延迟和 token 消耗。
问题是:当我们要删除某些旧的 tool result 时,如果直接修改消息内容,整个前缀的字节序列就变了,KVCache 全部失效,服务端必须重新 prefill 全部内容。这就是传统压缩的代价------你节省了上下文 token 数量,但浪费了 cache 命中率。
cache_edits API 解决了这个矛盾。它的工作方式是:
- 客户端在请求体中额外附带一个
cache_edits块,声明要删除哪些内容 - 服务端收到请求后,先匹配前缀 KVCache(此时前缀未变,cache 命中),然后再执行删除操作
- 删除操作是在 cache 命中之后进行的,所以不会影响前缀的 cache 命中率
autocompact 的处理逻辑:
- 守卫检查:
DISABLE_COMPACT开启则跳过 - 熔断器检查:连续失败次数达到阈值则跳过
shouldAutoCompact()判断是否需要压缩- 优先尝试
trySessionMemoryCompaction()--- 将对话信息提取到 session memory 中,然后删除旧消息 - 如果 session memory 方式不可用,兜底执行
compactConversation()--- 生成整个对话的摘要替换全部历史 - 失败时递增失败计数,触发熔断
执行顺序也很讲究。collapse 在 autocompact 之前执行,因为 collapse 是一个 read-time 的 view projection,不会真正删除消息。如果 collapse 能把上下文压到 autocompact 阈值以下,autocompact 就变成 no-op,从而保留更细粒度的上下文而不是一个粗粒度的摘要。
这些压缩机制都通过 bun:bundle 的 feature() 函数进行编译期树摇。外部构建可以完全剔除未启用的功能代码,减小包体积。
设计思想
当上下文超出模型限制,API 返回 413 (prompt too long) 错误时,Claude Code 不是简单报错退出,而是设计了渐进式的恢复路径。核心思路是:先做便宜的恢复(保留更多上下文),不行再做重量级恢复。
实现过程
恢复流程分两层:
- recoverFromOverflow() --- 折叠释放
- 将所有 staged 的 context collapses 提交
- 这是一个相对便宜的操作,只释放之前已经计算好的折叠摘要
- 保留了细粒度的上下文结构
- 如果没有 staged collapses 或已经执行过(通过
transition.reason === 'collapse_drain_retry'判断),则跳过
- tryReactiveCompact() --- 反应式压缩
- 当折叠释放不够用时触发
- 做一次完整的摘要压缩,替换历史消息
- 有
hasAttemptedReactiveCompact守卫,防止重复执行 - 如果 oversized 的是媒体内容(图片/PDF),跳过 collapse drain 直接走这层,因为 collapse 不处理图片
max_output_tokens 错误也有类似的恢复路径:
- 首先尝试 escalation:如果使用了 capped 8k 默认值,将
maxOutputTokensOverride提升到 64K,用同样的消息重试 - 如果仍然超出,进入 multi-turn recovery:注入一条 meta 消息告诉模型 "Output token limit hit. Resume directly --- no apology, no recap",最多重试 3 次
- 3 次重试后用 withheld 的错误消息终止循环
上下文工程:精细化控制每一点 token
Memory 预取机制
设计思想
Memory 系统的设计目标很明确:让 Agent 能在跨会话中积累知识并复用。但注入太多记忆会浪费 token,注入不相关的记忆会干扰模型判断。所以需要在检索的准确性和注入的成本之间做平衡。
实现过程
startRelevantMemoryPrefetch() 在循环外启动,返回一个 MemoryPrefetch 句柄。整个流程包括:
- 功能开关检查 --- 判断
isAutoMemoryEnabled()和对应的 feature flag - 提取用户消息 --- 获取最后一条真实用户消息,跳过
isMeta标记的系统注入消息 - 词长过滤 --- 单词数少于 2 个的查询直接跳过,不浪费检索资源
- 累计熔断 --- 检查会话累计已注入字节是否 >= 60KB,达到上限后停止预取
- 异步搜索 --- 启动不阻塞主流程的后台检索
检索过程的具体实现:
- 扫描 memory 目录,读取所有文件的 header
- 用 Sonnet 模型的
sideQuery做相关性评分,选出最多 5 个相关记忆 - 读取每个记忆的内容,单文件上限 4KB,超出截断
消费阶段在 getAttachmentMessages() 中进行:
- 检查
pendingMemoryPrefetch.settledAt !== null判断是否就绪 - 检查
consumedOnIteration === -1避免重复消费 - 通过
filterDuplicateMemoryAttachments()过滤已读取过的文件(基于readFileState判断) - 将过滤后的记忆转为
AttachmentMessage注入
plain
startRelevantMemoryPrefetch(messages, toolUseContext)
│
├─ 1. isAutoMemoryEnabled() + feature flag?
│ └─ NO → 返回 null
│
├─ 2. 提取最后一条非 isMeta 用户消息
│ └─ 单词数 < 2? → 返回 null
│
├─ 3. 会话累计注入字节 >= 60KB?
│ └─ YES → 返回 null
│
├─ 4. 启动异步搜索(fire-and-forget)
│ └─ getRelevantMemoryAttachments()
│ ├─ 扫描 memory 目录,读取文件 header
│ ├─ Sonnet sideQuery 评分 → 最多选 5 个
│ └─ 读取内容(单文件 4KB 上限)
│
└─ 5. 返回 MemoryPrefetch 句柄
后续 turn 中通过 settledAt 和 consumedOnIteration 判断消费时机这套设计有几个值得注意的细节。已读取过的文件通过 readFileState 过滤,这是 cumulative 的状态,跨 turn 累加,确保同一份记忆不会被重复注入。Sonnet 筛选保证了选出的 5 个文件与当前上下文的相关度最高。每个文件只读取 4KB,这个量级大致只够做开头摘要,至于是否读取全文留给后续工具决策。
Skill 发现预取
设计思想
Skill 是 Claude Code 中自定义的命令集合(类似 .claude/commands/ 目录下的命令)。如果每次 turn 都阻塞式搜索哪些 skill 适用,生产数据显示 97% 的情况下搜不到匹配项,白白浪费时间。所以设计为异步预取。
实现过程
startSkillDiscoveryPrefetch() 每轮 turn 启动一次(与 Memory prefetch 不同,skill prefetch 是每轮都启动的,因为它依赖 findWritePivot 守卫来判断是否是非 write 迭代)。
发现搜索在模型流式返回和工具执行的窗口期内运行,等到工具执行结束后与 memory prefetch 结果一起消费。只有 turn-0 的用户输入 discovery 才会阻塞在 userInputAttachments 中,因为那是唯一一个没有前置工作可以隐藏等待时间的信号。
Command Queue
设计思想
在多 Agent 场景下,子 Agent 完成任务后需要通知父 Agent,用户也可以在中途发送新的消息。Claude Code 用一个进程全局的 CommandQueue 单例来管理这些异步消息。
关键设计是消息的作用域隔离。队列是进程全局的,Coordinator 和所有 in-process 子 Agent 共享同一个队列。每个 Agent 在循环中只 drain 属于自己的消息:
- 主线程(
agentId === undefined):获取所有非 slash-command 的通知 - 子 Agent:只获取
mode === 'task-notification'且agentId匹配自己的通知 - 用户提示(
mode: 'prompt')始终只发送给主线程,子 Agent 永远不会看到用户的 prompt 流
实现过程
在 query.ts 的每轮 turn 中,工具执行后、附件注入前,会从队列中取出消息:
plain
const sleepRan = toolUseBlocks.some(b => b.name === SLEEP_TOOL_NAME)
const queuedCommandsSnapshot = getCommandsByMaxPriority(
sleepRan ? 'later' : 'next'
).filter(cmd => {
if (isSlashCommand(cmd)) return false // slash command 不走这个路径
if (isMainThread) return cmd.agentId === undefined // 主线程拿所有通知
return cmd.mode === 'task-notification' && cmd.agentId === currentAgentId
})Sleep 工具在这里起调度作用。如果本轮执行了 Sleep,队列优先级切换到 later,否则用 next。这使得不同类型的任务通知可以有不同的调度优先级。
提示词工程
系统提示词的分层构建
设计思想
系统提示词不是单一的字符串,而是由多层组件拼装而成。这种设计让不同来源的配置可以独立演进,互不干扰。
实现过程
构建分三个阶段:
第一阶段:获取基础组件 (fetchSystemPromptParts())
defaultSystemPrompt--- 默认系统提示,定义 Agent 的基本行为userContext--- 来自getUserContext(),包含 CLAUDE.md 内容和当前日期systemContext--- 来自getSystemContext(),包含 git 状态(分支、近期提交、用户等)
getUserContext 和 getSystemContext 都用 memoize 缓存,在对话开始时计算一次,整个对话周期复用。
第二阶段:在 query.ts 中拼接
plain
const systemPrompt = asSystemPrompt([
...(customPrompt ? [customPrompt] : defaultSystemPrompt),
...(memoryMechanicsPrompt ? [memoryMechanicsPrompt] : []),
...(appendSystemPrompt ? [appendSystemPrompt] : []),
])自定义 prompt 存在时替换默认系统提示。memory mechanics prompt 和 append system prompt 作为可选层追加。
第三阶段:在 claude.ts 的 queryModel 中最终组装
plain
systemPrompt = asSystemPrompt([
getAttributionHeader(fingerprint), // 归属头
getCLISyspromptPrefix(...), // CLI 前缀
...systemPrompt, // 上面传下来的系统提示词
...(advisorModel ? [ADVISOR_TOOL_INSTRUCTIONS] : []),
...(injectChromeHere ? [CHROME_TOOL_SEARCH_INSTRUCTIONS] : []),
])上下文注入
消息最终发给模型时,通过 prependUserContext(messagesForQuery, userContext) 将用户上下文插入到消息数组的最前面。系统上下文通过 appendSystemContext(systemPrompt, systemContext) 追加到系统提示词的末尾。
这种 prepend/append 的设计保证了用户上下文(CLAUDE.md 等)出现在消息序列的最前面,离用户输入最近,注意力权重最高。而系统上下文(git 状态等)放在系统提示词最后,作为背景信息。
工具 Schema 构建
工具 schema 的构建流程:
filteredTools--- 按当前权限和可用性过滤工具列表toolToAPISchema--- 将每个工具的定义转换为 API 可接受的 schema 格式toolSchemas + extraToolSchemas--- 合并基础工具 schema 和额外工具 schemaallTools--- 最终发送给模型的完整工具列表
在 Coordinator 模式下,Coordinator 只能看到 4 个工具(Agent、SendMessage、TaskStop、SyntheticOutput),而 Worker 能看到完整的工具池。这个过滤在 toolUseContext.options.tools 中完成,由 coordinatorMode 的配置决定。
多 Agent 架构
Coordinator 模式:编排者与工作者
设计思想
Coordinator 模式是最经典的多 Agent 架构,核心思想是角色分离:Coordinator 负责理解和规划,Worker 负责执行和探索。Coordinator 被刻意限制只能使用 4 个工具,防止它越俎代庖去做具体的代码工作。
工作流分为四个阶段:Research → Synthesis → Implementation → Verification,支持并行研究。
Coordinator 的工具限制
Coordinator 只能使用以下 4 个工具:
- Agent --- 启动新的 Worker
- SendMessage --- 继续已有的 Worker(复用其上下文)
- TaskStop --- 停止运行中的 Worker
- SyntheticOutput --- 合成输出
在 Coordinator 模式下,模型参数被忽略,不允许自选模型。Worker 使用默认模型进行实质性任务。
AgentTool 的调用逻辑
AgentTool.call() 的执行流程:
- 参数解析和前置校验
- Coordinator 模式下忽略 model 参数
- 检查 team_name 参数
- 路由分发
- 如果指定了 team_name,走
spawnTeammate路径,直接进入 team 模式 - 如果没有指定 subagent_type 且 FORK_SUBAGENT 开启,fork 子 Agent(禁止递归 fork)
- 否则在已定义的 agent 列表中查找匹配的 agent
- 如果指定了 team_name,走
- Agent 配置解析
- 等待 MCP 服务器连接
- 解析模型并记录
- 解析 isolation 参数(worktree 或 remote)
- 构建 system prompt 和 prompt messages:
- fork 的 Agent 继承父 Agent 的 system prompt、上下文、tool result 和指令
- 普通 Agent 重新组装,只传递一条单独的简单 user message
- 组装
runAgentParams对象
- 异步/同步 Agent 执行
- 异步 Agent:注册到后台,调用
runWithAgentContext,启用每 30 秒生成进度摘要,返回async_launched状态 - 同步 Agent:保留中途异步化的能力
- 异步 Agent:注册到后台,调用
plain
AgentTool.call()
│
├─ 1. 参数解析 & 前置校验
│ ├─ Coordinator 模式 → 忽略 model 参数
│ └─ 检查 team_name
│
├─ 2. 路由分发
│ ├─ team_name 存在 → spawnTeammate → return
│ ├─ 无 subagent_type + FORK_SUBAGENT → forkSubagent(禁止递归)
│ └─ 有 subagent_type → 查找匹配的 agent 定义
│
├─ 3. Agent 配置解析
│ ├─ 等待 MCP 服务器连接
│ ├─ 解析模型
│ ├─ 解析 isolation(worktree / remote)
│ └─ 构建 system prompt 和 messages
│ ├─ fork: 继承父 Agent 的完整上下文
│ └─ 普通: 单条 user message
│
├─ 4. 执行
│ ├─ 异步: runAsyncAgentLifecycle() → fire-and-forget
│ │ 后台执行,实时更新 UI 进度
│ │ stream 结束后 → finalizeAgentTool()
│ │ → completeAsyncAgent()
│ │ → enqueueAgentNotification()
│ └─ 同步: 阻塞等待结果
│
└─ 5. 返回 { status: 'async_launched', agentId }异步 Agent 的通知机制
异步 Agent 通过以下流程与父 Agent 通信:
runAsyncAgentLifecycle()在后台执行,通过for await (msg of runAgent())逐条消费 Agent 输出- 实时更新 UI 进度(
updateAsyncAgentProgress()) - Stream 结束后,
finalizeAgentTool()提取运行结果 completeAsyncAgent()标记任务状态为 completedenqueueAgentNotification()构造 XML 通知推入全局commandQueue
父 Agent 在下一个 turn 开始时从队列中 drain 这些通知,作为 AttachmentMessage 注入。模型看到 <task-notification> XML 后处理结果并决定下一步。
plain
AgentTool.call()
│
+--[异步] void runAsyncAgentLifecycle() ←── fire-and-forget
| │
| +-- for await (msg of runAgent()) ←── 后台执行,逐条消费
| | updateAsyncAgentProgress() ←── 实时更新 UI 进度
| │
| +-- finalizeAgentTool() ←── stream 结束
| +-- completeAsyncAgent() ←── task.status = 'completed'
| +-- enqueueAgentNotification() ←── 构造 XML
| │
| +-- enqueuePendingNotification() ←── 推入全局 commandQueue
| │
| +-- notifySubscribers() ←── 唤醒订阅者
│
+--[立即] return { status: 'async_launched', agentId }
... 父 Agent 继续做其他事 ...
父 Agent 下一个 turn:
query.ts 主循环
│
+-- getCommandsByMaxPriority() ←── 从 commandQueue drain
+-- getQueuedCommandAttachments() ←── 转为 attachment
+-- yield AttachmentMessage ←── 作为 user message 注入
│
Claude 看到 <task-notification> XML ←── 处理结果,决定下一步Coordinator 的提示词设计
Coordinator 的系统提示词有一个非常关键的设计:它被明确告知 "Workers can't see your conversation",所以每个 Worker prompt 必须是自包含的。这防止了 Coordinator 写出 "基于我们刚才讨论的内容" 这种依赖对话历史的无效 prompt。
Research 完成后,Coordinator 被要求自己做 Synthesis ------ 不是简单地把研究结果转发给下一个 Worker,而是自己理解后发现,写出具体的文件路径、行号和变更内容。提示词中给出了明确的反例和正例:
plain
// 反例 ------ 懒惰委托
AgentTool({ prompt: "Based on your findings, fix the auth bug" })
// 正例 ------ 自己理解后合成规格
AgentTool({ prompt: "Fix the null pointer in src/auth/validate.ts:42.
The user field on Session (src/auth/types.ts:15) is undefined when
sessions expire. Add a null check before user.id access." })Fork Subagent 模式:上下文继承与并行扇出
设计思想
Fork 模式的核心价值是上下文继承。与 Coordinator 模式下 Worker 获得独立 prompt 不同,Fork 子 Agent 继承父 Agent 的完整对话历史。这在需要并行探索同一个代码库的不同角度时特别有用。
实现过程
为了最大化 prompt cache 命中率,所有 Fork 子 Agent 的 API 请求前缀必须是字节级一致的。buildForkedMessages() 的实现很巧妙:
- 保留完整的父 assistant 消息(包含所有 tool_use 块)
- 为每个 tool_use 块生成统一的占位 tool_result(
FORK_PLACEHOLDER_RESULT = "Fork started --- processing in background") - 附加每个子 Agent 独有的指令
plain
buildForkedMessages(directive, assistantMessage):
│
├─ fullAssistantMessage = clone(assistantMessage)
│ 保留所有 tool_use 块、thinking、text
│
├─ toolUseBlocks = extract all tool_use blocks
│
├─ toolResultBlocks = toolUseBlocks.map(block => {
│ type: 'tool_result',
│ tool_use_id: block.id,
│ content: FORK_PLACEHOLDER_RESULT // 所有子 Agent 完全一致
│ })
│
└─ return [
fullAssistantMessage, // 完全一致
createUserMessage([
...toolResultBlocks, // 完全一致
{ text: buildChildMessage(directive) } // 每个子 Agent 不同
])
]这样构造的结果是:所有 Fork 子 Agent 的 API 请求只有最后一个 text block 不同,前面的消息内容完全一致,最大化 prompt cache 命中。
Fork 有一个重要限制:禁止递归 fork。源码中通过 isInForkChild() 检测消息中是否存在 FORK_BOILERPLATE_TAG 来实现。Fork 子 Agent 的 system prompt 中也有明确规则:"Your system prompt says 'default to forking.' IGNORE IT --- that's for the parent. You ARE the fork. Do NOT spawn sub-agents."
Fork 子 Agent 还通过 permissionMode: 'bubble' 让权限提示冒泡到父终端,通过 model: 'inherit' 保持与父 Agent 相同的模型选择,确保上下文长度一致。
Swarm / Team 模式:多队友协作
设计思想
Swarm 模式引入了真正的团队概念。与 Coordinator 模式下 Coordinator 通过 Agent tool 直接管理 Worker 不同,Swarm 模式中有一个 Team Leader 和多个 Teammate,队友之间可以通过任务列表自主 claim 任务。
Team = TaskList。创建团队的同时创建对应的任务列表,任务所有权通过 TaskUpdate 的 owner 参数管理。队友的主循环是:findAvailableTask() → tryClaimNextTask() → runAgent() → sendIdleNotification()。
实现过程
团队创建
TeamCreateTool 的执行流程:
- 检查是否已经在团队中(一个 Leader 只能管理一个团队)
- 生成唯一的 team name(如果名称冲突则生成新的 word slug)
- 生成确定性的 Lead Agent ID:
formatAgentId(TEAM_LEAD_NAME, teamName) - 读取当前模型的配置(处理 session model、settings、CLI 覆盖)
- 写入 Team File(
.claude/teams/{team_name}/team.json) - 重置并创建对应的 Task List 目录(确保任务编号从 1 开始)
- 注册团队名称到 Leader 上下文,更新 AppState
队友初始化
队友(teammate)启动时通过 initializeTeammateHooks() 注册 Stop hook:
- 读取 team file,获取 Leader 的 Agent ID
- 查找 Leader 的名字
- 如果当前 Agent 就是 Leader,跳过(Leader 不需要给自己发 idle 通知)
- 注册 Stop hook:
- 当 Agent 的 turn 结束时触发
- 标记自己不活跃(
setMemberActive(teamName, agentName, false)) - 创建
idle_notification写入 Leader 的邮箱
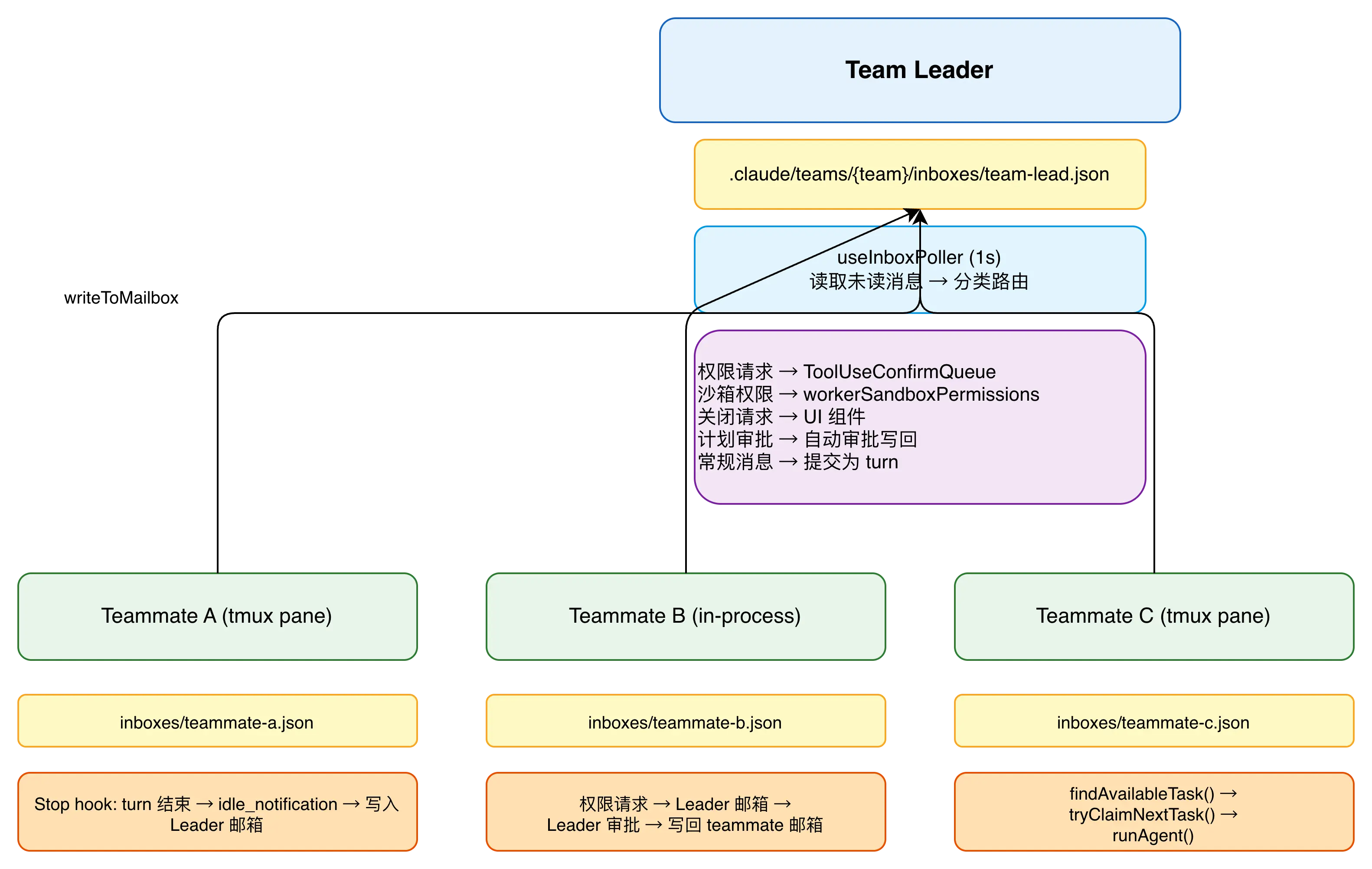
跨进程通信:文件邮箱系统
Swarm 模式最有趣的设计是跨进程通信。队友可以是同进程(in-process teammate),也可以是独立进程(tmux pane 或 iTerm2 pane),所以需要一种通用的通信机制。
Claude Code 选择了基于文件的邮箱系统:
- 每个队友的收件箱路径:
.claude/teams/{team_name}/inboxes/{agent_name}.json - 写操作通过
writeToMailbox()完成,使用proper-lockfile防止并发写入冲突 - 锁重试配置:最多 10 次,退避时间 5ms-100ms
plain
writeToMailbox(recipientName, message, teamName):
│
├─ ensureInboxDir(teamName)
│
├─ inboxPath = .claude/teams/{team}/inboxes/{agent}.json
├─ lockPath = inboxPath + .lock
│
├─ 确保收件箱文件存在(flag: 'wx',已存在则忽略)
│
├─ lockfile.lock(inboxPath, { retries: 10, minTimeout: 5, maxTimeout: 100 })
│
├─ readMailbox() → messages(获取锁后重新读取最新状态)
│
├─ messages.push({ ...message, read: false })
│
├─ writeFile(inboxPath, JSON.stringify(messages))
│
└─ release lockTeam Leader 的轮询消费
Team Leader 通过 useInboxPoller 每 1 秒轮询自己的邮箱:
plain
useInboxPoller(poll):
│
├─ 每 1000ms 执行一次 poll()
│
├─ poll():
│ ├─ agentName = getAgentNameToPoll(appState)
│ │ 跳过 in-process teammate(有自己的轮询机制)
│ │ Teammate 返回 getAgentName()
│ │ Team Lead 返回 teamContext.teammates[leadAgentId].name
│ │
│ ├─ unread = readUnreadMessages(agentName, teamName)
│ │
│ ├─ 按消息类型分类:
│ │ ├─ permissionRequests → 路由到 ToolUseConfirmQueue
│ │ ├─ permissionResponses → 处理权限回调
│ │ ├─ sandboxPermissionRequests → workerSandboxPermissions 队列
│ │ ├─ sandboxPermissionResponses → 处理沙箱回调
│ │ ├─ shutdownRequests → 传递给 UI 组件
│ │ ├─ shutdownApprovals → 关闭 pane + 清理团队状态
│ │ ├─ teamPermissionUpdates → 应用权限更新
│ │ ├─ modeSetRequests → 设置队友模式
│ │ ├─ planApprovalRequests → 自动审批并写回
│ │ └─ regularMessages → 常规消息
│ │
│ ├─ 如果没有 regularMessages → markRead() + return
│ │
│ ├─ 格式化 regularMessages 为 XML:
│ │ <teammate_message teammate_id="..." color="..." summary="...">
│ │ {message text}
│ │ </teammate_message>
│ │
│ ├─ 如果 idle(!isLoading && !focusedInputDialog):
│ │ onSubmitTeammateMessage(formatted) → 立即作为新 turn 提交
│ │
│ └─ 如果 busy:
│ 消息入队 AppState.inbox → 等空闲时投递
│
└─ 空闲时交付 pending messages(useEffect)
格式化 → onSubmitTeammateMessage → 清除已提交的消息邮箱系统的协议消息
邮箱不只传递简单文本,还承载了多种结构化协议消息,通过 JSON 序列化后以 type 字段区分:
- PermissionRequest / PermissionResponse --- 工具权限请求/响应。Teammate 需要执行需要审批的工具时,写入 PermissionRequest 到 Leader 的邮箱。Leader 通过 UI 审批后,写回 PermissionResponse
- SandboxPermissionRequest / SandboxPermissionResponse --- 沙箱网络访问权限。当沙箱运行时检测到非允许主机的网络连接时触发
- PlanApprovalRequest / PlanApprovalResponse --- 计划审批。Teammate 在 plan 模式下完成计划后,请求 Leader 审批
- ShutdownRequest / ShutdownApproved / ShutdownRejected --- 关闭请求。Leader 发送 shutdown_request 给队友,队友可以批准或拒绝
- TeamPermissionUpdate --- 团队权限广播。Leader 修改权限后广播给所有队友
- ModeSetRequest --- 模式设置。Leader 修改队友的 permission mode
- IdleNotification --- 空闲通知。队友 turn 结束时通过 Stop hook 写入
与 OpenClaw 的设计对比
Claude Code 和 OpenClaw 都是 Agent 驱动的产品,但阅读两者的源码会发现,它们在 Agent 循环、上下文管理和多 Agent 通信上的设计思路有显著差异。这些差异不是技术能力的差距,而是产品定位不同导致的架构分叉。关于 OpenClaw 的具体介绍可以看:OpenClaw架构与实现解析
定位差异:专用工具 vs 通用平台
Claude Code 是 Anthropic 自家的产品,深度绑定 Claude API。它的设计目标是把一个 Agent 做到极致------极致的上下文控制、极致的 cache 利用、极致的单用户体验。所有压缩策略都围绕 cache_edits API 设计,所有消息格式都围绕 Anthropic 的 message schema 构建。
OpenClaw 是一个通用 Agent 平台,需要对接所有主流厂商(Anthropic、OpenAI、Google、Ollama 等),支持多种消息通道(Discord、Telegram、WhatsApp、Slack、Web UI),并且允许插件注入自定义的上下文管理逻辑和安全守卫。它的设计目标是可扩展性和多厂商适配,而非对单一 API 的深度优化。
Agent 实现的差异:手写工具 vs 框架包装
Claude Code:手写完整的 Agent 循环
Claude Code 的 queryLoop() 从零手写了整个 Agent 循环。query.ts 里 1700 多行代码完整实现了:上下文准备管线(6 层压缩)、模型调用、工具执行、附件注入、停止决策、错误恢复。没有任何外部 Agent 框架参与。
这背后的原因是 Claude Code 的定位------它是一个工具,不是一个平台。Anthropic 控制从 API 到客户端的整个栈,有动机也有能力对每个环节做深度优化。手写循环让他们可以在精确的位置插入精确的逻辑:在 snipCompact 和 microcompact 之间插入 applyCollapses,在工具执行后注入 getAttachmentMessages,在 413 错误时走 recoverFromOverflow 而不是直接报错。每一行代码都为 Claude API 服务。
OpenClaw:包装 PI 框架,提供平台能力
OpenClaw 的 Agent 核心不是自己写的,而是复用了 @mariozechner/pi-coding-agent 库(简称 PI 框架)。它的职责不是实现 Agent 循环,而是围绕 PI 框架做包装和适配:
- 多厂商 API 适配层 :
runEmbeddedPiAgent()内部通过streamSimple(来自@mariozechner/pi-ai)统一调用不同厂商的 API。Claude、OpenAI、Google、Ollama 的流式接口各不相同,PI 框架把它们统一成一致的AsyncGenerator接口。OpenClaw 在此基础上再做模型选择、鉴权、重试和降级 - SessionManager 生命周期管理 :PI 框架的
SessionManager负责管理对话历史、工具注册、消息流转。OpenClaw 负责创建、持久化、预热 SessionManager,处理 session 文件锁、transcript 修复、compaction 重试 - 插件和扩展点 :OpenClaw 在 PI 框架外围构建了完整的插件体系------
before_prompt_build、before_agent_start钩子,ContextEngine可插拔接口,安全守卫注入。这些都不是 PI 框架提供的,而是 OpenClaw 作为平台的核心价值
plain
Claude Code 的 Agent 层次:
┌─────────────────────────────────┐
│ queryLoop() (手写, 1700+ 行) │ ← 完整实现
│ ├── 上下文管线 (6层) │
│ ├── callModel() │ ← 直接调 Anthropic API
│ ├── runTools() │
│ ├── getAttachmentMessages() │
│ └── 决策层 (stop hooks) │
└─────────────────────────────────┘
直接面向 Claude API
OpenClaw 的 Agent 层次:
┌──────────────────────────────────┐
│ OpenClaw 平台层 │ ← 包装 + 适配
│ ├── 多厂商 API 适配 │
│ ├── SessionManager 生命周期 │
│ ├── 插件体系 (钩子/ContextEngine)│
│ ├── 多通道路由 (Discord/Slack..) │
│ └── Gateway 事件总线 │
├──────────────────────────────────┤
│ PI 框架 (@mariozechner/...) │ ← Agent 核心
│ ├── SessionManager │
│ ├── streamSimple (统一 API 调用) │
│ └── 工具注册/消息流转 │
└──────────────────────────────────┘
面向所有厂商 API本质差异 :Claude Code 的 Agent 就是它自己------整个 queryLoop 就是 Agent 循环。OpenClaw 的 Agent 是 PI 框架------OpenClaw 提供的是平台能力:多厂商适配、插件扩展、多通道路由、Gateway 调度。Claude Code 是"工具",把一件事做到极致;OpenClaw 是"平台",让不同的 Agent 实现和插件都能跑起来。
上下文管理的差异
Claude Code:极致精细的内置管线
Claude Code 的上下文管理完全内置,包含 6 层递进管线:
applyToolResultBudget → snipCompact → microcompact → applyCollapses → autocompact → 硬上限拦截。
每一层都有精确的阈值控制和状态跟踪。
关键特点:
- 深度适配 Claude API 的
cache_edits,利用 KVCache 保持能力 - 工具结果分三类(mustReapply/frozen/fresh),每类处理策略不同
- 200KB 工具结果预算、4KB memory 截断、60KB 累计熔断
- 413 错误两层渐进恢复
OpenClaw:插件化的 ContextEngine 接口
OpenClaw 通过 ContextEngine 接口实现上下文管理的可插拔:
typescript
interface ContextEngine {
assemble(params): AssembleResult // 组装上下文
compact(params): CompactResult // 压缩
ingest(params): IngestResult // 摄入新信息
maintenance(params): ContextEngineMaintenanceResult // 维护
}用户可以注册自定义的 ContextEngine 实现,替换默认的压缩和组装逻辑。插件还可以通过 before_prompt_build 和 before_agent_start 钩子注入上下文或修改消息。
关键特点:
- 多厂商适配 :不同 API 有不同的上下文限制和错误模式。OpenClaw 的
pi-embedded-helpers中有专门的 guard 逻辑:isContextOverflowError、isCompactionFailureError、isBillingErrorMessage,针对不同厂商返回不同的错误分类 - 安全守卫 :
resolveContextWindowGuard检查上下文窗口是否低于安全阈值(CONTEXT_WINDOW_HARD_MIN_TOKENS),防止在极端情况下发起请求 - 插件注入:安全插件可以通过钩子在 prompt 构建前插入指令,比如注入 rate limit 提示、安全警告等
- Bootstrap 注入 :
bootstrap-budget管理启动时的上下文注入量,根据剩余预算决定注入多少 bootstrap 文件内容
plain
OpenClaw 上下文组装流程:
│
├─ 1. 加载 Session 历史
│ limitHistoryTurns(sessionKey) → 根据通道类型限制 turn 数
│
├─ 2. Bootstrap 注入
│ resolveBootstrapContextForRun() → 按预算截断
│
├─ 3. ContextEngine.assemble()
│ 可插拔的实现
│ 默认: LegacyContextEngine
│ 自定义: 用户注册的插件引擎
│
├─ 4. 插件钩子: before_prompt_build
│ 可修改 prompt 和 messages
│
├─ 5. 插件钩子: before_agent_start
│ 可做最终修改
│
├─ 6. Context Window Guard
│ evaluateContextWindowGuard() → 低于 MIN 则拒绝
│
└─ 7. 发起请求
多厂商 API 适配层统一调用核心差异总结:Claude Code 的上下文管理是"深度优化"------针对单一 API 做到极致。OpenClaw 的上下文管理是"广度适配"------用接口抽象让不同厂商和插件都能工作。Claude Code 选择深度是因为 Anthropic 控制整个栈,可以做字节级优化;OpenClaw 选择广度是因为它面对的是碎片化的 AI 生态。
多 Agent 通信的差异
在异步 Agent 通信方面,两者的协调模式有一个共同点:Coordinator/主 Agent 启动子 Agent 后都继续做自己的事,子 Agent 完成后通过某种机制把结果送回给父 Agent。但它们的"turn 结束"语义和通信通道截然不同。
Claude Code:循环不结束,轮询消费
Claude Code 的 Coordinator 调用 Agent tool 启动异步 Worker 后,queryLoop 继续运行------它不会 yield 或暂停。Worker 完成后通过 enqueueAgentNotification() 把 XML 通知推入全局 CommandQueue,Coordinator 在下一轮 turn 的开头通过 getCommandsByMaxPriority() 从队列中取出通知,作为 AttachmentMessage 注入。
团队模式下,队友(Teammate)可能运行在不同进程(tmux pane / iTerm2 pane),通过文件邮箱系统通信:写入 .claude/teams/{team}/inboxes/{agent}.json,Leader 每 1 秒轮询一次。
OpenClaw:session_yield 让出,Gateway 事件唤醒
OpenClaw 的主 Agent 调用 sessions_yield 后,当前 turn 直接结束 。queueSessionsYieldInterruptMessage() 通过 agent.steer() 注入一个自定义中断消息,persistSessionsYieldContextMessage() 写入 yield 原因到 session 上下文。整个 Agent 进入等待状态,不再消耗资源。
子 Agent(或外部事件)完成后,通过 Gateway 的事件系统(emitAgentEvent)通知父 Agent。Gateway 检测到父 Agent 处于 yield 等待状态,将其唤醒并注入子 Agent 的结果作为下一条消息,触发新一轮 turn。
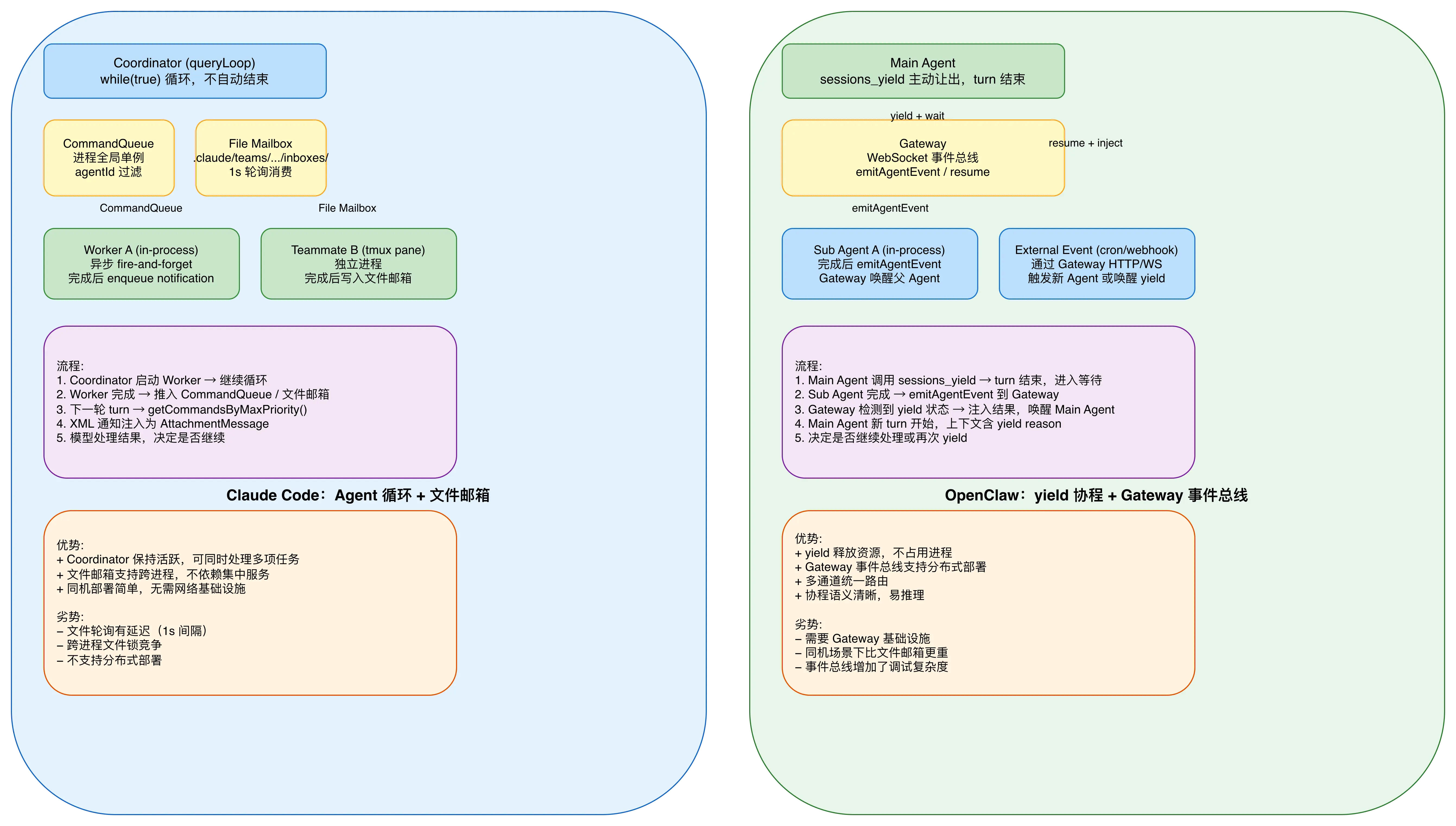
通信通道的本质区别
Claude Code 的文件邮箱系统是"同机优先"的设计。它假设所有 Agent 运行在同一台机器上,通过共享文件系统通信就够了。这在实际使用中是合理的------Claude Code 的目标用户是单机开发者,Team 模式最多扩展到几个 tmux pane。文件系统通信的好处是零依赖:不需要启动额外的服务,不需要网络连接,开箱即用。
OpenClaw 的 Gateway 是"分布式优先"的设计。Gateway 是一个独立的 WebSocket 服务,所有 Agent 实例(无论是同进程、同机不同进程、还是远程机器)都通过 Gateway 通信。这使得 OpenClaw 可以部署在云服务器上,Agent 可以分布在不同的节点。代价是必须维护 Gateway 基础设施,增加了系统复杂度。
相同点
两者在异步 Agent 的核心思想上是一致的:父 Agent 启动子 Agent 后不阻塞等待,子 Agent 完成后通过某种通知机制把结果送回。这都体现了"非阻塞优先"的设计理念。两者的 CommandQueue 和 Gateway 事件总线在功能上是等价的------都是解耦生产者和消费者的消息通道。
不同点的根源
这些差异都可以追溯到产品定位。Claude Code 是一个精心打磨的单机编程工具,Anthropic 控制整个技术栈,可以做深度优化。OpenClaw 是一个通用的 Agent 平台,需要适配多厂商、多通道、多部署场景,必须在灵活性和深度优化之间做取舍。Claude Code 选择了深度,OpenClaw 选择了广度。两者没有对错之分,只是各自服务于不同的用户群体和使用场景。
总结
Claude Code 的架构设计中,有几个贯穿始终的设计原则:
非阻塞优先。Memory 预取、Skill 发现、工具执行总结都是异步启动、按需消费的模式。主流程绝不等待可能没有结果的后台操作。97% 的 skill 搜索命中率意味着阻塞式搜索几乎总是浪费时间。
精细化控制。从 tool result 的三类分区(mustReapply/frozen/fresh),到 memory 文件的 4KB 截断和已读过滤,到 60KB 的累计熔断,到 fork 子 Agent 的字节级 cache 对齐,每个环节都在精打细算 token 和 cache 的使用。
Agent 间通信解耦。Coordinator 模式的 XML 通知、Fork 模式的继承上下文、Swarm 模式的文件邮箱,都保持了 Agent 间的松耦合。每个 Agent 不需要知道对方是谁,只需要按照协议读写。文件邮箱系统通过 JSON 类型区分、文件锁序列化、轮询投递,实现了跨进程的可靠消息传递。
一些个人见解-关于Claude Code的"遥遥领先"
Claude Code的代码泄漏让我们得以窥见其内部运作的精妙,但这并不意味着它就是AI编程领域的唯一真理。Claude Code的设计优秀,更多体现的是Anthropic在特定技术路径上的深耕,而非AI编程助手的终极形态。
这恰恰是我们在评估AI工具时最需要警惕的认知陷阱。今天也有不少人因为看到Claude Code使用体验不错,Agent设计又用优秀之处,就对 Claude Code 大吹特吹,甚至贬低其他的 AI Coding 工具。但实际上也没有几个人会去分析它的代码和设计,也不会同时深度使用多个 AI Coding 工具。就像几年前新能源汽车爆发时,很多人不认识几个汽车零件,就盲目吹捧某个品牌"天下第一"一样。
真正的智慧在于理解差异的本质。Prompt工程的差异决定了AI如何理解任务,Agent架构的差异决定了AI如何执行任务,而模型差异只是底层的能力支撑。对于开发者而言,与其纠结于哪个工具"更好",不如从原理出发,理解不同设计选择背后的权衡,然后在实际使用中验证这些权衡是否适合自己的需求。
多用、多总结、多学习,这才是AI时代技术人的正确打开方式。无论是Claude Code的精工细作,还是OpenClaw的宏大架构,都值得我们深入研究和实践。因为最终,定义我们生产力的不是某个工具,而是我们驾驭工具的能力。