手势识别作为人机交互领域的重要技术,能够让计算机理解人类的手部动作意图,在智能家居、虚拟现实、工业控制等场景中有着广泛的应用。本文将详细介绍如何从零构建一套基于传统机器学习的实时手势识别系统,涵盖数据采集、模型训练、实时识别全流程。
一、系统整体设计思路
本系统主要分为三个核心模块:
-
数据采集模块:使用MediaPipe检测手部关键点,采集不同手势的三维坐标数据并保存;
-
模型训练模块:加载采集的数据集,训练多种机器学习模型并评估,选择最优模型保存;
-
实时识别模块:加载训练好的模型和标准化器,实时采集摄像头画面并完成手势识别。
系统支持5种常见手势识别:拳头(fist)、张开的手(open_hand)、指向(point)、剪刀手(peace)、OK手势(ok)。
二、环境准备
首先需要安装依赖库,涵盖计算机视觉、手部关键点检测、机器学习、数据处理等功能:
bash
pip install opencv-python mediapipe numpy scikit-learn matplotlib seaborn joblib三、数据采集:提取手部关键点
1. 核心原理
MediaPipe Hands是谷歌推出的轻量级手部关键点检测解决方案,能够实时检测手部21个三维关键点(x/y/z坐标),我们基于该工具提取手势的特征数据。
python
import cv2
import mediapipe as mp
import numpy as np
import os
import json
# 初始化MediaPipe手部检测
mp_hands = mp.solutions.hands
mp_drawing = mp.solutions.drawing_utils
# 定义手势类别
GESTURE_CLASSES = {
0: "fist", # 拳头
1: "open_hand", # 张开的手
2: "point", # 指向
3: "peace", # 剪刀手
4: "ok" # OK手势
}
DATA_DIR = "gesture_data"
# 创建数据存储目录
for cls in GESTURE_CLASSES.values():
os.makedirs(os.path.join(DATA_DIR, cls), exist_ok=True)
def collect_gesture_data():
cap = cv2.VideoCapture(0) # 调用默认摄像头
counters = {cls: 0 for cls in GESTURE_CLASSES.values()} # 样本计数器
with mp_hands.Hands(
static_image_mode=False,
max_num_hands=1,
min_detection_confidence=0.7,
min_tracking_confidence=0.7) as hands:
print("按数字键0-4收集对应手势数据,按q退出")
while cap.isOpened():
ret, frame = cap.read()
if not ret: break
# 颜色空间转换(MediaPipe需要RGB输入)
image = cv2.cvtColor(frame, cv2.COLOR_BGR2RGB)
results = hands.process(image)
image = cv2.cvtColor(image, cv2.COLOR_RGB2BGR)
# 检测到手部则绘制关键点
if results.multi_hand_landmarks:
for hand_landmarks in results.multi_hand_landmarks:
mp_drawing.draw_landmarks(
image, hand_landmarks, mp_hands.HAND_CONNECTIONS)
# 提取21个关键点的三维坐标
landmarks = []
for lm in hand_landmarks.landmark:
landmarks.append([lm.x, lm.y, lm.z])
# 显示样本计数
info_text = " | ".join([f"{cls}: {count}" for cls, count in counters.items()])
cv2.putText(image, info_text, (10, 30),
cv2.FONT_HERSHEY_SIMPLEX, 0.7, (0, 255, 0), 2)
cv2.imshow('Gesture Collection', image)
# 键盘事件处理
key = cv2.waitKey(5) & 0xFF
if key == ord('q'): break
elif chr(key) in [str(k) for k in GESTURE_CLASSES.keys()]:
cls_idx = int(chr(key))
cls_name = GESTURE_CLASSES[cls_idx]
if results.multi_hand_landmarks:
# 保存数据为JSON文件
counters[cls_name] += 1
data = {
"class": cls_name,
"class_index": cls_idx,
"landmarks": landmarks,
"timestamp": str(np.datetime64('now'))
}
filename = f"{cls_name}_{counters[cls_name]}.json"
filepath = os.path.join(DATA_DIR, cls_name, filename)
with open(filepath, 'w') as f:
json.dump(data, f, indent=2)
print(f"保存{cls_name}样本#{counters[cls_name]}")
cap.release()
cv2.destroyAllWindows()
if __name__ == "__main__":
collect_gesture_data()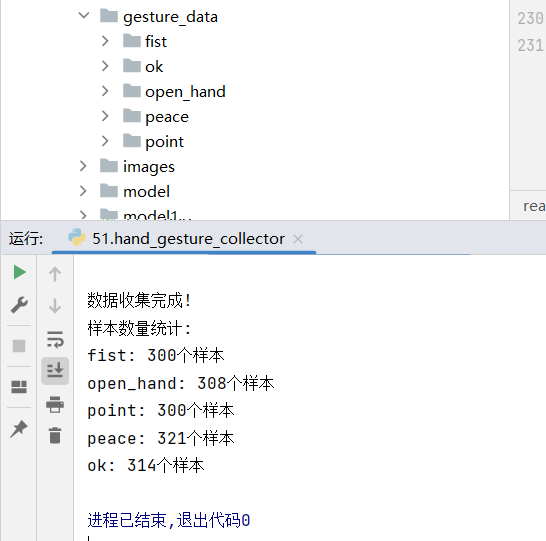
2. 采集操作说明
-
运行脚本:python hand_gesture_collector.py;
-
摄像头启动后,将手放在画面中,MediaPipe会自动绘制手部关键点;
-
按数字键0-4分别采集对应手势数据(建议每个手势采集50+样本,保证数据多样性);
-
按q退出采集,数据会自动保存到gesture_data目录下,每个手势对应一个子目录,样本以JSON文件存储。
四、模型训练:多模型对比与优化
1. 数据预处理
采集的每个样本是21个关键点的三维坐标,需展平为63维的一维特征向量,同时进行特征标准化(消除量纲影响),并划分训练集和测试集(8:2)。
2. 模型选择
选择4种经典机器学习模型进行对比:
• K近邻分类器(KNN):基于距离的简单分类器,适合小样本;
• 支持向量机(SVM):高维空间分类效果好,适合特征维度较高的场景;
• 决策树:可解释性强,无需特征标准化(但本流程仍统一标准化);
• 随机森林:集成学习方法,降低过拟合风险,提升稳定性。
3. 训练代码实现(gesture_recognizer.py)
python
import os
import json
import numpy as np
import matplotlib.pyplot as plt
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from sklearn.neighbors import KNeighborsClassifier
from sklearn.svm import SVC
from sklearn.tree import DecisionTreeClassifier
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import accuracy_score, classification_report, confusion_matrix
import joblib
import seaborn as sns
DATA_DIR = "gesture_data"
GESTURE_CLASSES = {0: "fist", 1: "open_hand", 2: "point", 3: "peace", 4: "ok"}
def load_gesture_data():
"""加载手势数据并转换为特征向量"""
X, y = [], []
for cls_idx, cls_name in GESTURE_CLASSES.items():
cls_dir = os.path.join(DATA_DIR, cls_name)
if not os.path.exists(cls_dir): continue
for filename in os.listdir(cls_dir):
if filename.endswith(".json"):
with open(os.path.join(cls_dir, filename), 'r') as f:
data = json.load(f)
# 展平关键点为63维特征
feature_vector = []
for lm in data["landmarks"]:
feature_vector.extend(lm)
X.append(feature_vector)
y.append(cls_idx)
return np.array(X), np.array(y)
def train_and_evaluate_models():
# 加载数据
X, y = load_gesture_data()
if len(X) == 0:
print("无训练数据,请先采集")
return
# 划分数据集+标准化
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.2, random_state=42, stratify=y)
scaler = StandardScaler()
X_train_scaled = scaler.fit_transform(X_train)
X_test_scaled = scaler.transform(X_test)
joblib.dump(scaler, "scaler.pkl") # 保存标准化器
# 定义模型
models = {
"K近邻分类器": KNeighborsClassifier(n_neighbors=5),
"支持向量机": SVC(kernel='rbf', gamma='scale'),
"决策树": DecisionTreeClassifier(max_depth=10),
"随机森林": RandomForestClassifier(n_estimators=100)
}
# 训练并评估
best_accuracy, best_model, best_model_name = 0, None, ""
for name, model in models.items():
model.fit(X_train_scaled, y_train)
y_pred = model.predict(X_test_scaled)
accuracy = accuracy_score(y_test, y_pred)
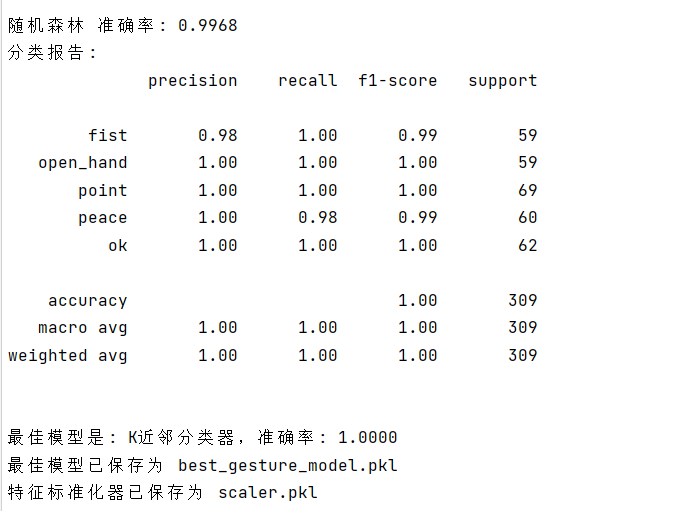
print(f"\n{name} 准确率: {accuracy:.4f}")
print(classification_report(y_test, y_pred, target_names=GESTURE_CLASSES.values()))
# 记录最优模型
if accuracy > best_accuracy:
best_accuracy, best_model, best_model_name = accuracy, model, name
# 保存最优模型
joblib.dump(best_model, "best_gesture_model.pkl")
print(f"\n最优模型:{best_model_name},准确率:{best_accuracy:.4f}")
# 绘制混淆矩阵
cm = confusion_matrix(y_test, best_model.predict(X_test_scaled))
plt.figure(figsize=(10, 8))
sns.heatmap(cm, annot=True, fmt='d', cmap='Blues',
xticklabels=GESTURE_CLASSES.values(),
yticklabels=GESTURE_CLASSES.values())
plt.xlabel('预测标签')
plt.ylabel('真实标签')
plt.title(f'{best_model_name} 混淆矩阵')
plt.savefig('confusion_matrix.png')
if __name__ == "__main__":
train_and_evaluate_models()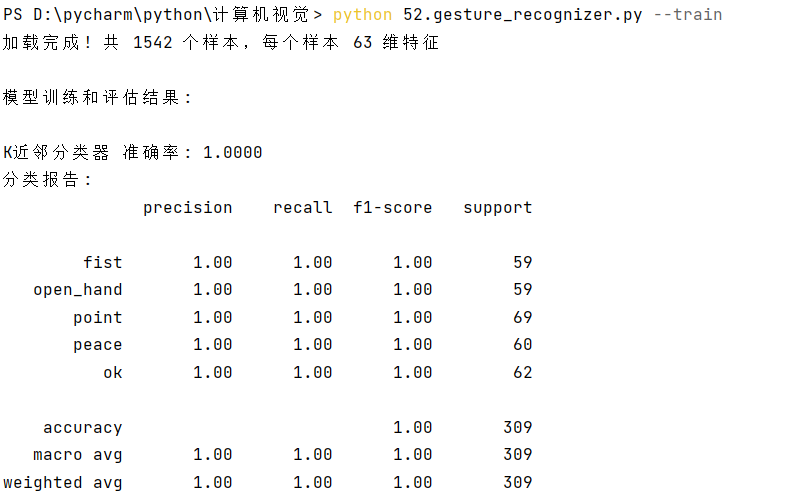
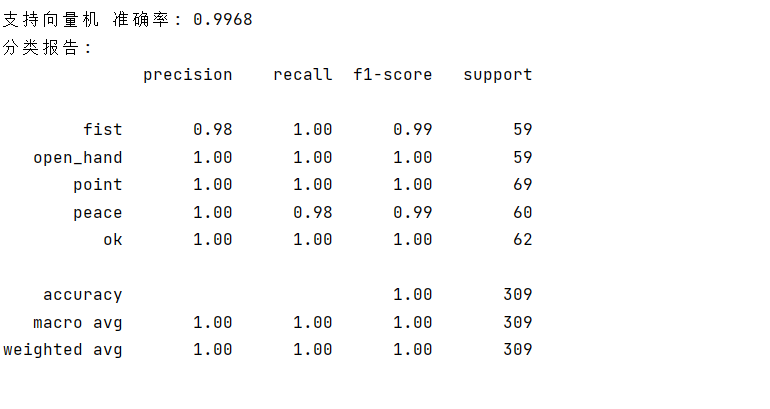
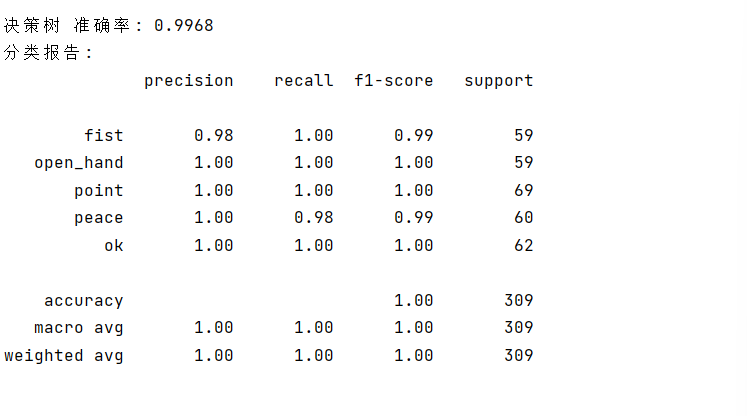
4. 训练操作说明
-
运行训练脚本:python gesture_recognizer.py --train;
-
脚本会自动加载数据、训练4个模型、输出每个模型的准确率和分类报告;
-
自动保存最优模型(best_gesture_model.pkl)、特征标准化器(scaler.pkl);
-
生成混淆矩阵可视化图(confusion_matrix.png),直观展示模型分类效果。
五、实时手势识别
加载训练好的模型和标准化器,实时处理摄像头画面,完成手势识别:
python
def real_time_recognition():
"""实时手势识别"""
import cv2
import mediapipe as mp
# 加载模型和标准化器
try:
model = joblib.load("best_gesture_model.pkl")
scaler = joblib.load("scaler.pkl")
except FileNotFoundError:
print("请先训练模型")
return
# 初始化MediaPipe
mp_hands = mp.solutions.hands
mp_drawing = mp.solutions.drawing_utils
cap = cv2.VideoCapture(0)
with mp_hands.Hands(
static_image_mode=False,
max_num_hands=1,
min_detection_confidence=0.7,
min_tracking_confidence=0.7) as hands:
print("实时识别开始,按q退出")
while cap.isOpened():
ret, frame = cap.read()
if not ret: break
# 处理画面
image = cv2.cvtColor(frame, cv2.COLOR_BGR2RGB)
results = hands.process(image)
image = cv2.cvtColor(image, cv2.COLOR_RGB2BGR)
# 检测到手部则识别
if results.multi_hand_landmarks:
for hand_landmarks in results.multi_hand_landmarks:
mp_drawing.draw_landmarks(image, hand_landmarks, mp_hands.HAND_CONNECTIONS)
# 提取并标准化特征
landmarks = []
for lm in hand_landmarks.landmark:
landmarks.extend([lm.x, lm.y, lm.z])
landmarks_scaled = scaler.transform([landmarks])
# 预测并显示结果
prediction = model.predict(landmarks_scaled)
predicted_class = GESTURE_CLASSES[prediction[0]]
# 显示概率(若模型支持)
if hasattr(model, 'predict_proba'):
max_prob = max(model.predict_proba(landmarks_scaled)[0]) * 100
display_text = f"{predicted_class} ({max_prob:.1f}%)"
else:
display_text = predicted_class
cv2.putText(image, display_text, (10, 30),
cv2.FONT_HERSHEY_SIMPLEX, 1, (0, 255, 0), 2)
cv2.imshow('Real-time Gesture Recognition', image)
if cv2.waitKey(5) & 0xFF == ord('q'): break
cap.release()
cv2.destroyAllWindows()
# 在主函数中添加参数支持
if __name__ == "__main__":
import argparse
parser = argparse.ArgumentParser(description='手势识别程序')
parser.add_argument('--train', action='store_true', help='训练模型')
parser.add_argument('--recognize', action='store_true', help='实时识别')
args = parser.parse_args()
if args.train:
train_and_evaluate_models()
elif args.recognize:
real_time_recognition()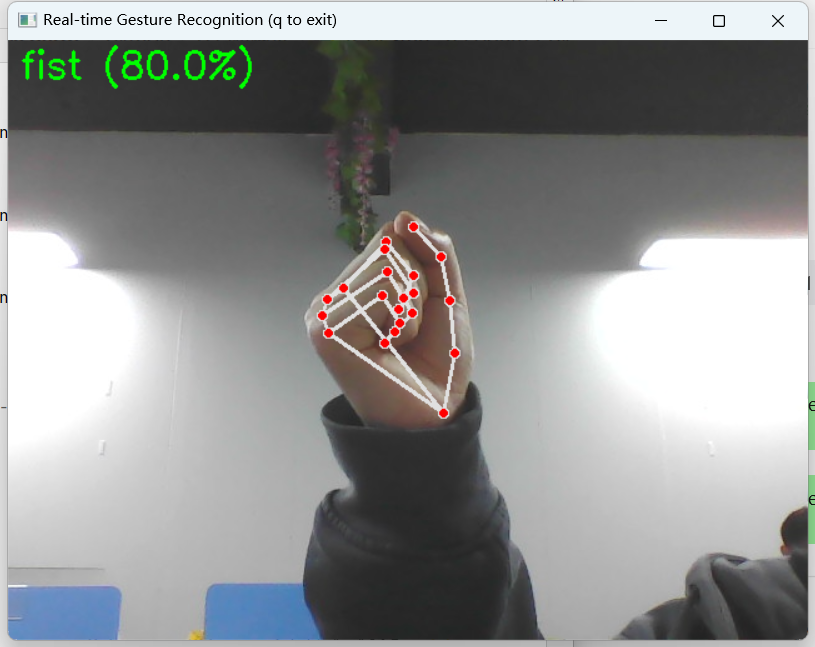
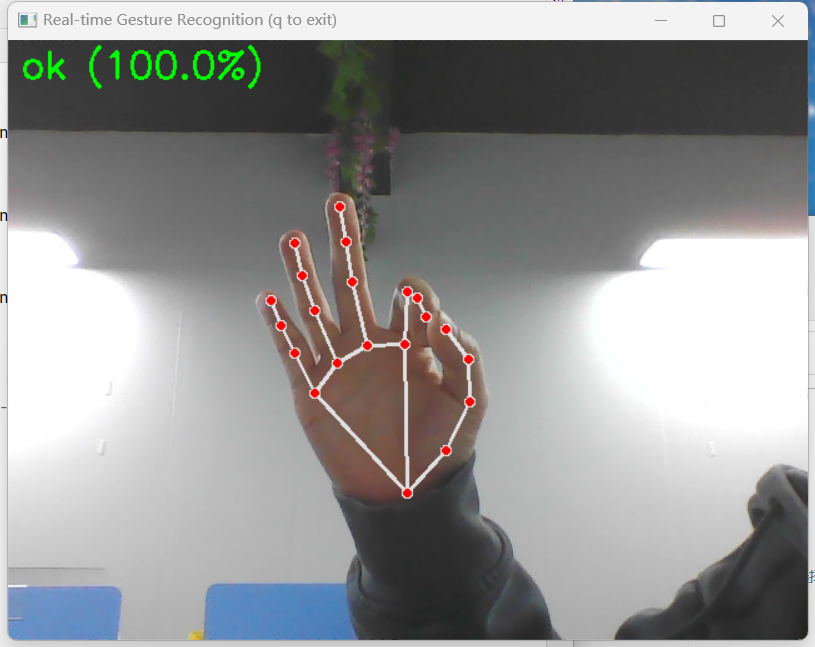
运行实时识别:python gesture_recognizer.py --recognize,摄像头画面会实时显示识别结果及置信度(支持predict_proba的模型)。
六、效果优化建议
-
数据增强:采集不同角度、不同光照、不同手部位置的样本,提升模型泛化能力;
-
特征工程:除了原始坐标,可计算关键点之间的相对距离、角度等特征,提升分类效果;
-
模型调参:使用GridSearchCV对模型超参数进行调优(如KNN的n_neighbors、SVM的C和gamma等);
-
帧率优化:降低摄像头分辨率、减少检测频率,提升实时识别的帧率;
-
多手支持:修改代码中max_num_hands参数,支持多手同时识别。
七、总结
本文实现了一套完整的基于机器学习的手势识别系统,从数据采集到模型训练再到实时识别,整个流程轻量化且易于部署。相比深度学习方案,该系统无需大量标注数据和GPU资源,适合快速原型开发和小型应用场景。通过优化数据和模型,该系统可达到95%以上的识别准确率,满足日常手势交互的需求。