前言
本文旨在写一个新手小白都能看懂的项目教程。有很多基础知识,如:pytest框架、日志等。会的同学可以点开目录自行跳过。文章肯定有很多不足的地方,欢迎大家给出整改意见。
1.什么是接口测试
接口测试就是针对接口发起请求(增删查改),用各种正常/异常参数发起访问,然后校验返回的状态码、响应数据(特别是业务错误码和关键字段)是否符合预期。
我们可以基本理解为:输入 → 操作 → 断言输出
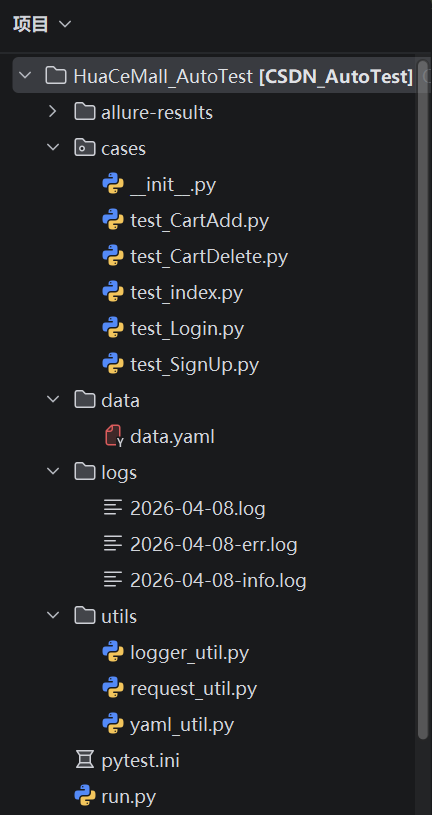
2. 项目介绍及架构
2.1 项目介绍
我们测试的网站为华测在线商城。一个非常适合新手练习测试的网站。网站如图:
2.2 项目架构
3.主页接口测试实操
3.1 百度主页接口测试
记好这个流程,我们先来实操一下:
输入 → 操作 → 断言输出
以百度举例:
我们在 postman 上输入百度的URL,点击send:
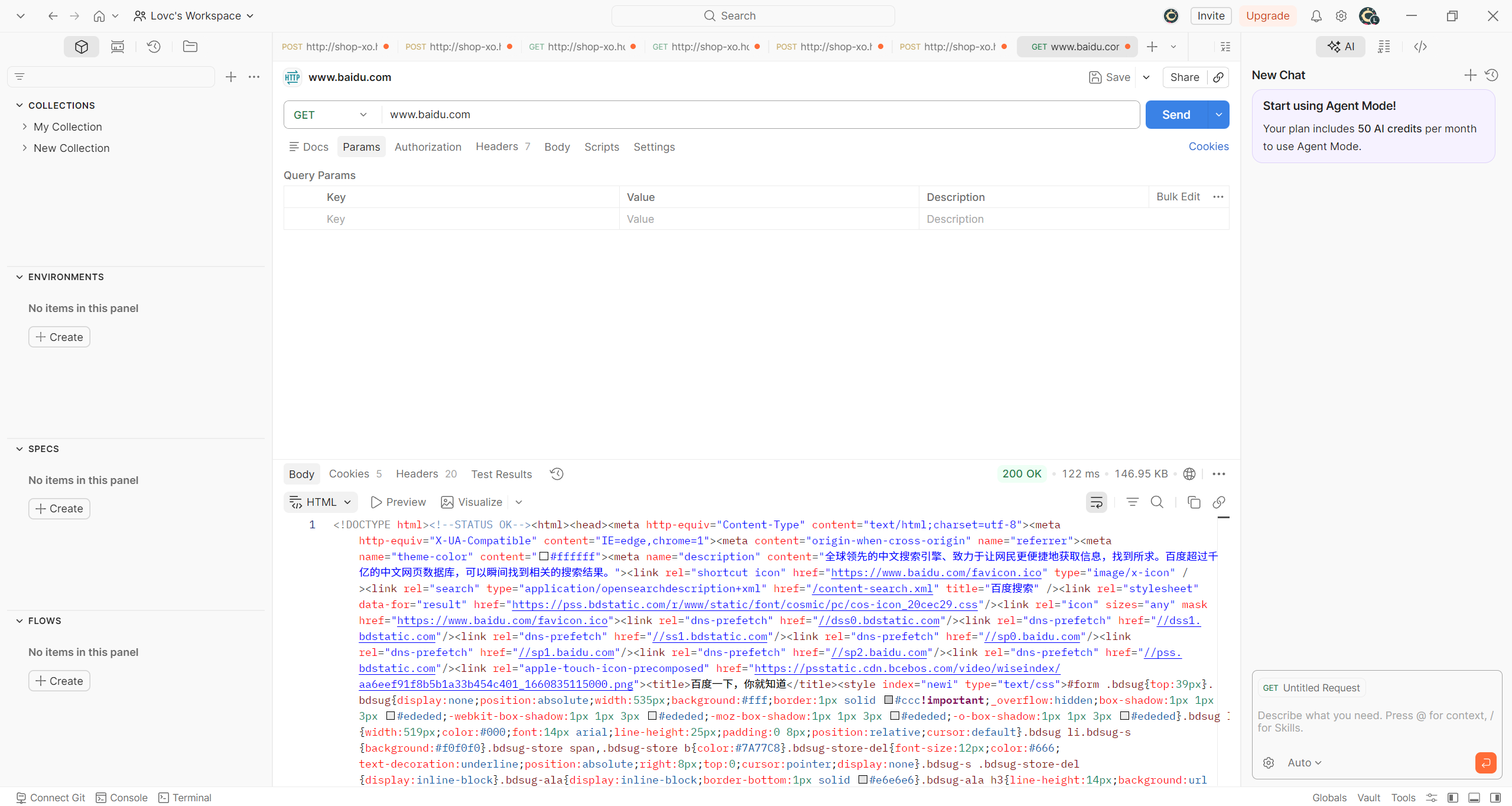
我们自动化要做的就是,确定url是什么,发送相应请求(这里是get),然后检验返回值是否符合预期。
一般首页返回的会是一个html页面,我们这里直接检验返回内容中是否包含关键词和状态码。
python
import requests
def baidu_homepage():
"""
测试用例:验证百度首页(HTML接口)能否正常访问。
测试点:
1. HTTP响应状态码是否为200。
2. 响应内容中是否包含关键文本,如"百度一下"。
"""
url = "https://www.baidu.com"
# 发送GET请求
response = requests.get(url=url)
# 强制指定编码为 UTF-8(百度首页实际是 UTF-8)
response.encoding = 'utf-8'
# 1. 断言状态码是否为200(200代表运行正常)
assert response.status_code == 200, "首页状态码不是200"
# 2. 断言关键文本
assert "百度一下" in response.text, "首页未找到关键字'百度一下'"
print("测试通过!百度首页访问正常。")
# 调用函数
baidu_homepage()代码解析
-
requests.get(url):向百度首页发送一个HTTP GET请求。 -
assert:这是测试的核心,用于验证实际结果是否符合预期。如果response.status_code不等于200,程序会抛出一个AssertionError,并显示我们提供的错误信息。 -
in response.text:response.text是服务器返回的HTML页面源代码,这个断言会检查页面中是否包含"百度一下"这个关键字。
3.2 华测商城主页接口测试
同理,华测商城的也是一样:
甚至百度的测试代码,我们更改一下url和检测文字就可以使用:
不过文字要结合网站而定,一定是网站里面存在的元素,比如我准备断言的内容,就在这里(网页按F12打开开发者工具)。
代码如下:
python
import requests
def baidu_homepage():
"""
测试用例:验证百度首页(HTML接口)能否正常访问。
测试点:
1. HTTP响应状态码是否为200。
2. 响应内容中是否包含关键文本,如"百度一下"。
"""
url = "http://shop-xo.hctestedu.com"
# 发送GET请求
response = requests.get(url=url)
# 强制指定编码为 UTF-8(百度首页实际是 UTF-8)
response.encoding = 'utf-8'
# 1. 断言状态码是否为200(200代表运行正常)
assert response.status_code == 200, "首页状态码不是200"
# 2. 断言关键文本
assert "ShopXO应用商店" in response.text, "首页未找到关键字'ShopXO应用商店'"
print("测试通过!华测商城首页访问正常。")
# 调用函数
baidu_homepage()ok,这个就是为了使我们理解什么是接口测试,下面我们看一点常规难度的。
4. pytest框架
pytest 是 Python 的一个成熟、功能强大的测试框架,用于编写各类测试(单元测试、集成测试、功能测试等)。它基于 Python 原生的 assert 语句,通过丰富的插件和特性,让测试代码更简洁、可读性更高,同时具备很强的扩展能力。
老规矩,话不多说,上代码

4.1 测试函数与断言
python
def test_addition():
#简单的断言示例
assert 1 + 1 == 2
def test_string_contains():
#字符串包含关系断言
assert "hello" in "hello world"运行这段代码,你会看到两个测试通过。
4.2 参数化测试
我们可以使用 @pytest.mark.parametrize 用多组数据运行同一个测试:
python
import pytest
@pytest.mark.parametrize("a,b,expected", [
(1, 2, 3),#断言通过案例
(0, 3, 0),#断言失败案例
(-1, 1, 0),#断言通过案例
])
def test_add(a, b, expected):
assert a + b == expected4.3 使用 Fixture 管理资源
Fixture 可以创建可复用的测试前置/后置逻辑:
yield之前的代码相当于前置,在测试执行前运行。
yield之后(后置代码)在测试执行完毕后运行,用于清理资源(关闭文件、断开数据库连接等)。
python
import pytest
@pytest.fixture
def sample_data():
print("\n[前置] 准备测试数据")
data = {"name": "Alice", "age": 30}
yield data
print("\n[后置] 清理资源")
def test_data_contains(sample_data):
assert "name" in sample_data
assert sample_data["age"] == 30fixture 默认是 function 作用域,即每个测试函数调用一次前置和后置。你可以通过 scope 参数控制:
| scope | 说明 |
|---|---|
function |
默认,每个测试函数执行一次(前置和后置各一次)。 |
class |
每个测试类执行一次(前置在类中第一个测试前执行,后置在最后一个测试后执行)。 |
module |
每个测试模块(.py 文件)执行一次。 |
session |
整个 pytest 会话执行一次(多个测试文件共享)。 |
示例:
python
@pytest.fixture(scope="class")
def db_connection():
print("连接数据库")
yield
print("关闭数据库连接")4.4 自定义标记与按标记运行
python
import pytest
@pytest.mark.slow
def test_long_running():
"""标记为慢速测试"""
import time
time.sleep(2)
assert True
@pytest.mark.fast
def test_quick():
"""快速测试"""
assert 1 == 1运行 pytest test_mark.py -m "fast" 将只执行快速测试,运行 pytest test_mark.py -m "slow" 则只执行慢速测试。(这是终端命令,test_mark.py是我的文件名,大家运行的时候要逐一命令行里为自己的文件名)
5. pytest.ini 文件的配置
pytest.ini是 pytest 框架的主配置文件 ,用于集中管理 pytest 的行为和运行选项。通过这个文件,你可以避免每次运行测试时在命令行重复输入参数,统一团队内的测试执行方式。(pytest.ini通常放在项目根目录)
5.1 pytest 使用示例
主要作用:
-
指定测试目录:定义 pytest 从哪些目录或文件收集测试用例。
-
配置命令行选项 :例如默认的
-v(详细输出)、--tb=short(简化回溯)、--maxfail(失败几次后停止)等。 -
注册自定义标记 :声明你使用的标记(如
@pytest.mark.slow),避免警告并控制运行哪些标记。 -
设置日志、报告、插件等:控制日志输出级别、测试报告格式、插件行为等。
-
定义测试类、函数的前缀 :指定哪些文件名/类名/函数名被视为测试用例(默认是
test_或_test开头)。
常见配置示例:
python
[pytest]
# 测试文件搜索路径
testpaths = tests
# 默认命令行选项
addopts = -v --tb=short --strict-markers
# 注册自定义标记
markers =
slow: 标记为慢速测试,可通过 -m "not slow" 跳过
login: 仅与登录相关的测试
# 日志配置
log_cli = true
log_cli_level = INFO
log_file = pytest.log
# 最小 Python 版本
minversion = 6.0总之,pytest.ini 是让 pytest 更加贴合项目需求的配置入口。
5.2 我们的 pytest.ini 文件配置
哈哈哈,上面的看着是不是有点复杂?别慌,咱们的没有那么复杂:
python
[pytest]
addopts = -vs
[pytest]:表示 pytest 的配置节。
addopts:指定 pytest 默认附加的命令行参数,每次运行pytest时都会自动带上。
-vs:
-v(verbose):输出更详细的测试执行信息(如测试名称和结果)。
-s:禁用输出捕获,允许
因为添加在了 pytest.ini 中,每次执行 pytest 时,都等价于运行 pytest -vs。
6. 日志
6.1 日志的概念
日志就是系统或应用在运行过程中产生的"流水账"记录。
核心用途:
排错:程序崩了,查日志看哪里报错
审计:谁、什么时间、做了什么操作
监控:分析性能、流量、异常趋势
常见类型:
系统日志:操作系统层面的记录
应用日志:程序自己打印的运行信息
访问日志:谁在什么时候请求了什么资源
6.2 logging日志模块
logging 是 Python 标准库中的一个模块,它提供了灵活的日志记录功能。通过logging ,开发者可以方便地将日志信息输出到控制台、文件、网络等多种目标,同时支持不同级别的日志记录,以满足不同场景下的需求。
6.2.1 日志记录器(logger)
作用 :日志系统的入口 。你在代码中通过
logging.getLogger(name)获取一个 Logger 对象,然后调用其info()、error()等方法记录日志。职责:
接收日志消息,并根据设置的级别(如 DEBUG、INFO)决定是否处理该消息。
将消息传递给已添加的处理器(Handler)进行后续输出。
类比 :可以理解为一个日志收集器,它只负责接收日志,不关心日志最终写到哪里。
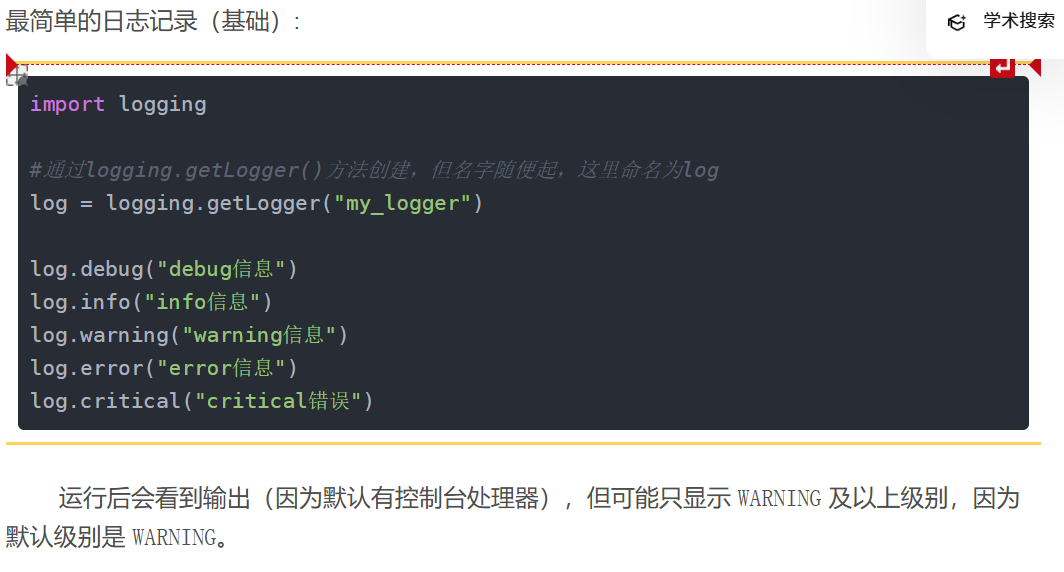
最简单的日志记录(基础):
python
import logging
#通过logging.getLogger()方法创建,但名字随便起,这里命名为log
log = logging.getLogger("my_logger")
log.debug("debug信息")
log.info("info信息")
log.warning("warning信息")
log.error("error信息")
log.critical("critical错误")运行后会看到输出(因为默认有控制台处理器),但可能只显示 WARNING 及以上级别,因为默认级别是 WARNING。
6.2.2 文件处理器(FileHandler)
作用 :将日志消息输出到文件。它是 Handler 的一种具体实现。
职责:
指定输出文件路径(如
app.log)。可以设置自己的日志级别(例如只输出 WARNING 及以上到文件)。
可以设置日志格式(Formatter),控制日志的显示样式。
类比 :可以理解为一个日志写入器,它知道要把日志写在哪个文件里。
添加文件处理器:
python
import logging
log = logging.getLogger("my_logger")
log.setLevel(logging.DEBUG) # 全局级别
# 创建文件处理器,写入到文件
file_handler = logging.FileHandler("app.log", encoding="utf-8")
file_handler.setLevel(logging.INFO) # 处理器级别
#如果将logging.ERROR,那么INFO就不会被输出到文件了
# 添加处理器
log.addHandler(file_handler)
log.info("这是一条 INFO 日志")
log.error("这是一条 ERROR 日志")运行后,同目录下会生成 app.log,包含这两条日志。但控制台看不到(因为没有添加控制台处理器)。
6.2.3 控制台处理器(ConsoleHandler)
这个没有文件处理器那么重要,当你加入了控制台处理器的话,内容就会被输出到控制台。
python
import logging
log = logging.getLogger("my_logger")
#设置log级别为debug及以上
log.setLevel(logging.DEBUG)
# 创建控制台处理器
console_handler = logging.StreamHandler()
log.addHandler(console_handler)
# 现在所有级别的日志都会输出到控制台
log.debug("调试信息")
log.info("普通信息")
log.warning("警告信息")
log.error("错误信息")
log.critical("严重错误")不知道有没有细心的同学发现了一个细节(这是3.2.1的截图):
上面的代码,并没有处理器,怎么输出了呢?这是因为如果不添加处理器,系统会默认给一个级别为WARNING的控制台处理器。
6.2.4 设置日志格式(附占位符含义表)
这个表大家不用记,遇到不清楚的看一下就可以了。
| 占位符 | 含义 | 示例值 |
|---|---|---|
%(asctime)s |
日志事件发生的时间,格式默认为 YYYY-MM-DD HH:MM:SS,mmm,可通过 datefmt 参数自定义。 |
2025-03-21 15:30:45,123 |
%(levelname)s |
日志级别名称(如 DEBUG、INFO、WARNING、ERROR、CRITICAL)。 |
INFO |
%(name)s |
日志记录器的名称(即 getLogger(name) 传入的名称)。 |
my_logger |
%(message)s |
日志消息内容(调用 log.info("...") 时传入的字符串)。 |
用户登录成功 |
%(filename)s |
调用日志记录所在的源文件名(不含路径)。 | test_login.py |
%(funcName)s |
调用日志记录所在的函数名。 | test_login_success |
%(lineno)d |
调用日志记录所在的行号(整数)。 | 42 |
%(pathname)s |
调用日志记录所在的源文件完整路径。 | /home/user/project/test_login.py |
%(module)s |
调用日志记录所在的模块名(即文件名去掉 .py)。 |
test_login |
%(process)d |
进程 ID(整数)。 | 12345 |
%(thread)d |
线程 ID(整数)。 | 140735123456789 |
%(threadName)s |
线程名称。 | MainThread |
%(created)f |
日志事件的时间戳(time.time() 返回的浮点数)。 |
1742567445.123456 |
%(relativeCreated)d |
日志事件相对于 logging 模块初始化时间的毫秒数。 | 1234 |
我们先举个例子:
python
import logging
log = logging.getLogger("my_logger")
log.setLevel(logging.DEBUG)
# 创建格式
formatter = logging.Formatter("%(asctime)s - %(levelname)s - %(message)s")
#显示到控制台
console_handler = logging.StreamHandler()
console_handler.setFormatter(formatter)
log.addHandler(console_handler)
log.info("info信息")这段代码中规定格式的语句为
python
formatter = logging.Formatter("%(asctime)s - %(levelname)s - %(message)s")含义为:时间 - 错误等级 - 日志消息内容
控制台输出如下:

如果不想要最后的毫秒的话,添加 datefmt="%Y-%m-%d %H:%M:%S" 到 formatter 就行。
python
import logging
log = logging.getLogger("my_logger")
log.setLevel(logging.DEBUG)
# 创建格式
formatter = logging.Formatter("%(asctime)s - %(levelname)s - %(message)s",
datefmt="%Y-%m-%d %H:%M:%S")
#显示到控制台
console_handler = logging.StreamHandler()
console_handler.setFormatter(formatter)
log.addHandler(console_handler)
log.info("info信息")6.2.5 过滤器(Filter)
过滤器(Filter)是 Python logging 模块中用于精细控制哪些日志记录应该被处理的组件。
你可以给 日志记录器(Logger) 或 处理器(Handler) 添加过滤器。
过滤器通过一个
filter(record)方法来判断某条日志是否应该被放过(返回True)还是丢弃(返回False)。
如下,就是一个 info 过滤器:
python
# 自定义过滤器,只允许 INFO 级别通过
class InfoFilter(logging.Filter):
def filter(self, record):
return record.levelno == logging.INFO啥东西?这咋还有个类?

因为 logging.Filter 是一个基类 ,它定义了一个 filter(record) 方法,你只需要继承它并实现自己的过滤逻辑。
-
用类的好处:可读性好、可复用、可以携带状态(比如记录过滤次数)。
-
过滤器本质是"有
filter方法的对象",所以只要一个对象有这个方法,addFilter就可以接受它。
record 是 LogRecord 类的实例,代表一条日志记录。它包含日志的所有信息:级别、消息、时间、记录器名称、文件名、行号等。在 filter 方法中,通过检查 record 的属性来决定是否放行。
python
import logging
# 1. 自定义过滤器类
class InfoFilter(logging.Filter):
def filter(self, record):
# record 是一条日志记录对象,包含级别、消息、时间等属性
return record.levelno == logging.INFO
# 2. 获取日志记录器
log = logging.getLogger("my_logger")
log.setLevel(logging.DEBUG) # 总开关设为 DEBUG,让所有级别都能进入记录器
# 3. 创建控制台处理器
console = logging.StreamHandler()
console.setLevel(logging.DEBUG) # 处理器也设为 DEBUG,接收所有
# 4. 添加过滤器到处理器(只允许 INFO 通过)
console.addFilter(InfoFilter())
# 5. 把处理器添加到记录器
log.addHandler(console)
# 6. 测试
log.debug("debug信息") # 不会显示
log.info("info信息") # 会显示
log.warning("warning信息") # 不会显示
log.error("error信息") # 不会显示6.2.6 按日期自动切分文件
其实这个实现原理很简单,就是因为每一天的日期不同。文件名是根据日期确定的,日期不同文件名自然不同,如果一天内首次运行,没有相同的文件名就会创建。如果有同名的,则会续写。
python
import logging
import time
import os #导入os库
# 确保目录存在,不存在会自动创建
os.makedirs("./logs", exist_ok=True)
# 每次记录日志时,根据当前日期生成文件名
log_file = f"./logs/{time.strftime('%Y-%m-%d')}.log"
# 配置日志(每次运行都会重新配置,但实际项目中需要避免重复配置)
logging.basicConfig(
filename=log_file,
level=logging.DEBUG,
format="%(message)s" # 只显示消息,不显示时间
encoding="utf-8" #编码格式
)
logging.info("今天的信息会写入今天的文件")6.2.7 我们的日志文件
python
import logging
import os.path
import time
#定义info类型过滤器
class infoFilter(logging.Filter):
def filter(self, record):
return record.levelno == logging.INFO
#定义error类型过滤器
class errFilter(logging.Filter):
def filter(self, record):
return record.levelno == logging.ERROR
class logger:
#获取日志对象---定义类方法@classmethod
@classmethod
def getlog(cls):
#创建日志对象
cls.logger = logging.getLogger(__name__)
cls.logger.setLevel(logging.DEBUG)
# LOG_PATH可以帮助日志文件存放到正确文件夹
LOG_PATH = "./logs/"
# 如果没有LOG_PATH
if not os.path.exists(LOG_PATH):
# 创建LOG_PATH
os.mkdir(LOG_PATH)
#将日志输出到日志文件中
now = time.strftime("%Y-%m-%d")
#所有日志
log_name = LOG_PATH + now + ".log"
#操作日志
info_log_name = LOG_PATH + now + "-info.log"
#错误日志
err_log_name = LOG_PATH + now + "-err.log"
#创建文件处理器,分别对于上述日志,不解释
all_handler = logging.FileHandler(log_name,encoding="utf-8")
info_handler = logging.FileHandler(info_log_name,encoding="utf-8")
err_handler = logging.FileHandler(err_log_name,encoding="utf-8")
#创建处理器,将日志输出到控制台
streamHandler = logging.StreamHandler()
#设置日志的格式
formatter = logging.Formatter(
"%(asctime)s %(levelname)s [%(name)s] [%(filename)s (%(funcName)s:%(lineno)d)] - %(message)s"
)
all_handler.setFormatter(formatter)
info_handler.setFormatter(formatter)
err_handler.setFormatter(formatter)
streamHandler.setFormatter(formatter)
#添加过滤器
info_handler.addFilter(infoFilter())
err_handler.addFilter(errFilter())
#添加处理器
cls.logger.addHandler(all_handler)
cls.logger.addHandler(info_handler)
cls.logger.addHandler(err_handler)
# cls.logger.addHandler(streamHandler)
#返回以供外部使用
return cls.logger7.请求封装工具
好家伙,这玩意听着都难

别慌!这个老简单了!其实这个的作用就是重定义方法方便记录日志。
大家先看一眼代码,其实我们就写了 Request.get 和 Request.post (不影响正常使用,正常使用request就好),而且改的很简单,就是调用 get 和 post 时先向日志中输出了一下接口信息,结束后输出了一下重要参数。
python
import requests
from utils.logger_util import logger
host = "http://shop-xo.hctestedu.com/"
class Request:
log = logger.getlog()
def get(self,url,**kwargs):
self.log.info("准备发起get请求,url:"+url)
self.log.info("接口信息:{}".format(kwargs))
r = requests.get(url=url,**kwargs)
self.log.info("接口响应状态码:{}".format(r.status_code))
self.log.info("接口响应内容:{}".format(r.text))
return r
def post(self,url,**kwargs):
self.log.info("准备发起post请求,url:"+url)
self.log.info("接口信息:{}".format(kwargs))
r = requests.post(url=url,**kwargs)
self.log.info("接口响应状态码:{}".format(r.status_code))
self.log.info("接口响应内容:{}".format(r.text))
return r简单说一下**kwargs:
python
def get(self, url, **kwargs):
**kwargs是 Python 中的可变关键字参数。它可以将调用时传入的任意多个key=value形式的参数收集成一个字典,比如params={"page":1}、headers={"User-Agent": "..."}等。在函数内部,
**kwargs会被直接传递给requests.get(url=url, **kwargs),这样就无需在方法定义时列出所有可能的参数。
7.1 首页代码融入项目
我们现在改一下首页的日志代码,使首页发出的get请求可以被日志记录。直接导入自己写的请求库,然后调用函数:
python
from utils.request_util import Request
import pytest
@pytest.mark.order(1)
def test_huace_homepage():
"""
测试用例:验证华测首页(HTML接口)能否正常访问。
测试点:
1. HTTP响应状态码是否为200。
2. 响应内容中是否包含关键文本,如"ShopXO应用商店"。
"""
url = "http://shop-xo.hctestedu.com"
# 发送GET请求
response = Request().get_index(url=url)
# 强制指定编码为 UTF-8(百度首页实际是 UTF-8)
response.encoding = 'utf-8'
# 1. 断言状态码是否为200(200代表运行正常)
assert response.status_code == 200, "首页状态码不是200"
# 2. 断言关键文本
assert "ShopXO应用商店" in response.text, "首页未找到关键字'ShopXO应用商店'"
print("测试通过!华测商城首页访问正常。")修改完成,我们来看一下日志文件:
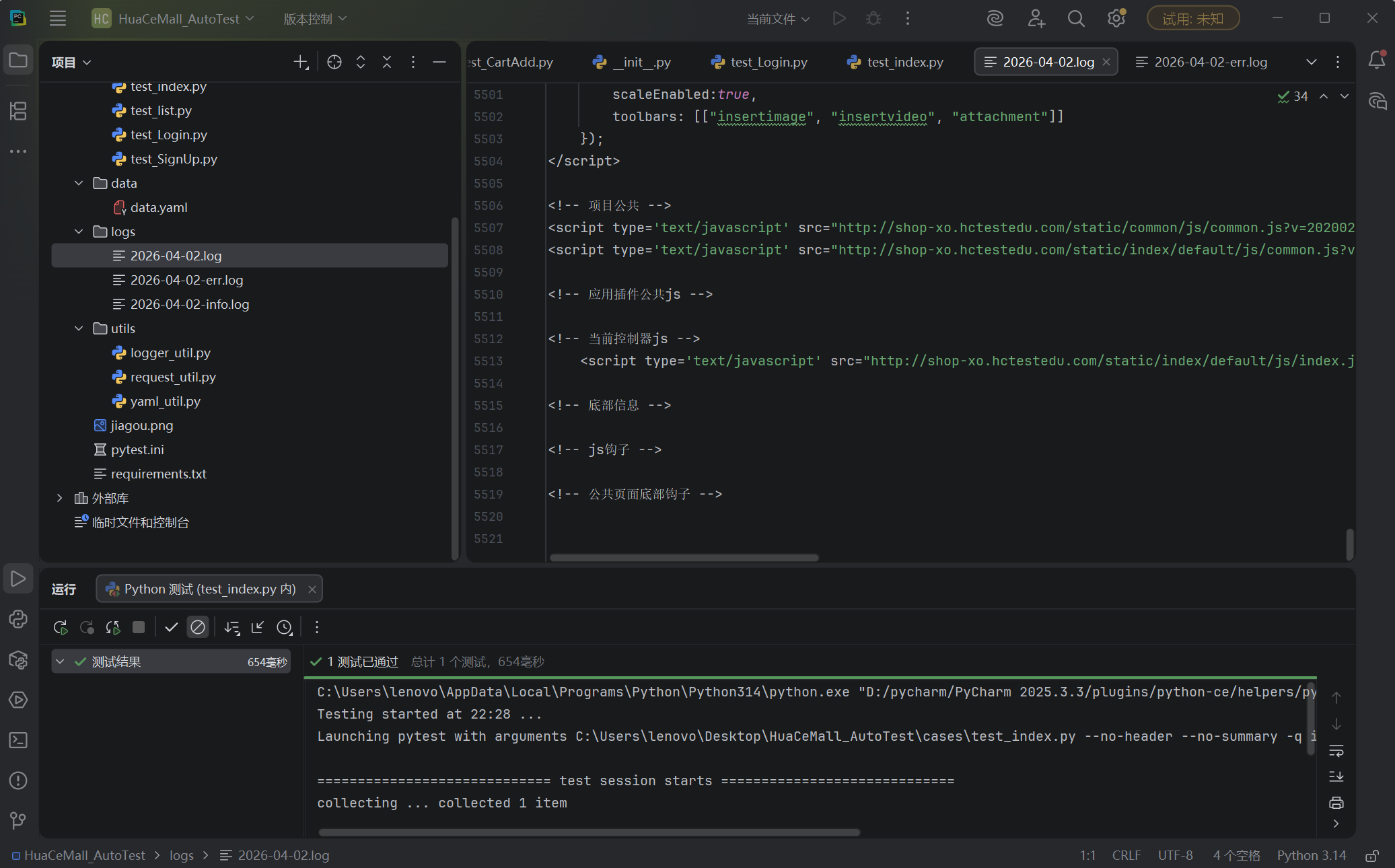
呃......返回了5000多行,这肯定是及不方便阅读的。没关系,我们修改一下,在request文件写一个首页专用的日志写入方法,直接粘贴到文件末尾即可:
python
def get_index(self,url,**kwargs):
self.log.info("准备发起get请求,url:"+url)
self.log.info("接口信息:{}".format(kwargs))
r = requests.get(url=url,**kwargs)
self.log.info("接口响应状态码:{}".format(r.status_code))
self.log.info("接口响应内容:{}".format("华测商城首页测试成功"))
return r重新修改日志文件,用get_index方法而不是get方法:
python
from utils.request_util import Request
def test_baidu_homepage():
"""
测试用例:验证华测首页(HTML接口)能否正常访问。
测试点:
1. HTTP响应状态码是否为200。
2. 响应内容中是否包含关键文本,如"ShopXO应用商店"。
"""
url = "http://shop-xo.hctestedu.com"
# 发送GET请求
response = Request().get_index(url=url)
# 强制指定编码为 UTF-8(百度首页实际是 UTF-8)
response.encoding = 'utf-8'
# 1. 断言状态码是否为200(200代表运行正常)
assert response.status_code == 200, "首页状态码不是200"
# 2. 断言关键文本
assert "ShopXO应用商店" in response.text, "首页未找到关键字'ShopXO应用商店'"
print("测试通过!华测商城首页访问正常。")我们再来看一下日志文件:
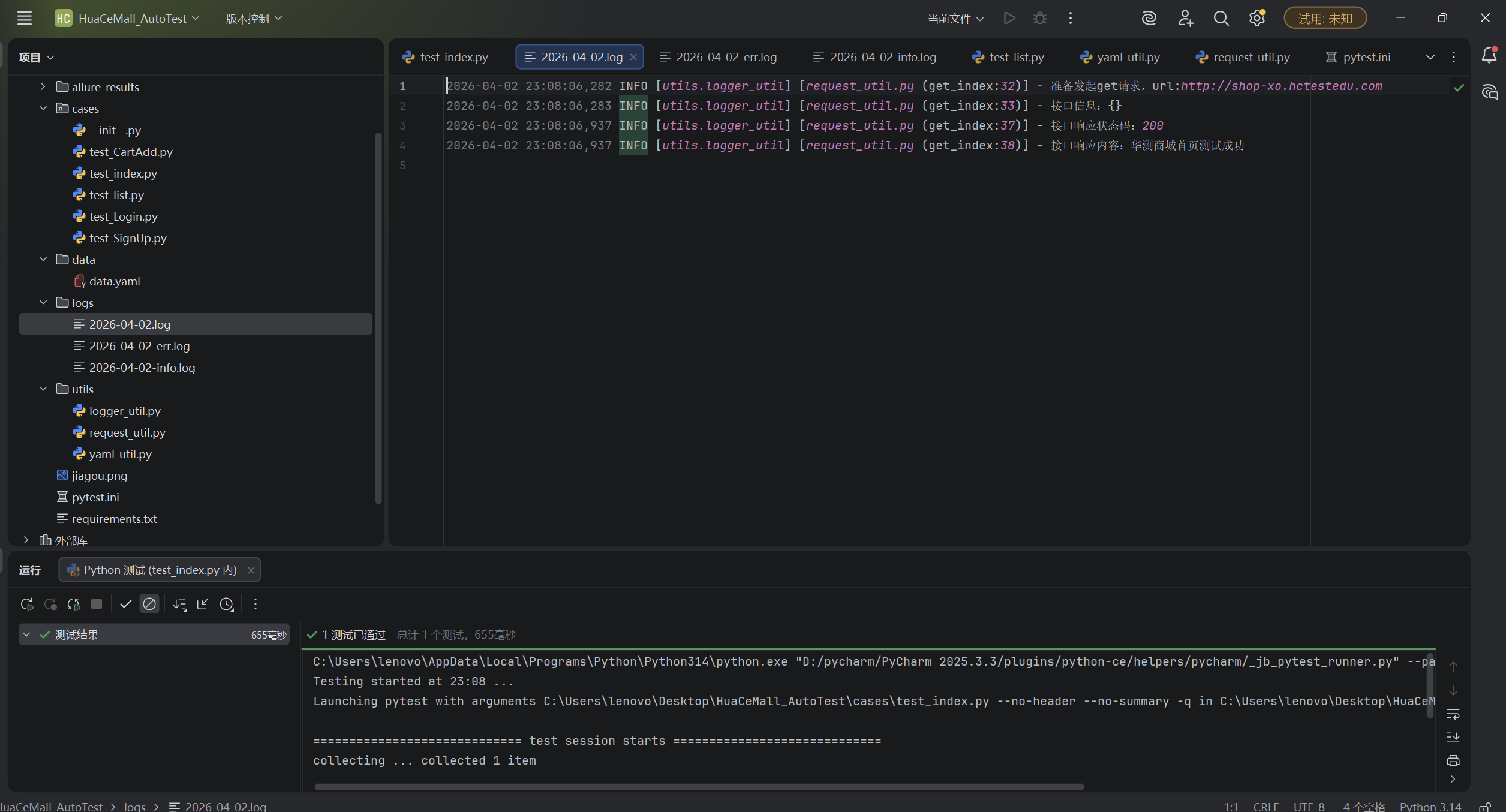
好的,干得不错。我们下面来学习其他重要的接口测试。
8.登录接口测试
OK,前面的搞定。我们终于可以来测试接口了。下面我带大家逐步完成登录接口的测试:
- 点击登录按钮,跳转至登录页面:
- 按F12打开开发者工具,并点击状态栏的"网络":
在浏览器开发者工具的 Network 面板中,测试时建议打开这两个选项:
-
保留日志(Preserve log):页面刷新或跳转后不会清空网络请求记录,便于查看完整请求链路(尤其是登录后自动跳转的场景)。
-
禁用缓存(Disable cache):强制所有请求绕过浏览器缓存,确保每次请求都发送到服务器,获取最新响应,避免缓存干扰调试。
打开后能更准确观察实际网络交互,定位问题。
3.填写登录信息,点击登录,注意查看接口:
信息填写后,点击登录(这里已经为大家准备了测试用的账号,账号"zhangsan",密码"123456"),此时接口回像服务器发起请求,开发者工具的"网络"会将其记录:
此时已经登录,"网络"活动如下所示的三条:
这里我的登录接口是第一条,下面给大家总结了一下如何找到登录接口:
找到登录接口的常见特征:
请求方法 :通常为
POST。URL 特征 :路径中含
login、signin、auth、/user/login等。请求参数 :携带用户名、密码字段(如
username/password、accounts/pwd、mobile/code等)。响应特征 :返回
token、session_id、用户信息或跳转地址。调用时机:一般是点击登录按钮后发起的第一个请求(也可在 Network 面板中筛选 XHR/Fetch)。
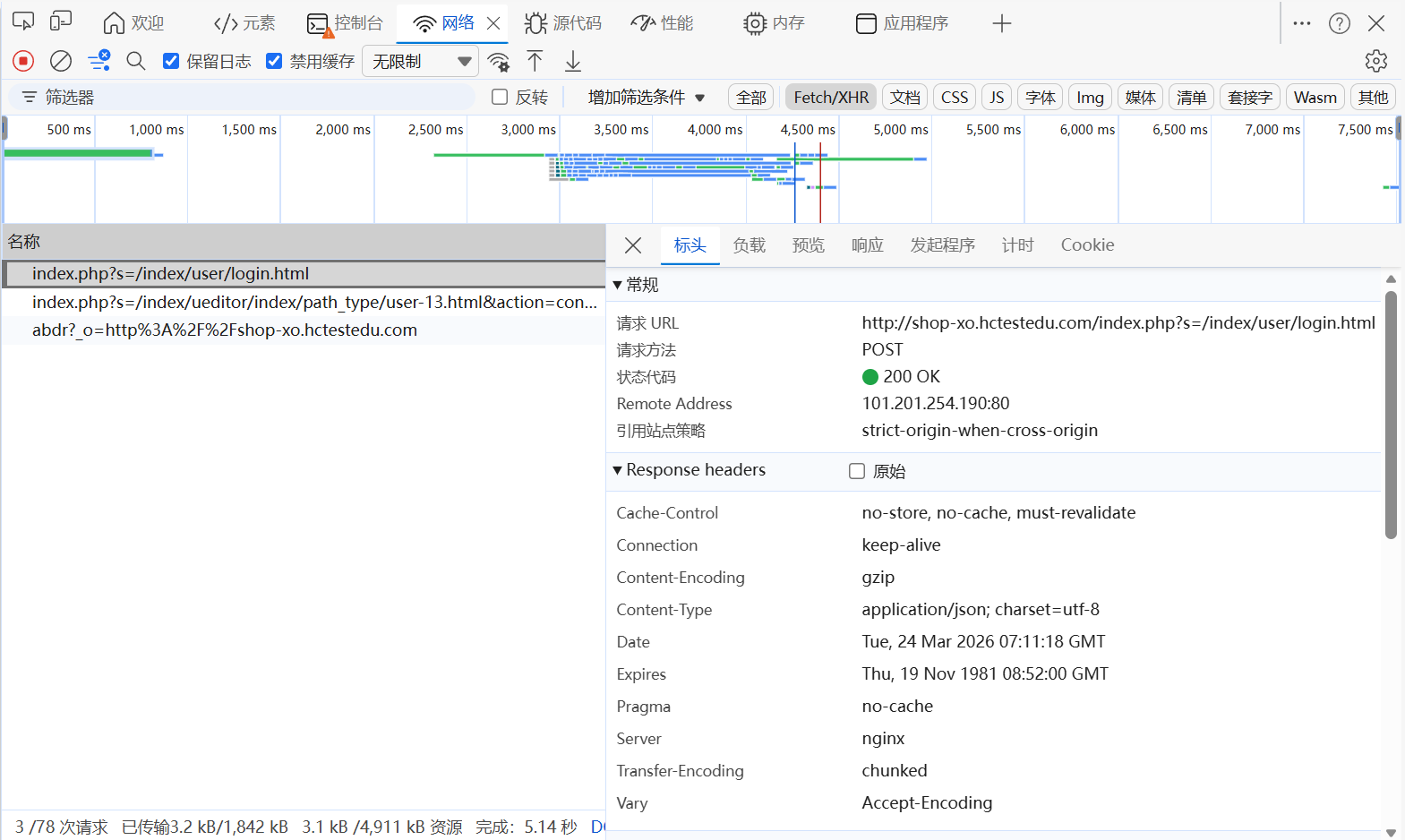
我们将这个URL复制到我们的postman:http://shop-xo.hctestedu.com/index.php?s=/index/user/login.html
点击body,选择form-data类型(表格数据类型),传入我们要传的数据(账号、密码和类型):
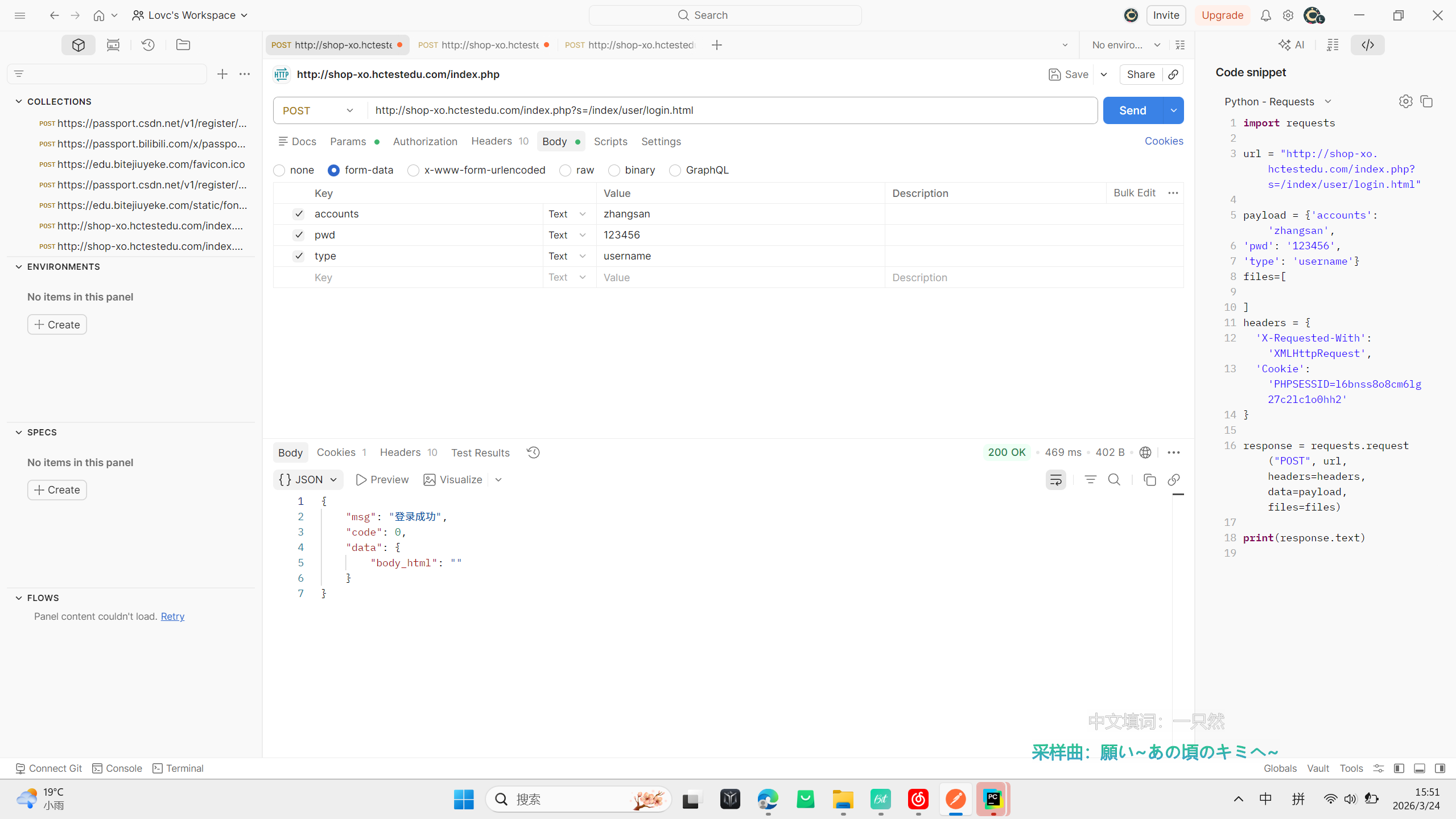
点击头,并添加一个名为X-Requested-With的头(X-Requested-With 是一个 HTTP 请求头,通常用来标识请求是否为异步 Ajax 请求) ,值为 XMLHttpRequest(服务端通过判断该头,决定是否返回 JSON 数据、跳过 CSRF 校验、或者执行其他针对异步请求的逻辑)。
点击send:
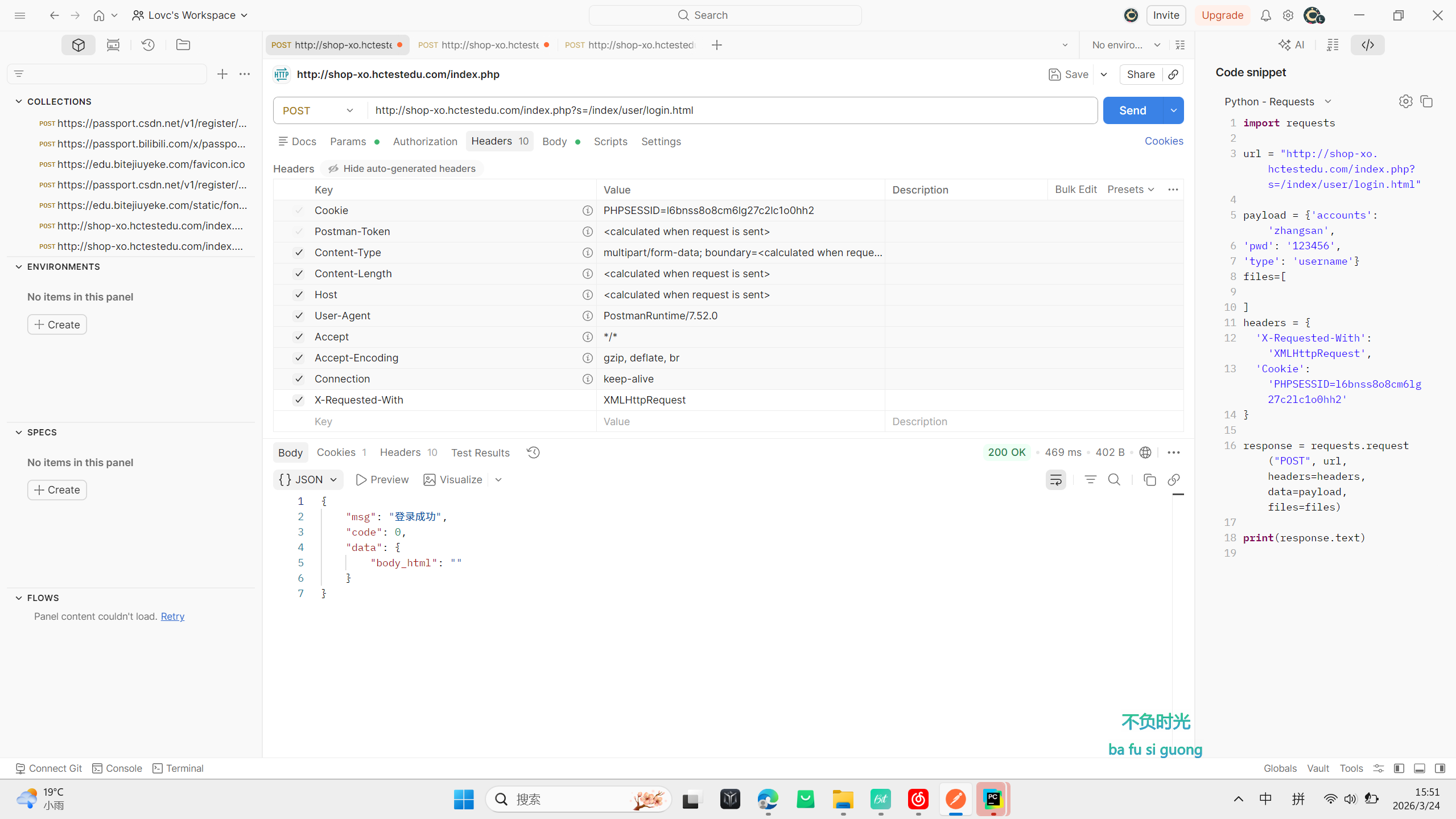
显示登录成功,这意味着我们在登陆接口中成功登录了。
我们这时候看右边的代码,这里postman会自动生成一段代码。这段代码中的header(头部)、payload(负载)、URL等信息已经写好了,我们可以直接拿过来写在我们的自动化脚本中。
python
data = {'accounts': 'zhangsan',
'pwd': '123456',
'type': 'username'
}
headers = {
'X-Requested-With': 'XMLHttpRequest',
}
r=requests.post(url=self.url,data=data,headers=headers)
print(r.json())登录和注册时并不需要 Cookie,因为这些接口是公开的,用于创建新用户,无需携带任何认证信息。而 Cookie 是登录成功后由服务器返回的会话凭证,用于标识当前已登录的用户身份。后续访问个人中心等需要登录的接口时,必须携带这个 Cookie,服务器才能识别你是谁。
返回内容如下:
此时我们接口便登录成功。
8.1 JSON Schema介绍(附自动转换工具及关键字表)
JSON Schema 是一种用于描述和验证 JSON 数据结构的规范语言,类似于 XML 的 DTD 或 XSD。它通过定义 JSON 数据的结构、类型、必填字段、取值范围等约束,确保数据符合预期格式。
核心作用:
数据验证:校验 API 请求/响应是否符合约定格式
接口文档:作为接口契约,清晰定义数据结构
自动化测试:配合测试框架自动验证数据正确性
开发辅助:IDE 可基于 Schema 提供智能提示
常用关键字
| 关键字 | 说明 | 示例 |
|---|---|---|
type |
数据类型 | "string", "integer", "object", "array" |
properties |
定义对象的属性 | {"name": {"type": "string"}} |
required |
必填字段列表 | ["username", "password"] |
additionalProperties |
是否允许额外属性 | false(禁止未定义字段) |
items |
数组元素的类型 | {"type": "array", "items": {"type": "integer"}} |
enum |
枚举值 | {"enum": ["admin", "user"]} |
minimum/maximum |
数值范围 | {"type": "integer", "minimum": 1} |
pattern |
正则表达式 | {"type": "string", "pattern": "^[A-Za-z]+$"} |
比如对于我们这个网页返回的json:
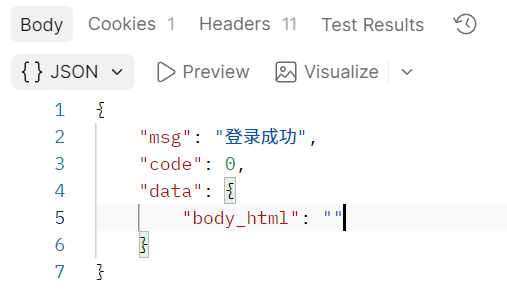
json schema如下:
python
# 定义 JSON 数据结构的校验规则
schema = {
# 整个响应应该是一个对象
"type": "object",
# 定义对象包含哪些属性
"properties": {
# msg 字段必须是字符串类型
"msg": {"type": "string"},
# code 字段必须是整数类型
"code": {"type": "integer"},
# data 字段本身也是一个对象
"data": {
"type": "object",
# data 对象的属性定义
"properties": {
# body_html 必须是字符串
"body_html": {"type": "string"}
},
# 不允许 data 对象包含除了 body_html 以外的其他属性
"additionalProperties": False,
# data 对象中 body_html 字段是必填的
"required": ["body_html"]
}
},
# 整个响应对象不允许包含 msg、code、data 之外的字段
"additionalProperties": False,
# 整个响应对象中 msg、code、data 三个字段都是必填的
"required": ["msg", "code", "data"]
}什么?这么长?

别慌别慌,送你个神器:在线JSON数据生成JSON Schema
不过最好大家还是能看懂,因为有些时候可能需要我们对这个json schema进行一些小的调整。
8.2 validate的介绍
validate 是 jsonschema 库提供的核心函数,用于验证 Python 字典是否符合 JSON Schema 定义的结构规则。
基本用法
python
from jsonschema import validate
validate(instance=response_data, schema=my_schema)参数
instance:待验证的数据(通常是字典或列表)
schema:定义数据结构的 JSON Schema(字典形式)返回值
验证通过时,函数无返回值 (返回
None)验证失败时,抛出
ValidationError异常
我们现在就可以编写用例了,确定好schema、URL、data(payload)、header。发起post请求,然后用validate函数将 r 返回的 json 和JSON Schema对比。
python
import requests
from jsonschema import validate
class TestLogin:
url="http://shop-xo.hctestedu.com/index.php?s=/index/user/login.html"
schema = {
"type": "object",
"properties": {
"msg": {"type": "string"},
"code": {"type": "integer"},
"data": {
"type": "object",
"properties": {
"body_html": {"type": "string"}
},
"additionalProperties": False,
"required": ["body_html"]
}
},
"additionalProperties": False,
"required": ["msg", "code", "data"]
}
def test_login_success(self):
data = {'accounts': 'zhangsan',
'pwd': '123456',
'type': 'username'
}
headers = {
'X-Requested-With': 'XMLHttpRequest',
}
r=requests.post(url=self.url,data=data,headers=headers)
validate(instance=r.json(),schema=self.schema)到这里我们就可以试着复制上面代码,运行一下。我们可以看到:
不过到这里,我们仅仅是判断了返回的 json 格式符合预期。还可以加一些判断比如:
python
#接口状态码为200,代表接口状态正常
assert r.status_code == 200
#msg的值为"登录成功"
assert r.json()['msg'] == '登录成功'代码如下:
python
import requests
from jsonschema import validate
class TestLogin:
url="http://shop-xo.hctestedu.com/index.php?s=/index/user/login.html"
schema = {
"type": "object",
"properties": {
"msg": {"type": "string"},
"code": {"type": "integer"},
"data": {
"type": "object",
"properties": {
"body_html": {"type": "string"}
},
"additionalProperties": False,
"required": ["body_html"]
}
},
"additionalProperties": False,
"required": ["msg", "code", "data"]
}
def test_login_success(self):
data = {'accounts': 'zhangsan',
'pwd': '123456',
'type': 'username'
}
headers = {
'X-Requested-With': 'XMLHttpRequest',
}
r=requests.post(url=self.url,data=data,headers=headers)
validate(instance=r.json(),schema=self.schema)
assert r.status_code == 200
assert r.json()['msg'] == '登录成功'运行结果:
我们来测试一个别的,比如把 data 中的 pwd 改为12345(错误密码):
python
import requests
from jsonschema import validate
class TestLogin:
url="http://shop-xo.hctestedu.com/index.php?s=/index/user/login.html"
schema = {
"type": "object",
"properties": {
"msg": {"type": "string"},
"code": {"type": "integer"},
"data": {
"type": "object",
"properties": {
"body_html": {"type": "string"}
},
"additionalProperties": False,
"required": ["body_html"]
}
},
"additionalProperties": False,
"required": ["msg", "code", "data"]
}
def test_login_success(self):
data = {'accounts': 'zhangsan',
'pwd': '12345',
'type': 'username'
}
headers = {
'X-Requested-With': 'XMLHttpRequest'
}
r=requests.post(url=self.url,data=data,headers=headers)
validate(instance=r.json(),schema=self.schema)
assert r.status_code == 200
assert r.json()['msg'] == '登录成功'结果如下:
OK,这时我们完成了一个测试用例。可是我们不能只验证这一个用例,还有诸多情况。
一个都这么难了?还有?

哈哈,那当然不会让你每个用例费这么大劲,接下来我们再来认识一个语法。
8.3 @pytest.mark.parametrize装饰器
基本语法
python
@pytest.mark.parametrize("参数名列表", 数据列表)
def test_xxx(self, 参数名):
# 测试代码
"参数名列表"是一个字符串,用逗号分隔参数名,例如"username,password,expected_code"。
数据列表是一个可迭代对象,每个元素对应一组参数的值,通常是一个元组或字典。测试函数的参数必须与
"参数名列表"中的参数名一一对应。
举个例子:
python
import pytest
def add(a, b):
return a + b
@pytest.mark.parametrize("x, y, expected", [
(1, 2, 3),
(-1, 1, 0),
(0, 0, 0),
(100, 200, 300)
])
def test_add(x, y, expected):
assert add(x, y) == expected运行后,pytest 会生成 4 个独立的测试用例 :test_add[1-2-3]、test_add[-1-1-0]......每个用例独立执行,任何一个失败都不会影响其他。
除了元组,也可以用字典让代码更清晰:
python
@pytest.mark.parametrize("login", [
{"username": "admin", "password": "123", "msg": "成功"},
{"username": "user", "password": "", "msg": "密码不能为空"},
{"username": "", "password": "123", "msg": "用户名不能为空"},
])
def test_login(login):
# login 是一个字典,通过 login["username"] 取值
assert check_login(login["username"], login["password"]) == login["msg"]8.4 错误测试用例测试
下面我们将我们的代码修改:
注:msg 为返回的信息,预期的错误信息我们写在测试用例中,将预期的信息和实际返回的信息对照,一致即可判断该用例通过。
python
import pytest
import requests
from jsonschema import validate
class TestLogin:
url="http://shop-xo.hctestedu.com/index.php?s=/index/user/login.html"
schema = {
"type": "object",
"properties": {
"msg": {"type": "string"},
"code": {"type": "integer"},
"data": {
"type": "object",
"properties": {
"body_html": {"type": "string"}
},
"additionalProperties": False,
"required": ["body_html"]
}
},
"additionalProperties": False,
"required": ["msg", "code", "data"]
}
@pytest.mark.parametrize("login", [
# 错误的账号错误的密码
{
"accounts": "muluixingcheng",
"pwd": "123456",
"type": "username",
"msg": "登录帐号不存在"
},
# 错误的账号,正确的密码
{
"accounts": "muliuxingcheng",
"pwd": "123456",
"type": "username",
"msg": "登录帐号不存在"
},
# 正确的账号,错误的密码
{
"accounts": "zhangsan",
"pwd": "123666",
"type": "username",
"msg": "密码错误"
},
# 不存在的账号
{
"accounts": "muliuxingcheng",
"pwd": "123456",
"type": "username",
"msg": "登录帐号不存在"
},
# 账号和密码都为空
{
"accounts": "",
"pwd": "",
"type": "username",
"msg": "登录账号不能为空"
},
# 过短的密码格式
{
"accounts": "zhang",
"pwd": "123",
"type": "username",
"msg": "密码格式 6~18 个字符"
},
# 过长的密码格式
{
"accounts": "zhang",
"pwd": "12345678987654321666",
"type": "username",
"msg": "密码格式 6~18 个字符"
},
])
# 异常登录------放在正常登录之前
def test_login_fail(self, login):
data = {
'accounts': login['accounts'],
'pwd': login['pwd'],
'type': login['type'],
}
headers = {
'X-Requested-With': 'XMLHttpRequest'
}
r = requests.post(url=self.url, data=data, headers=headers)
validate(instance=r.json(), schema=self.schema)
assert r.status_code == 200
assert r.json()['msg'] == login["msg"]运行结果:
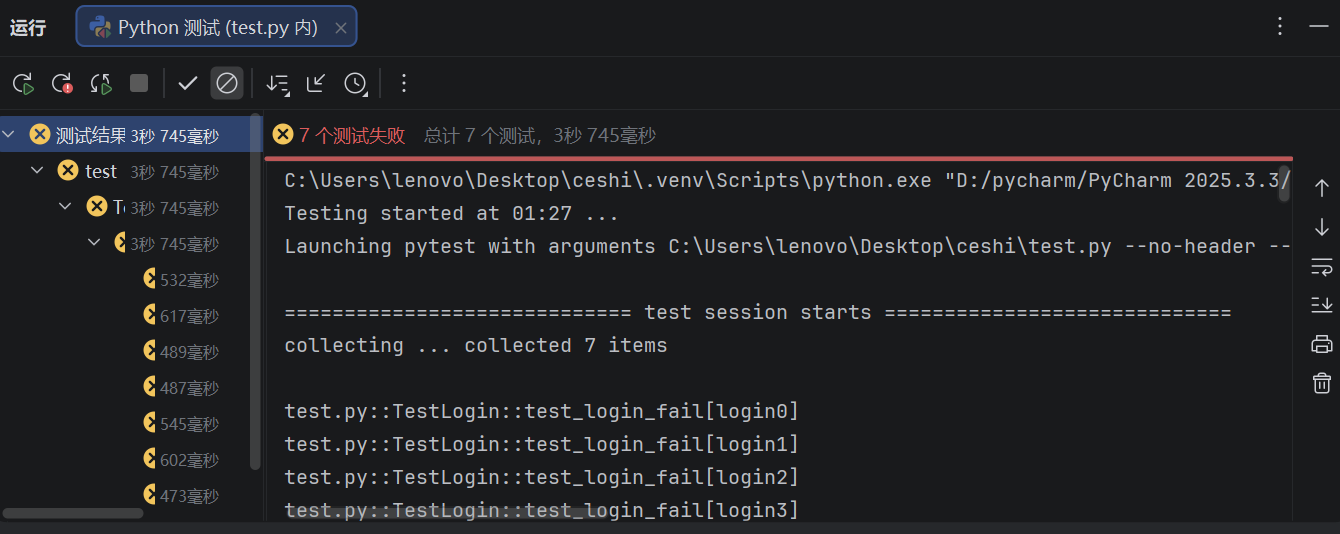
作者你认真的吗?好不容易听明白了,可你这结果咋全是错的?

哈哈哈,那当然是因为这里有一个需要特别注意的地方。
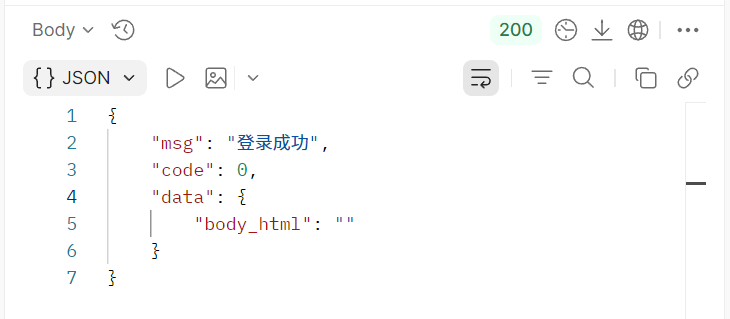
这是登录成功的返回结果:
这是登录失败的返回结果:
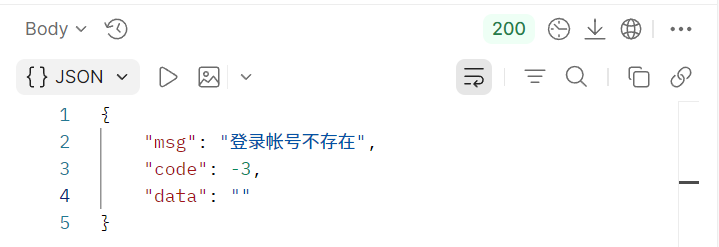
发现没有?**返回的 data 不一样!**一个是空,一个是字符串。因此我们需要修改我们的Schema,分成两种情况,返回空和字符串应该都可以被允许。
代码如下:
python
schema = {
...
"properties": {
...
"data": {
"anyOf": [
{"type": "object", "properties": {"body_html": {"type": "string"}}, "required": ["body_html"], "additionalProperties": False},
{"type": "string"} # 异常时 data 为空字符串
]
}
}
}
anyOf是 JSON Schema 中的一个关键字,表示数据可以匹配其中任意一个子规则 。在这里,
data字段被定义为两种可能:
成功登录时 :
data是一个对象,包含body_html字符串(例如跳转后的页面 HTML)。异常登录时 :
data直接是一个字符串,通常为空字符串"",如接口返回{"code": -1, "data": "", "msg": "登录账号不能为空"}。因此,通过
anyOf将这两种情况都纳入允许范围,使得同一个 schema 既能校验成功响应,也能校验异常响应,避免因data类型不匹配而抛出验证错误。
更改完成:
python
import pytest
import requests
from jsonschema import validate
class TestLogin:
url="http://shop-xo.hctestedu.com/index.php?s=/index/user/login.html"
schema = {
"type": "object",
"properties": {
"msg": {"type": "string"},
"code": {"type": "integer"},
"data": {
"anyof":[
{
"type": "object",
"properties": {
"body_html": {"type": "string"}
},
"additionalProperties": False,
"required": ["body_html"]
},
{"type": "srting"}
]
}
},
"additionalProperties": False,
"required": ["msg", "code", "data"]
}
@pytest.mark.parametrize("login", [
# 错误的账号错误的密码
{
"accounts": "muluixingcheng",
"pwd": "123456",
"type": "username",
"msg": "登录帐号不存在"
},
# 错误的账号,正确的密码
{
"accounts": "muliuxingcheng",
"pwd": "123456",
"type": "username",
"msg": "登录帐号不存在"
},
# 正确的账号,错误的密码
{
"accounts": "zhangsan",
"pwd": "123666",
"type": "username",
"msg": "密码错误"
},
# 不存在的账号
{
"accounts": "muliuxingcheng",
"pwd": "123456",
"type": "username",
"msg": "登录帐号不存在"
},
# 账号和密码都为空
{
"accounts": "",
"pwd": "",
"type": "username",
"msg": "登录账号不能为空"
},
# 过短的密码格式
{
"accounts": "zhang",
"pwd": "123",
"type": "username",
"msg": "密码格式 6~18 个字符"
},
# 过长的密码格式
{
"accounts": "zhang",
"pwd": "12345678987654321666",
"type": "username",
"msg": "密码格式 6~18 个字符"
},
])
# 异常登录------放在正常登录之前
def test_login_fail(self, login):
data = {
'accounts': login['accounts'],
'pwd': login['pwd'],
'type': login['type'],
}
headers = {
'X-Requested-With': 'XMLHttpRequest'
}
r = requests.post(url=self.url, data=data, headers=headers)
validate(instance=r.json(), schema=self.schema)
assert r.status_code == 200
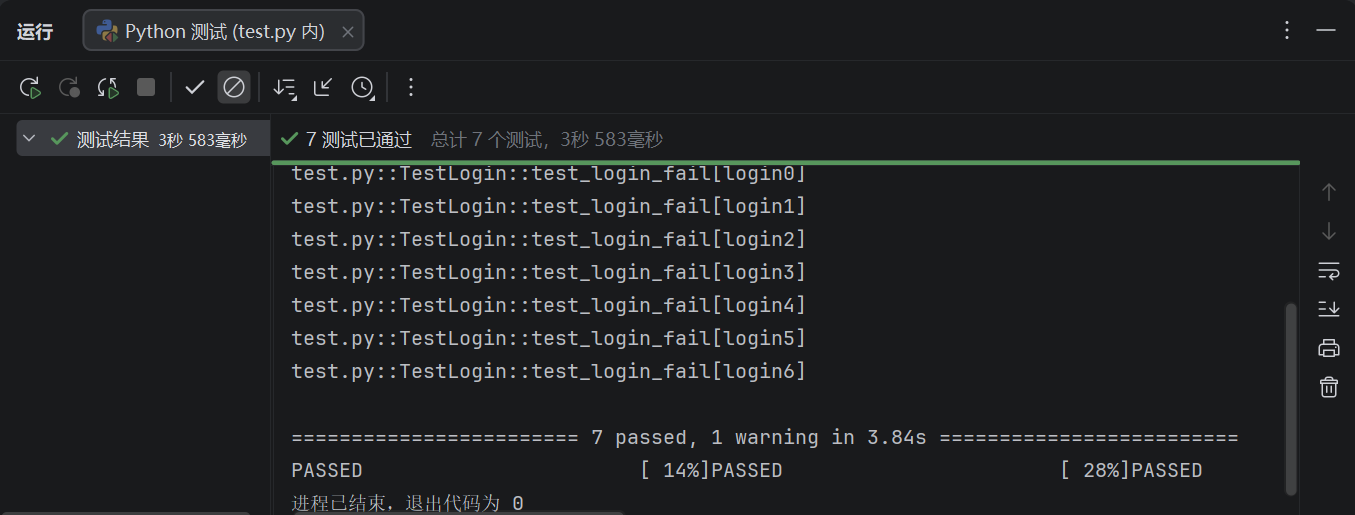
assert r.json()['msg'] == login["msg"]运行结果如下图:
注意!!!
该网站的注册接口没有关闭,为方便其他同学学习,大家请不要用测试用例中的"muliuxingcheng"注册。
上面的代码用例应该是可以全部通过的!如果大家出现测试用例不通过,是有同学将用例中未注册的账号进行了注册,大家可以将"muliuxingcheng"更换成其他未注册的账号(就是自己随便输符合格式要求的字符串)。
8.5 正确测试用例测试
这里和错误测试用例的测试差不多,语法都给大家讲过了,大家自行理解一下,不懂的可以发在评论区:
python
import pytest
import requests
from jsonschema import validate
class TestLogin:
url="http://shop-xo.hctestedu.com/index.php?s=/index/user/login.html"
schema = {
"type": "object",
"properties": {
"msg": {"type": "string"},
"code": {"type": "integer"},
"data": {
"anyof":[
{
"type": "object",
"properties": {
"body_html": {"type": "string"}
},
"additionalProperties": False,
"required": ["body_html"]
},
{"type": "srting"}
]
}
},
"additionalProperties": False,
"required": ["msg", "code", "data"]
}
@pytest.mark.parametrize("login", [
# 错误的账号错误的密码
{
"accounts": "muluixingcheng",
"pwd": "123456",
"type": "username",
"msg": "登录帐号不存在"
},
# 错误的账号,正确的密码
{
"accounts": "muliuxingcheng",
"pwd": "123456",
"type": "username",
"msg": "登录帐号不存在"
},
# 正确的账号,错误的密码
{
"accounts": "zhangsan",
"pwd": "123666",
"type": "username",
"msg": "密码错误"
},
# 不存在的账号
{
"accounts": "muliuxingcheng",
"pwd": "123456",
"type": "username",
"msg": "登录帐号不存在"
},
# 账号和密码都为空
{
"accounts": "",
"pwd": "",
"type": "username",
"msg": "登录账号不能为空"
},
# 过短的密码格式
{
"accounts": "zhang",
"pwd": "123",
"type": "username",
"msg": "密码格式 6~18 个字符"
},
# 过长的密码格式
{
"accounts": "zhang",
"pwd": "12345678987654321666",
"type": "username",
"msg": "密码格式 6~18 个字符"
},
])
# 异常登录------放在正常登录之前
def test_login_fail(self, login):
data = {
'accounts': login['accounts'],
'pwd': login['pwd'],
'type': login['type'],
}
headers = {
'X-Requested-With': 'XMLHttpRequest',
'Cookie': 'PHPSESSID=l6bnss8o8cm6lg27c2lc1o0hh2'
}
r = requests.post(url=self.url, data=data, headers=headers)
validate(instance=r.json(), schema=self.schema)
assert r.status_code == 200
assert r.json()['msg'] == login["msg"]
@pytest.mark.parametrize("login", [
{
"accounts": "zhangsan",
"pwd": "123456",
"type": "username"
},
{
"accounts": "zhang",
"pwd": "123456",
"type": "username"
},
{
"accounts": "lisi",
"pwd": "123456",
"type": "username"
}
])
def test_login_success(self,login):
data = {
'accounts': login['accounts'],
'pwd': login['pwd'],
'type': login['type'],
}
headers = {
'X-Requested-With': 'XMLHttpRequest'
}
r=requests.post(url=self.url,data=data,headers=headers)
validate(instance=r.json(),schema=self.schema)
assert r.status_code == 200
assert r.json()['msg'] == '登录成功'运行结果如下:
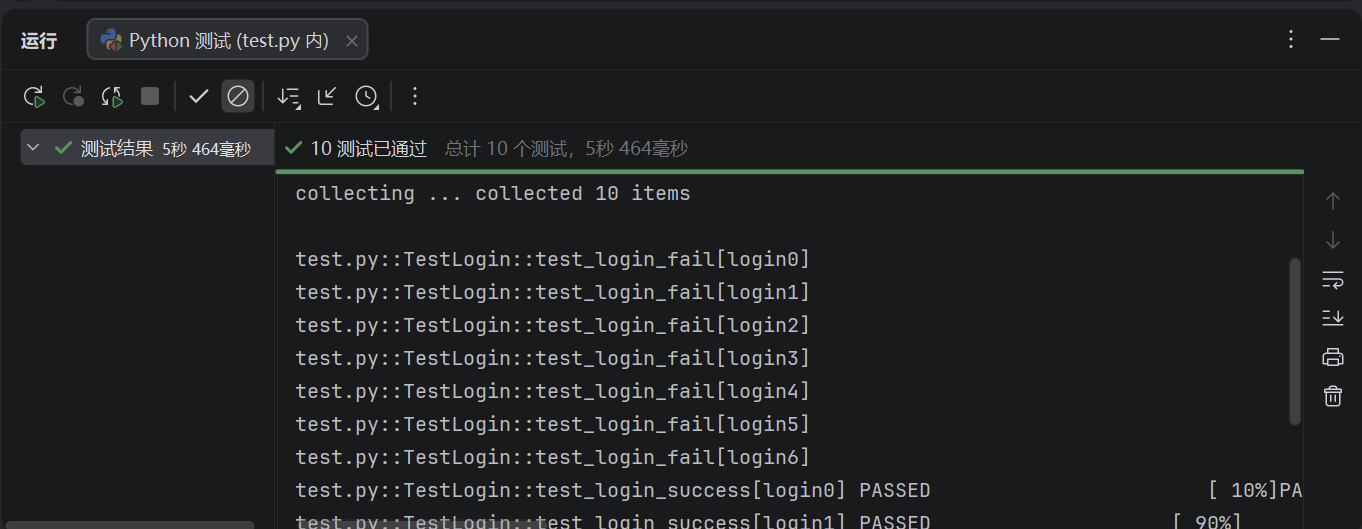
好了,现在我们已经完美的通过了10组测试用例。登录接口的测试完成!
舒坦!

下面我们再去学其他的接口,方法其实都差的不大,会轻松很多。
9.注册接口测试
不是?你找茬吧?注册排在登录接口后面?

很好的问题,主要是注册接口比登录接口稍微复杂一点,大家的问题,我会在下一部分进行解答。
话不多说,先打开postman,将接口连接成功。
直接输入url就行,header还是需要加上X-Resquested-With,值为XMLHttpRequest。
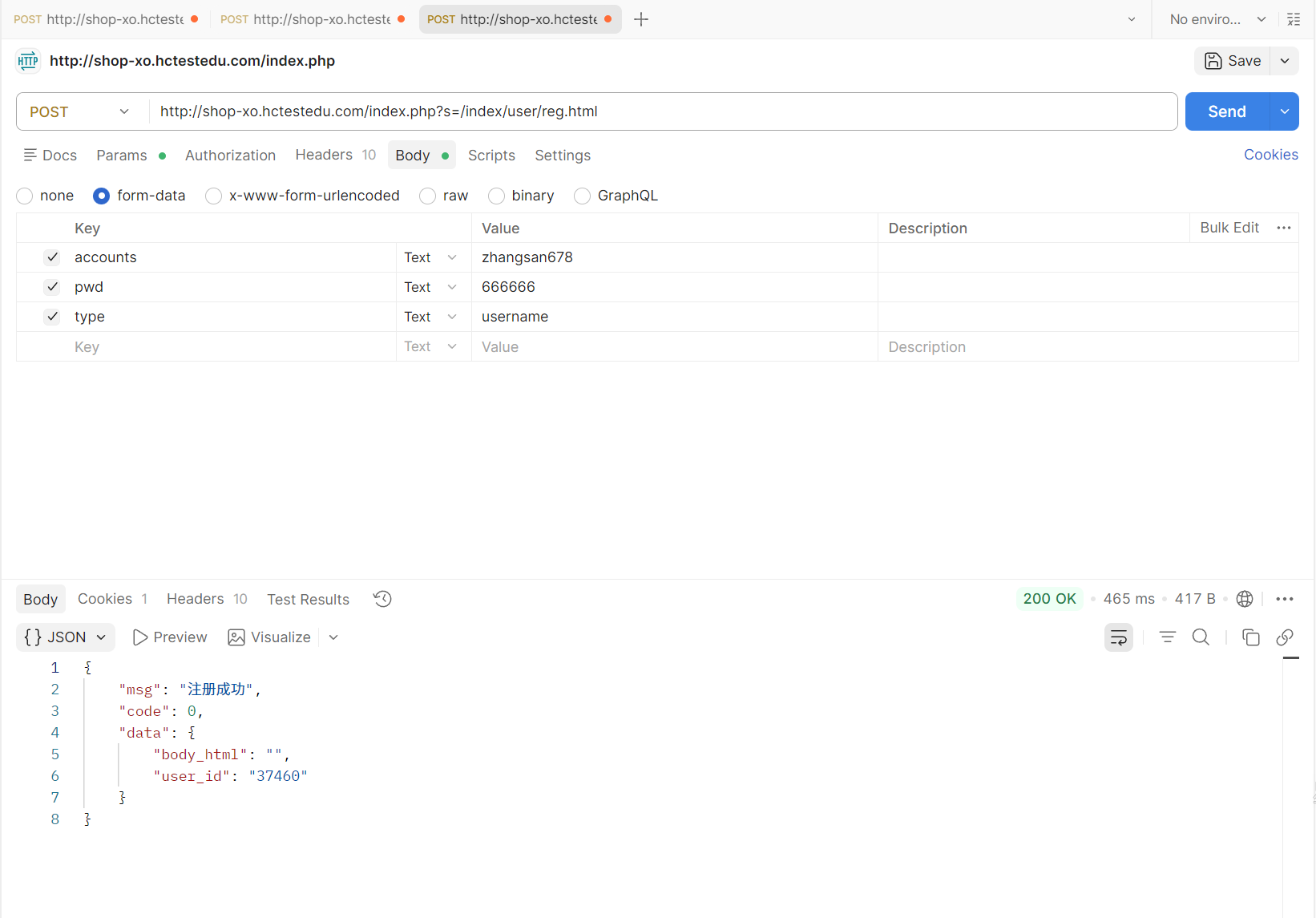
我们随便输一个账号密码
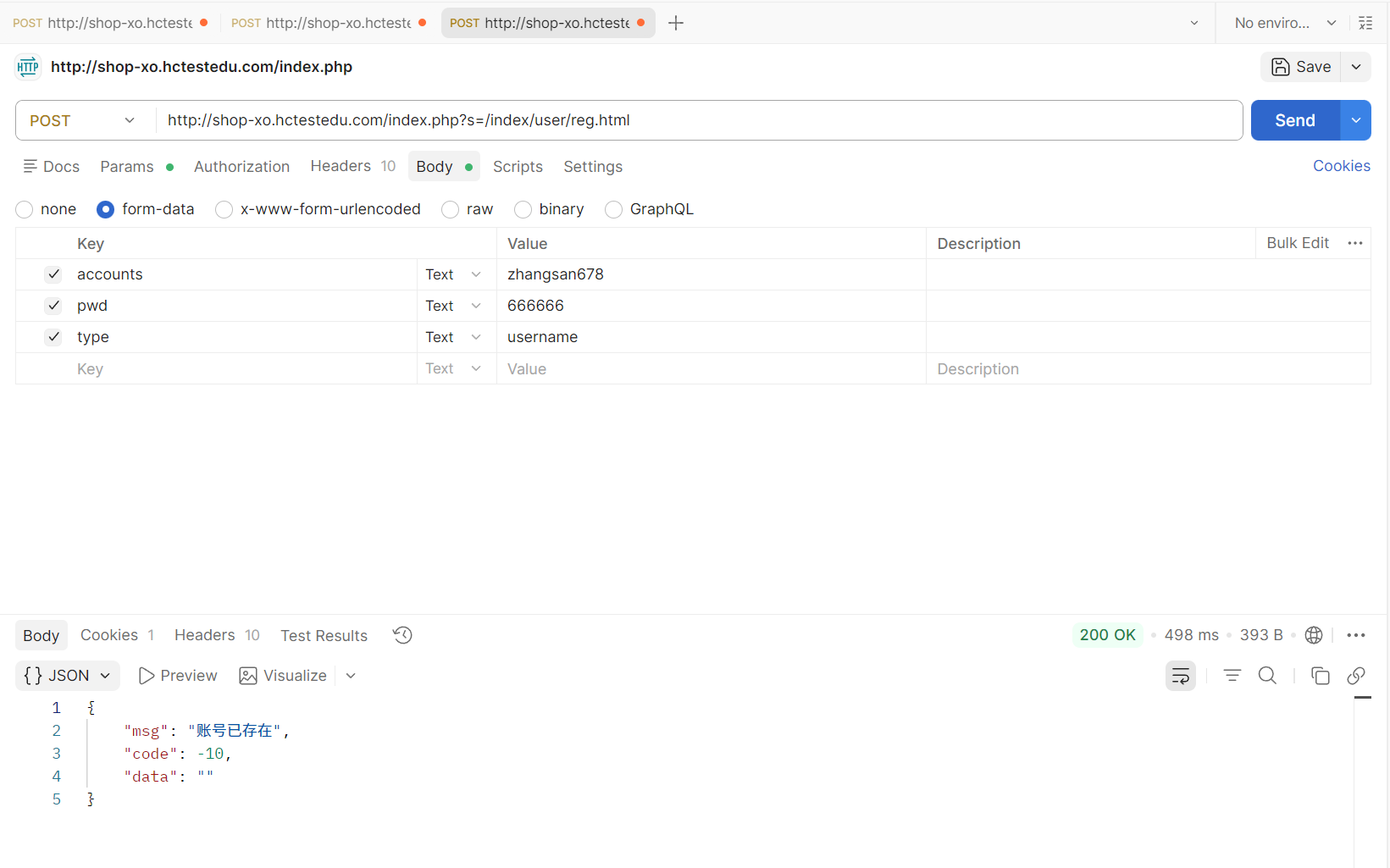
还有注册失败的情况:
我们还是将两种Schema合成一种:
python
Schema={
"type": "object",
"properties": {
"msg": {
"type": "string"
},
"code": {
"type": "integer"
},
"data": {"anyOf":[
{
"type": "object",
"properties": {
"body_html": {
"type": "string"
},
"user_id": {
"type": "string"
}
},
"additionalProperties": False,
"required": [
"body_html",
"user_id"
]
},
{
"type": "string"
}
]}
},
"additionalProperties": False,
"required": [
"msg",
"code",
"data"
]
}直接去postman中拿到自动生成的代码(header部分和data/paylode部分)后,我们现在写一下成功登录的测试用例,随便输一个没人用的账号,就用zhangsan777吧:
python
import pytest
import requests
import time
from jsonschema import validate
class TestSignUp:
url = 'http://shop-xo.hctestedu.com/index.php?s=/index/user/reg.html'
Schema={
"type": "object",
"properties": {
"msg": {
"type": "string"
},
"code": {
"type": "integer"
},
"data": {"anyOf":[
{
"type": "object",
"properties": {
"body_html": {
"type": "string"
},
"user_id": {
"type": "string"
}
},
"additionalProperties": False,
"required": [
"body_html",
"user_id"
]
},
{
"type": "string"
}
]}
},
"additionalProperties": False,
"required": [
"msg",
"code",
"data"
]
}
def test_sign_up_success(self):
data = {'accounts': 'zhangsan777'),
'pwd': '666666',
'type': 'username'}
headers = {
'X-Requested-With': 'XMLHttpRequest',
}
r = requests.request("POST", url=TestSignUp.url, headers=headers, data=data)
validate(instance=r.json(), schema=self.Schema)
assert r.status_code == 200
assert r.json()['msg']=="注册成功"成功通过:

不小心又点了一下运行,诶?怎么刚刚还可以的,现在不行了?我明明没改代码啊?

这是因为第一次没有注册,所以注册成功,可是现在注册以后,重复注册就失败了。
那怎么办?
我推荐使用随机数生成唯一的测试用例,比如再张三后面加上时间戳,这样不是就唯一了吗?至于要不要测试完注销,那就看大家了。不过这次肯定是不行了,因为这个网站没有注销功能。
实现起来很简单,就是账号后面加上时间戳就行,不要忘记导入time:
python
import time
'accounts': 'zhangsan'+str(int(time.time()))
没毛病,接下来就是失败案例,我们还是随便先试一下,就用zhangsan吧,那错误信息肯定是账号已存在:
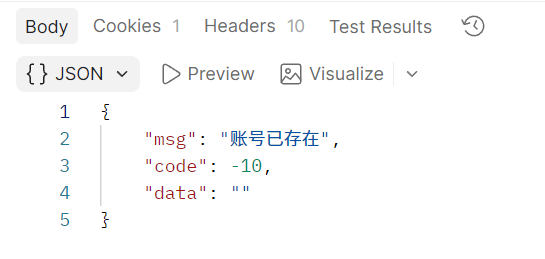
python
import pytest
import requests
import time
from jsonschema import validate
class TestSignUp:
url = 'http://shop-xo.hctestedu.com/index.php?s=/index/user/reg.html'
Schema={
"type": "object",
"properties": {
"msg": {
"type": "string"
},
"code": {
"type": "integer"
},
"data": {"anyOf":[
{
"type": "object",
"properties": {
"body_html": {
"type": "string"
},
"user_id": {
"type": "string"
}
},
"additionalProperties": False,
"required": [
"body_html",
"user_id"
]
},
{
"type": "string"
}
]}
},
"additionalProperties": False,
"required": [
"msg",
"code",
"data"
]
}
def test_sign_up_failure(self):
data = {'accounts': 'zhangsan',
'pwd': '666666',
'type': 'username'}
headers = {
'X-Requested-With': 'XMLHttpRequest',
'Cookie': 'PHPSESSID=27p1md0uipnddnjfcjiohuftdh'
}
r = requests.request("POST", url=TestSignUp.url, headers=headers, data=data)
validate(instance=r.json(), schema=self.Schema)
assert r.status_code == 200
assert r.json()['msg'] == "账号已存在"
def test_sign_up_success(self):
data = {'accounts': 'zhangsan'+str(int(time.time())),
'pwd': '666666',
'type': 'username'}
headers = {
'X-Requested-With': 'XMLHttpRequest',
}
r = requests.request("POST", url=TestSignUp.url, headers=headers, data=data)
validate(instance=r.json(), schema=self.Schema)
assert r.status_code == 200
assert r.json()['msg']=="注册成功"
好了,现在开始写用例:
python
import pytest
import requests
import time
from jsonschema import validate
class TestSignUp:
url = 'http://shop-xo.hctestedu.com/index.php?s=/index/user/reg.html'
Schema={
"type": "object",
"properties": {
"msg": {
"type": "string"
},
"code": {
"type": "integer"
},
"data": {"anyOf":[
{
"type": "object",
"properties": {
"body_html": {
"type": "string"
},
"user_id": {
"type": "string"
}
},
"additionalProperties": False,
"required": [
"body_html",
"user_id"
]
},
{
"type": "string"
}
]}
},
"additionalProperties": False,
"required": [
"msg",
"code",
"data"
]
}
#测试错误用例
@pytest.mark.parametrize("SignUpFail", [
#账号已存在
{
'accounts': 'zhangsan',
'pwd': '666666',
'type': 'username',
'msg':'账号已存在'
},
#账号长度过长
{
'accounts': 'zhangsan7777777777777777777777777777777777',
'pwd': '666666',
'type': 'username',
'msg':'用户名格式由 字母数字下划线 2~18 个字符'
},
#账号长度过短
{
'accounts': 'z' ,
'pwd': '666666',
'type': 'username',
'msg':'用户名格式由 字母数字下划线 2~18 个字符'
},
#账号存在特殊字符
{
'accounts': '#666',
'pwd': '666666',
'type': 'username',
'msg': '用户名格式由 字母数字下划线 2~18 个字符'
}
])
def test_sign_up_failure(self, SignUpFail):
data = {
'accounts': SignUpFail['accounts'],
'pwd': SignUpFail['pwd'],
'type': SignUpFail['type']
}
headers = {
'X-Requested-With': 'XMLHttpRequest',
'Cookie': 'PHPSESSID=27p1md0uipnddnjfcjiohuftdh'
}
r = requests.request("POST", url=TestSignUp.url, headers=headers, data=data)
validate(instance=r.json(), schema=self.Schema)
assert r.status_code == 200
assert r.json()['msg'] == SignUpFail['msg']
#测试正确用例
@pytest.mark.parametrize("SignUpSuccess", [
{
'accounts': 'zhangsan'+str(int(time.time())),
'pwd': '666666',
'type': 'username'
},
{
'accounts': 'lisi'+str(int(time.time())),
'pwd': '666666',
'type': 'username'
},
{
'accounts': 'wangwu'+str(int(time.time())),
'pwd': '666666',
'type': 'username'
}
])
def test_sign_up_success(self, SignUpSuccess):
data = {
'accounts': SignUpSuccess['accounts'],
'pwd': SignUpSuccess['pwd'],
'type': SignUpSuccess['type']
}
headers = {
'X-Requested-With': 'XMLHttpRequest',
}
r = requests.request("POST", url=TestSignUp.url, headers=headers, data=data)
validate(instance=r.json(), schema=self.Schema)
assert r.status_code == 200
assert r.json()['msg']=="注册成功"搞定:

10. 接口间的关联
不知道大家学到这里有没有这样的一个疑问:文章里的登录接口有测试账号,可如果没有呢?我是不是要手动注册一个?
答案肯定是不用手动注册的,毕竟我们的自动化测试用例刚讲完。那我们怎么让这两个文件产生关联,让注册比登录先被运行 (7.1) ?又怎么保证刚注册的账号,可以被记录下来用于登录测试呢 (7.2) ?
10.1 @pytest.mark.order() 的用法
@pytest.mark.order 是 pytest-order 插件提供的标记,用于显式指定测试用例或类的执行顺序。
用法示例:
python
import pytest
# test_register.py
@pytest.mark.order(1)
def test_register():
write_yaml("data.yml", {"user": "test"})
# test_login.py
@pytest.mark.order(2)
def test_login():
user = read_yaml("data.yml", "user")-
数字越小越先执行。
-
可以标记在类上,类中的所有测试方法会按类的顺序整体执行。
10.2 用 YAML 文件传递数据
注册测试将生成的账号密码写入 YAML 文件(如 data.yml),登录测试再读取出来。这样即使两个测试不在同一个文件,也能共享数据。
基本语法:
写入:
pythonimport yaml def write_yaml(file_path, data, mode='a'): with open(file_path, mode, encoding='utf-8') as f: yaml.safe_dump(data, stream=f, allow_unicode=True, default_flow_style=False)
open模式:
'w':覆盖写入(清空原有内容)。
'a'或'a+':追加写入,会在文件末尾添加新的 YAML 文档。
yaml.safe_dump(data, stream, ...):
data:要写入的 Python 对象(通常是字典或列表)。
stream:文件对象(已打开)。
allow_unicode=True:允许输出 Unicode 字符(避免转义)。
default_flow_style=False:使用块样式(更易读),True使用内联样式(紧凑)。追加 vs 覆盖:
覆盖 :
mode='w',每次写入都会替换文件内容。追加 :
mode='a',会在文件末尾追加一个新的 YAML 文档(文件会包含多个---分隔的文档)。读取时需用safe_load_all才能获取全部。
读取:
pythonimport yaml def read_yaml(file_path): with open(file_path, 'r', encoding='utf-8') as f: data = yaml.safe_load(f) return data
open模式 :'r'只读。
yaml.safe_load(stream):将 YAML 文档解析成 Python 对象(字典、列表等)。
如果文件包含多个 YAML 文档 (用
---分隔),safe_load只返回第一个文档。要获取全部,使用yaml.safe_load_all。推荐使用
safe_load而非load,因为load可能执行任意代码(不安全)。
10.3 登录接口测试和注册接口测试的排序(7.1的运用)
我们这一部分的目的就是将登录接口和注册接口修改,使其二者相关联。
其实老简单了,就是把 @pytest.mark.order() 放在想排序的类或函数前面。比如:
python
@pytest.mark.order(1)
class TestRegister: # 整个类第一个执行
def test_register(self): ...
@pytest.mark.order(2)
class TestLogin: # 这个类第二个执行
def test_login(self): ...我们对我们的登录和测试进行修改:
注册接口:
python
import pytest
import requests
import time
from jsonschema import validate
#就加了下面的一行
@pytest.mark.order(2)
class TestSignUp:
url = 'http://shop-xo.hctestedu.com/index.php?s=/index/user/reg.html'
Schema={
"type": "object",
"properties": {
"msg": {
"type": "string"
},
"code": {
"type": "integer"
},
"data": {"anyOf":[
{
"type": "object",
"properties": {
"body_html": {
"type": "string"
},
"user_id": {
"type": "string"
}
},
"additionalProperties": False,
"required": [
"body_html",
"user_id"
]
},
{
"type": "string"
}
]}
},
"additionalProperties": False,
"required": [
"msg",
"code",
"data"
]
}
#测试错误用例
@pytest.mark.parametrize("SignUpFail", [
#账号已存在
{
'accounts': 'zhangsan',
'pwd': '666666',
'type': 'username',
'msg':'账号已存在'
},
#账号长度过长
{
'accounts': 'zhangsan7777777777777777777777777777777777',
'pwd': '666666',
'type': 'username',
'msg':'用户名格式由 字母数字下划线 2~18 个字符'
},
#账号长度过短
{
'accounts': 'z' ,
'pwd': '666666',
'type': 'username',
'msg':'用户名格式由 字母数字下划线 2~18 个字符'
},
#账号存在特殊字符
{
'accounts': '#666',
'pwd': '666666',
'type': 'username',
'msg': '用户名格式由 字母数字下划线 2~18 个字符'
}
])
def test_sign_up_failure(self, SignUpFail):
data = {
'accounts': SignUpFail['accounts'],
'pwd': SignUpFail['pwd'],
'type': SignUpFail['type']
}
headers = {
'X-Requested-With': 'XMLHttpRequest'
}
r = requests.request("POST", url=TestSignUp.url, headers=headers, data=data)
validate(instance=r.json(), schema=self.Schema)
assert r.status_code == 200
assert r.json()['msg'] == SignUpFail['msg']
#测试正确用例
@pytest.mark.parametrize("SignUpSuccess", [
{
'accounts': 'zhangsan'+str(int(time.time())),
'pwd': '666666',
'type': 'username'
},
{
'accounts': 'lisi'+str(int(time.time())),
'pwd': '666666',
'type': 'username'
},
{
'accounts': 'wangwu'+str(int(time.time())),
'pwd': '666666',
'type': 'username'
}
])
def test_sign_up_success(self, SignUpSuccess):
data = {
'accounts': SignUpSuccess['accounts'],
'pwd': SignUpSuccess['pwd'],
'type': SignUpSuccess['type']
}
headers = {
'X-Requested-With': 'XMLHttpRequest',
}
r = requests.request("POST", url=TestSignUp.url, headers=headers, data=data)
validate(instance=r.json(), schema=self.Schema)
assert r.status_code == 200
assert r.json()['msg']=="注册成功"登录接口:
python
import pytest
import requests
from jsonschema import validate
#就加了下面一行
@pytest.mark.order(3)
class TestLogin:
url="http://shop-xo.hctestedu.com/index.php?s=/index/user/login.html"
schema = {
"type": "object",
"properties": {
"msg": {"type": "string"},
"code": {"type": "integer"},
"data": {
"anyof":[
{
"type": "object",
"properties": {
"body_html": {"type": "string"}
},
"additionalProperties": False,
"required": ["body_html"]
},
{"type": "srting"}
]
}
},
"additionalProperties": False,
"required": ["msg", "code", "data"]
}
@pytest.mark.parametrize("login", [
# 错误的账号错误的密码
{
"accounts": "muluixingcheng",
"pwd": "123456",
"type": "username",
"msg": "登录帐号不存在"
},
# 错误的账号,正确的密码
{
"accounts": "muliuxingcheng",
"pwd": "123456",
"type": "username",
"msg": "登录帐号不存在"
},
# 正确的账号,错误的密码
{
"accounts": "zhangsan",
"pwd": "123666",
"type": "username",
"msg": "密码错误"
},
# 不存在的账号
{
"accounts": "muliuxingcheng",
"pwd": "123456",
"type": "username",
"msg": "登录帐号不存在"
},
# 账号和密码都为空
{
"accounts": "",
"pwd": "",
"type": "username",
"msg": "登录账号不能为空"
},
# 过短的密码格式
{
"accounts": "zhang",
"pwd": "123",
"type": "username",
"msg": "密码格式 6~18 个字符"
},
# 过长的密码格式
{
"accounts": "zhang",
"pwd": "12345678987654321666",
"type": "username",
"msg": "密码格式 6~18 个字符"
},
])
# 异常登录------放在正常登录之前
def test_login_fail(self, login):
data = {
'accounts': login['accounts'],
'pwd': login['pwd'],
'type': login['type'],
}
headers = {
'X-Requested-With': 'XMLHttpRequest'
}
r = requests.post(url=self.url, data=data, headers=headers)
validate(instance=r.json(), schema=self.schema)
assert r.status_code == 200
assert r.json()['msg'] == login["msg"]
@pytest.mark.parametrize("login", [
{
"accounts": "zhangsan",
"pwd": "123456",
"type": "username"
},
{
"accounts": "zhang",
"pwd": "123456",
"type": "username"
},
{
"accounts": "lisi",
"pwd": "123456",
"type": "username"
}
])
def test_login_success(self,login):
data = {
'accounts': login['accounts'],
'pwd': login['pwd'],
'type': login['type'],
}
headers = {
'X-Requested-With': 'XMLHttpRequest'
}
r=requests.post(url=self.url,data=data,headers=headers)
validate(instance=r.json(),schema=self.schema)
assert r.status_code == 200
assert r.json()['msg'] == '登录成功'简单吧?不过这并不是最终版,我们一会儿还要实现注册后,将信息存入yaml文件,登陆时读取。实现登录刚刚注册用例注册的账号。
10.4 对写入写出 yaml 方法的封装(7.2的运用)
我们在 yaml_util.py 中将我们的方法封装。
至于为什么用w而不是a呢?这是因为我们每次随机数注册的账号,意义不大,其实保留最后一个就行了,也方便追加记录账号的cookie等信息。
python
import os
import yaml
# 获取当前文件所在目录
BASE_DIR = os.path.dirname(os.path.abspath(__file__))
#写入yaml文件
def write_yaml(filename, data):
with open(os.path.join(BASE_DIR, "data", filename), mode="w", encoding="utf-8") as f:
yaml.safe_dump(data, stream=f)
#读取yaml文件
def read_yaml(filename, key):
with open(os.path.join(BASE_DIR, "data", filename), mode="r", encoding="utf-8") as f:
data = yaml.safe_load(f)
return data[key]
#清空yaml文件
def clear_yaml(filename):
with open(os.path.join(BASE_DIR, "data", filename), mode="w", encoding="utf-8") as f:
f.truncate()10.4.1 with的简介
with是 Python 中用于简化资源管理的关键字,它确保代码块执行完毕后自动释放资源(如关闭文件、释放锁等),即使发生异常也能正确处理。10.4.2
yaml.safe_dump(data, stream=f)
yaml.safe_dump(data, stream=f)的作用是将 Python 对象data以 YAML 格式写入到文件对象f中。
yaml.safe_dump:PyYAML 库提供的安全序列化函数,将 Python 对象(如字典、列表)转换为 YAML 字符串。与yaml.dump相比,它只处理基本类型(字符串、数字、列表、字典等),不会执行危险操作,因此更安全。
stream=f:指定写入的目标流。这里的f是通过open()打开的文件对象(如open('file.yml', 'w'))。stream参数告诉safe_dump将生成的 YAML 内容直接写入该文件,而不是返回字符串。如果你不传stream,函数会返回 YAML 字符串;传入stream则直接写入文件,方便快捷。
pythonimport yaml data = {"name": "张三", "age": 18} with open("data.yml", "w", encoding="utf-8") as f: yaml.safe_dump(data, stream=f, allow_unicode=True)执行后,
data.yml文件中会写入:
pythonname: 张三 age: 18
10.4.3 获取data路径
pythonBASE_DIR = os.path.dirname(os.path.abspath(__file__))它用于获取当前 Python 文件所在的目录的绝对路径,是构建稳定文件路径的常用方法。下面拆解每个部分:
10.4.3.1 __file__
__file__是 Python 的一个内置变量 ,表示当前被执行的脚本文件的路径(可能为相对路径或绝对路径)。例如,如果你的脚本位于
/home/user/project/utils/yaml_util.py,那么:
当直接运行该脚本时,
__file__可能是utils/yaml_util.py(相对路径)。当被其他脚本导入时,
__file__通常就是该文件的绝对路径。注意 :
__file__的值取决于 Python 如何执行它,不一定是绝对路径,所以不能直接作为稳定的目录基准。
10.4.3.2 os.path.abspath()
os.path.abspath(path)将给定的路径转换为绝对路径(从根目录开始的完整路径)。它会把相对路径转换成绝对路径,并消除符号链接等干扰(但不解析符号链接)。
作用:无论
__file__是相对还是绝对,abspath(__file__)总能得到当前脚本文件的绝对路径。示例:
pythonimport os print(os.path.abspath("utils/yaml_util.py")) # 输出:/home/user/project/utils/yaml_util.py
10.4.3.3 os.path.dirname()
os.path.dirname(path)返回路径中的目录部分,去掉最后一个文件名(或最后一个路径组件)。例如:
os.path.dirname("/home/user/project/utils/yaml_util.py")返回/home/user/project/utils。
10.5 注册及登录代码融入项目
我们现在对我们的登录和注册接口进行最后一次升级,这将是我们的最终版自动化代码:
注册接口:
将requests.post替换成自定义的请求Request().post,并将最后一次注册成功的账号,密码,类型等信息写入文件data.yaml。改动是在代码末尾添加了文件写入,大家前面理解的话可以直接看末尾。
python
import pytest
import requests
import time
from jsonschema import validate
from utils.yaml_util import write_yaml
from utils.request_util import Request
#就加了下面的一行
@pytest.mark.order(2)
class TestSignUp:
url = 'http://shop-xo.hctestedu.com/index.php?s=/index/user/reg.html'
Schema={
"type": "object",
"properties": {
"msg": {
"type": "string"
},
"code": {
"type": "integer"
},
"data": {"anyOf":[
{
"type": "object",
"properties": {
"body_html": {
"type": "string"
},
"user_id": {
"type": "string"
}
},
"additionalProperties": False,
"required": [
"body_html",
"user_id"
]
},
{
"type": "string"
}
]}
},
"additionalProperties": False,
"required": [
"msg",
"code",
"data"
]
}
#测试错误用例
@pytest.mark.parametrize("SignUpFail", [
#账号已存在
{
'accounts': 'zhangsan',
'pwd': '666666',
'type': 'username',
'msg':'账号已存在'
},
#账号长度过长
{
'accounts': 'zhangsan7777777777777777777777777777777777',
'pwd': '666666',
'type': 'username',
'msg':'用户名格式由 字母数字下划线 2~18 个字符'
},
#账号长度过短
{
'accounts': 'z' ,
'pwd': '666666',
'type': 'username',
'msg':'用户名格式由 字母数字下划线 2~18 个字符'
},
#账号存在特殊字符
{
'accounts': '#666',
'pwd': '666666',
'type': 'username',
'msg': '用户名格式由 字母数字下划线 2~18 个字符'
}
])
def test_sign_up_failure(self, SignUpFail):
data = {
'accounts': SignUpFail['accounts'],
'pwd': SignUpFail['pwd'],
'type': SignUpFail['type']
}
headers = {
'X-Requested-With': 'XMLHttpRequest'
}
r=Request().post(url=TestSignUp.url,data=data,headers=headers)
validate(instance=r.json(), schema=TestSignUp.Schema)
assert r.status_code == 200
assert r.json()['msg'] == SignUpFail['msg']
#测试正确用例
@pytest.mark.parametrize("SignUpSuccess", [
{
'accounts': 'zhangsan'+str(int(time.time())),
'pwd': '666666',
'type': 'username'
},
{
'accounts': 'lisi'+str(int(time.time())),
'pwd': '666666',
'type': 'username'
},
{
'accounts': 'wangwu'+str(int(time.time())),
'pwd': '666666',
'type': 'username'
}
])
def test_sign_up_success(self, SignUpSuccess):
data = {
'accounts': SignUpSuccess['accounts'],
'pwd': SignUpSuccess['pwd'],
'type': SignUpSuccess['type']
}
headers = {
'X-Requested-With': 'XMLHttpRequest'
}
r=Request().post(url=TestSignUp.url,data=data,headers=headers)
validate(instance=r.json(), schema=TestSignUp.Schema)
assert r.status_code == 200
assert r.json()['msg']=="注册成功"
#将UserCase写入data.yaml,UseCase中有账号密码和类型
UseCase={
"user_account": SignUpSuccess['accounts'], # 注意:键名是 'accounts'
"user_pwd": SignUpSuccess['pwd'],
"user_type": SignUpSuccess['type']
}
write_yaml("data.yaml", UseCase)yaml文件:
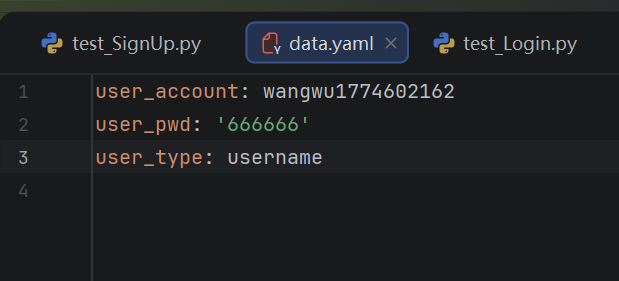
日志文件:
登录接口:
将requests.post替换成自定义的请求Request().post,并除在文件末尾加入了写入语句,还有测试成功的测试用例也增加了一组,是刚刚data.yaml文件中存储的账号信息。
python
import pytest
from jsonschema import validate
from utils.yaml_util import read_yaml, write_yaml
from utils.request_util import Request
#就加了下面一行
@pytest.mark.order(3)
class TestLogin:
url="http://shop-xo.hctestedu.com/index.php?s=/index/user/login.html"
schema = {
"type": "object",
"properties": {
"msg": {"type": "string"},
"code": {"type": "integer"},
"data": {
"anyof":[
{
"type": "object",
"properties": {
"body_html": {"type": "string"}
},
"additionalProperties": False,
"required": ["body_html"]
},
{"type": "srting"}
]
}
},
"additionalProperties": False,
"required": ["msg", "code", "data"]
}
@pytest.mark.parametrize("login", [
# 错误的账号错误的密码
{
"accounts": "muluixingcheng",
"pwd": "123456",
"type": "username",
"msg": "登录帐号不存在"
},
# 错误的账号,正确的密码
{
"accounts": "muliuxingcheng",
"pwd": "123456",
"type": "username",
"msg": "登录帐号不存在"
},
# 正确的账号,错误的密码
{
"accounts": "zhangsan",
"pwd": "123666",
"type": "username",
"msg": "密码错误"
},
# 不存在的账号
{
"accounts": "muliuxingcheng",
"pwd": "123456",
"type": "username",
"msg": "登录帐号不存在"
},
# 账号和密码都为空
{
"accounts": "",
"pwd": "",
"type": "username",
"msg": "登录账号不能为空"
},
# 过短的密码格式
{
"accounts": "zhang",
"pwd": "123",
"type": "username",
"msg": "密码格式 6~18 个字符"
},
# 过长的密码格式
{
"accounts": "zhang",
"pwd": "12345678987654321666",
"type": "username",
"msg": "密码格式 6~18 个字符"
},
])
# 异常登录------放在正常登录之前
def test_login_fail(self, login):
data = {
'accounts': login['accounts'],
'pwd': login['pwd'],
'type': login['type'],
}
headers = {
'X-Requested-With': 'XMLHttpRequest'
}
r = Request().post(url=self.url, data=data, headers=headers)
validate(instance=r.json(), schema=self.schema)
assert r.status_code == 200
assert r.json()['msg'] == login["msg"]
@pytest.mark.parametrize("login", [
{
"accounts": "zhangsan",
"pwd": "123456",
"type": "username"
},
{
"accounts": "zhang",
"pwd": "123456",
"type": "username"
},
{
"accounts": "lisi",
"pwd": "123456",
"type": "username"
},
#刚刚注册的账号作为测试用例
{
"accounts": read_yaml("data.yaml", "user_account"),
"pwd": read_yaml("data.yaml", "user_pwd"),
"type": read_yaml("data.yaml", "user_type"),
}
])
def test_login_success(self,login):
data = {
'accounts': login['accounts'],
'pwd': login['pwd'],
'type': login['type'],
}
headers = {
'X-Requested-With': 'XMLHttpRequest',
}
r=Request().post(url=self.url,data=data,headers=headers)
validate(instance=r.json(),schema=self.schema)
assert r.status_code == 200
assert r.json()['msg'] == '登录成功'
cookies={
"user_cookie":r.cookies.get_dict()
}
write_yaml("data.yaml", cookies)第一次运行:
yaml文件:

日志文件:
第二次运行:
这是因为我们的写入方法是w,直接覆盖,因此data.yaml中的数据被覆盖了,存储内容为我们的cookie(这个项目后面也用不着账号密码等信息了,拿到cookie就相当拿到了登录凭证)。因此我们每次运行登录之前,要先运行一下注册。
大家如果想解决这个问题也挺简单,自己写一个方式为追加的写入方法就行了,有想尝试的小伙伴可以自己实现一下。
11. 购物车的添加删除
登录和注册好像挺难的是吧?但其实主要是要学的语法太多了,可能一时间不好消化。仔细想想,其根本还是我们前面讲的:
输入 → 操作 → 断言输出
至于我为什么选择讲购物车接口呢?主要有以下原因:
-
需要登录 → 演示如何从 YAML 读取 Cookie 完成身份认证。
-
参数丰富 → 涉及商品 ID、数量、规格等,适合参数化测试。
-
业务逻辑复杂 → 库存校验、数量累加、重复添加等,需要断言结果。
-
异常场景多 → 未登录、缺货、参数错误等,覆盖各种错误码。
-
数据一致性 → 必要时需要我们查看数据库数据是否和测试结果一致
我们下面写一下购物车的增删功能:
11.1 购物车增加商品
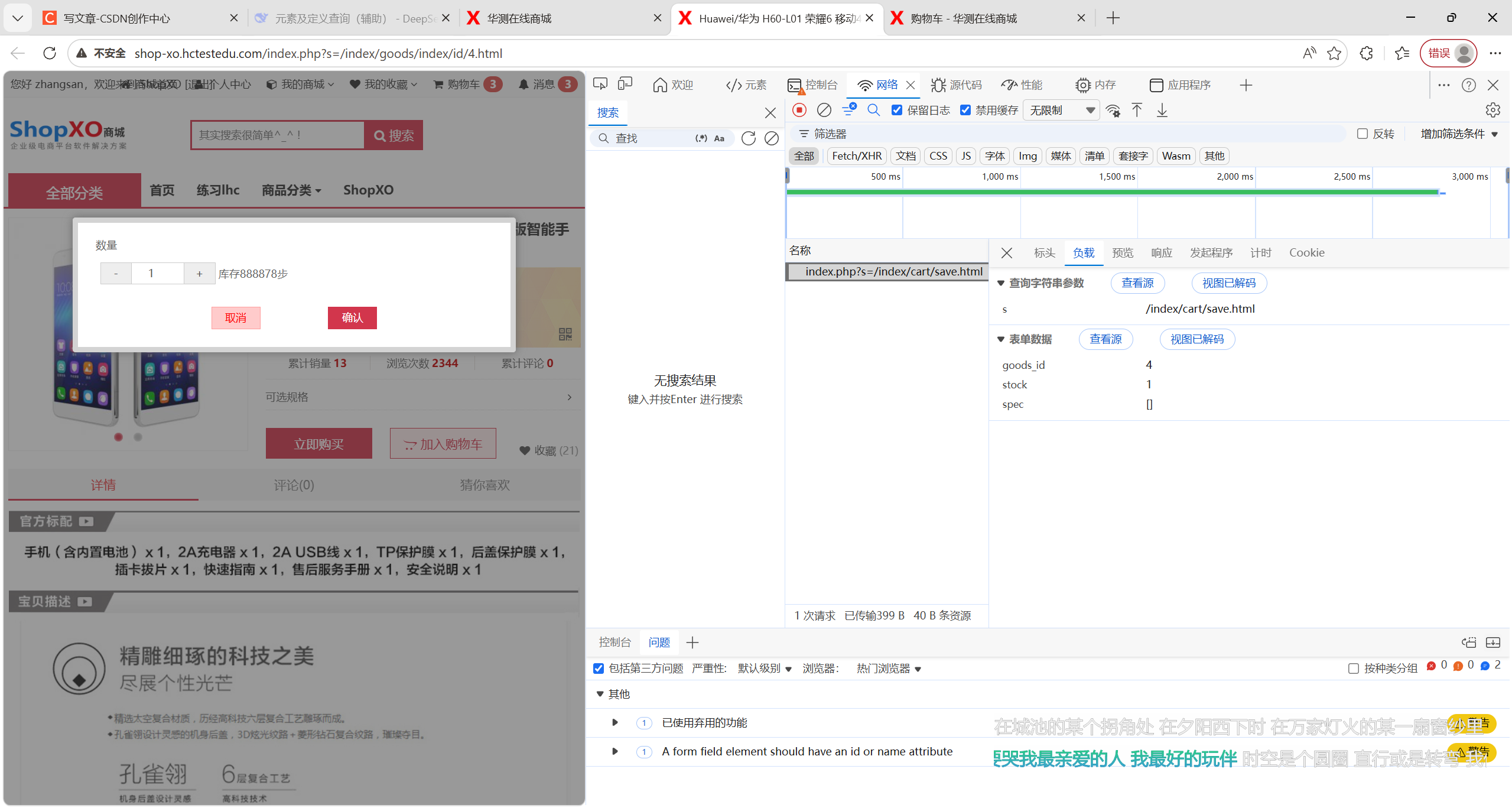
打开开发者工具,按确认的时候注意看"网络"的新增接口,捕捉到接口信息:
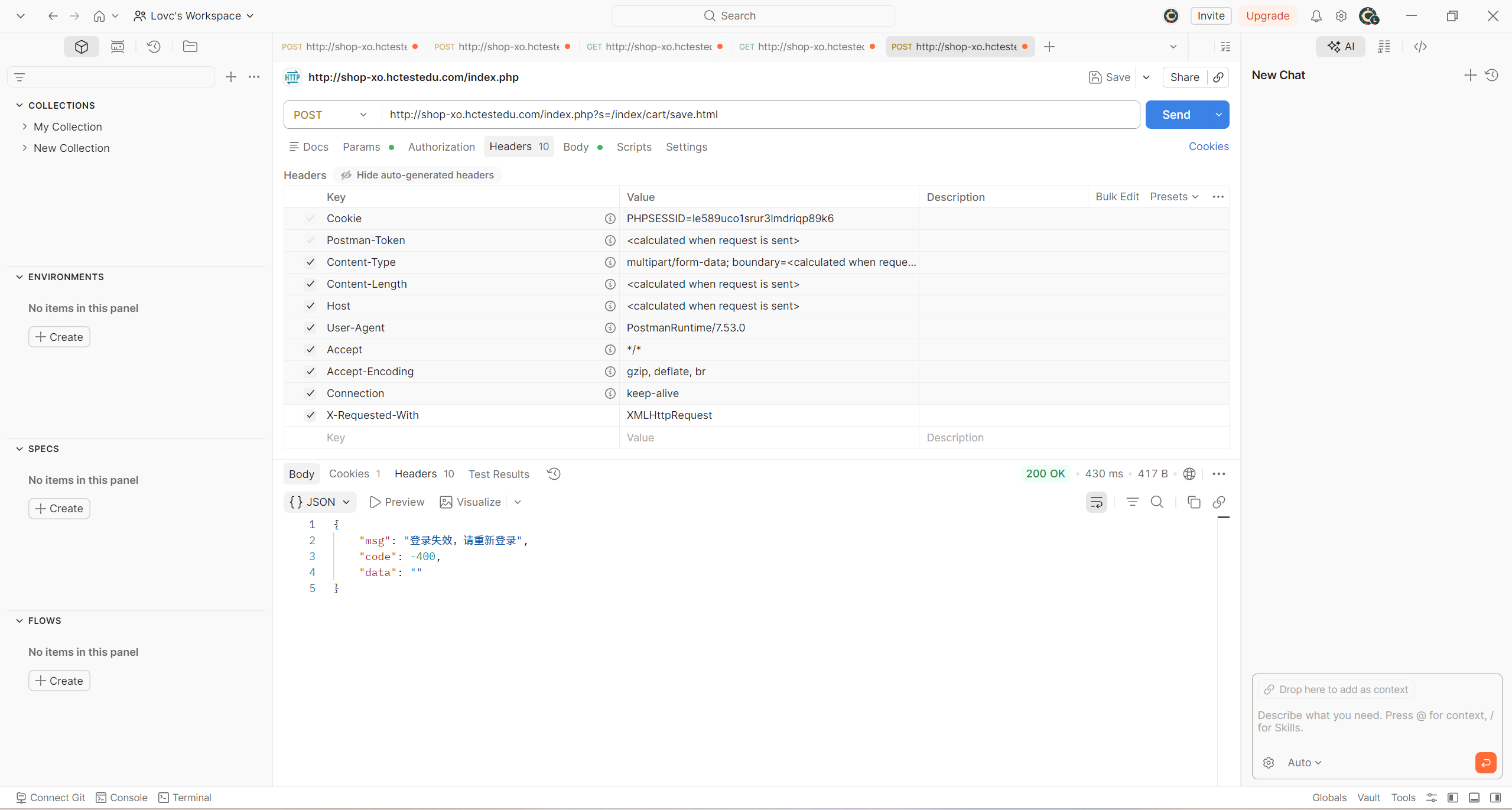
这是没有登录时的返回结果:
登录后:
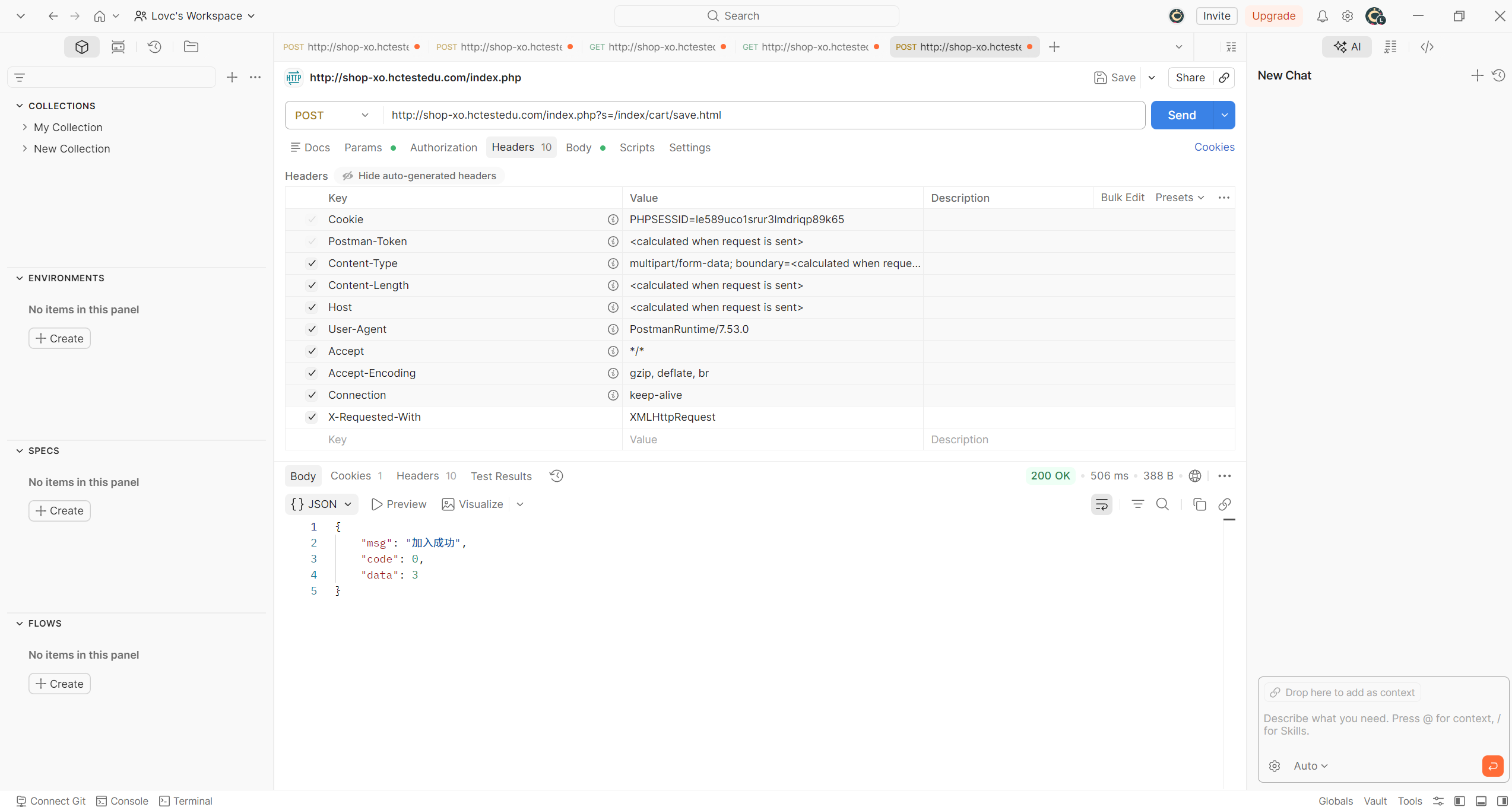
诶,发现个好消息,就是这次的 json schema 不用合并。
那我们下面只需要写测试用例就行。其实和前面的逻辑差不多,我不详细讲解了。代码我添加了详细注释,大家有问题可以评论区提问:
python
import pytest
from utils.yaml_util import read_yaml
from jsonschema import validate
from utils.request_util import Request
@pytest.mark.order(4)
class TestCartAdd:
url = "http://shop-xo.hctestedu.com/index.php?s=/index/cart/save.html"
schema={
"type": "object",
"properties": {
"msg": {
"type": "string"
},
"code": {
"type": "integer"
},
"data": {
"anyOf": [
{"type": "integer"},
{"type": "string"}
]}
},
"additionalProperties": False,
"required": [
"msg",
"code",
"data"
]
}
def test_add_cart_unauthorized(self):
#未登录状态添加购物车
payload = {
'goods_id': '3',
'stock': '1',
'spec': '[]'
}
headers = {
'X-Requested-With': 'XMLHttpRequest'
}
# 不传 cookies 参数
r = Request().post(url=TestCartAdd.url, headers=headers, data=payload)
# 此处预期状态码是200(不同网站返回不同,401和200都有可能)
assert r.status_code in [200, 401]
# 如果状态码 200,业务 code 应为非 0,且 msg 包含"登录"
if r.status_code == 200:
assert r.json()['msg']=="登录失效,请重新登录"
else:
assert r.status_code == 401
def test_add_cart_invalid_cookie(self):
#携带无效 Cookie 添加购物车
payload = {'goods_id': '3', 'stock': '1', 'spec': '[]'}
headers = {'X-Requested-With': 'XMLHttpRequest'}
# 构造一个错误的 Cookie 字典
invalid_cookie = {'PHPSESSID': 'invalid_session_id'}
r = Request().post(url=TestCartAdd.url, headers=headers, data=payload, cookies=invalid_cookie)
# 断言与未登录类似
assert r.status_code in [200, 401]
if r.status_code == 200:
assert r.json()['msg'] == "登录失效,请重新登录"
else:
assert r.status_code == 401
@pytest.mark.parametrize("Add_Fail",[
#商品数量超出库存
{
'goods_id': '3',
'stock': '1000000000000000',
'spec': '[]',
'msg':"库存不足"
},
# 商品不存在或已删除
{
'goods_id': '30',
'stock': '1',
'spec': '[]',
'msg':"商品不存在或已删除"
},
# 商品购买数量为0
{
'goods_id': '3',
'stock': '0',
'spec': '[]',
'msg': "购买数量有误"
},
# 商品参数有误
{
'goods_id': '2',
'stock': '1',
'spec': '[{"type": "套餐", "value": "套餐"}, {"type": "颜色", "value": "五彩斑斓的黑"},{"type": "容量", "value": "64G"}]',
'msg': "没有相关规格"
}
])
def test_Add_Fail(self,Add_Fail):
payload = {
'goods_id': Add_Fail['goods_id'],
'stock': Add_Fail['stock'],
'spec': Add_Fail['spec']}
headers = {
'X-Requested-With': 'XMLHttpRequest'
}
r = Request().post( url=TestCartAdd.url, headers=headers, data=payload, cookies=read_yaml(
"data.yaml", "user_cookie"))
assert r.status_code == 200
assert r.json()['msg']==Add_Fail['msg']
validate(instance=r.json(), schema=self.schema)
@pytest.mark.parametrize("Add_Success",[
#添加一件商品
{
'goods_id': '3',
'stock': '1',
'spec': '[]'},
#添加多件商品
{
'goods_id': '3',
'stock': '10',
'spec': '[]'
},
#添加含参数的商品
{
'goods_id': '2',
'stock': '1',
'spec':[{"type":"套餐","value":"套餐一"},{"type":"颜色","value":"银色"},{"type":"容量","value":"64G"}]
},
#添加多件含参商品
{
'goods_id': '2',
'stock': '10',
'spec': [{"type": "套餐", "value": "套餐一"}, {"type": "颜色", "value": "银色"},{"type": "容量", "value": "64G"}]
}
])
def test_Add_Success(self,Add_Success):
payload = {
'goods_id': Add_Success['goods_id'],
'stock': Add_Success['stock'],
'spec': Add_Success['spec']}
headers = {
'X-Requested-With': 'XMLHttpRequest'
}
r = Request().post(url=TestCartAdd.url, headers=headers, data=payload, cookies=read_yaml(
"data.yaml", "user_cookie"))
assert r.status_code == 200
assert r.json()['msg']=='加入成功'
validate(instance=r.json(), schema=self.schema)11.2 购物车删除商品
我们来讲一下删除商品的核心思路:添加一件商品,然后在购物车的列表里面找到这个商品,再进行删除。
捕捉接口信息:

错误传参时:
正确传参时:
而删除购物车商品最重要的参数就是这个id,这个id是动态变化的。我们该怎么做呢?
我们需要找到这个id的数据接口,这里的id数据是直接嵌入在HTML页面中的(tr中的 data-id就是)。
我们用第二条信息举例:

代码在这里:
table里面是列表,tr是每一行的信息。第一个tr是小米的手机,第二个是魅族的。我们看到魅族的data-id是20374。那就postman走起。

输入后点击send:
刷新网页,删除成功:

代码其实和前面差不多,唯一需要我们确定的就是:请求返回的内容是HTML信息,我们怎么从这么多HTML代码中获取到我们想要的id信息?
引入一个新东西:BeautifulSoup
11.2.1 BeautifulSoup从html代码获取想要的信息
这里主要讲解select() -- CSS 选择器
python
# 类选择器
items = soup.select('.cart-list .cart-item')
# ID 选择器
box = soup.select('#main')
# 标签+类
divs = soup.select('div.item')
# 属性选择器
inputs = soup.select('input[name="username"]')
# 层级
text = soup.select('.cart-item .price span')如果将select()换为**select_one(),** 即返回第一个匹配的元素,相当于 select()[0]。
11.2.2 购物车删除接口详解
11.2.2.1公共部分
主要是url和负载信息,这里不啰嗦了:
python
import pytest
from bs4 import BeautifulSoup
from utils.yaml_util import read_yaml
from utils.request_util import Request
@pytest.mark.order(5)
class TestCartDelete:
add_url = "http://shop-xo.hctestedu.com/index.php?s=/index/cart/save.html"
list_url = "http://shop-xo.hctestedu.com/index.php?s=/index/cart/index.html"
delete_url = "http://shop-xo.hctestedu.com/index.php?s=/index/cart/delete.html"
def test_delete_success(self):
# 直接从 YAML 读取 Cookie
cookie = read_yaml("data.yaml", "user_cookie")
headers = {'X-Requested-With': 'XMLHttpRequest'}11.2.2.2 添加商品
前面已经讲了添加了,这里也不详细讲解:
python
# 1. 添加商品
add_payload = {'goods_id': '3', 'stock': '1', 'spec': '[]'}
add_r = Request().post(url=self.add_url, data=add_payload, cookies=cookie, headers=headers)
assert add_r.json()['msg'] == '加入成功'11.2.2.3 查找商品
这部分算是核心,也是难点所在:
先发送请求:
为什么获取页面不加 'X-Requested-With': 'XMLHttpRequest'头
因为我们要的是完整的 HTML 页面,以便解析出商品行的
data-id。加了头可能会返回空页面或 JSON。
python
list_r = Request().get(url=self.list_url, cookies=cookie)用BeautifulSoup处理list_r,soup(名字可自定义)接收:
python
# soup 表示BeautifulSoup处理后的结果
soup = BeautifulSoup(list_r.text, 'html.parser')然后我们要用 soup.select() 选择一下,话不多说上图:
找到列表的区域,tbody是列表内容整体部分,每一行tr代表一个不同的商品:
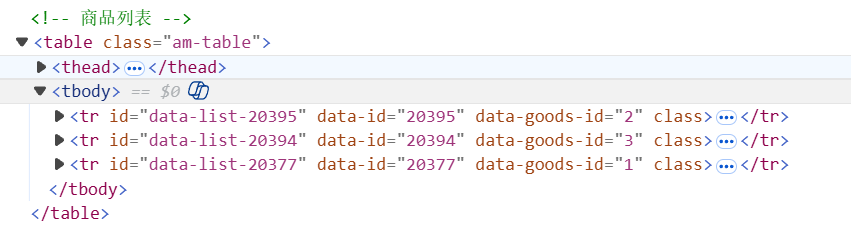
我们复制一下第一个tr的selector:

内容如下,其含义为,id 值为 data-list-20395:
data-list-20395但我们如果想获取列表中的所有信息,就需要获取所有 <tr id="data-list-xxxx"......>,这该怎么办呢?这么写:
tr[id^="data-list-"]这个选择器
tr[id^="data-list-"]是一个 CSS 选择器 ,用在 BeautifulSoup 的select()方法中,用于从 HTML 文档中查找特定的元素。拆解说明
tr:表示要查找的 HTML 标签是<tr>(表格中的一行)。
[id^="data-list-"]:这是一个 属性选择器 ,用于匹配id属性值以data-list-开头的元素。
^=符号表示"以...开头"。整个选择器的意思是:选择所有
id属性值以"data-list-"开头的<td>元素。
这个就是我们的商品列表。返回内容是一个列表:
python
# items 返回商品列表
items=soup.select('tr[id^="data-list-"]')我们尝试一下:
python
# 2. 找到商品
list_r = Request().get(url=self.list_url, cookies=cookie)
# soup 表示BeautifulSoup处理后的结果
soup = BeautifulSoup(list_r.text, 'html.parser')
# items 返回商品列表
# data-list-20395
items=soup.select('tr[id^="data-list-"]')
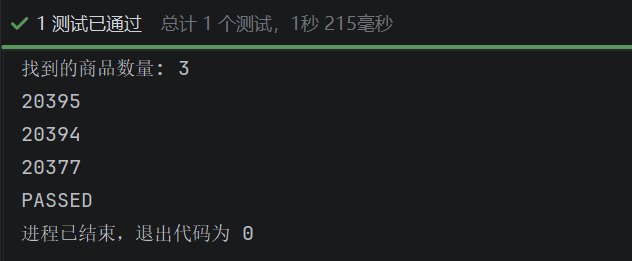
print("找到的商品数量:", len(items))
for item in items:
print(item.get('data-id'))数量和data-id都正确!
ok,我们加一个小小的断言,防止购物车里什么都没有:
python
# 2. 找到商品
list_r = Request().get(url=self.list_url, cookies=cookie)
# soup 表示BeautifulSoup处理后的结果
soup = BeautifulSoup(list_r.text, 'html.parser')
# items 返回商品列表
# data-list-20395
items=soup.select('tr[id^="data-list-"]')
assert len(items) > 0, "购物车为空,无法测试删除"那我们准备写删除:
11.2.2.4 删除商品
这里没什么难点,就是data-id和data-goods-id不要搞混就行:
python
#循环查找刚刚加入购物车的产品
for item in items:
if item.get('data-goods-id')=='3':
# 3. 调用删除接口(需要 Ajax 头)
del_headers = {'X-Requested-With': 'XMLHttpRequest'}
del_data={'value': '','field': '','id': item.get('data-id')}
del_r = Request().post(url=self.delete_url, data=del_data, cookies=cookie, headers=del_headers)
assert del_r.status_code == 200
assert del_r.json()['msg'] == '删除成功'代码整体:
python
import pytest
from bs4 import BeautifulSoup
from utils.yaml_util import read_yaml
from utils.request_util import Request
@pytest.mark.order(5)
class TestCartDelete:
add_url = "http://shop-xo.hctestedu.com/index.php?s=/index/cart/save.html"
list_url = "http://shop-xo.hctestedu.com/index.php?s=/index/cart/index.html"
delete_url = "http://shop-xo.hctestedu.com/index.php?s=/index/cart/delete.html"
def test_delete_success(self):
# 直接从 YAML 读取 Cookie
cookie = read_yaml("data.yaml", "user_cookie")
headers = {'X-Requested-With': 'XMLHttpRequest'}
# 1. 添加商品
add_payload = {'goods_id': '3', 'stock': '1', 'spec': '[]'}
add_r = Request().post(url=self.add_url, data=add_payload, cookies=cookie, headers=headers)
assert add_r.json()['msg'] == '加入成功'
# 2. 找到商品
list_r = Request().get(url=self.list_url, cookies=cookie)
# soup 表示BeautifulSoup处理后的结果
soup = BeautifulSoup(list_r.text, 'html.parser')
# items 返回商品列表
# data-list-20395
items=soup.select('tr[id^="data-list-"]')
assert len(items) > 0, "购物车为空,无法测试删除"
#循环查找刚刚加入购物车的产品
for item in items:
if item.get('data-goods-id')=='3':
# 3. 调用删除接口(需要 Ajax 头)
del_headers = {'X-Requested-With': 'XMLHttpRequest'}
del_data={'value': '','field': '','id': item.get('data-id')}
del_r = Request().post(url=self.delete_url, data=del_data, cookies=cookie, headers=del_headers)
assert del_r.status_code == 200
assert del_r.json()['msg'] == '删除成功'12. 项目小结
还有很多接口没有完善,不过我们的覆盖已经比较全面了,先小小的总结一下:
这个电商项目覆盖了自动化测试的核心流程:
注册 → 动态生成账号,写入 YAML
登录 → 读取账号,获取 Cookie 并更新 YAML
购物车添加 → 参数化成功/失败场景,校验 JSON Schema
购物车查询 → 解析 HTML(服务端渲染),提取商品信息
购物车删除 → 通过页面解析获取动态 ID,调用删除接口并验证
覆盖的技术点:
pytest 框架(参数化、顺序控制、夹具)
requests 库(GET/POST、Cookie 处理、请求头)
JSON Schema 校验响应结构
BeautifulSoup 解析 HTML(CSS 选择器)
YAML 文件读写(测试数据共享)
处理 Ajax 与非 Ajax 请求的区别(
X-Requested-With)
上面学完,你应该就可以直接独立写测试用例了。下面我给项目升级一下。使其有更方便的入口,不用自己一个一个去打开。并且可以自动生成一个测试报告。
13. 项目升级
还记得我们的 @pytest.mark.order() 吗?就是调顺序那个。之前没用到,这里就可以作为程序运行的依据了。
13.1 登录接口的修改
我们的登录接口需要改的原因是:
order只控制 "谁先跑" ,但 pytest 在 "开跑之前" 就已经把你的代码扫了一遍,并且把参数化里的read_yaml当场执行了。
我们修改方向如下:
-
不要在
@pytest.mark.parametrize里写read_yaml。 -
把动态账号的登录单独写成一个普通方法(不用参数化),在方法 内部 去
read_yaml。
这样,pytest 收集阶段只会看到"这个方法需要运行",而不会当场执行 read_yaml。等到 真正轮到它跑的时候 ,注册已经完成,data.yaml 里就有数据了,自然就不会报错。
python
import pytest
from jsonschema import validate
from utils.yaml_util import read_yaml, write_yaml
from utils.request_util import Request
@pytest.mark.order(3)
class TestLogin:
url = "http://shop-xo.hctestedu.com/index.php?s=/index/user/login.html"
schema = {
"type": "object",
"properties": {
"msg": {"type": "string"},
"code": {"type": "integer"},
"data": {
"anyOf": [
{
"type": "object",
"properties": {
"body_html": {"type": "string"}
},
"additionalProperties": False,
"required": ["body_html"]
},
{"type": "string"}
]
}
},
"additionalProperties": False,
"required": ["msg", "code", "data"]
}
# ---------- 异常登录测试 ----------
@pytest.mark.parametrize("login", [
{"accounts": "muluixingcheng", "pwd": "123456", "type": "username", "msg": "登录帐号不存在"},
{"accounts": "muliuxingcheng", "pwd": "123456", "type": "username", "msg": "登录帐号不存在"},
{"accounts": "zhangsan", "pwd": "123666", "type": "username", "msg": "密码错误"},
{"accounts": "muliuxingcheng", "pwd": "123456", "type": "username", "msg": "登录帐号不存在"},
{"accounts": "", "pwd": "", "type": "username", "msg": "登录账号不能为空"},
{"accounts": "zhang", "pwd": "123", "type": "username", "msg": "密码格式 6~18 个字符"},
{"accounts": "zhang", "pwd": "12345678987654321666", "type": "username", "msg": "密码格式 6~18 个字符"},
])
def test_login_fail(self, login):
data = {
'accounts': login['accounts'],
'pwd': login['pwd'],
'type': login['type'],
}
headers = {'X-Requested-With': 'XMLHttpRequest'}
r = Request().post(url=self.url, data=data, headers=headers)
validate(instance=r.json(), schema=self.schema)
assert r.status_code == 200
assert r.json()['msg'] == login["msg"]
# ---------- 固定账号登录成功(参数化,不写入cookie)----------
@pytest.mark.parametrize("login", [
{"accounts": "zhang", "pwd": "123456", "type": "username"},
{"accounts": "lisi", "pwd": "123456", "type": "username"},
{"accounts": "zhangsan", "pwd": "123456", "type": "username"},
])
def test_login_success_fixed(self, login):
data = {
'accounts': login['accounts'],
'pwd': login['pwd'],
'type': login['type'],
}
headers = {'X-Requested-With': 'XMLHttpRequest'}
r = Request().post(url=self.url, data=data, headers=headers)
validate(instance=r.json(), schema=self.schema)
assert r.status_code == 200
assert r.json()['msg'] == '登录成功'
# 固定账号登录不写入cookie,避免覆盖动态账号的cookie
# ---------- 动态注册账号登录成功(单独方法,读取YAML,并写入cookie)----------
def test_login_success_registered(self):
# 读取注册时保存的账号密码
username = read_yaml("data.yaml", "user_account")
password = read_yaml("data.yaml", "user_pwd")
data = {
'accounts': username,
'pwd': password,
'type': 'username',
}
headers = {'X-Requested-With': 'XMLHttpRequest'}
r = Request().post(url=self.url, data=data, headers=headers)
validate(instance=r.json(), schema=self.schema)
assert r.status_code == 200
assert r.json()['msg'] == '登录成功'
# 登录成功后将cookie写入YAML,供后续购物车等测试使用
cookie_dict = r.cookies.get_dict()
write_yaml("data.yaml", {"user_cookie": cookie_dict})ok,我们来写一下run.py(终于快写完这个博客了,好不容易)。
13.2 文件入口run.py
代码很短,直接将讲解放在了代码注释里:
python
# run.py - 自动化测试的统一入口脚本
# 导入 pytest 框架,用于运行测试用例
import pytest
# 从自定义的日志工具模块导入 logger 类,用于记录日志
from utils.logger_util import logger
# 判断是否直接运行此脚本(而不是被作为模块导入)
if __name__ == "__main__":
# 获取配置好的日志记录器对象
log = logger.getlog()
# 记录一条 INFO 级别的日志,表示测试开始
log.info("开始运行全部测试用例...")
# 直接调用 pytest.main(),会自动读取 pytest.ini 中的 addopts
# 如果想指定测试目录,可以传 ["cases/"],也可以不传(默认收集当前目录下所有测试)
exit_code = pytest.main(["cases/"]) # 或者 pytest.main()
# 记录测试结束及退出码(0 表示全部通过,非0 表示有失败)
log.info(f"测试结束,退出码: {exit_code}")运行结果:
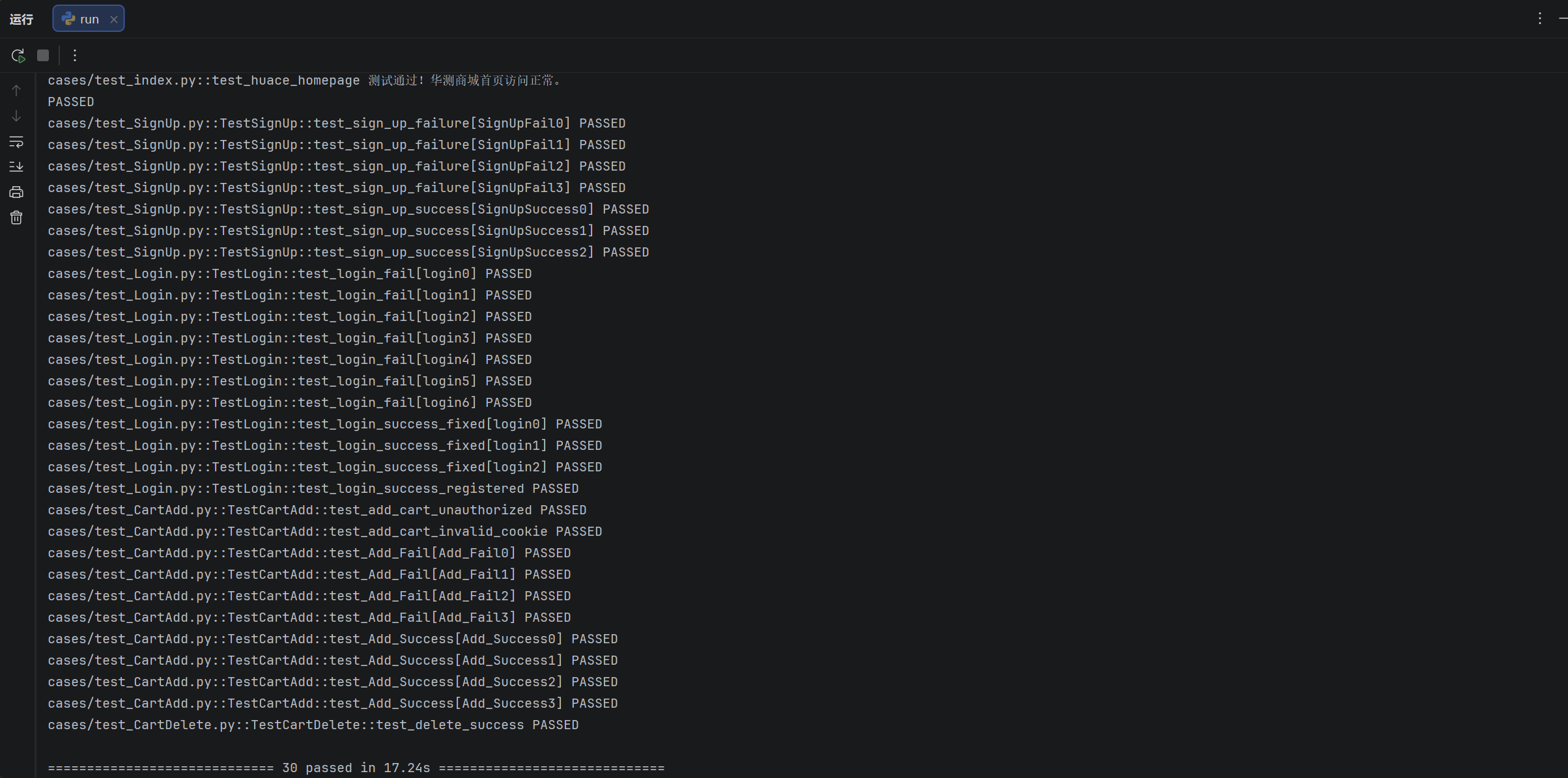
13.3 生成更美观的测试报告
13.3.1 修改pytest.ini 文件
我们修改我们的pytest.ini文件为:
python
[pytest]
addopts = -vs --alluredir allure-results --alluredir allure-results 是 pytest 中 Allure 报告插件的参数 ,用于指定 Allure 原始数据文件的输出目录。
-
--alluredir:固定参数名,告诉 pytest 要生成 Allure 格式的测试结果。 -
allure-results:你指定的目录名称(可以自定义)。运行测试后,pytest 会在当前目录下创建allure-results文件夹,里面存放 JSON、XML 等中间文件。
使用:我们运行run.py后,会自动生成很多文件:
这些中间文件不能直接查看,需要用 Allure 命令行工具转换成 HTML 报告。
我们在项目根目录下创建文件夹 allure-reports:
然后控制台输入此命令:
python
allure generate .\allure-results\ -o .\allure-reports\这个命令用于将 Allure 的原始测试结果数据转换成可视化的 HTML 报告。
allure generate:Allure 命令行工具的核心命令,用于生成报告。
.\allure-results\:指定输入目录,即 pytest 生成的原始数据(JSON/XML 文件)所在的文件夹。
-o .\allure-reports\:指定输出目录 ,生成的 HTML 报告将保存到allure-reports文件夹中。执行后,你可以用浏览器打开
allure-reports/index.html查看美观的测试报告。如果目录已存在,建议加上--clean参数清除旧文件。
自动生成的结果如下:
看到那个index.html文件了吗?用浏览器打开它:
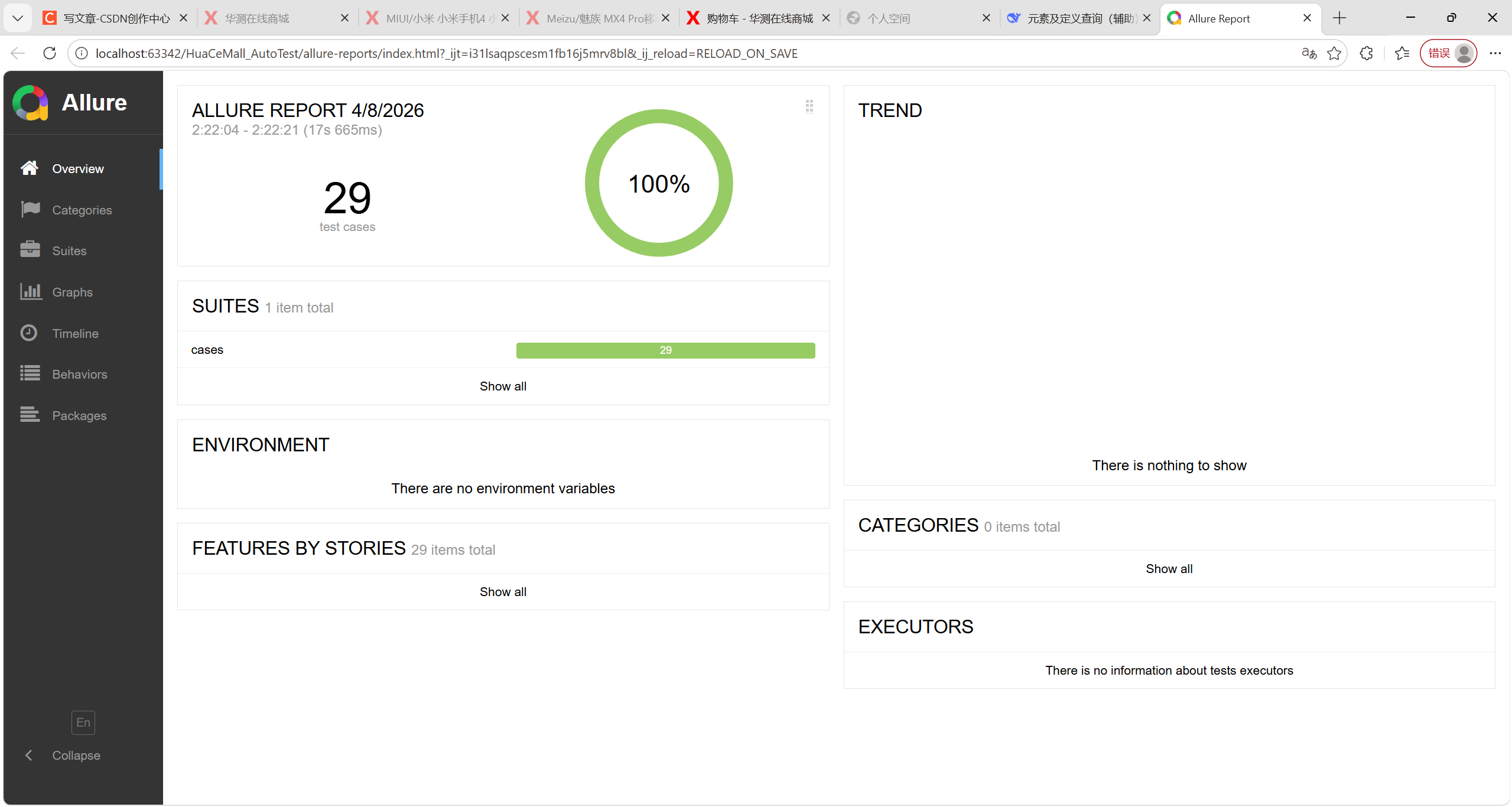
suites中还有更详细的信息,可以看用例详情:
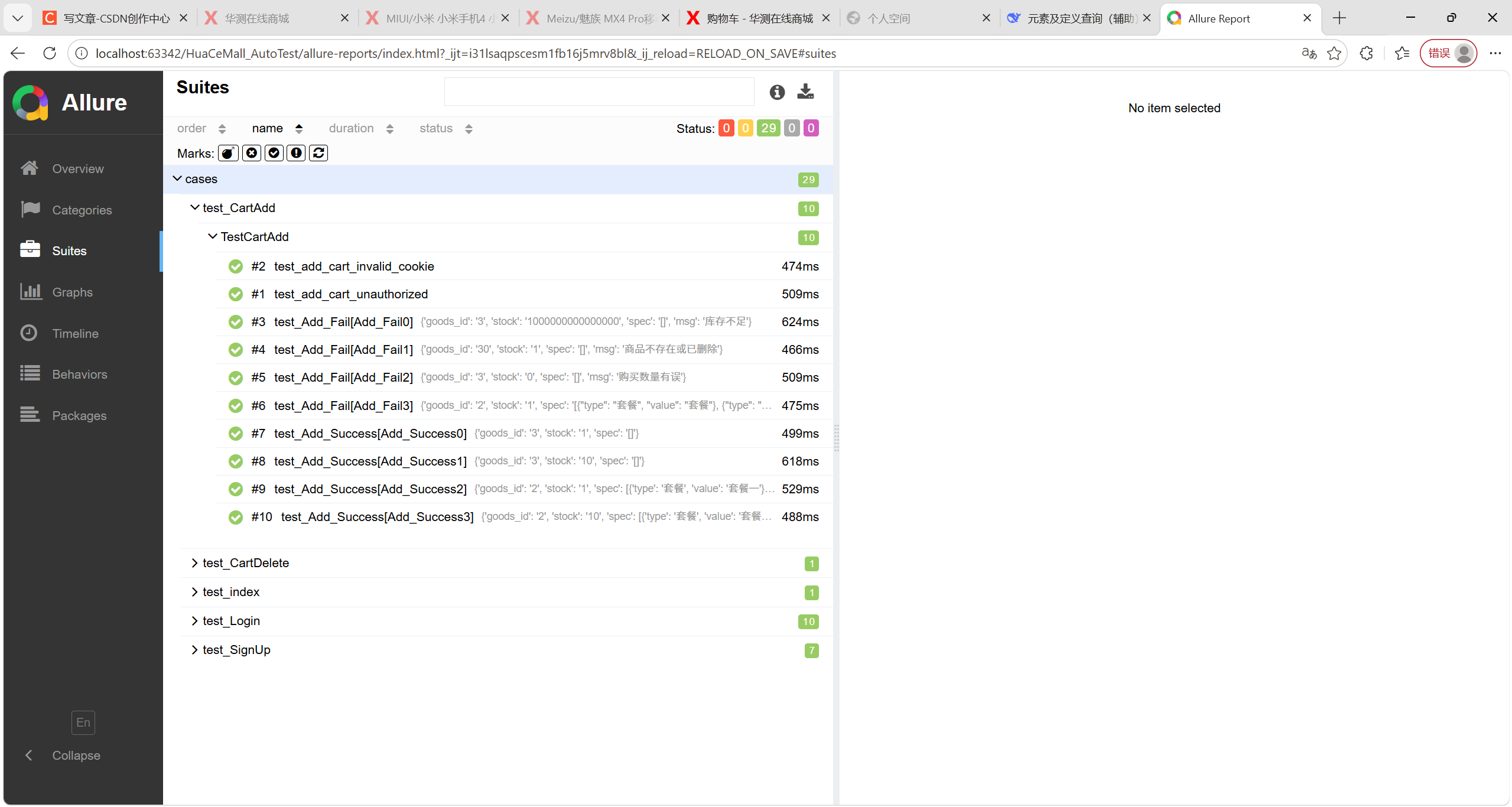
到这里,我们的项目就算是结束了,感谢大家的阅读。
所谓"纸上得来终觉浅,绝知此事要躬行",大家想测试什么可以自己尝试着去写一下。也可以将好的想法发在评论区。
学会了就给博主点个赞呗?(✪ω✪)
---------(如有问题,欢迎评论区提问)---------