随着 Llama 3 系列模型的开源,开源大语言模型的能力再次被推向新高度。在实际业务中,经常面临需要问答对生成的需求,比如说智能客服等等,用于构建知识库或训练更垂直的模型。还可以根据具体需求,选择适合的模型,数据集,结合RAG进行特定领域微调。在特殊领域,通用大模型能力效果是不如微调的模型的。
本文将在单张 RTX 4090 (24GB) 显卡上,通过 LoRA 微调对 Llama3-8B 进行微调(具体模型可换),将其打造为一个高效的 化学含能QA 问答对(将数据集替换后微调可以打造为:公司专业顾问专家等等)生成专家。
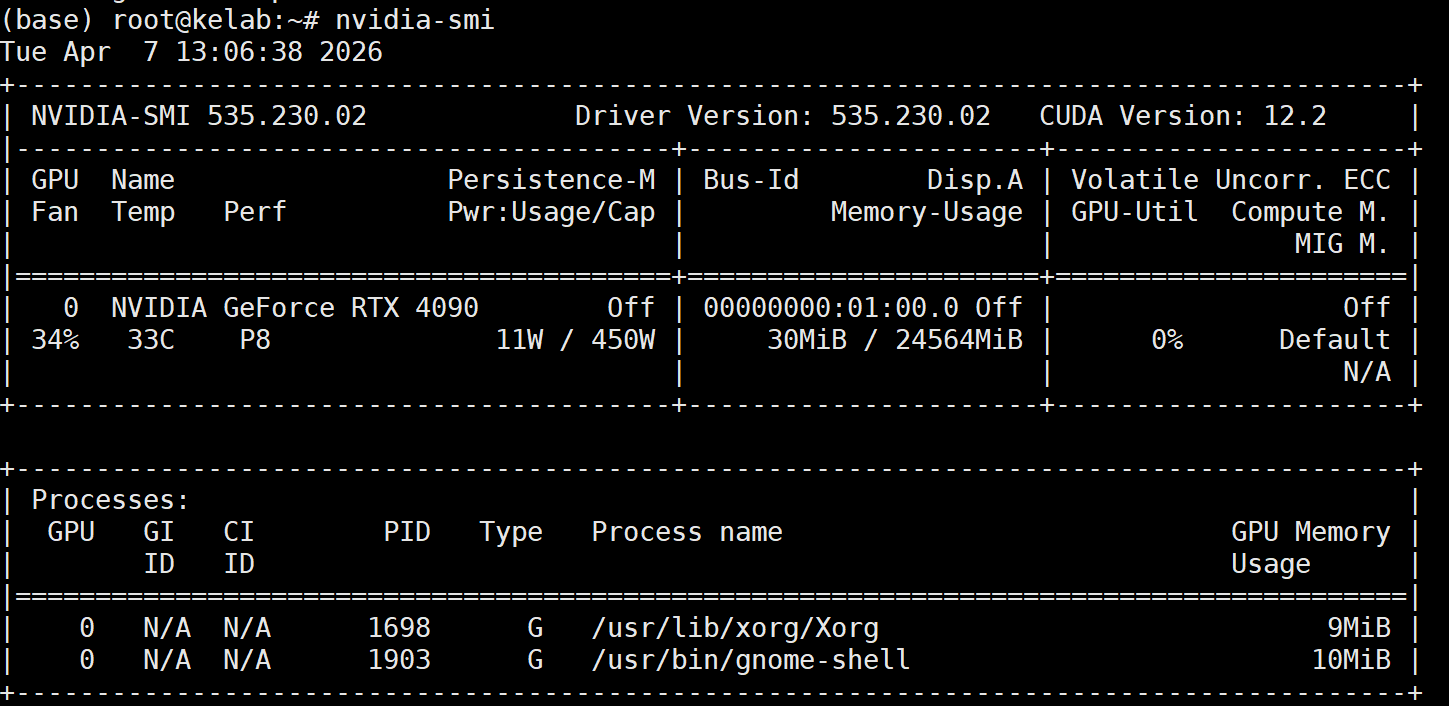
1. 设备
Llama3-8B 的全参数量为 80 亿,如果使用全精度(FP32)或半精度(FP16)进行全量微调,24GB 显存是远远不够的。但通过 QLoRA(4-bit 量化加载 + LoRA 微调),我们可以在 24G 显存的 RTX 4090 上非常游刃有余地完成训练,甚至可以开较大的 Batch Size。
2. 模型下载
在国内网络环境下,建议直接从 ModelScope(魔搭社区)下载 Llama3-8B-Instruct 模型,速度更快。按要求下载即可。本文用Huggingface,ModeScope更快,但是有些模型可能没有。
from transformers import AutoTokenizer, AutoModelForCausalLM
tokenizer = AutoTokenizer.from_pretrained("meta-llama/Llama-3.1-8B-Instruct")
model = AutoModelForCausalLM.from_pretrained("meta-llama/Llama-3.1-8B-Instruct")3. 数据集准备与示例
为了让模型学会基于文本生成高质量的 QA 对,我们需要准备 Instruction-tuning 格式的数据。可以直接用开源数据集,或者按需求自己构建。
3.1 数据集示例 (qa_dataset.jsonl)
每一行是一个 JSON 对象,包含 instruction(指令)、input(给定的参考文本)和 output(模型应该输出的 QA 对)。
JSON
{"instruction": "你是一个专业的知识提取专家。请阅读以下文本,并从中提取3个高质量的问答对(QA)。", "input": "自然语言处理是计算机科学领域与人工智能领域中的一个重要方向。它研究能实现人与计算机之间用自然语言进行有效通信的各种理论和方法。自然语言处理是一门融语言学、计算机科学、数学于一体的科学。", "output": "Q1: 什么是自然语言处理?\nA1: 自然语言处理是计算机科学与人工智能领域中的一个重要方向,研究人与计算机之间用自然语言进行有效通信的理论和方法。\nQ2: 自然语言处理涉及哪些学科?\nA2: 自然语言处理是一门融语言学、计算机科学、数学于一体的科学。\nQ3: 自然语言处理的核心研究目的是什么?\nA3: 其核心目的是实现人与计算机之间用自然语言进行有效的通信。"}
{"instruction": "你是一个专业的知识提取专家。请阅读以下文本,并从中提取高质量的问答对(QA)。", "input": "LoRA(Low-Rank Adaptation)是一种用于微调大型语言模型的有效方法。它通过冻结预训练模型的权重,并在 Transformer 架构的每一层中注入可训练的秩分解矩阵,从而大大减少了下游任务的可训练参数数量。", "output": "Q1: LoRA 微调技术的核心原理是什么?\nA1: LoRA 的核心原理是冻结预训练模型的权重,并在 Transformer 每一层中注入可训练的秩分解矩阵。\nQ2: 使用 LoRA 有什么主要优势?\nA2: 它可以大大减少下游任务中的可训练参数数量,降低计算和显存开销。"}4. LoRA 微调关键代码
我们将使用 Hugging Face 的 trl 库中的 SFTTrainer 进行监督微调。以下是核心训练脚本 train.py 的关键代码片段。
4.1 模型与分词器加载 (4-bit 量化)
Python
import torch
from transformers import AutoModelForCausalLM, AutoTokenizer, BitsAndBytesConfig
from peft import LoraConfig, get_peft_model
from datasets import load_dataset
from trl import SFTTrainer, SFTConfig
model_path = "./Meta-Llama-3-8B-Instruct"
# 配置 4-bit 量化
bnb_config = BitsAndBytesConfig(
load_in_4bit=True,
bnb_4bit_quant_type="nf4",
bnb_4bit_compute_dtype=torch.bfloat16,
bnb_4bit_use_double_quant=True,
)
# 加载 Tokenizer
tokenizer = AutoTokenizer.from_pretrained(model_path)
tokenizer.pad_token = tokenizer.eos_token # Llama3 需要设置 pad_token
# 加载基础模型
model = AutoModelForCausalLM.from_pretrained(
model_path,
quantization_config=bnb_config,
device_map="auto" # 自动映射到 4090
)4.2 配置 LoRA 参数
针对 Llama 3 架构,通常建议对所有的线性层(Linear layers)应用 LoRA,以获得更好的效果。
Python
lora_config = LoraConfig(
r=16, # LoRA 秩,通常 8 或 16 即可
lora_alpha=32, # LoRA 缩放系数
target_modules=["q_proj", "k_proj", "v_proj", "o_proj", "gate_proj", "up_proj", "down_proj"],
lora_dropout=0.05,
bias="none",
task_type="CAUSAL_LM"
)
# 将模型包装为 PEFT 模型
model = get_peft_model(model, lora_config)
model.print_trainable_parameters()4.3 数据处理与训练配置
将 JSONL 数据映射为模型所需的 Prompt 格式:
Python
def format_prompts_func(example):
output_texts = []
for i in range(len(example['instruction'])):
text = f"<|begin_of_text|>User: {example['instruction'][i]}\nContext: {example['input'][i]}\n\nAssistant: {example['output'][i]}<|end_of_text|>"
output_texts.append(text)
return output_texts
dataset = load_dataset("json", data_files="qa_dataset.jsonl", split="train")
# 训练参数设置
training_args = SFTConfig(
output_dir="./llama3-8b-qa-lora",
per_device_train_batch_size=4,
gradient_accumulation_steps=4, # 全局 batch size = 4 * 4 = 16
learning_rate=2e-4,
logging_steps=10,
max_steps=500, # 根据数据集大小调整,或使用 num_train_epochs
save_steps=100,
fp16=False,
bf16=True, # 4090 支持 bf16,推荐开启
optim="paged_adamw_32bit"
)
trainer = SFTTrainer(
model=model,
train_dataset=dataset,
peft_config=lora_config,
formatting_func=format_prompts_func,
max_seq_length=1024, # 截断长度
tokenizer=tokenizer,
args=training_args,
)
# 开始训练
trainer.train()
# 保存 LoRA 权重
trainer.model.save_pretrained("./llama3-8b-qa-lora/final")
tokenizer.save_pretrained("./llama3-8b-qa-lora/final")5.总结
还可以根据具体需求,选择适合的模型,数据集,结合RAG进行特定领域微调。