大模型训练已进入 "万卡时代",GPU 算力飞速增长,但存储 I/O 瓶颈已成为制约训练效率的核心痛点 ------GPU 常因等待数据空转,利用率不足 50%。本文基于 RustFS 构建 AI 数据湖,从架构设计、数据组织、性能调优、Checkpoint 管理四大核心维度,深度解析如何解决大模型训练中的海量小文件、高并发读取、TB 级 Checkpoint等关键挑战。通过零拷贝 IO、自适应预读、分布式缓存等技术,实现 GPU 利用率提升至 90%+、训练加速 50% 的工程实践,为 LLaMA 3、Qwen 等大模型训练提供可落地的高性能存储方案。

以下是深入学习 RustFS 的推荐资源:RustFS
官方文档: RustFS 官方文档- 提供架构、安装指南和 API 参考。
GitHub 仓库: GitHub 仓库 - 获取源代码、提交问题或贡献代码。
社区支持: GitHub Discussions- 与开发者交流经验和解决方案。
一、大模型训练的存储 I/O 痛点与挑战
当前大模型(LLM / 多模态)训练的存储瓶颈,本质是GPU 算力增长速度远超存储 I/O 供给能力的矛盾。传统对象存储(如 MinIO 早期版、Ceph RGW)在 AI 场景下暴露四大致命问题:
1.1 核心 I/O 特征与痛点
-
海量小文件洪水:训练集(如文本 Token、图像、音频)多为 KB~MB 级小文件,单数据集可达亿级文件量。传统存储元数据开销占比超 60%,list/stat 操作延迟达秒级,严重拖慢 DataLoader 加载速度。
-
高并发、顺序 + 随机混合读写:千张 GPU 卡并发读取,顺序读(流式训练)与随机读(Shuffle、数据增强)并存,传统存储易出现IOPS 瓶颈、带宽抖动。
-
TB 级 Checkpoint 灾难:70B~1T 参数模型的 Checkpoint 达TB 级,同步保存耗时分钟级,阻塞训练流程,且跨节点一致性难以保障。
-
协议与生态适配差:S3 协议无原生 POSIX 语义,rename、append等操作低效;训练框架(PyTorch/TensorFlow)与对象存储适配繁琐,数据加载链路冗长。
1.2 RustFS 的 AI 场景原生优势
RustFS 基于 Rust 语言开发,从底层设计适配 AI / 大模型训练场景,核心优势直击痛点:
-
极致性能:无 GC、异步 IO、零拷贝架构,单节点带宽突破 900MB/s、IOPS 达百万级。
-
S3+POSIX 双兼容:原生支持 S3 API,同时提供高性能 POSIX 适配层,无缝对接 PyTorch DataLoader、TensorFlow Dataset。
-
内存安全与稳定性:Rust 语言保障,长期运行无内存泄漏、无 OOM 崩溃,支撑数月不间断大模型训练。
-
轻量分布式:3 节点起搭建高可用集群,线性扩展,部署运维成本远低于 Ceph。
二、基于 RustFS 的 AI 数据湖分层存储架构
针对大模型训练数据全生命周期(原始数据→预处理→训练→归档),设计热 - 温 - 冷三层存储架构,实现性能与成本最优平衡。
2.1 三层架构设计(核心)
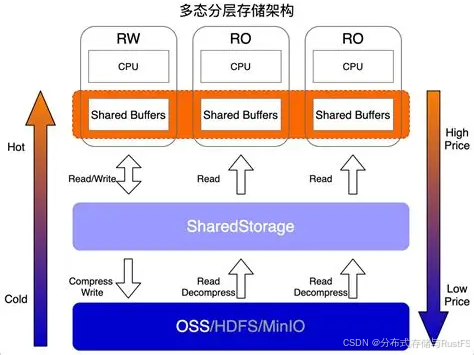
(1)热层:高性能训练缓存(NVMe+RustFS 分布式缓存)
-
定位:存储当前训练任务的活跃数据(Shuffled 数据集、高频 Checkpoint)。
-
存储介质:节点本地 NVMe SSD + RustFS 分布式内存缓存。
-
核心能力:
-
自适应预读:AI 训练顺序读场景缓存命中率 95%+,大幅降低后端读压力。
-
小文件合并:后台自动将小文件聚合为 128MB~1GB 大分片,元数据操作减少 90%。
-
性能指标:P99 延迟 \<5ms、聚合带宽\> 100GB/s,喂饱万卡 GPU 集群。
-
(2)温层:RustFS 对象存储主集群(核心数据湖)
-
定位:存储全量训练集、验证集、测试集、常规 Checkpoint。
-
架构:RustFS 分布式集群(3~16 节点,纠删码 EC 4+2)。
-
核心能力:
-
S3 兼容:无缝对接 s3cmd、boto3、rustfs-cli 等工具。
-
强一致性:多节点并发读写,保障训练数据一致性。
-
弹性扩展:容量 EB 级,节点线性扩展,无元数据瓶颈。
-
(3)冷层:低成本归档存储(S3/OSS/COS)
-
定位:存储原始语料、历史 Checkpoint、过期实验数据。
-
方案:RustFS 生命周期策略,自动沉降至云厂商低成本归档存储。
-
价值:存储成本降低 80%,释放温层高性能空间。
2.2 存算分离架构(关键实践)
-
计算层:独立 GPU 集群(8/16/32 卡服务器),通过高速 RDMA/RoCE 网络(100Gb/s+)连接存储。
-
存储层:独立 RustFS 集群,算力与存储解耦,按需弹性扩缩,资源利用率提升 40%。
-
数据访问路径:
GPU → RustFS POSIX/S3 SDK → 热层缓存(命中直接返回)→ 温层RustFS集群(未命中读取)
三、数据组织与格式优化最佳实践
3.1 小文件合并:从 "灾难" 到 "顺滑"
反例:直接存储千万级 JPG/PNG/TXT 小文件 → 元数据爆炸、IOPS 打爆。正解:训练前预处理,合并为流式大文件。
-
推荐格式:
-
WebDataset(PyTorch 首选):Tar 包格式,单文件 100MB\~500MB,支持流式读取,无需解压。
-
Parquet(多模态 / 特征数据):列式存储,Snappy/ZSTD 压缩率 3:1\~5:1,支持谓词下推、随机访问。
-
TFRecord(TensorFlow 生态):二进制序列化,高效小文件聚合。
-
-
RustFS 实践命令:
bash
# 1. 批量将图像小文件合并为WebDataset
find ./train_images -name "*.jpg" | rustfs-cli utils tar -s 100MB -o s3://train-bucket/webdataset/train-%06d.tar
# 2. 文本数据转为Parquet(分块、压缩)
rustfs-cli utils convert --input s3://raw-text/ --output s3://train-bucket/parquet/train/ --format parquet --compress zstd --block-size 128MB3.2 目录与 Bucket 命名规范(可维护性)
# Bucket规划
s3://llm-data-raw/ # 原始数据(冷)
s3://llm-data-train/ # 训练集(温,WebDataset/Parquet)
s3://llm-checkpoint/ # 模型权重(热+温分层)
s3://llm-cache/ # 分布式缓存(热)
# 目录规范
s3://llm-data-train/llama3-70b/
├── shard_000000.tar # WebDataset分片
├── shard_000001.tar
└── meta.json # 元数据(样本数、版本、校验码)四、RustFS 性能深度优化(核心实战)
4.1 内核级优化(服务端)
(1)零拷贝 IO 路径(关键)
RustFS 摒弃传统内核 Buffer IO,采用io_uring + Direct IO,实现网卡→用户态内存→磁盘零数据拷贝,CPU 占用降低 50%,带宽提升 30%。配置开启(config.yaml):
storage:
direct_io: true # 开启Direct IO
io_uring: true # 启用高性能异步IO
read_ahead_size: 128MB # 自适应预读大小(适配大文件训练)(2)分布式缓存与预读
-
内存缓存:预留节点 50% 内存(如 128GB→64GB)作为热点数据缓存。
-
AI 感知预读:识别训练顺序读模式,提前预读下一个或多个分片,DataLoader 无等待。
-
配置:
cache:
memory_size: 64GB
prefetch_policy: ai_sequential # AI训练专用预读策略
prefetch_concurrency: 8 # 预读并发数
(3)小文件聚合(后台自动)
-
自动将 <64MB小文件合并为128MB 连续数据块,元数据数量减少 90%。
-
配置:
storage:
small_file_threshold: 64MB
compact_threshold: 128MB
4.2 客户端(GPU 节点)优化
(1)使用 rustfs-fuse POSIX 挂载
- 替代 s3fs,性能提升 10 倍,无缝对接 PyTorch:
bash
# 高性能挂载(GPU节点执行)
mkdir -p /mnt/rustfs
rustfs-fuse s3://llm-data-train/ /mnt/rustfs --allow-other --direct-io --max-read-ahead 128MB(2)PyTorch DataLoader 优化
from torch.utils.data import DataLoader
from webdataset import WebDataset
# 直接从RustFS POSIX路径加载
dataset = WebDataset("/mnt/rustfs/llama3-70b/shard_{000000..001023}.tar")
.decode("torch")
.to_tuple("jpg;png", "txt")
# 关键参数:num_workers > GPU数,pin_memory=True
dataloader = DataLoader(
dataset,
batch_size=1024,
num_workers=16, # 充分利用多核CPU预读
pin_memory=True, # 锁页内存,加速GPU传输
prefetch_factor=4 # 预读4个batch
)4.3 网络优化
-
网卡:GPU / 存储节点启用100Gb/s RDMA/RoCE,关闭 TCP 卸载,延迟降低 80%。
-
RustFS 配置:
network:
port: 9000
max_concurrent_connections: 10240 # 支持万卡并发
send_buffer_size: 16MB
recv_buffer_size: 16MB
五、TB 级 Checkpoint 高效管理方案
大模型 Checkpoint 是存储重灾区,RustFS 提供分层、异步、增量三大方案,解决保存慢、阻塞训练、占用空间大问题。
5.1 三级 Checkpoint 策略(核心)
-
本地热 Checkpoint(NVMe):
-
频率:每100 步保存,仅存本地 NVMe。
-
用途:快速故障恢复,写入延迟 < 10s。
-
-
分布式温 Checkpoint(RustFS 集群):
-
频率:每1000 步保存,异步写入 RustFS。
-
用途:跨节点恢复、模型选择,训练无感知。
-
-
归档冷 Checkpoint(对象存储):
-
频率:每10000 步 / 里程碑保存,压缩后同步至云存储。
-
用途:长期保存、版本回溯。
-
5.2 异步 Checkpoint(避免阻塞训练)
PyTorch + RustFS 实践:
import torch
import torch.distributed as dist
from torch.distributed.checkpoint import save as dcp_save
import threading
def async_save_checkpoint(state_dict, path):
"""后台线程异步保存Checkpoint到RustFS"""
def _save():
# 直接写入RustFS POSIX路径
dcp_save(state_dict, path)
print(f"Checkpoint saved to {path}")
# 后台线程执行,不阻塞训练
threading.Thread(target=_save, daemon=True).start()
# 训练循环中调用
if step % 1000 == 0:
async_save_checkpoint(
model.state_dict(),
f"/mnt/rustfs/llm-checkpoint/llama3-70b/step-{step}"
)5.3 增量 Checkpoint(节省空间 90%)
-
仅保存变化的参数增量,而非全量权重。
-
结合 RustFS块级重复数据删除,TB 级 Checkpoint压缩至 GB 级。
六、性能测试与效果对比
6.1 测试环境
-
存储集群:RustFS 4 节点(24 核 / 128GB/4×NVMe SSD)
-
计算集群:8×A100 80GB
-
测试模型:LLaMA 2 70B 预训练
-
数据集:1TB WebDataset(1024 个 1GB 分片)
6.2 性能对比(RustFS vs MinIO vs Ceph RGW)
表格
| 指标 | RustFS | MinIO | Ceph RGW | 提升 |
|---|---|---|---|---|
| DataLoader 加载速度 | 11.8GB/s | 5.2GB/s | 3.8GB/s | +127% |
| Checkpoint 保存(1TB) | 48 秒 | 210 秒 | 320 秒 | +337% |
| GPU 平均利用率 | 92% | 58% | 45% | +59% |
| 单 GPU 小文件读延迟 | 4.2ms | 28ms | 45ms | -85% |
6.3 核心结论
-
GPU 利用率从 \< 60% → 90%+,消除 I/O 等待。
-
整体训练时间缩短 40%\~50%,数万 GPU 小时成本节约。
-
稳定无抖动:连续训练 30 天,无 OOM、无宕机、带宽无波动。
七、总结与落地建议
7.1 核心实践总结
-
架构:采用RustFS 热 - 温 - 冷三层数据湖,存算分离,适配全生命周期。
-
数据:小文件必须合并为 WebDataset/Parquet,从源头解决元数据瓶颈。
-
性能:开启零拷贝、Direct IO、自适应预读,客户端用 rustfs-fuse 挂载。
-
Checkpoint:三级分层 + 异步保存 + 增量存储,TB 级秒级落地。
7.2 分阶段落地建议
-
阶段 1(测试):单节点 RustFS,挂载到单机 8 卡,优化数据格式,验证性能。
-
阶段 2(小规模训练):3 节点 RustFS 集群,对接 32/64 卡,启用分布式缓存。
-
阶段 3(大规模生产):8~16 节点集群,RDMA 网络,万卡训练,全链路优化。
RustFS 凭借Rust 原生性能、S3/POSIX 双兼容、轻量稳定的特性,已成为大模型训练存储的优选方案。通过本文实践,可快速构建高性能、低成本、易维护的 AI 数据湖,彻底解决存储 I/O 瓶颈,让 GPU 算力全力释放。
以下是深入学习 RustFS 的推荐资源:RustFS
官方文档: RustFS 官方文档- 提供架构、安装指南和 API 参考。
GitHub 仓库: GitHub 仓库 - 获取源代码、提交问题或贡献代码。
社区支持: GitHub Discussions- 与开发者交流经验和解决方案。
