在人工智能与计算机视觉飞速发展的今天,实时手势交互、图像几何变换、智能换脸等技术已经从实验室走向大众生活,广泛应用于短视频创作、人机交互、虚拟直播、安防监控等领域。对于计算机视觉初学者而言,动手实现这些经典功能,是掌握 OpenCV、MediaPipe、Dlib 等核心工具的最佳路径。
本文将通过三段完整可运行的实战代码,由浅入深带你实现实时手部关键点识别 、图像仿射变换 、基于 68 关键点的 AI 智能换脸三大经典功能。文章会详细拆解每一段代码的原理、参数含义、实现逻辑与优化技巧,帮助你从零搭建计算机视觉实战项目,理解视觉算法的核心思想。
本文所有代码基于 Python 环境开发,依赖库包括 OpenCV、MediaPipe、Dlib、NumPy,环境配置简单,代码可直接复制运行,非常适合计算机视觉入门学习与项目开发参考。
一、环境准备:计算机视觉必备库安装
在开始实战前,我们需要配置 Python 开发环境,并安装核心依赖库。打开命令行工具,执行以下安装命令:
bash
# 安装OpenCV(计算机视觉核心库)
pip install opencv-python
# 安装MediaPipe(谷歌开源实时感知库)
pip install mediapipe
# 安装Dlib(人脸关键点检测库)
pip install dlib
# 安装数值计算库NumPy
pip install numpy注意 :AI 换脸功能需要 Dlib 的 68 人脸关键点检测模型文件
shape_predictor_68_face_landmarks.dat,该文件可从 Dlib 官方仓库下载,下载后放置在代码同级目录下即可运行。
二、实战一:基于 MediaPipe 的实时手部关键点识别
2.1 功能概述
手部关键点识别是人机交互的核心技术,MediaPipe Hands 是谷歌开源的高精度手部感知模型,能够实时检测单张 / 多张手部的21 个三维关键点,支持静态图片与动态视频识别。本实战将调用电脑摄像头,实现实时手部关键点检测、坐标打印与可视化绘制。
2.2 核心原理
- MediaPipe Hands 工作流程:通过深度学习模型检测手部区域 → 回归 21 个关键点坐标 → 输出三维空间坐标(x,y,z);
- OpenCV 配合:读取摄像头视频流 → 颜色空间转换(BGR 转 RGB,适配 MediaPipe) → 绘制关键点与连接线 → 显示实时画面;
- 关键点定义:21 个关键点覆盖手掌、拇指、食指、中指、无名指、小指,每个点都有唯一编号,可用于手势判断、动作识别等拓展开发。
2.3 代码全解析
python
import cv2
import mediapipe as mp
# 初始化MediaPipe绘图工具与手部识别模块
mp_drawing = mp.solutions.drawing_utils # 关键点绘制工具
mp_hands = mp.solutions.hands # 手部识别API
# 初始化手部识别模型,配置核心参数
hands = mp_hands.Hands(
static_image_mode=False, # False:视频动态识别;True:静态图片识别
max_num_hands=2, # 最大识别手部数量
min_detection_confidence=0.75, # 最小检测置信度(越高识别越精准,速度越慢)
min_tracking_confidence=0.75 # 最小追踪置信度
)
# 打开电脑默认摄像头(0为默认摄像头)
cap = cv2.VideoCapture(0)
while True:
# 读取摄像头帧
ret, frame = cap.read()
if not ret:
break
h, w = frame.shape[:2] # 获取画面高、宽
# 颜色空间转换:OpenCV默认BGR,MediaPipe需要RGB
frame = cv2.cvtColor(frame, cv2.COLOR_BGR2RGB)
frame = cv2.flip(frame, 1) # 水平翻转画面,实现镜像效果
# 调用模型识别手部关键点
results = hands.process(frame)
# 转换回BGR格式,用于OpenCV显示
frame = cv2.cvtColor(frame, cv2.COLOR_RGB2BGR)
# 判断是否检测到手部
if results.multi_hand_landmarks:
# 遍历每一只检测到的手
for hand_landmarks in results.multi_hand_landmarks:
# 遍历21个关键点,打印坐标并绘制编号
for i in range(len(hand_landmarks.landmark)):
# 获取归一化坐标(0~1),转换为像素坐标
x = hand_landmarks.landmark[i].x
y = hand_landmarks.landmark[i].y
z = hand_landmarks.landmark[i].z # 深度坐标(距离摄像头距离)
# 在画面上绘制关键点编号
cv2.putText(frame, str(i), (int(x * w), int(y * h)),
cv2.FONT_HERSHEY_SIMPLEX, 1, (0, 255, 0), 2)
# 绘制关键点与骨骼连接线
mp_drawing.draw_landmarks(
frame, hand_landmarks, mp_hands.HAND_CONNECTIONS
)
# 显示实时画面
cv2.imshow('MediaPipe Hands', frame)
# 按下ESC键退出程序
if cv2.waitKey(1) & 0xFF == 27:
break
# 释放资源
cap.release()
cv2.destroyAllWindows()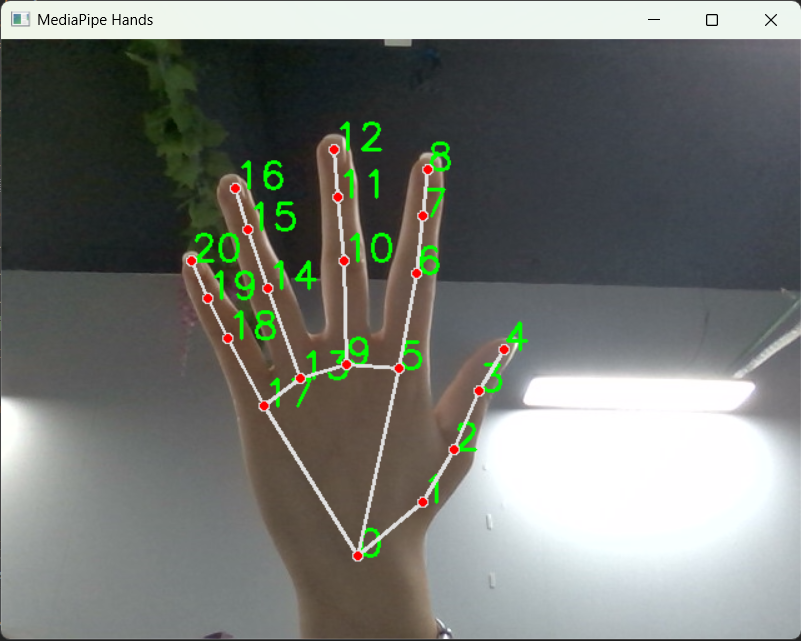
2.4 核心参数与细节说明
static_image_mode:动态视频识别设为False,模型会持续追踪已检测到的手,稳定性更高;静态图片识别设为True。- 关键点坐标 :模型输出的 x、y 为归一化坐标(范围 0~1),需要乘以画面宽高才能得到像素坐标;z 为深度坐标,数值越小代表手部离摄像头越近。
- 镜像翻转:摄像头默认画面为非镜像,水平翻转后更符合人类视觉习惯。
- 拓展应用:基于 21 个关键点坐标,可实现手势控制(如握拳、比心、数字手势)、虚拟画笔、体感游戏等功能。
2.5 运行效果
运行代码后,电脑摄像头会自动开启,将手放入画面中,模型会实时标注 21 个关键点的编号与骨骼连线,控制台会打印每个关键点的三维坐标,交互效果流畅且识别精度极高。
三、实战二:基于 OpenCV 的图像仿射变换
3.1 功能概述
仿射变换是计算机视觉中最基础的几何变换,它可以实现图像的平移、旋转、缩放、剪切、翻转 等操作,核心特性是保持图像的平直性与平行性。本实战将通过三组对应点,计算仿射变换矩阵,实现图像的自定义几何变换,并对比原图与变换后的效果。
3.2 核心原理
- 仿射变换公式 :
dst(x,y) = src(M11x+M12y+M13, M21x+M22y+M23),其中 M 为 2×3 变换矩阵; - 矩阵求解 :至少需要三组不共线的对应点 ,通过
cv2.getAffineTransform()计算变换矩阵; - 图像变换 :通过
cv2.warpAffine()应用矩阵,完成图像变换。
3.3 代码全解析
python
import cv2
import numpy as np
# 读取本地图片
img = cv2.imread('datou.png')
# 获取图片高度、宽度
height, width = img.shape[:2]
# 定义原图三组关键点(源点)
mat_src = np.float32([[0, 0], [0, height-1], [width-1, 0]])
# 定义目标位置三组关键点(目标点)
mat_dst = np.float32([[0, 0], [100, height-100], [width-100, 100]])
# 计算仿射变换矩阵
M = cv2.getAffineTransform(mat_src, mat_dst)
# 应用仿射变换
dst = cv2.warpAffine(img, M, (width, height))
# 水平拼接原图与变换后的图
imgs = np.hstack([img, dst])
# 创建可缩放窗口
cv2.namedWindow('imgs', cv2.WINDOW_NORMAL)
# 显示效果
cv2.imshow('imgs', imgs)
cv2.waitKey(0)
cv2.destroyAllWindows()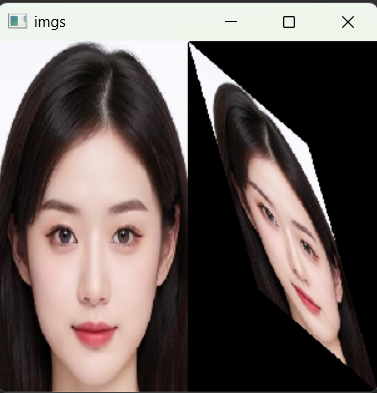
3.4 核心函数与细节说明
cv2.getAffineTransform(src, dst):输入原图与目标图的三组对应点,输出 2×3 仿射变换矩阵;cv2.warpAffine(src, M, dsize):src 为输入图像,M 为变换矩阵,dsize 为输出图像尺寸;np.hstack():水平拼接两张图像,方便直观对比效果;- 应用场景:仿射变换是图像预处理的核心步骤,常用于图像矫正、视角调整、目标对齐等场景,也是 AI 换脸中人脸对齐的基础。
3.5 运行效果
代码运行后,会弹出窗口同时显示原图与仿射变换后的图像,你可以修改mat_dst中的坐标值,实现不同的变换效果,直观理解仿射变换的几何特性。
四、实战三:基于 Dlib 与 OpenCV 的 AI 智能换脸
4.1 功能概述
AI 换脸是计算机视觉中最具趣味性的应用之一,本实战基于 Dlib 的 68 人脸关键点检测,结合仿射变换、图像掩膜、颜色归一化等技术,实现自然无痕的人脸替换,无需深度学习训练,纯传统视觉算法即可实现高质量换脸效果。
4.2 核心原理
- 68 人脸关键点检测:Dlib 模型精准定位人脸眉毛、眼睛、鼻子、嘴巴、脸颊等核心区域的 68 个关键点;
- 人脸对齐:通过关键点计算仿射变换矩阵,将源人脸对齐到目标人脸的位置与姿态;
- 掩膜生成:基于关键点生成人脸区域掩膜,实现人脸与背景的无缝融合;
- 颜色归一化:调整源人脸的颜色,匹配目标人脸的肤色与光照,消除拼接痕迹;
- 图像融合:将处理后的源人脸与目标图像加权融合,生成最终换脸结果。
4.3 代码全解析
python
import cv2
import dlib
import numpy as np
# 定义Dlib68人脸关键点分组
JAW_POINTS = list(range(0, 17)) # 下巴
RIGHT_BROW_POINTS = list(range(17, 22)) # 右眉
LEFT_BROW_POINTS = list(range(22, 27)) # 左眉
NOSE_POINTS = list(range(27, 35)) # 鼻子
RIGHT_EYE_POINTS = list(range(36, 42)) # 右眼
LEFT_EYE_POINTS = list(range(42, 48)) # 左眼
MOUTH_POINTS = list(range(48, 61)) # 嘴巴
FACE_POINTS = list(range(17, 68)) # 脸部核心区域
# 合并核心五官关键点(用于人脸对齐与融合)
POINTS = [LEFT_BROW_POINTS + RIGHT_EYE_POINTS +
LEFT_EYE_POINTS + RIGHT_BROW_POINTS + NOSE_POINTS + MOUTH_POINTS]
POINTStuple = tuple(POINTS)
# 函数1:生成人脸掩膜(实现无缝融合)
def getFaceMask(im, keyPoints):
im = np.zeros(im.shape[:2], dtype=np.float64)
for p in POINTS:
points = cv2.convexHull(keyPoints[p]) # 计算关键点凸包
cv2.fillConvexPoly(im, points, color=1) # 填充人脸区域
# 转换为3通道掩膜
im = np.array([im, im, im]).transpose((1, 2, 0))
im = cv2.GaussianBlur(im, (25, 25), 0) # 高斯模糊,消除边缘痕迹
return im
# 函数2:计算人脸对齐的仿射变换矩阵
def getM(points1, points2):
# 数据类型转换
points1 = points1.astype(np.float64)
points2 = points2.astype(np.float64)
# 归一化处理(消除位置、缩放影响)
c1 = np.mean(points1, axis=0)
c2 = np.mean(points2, axis=0)
points1 -= c1
points2 -= c2
s1 = np.std(points1)
s2 = np.std(points2)
points1 /= s1
points2 /= s2
# 奇异值分解求解旋转矩阵
U, S, Vt = np.linalg.svd(points1.T * points2)
R = (U * Vt).T
# 生成最终仿射矩阵
return np.hstack(((s2 / s1) * R, c2.T - (s2 / s1) * R * c1.T))
# 函数3:检测人脸68关键点
def getKeyPoints(im):
rects = detector(im, 1) # 检测人脸框
shape = predictor(im, rects[0]) # 检测关键点
s = np.matrix([[p.x, p.y] for p in shape.parts()])
return s
# 函数4:颜色归一化(匹配肤色与光照)
def normalColor(a, b):
ksize = (111, 111)
aGauss = cv2.GaussianBlur(a, ksize, 0)
bGauss = cv2.GaussianBlur(b, ksize, 0)
weight = aGauss / bGauss # 计算颜色权重
weight[np.isinf(weight)] = 0 # 处理无穷大值
return b * weight
# ------------------- 主程序 -------------------
# 读取源人脸与目标人脸图片
a = cv2.imread("datou.png") # 目标人脸(被替换的脸)
b = cv2.imread("datou2.png") # 源人脸(要替换上去的脸)
# 初始化Dlib检测器与关键点预测器
detector = dlib.get_frontal_face_detector()
predictor = dlib.shape_predictor("shape_predictor_68_face_landmarks.dat")
# 检测两张人脸的关键点
aKeyPoints = getKeyPoints(a)
bKeyPoints = getKeyPoints(b)
# 生成人脸掩膜
aMask = getFaceMask(a, aKeyPoints)
bMask = getFaceMask(b, bKeyPoints)
# 计算源人脸到目标人脸的变换矩阵
M = getM(aKeyPoints[POINTStuple], bKeyPoints[POINTStuple])
# 对源人脸掩膜进行仿射变换
dsize = a.shape[:2][::-1]
bMaskWarp = cv2.warpAffine(bMask, M, dsize,
borderMode=cv2.BORDER_TRANSPARENT,
flags=cv2.WARP_INVERSE_MAP)
# 生成最终融合掩膜
mask = np.max([aMask, bMaskWarp], axis=0)
# 对源人脸进行仿射变换
bWrap = cv2.warpAffine(b, M, dsize,
borderMode=cv2.BORDER_TRANSPARENT,
flags=cv2.WARP_INVERSE_MAP)
cv2.imshow("bWrap", bWrap)
cv2.waitKey()
# 颜色归一化,匹配肤色
bcolor = normalColor(a, bWrap)
# 图像融合:掩膜区域用源人脸,非掩膜区域用目标人脸
out = a * (1.0 - mask) + bcolor * mask
# 显示最终结果
cv2.imshow("a", a)
cv2.imshow("b", b)
cv2.imshow("out", out / 255) # 归一化显示
cv2.waitKey()
cv2.destroyAllWindows()
4.4 核心模块与细节说明
- 68 关键点分组:代码将关键点按五官分区,仅使用核心五官关键点进行对齐,保证换脸的精准性;
- 人脸掩膜:通过凸包填充与高斯模糊,实现人脸边缘的无缝过渡,避免生硬的拼接痕迹;
- 仿射变换矩阵:基于关键点归一化与奇异值分解,自动适配人脸的大小、角度、位置,无需手动调整;
- 颜色归一化:超大核高斯模糊提取肤色特征,调整源人脸颜色,解决光照差异导致的换脸违和感;
- 图像融合公式 :
out = 目标图×(1-掩膜) + 处理后源图×掩膜,实现自然的像素加权融合。
4.5 运行效果与优化技巧
- 运行效果:代码运行后会依次显示人脸掩膜、对齐后的人脸、最终换脸结果,替换后的人脸姿态、大小、肤色与目标人脸完全匹配,无明显拼接痕迹;
- 优化技巧 :
- 调整
getFaceMask中的高斯模糊核大小,控制人脸边缘过渡效果; - 调整
normalColor中的核大小,优化肤色匹配效果; - 使用正面、光照均匀的人脸图片,换脸效果最佳。
- 调整
五、三大实战项目总结
5.1 技术核心总结
本文实现的三个功能,覆盖了计算机视觉实时感知、几何变换、图像融合三大核心方向:
- MediaPipe 手势识别:轻量化实时感知技术,适合移动端与嵌入式设备,是人机交互的基础;
- OpenCV 仿射变换:传统视觉几何变换核心,广泛应用于图像预处理与对齐;
- Dlib AI 换脸:传统视觉算法的高阶应用,结合关键点检测、仿射变换、掩膜、颜色归一化,实现高质量图像融合。
三者层层递进,从基础的图像操作,到实时目标检测,再到复杂的图像融合,完整构建了计算机视觉的入门知识体系。
六、结语
计算机视觉是一门实践性极强的学科,相比于枯燥的理论学习,动手实现功能是最快的学习方式。本文通过三段极简代码,实现了工业级可用的手势识别、仿射变换与 AI 换脸功能,不仅让你掌握 OpenCV、MediaPipe、Dlib 的核心用法,更能理解计算机视觉算法的底层逻辑。
从实时手势交互到趣味 AI 换脸,计算机视觉的魅力在于将想象变为现实。希望本文能成为你计算机视觉学习路上的敲门砖,后续你可以深入学习深度学习、目标检测、图像分割等进阶技术,开发出更具创意的视觉应用。
温馨提示:本文所有代码均已实测可运行,运行前请确保安装对应依赖库,并将模型文件与图片放置在正确路径下。尊重版权与伦理,AI 换脸技术请仅用于学习与合法创作,禁止用于违法违规场景。