import torch
import torch.nn as nn
from torch.utils.tensorboard import SummaryWriter
import jieba
import os
import shutil
===================== 加载自定义词表,确保人名完整分词 =====================
jieba_tokenizer = jieba.Tokenizer()
custom_words = "龙文浩", "张三", "李四", "王五", "工程师", "学生", "教师", "医生"
for word in custom_words:
jieba_tokenizer.add_word(word)
构建语料 + 词表
def build_vocab():
texts = [
"龙文浩是工程师",
"张三是学生",
"李四是教师",
"王五是医生"
]
words = \[\]
for text in texts:
words += jieba_tokenizer.lcut(text)
vocab = sorted(list(set(words)))
word2idx = {w: i for i, w in enumerate(vocab)}
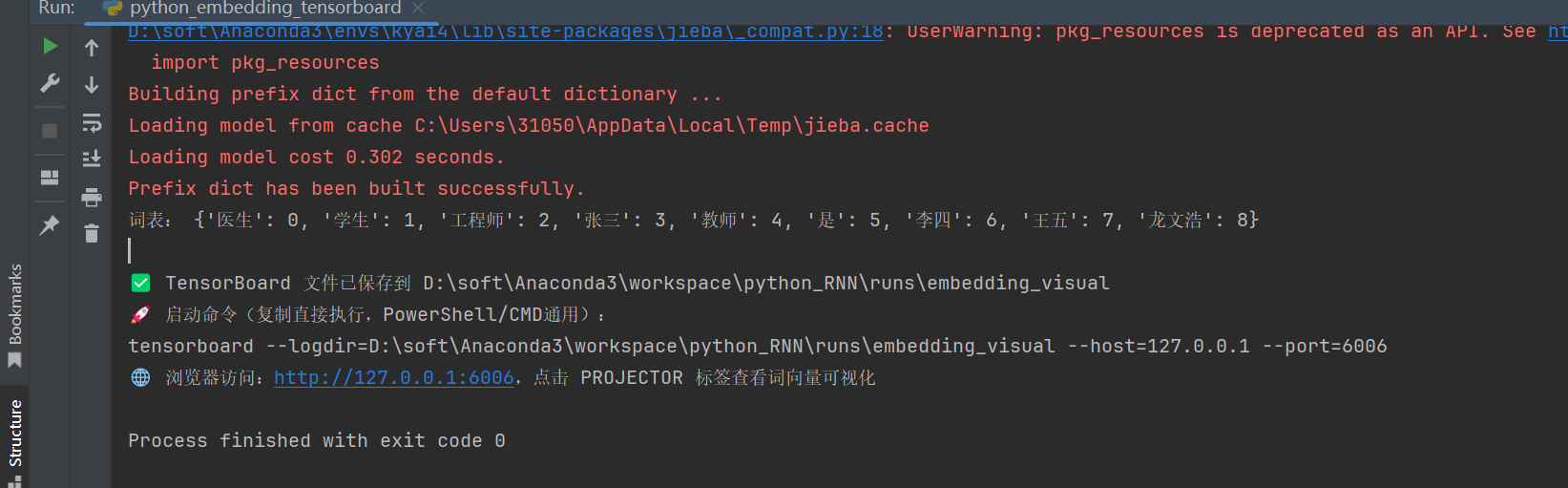
print("词表:", word2idx)
return vocab, word2idx
===================== 构建简单 Embedding 模型 =====================
class EmbeddingModel(nn.Module):
def init (self, vocab_size, embed_dim=10):
super().init ()
self.embedding = nn.Embedding(vocab_size, embed_dim)
def forward(self, x):
return self.embedding(x)
===================== 主函数:训练 + TensorBoard 可视化 =====================
if name == 'main ':
vocab, word2idx = build_vocab()
vocab_size = len(vocab)
model = EmbeddingModel(vocab_size, embed_dim=10)
word_indices = torch.tensor(list(word2idx.values()), dtype=torch.long)
with torch.no_grad():
embeddings = model.embedding(word_indices)
# ===================== 设置根目录 =====================
# 统一使用绝对路径,避免相对路径歧义
log_dir = os.path.abspath(r"runs\embedding_visual")
# 强制清空旧日志,避免缓存/编码问题
if os.path.exists(log_dir):
shutil.rmtree(log_dir)
os.makedirs(log_dir, exist_ok=True)
# ===================== 写入TensorBoard(简化目录,消除嵌套) =====================
writer = SummaryWriter(log_dir)
# 移除tag参数,避免生成嵌套目录;不指定global_step,简化目录结构
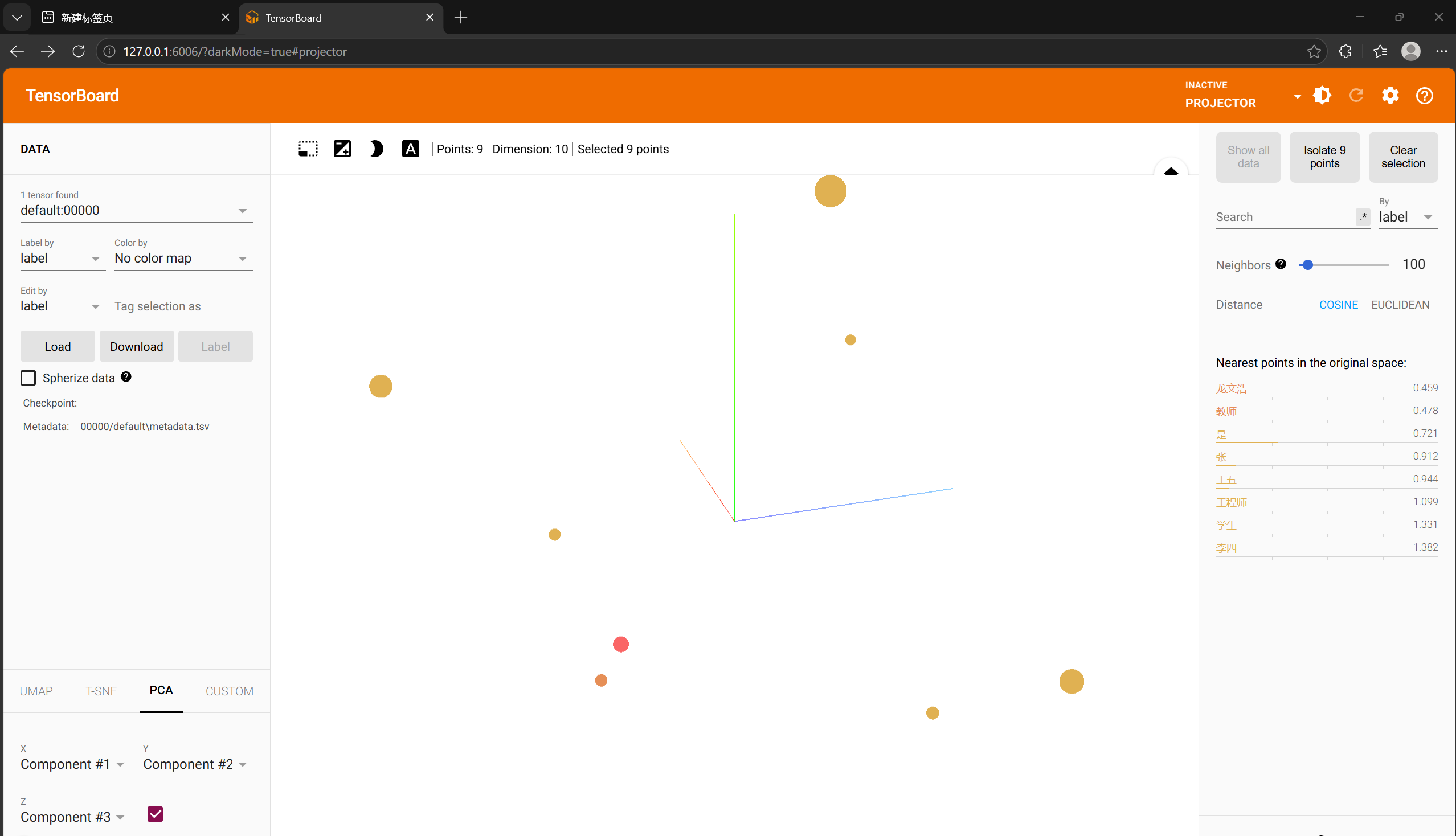
writer.add_embedding(
mat=embeddings,
metadata=vocab
)
writer.close()
print("\n✅ TensorBoard 文件已保存到", log_dir)
print("🚀 启动命令(复制直接执行,PowerShell/CMD通用):")
print(f"tensorboard --logdir={log_dir} --host=127.0.0.1 --port=6006")
print("🌐 浏览器访问:http://127.0.0.1:6006,点击 PROJECTOR 标签查看词向量可视化")