背景与目标
在 Android 项目的日常迭代中,分析和定位 UI 卡顿问题往往需要耗费大量时间。传统的排查流程(手动录制 Trace → 拖入 Perfetto UI 逐帧查看 → 对照业务代码排查)不仅效率低下,且高度依赖开发经验,学习曲线陡峭。
本文档介绍如何为 Android 项目接入一套自动化智能性能诊断管线。其核心价值:
- 自动化特征提取:用精准的 SQL 查询从 Perfetto Trace 中提取卡顿特征,彻底消除人工看帧的繁琐和经验门槛。
- 源码上下文绑定:为 AI 会诊提供问题发生时的完整涉事代码、依赖引用及关联 XML 布局,从根本上杜绝 AI "幻觉"诊断。
- 输出可执行报告:最终输出一份包含代码级优化建议的 Markdown 诊断报告,助力快速修复。
本方案无需私有化服务器部署,在任意配置了 adb 环境的 macOS / Linux 机器上即可一键启用。
系统架构
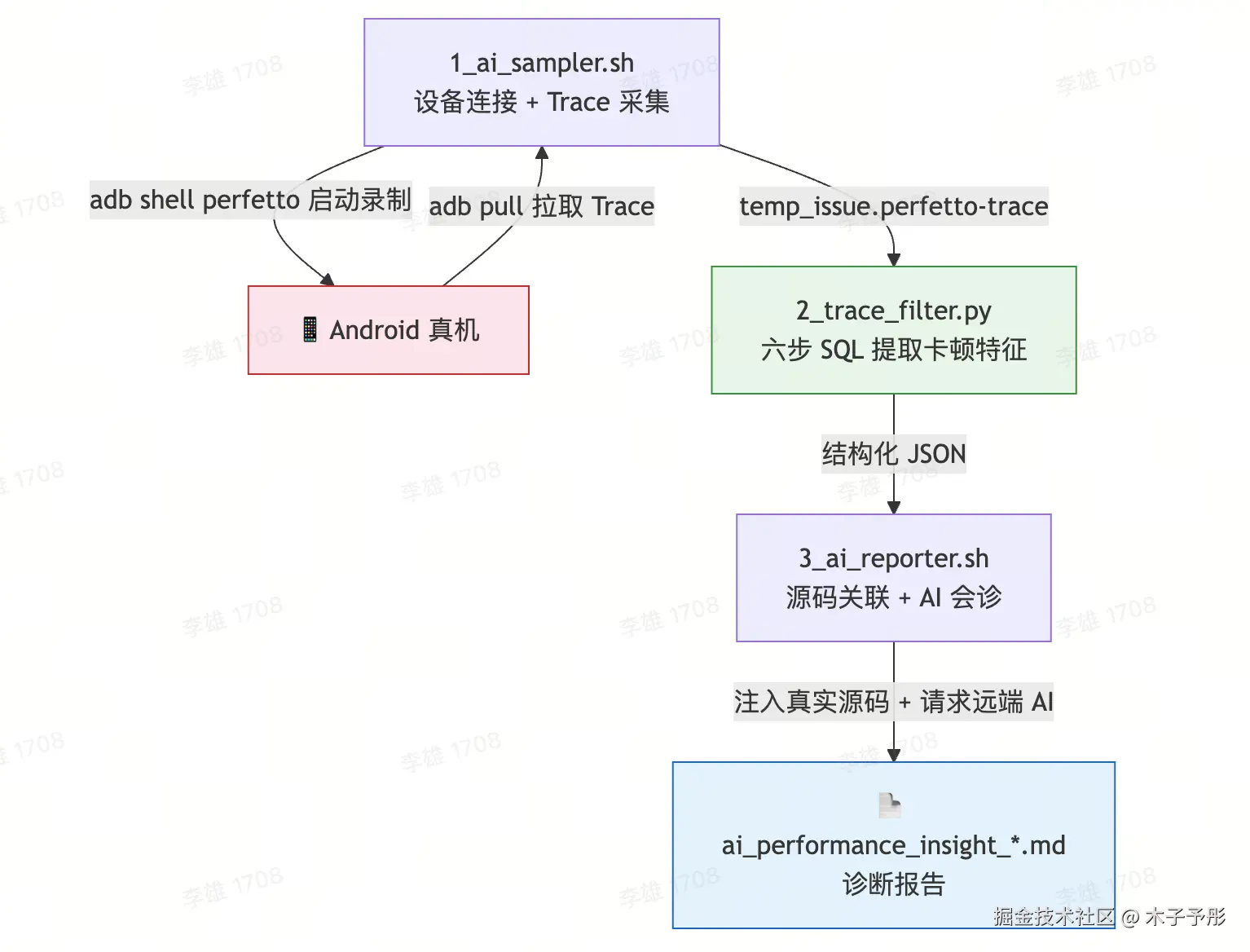
一句话概括:在真机上采集 Trace → Python 脚本用 SQL 提取卡顿特征 → Shell 脚本自动找到涉事源码并注入 AI Prompt → 远端大模型输出诊断报告。
入口脚本 run_profiler.sh 串联全部阶段,开发者执行一条命令即可走完全流程。
Perfetto SQL 数据库表结构
Perfetto 在解析 Trace 文件后,将所有性能数据映射为一个关系型 SQLite 数据库。理解以下四张核心表是读懂分析脚本逻辑的前提。
完整的表结构索引见 Perfetto SQL Tables 官方文档。
slice(耗时轨迹切片表)
记录被系统/应用打桩的每一段函数执行区间,是定位卡顿的主查询表。
| 字段 | 类型 | 说明 |
|---|---|---|
| id | INTEGER | 切片 ID,用于 descendant_slice(id) 向下查询子调用栈 |
| track_id | INTEGER | 所属时间轨道,关联 thread_track.id |
| name | TEXT | 事件或方法名,如 Choreographer#doFrame、View.draw |
| ts | INTEGER | 开始时间(纳秒绝对时间戳) |
| dur | INTEGER | 持续时长(纳秒)。Android 要求每帧在 16.6ms 内完成以保持 60fps 流畅,因此超过 16,600,000ns 的帧即为掉帧 |
| depth | INTEGER | 调用栈嵌套深度,0 为最外层 |
探索 slice 表的实际数据
-
通过 Python 脚本 执行 SQL 语句查询
pythonfrom perfetto.trace_processor import TraceProcessor tp = TraceProcessor(trace='temp_issue.perfetto-trace') for row in tp.query("SELECT * FROM slice LIMIT 5"): print(row.__dict__) -
在 ui.perfetto.dev 快捷查询,把 Trace 文件拖入 Perfetto UI,选择 SQL 模式执行 SQL 语句即可。
thread(系统线程表)
记录 Trace 录制期间所有被调度过的线程信息。
| 字段 | 类型 | 说明 |
|---|---|---|
| utid | INTEGER | Perfetto 内部唯一线程 ID,所有跨表关联的核心键 |
| tid | INTEGER | 操作系统真实线程 ID,与 logcat 中的 TID 一一对应 |
| name | TEXT | 线程名,如 main(主线程)、RenderThread(渲染线程) |
| is_main_thread | INTEGER | 1 = UI 主线程;0 = 后台线程 |
thread_track(线程轨道桥接表)
slice 存的是 track_id,而非直接存 utid。此表负责将时间轨道 ID 映射回真实线程。
| 字段 | 类型 | 说明 |
|---|---|---|
| id | INTEGER | 轨道 ID,对应 slice.track_id |
| utid | INTEGER | 执行该轨道的真实线程,对应 thread.utid |
三表关联模式:slice JOIN thread_track ON slice.track_id = thread_track.id JOIN thread ON thread_track.utid = thread.utid,即可知道"哪个方法在哪个线程上执行了多久"。
thread_state(CPU 调度状态表)
追踪线程的每一个 CPU 调度状态,是判断卡顿根因的关键表:区分"代码逻辑本身慢"还是"线程被系统挂起等待"。
| 字段 | 类型 | 说明 |
|---|---|---|
| utid | INTEGER | 线程 ID |
| ts / dur | INTEGER | 该状态的起止时间(纳秒) |
| state | TEXT | CPU 调度状态标识,见下表 |
| io_wait | INTEGER | 1 = 正阻塞于磁盘/网络 I/O,ANR 的高频原因 |
state 字段值域:
| 值 | 含义 | 诊断意义 |
|---|---|---|
| Running | CPU 正在执行该线程的代码 | 此状态时间长 → 代码计算量过重(CPU 密集型卡顿) |
| R | 线程已就绪,等待 CPU 分配时间片 | 频繁出现 → 被高优先级任务抢占 |
| S | 主动休眠,等待事件唤醒 | 正常等待状态,通常无害 |
| D | 不可中断睡眠(Uninterruptible Sleep) | ANR 高危,阻塞于磁盘 I/O 或互斥锁 |
process(进程信息表)
记录 Trace 录制期间所有活跃的进程。和 thread 表配合使用,确定某个线程属于哪个应用进程。
| 字段 | 类型 | 说明 |
|---|---|---|
| upid | INTEGER | Perfetto 内部唯一进程 ID |
| pid | INTEGER | 操作系统真实进程 ID |
package_list(包名与 UID 映射底层基表)
由 android.packages_list 数据源在采样期间抓取生成的应用层全局映射表。 核心价值 :我们分析卡顿的入口是"目标包名"。但遇到应用冷启动阶段(进程名显示为 <pre-initialized> 或 zygote64)时,process 表里根本找不到包名字样。此时,我们依靠这张表,利用已知的"包名"反查其内部 uid,进而关联出其底下所有存活的真实 pid,为后续各维度的深颗粒度筛选奠定 100% 可靠的进程基础。
| 字段 | 类型 | 说明 |
|---|---|---|
| id | INTEGER | Android 系统为应用统一分配的 Linux 用户 ID |
| package_name | TEXT | 应用的正式包名(如 com.luck.pictureselector)或系统进程标识(如 AID_SYSTEM_USER) |
实战用法(依靠包名找出所有真实 PID):
css
SELECT
p.pid,
p.name AS process_name,
p.id,
l.package_name
FROM process p
LEFT JOIN package_list l ON p.uid = l.id
WHERE l.package_name = 'com.luck.pictureselector';以上查询可彻底无视应用处于何种启动阶段,精准定位并提取出该应用底层真实的全部 PID,用于后续漏斗过滤。
args(Slice 附加参数表)
部分 slice 事件携带了额外的 key-value 参数(如 View 类型、Adapter Position、Binder 目标等)。这张表存储了这些附加上下文信息。
| 字段 | 类型 | 说明 |
|---|---|---|
| arg_set_id | INTEGER | 参数组 ID,对应 slice.arg_set_id |
| key | TEXT | 参数键名,如 view_type、adapter_position、dest_proc |
| string_value | TEXT | 字符串类型的值(与 int_value/real_value 互斥) |
| int_value | INTEGER | 整数类型的值 |
| real_value | REAL | 浮点数类型的值 |
actual_frame_timeline_slice(帧级卡顿归因表,Android 12+)
Frame Timeline 是 Android 12 引入的帧级归因机制。SurfaceFlinger 为每一帧打上标签,说明这一帧是否卡了、卡在哪个环节。
| 字段 | 类型 | 说明 |
|---|---|---|
| ts | INTEGER | 帧开始时间(纳秒) |
| dur | INTEGER | 帧总持续时间(纳秒) |
| layer_name | TEXT | 图层名,格式通常为 TX - <包名>/<Activity名>#。用于区分哪个应用的哪个窗口 |
| jank_type | TEXT | 卡顿类型:None(正常)/ App Deadline Missed(应用超时)/ SurfaceFlinger Scheduling(合成器问题)/ Buffer Stuffing 等 |
| present_type | TEXT | 呈现类型:On-time Present(正常)/ Late Present(迟到)/ Dropped(丢帧) |
| on_time_finish | INTEGER | 0 = 未按时完成,1 = 按时完成 |
诊断价值:如果 jank_type = "App Deadline Missed",说明卡顿是应用自己的代码造成的(而不是系统合成器或 GPU 的问题),可以放心在应用源码中找原因。
perf_sample(CPU 采样表,Android 15+)
linux.perf 数据源产生的 CPU 采样记录。每条记录代表一次 CPU 快照------记录了此刻哪个线程的哪个函数正在被 CPU 执行。
| 字段 | 类型 | 说明 |
|---|---|---|
| ts | INTEGER | 采样时间(纳秒) |
| utid | INTEGER | 被采样的线程 ID,关联 thread.utid |
| callsite_id | INTEGER | 调用栈叶子节点 ID,关联 stack_profile_callsite.id。从这个叶子节点沿 parent_id 往上走,可以还原完整调用链 |
| cpu | INTEGER | 采样发生在哪个 CPU 核心上 |
诊断价值:同一个 callsite_id 被多次采样到,说明 CPU 反复在执行同一条调用路径------这就是 CPU 热点。采样命中次数越多,该路径的 CPU 占用越重。
stack_profile_callsite(调用栈链表,与 perf_sample 配套)
每一次 CPU 采样的调用栈以链表 形式存储在此表中。每个节点指向一个 stack_profile_frame(具体的函数帧),通过 parent_id 链接到上一级调用者,直到栈顶(parent_id = NULL)。
| 字段 | 类型 | 说明 |
|---|---|---|
| id | INTEGER | 节点 ID,被 perf_sample.callsite_id 引用 |
| frame_id | INTEGER | 对应的函数帧 ID,关联 stack_profile_frame.id |
| parent_id | INTEGER | 父节点 ID(上一级调用者),NULL 表示栈顶 |
使用 WITH RECURSIVE SQL 从叶子节点沿 parent_id 一路回溯到栈顶,即可还原完整调用链:
vbnet
-- 从叶子节点 (callsite_id=123) 回溯完整调用链
WITH RECURSIVE chain AS (
SELECT spc.frame_id, spc.parent_id, 0 AS depth
FROM stack_profile_callsite spc WHERE spc.id = 123
UNION ALL
SELECT spc.frame_id, spc.parent_id, c.depth + 1
FROM chain c JOIN stack_profile_callsite spc ON c.parent_id = spc.id
WHERE c.depth < 40
)
SELECT spf.name AS func_name, spm.name AS module_name
FROM chain c
JOIN stack_profile_frame spf ON c.frame_id = spf.id
JOIN stack_profile_mapping spm ON spf.mapping = spm.id
ORDER BY c.depth DESC; -- 栈顶(调用者) → 栈底(被调用者)stack_profile_frame + stack_profile_mapping(函数帧与模块映射)
这两张表配合 stack_profile_callsite 使用,提供调用链中每个帧的函数名和所属模块。
stack_profile_frame:
| 字段 | 类型 | 说明 |
|---|---|---|
| id | INTEGER | 帧 ID,被 stack_profile_callsite.frame_id 引用 |
| name | TEXT | 函数名(可能是混淆后的名称) |
| deobfuscated_name | TEXT | 反混淆后的函数名(如果有映射文件) |
| mapping | INTEGER | 所属模块 ID,关联 stack_profile_mapping.id |
stack_profile_mapping:
| 字段 | 类型 | 说明 |
|---|---|---|
| id | INTEGER | 模块 ID |
| name | TEXT | 模块名,如 libc.so、libart.so、memfd:jit-cache。memfd:jit-cache 表示 JIT 编译的 Java/Kotlin 方法------这是区分应用 Java 代码和原生 C 代码的关键标志 |
诊断价值:module_name = memfd:jit-cache + 函数名不以 java./android./kotlin. 等系统前缀开头 = 应用自身的 Java/Kotlin 业务代码。
动态查询任意表的字段结构
当需要确认某张表的完整字段(包括文档未覆盖的字段),可使用 PRAGMA table_info:
bash
# Shell 方式(最快)
echo "PRAGMA table_info(thread);" | ~/.local/share/perfetto/prebuilts/trace_processor_shell temp_issue.perfetto-trace
python
# Python 方式(可集成进脚本)
from perfetto.trace_processor import TraceProcessor
tp = TraceProcessor(trace='temp_issue.perfetto-trace')
for c in tp.query("PRAGMA table_info(thread);"):
print(f"{c.name} (类型: {c.type})")Perfetto 采集类别说明
采样脚本(1_ai_sampler.sh)在录制时固定开启以下 11 个数据源类别,覆盖 UI 卡顿诊断所需的全部维度:
sched freq idle am wm gfx view binder_driver hal dalvik memory
| 类别 | 记录什么 | 对卡顿诊断有什么用 |
|---|---|---|
| sched | 内核线程调度(上下文切换、CPU 亲和性) | 判断主线程是否被其他线程抢占了 CPU |
| freq | CPU 频率变化 | 判断是否因 CPU 降频导致计算变慢 |
| idle | CPU 空闲状态进出 | 判断 CPU 是否在关键时刻进入了省电模式 |
| am | ActivityManager(Activity 生命周期) | 发现 Activity 创建/销毁引起的卡顿 |
| wm | WindowManager(窗口层级变化) | 发现窗口切换引起的卡顿 |
| gfx | 图形管线(帧提交、SurfaceFlinger) | 直接看到每一帧的渲染耗时 |
| view | View 系统(measure / layout / draw) | 定位具体哪个 View 的绘制最慢 |
| binder_driver | Binder IPC 跨进程调用 | 发现跨进程通信导致的主线程阻塞 |
| hal | HAL 层调用 | 发现硬件抽象层的延迟 |
| dalvik | ART 虚拟机(GC、JIT 编译) | 发现垃圾回收停顿导致的卡顿 |
| memory | 内存分配与回收 | 发现内存压力引起的性能下降 |
环境准备
依赖项
| 依赖 | 用途 | 怎么检查 | 怎么安装 |
|---|---|---|---|
| Python 3 (3.8+) | Trace 解析引擎 | python3 --version | python.org |
| perfetto 库 | SQL 查询 Trace | --- | pip3 install perfetto |
| jq | JSON 格式化与解析 | jq --version | brew install jq(macOS) |
| adb | Android 设备连接 | adb version | 安装 Android SDK Platform-Tools |
| DeepSeek API Key | AI 引擎调用鉴权 | --- | 填入 3_ai_reporter.sh 第 5 行 |
首次初始化 trace_processor_shell 二进制
bash
CACHE_DIR=~/.local/share/perfetto/prebuilts
mkdir -p $CACHE_DIR
# macOS Apple Silicon
curl -L "https://commondatastorage.googleapis.com/perfetto-luci-artifacts/v50.0/mac-arm64/trace_processor_shell" \
-o "$CACHE_DIR/trace_processor_shell"
chmod +x "$CACHE_DIR/trace_processor_shell"
echo "✓ trace_processor_shell 安装完毕,后续运行无需网络。"赋予脚本执行权限
bash
chmod +x tools/ai_profiler/*.sh脚本详解
1_ai_sampler.sh --- Trace 采集器
负责连接 Android 设备,启动 perfetto 录制。核心能力:
- 支持多设备自动选择
- 必须传入目标包名 :不传包名直接退出。传入后,Callstack Sampling(
linux.perf)会加入target_cmdline限定只对该应用的进程展开解析调用栈 (而非内核采样层面的过滤,其他进程的原始采样点可能仍存在于perf_sample表中),同时linux.process_stats加入进程采集特征 - 使用 config 模式启动 perfetto,同时开启 atrace 类别、Frame Timeline(Android 12+)和 Callstack Sampling(Android 15+)三个数据源
- config 通过
cat config.pbtxt | perfetto --txt -c - -o <path>方式传入(文本 proto 格式需要--txt参数;通过设备端cat管道绕过 SELinux 对 perfetto 进程的文件读取限制) - 低版本设备不支持的数据源会被 perfetto 自动跳过;若 config 模式整体启动失败,自动降级到命令行模式(仅 atrace 类别)
bash
#!/bin/bash
# ============================================================================
# 1_ai_sampler.sh --- Android Perfetto Trace 采集脚本
# ============================================================================
#
# 【这个脚本是干什么的?】
# 这是 V1 方案的"采集器"。它的唯一职责是:
# 1. 连上 Android 手机
# 2. 启动 Perfetto 性能追踪
# 3. 等用户操作完成后,把追踪数据拉回电脑
#
# 采集到的 .perfetto-trace 文件会交给 2_trace_filter.py 做分析。
#
# 【怎么用?】
# 必须传入目标应用包名:
# bash tools/ai_profiler/1_ai_sampler.sh <包名>
# 示例:
# bash tools/ai_profiler/1_ai_sampler.sh com.luck.pictureselector
# Callstack Sampling(linux.perf)会限定只采集该应用的线程,采集更精准、数据量更小。
# 然后在手机上操作复现卡顿,操作完按 Enter 键结束采集。
#
# 【Perfetto 是什么?】
# Perfetto 是 Android 系统内置的性能追踪工具(类似一个超级详细的"录像机",
# 但录的不是画面,而是 CPU、内存、线程调度等系统底层活动)。
# 它从 Android 9 开始内置,功能随版本升级越来越强。
# ============================================================================
# ==================== 第一步:解析包名参数 ====================
#
# 第一个参数为目标应用包名(必填,如 com.luck.pictureselector)。
# perfetto config 中 linux.perf 会加入 target_cmdline 限定只采集该应用的 CPU 调用栈。
TARGET_PACKAGE="${1:-}"
if [ -z "$TARGET_PACKAGE" ]; then
echo "[错误] 必须传入目标应用包名。"
echo "用法: bash 1_ai_sampler.sh <包名>"
echo "示例: bash 1_ai_sampler.sh com.luck.pictureselector"
exit 1
fi
echo "[提示] 目标应用包名: ${TARGET_PACKAGE} (Callstack Sampling 将限定采集该应用)"
# ==================== 第二步:检测 Android 设备连接 ====================
#
# 执行 adb devices 命令,统计已连接且已授权的设备数量。
# grep -w "device" 精确匹配 "device" 这个单词(排除 "unauthorized" 等状态)。
# wc -l 统计行数,tr -d ' ' 去掉多余空格。
device_count=$(adb devices | grep -w "device" | wc -l | tr -d ' ')
if [ "$device_count" -eq 0 ]; then
# 没有检测到任何设备------可能是:
# 1. USB 线没插好
# 2. 手机上没有打开"USB 调试"开关
# 3. 手机弹出了 USB 调试授权弹窗但用户没有点"允许"
echo "[错误] 未检测到已连接的 Android 设备。请确保设备已连接并授权 USB 调试。"
exit 1
elif [ "$device_count" -eq 1 ]; then
# 只有一台设备,自动选定,不需要用户手动选择
DEVICE_SERIAL=$(adb devices | grep -w "device" | awk '{print $1}')
echo "[提示] 检测到单台设备,自动连接: $DEVICE_SERIAL"
else
# 连接了多台设备(比如同时插了手机和平板),让用户选择要追踪哪一台
echo "[提示] 检测到多台设备,请选择要追踪的设备序号:"
devices=($(adb devices | grep -w "device" | awk '{print $1}'))
select DEVICE_SERIAL in "${devices[@]}"; do
if [ -n "$DEVICE_SERIAL" ]; then
echo "已选择设备: $DEVICE_SERIAL"
break
else
echo "无效的选择,请重新输入。"
fi
done
fi
# 后续所有 adb 命令都通过 -s 参数指定目标设备,避免多设备场景下命令发错设备
ADB_CMD="adb -s $DEVICE_SERIAL"
# ==================== 第三步:定义文件路径 ====================
# 本地电脑上保存 trace 文件的路径(脚本运行目录下)
TRACE_FILE="temp_issue.perfetto-trace"
# 设备上 perfetto 写入 trace 数据的路径
# /data/misc/perfetto-traces/ 是 perfetto 进程有写权限的目录
DEVICE_TRACE_FILE="/data/misc/perfetto-traces/app.trace"
# 设备上临时存放 config 文件的路径
# 注意:perfetto 进程无法直接读取这个路径(SELinux 限制),
# 但 shell 用户可以读取,所以后面用 cat 管道的方式绕过
DEVICE_CONFIG_FILE="/data/local/tmp/trace_config.pbtxt"
# 清理上一次的残留文件,确保拿到的是本次采集的新数据
rm -f ./$TRACE_FILE
$ADB_CMD shell rm -f $DEVICE_TRACE_FILE
# ==================== 第四步:构建 Perfetto 配置并启动采集 ====================
#
# 【为什么要用 config 模式?】
# perfetto 有两种启动方式:
# 1. 命令行模式:perfetto -o file.trace sched gfx view ...
# 简单但功能有限,只能指定 atrace 类别
# 2. config 模式:perfetto --txt -c - -o file.trace < config.pbtxt
# 可以配置额外数据源(Frame Timeline、Callstack Sampling 等)
#
# 我们优先用 config 模式以获取最丰富的数据,失败时自动回退到命令行模式。
# 创建一个本地临时文件来存放 Perfetto 配置
# mktemp 会在 /tmp 目录下生成一个唯一的临时文件名
LOCAL_CONFIG=$(mktemp)
# 将 Perfetto TraceConfig(text proto 格式)写入临时文件
# 先写 buffers + ftrace + frametimeline 部分(所有场景通用)
cat > "$LOCAL_CONFIG" <<'PART1'
buffers {
size_kb: 65536
fill_policy: RING_BUFFER
}
data_sources {
config {
name: "linux.ftrace"
ftrace_config {
atrace_categories: "sched"
atrace_categories: "freq"
atrace_categories: "idle"
atrace_categories: "am"
atrace_categories: "wm"
atrace_categories: "gfx"
atrace_categories: "view"
atrace_categories: "binder_driver"
atrace_categories: "hal"
atrace_categories: "dalvik"
atrace_categories: "memory"
ftrace_events: "sched/sched_switch"
}
}
}
data_sources {
config {
name: "android.surfaceflinger.frametimeline"
}
}
data_sources {
config {
name: "android.packages_list"
}
}
PART1
# linux.perf 部分:用 target_cmdline 限定对目标应用展开 CPU 调用栈解析
# 注意:target_cmdline 作用于 Perfetto callstack unwind 层,而非内核采样层------内核仍全量采样所有
# 进程,target_cmdline 只是让 Perfetto 仅对匹配包名的进程展开调用栈,其他进程原始采样点
# 可能依然存在于 perf_sample 表。OEM/系统框架噪音由 2_trace_filter.py 的 SYSTEM_PREFIXES 过滤
cat >> "$LOCAL_CONFIG" <<EOF
data_sources {
config {
name: "linux.perf"
perf_event_config {
timebase {
counter: SW_CPU_CLOCK
frequency: 500
timestamp_clock: PERF_CLOCK_MONOTONIC
}
callstack_sampling {
kernel_frames: false
}
target_cmdline: "$TARGET_PACKAGE"
}
}
}
EOF
# linux.process_stats 部分:此项不可或缺!
# 必须依赖它在采集开始时扫描 `/proc/*/status` 来获取每个进程的 Uid。
# 否则 Perfetto 的 process 表中 uid 将全为 NULL,导致我们在 2_trace_filter.py 的 1/6 步
# 无法通过 UID JOIN 到 package_list 表中,从而完全丢失目标应用特征。
cat >> "$LOCAL_CONFIG" <<'PROCESS_STATS'
data_sources {
config {
name: "linux.process_stats"
process_stats_config {
scan_all_processes_on_start: true
record_thread_names: true
}
}
}
PROCESS_STATS
echo "[提示] linux.perf 已配置 target_cmdline: $TARGET_PACKAGE"
echo "[提示] linux.process_stats 已开启(映射 process.uid 基石数据)"
# 安全时长上限
echo "duration_ms: 600000" >> "$LOCAL_CONFIG"
# ---- 配置与启动说明 ----
# 1. 数据源包含:基础 atrace 类别 (sched/gfx/view...)、帧级归因 (frametimeline, API 31+)、以及内核调度栈提取 (linux.perf, API 35+)。
# 2. 缓冲区策略:全局 64MB RING_BUFFER,封顶 10 分钟自动熔断,防止设备无限制积压。
# 3. 启动流转:为绕过目标机 SELinux 严格模式下 perfetto 原生引擎被拒读取临时文件的权限封堵问题,
# 脚本需利用 ADB Shell 宿主的提权管道(cat FILE | perfetto -c -)变向送入参数。
echo "[提示] 尝试 config 模式启动 perfetto..."
# 先把本地的配置文件内容写入设备端(通过 stdin 重定向,不是 adb push)
$ADB_CMD shell "cat > $DEVICE_CONFIG_FILE" < "$LOCAL_CONFIG"
# 本地临时文件用完了,删掉
rm -f "$LOCAL_CONFIG"
# 在设备上启动 perfetto(后台运行,& 放到后台)
$ADB_CMD shell "cat $DEVICE_CONFIG_FILE | perfetto --txt -c - -o $DEVICE_TRACE_FILE" >/dev/null 2>&1 &
# 等待 2 秒让 perfetto 完成初始化
sleep 2
# ---- 检查 perfetto 是否成功启动 ----
if $ADB_CMD shell "pidof perfetto" > /dev/null 2>&1; then
# config 模式启动成功!可以享受 Frame Timeline + Callstack Sampling 的完整数据
echo "[提示] config 模式启动成功(含 Frame Timeline + Callstack Sampling)"
else
# config 模式失败了------可能是低版本 perfetto 不支持 --txt,或者设备有其他限制
# 自动回退到命令行模式,虽然数据没那么丰富,但至少能拿到基础 atrace 数据
echo "[警告] config 模式启动失败,回退到命令行模式..."
$ADB_CMD shell rm -f $DEVICE_TRACE_FILE
$ADB_CMD shell "perfetto -o $DEVICE_TRACE_FILE sched freq idle am wm gfx view binder_driver hal dalvik memory" > /dev/null 2>&1 &
sleep 1
fi
# ==================== 第五步:等待用户操作完成 ====================
#
# 此时 perfetto 正在设备上录制性能数据。
# 您需要在手机上操作以复现卡顿场景(比如快速滑动列表、打开某个页面等)。
# 操作完成后按 Enter 键,脚本会停止录制并挂载抓取数据。
echo "[Trace 系统捕获开启] 复现该故障交互路径全过程后,通过 [Enter] 键回车截断并开始切片分析:"
read -p ""
# 记录结束时间,准备停止采集
# ==================== 第六步:停止采集并拉取数据 ====================
# 发送 SIGINT(Ctrl+C)信号给 perfetto,让它优雅地结束并把缓冲区数据写入文件
# 不能直接 kill -9,那样会丢失还在缓冲区中没来得及写入的数据
$ADB_CMD shell pkill -INT perfetto
echo "等待性能数据落盘中..."
# 等待 2 秒确保数据完整写入磁盘
sleep 2
# 清理设备端的临时配置文件(不留垃圾)
$ADB_CMD shell rm -f $DEVICE_CONFIG_FILE > /dev/null 2>&1
# 从设备把 trace 文件拉到电脑上
$ADB_CMD pull $DEVICE_TRACE_FILE ./$TRACE_FILE
# 检查文件是否成功拉取
if [ ! -f "./$TRACE_FILE" ]; then
echo "[错误] 无法获取 Trace 文件。可能是设备端 perfetto 进程未成功启动或写入失败。"
exit 1
fi
# 所有采集和准备工作就绪。
echo "底层结构体回传完结,启动中心化分析。"2_trace_filter.py --- SQL 分析引擎
调用 perfetto.trace_processor 对 .perfetto-trace 文件执行六步 SQL 分析,输出结构化 JSON 特征,供下游 AI 使用。其中步骤 4-6 为渐进增强------数据不可用时自动跳过,不影响基础诊断。
三步 SQL 下探流程

步骤 4 的系统框架过滤规则(排除以下,仅保留业务层嫌疑节点):
- Choreographer 自身切片
- 系统 View 层:
android.widget.*、android.view.*、androidx.*、com.android.* - 通用渲染切片:
traversal、measure、layout、draw、inflate等 - RenderThread 内部切片:
DrawFrame、syncFrameState、flush commands、eglSwap等
输出 JSON 格式:
json
{
"status": "anomaly_detected",
"target_process": "com.luck.pictureselector",
"diagnostic_desc": "在关键主线程区捕捉到失帧阻塞段",
"anomalous_frame_cost_ms": 85.73,
"top_jank_frames": [
"Choreographer#doFrame 57445701 (85.73ms)",
"Choreographer#doFrame 57452810 (33.99ms)",
"Choreographer#doFrame 57445539 (26.4ms)"
],
"thread_os_states": [
"CPU内核调度向量: '有效算力调用', 细分耗时 76.98 ms",
"CPU内核调度向量: '等 CPU 分配', 细分耗时 3.51 ms"
],
"suspect_root_cause_methods": [
"draw-VRI[PictureSelectorSupporterActivity] (耗时: 9.07ms)",
"draw-VRI[MainActivity] (耗时: 6.29ms)",
"HWUI:com.luck.picture.lib.widget.RecyclerPreloadView (耗时: 6.16ms)"
],
"frame_timeline_jank": [
"TX - com.luck.pictureselector/MainActivity: App Deadline Missed (present: Late Present) (86.36ms)",
"TX - com.luck.pictureselector/PictureSelectorSupporterActivity: App Deadline Missed (present: Late Present) (88.11ms)"
],
"callstack_chains": [
{
"hits": 2,
"chain": [
"[APP] com.luck.picture.lib.adapter.holder.BaseRecyclerMediaHolder.generate",
"[APP] com.luck.picture.lib.widget.MediumBoldTextView.<init>",
"[FWK] android.database.AbstractWindowedCursor.getString"
]
}
]
}若无卡顿,输出 {"status": "perfect"},流程终止。
各字段含义:
| 字段 | 类型 | 含义 |
|---|---|---|
| status | 枚举 | perfect(无卡顿)/ error(脚本出错)/ anomaly_detected(发现卡顿) |
| target_process | 字符串 | 被锁定的目标进程名或包名 |
| diagnostic_desc | 字符串 | 一句话总结 |
| anomalous_frame_cost_ms | 浮点数 | 最严重帧耗时(ms),正常应 ≤ 16.6ms |
| top_jank_frames | 字符串数组(可选) | Top 3 卡顿帧概览,辅助判断偶发 vs 持续性卡顿。多帧都卡说明是系统性问题 |
| blocked_functions | 字符串数组(可选) | 卡顿区间内内核阻塞函数列表(如 binder_thread_read、SyS_futex),对 I/O 阻塞和锁竞争诊断非常有价值 |
| thread_os_states | 字符串数组 | 该帧内主线程在各 CPU 状态下的耗时分布,用来判断"算太多"还是"等太久" |
| suspect_root_cause_methods | 字符串数组 | 按耗时从高到低的嫌疑业务代码(含 args 附加上下文),下游 AI 据此做根因分析 |
| frame_timeline_jank | 字符串数组(可选) | Frame Timeline 卡顿归因,区分 App 逻辑慢 / GPU 超时 / SurfaceFlinger 延迟。Android 12+ 可用 |
| callstack_chains | 对象数组(可选) | 主线程 CPU 采样的调用链重建,每条链包含 hits(采样命中次数)和 chain(APP/FWK 标记的调用路径)。仅包含应用自身 Java 代码和可操作的框架调用,已过滤 ART 运行时噪声。Android 15+ 可用 |
2_trace_filter.py 完整代码
python
# ============================================================================
# 2_trace_filter.py --- Perfetto Trace 六步 SQL 分析管线
# ============================================================================
#
# 【这个脚本是干什么的?】
# 输入:一个 .perfetto-trace 二进制文件
# 输出:一个 JSON 字符串(打印到 stdout),包含卡顿帧的诊断特征
#
# 脚本内部用 Perfetto 的 Python 库打开 trace 文件,然后执行 6 步 SQL 查询,
# 从海量原始数据中层层筛选出"导致卡顿的嫌疑方法",最终组装成结构化 JSON。
#
# 【最简六步分析法】
# 步骤 1: 进程决议 ------ 利用 package_list 表基于包名和 UID 推导真实的冷/热启动 PID
# 步骤 2: 帧级筛选 ------ 找到最卡的 Top 3 帧(Choreographer#doFrame > 16.6ms)
# 步骤 3: OS 调度状态 ------ 看看卡顿时主线程在干嘛(跑着/等 CPU/被 I/O 卡住/睡眠)
# 步骤 4: 调用栈下探 ------ 在最差帧的子 slice 中找到真正耗时的业务方法
# 步骤 5: Frame Timeline ------ Android 12+ 的帧级归因(App 的锅还是系统的锅)
# 步骤 6: Callstack Sampling ------ Android 15+ 的函数级 CPU 热点(精确到哪个方法最耗 CPU)
#
# 【输出 JSON 的三种 status】
# "perfect" ------ 没有检测到任何卡顿帧,系统很流畅
# "error" ------ 脚本运行出错(文件损坏、环境缺失等)
# "anomaly_detected" ------ 检测到卡顿,附带完整诊断数据
#
# 【运行方式】
# python3 2_trace_filter.py ./temp_issue.perfetto-trace com.luck.pictureselector
# ============================================================================
import sys, json
from perfetto.trace_processor import TraceProcessor
def perform_deep_dive(trace_path, package_name):
"""
核心分析函数:接收 trace 文件路径和目标应用包名,执行八步 SQL 分析。
所有进度信息打印到 stderr(不影响 JSON 输出的解析)。
参数:
trace_path: .perfetto-trace 文件路径
package_name: 目标应用包名(如 com.luck.pictureselector)
脚本内部通过左外连接 trace 文件的 process 和 package_list 表自动决议 PID。
"""
sys.stderr.write(f"[Python 引擎层] 正在装载 Perfetto 解析器 (若出现进度条属于首次下载环境,请耐心等待)...\n")
sys.stderr.flush()
try:
tp = TraceProcessor(trace=trace_path)
except Exception as e:
sys.stderr.write(f"\n[运行异常] TraceProcessor 启动失败!若因网络导致下载超时,请参考上一节手册挂载终端代理后重试。\n错误堆栈: {str(e)}\n")
print(json.dumps({"status": "error", "message": "内核解析引擎拉起异常,请检查网络下载或文件权限。"}, ensure_ascii=False))
sys.exit(1)
sys.stderr.write(f"[Python 引擎层] 引擎挂载成功,正在剥离分析异常调用栈...\n")
sys.stderr.flush()
# ========== 步骤 1/8: 智能通过包名寻找目标进程 PID ==========
sys.stderr.write(f"\n[Python 引擎层] [步骤 1/8] 正在通过 UID 层级特征推断目标进程 PID...\n")
target_pids = []
# 进行系统级的大规模 SQL 特征检索 (通过 android.packages_list 映射及其它特征兜底)
try:
query_pid = f"""
SELECT DISTINCT process.pid
FROM process
LEFT JOIN package_list ON process.uid = package_list.uid
WHERE process.name = '{package_name}'
OR package_list.package_name = '{package_name}'
"""
for r in tp.query(query_pid):
if r.pid is not None and r.pid > 0 and r.pid not in target_pids:
target_pids.append(r.pid)
if not target_pids:
sys.stderr.write(f"\n[运行异常] Trace 中未找到包名 '{package_name}' 相关的任何进程。请确认记录期间该应用是否处于活跃状态。\n")
print(json.dumps({"status": "error", "message": f"未能在 Trace 中定位到目标应用 ({package_name})。请确保采集期间应用已被正确启动。"}, ensure_ascii=False))
sys.exit(1)
sys.stderr.write(f"[Python 引擎层] [OK] 智能解析包名 '{package_name}' 命中以下 PID: {target_pids}\n")
except Exception as e:
sys.stderr.write(f"\n[运行异常] PID 决议查询失败: {str(e)}\n")
print(json.dumps({"status": "error", "message": f"基于包名推导进程标识过程异常。"}, ensure_ascii=False))
sys.exit(1)
# ========== 步骤 2/8: 帧级筛选(Top 3 卡顿帧) ==========
#
# 【原理】Android 的每一帧都由 Choreographer#doFrame 驱动。
# 正常情况下一帧应在 16.6ms 内完成(60fps)。超过 16.6ms 说明这一帧"卡了"。
# 我们找出最卡的 3 帧(按耗时降序),最差的那帧作为后续所有分析的焦点。
#
# 【查询模式】
# 指定 PID 模式:SQL 中直接用 process.pid IN (...) 过滤目标进程的卡顿帧
# 【SQL 解读】
# - slice 表存储了所有 trace event(可以理解为"时间段")
# - thread_track 和 thread 表用于关联到具体线程
# - process 表用于关联到进程,获取进程名和 upid
# - is_main_thread = 1 确保只看主线程(UI 线程)
# - dur > 16600000 纳秒 = 16.6 毫秒(一帧的预算时间)
sys.stderr.write(f"\n[Python 引擎层] [步骤 2/8] 正在提取 UI 线程超时重绘帧 (Top 3)...\n")
sys.stderr.flush()
# ---- 指定 PID 模式:SQL 层直接用 process.pid 限定目标进程 ----
pid_list = ','.join(str(p) for p in target_pids)
sys.stderr.write(f"[Python 引擎层] 检索卡顿: 针对已决议 PID ({pid_list}) 进行帧序拉取\n")
query_jank = f"""
SELECT slice.id, slice.name, slice.dur AS dur_ns, slice.dur / 1000000.0 AS ms,
thread.utid, slice.ts, process.name AS process_name, process.upid
FROM slice
JOIN thread_track ON slice.track_id = thread_track.id
JOIN thread ON thread_track.utid = thread.utid
JOIN process ON thread.upid = process.upid
WHERE slice.name LIKE 'Choreographer#doFrame%'
AND slice.dur > 16600000
AND thread.is_main_thread = 1
AND process.pid IN ({pid_list})
ORDER BY slice.dur DESC LIMIT 3;
"""
jank_frames = list(tp.query(query_jank))
if not jank_frames:
sys.stderr.write(f"[Python 引擎层] [分析完成] 目标 PID ({pid_list}) 在 trace 中无卡顿帧!系统极其平滑。\n")
sys.stderr.flush()
print(json.dumps({"status": "perfect"}))
return
# target_process 直接使用外层传入的精准 target_package_name
target_process = package_name
# 此时 jank_frames 确定
jank = jank_frames[0]
sys.stderr.write(f"[Python 引擎层] [OK] 该进程 Top {len(jank_frames)} 卡顿帧,最差帧: {jank.name} (耗损 {round(jank.ms,2)}ms)\n")
for i, f in enumerate(jank_frames):
display_name = package_name if not f.process_name or f.process_name in ["<pre-initialized>", "zygote64"] else f.process_name
sys.stderr.write(f" -> [Top {i+1}]: {f.name} ({round(f.ms,2)}ms) [进程: {display_name}]\n")
# ========== 步骤 3/8: OS 调度状态分析 ==========
#
# 【原理】线程卡住不一定是在"跑代码",也可能是在"等资源"。
# thread_state 表记录了线程在每个时刻的 CPU 调度状态:
# - Running:线程正在 CPU 上执行代码(真正在干活)
# - R(Runnable):线程想跑但 CPU 被其他线程占了(在排队)
# - R+(Preempted):线程正在跑但被更高优先级的线程抢走了 CPU
# - S(Sleeping):线程主动睡眠(等锁、等信号、等 I/O 完成通知)
# - D(Uninterruptible Sleep):不可中断睡眠,通常是磁盘 I/O 阻塞
#
# 如果卡顿期间大量时间花在 D 状态 + io_wait=1,说明主线程在做磁盘读写。
# 如果大量时间花在 R 状态,说明 CPU 太忙,主线程抢不到时间片。
# HAVING SUM(dur)/1000000.0 > 0.1 过滤掉不到 0.1ms 的微量状态,减少噪音。
sys.stderr.write(f"\n[Python 引擎层] [步骤 3/8] 计算卡顿区间的 OS 调度内幕 (I/O 阻塞/线程抢夺)...\n")
sys.stderr.flush()
query_state = f"""
SELECT state, SUM(dur)/1000000.0 AS ms, io_wait, IFNULL(GROUP_CONCAT(DISTINCT blocked_function), 'none') as kernel_blocks
FROM thread_state
WHERE utid = {jank.utid}
AND ts >= {jank.ts}
AND ts <= {jank.ts + jank.dur_ns}
GROUP BY state, io_wait
HAVING SUM(dur)/1000000.0 > 0.1;
"""
state_map = {"Running": "有效算力调用", "R": "等 CPU 分配", "R+": "被抢占后等 CPU", "S": "软挂起睡眠态", "D": "不中断型 I/O 阻塞"}
blocking_states = []
blocked_functions = [] # 独立记录内核阻塞函数(blocked_function 字段有值时)
sys.stderr.write("[Python 引擎层] 提取到的 OS 调度底层挂起向量行数据:\n")
for r in tp.query(query_state):
sys.stderr.write(f" -> [步骤 3 SQL 原始返回行]: {r.__dict__}\n")
info = f"CPU内核调度向量: '{state_map.get(r.state, r.state)}', 细分耗时 {round(r.ms,2)} ms"
if hasattr(r, 'kernel_blocks') and r.kernel_blocks is not None and str(r.kernel_blocks) != "none":
info += f" [底层内核诊断:探测到阻塞函数链 -> {r.kernel_blocks}]"
# blocked_function 记录了线程被阻塞时 CPU 停在哪个内核函数上
# 例如 binder_thread_read(等 Binder 返回)、SyS_futex(等锁)、
# do_page_fault(内存页错误)、__wait_rcu_gp(等 RCU 同步)等
# 这个信息对诊断 I/O 阻塞和锁竞争非常有价值
for bf in str(r.kernel_blocks).split(','):
bf = bf.strip()
if bf and bf != 'none':
blocked_functions.append(f"{bf} ({r.state}, {round(r.ms,2)}ms)")
elif r.io_wait == 1:
info += " [底层内核诊断:监测到重度 I/O_WAIT 同步等待]"
blocking_states.append(info)
if blocked_functions:
sys.stderr.write(f"[Python 引擎层] [OK] 发现 {len(blocked_functions)} 个内核阻塞函数:\n")
for bf in blocked_functions:
sys.stderr.write(f" -> [blocked_function]: {bf}\n")
sys.stderr.write(f"[Python 引擎层] [OK] 成功解析底层微状态,排队被剥夺占用 {len(blocking_states)} 条特征\n")
# ========== 步骤 4/8: 调用栈下探 + args 关联 ==========
#
# 【原理】步骤 1 找到了卡顿帧(Choreographer#doFrame),但这只是"外壳"。
# 真正导致卡顿的代码藏在 doFrame 的子 slice 里面。
#
# descendant_slice(jank.id) 是 Perfetto 内置函数,返回指定 slice 的所有后代节点。
# 我们从中筛选出耗时超过阈值(帧总耗时的 5%,至少 1ms)的子节点。
#
# 过滤掉 Android 框架自身的通用方法(traversal/measure/layout/draw/inflate 等),
# 这些方法虽然耗时但不是用户可控的,我们要找的是业务代码。
#
# 同时关联 slice 的 args 表,提取附加上下文(如 view type、adapter position),
# 帮助 AI 更精确地定位问题。
sys.stderr.write(f"\n[Python 引擎层] [步骤 4/8] 下探调用栈,锁定真实肇事的业务代码树节点...\n")
sys.stderr.flush()
threshold_ns = max(1000000, int(jank.ms * 1000000 * 0.05))
query_children = f"""
SELECT id, name, dur/1000000.0 AS ms FROM descendant_slice({jank.id})
WHERE dur > {threshold_ns}
AND name NOT IN ('traversal', 'measure', 'layout', 'draw', 'inflate', 'Record View#draw()', 'animation', 'animator', 'ViewRootImpl#draw')
AND name NOT LIKE 'Choreographer#%'
AND name NOT LIKE '%android.widget.%'
AND name NOT LIKE '%android.view.%'
AND name NOT LIKE '%androidx.%'
AND name NOT LIKE '%com.android.%'
AND name NOT LIKE 'DrawFrame%'
AND name NOT LIKE 'syncFrameState%'
AND name NOT LIKE 'flush commands%'
AND name NOT LIKE 'eglSwap%'
ORDER BY dur DESC LIMIT 12;
"""
children_rows = list(tp.query(query_children))
sys.stderr.write("[Python 引擎层] 提取到的下探调用栈原始行数据:\n")
for r in children_rows:
sys.stderr.write(f" -> [步骤 4 SQL 原始返回行]: {r.__dict__}\n")
# 关联 slice args,提取嫌疑切片的附加上下文(如 view type、adapter position 等)
slice_args_map = {}
if children_rows:
ids_str = ','.join(str(r.id) for r in children_rows)
query_args = f"""
SELECT s.id AS slice_id, a.key, a.string_value, a.int_value, a.real_value
FROM slice s
JOIN args a ON s.arg_set_id = a.arg_set_id
WHERE s.id IN ({ids_str})
AND s.arg_set_id IS NOT NULL
"""
try:
for a in tp.query(query_args):
val = a.string_value if a.string_value else (a.int_value if a.int_value is not None else a.real_value)
if val is not None:
slice_args_map.setdefault(a.slice_id, []).append(f"{a.key}={val}")
except Exception as e:
sys.stderr.write(f"[Python 引擎层] [WARN] args 表关联查询失败: {str(e)}\n")
if slice_args_map:
sys.stderr.write(f"[Python 引擎层] [OK] 成功关联 {len(slice_args_map)} 个切片的 args 附加上下文\n")
for sid, args_list in slice_args_map.items():
sys.stderr.write(f" -> slice {sid}: {', '.join(args_list)}\n")
# 组装嫌疑方法列表(附带 args 上下文)
suspect_methods = []
for r in children_rows:
entry = f"{r.name} (耗时: {round(r.ms,2)}ms)"
if r.id in slice_args_map:
entry += f" [args: {', '.join(slice_args_map[r.id])}]"
suspect_methods.append(entry)
# ========== 步骤 5/6: Frame Timeline 卡顿归因(Android 12+,可选) ==========
#
# 【原理】Frame Timeline 是 Android 12+ 引入的帧级归因机制。
# 它能区分一帧的卡顿到底是谁导致的:
# - App Deadline Missed:应用自己没在截止时间前画完(最常见,业务代码问题)
# - SurfaceFlinger Deadline Missed:系统合成器来不及合成(系统问题,应用无责)
# - Display HAL / Composition:硬件合成或显示层问题
#
# 如果 jank_type = "App Deadline Missed",配合步骤 4 的嫌疑方法,就能确认
# 是应用自己的代码导致了卡顿,而不是系统或硬件的问题。
sys.stderr.write(f"\n[Python 引擎层] [步骤 5/6] 尝试提取 Frame Timeline 卡顿归因 (需 Android 12+ 且采集时开启)...\n")
sys.stderr.flush()
frame_jank_info = []
try:
# 【关键改进】按目标进程的 layer_name 过滤
# actual_frame_timeline_slice 是全局帧数据,时间窗口内可能有多个应用的帧。
# layer_name 格式通常是 "TX - <package>/<activity>#<id>",用目标进程名做模糊匹配。
# 同时也查不带进程过滤的数据作为补充(某些系统合成帧没有应用 layer_name)。
query_ft = f"""
SELECT layer_name, jank_type, present_type, on_time_finish, dur/1000000.0 AS ms
FROM actual_frame_timeline_slice
WHERE ts >= {jank.ts}
AND ts <= {jank.ts + jank.dur_ns}
AND jank_type != 'None'
AND (layer_name LIKE '%{target_process}%' OR layer_name LIKE 'TX -%')
ORDER BY dur DESC LIMIT 5;
"""
ft_rows = list(tp.query(query_ft))
for r in ft_rows:
sys.stderr.write(f" -> [步骤 5 Frame Timeline]: layer={r.layer_name}, jank_type={r.jank_type}, present={r.present_type}, on_time={r.on_time_finish}, {round(r.ms,2)}ms\n")
jank_desc = f"{r.layer_name}: {r.jank_type}"
if hasattr(r, 'present_type') and r.present_type and r.present_type != 'On-time Present':
jank_desc += f" (present: {r.present_type})"
jank_desc += f" ({round(r.ms,2)}ms)"
frame_jank_info.append(jank_desc)
if ft_rows:
sys.stderr.write(f"[Python 引擎层] [OK] 成功提取 {len(ft_rows)} 条 Frame Timeline 卡顿归因\n")
else:
sys.stderr.write("[Python 引擎层] [INFO] Frame Timeline 无卡顿记录(该帧未被 SurfaceFlinger 标记为 jank)\n")
except Exception as e:
sys.stderr.write(f"[Python 引擎层] [SKIP] Frame Timeline 数据不可用: {str(e)}\n")
# ========== 步骤 6/6: Callstack Sampling 函数级热点(Android 15+,可选) ==========
# 解析 linux.perf 给出的 CPU 采样快照,回溯主线程调用链并过滤掉系统 C/C++ 库与 ART 虚拟机跳板代码。
sys.stderr.write(f"\n[Python 引擎层] [步骤 6/6] 尝试提取 Callstack Sampling 函数级热点 (需 Android 15+ 且采集时开启 linux.perf)...\n")
sys.stderr.flush()
callstack_hotspots = []
# -------- 过滤规则定义 --------
#
# 【背景】linux.perf 做的是 CPU 指令级采样。对于 Java/Kotlin 应用,CPU 绝大多数
# 时间在执行 ART 虚拟机的 C++ 代码(JIT编译、解释器、GC),而非用户的业务方法。
# 因此需要回溯完整调用链,从叶子帧(CPU 正在执行的原生代码)沿 parent_id 往上走,
# 找到调用链中属于应用自身包名的 Java/Kotlin 方法。
#
# 过滤策略分三层:
# 1. SYSTEM_PREFIXES: Java/Kotlin/Android 框架包名前缀,这些是系统代码,直接跳过
# 2. ART_NOISE: ART 虚拟机内部的跳板函数(出现在 JIT cache 中但不是真正的业务逻辑)
# 3. ACTIONABLE_PATTERNS: 虽然属于系统前缀,但对性能诊断有实际价值的框架调用
# 例如 android.database.* 出现在主线程说明有数据库操作卡主线程
# 系统/框架/运行时包名前缀------匹配到这些前缀的方法视为"系统代码",默认过滤
SYSTEM_PREFIXES = (
'java.', 'javax.', 'sun.', 'jdk.', # Java 标准库
'kotlin.', 'kotlinx.', # Kotlin 标准库和协程
'android.', 'androidx.', # Android SDK 和 Jetpack 库
'dalvik.', 'libcore.', # Dalvik/ART 运行时
'com.android.', 'android.', 'system.', # Android 平台内部实现
# --- OEM 厂商系统框架前缀(不属于应用业务代码)---
'oplus.', 'com.oplus.', 'oppo.', 'com.oppo.', 'coloros.', 'com.coloros.', 'oneplus.', 'com.oneplus.',
'miui.', 'com.miui.', 'com.xiaomi.',
'com.huawei.', 'com.hihonor.', 'honor.', 'com.honor.',
'com.samsung.', 'sec.', 'com.sec.',
'com.vivo.', 'com.iqoo.', 'vivo.', 'iqoo.',
'flyme.', 'com.meizu.',
)
# ART 虚拟机内部跳板/桥接函数------即使出现在 memfd:jit-cache 中也不是业务代码
# 这些函数是 ART 执行 Java 方法时的底层桩代码,对性能分析无意义
ART_NOISE = {
'art_jni_trampoline', # JNI 调用跳板
'art_quick_generic_jni_trampoline', # 通用 JNI 跳板
'art_quick_to_interpreter_bridge', # JIT→解释器桥接
'artQuickToInterpreterBridge', # 同上(不同命名风格)
'art_quick_invoke_stub', # 方法调用桩
'art_quick_resolution_trampoline', # 方法解析跳板
'art_quick_imt_conflict_trampoline', # 接口方法表冲突跳板
'art_quick_deoptimize', # 去优化跳板
'nterp_op_invoke_virtual', # 解释器虚方法调用
'nterp_op_invoke_interface', # 解释器接口方法调用
'nterp_op_invoke_direct', # 解释器直接方法调用
'nterp_op_invoke_static', # 解释器静态方法调用
'nterp_op_invoke_super', # 解释器父类方法调用
'ExecuteSwitchImplAsm', # Switch 解释器主循环
'MterpInvokeVirtual', # Mterp 解释器虚调用
'MterpInvokeInterface', # Mterp 解释器接口调用
}
# 可操作的框架调用------虽然包名以系统前缀开头,但出现在主线程意味着性能隐患
# 这些方法不会被过滤,而是标记为 [FWK] 展示在调用链中
ACTIONABLE_PATTERNS = (
'android.database.', # 数据库游标操作(不应在主线程)
'ContentResolver', # ContentProvider 跨进程查询
'SharedPreferences', # SP 读写(commit/apply)
'android.graphics.Bitmap', # Bitmap 解码/压缩(CPU 密集)
)
def _is_app_java_code(name, module):
"""判断是否为应用层的 Java/Kotlin 核心业务代码(根据模块特征产物防误判)"""
if not name or not module:
return False
# 放宽 Module 限制:Java/Kotlin 字节码可能来源于:
# 1. 'jit-cache' (运行时即时编译)
# 2. '.apk' (直接解释执行,常见于 Debug 包)
# 3. '.odex' / '.vdex' / '.oat' (AOT 全量/部分静态编译)
# 4. 'dalvik-' (Dalvik 内存空间中的动态代码)
# 如果都不是,且属于系统 native 层(如 /system/libxx, [kernel.*]),则必定是干扰噪点,直接毙掉
valid_java_modules = ('jit-cache', '.apk', '.odex', '.vdex', '.oat', '.dex', 'dalvik-')
if not any(m in module for m in valid_java_modules):
return False
# 排除 ART 内部跳板函数
if name in ART_NOISE:
return False
# 排除所有以系统包名前缀开头的方法
if name.startswith(SYSTEM_PREFIXES):
return False
return True
def _is_interesting(name, module):
"""
判断一个帧是否值得展示在调用链中。
分两类:
1. 应用自身 Java 代码(标记为 [APP])
2. 可操作的框架调用(标记为 [FWK]),如 android.database.*
这些虽然是系统代码,但出现在主线程意味着性能隐患,有诊断价值
"""
if _is_app_java_code(name, module):
return True
return any(p in name for p in ACTIONABLE_PATTERNS)
# 线程空闲/等待函数------出现在调用链中说明线程在等待而非干活,整条链无分析价值
IDLE_FUNCS = {
'__epoll_pwait', 'epoll_pwait', 'SyS_epoll_wait', 'do_epoll_wait',
'__futex_wait', 'futex_wait', 'syscall',
'__start_thread', '__pthread_start',
'SyS_futex', '__rt_sigtimedwait',
}
try:
# -------- 第一步:查询主线程 CPU 采样热点 --------
sys.stderr.write(f"[Python 引擎层] 正在查询 perf_sample 表 (utid={jank.utid}, 进程='{target_process}', "
f"时间窗口={jank.ts}~{jank.ts + jank.dur_ns})...\n")
query_samples = f"""
SELECT callsite_id, COUNT(*) AS hits
FROM perf_sample
WHERE ts >= {jank.ts} AND ts <= {jank.ts + jank.dur_ns}
AND callsite_id IS NOT NULL
AND utid = {jank.utid}
GROUP BY callsite_id ORDER BY hits DESC LIMIT 50;
"""
sample_groups = list(tp.query(query_samples))
sys.stderr.write(f"[Python 引擎层] perf_sample 查询返回 {len(sample_groups)} 组 callsite\n")
if not sample_groups:
sys.stderr.write("[Python 引擎层] [INFO] 卡顿帧时间窗口内无 perf_sample 采样数据(可能设备低于 Android 15 或采集未开启 linux.perf)\n")
else:
# -------- 第二步:为每个 callsite 回溯完整调用链 --------
chain_results = [] # 最终结果:[(hits, filtered_frames)]
seen_chains = set() # 用于去重:存储已见过的调用链指纹
for sg in sample_groups:
query_chain = f"""
WITH RECURSIVE chain AS (
SELECT spc.frame_id, spc.parent_id, 0 AS depth
FROM stack_profile_callsite spc WHERE spc.id = {sg.callsite_id}
UNION ALL
SELECT spc.frame_id, spc.parent_id, c.depth + 1
FROM chain c JOIN stack_profile_callsite spc ON c.parent_id = spc.id
WHERE c.depth < 40
)
SELECT IFNULL(spf.deobfuscated_name, spf.name) AS display_name,
spf.name AS func_name,
spm.name AS module_name
FROM chain c
JOIN stack_profile_frame spf ON c.frame_id = spf.id
JOIN stack_profile_mapping spm ON spf.mapping = spm.id
ORDER BY c.depth DESC;
"""
# all_frames: [(func_name, display_name, module_name), ...]
# 排序为:调用者(栈顶) → 被调用者(栈底)
all_frames = [
(f.func_name or '', f.display_name or f.func_name or '', f.module_name or '')
for f in tp.query(query_chain)
]
# -------- 第三步:过滤 + 去重 + 链内去重 + 最小长度检查 --------
# 3-前置. 跳过包含空闲/等待函数(处于阻塞态而非运算态)的整条调用链
has_idle = any(fn in IDLE_FUNCS for fn, _, _ in all_frames)
if has_idle:
continue
# 3a. 只保留"有价值"的帧(应用 Java 代码 + 可操作框架调用)
filtered = [(fn, dn, mod) for fn, dn, mod in all_frames if _is_interesting(fn, mod)]
# 3b. 链内连续去重(将递归/内联如 [A, A, B] 化简为 [A, B])
deduped = []
for item in filtered:
if not deduped or item[0] != deduped[-1][0]:
deduped.append(item)
filtered = deduped
# 3c. 至少保留 2 个帧的链路以确保拥有上下文
if len(filtered) < 2:
continue
# 3d. 基于节点序列指纹去重(过滤多出的无用叶子系统调用片段)
chain_fingerprint = tuple(fn for fn, _, _ in filtered)
if chain_fingerprint in seen_chains:
continue
# 3e. 子集涵盖去重(长序列涵盖了短序列则丢弃短序列)
is_subset = False
for existing in seen_chains:
if len(chain_fingerprint) <= len(existing):
if existing[:len(chain_fingerprint)] == chain_fingerprint:
is_subset = True
break
if is_subset:
continue
seen_chains.add(chain_fingerprint)
chain_results.append((sg.hits, filtered))
# 最多输出 5 条不重复的调用链,避免输出过长
if len(chain_results) >= 5:
break
# -------- 第四步:格式化输出(垂直树形,带 [APP]/[FWK] 标签) --------
# 输出格式示例:
# [调用链 1] 17次采样命中:
# ├─ [APP] com.luck.picture.lib.loader.LocalMediaPageLoader$3.doInBackground
# ├─ [APP] com.luck.picture.lib.loader.LocalMediaPageLoader.parseLocalMedia
# ├─ [APP] com.luck.picture.lib.utils.MediaUtils.getRealPathUri
# └─ [FWK] android.database.AbstractCursor.getColumnIndex
for idx, (hits, filtered) in enumerate(chain_results, 1):
sys.stderr.write(f"\n [调用链 {idx}] {hits}次采样命中:\n")
chain_lines = []
for i, (fn, dn, mod) in enumerate(filtered):
# [APP] = 应用自身 Java 业务代码(来自 JIT cache)
# [FWK] = 可操作的框架调用(如数据库操作出现在主线程)
tag = "[APP]" if _is_app_java_code(fn, mod) else "[FWK]"
# 最后一个帧用 └─,其他用 ├─,形成树形视觉
connector = "└─" if i == len(filtered) - 1 else "├─"
sys.stderr.write(f" {connector} {tag} {dn}\n")
chain_lines.append(f"{tag} {dn}")
callstack_hotspots.append({"hits": hits, "chain": chain_lines})
if callstack_hotspots:
sys.stderr.write(f"\n[Python 引擎层] [OK] 成功重建 {len(callstack_hotspots)} 条应用级调用链\n")
elif sample_groups:
sys.stderr.write("[Python 引擎层] [INFO] 调用链中未发现应用自身代码(业务方法执行过快,CPU 采样未命中)\n")
except Exception as e:
sys.stderr.write(f"[Python 引擎层] [SKIP] Callstack Sampling 数据不可用: {str(e)}\n")
# ========== 组装 JSON 输出 ==========
#
# 将八步分析的结果汇总为一个 JSON 对象,打印到 stdout。
# 只有存在数据的字段才会被加入(避免空数组误导 AI)。
#
# 【JSON 字段说明】
# status: "anomaly_detected" --- 固定值,表示检测到卡顿
# anomalous_frame_cost_ms: 最差帧耗时(毫秒)
# thread_os_states: 步骤 3 的 CPU 调度状态分析
# suspect_root_cause_methods: 步骤 4 的嫌疑方法列表
# top_jank_frames: 步骤 2 的 Top 3 帧概览(仅当 >1 帧时才有)
# frame_timeline_jank: 步骤 5 的帧级归因(仅 Android 12+ 且有 jank 时才有)
# callstack_chains: 步骤 6 的调用链(仅 Android 15+ 且有应用级命中时才有)
report_context = {
"status": "anomaly_detected",
"target_process": target_process,
"diagnostic_desc": "在关键主线程区捕捉到失帧阻塞段",
"anomalous_frame_cost_ms": round(jank.ms, 2),
"thread_os_states": blocking_states,
"suspect_root_cause_methods": suspect_methods
}
# blocked_function 单独输出(对 I/O 阻塞和锁竞争诊断非常有价值)
if blocked_functions:
report_context["blocked_functions"] = blocked_functions
# Top 3 卡顿帧概览(辅助判断是偶发还是持续性卡顿)
if len(jank_frames) > 1:
report_context["top_jank_frames"] = [
f"{f.name} ({round(f.ms,2)}ms) [{f.process_name or '<unknown>'}]" for f in jank_frames
]
if frame_jank_info:
report_context["frame_timeline_jank"] = frame_jank_info
if callstack_hotspots:
report_context["callstack_chains"] = callstack_hotspots
sys.stderr.write(f"[Python 引擎层] [OK] 引擎数据剖分收官!已成功构建 JSON 特征,正向AI 引擎发起跨传...\n\n")
sys.stderr.flush()
print(json.dumps(report_context, ensure_ascii=False))
if __name__ == "__main__":
if len(sys.argv) != 3:
sys.stderr.write("用法: python3 2_trace_filter.py <perfetto-trace文件路径> <包名>\n")
sys.exit(1)
trace_path = sys.argv[1]
package_name = sys.argv[2]
sys.stderr.write(f"[Python 引擎层] 目标应用包名: {package_name}\n")
perform_deep_dive(trace_path, package_name=package_name)3_ai_reporter.sh --- 源码关联与智能报告生成器
这是全系统最高价值的环节。它从 2_trace_filter.py 的输出中提取出引发耗时的嫌疑类名,借助两种智能策略将本地真实代码片段组装至 AI 诊断引擎的特征上下文中。通过严格约束上下文,确保呈现给开发者的每一条性能优化方案都具备事实支撑。
两种源码关联策略:
| 策略 | 实现原理 | 覆盖场景 |
|---|---|---|
| 目标文件直搜 | 从 suspect_root_cause_methods 提取大驼峰类名,find 搜索 .kt/.java 文件 | 核心肇事业务类完整源码 |
| ViewBinding 布局反解析 | 检测代码中的 *Binding 类名,CamelCase → snake_case 找对应 XML | 如 UserProfileBinding → user_profile.xml |
为什么不追踪 import 依赖树?
Android 是高度耦合的组件网状架构,盲目追踪
import引入树会形成"雪球效应"------由一个组件扩散到全局上百个类,产出 2MB+ 的文本。这不仅会触发操作系统的参数长度限制(Argument list too long),更会严重稀释 AI 的判断力,导致其在噪音中产生幻觉。因此本方案坚持极简上下文------只上载事发现场的文件本体及其紧密关联的 UI 布局。
js
#!/bin/bash
# 3_ai_reporter.sh
TRACE_FILE=$1
TARGET_PACKAGE=$2
API_KEY="sk-fdb3477cded3403cb8196da9c8691696" # 请替换内部调用的网关授信 KEY
API_URL="https://api.deepseek.com/v1/chat/completions"
if [ -z "$TARGET_PACKAGE" ]; then
echo "[错误] 必须传入目标应用包名,无法进行 Trace 分析。"
exit 1
fi
JSON_CONTEXT=$(python3 2_trace_filter.py ${TRACE_FILE} ${TARGET_PACKAGE})
# 新增安全阻断:检查 Python 引擎是否正常退出
if [ $? -ne 0 ]; then
echo ""
echo "[错误] TraceSQL 分析引擎发生崩溃 (退出码 $?),流程强行阻断,终止向智谱层级发起无意义 API 调用。"
exit 1
fi
if [[ "$JSON_CONTEXT" == *"perfect"* ]]; then
echo "[中止信号] 运行正常,当前检测区间无过度时耗积压。"
exit 0
fi
if [ -z "$JSON_CONTEXT" ]; then
echo "[错误] 分析引擎未能返回任何有效特征 JSON,流程强行阻断。"
exit 1
fi
# AI 策略定义与限定
SYSTEM_PROMPT="你负责系统级底座性能卡顿原因的定位。
依赖 'thread_os_states' 认定导致卡死的原因分类,必须全面分析 'suspect_root_cause_methods' 中挖掘出的【所有】业务包名和特征节点,找出所有共同造成卡顿的组合因素,绝不可只单独分析占比最大的一个。
限定输出格式:你必须严格遵循以下大纲输出报告,绝对禁止生成"预期效果"、"验证方法"、"修改优先级"等废话,违背此限定将被判定为不合格:
### 1. 🔍 根因定责
**【肇事源码片段】**
\`\`\`kotlin/java
// 你必须在这里原封不动地精准摘抄贴出引发卡顿的那几行真实肇事代码!无代码段即视为不合格!
\`\`\`
**【深度硬核剖析】**
(在此详细硬核地剖析这几行代码为什么会慢,例如:这是锁竞争、主线程 I/O 还是繁重绘制?严禁只给空泛总结!)
### 2. 🛠️ 修复建议
**【重构后代码】**
\`\`\`kotlin/java
// 你必须基于真实源码,在这里直接写出修改和优化后的具体可执行代码块!
\`\`\`
(并在下方补充一段极简的修复原理解释)"
# [核心优化]: 智能反查本地原生代码并附带进 Prompt,防止 AI 对未知类库产生幻觉
RAW_NAMES=$(echo "$JSON_CONTEXT" | jq -r '(.suspect_root_cause_methods[]?) // empty, (.callstack_chains[]?.chain[]?) // empty' 2>/dev/null | grep -v '^null$')
echo ""
echo "====== [Debug] 源码关联流程开始 ======"
echo "[Debug 1] suspect_root_cause_methods 原始提取值:"
echo "$RAW_NAMES"
echo ""
# 智能提取策略升级:
# 1. 剔除系统库全限定名前缀 (android.* / java.* 等) 防止误判 View, LayoutInflater 等类名
# 2. 从剩余干净文本中精准抽离大驼峰业务类
# 3. 过滤绝大多数常见但毫无业务意义的 Android 系统类和基础结构词汇
CLEAN_NAMES=$(echo "$RAW_NAMES" | sed -E 's/\[APP\] |\[FWK\] //g' | sed -E 's/(android|com\.android|java|kotlin|androidx|org)\.[a-zA-Z0-9_.]+//g')
IGNORE_WORDS="Lock|Thread|Dispatch(er)?|DefaultDispatcher|MainDispatcher|System|String|Runnable|Choreographer|VRI|HWUI|ClassLinker|LayoutInflater|Monitor|Contention|Binder|Transaction|Handler"
IGNORE_WORDS="$IGNORE_WORDS|Window|View(Group)?|Activity(Thread|Manager)?|Fragment|Context|Intent|Bundle|Message(Queue)?|Looper|MeasureSpec|Canvas|Paint|Bitmap|Surface(Flinger)?|Render(Thread|Node)"
IGNORE_WORDS="$IGNORE_WORDS|Task|Worker|Coroutine|Event|Object|Math|Collections?|List|Map|Set|Array|Trace|Android|Java|Kotlin|JNI|GC|Alloc|Free|Main|UI|Layout|Draw|Measure|Inflate|Scroll|Fling"
IGNORE_WORDS="$IGNORE_WORDS|Recycler(View)?|Text(View)?|Image(View)?|Frame(Layout)?|Linear(Layout)?|Relative(Layout)?|Constraint(Layout)?|Animat(ion|or)"
CLASS_FILES=$(echo "$CLEAN_NAMES" | grep -oE '\b[A-Z][a-zA-Z0-9_]+\b' | sort | uniq | grep -vE "^($IGNORE_WORDS)$")
echo "[Debug 2] 从字符串中净化并剥离出的高度疑似业务类名列表:"
echo "$CLASS_FILES"
echo ""
CODE_CONTEXT=""
# [性能优化]: 从 O(N) 全局硬搜到 O(1) 预载缓存检索池的升维
# 针对动辄百万行级的多 Module Android 工程结构,我们大幅改造了原有的暴力遍历机制:
# 1. 在大盘扫描阶段仅花费极小开销执行**单次全盘抓取**,将文件结构存入本地索引库 (.file_cache)。
# 2. 【深度提速与净化】:强制修剪丢弃 `build/`、`.gradle/`、`.git/` 等包含海量中间产物(如 R.java、BuildConfig 文件)的垃圾目录树!这不仅避免了磁盘寻址假死,更阻断了大模型吃下非业务代码而产生的分析幻觉。
# 3. 后续循环仅对内存级文本文件做单纯的 `grep -E` 后缀匹配,查找耗时降至近乎零点。
echo "[Debug 3] 大盘预载:正在生成全局项目索引缓存库 (严格剔除 build 结构)..."
TMP_FILE_CACHE=$(mktemp)
find ../../ -type d \( -name "build" -o -name ".gradle" -o -name ".idea" -o -name ".git" \) -prune -o -type f \( -name "*.kt" -o -name "*.java" -o -name "*.xml" \) -print > "$TMP_FILE_CACHE"
for CLASS_FILE in $CLASS_FILES; do
echo "[Debug 3] 正在搜索: ${CLASS_FILE}.kt / ${CLASS_FILE}.java ..."
# 直接在文件列表缓存里秒级 grep 匹配,精准后缀名锚点
FILE_PATH=$(grep -E "/${CLASS_FILE}\.(kt|java)$" "$TMP_FILE_CACHE" | head -n 1)
if [ -n "$FILE_PATH" ]; then
echo "[Debug 4] [OK] 命中: $FILE_PATH"
# 读取目标文件完整内容
CODE_CONTEXT="$CODE_CONTEXT
=== [目标源文件] ${CLASS_FILE} ===
$(cat "$FILE_PATH")"
# --- 策略 2:ViewBinding 类名反解析 → 找对应 XML 布局文件 ---
# ViewBinding 类名规则:CamelCase → snake_case,如 ViewMomentContentBinding → view_moment_content.xml
BINDING_CLASSES=$(grep -oE '[A-Z][a-zA-Z]+Binding' "$FILE_PATH" | sort | uniq)
if [ -n "$BINDING_CLASSES" ]; then
echo "[Debug 6] 代码中检测到的 Binding 引用: $(echo $BINDING_CLASSES | tr '\n' ' ')"
fi
for BINDING in $BINDING_CLASSES; do
# 去掉 Binding 后缀,CamelCase 转 snake_case
LAYOUT=$(echo "${BINDING%Binding}" | sed 's/\([A-Z]\)/_\1/g' | sed 's/^_//' | tr '[:upper:]' '[:lower:]')
# 在缓存中精准搜索 layout 目录下的 xml
XML_PATH=$(grep -E "layout.*/${LAYOUT}\.xml$" "$TMP_FILE_CACHE" | head -n 1)
if [ -n "$XML_PATH" ]; then
echo "[Debug 6] + ViewBinding ${BINDING} → 附载布局文件: ${LAYOUT}.xml"
CODE_CONTEXT="$CODE_CONTEXT
=== [ViewBinding 关联布局] ${LAYOUT}.xml ===
$(cat "$XML_PATH")"
else
echo "[Debug 6] ~ ViewBinding ${BINDING} → 未找到布局文件: ${LAYOUT}.xml"
fi
done
# 兜底:补扫 R.layout.xxx 直接引用
LAYOUT_NAMES=$(grep -oE 'R\.layout\.[a-zA-Z0-9_]+' "$FILE_PATH" | awk -F'.' '{print $3}' | sort | uniq)
for LAYOUT in $LAYOUT_NAMES; do
XML_PATH=$(grep -E "layout.*/${LAYOUT}\.xml$" "$TMP_FILE_CACHE" | head -n 1)
if [ -n "$XML_PATH" ]; then
echo "[Debug 7] + R.layout 兜底 → 附载布局文件: ${LAYOUT}.xml"
CODE_CONTEXT="$CODE_CONTEXT
=== [R.layout 关联布局] ${LAYOUT}.xml ===
$(cat "$XML_PATH")"
fi
done
else
echo "[Debug 4] [WARN] 未找到: ${CLASS_FILE}.kt / ${CLASS_FILE}.java"
fi
done
rm -f "$TMP_FILE_CACHE"
echo ""
echo "[Debug 6] CODE_CONTEXT 总字符长度: ${#CODE_CONTEXT}"
if [ -n "$CODE_CONTEXT" ]; then
SYSTEM_PROMPT="$SYSTEM_PROMPT
【重要约束:以下是依据 Trace 抓取到的嫌疑节点所对齐的真实项目原生代码(含同包关联文件)。你的性能分析诊断请务必严格基于、并且只基于这些真实代码!绝对不要在没有任何代码支撑的情况下脱空臆想原因!】$CODE_CONTEXT"
echo "[Debug 7] [OK] 源码已注入至 SYSTEM_PROMPT,当前 Prompt 总字符数: ${#SYSTEM_PROMPT}"
else
echo "[Debug 7] [WARN] CODE_CONTEXT 为空,未解析到任何源文件,AI 引擎将无代码支撑直接分析。"
fi
echo "============================="
echo ""
# 生成临时文件传递海量 Prompt 和最终的 JSON Payload,彻底绕过 bash 参数长度限制
TMP_SYS=$(mktemp)
echo "$SYSTEM_PROMPT" > "$TMP_SYS"
TMP_PAYLOAD=$(mktemp)
jq -n --rawfile sys "$TMP_SYS" --arg usr "$JSON_CONTEXT" \
'{
model: "deepseek-chat",
messages: [
{role: "system", "content": $sys},
{role: "user", "content": $usr}
],
temperature: 0.1
}' > "$TMP_PAYLOAD"
rm -f "$TMP_SYS"
AI_ADVICE=$(curl -s -X POST $API_URL \
-H "Content-Type: application/json" \
-H "Authorization: Bearer $API_KEY" \
-d @"$TMP_PAYLOAD" | jq -r 'if .choices then .choices[0].message.content else "推送服务被拒: \(.error.message)" end')
rm -f "$TMP_PAYLOAD"
REPORT_NAME="ai_performance_insight_$(date +%Y%m%d_%H%M%S).md"
echo "# 系统性能推演断裂溯源简报" > $REPORT_NAME
echo "> *节点构建生成于: $(date +"%Y-%m-%d %H:%M:%S")*" >> $REPORT_NAME
echo "" >> $REPORT_NAME
echo "## 一、 降阶核心 SQL Trace 元信息提取集" >> $REPORT_NAME
echo "\`\`\`json" >> $REPORT_NAME
echo "$JSON_CONTEXT" | jq . >> $REPORT_NAME
echo "\`\`\`" >> $REPORT_NAME
echo "" >> $REPORT_NAME
echo "## 二、 AI 系统层分析结论指令" >> $REPORT_NAME
echo "$AI_ADVICE" >> $REPORT_NAME
echo "[报告完备] 性能检测归档落地完毕,路径向指: ./${REPORT_NAME}"run_profiler.sh --- 一键自动化串联脚手架
该脚手架旨在将原本需人工分别执行的取样、清洗、智能报告生成三个阶段进行一体化串联。作为开发者最常用的本地调用入口文件。
bash
#!/bin/bash
# ============================================================================
# run_profiler.sh --- 一键自动化诊断入口
# ============================================================================
TARGET_PACKAGE="${1:-}"
if [ -z "$TARGET_PACKAGE" ]; then
echo "[错误] 必须传入目标应用包名。"
echo " 用法: ./run_profiler.sh <包名>"
exit 1
fi
echo "========================================="
echo " >>> AI 性能卡顿自动化诊断管线启动"
echo "========================================="
echo ""
echo "[目标应用] $TARGET_PACKAGE"
echo "[采集模式] 定向采集 --- Callstack Sampling 仅采集该应用线程"
echo ""
# 1. 样本采集阶段
echo "[1/3] 执行真机采样环境检查..."
bash 1_ai_sampler.sh $TARGET_PACKAGE
if [ $? -ne 0 ]; then
echo "[ERROR] 采样阶段中断,请检查设备连接或权限。"
exit 1
fi
TRACE_FILE="temp_issue.perfetto-trace"
if [ ! -f "$TRACE_FILE" ]; then
echo "[ERROR] 未能获取到底层记录文件: $TRACE_FILE"
exit 1
fi
echo "[OK] 采样文件已锁定。"
echo ""
# 2 & 3. 关联与会诊阶段(内嵌调用)
echo "[2/3 & 3/3] 正唤起核心计算引擎与智能分析..."
bash 3_ai_reporter.sh "$TRACE_FILE" "$TARGET_PACKAGE"使用方法
自动化一键执行
bash
cd tools/ai_profiler/
./run_profiler.sh com.luck.pictureselector分步执行
perl
# 步骤 1:采集 Trace(必须传入包名)
bash 1_ai_sampler.sh com.luck.pictureselector
# 采集完成后会生成 temp_issue.perfetto-trace 文件
# 步骤 2:基于已有 Trace 文件直接分析
# 经过重构,只需要向底层分析引擎传入包名即可自动处理
python3 2_trace_filter.py temp_issue.perfetto-trace com.luck.pictureselector
# 步骤 3:生成 AI 报告(传入 trace 文件与目标包名)
bash 3_ai_reporter.sh temp_issue.perfetto-trace com.luck.pictureselector
# 步骤 4:查看报告
open ai_performance_insight_*.md验证源码关联是否生效
执行时观察终端输出的 Debug 日志:
ini
[Debug 4] [OK] 命中: ../../moment/.../MomentContentView.kt
[Debug 5] + 附载 import 源文件: MomentViewModel
[Debug 6] + ViewBinding ViewMomentContentBinding → 附载布局文件: view_moment_content.xml
[Debug 7] [OK] 源码已注入至 SYSTEM_PROMPT,当前 Prompt 总字符数: 28456若 [Debug 7] 显示 [OK] 且字符数明显大于 500(基础 Prompt 长度),说明源码已成功注入。
真实运行效果展示
经过强约束模板调优后,即使是复杂的嵌套布局或第三方列表滑动卡顿,AI 引擎也能精准输出肇事源码片段与针对性修改建议:
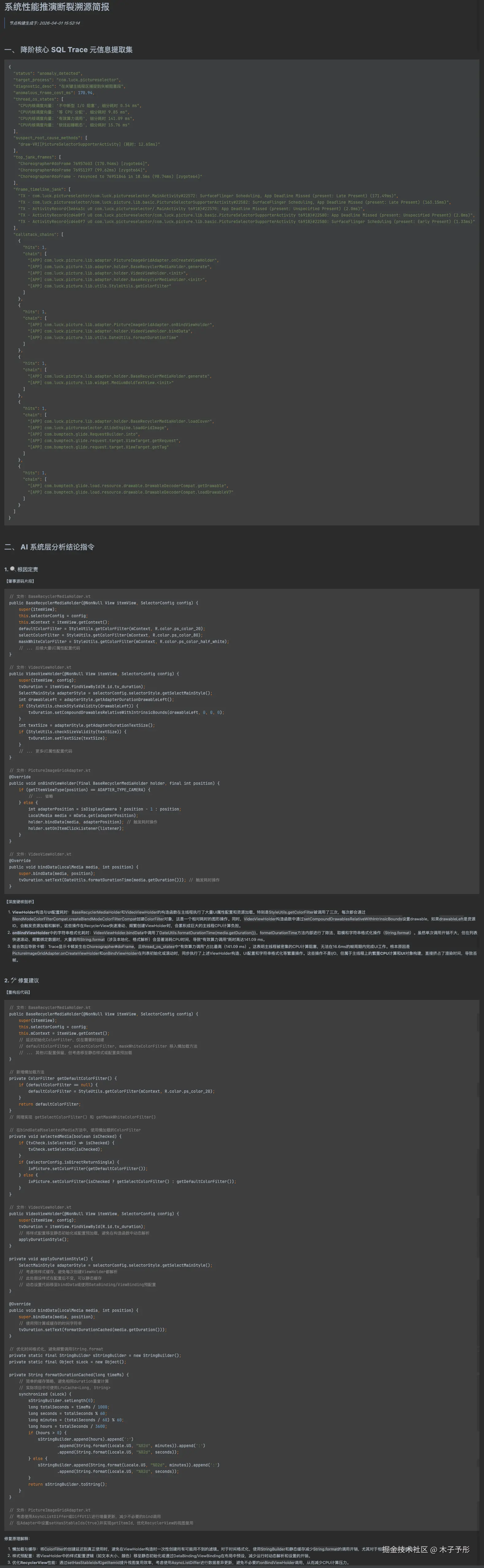
总结
本方案通过 自动化降噪 与 源码强制锚定 从本质上解决了性能诊断的效率难题:
- 工程提效:利用精准的 SQL 过滤替代繁复的人工看帧,将海量 Perfetto 调度事件降维提取为结构化根因特征。
- 源码防幻觉:向智能诊断引擎同步注入实际发生问题的关联源码,强制束缚其推理范围,使得输出的优化建议精准且开箱即用。
边界与展望 : 尽管该管线无法完全替代宏观视角的 Android Studio Profiler,且其内部 SQL 规则亦需伴随业务发展而持续演进。但面对日常工作中最拉低团队效能的 "UI 主线程卡顿" 问题,它以极低的使用门槛实现了分钟级、代码级的快速定责。