一、bert模型介绍
BERT(Bidirectional Encoder Representations from Transformers)是由 Google 于 2018 年提出的一种语言预训练模型。其核心创新在于采用 Transformer 的编码器(Encoder)结构,通过双向自注意力机制,在建模每个 token 表示时同时整合左右两个方向的上下文信息,从而获得更准确、更丰富的语义表示。
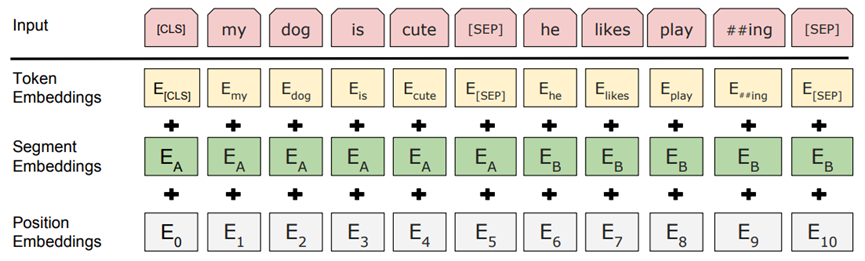
BERT 的每个输入 token 表示由三部分嵌入相加组成:
- Token Embedding:词本身的语义表示;
- Position Embedding:表示 token 在序列中的位置,为可学习向量;
- Segment Embedding:用于区分句子对任务中的两个句子,分别用一个可学习的向量表示。
如下图所示:
此外,BERT 输入中通常包含两个特殊符号:
CLS:句首标志,其输出向量常用于下游的文本分类任务;
SEP:句间分隔符,出现在每个句子末尾。
BERT 的预训练阶段包含两个核心任务:掩码语言模型( Masked Language Modeling, MLM ) 和 下一句预测(Next Sentence Prediction, NSP ),分别用于学习词级语义和句间逻辑关系。
1.掩码语言模型( Masked Language Modeling, MLM )
为实现双向语言建模,BERT 不采用传统的从左到右或从右到左预测方式,而是引入了掩码语言模型。在训练中,BERT 会随机遮盖输入序列中约 15% 的 token,并训练模型根据上下文预测被遮盖的词。
遮盖策略如下:
- 80% 的被遮盖 token 替换为 MASK;
- 10% 替换为随机词;
- 10% 保持原词不变。
这种机制让模型在预训练时既能看到左侧上下文,也能看到右侧上下文,真正实现深度双向建模。

2.下一句预测(Next Sentence Prediction, NSP )
为了提升模型理解句间关系的能力,BERT 引入了"下一句预测"任务。训练时模型接收两个句子,判断第二句是否是第一句的真实后续句,其中:
50% 的训练样本是上下文中真实相邻的句子(正例);
50% 是从语料中随机采样的非相邻句子(反例)。
二、微调
BERT 的输入格式在微调阶段基本保持与预训练一致,仍以 token 序列为输入,使用 CLS 和 SEP 等特殊符号。不同任务的差异主要体现在输出层设计,以及从模型输出中提取哪些表示进行预测。
下面分别介绍 BERT 在四类典型任务中的微调方式:
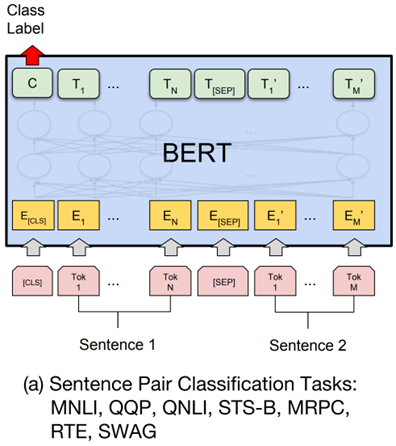
(a) 句子对分类任务
输入格式:CLS 句子1 SEP 句子2 SEP
输出方式:使用 CLS 的输出向量接入线性层进行分类,用于判断两个句子之间是否存在重复、蕴含、矛盾等关系。
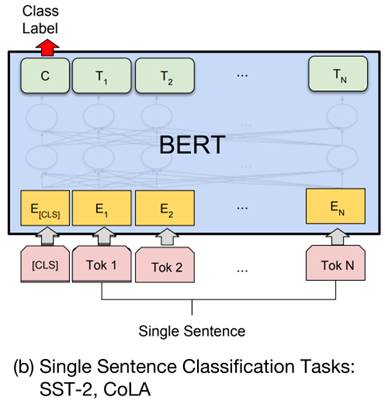
(b) 单句分类任务
输入格式:CLS 句子 SEP
输出方式:同样使用 CLS 的输出向量,经过线性层用于情感极性判断、语法可接受性判断等。
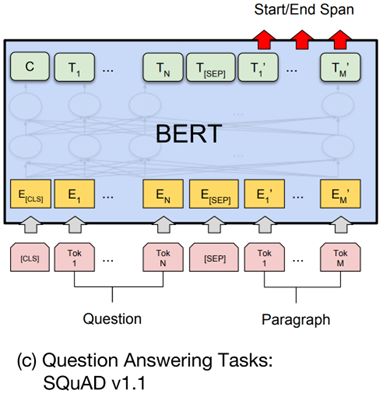
(c) 问答任务
输入格式:CLS 问题 SEP 段落 SEP
输出方式: 模型不会使用 CLS 向量,而是对每个 token 分别预测其作为答案起始位置和结束位置的概率。最终根据得分确定答案在段落中的位置范围,从中直接抽取连续的答案文本。
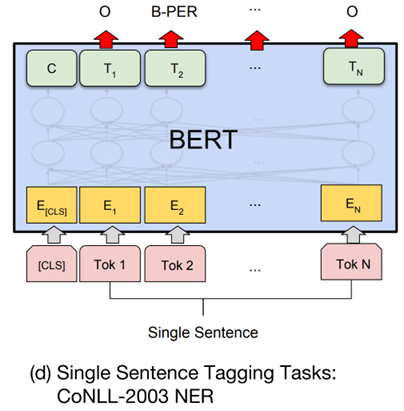
(d) 序列标注任务
输入格式:CLS 句子 SEP
输出方式:对每个 token 的输出向量单独进行分类,例如判断是否为人名(B-PER)、地名(B-LOC)等。
三、GPT
GPT(Generative Pre-trained Transformer)是第一个系统性提出**"预训练 + 微调"**范式的语言模型。
其核心思想是通过大规模无监督语料进行生成式语言建模预训练 ,即训练模型根据左侧上下文预测下一个词,从而让模型学习自然语言的通用语法、语义和上下文依赖能力。完成预训练后,再通过微调适应具体的下游任务。
GPT首次展示了生成式语言模型在自然语言理解任务中的广泛迁移能力,为后续 GPT 系列及整个预训练语言模型的发展奠定了基础。
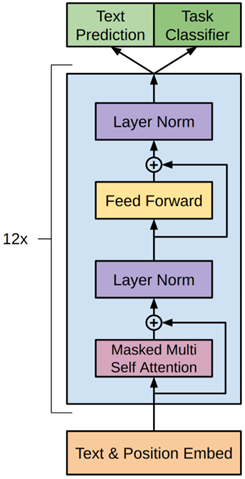
GPT基于Transformer的解码器结构,但与标准的Transformer解码器并不完全相同,GPT具体结构如下图所示:
与原始Transformer一样,每个输入 token 的表示也由两部分组成:
- Text Embedding:将词或子词映射为向量;
- Position Embedding:提供词在序列中的位置信息。
GPT不同于原始Transformer的一点在于:位置编码采用的是可学习的位置嵌入(learnable positional embedding)。这意味着每个位置对应一个可训练的向量,模型可以在训练过程中自动优化这些向量,而非使用不可训练的三角函数编码(如正弦/余弦函数)。
每个token的最终表示是词嵌入与位置嵌入的向量和,向量维度为 768。
解码器部分由12个结构相同的解码器层堆叠而成,每个解码器层只包含如下两个子层:
- 掩码多头自注意力(12 头)
- 前馈网络
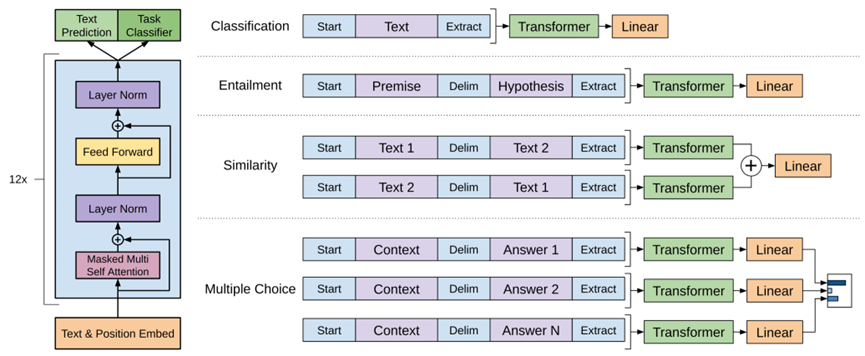
微调:
四、项目架构
本质上就是基于bert做了一个多分类问题:
也就是用户给了一个标题,然后预测其所属的分类
整体流程
原始数据(TSV) → 预处理 → BERT编码 → 训练分类器 → 保存模型 → 推理/Web服务1. 数据准备
原始数据是 TSV 格式,两列:text_a(商品标题)和 label(类别名)。
process.py 做了三件事:
- 用 BERT tokenizer 把文本转成
input_ids+attention_mask - 把字符串类别转成数字 id(
ClassLabel) - 保存为 HuggingFace Dataset 格式
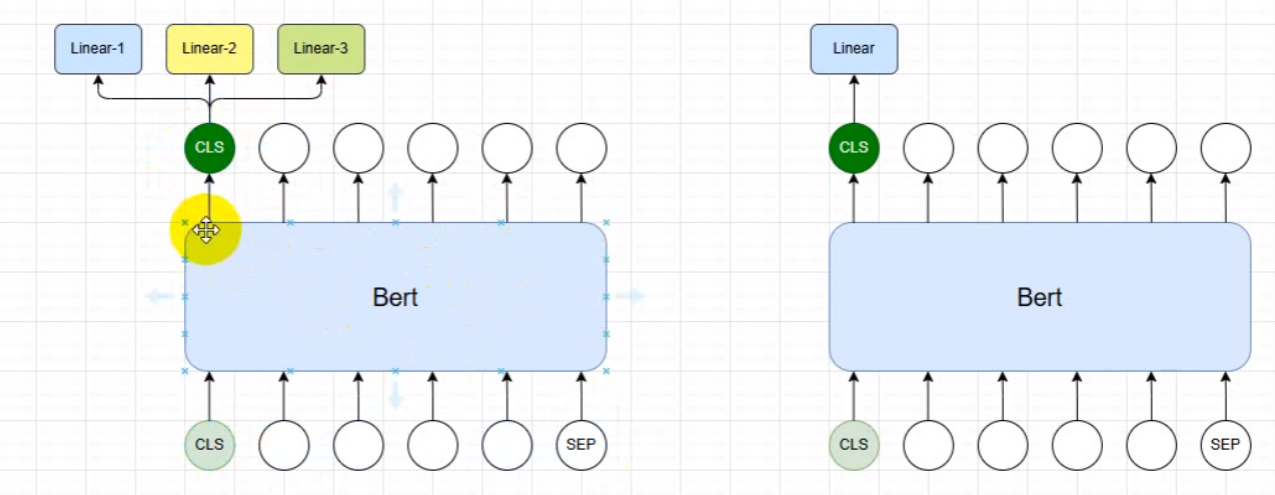
2. 模型结构
商品标题文本
↓ tokenizer
[CLS] 手 机 壳 苹 果 ... [SEP] [PAD]
↓ BERT(冻结参数,只做特征提取)
每个token的向量表示 [batch, seq_len, 768]
↓ 取第0位 CLS token
[batch, 768] ← 代表整句话的语义
↓ 线性层 Linear(768 → 30)
[batch, 30] ← 30个类别的得分关键设计:freeze_bert=True 冻结了 BERT 的所有参数,只训练最后的线性层。这样训练快、不容易过拟合,适合数据量不大的场景。
3. 训练
- 损失函数:CrossEntropyLoss
- 优化器:AdamW,学习率 1e-5
- 早停:验证集损失连续 2 轮不下降就停止,保存最佳模型为
best.pt - FP16 混合精度加速训练
4. 推理
用户输入 "苹果手机壳透明软壳"
↓ tokenizer 编码
↓ 模型前向传播
↓ argmax 取最大得分的类别 id(如 15)
↓ int2str 转回类别名(如 "手机配件")
↓ 输出结果5. Web 服务
FastAPI 提供 /predict 接口,前端页面输入商品标题,POST 请求返回分类结果。service.py 在启动时就把模型加载好,避免每次请求重新加载。
核心思想
BERT 是在海量中文语料上预训练的,已经理解了中文语义。这里只需要在它的输出上加一个线性层,用少量商品数据微调,就能让它学会区分 30 种商品类别。这就是迁移学习的核心价值。