一、什么是内存池
内存池是一种内存管理技术,在程序启动时预先分配一大块内存,然后由程序自己管理这块内存的分配和释放,而不是每次都向操作系统申请。
二、为什么要用内存池
使用内存池主要是为了解决频繁动态分配小对象时的性能问题。传统的 new 和 delete 每次都会触发系统调用,开销大且容易产生内存碎片,导致 CPU 缓存命中率下降。而内存池预先申请一大块连续内存,在用户态自行管理分配,分配操作仅需移动链表指针,速度可提升数十倍。同时,固定大小的块消除了外部碎片,连续的内存布局也显著提高了缓存友好性,特别适合游戏粒子系统、网络连接等高频创建销毁小对象的场景。
三、内存池的原理
内存池一般采用**分层存储结构,**由多个固定大小的内存页(Page)组成,使用数组或者链表存储这些页,每个页还可以分成多个内存块(Block),内存块一般采用空闲链表存储,通过从头节点取出来分配内存,通过头插法重新插入空闲链表来回收内存。
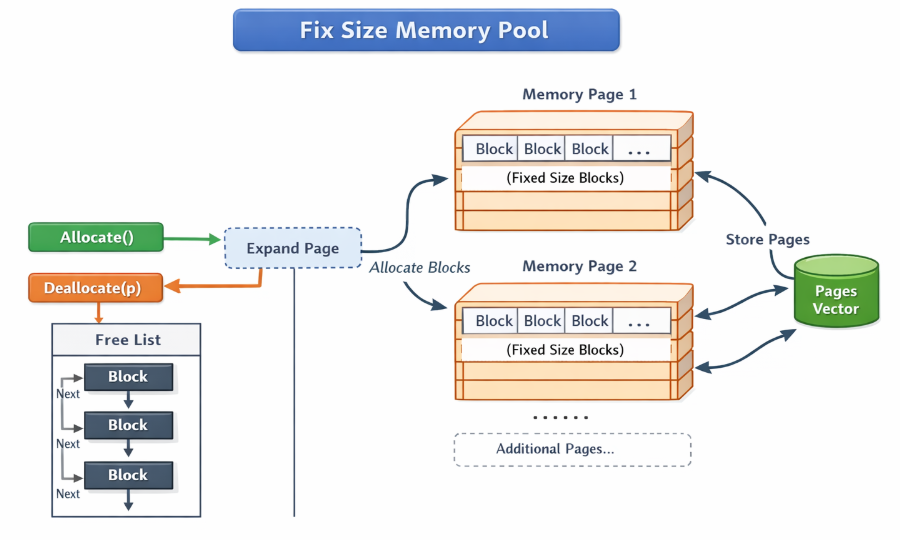
上面这张架构图展示的就是下面设计的一个定长内存池的整体工作机制,系统通过一次性申请较大的连续内存块(称为内存页),再将其按固定大小切分成多个小块(block),所有空闲块通过单链表(free list)串联起来进行统一管理;当调用 allocate() 时,直接从空闲链表头部取出一个块返回,如果链表为空则触发 expand_page() 新分配一页内存并切分补充到链表中,而在 deallocate() 时则将释放的内存块重新挂回链表头,实现内存的循环复用,同时所有分配过的内存页由一个数组集中管理以便最终统一释放,这种设计避免了频繁的系统级内存申请与释放,使得内存分配与回收都能在常数时间内完成,从而显著提升性能与效率。
struct Node { Node* next; }; //空闲链表结点 std::size_t block_size; //块大小 std::size_t block_per_pages; //每页分的块数 Node* free_list; //空闲链表 std::vector<void*> pages; //数组存储页
当空闲链表为空时,申请大块内存页并进行分块,然后把内存块加入到空闲链表中。
void expand_page() { std::size_t page_size = block_size * block_per_pages; char* page = new char[page_size]; // 分配内存页 pages.push_back(page); // 将页切分成块并加入空闲链表 for (std::size_t i = 0; i < block_per_pages; i++) { char* addr = page + i * block_size; Node* node = reinterpret_cast<Node*>(addr); node->next = free_list; free_list = node; } }
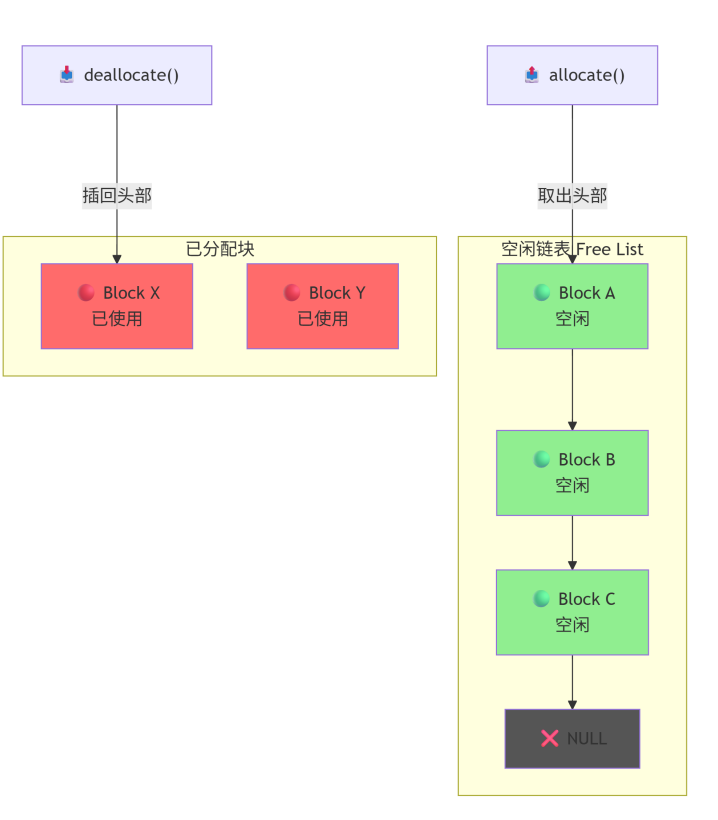
申请内存时,需要判断空闲链表是否为空,然后返回空闲链表的头节点,转移头节点指针指向。回收内存时,需判断对象/资源是否为空,防止重复释放,创建结点接收内存,通过头插法插入到空闲链表中。
void* allocate() { if (!free_list) { expand_page(); } Node* head = free_list; free_list = head->next; return head; } void deallocate(void* p) { if (!p) return; Node* node = static_cast<Node*>(p); node->next = free_list; free_list = node; }
此外,还需要保证最小内存块的大小,因为要加入到空闲链表,最起码要有一个指针的大小,即sizeof(Node*),并保证内存对齐。向上取整内存对齐算法,请查看这篇博客:内存对齐算法:向上取整到位运算-CSDN博客![]() https://blog.csdn.net/qq_32484211/article/details/159800389
https://blog.csdn.net/qq_32484211/article/details/159800389
//实现内存对齐 static inline std::size_t align_up(std::size_t size, std::size_t alignment) { return (size + alignment - 1) & ~(alignment - 1); }
//保证最小内存块的大小 std::size_t adjust_block_size(std::size_t size) { if (size < sizeof(Node*)) { return align_up(sizeof(Node*), sizeof(Node*)); } return align_up(size, sizeof(Node*)); }
四、代码整体实现
cpp
#include <iostream>
#include <vector>
#include <cassert>
using namespace std;
//实现内存对齐
static inline std::size_t align_up(std::size_t size, std::size_t alignment) {
return (size + alignment - 1) & ~(alignment - 1);
}
class Fix_size_Pool {
public:
explicit Fix_size_Pool(std::size_t block_size, std::size_t block_per_pages) {
this->block_size = adjust_block_size(block_size);
this->block_per_pages = block_per_pages;
this->free_list = nullptr;
}
~Fix_size_Pool() {
// 释放所有分配的内存页
for (void* page : pages) {
delete[] static_cast<char*>(page);
}
}
void* allocate() {
if (!free_list) {
expand_page();
}
Node* head = free_list;
free_list = head->next;
return head;
}
void deallocate(void* p) {
if (!p) return;
Node* node = static_cast<Node*>(p);
node->next = free_list;
free_list = node;
}
std::size_t get_block_size() const { return block_size; }
std::size_t get_block_per_pages() const { return block_per_pages; }
private:
std::size_t adjust_block_size(std::size_t size) {
if (size < sizeof(Node*)) {
return align_up(sizeof(Node*), sizeof(Node*));
}
return align_up(size, sizeof(Node*));
}
void expand_page() {
std::size_t page_size = block_size * block_per_pages;
char* page = new char[page_size]; // 分配内存页
pages.push_back(page);
// 将页切分成块并加入空闲链表
for (std::size_t i = 0; i < block_per_pages; i++) {
char* addr = page + i * block_size;
Node* node = reinterpret_cast<Node*>(addr);
node->next = free_list;
free_list = node;
}
}
struct Node {
Node* next;
};
std::size_t block_size;
std::size_t block_per_pages;
Node* free_list;
std::vector<void*> pages;
};
// 测试结构体(假设用于测试分配的对象)
struct Test {
double x, y, z;
int life;
// 自定义构造函数
Test(double a, double b, double c, int l) : x(a), y(b), z(c), life(l) {
std::cout << "Test Build Function: " << life << std::endl;
}
// 自定义析构函数
~Test() {
std::cout << "Test ~Build Function: " << life << std::endl;
}
};
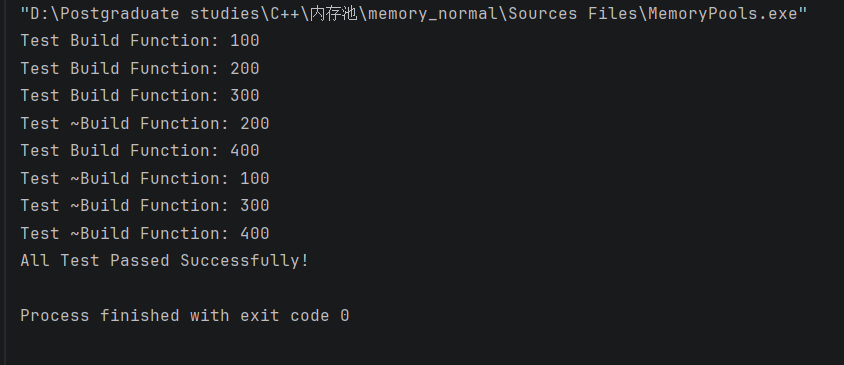
int main() {
Fix_size_Pool pool(32, 10);
assert(pool.get_block_size() == 32);
assert(pool.get_block_per_pages() == 10);
// ========== 正确构造对象 ==========
// 1. 分配裸内存
void* raw1 = pool.allocate();
// 2. placement new 构造对象
Test* t1 = new (raw1) Test(1.0, 2.0, 3.0, 100);
void* raw2 = pool.allocate();
Test* t2 = new (raw2) Test(4.0, 5.0, 6.0, 200);
void* raw3 = pool.allocate();
Test* t3 = new (raw3) Test(7.0, 8.0, 9.0, 300);
// 验证数据
assert(t1->life == 100);
assert(t2->life == 200);
assert(t3->life == 300);
// ========== 正确析构+释放内存 ==========
// 先析构,再归还内存
t2->~Test();
pool.deallocate(t2);
// 复用内存:分配的是t2的块,重新构造
void* raw4 = pool.allocate();
Test* t4 = new (raw4) Test(10.0, 11.0, 12.0, 400);
assert(t4->life == 400);
// 释放剩余对象
t1->~Test();
pool.deallocate(t1);
t3->~Test();
pool.deallocate(t3);
t4->~Test();
pool.deallocate(t4);
std::cout << "All Test Passed Successfully!" << std::endl;
return 0;
}
五、后续优化(面试问答)
1.这个内存池在多线程环境下安全吗?怎么改进?
当前实现是线程不安全的 ,因为 free_list 是共享链表,allocate() 和 deallocate() 都会修改它,如果多个线程同时操作,会产生数据竞争甚至链表损坏。
改进方案有三种层次:最简单的是加一个全局 std::mutex,但会导致严重锁竞争;更好的方式是使用线程局部缓存(Thread Local Pool) ,每个线程维护自己的 free_list,减少竞争,线程分配时,优先从自己的本地池拿,本地不够时,再从全局中心池批量取;还可以用无锁结构(lock-free stack) ,不使用 mutex,而是用 CPU 原子指令 CAS(Compare And Swap) 实现 free_list 的原子插入、删除,把整个空闲链表变成无锁栈。
2.这个内存池有没有内存对齐问题?
是有潜在风险的。当前通过 align_up(size, sizeof(Node*)) 做了基本对齐,但这只保证了指针对齐 ,并不能满足更高要求(比如 16 字节 SIMD 对齐或 cache line 对齐)。更严谨的做法是使用 std::max_align_t 或 std::align 来保证通用对齐,甚至可以让用户传入对齐参数;如果用于高性能场景(如游戏引擎),还可以按 cache line(通常64字节)对齐,避免 false sharing。
3.如果用户申请的对象大小不一致怎么办?
如果用户申请的对象大小不一致怎么办?如果支持不同大小,就需要做成多级内存池(类似 slab allocator):维护多个 pool,每个 pool 管理一种 block size(比如 16B、32B、64B...),分配时选择最接近的池,这样可以在减少碎片的同时保持高性能。这也是像 jemalloc / tcmalloc 的核心思想之一。
4.这个实现会不会产生内存浪费?
会,主要是内部碎片 。比如用户只需要 20 字节,但 block_size 是 32 字节,那么多余的 12 字节就是浪费。解决办法就是刚才说的分级内存池,或者允许用户自定义 block_size;另外也可以做"对象池"而不是"内存池",专门服务某一种对象类型。
5.如果 free_list 为空就扩容,那会不会无限增长?
是的,目前实现只扩不缩 ,如果程序在某一阶段大量申请内存,之后即使释放,内存页仍然保留在 pages 中,会导致内存占用持续偏高。改进方式是引入页级回收机制:记录每一页中空闲块数量,当一整页全部空闲时,可以释放该页。
6.free_list 用头插法有什么问题?
头插法是 O(1),但会导致热点复用 :刚释放的 block 很可能马上又被分配,容易造成 cache 行反复竞争。在多线程下可能加剧 false sharing。优化方法可以是:使用 FIFO(队列),或分段 free_list(冷热分离),使用热链表(hot_list)存放刚释放、还在 CPU 缓存里 的内存块 → 分配优先从这里拿,冷链表(cold_list)存放很久没使用、已被换出 CPU 缓存的内存块 → 热空了才从冷链表搬运。
7.这个内存池和 malloc 比优势在哪里?
速度快,减少了系统调用,减少了外部内存碎片。
它通过预分配连续内存页和空闲链表实现了 O (1) 的快速分配与释放,避免了通用 malloc 在查找适配块、切割内存、合并碎片及全局锁竞争上的大量开销,有效减少了外部内存碎片,让内存布局更规整、CPU 缓存局部性更优。