四、什么是损失函数**(Loss Function)**
损失函数(Loss Function)衡量单个样本的预测误差,即模型的预测值与真实值之间的差异。
成本函数/代价函数(Cost Function)衡量所有样本上预测值和真实值的平均误差。
目标函数(Objective Function) 是模型在训练过程中要最大化或最小化的函数,在机器学习里通常指的是成本函数+正则化项。
补充:很多人对损失函数、成本函数的区分并不严格,可以等同。
五、常见的损失函数
损失函数就像批阅试卷的时候扣分的规则,目的是衡量模型给出的结果和实际的结果之间的差距,差距越小说明这时候模型表现越好,而这个差距有很多种衡量方式。
5.1 均方误差(Mean Square Error, MSE)
预测值与真实值之差的平方 ,常用于回归 问题。设预测值是 ,真实值是
,误差 L 的定义如下:
5.2 平均绝对误差(Mean Absolute Error, MAE)
预测值与真实值之差的绝对值 ,常用于回归问题。
5.3 交叉熵损失(Cross-Entropy Loss)
预测概率分布与真实分布的差距,常用于分类问题。这个损失要稍微复杂一点,我们慢慢看:首先对于二分类问题,真实值有两种情况,要么是 1 要么是 0 ,假设问题是判断是不是小猫,这时候是小猫的标签为 1 ,对于一个实际上就是小猫的输入,模型给出的预测值 p (是小猫的概率)越接近 1 损失应该更小,越接近 0 损失应该越大,刚好下面这个图中的 -log(p) 函数就非常符合我们的需求。
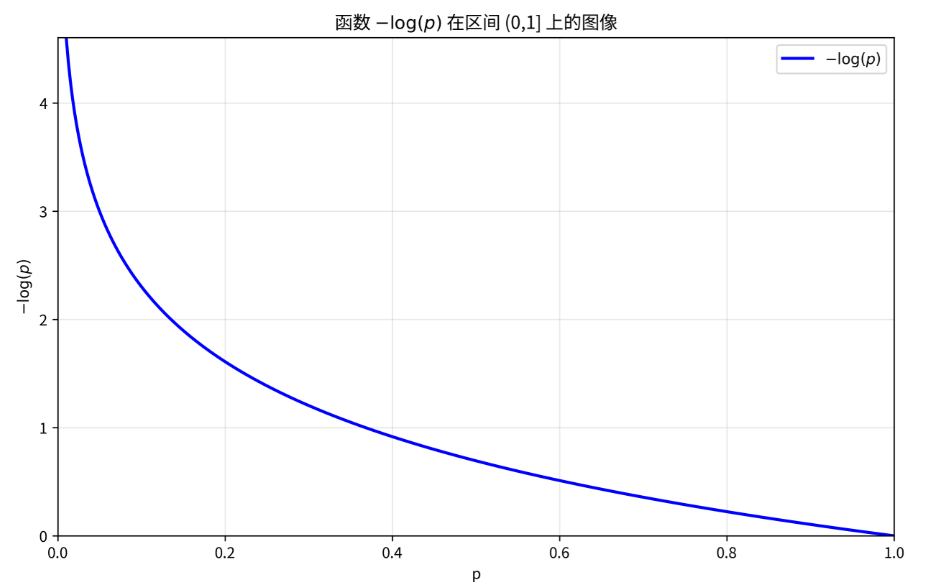
注意这里的 log 默认是以 e 为底的,机器学习中通常用 e 为底,Python 的 numpy 库中 np.log() 函数默认计算的也是自然对数。
但如果实际上不是小猫,模型给出的结果 1-p (不是小猫的概率)应该越接近 1 损失越小,也就是把上面那种情况的 p 换成了 1-p,损失应该是 -log(1-p)。把两种情况结合起来,就得到了下面这个很巧妙的交叉熵损失:
其中 p 是模型预测为正类的概率。可以分别代入 y = 1 及 y = 0 的情况,得到的就是上面的-log(p) 和 -log(1-p)。
有了损失函数,我们就可以明确机器学习的目标,怎么尽快让这个目标最小 就是梯度下降,这里内容有点多,放下一节了。