目录
Redis中常用数据类型:string(字符串)、hash(哈希)、list(列表)、set(集合)、Sorted set(有序集合)
特殊数据类型:stream(流)、Bitmaps(位图)、Bitfields(位域)HyperLogLogs(超日志)、Geospatial(地理空间)
上述这些数据类型,都是Redis提供给外部的数据类型。Redis底层在实现上述数据结构的时候,会在源码层面,针对上述实现进行特点的优化,来达到节省时间/空间的效果。
比如:hash表,插入、查询、删除操作的时间复杂度都是O(1),redis在底层实现hash表时不一定采用hash表,可能在特定的场景下,使用别的数据结构,但是仍然保证时间复杂度为O(1)。
redis中所有的key都是字符串,只有value的类型是存在差异的。
从redis3.2开始,引入了新的实现list的方式quicklist,兼顾了linkedlist和ziplist两者的优点。
在命令行可以输入object encoding key来查看key对应的value的实际编码方式。
String(字符串)
Redis中的字符串,直接就是按照二进制数据的方式存储的。(不会做任何编码转换,存的是啥,取出来还是啥)
Redis对于string类型,限制了大小最大是512M。
常见命令
SET
将string类型的value设置到key中。如果key之前存在,则覆盖,无论原来的数据类型是什么。之前关于此key的TTL也全部失效。
Set key value [EX seconds|PX millseconds][NX|XX]
选项:
EX seconds:使用秒作为单位设置key的过期时间。
PX millseconds:使用毫秒作为单位设置key的过期时间。
NX:表示如果key不存在,才会设置,如果key存在,就不设置返回nil。
XX:表示key存在,才设置(相当于更新key的value),如果不存在就不设置返回nil
SETNX=带选项NX的set
SETEX=带选项EX的set
PSETEX=带选项PX的set时间复杂度O(1)。成功返回OK,失败返回nil。
GET
获取key对应的value。如果key不存在,返回nil。如果value的数据类型不是string,会报错。
get key时间复杂度O(1)。返回key对应的value,或者nil。
MGET
一次性获取多个key的值。如果对应的key不存在或者对应的数据类型不是string,返回nil。
Redis要在get的基础上设置mget这一类命令的原因在上一章中已经叙述。
mget key [key ...]时间复杂度O(N),N表示的是命令中输入的key的数量。返回value对应的列表。
MSET
一次性设置多个key的值。
mset key value [key value ...]时间复杂度O(N),N是key的数量。返回值永远是OK。
计数命令
INCR
将key对应的string表示的数字+1。如果key不存在,则视为key对应的value是0.如果key对应的string不是一个整形或者范围超过了64为有符号整数,则报错。
incr key时间复杂度O(1)。返回integer类型的加完后的数值。
INCRBY
将key对应的string表示的数字加上对应的值。如果key不存在,则视为key对应的value是0。如果key对应的string不是一个整形或者范围超过了64位有符号整形,则报错。
incrby key increment时间复杂度O(1)。返回integer类型的加完后的数值。
DECR
将key对应的string表示数字减1。如果key不存在,则视为key对应的value是0。如果key对应的string不是一个整形或者范围超过了64位有符号整形,则报错。
decr key时间复杂度O(1)。返回integer类型的减完后的数值。
DECRBY
将key对应的string表示的数字减去对应的值。如果key不存在,则视为key对应的value是0。如 果key对应的string不是⼀个整型或者范围超过了64位有符号整型,则报错。
decrby key decrement时间复杂度O(1)。返回integer类型的减完后的数值。
INCRBYFLOAT
将key对应的string表⽰的浮点数加上对应的值。如果对应的值是负数,则视为减去对应的值。如果 key 不存在,则视为key对应的value是0。如果key对应的不是string,或者不是⼀个浮点数,则报 错。允许采⽤科学计数法表⽰浮点数。
incrbyfloat key increment时间复杂度O(1)。返回加/减完后的值。
其他命令
APPEND
如果key已经存在并且是⼀个string,命令会将value追加到原有string的后边。如果key不存在, 则效果等同于SET命令。
append key value时间复杂度O(1)。返回追加完成后string的长度。
GETRANGE
返回key对应的string的⼦串,由start和end确定(左闭右闭)。可以使⽤负数表⽰倒数。-1代表 倒数第⼀个字符,-2代表倒数第⼆个,其他的与此类似。超过范围的偏移量会根据string的⻓度调整 成正确的值。
getrange key start end时间复杂度O(N),N为start,end区间的长度,由于string通常比较短,可以视为O(1)。
SETRANGE
覆盖字符串的⼀部分,从指定的偏移开始。
setrange key offset value时间复杂度O(N),N为value的长度,由于一般给的value比较短,通常视为O(1)。返回替换后的string的长度。
STRLEN
获取key对应的string的⻓度。当key存放的类似不是string时,报错。
strlen key时间复杂度O(1)。返回string的长度,或者当key不存在时,返回0。
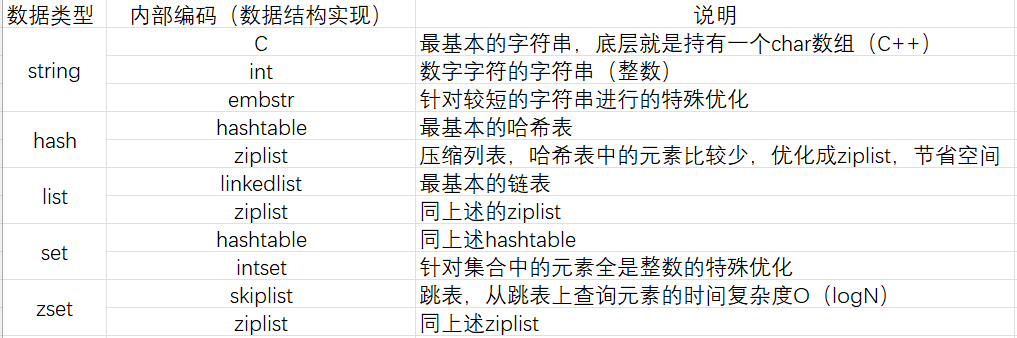
内部的编码
字符串类型的三种内部编码:
int:8字节的长整型
embstr:小于等于39字节的字符串
raw:大于39字节的字符串
redis会根据当前值的类型和长度动态决定使用哪种内部编码实现。
适用场景
-
缓存(Cache):加速读写,降低后端(如 MySQL)压力,支撑高并发访问。
-
计数(Counter):快速实现计数与查询,如视频播放次数自增,可异步落地。
-
共享会话(Session):分布式服务中集中存储用户登录信息,避免因负载均衡导致的重复登录。
-
手机验证码:限制验证码获取频率(如每分钟不超过5次),保障短信接口安全。
Hash(哈希)
这里的hash是指键值对中的value的数据类型。哈希类型中的映射关系通常称为field-value,用于区分redis整体的键值对(key-value),注意这里的value是指field对应的值,不是key对应的值。
注意field-value中的value只能是string类型。
命令
HSET
设置hash中指定的字段(field)的值(value)。
hset key field value [field value ...]时间复杂度O(N),N为插入的字段数量。返回添加字段的个数。
HGET
获取hash中指定字段的值。
hget key field时间复杂度O(1)。返回字段对应的值或者nil。
HEXISTS
判断hash中是否有指定的字段。
hexist key field时间复杂度O(1)。返回值1表示存在,0表示不存在。
HDEL
删除hash中指定的字段。
hdel key field [field ...]时间复杂度O(N),N为要删除的字段数量。返回本次操作删除的字段个数。
HKEYS
获取hash中所有字段(field)。
hkeys key时间复杂度为O(N),N为field的个数。返回查询到的字段列表。
HVALS
获取hash中的所有的值。
hvals key时间复杂度为O(N),N为field的个数。返回所有的值。
HGETALL
获取hash中的所有字段以及对应的值。是上述HKEYS 和HVALS 的结合**。**
hgetall key时间复杂度为O(N),N为field的个数。返回字段和对应的值。
HMGET
一次获取hash中多个字段的值。
hmget key field [field ...]时间复杂度O(N),N为查询字段的个数。返回字段对应的值或者nil。
HLEN
获取hash中的所有字段的个数。
hlen key时间复杂度为O(1)。返回字段的个数。
HSETNX
在字段不存在的情况下,设置hash中的字段和值。
hsetnx key field value时间复杂度O(1)。1表示设置成功,0表示设置失败。
HINCRBY
将hash中字段对应的数值添加指定的值。
hincrby key field increment时间复杂度O(1)。返回该字段变化后的值。
HINCRBYFLOAT
HINCRBY的float版本
内部编码
哈希类型的两种内部编码:
ziplist(压缩列表):当哈希类型元素个数⼩于hash-max-ziplist-entries配置(默认512个)、 同时所有值的长度都小于hash-max-ziplist-value配置(默认64字节)时,Redis会使⽤ziplist作为哈 希的内部实现,ziplist使⽤更加紧凑的结构实现多个元素的连续存储,所以在节省内存⽅⾯⽐ hashtable更加优秀。
hashtable(哈希表):当哈希类型⽆法满⾜ziplist的条件时,Redis会使⽤hashtable作为哈希 的内部实现,因为此时ziplist的读写效率会下降,⽽hashtable的读写时间复杂度为O(1)。
适用场景
-
存储对象(如用户信息、商品信息等):将每个对象的 ID 作为键后缀,对象的属性作为 field,属性值作为 value。相比 JSON 字符串,Hash 可以更直观地操作单个属性,且支持局部更新,避免序列化/反序列化开销。
-
稀疏数据结构:Hash 天然支持不同键拥有不同的 field 集合,适合属性不固定的对象(例如部分用户有"性别"字段,部分没有),而关系型数据库需要为所有行设置 NULL 值。
List(列表)
列表类型是⽤来存储多个有序的字符串。
注意这里的有序不是指升序/降序,而是说列表中的元素的顺序是很关键的,即将列表中的元素顺序进行调换,得到的新列表和原列表是不等价的。
这一特点意味着可以通过索引下标获取某个元素或某个范围的列表。
命令
LPUSH
将一个或者多个元素从左侧放入(头插)到list中。
lpush key element [element ...]时间复杂度O(N),N表示插入元素的个数,一般来说插入元素不会很多所以也可以看做O(1)
返回插入后list的长度。
LPUSHX
在key存在时,将一个或者多个元素从左侧放入(头插)到list中。列表不存在,则直接返回。
lpushx key element [element ...]时间复杂度同上述LPUSH。返回插入后列表的长度。
RPUSH
将一个或者多个元素从右侧放入(尾插)到list中。
rpush key element [element ...]时间复杂度同上述LPUSH。返回插入后列表的长度。
RPUSHX
在key存在时,将一个或者多个元素从右侧插入(尾插)到list中。
rpushx key element [element ...]时间复杂度同是上述LPUSH。返回插入后list的长度。
LINSERT
在特定位置插入元素。
linsert key <BEFORE|AFTER> pivot element
pivot:表示从左往右列表中第一个值等于pivot的位置
<BEFORE|AFTER>:表示两者选其中一个,before表示在指定位置之前插入,after表示在指定位置之后插入时间复杂度为O(N)。返回插入后的list长度。
LRANGE
获取从start到stop区间的所有元素,左闭右闭。
lrange key start stop时间复杂度为O(N)。返回指定区间的元素。
注意:这里的下标从0开始,如果是-1表示列表的最后一个元素。
LINDEX
获取从左数第index位置的元素。
lindex key index时间复杂度为O(N)。返回取出的元素,如果index超出列表范围返回nil。
LLEN
获取list长度。
llen key时间复杂度为O(1)。返回list的长度。
LPOP
从list左侧去除元素(即头删)。(从6.2.0版本之后,该命令新增了一个参数count)
lpop key时间复杂度为O(1)。返回取出的元素或者nil。
RPOP
从list右侧去取出元素(即尾删)。(从6.2.0版本之后,该命令新增了一个参数count)
rpop key时间复杂度为O(1)。返回取出的元素或者nil。
LREM
删除指定数量的指定元素。
lrem key count element
count:表示要删除的个数
count>0:表示从左往右删除count个element
count<0:表示从右往左删除count个element
count==0:表示删除列表中所有的element时间复杂度为O(N+M),N为列表的长度,M为count的值。
返回删除元素的个数。
LTRIM
将指定区间之外的元素全部删除,左闭右闭。
ltrim key start stop时间复杂度为O(N),N表示当前要删除的元素的个数。
LSET
根据下标修改元素。
lset key index element时间复杂度为O(N)。如果index超出范围则会报错。
阻塞版本的命令
blpop和brpop是lpop和rpop的阻塞版本。
在列表中有元素的情况下,阻塞和非阻塞表现是一样的。但是如果列表中没有元素,非阻塞版本会理解返回nil,但阻塞版本会根据timeout,阻塞一段时间,期间redis可以执行其他命令,但要求执行该命令的客户端会表现为阻塞状态。
命令中如果设置了多个键,那么会从左向右进行遍历键,一旦有一个键对应的列表中可以弹出元素,命令立即返回。
如果多个客户端同时对一个键执行pop,则最先执行命令的客户端会最先得到弹出的元素。
BLPOP
LPOP的阻塞版本。
BLPOP key [key ...] timeout
timeout:设置的阻塞时间,单位是sBRPOP
RPOP的阻塞版本。
BRPOP key [key ...] timeout内部编码
List内部的编码方式并非是一个简单的数组,而是更接近于"双端队列"(deque)。
列表类型的内部编码有两种:
ziplist(压缩列表):当列表的元素个数⼩于list-max-ziplist-entries配置(默认512个),同时 列表中每个元素的长度都小于list-max-ziplist-value配置(默认64字节)时,Redis会选用ziplist来作为列表的内部编码实现来减少内存消耗。
linkedlist(链表):当列表类型无法满足ziplist的条件时,Redis会使用linkedlist作为列表的内 部实现。
适用场景
-
阻塞式消息队列 :使用
lpush+brpop(或rpush+blpop)实现生产者-消费者模型。多个消费者阻塞等待队列中的元素,保证每个元素仅被一个消费者获取,实现负载均衡和高可用性。 -
分频道消息队列 :通过不同的 List 键模拟频道,消费者可以使用
brpop同时监听多个键,实现类似订阅不同频道的效果。 -
微博 Timeline / 最新列表 :利用 List 的有序性和支持按范围获取元素的特性,存储用户的微博 ID 列表。通过
lpush向列表头部添加新微博,使用lrange分页获取最新文章。