一、手部检测
1.1 MediaPipe中的重要组件
python
import mediapipe as mp
mp_drawing = mp.solutions.drawing_utils
mp_hands = mp.solutions.handsmp.solutions.drawing_utils: 这是 MediaPipe 提供的一个绘图工具包。它包含了方便的函数,可以直接在图像上绘制出检测到的关键点(landmarks)和它们之间的连接(connections)
mp.solutions.hands: 这是 MediaPipe 的手部检测解决方案。它封装了预训练好的模型,可以直接用于检测图像或视频中的人手
1.2 创建手部检测实例
python
hands = mp_hands.Hands(
static_image_mode=False,
max_num_hands=2,
min_detection_confidence=0.75,
min_tracking_confidence=0.75)
'''
static_image_mode=False:
False (动态模式): 适用于视频流。系统会首先尝试检测手,如果成功,就会切换到更快速的 "追踪" 模式。这大大提高了处理视频时的帧率。如果追踪失败,它会自动重新开始检测。
True (静态模式): 适用于单张图片。系统会对每一帧都进行完整的检测,而不会追踪。这在视频中会非常慢,但对于分析静态图片更准确。
max_num_hands=2: 指定最多可以同时检测的手的数量。这里设置为 2,意味着可以同时识别两只手。
min_detection_confidence=0.75: 最小检测置信度。只有当模型对检测结果的置信度(概率)高于这个值(这里是 75%)时,才会认为成功检测到了一只手。这个值越高,误检越少,但可能会漏掉一些手势。
min_tracking_confidence=0.75: 最小追踪置信度。在追踪模式下,只有当模型对追踪结果的置信度高于这个值时,才会继续追踪。如果低于这个值,系统会认为追踪丢失,并重新启动检测。
'''mp_hands.Hands 中的参数:
(1)static_image_mode=True适用于静态图片的手势识别,Flase适用于视频等动态识别,比较明显的区别是,若识别的手的数量超过了最大值,True时识别的手会在多个手之间不停闪烁,而False时,超出的手不会识别,系统会自动跟踪之前已经识别过的手。默认值为False;
(2)max_num_hands用于指定识别手的最大数量。默认值为2;
(3)min_detection_confidence 表示最小检测信度,取值为0.0,1.0这个值约小越容易识别出手,用时越短,但是识别的准确度就越差。越大识别的越精准,
但是响应的时间也会增加。默认值为0.5;
(4)min_tracking_confience 表示最小的追踪可信度,越大手部追踪的越准确,相应的响应时间也就越长。默认值为0.5。
代码:
python
import cv2
import mediapipe as mp
# pip install mediapipe
mp_drawing = mp.solutions.drawing_utils
mp_hands = mp.solutions.hands
hands = mp_hands.Hands(
static_image_mode=False,
max_num_hands=2,
min_detection_confidence=0.75,
min_tracking_confidence=0.75)
cap = cv2.VideoCapture(0)
while True:
ret, frame = cap.read()
h,w=frame.shape[:2]
frame = cv2.cvtColor(frame, cv2.COLOR_BGR2RGB)
# 因为摄像头是镜像的,所以将摄像头水平翻转
# 不是镜像的可以不翻转
frame = cv2.flip(frame, 1)
results = hands.process(frame)
frame = cv2.cvtColor(frame, cv2.COLOR_RGB2BGR)
if results.multi_hand_landmarks:
for hand_landmarks in results.multi_hand_landmarks:
# print('hand_landmarks:', hand_landmarks)
# 计算关键点的距离,用于判断手指是否伸直
for i in range(len(hand_landmarks.landmark)):
x = hand_landmarks.landmark[i].x
y = hand_landmarks.landmark[i].y
z = hand_landmarks.landmark[i].z
print(f'关键点{i}:',x,y,z)
cv2.putText(frame, str(i), (int(x*w),int(y*h)), cv2.FONT_HERSHEY_SIMPLEX, 1, (0, 255, 0),2)
# 关键点可视化
mp_drawing.draw_landmarks(frame,
hand_landmarks,
mp_hands.HAND_CONNECTIONS)
cv2.imshow('MediaPipe Hands', frame)
if cv2.waitKey(1) & 0xFF == 27:
break
cap.release()
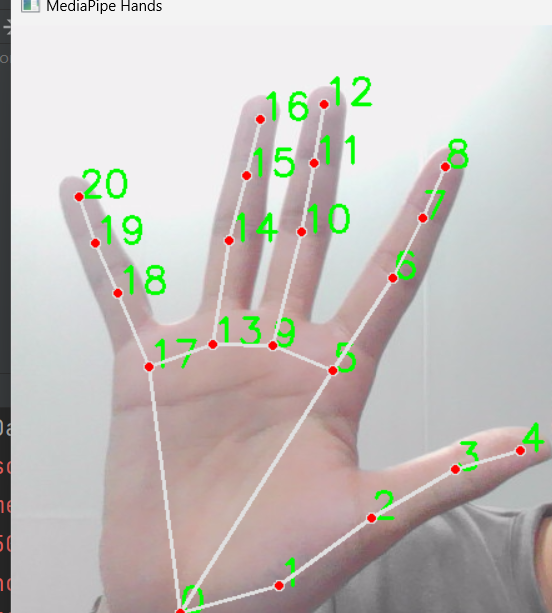
cv2.destroyAllWindows()其中各个点位的坐标可以通过hand_landmarks.landmark来获得如下图
结果:
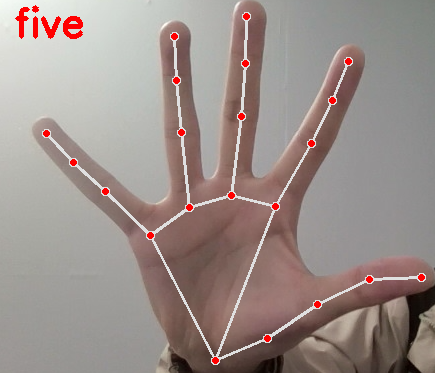
二、手部识别
这里识别的是0到10,10个数字,0设置为none,
设置一个参数flags(初始化为0)表示手指数,将0到5之间的距离作为基准距离,分别计算出5-4,0-8,0-12,0-16,0-20之间的距离,将这些距离与基准距离作比较,若大于则flags+1,当flags大于10时,设置flags为10,
python
import cv2
import mediapipe as mp
gesture = ["none", "one", "two", "three", "four", "five", "six", "seven", "eight", "nine", "ten"]
flag = 0
mp_drawing = mp.solutions.drawing_utils
mp_hands = mp.solutions.hands
hands = mp_hands.Hands(
static_image_mode=False,
max_num_hands=2,
min_detection_confidence=0.75,
min_tracking_confidence=0.75)
cap = cv2.VideoCapture(0)
while True:
flag = 0
ret, frame = cap.read()
frame = cv2.cvtColor(frame, cv2.COLOR_BGR2RGB)
# 因为摄像头是镜像的,所以将摄像头水平翻转
# 不是镜像的可以不翻转
frame = cv2.flip(frame, 1)
results = hands.process(frame)
frame = cv2.cvtColor(frame, cv2.COLOR_RGB2BGR)
# if results.multi_handedness:
# for hand_label in results.multi_handedness:
# print(hand_label)
if results.multi_hand_landmarks:
for hand_landmarks in results.multi_hand_landmarks:
# print('hand_landmarks:', hand_landmarks)
# 计算关键点的距离,用于判断手指是否伸直
p0_x = hand_landmarks.landmark[0].x
p0_y = hand_landmarks.landmark[0].y
p5_x = hand_landmarks.landmark[5].x
p5_y = hand_landmarks.landmark[5].y
distance_0_5 = pow(p0_x - p5_x, 2) + pow(p0_y - p5_y, 2)
base = distance_0_5 / 0.6
p4_x = hand_landmarks.landmark[4].x
p4_y = hand_landmarks.landmark[4].y
distance_5_4 = pow(p5_x - p4_x, 2) + pow(p5_y - p4_y, 2)
p8_x = hand_landmarks.landmark[8].x
p8_y = hand_landmarks.landmark[8].y
distance_0_8 = pow(p0_x - p8_x, 2) + pow(p0_y - p8_y, 2)
p12_x = hand_landmarks.landmark[12].x
p12_y = hand_landmarks.landmark[12].y
distance_0_12 = pow(p0_x - p12_x, 2) + pow(p0_y - p12_y, 2)
p16_x = hand_landmarks.landmark[16].x
p16_y = hand_landmarks.landmark[16].y
distance_0_16 = pow(p0_x - p16_x, 2) + pow(p0_y - p16_y, 2)
p20_x = hand_landmarks.landmark[20].x
p20_y = hand_landmarks.landmark[20].y
distance_0_20 = pow(p0_x - p20_x, 2) + pow(p0_y - p20_y, 2)
if distance_0_8 > base:
flag += 1
if distance_0_12 > base:
flag += 1
if distance_0_16 > base:
flag += 1
if distance_0_20 > base:
flag += 1
if distance_5_4 > base * 0.3:
flag += 1
if flag >= 10:
flag = 10
# 关键点可视化
mp_drawing.draw_landmarks(frame,
hand_landmarks,
mp_hands.HAND_CONNECTIONS)
cv2.putText(frame, gesture[flag], (50, 50), 0, 1.3, (0, 0, 255), 3)
cv2.imshow('MediaPipe Hands', frame)
if cv2.waitKey(1) & 0xFF == 27:
break
cap.release()
cv2.destroyAllWindows()