目录
🌈前言
本篇博客主要内容:介绍神经网络训练的关键组成部分。
神经网络(Neural Networks) : 是一个广义的概念,包含了所有模拟生物神经元结构的计算模型。它不仅包括 多层感知机(MLP),还包括卷积神经网络(CNN)、循环神经网络(RNN)、Transformer 等。后面的学习中我也会逐个记录介绍这些网络。
🔥损失函数
在神经网络的学习中,为了知道学习进行得如何,需要一个指标。这个指标通常称为损失(loss) 。损失(loss)指示学习阶段中某个时间点的神经网络的性能 。基于监督数据 (已知正确数据)和神经网络的预测结果(预测数据),将模型的恶劣程度作为标量计算出来(计算两者的差距),得到的就是损失(loss)。
注:计算神经网络的损失要使用损失函数(loss function)。进行多类别分类的神经网络通常使用交叉熵误差 (cross entropy error)作为损失函数。此时,交叉熵误差由神经网络输出的各类别的概率和监督标签求得。
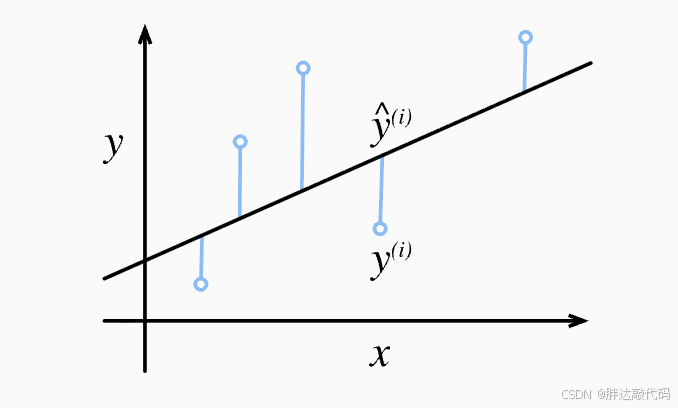
在上图中,可以将直线想象成我们训练的神经网络(y = kx + b),我们需要调整这条直线的角度k和高低b,使Loss达到最小,当loss达到最小时,就得到了整体最优的神经网络,通过输入x值,预测接近真实值的y。
单个loss点的定义:
l o s s ( i ) = 1 2 ( y ^ ( i ) − y ( i ) ) 2 loss^{(i)}= \frac{1}{2} \left( \hat{y}^{(i)} - y^{(i)} \right)^2 loss(i)=21(y^(i)−y(i))2
整体loss的定义:
L o s s = 1 n ∑ i = 1 n l o s s ( i ) Loss= \frac{1}{n} \sum_{i=1}^{n} loss^{(i)} Loss=n1i=1∑nloss(i)
这里给出的loss只是最最基础和易于理解的,实际上,在真正的复杂神经网络的训练中,loss函数更是层出不穷,有着各种变体,给其增加各种约束,以代表神经网络的性能,帮助优化神经网络。对于初学者,这里需要记住,损失函数(loss)是训练神经网络必不可少的一环,Loss越接近0,训练出来的神经网络模型效果越佳。
🔥导数和梯度
导数反映的是"变化率"。简单来说,导数告诉你:当自变量 x x x 发生微小变化时,函数值 y y y 会发生多大的变化。
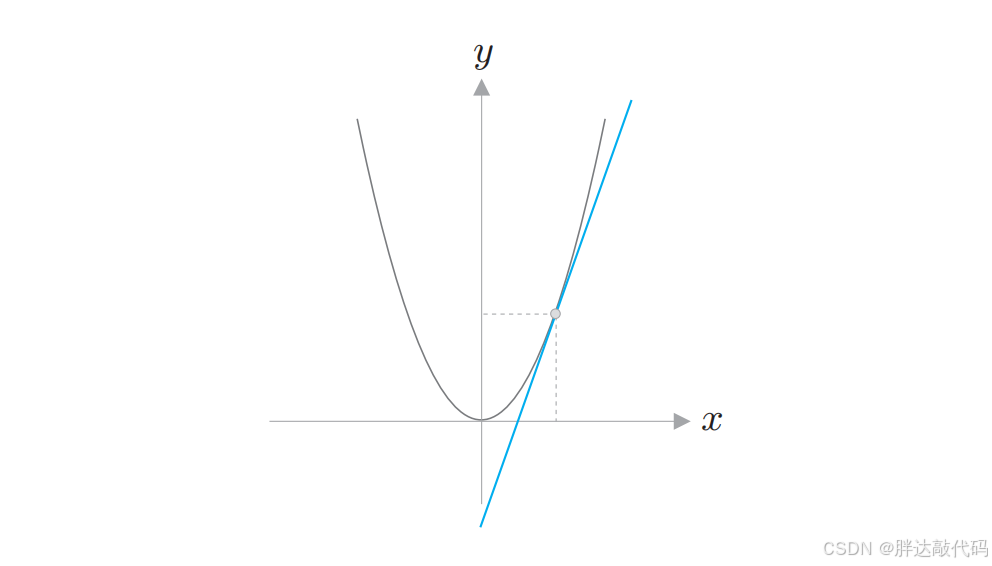
图中,灰色曲线代表了函数本身的变化趋势。对于蓝色切线,重点就在这条蓝线上。在某一个特定的点(图中那个小灰点),这条切线的斜率就是函数在该点的导数。如果你在曲线上的这个点放一个小球,小球滚动的瞬间方向就是这条切线的方向。导数的值越大,切线越陡,说明函数在该点增加得越快。
对于 y = x 2 y = x^2 y=x2,它的导数公式是: d y d x = 2 x \frac{dy}{dx} = 2x dxdy=2x这意味着在 x = 1 x=1 x=1 处,斜率是 2 2 2;在 x = 2 x=2 x=2 处,斜率是 4 4 4。越往右,坡度越陡。
梯度 是导数在高维空间(多变量)的延伸。如果函数只有一个自变量 x x x(如这张图),梯度其实就是导数。如果函数有多个自变量(比如 z = f ( x , y ) z = f(x, y) z=f(x,y),想象一个山坡),梯度就是一个向量,它指向函数值上升最快的方向。
导数是一个数值(标量),代表变化的大小。梯度是一个方向(向量),告诉你往哪走能让函数值增加最快。
在神经网络训练中,我们利用梯度来不断更新模型参数(相当于直线的斜率k和偏移b),从而找到损失函数(loss)的最小值。
🔥反向传播
链式法则
学习阶段的神经网络在给定学习数据后会输出损失。这里我们想得到的是损失关于各个参数的梯度。只要得到了它们的梯度,就可以使用这些梯度进行参数更新。那么,神经网络的梯度怎么求呢?这就轮到误差反向传播法出场了。
理解误差反向传播法的关键是链式法则 。链式法则是复合函数的求导法则,其中复合函数是由多个函数构成的函数。现在,我们来学习链式法则。这里考虑 y = f ( x ) y = f(x) y=f(x) 和 z = g ( y ) z = g(y) z=g(y) 这两个函数。如 z = g ( f ( x ) ) z = g(f(x)) z=g(f(x)) 所示,最终的输出 z z z 由两个函数计算而来。此时, z z z 关于 x x x 的导数可以按下式求得:
∂ z ∂ x = ∂ z ∂ y ∂ y ∂ x \frac{\partial z}{\partial x} = \frac{\partial z}{\partial y} \frac{\partial y}{\partial x} ∂x∂z=∂y∂z∂x∂y
如上式所示, z z z 关于 x x x 的导数由 y = f ( x ) y = f(x) y=f(x) 的导数和 z = g ( y ) z = g(y) z=g(y) 的导数之积求得,这就是链式法则。链式法则的重要之处在于,无论我们要处理的函数有多复杂(无论复合了多少个函数),都可以根据它们各自的导数来求复合函数的导数。也就是说,只要能够计算各个函数的局部的导数,就能基于它们的积计算最终的整体的导数。
可以认为神经网络是由多个函数复合而成的。误差反向传播法会充分利用链式法则来求关于多个函数(神经网络)的梯度。
计算图
计算图是计算过程的图形表示:
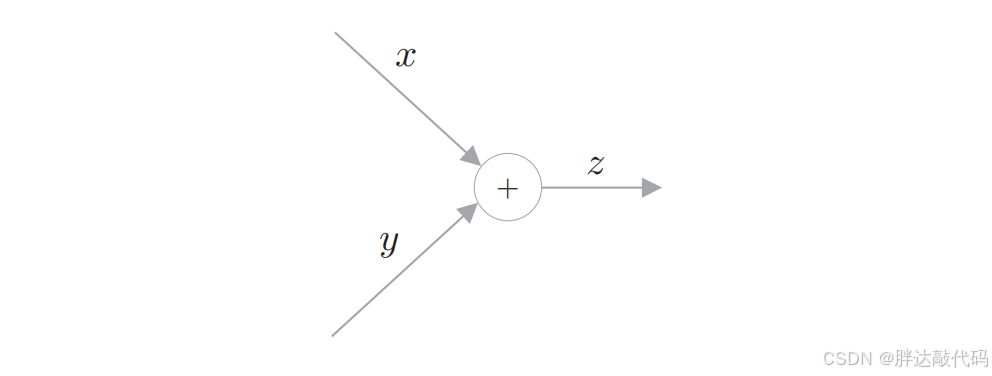
如上图,是 z = x + y z=x+y z=x+y的计算图。计算图通过节点和箭头来表示。这里,"+"表示加法,变量 x 和 y 写在各自的箭头上。像这样,在计算图中,用节点表示计算,处理结果有序(本例中是从左到右)流动。这就是计算图的正向传播。
使用计算图,可以直观地把握计算过程。另外,这样也可以直观地求梯度。这里重要的是,梯度沿与正向传播相反的方向传播,这个反方向的传播称为反向传播 。
这里说明一下反向传播的全貌。虽然我们处理的是 z = x + y z = x + y z=x+y 这一计算,但是在该计算的前后,还存在其他的"某种计算"。另外,假设最终输出的是标量 L(loss,在神经网络的学习阶段,计算图的最终输出是损失,它是一个标量)。
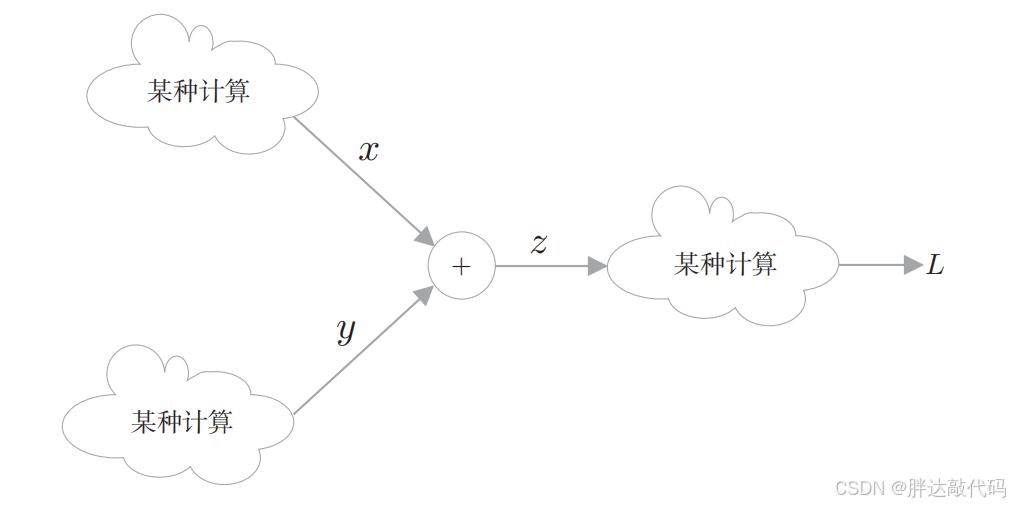
目标是求 L (loss)关于各个变量的导数(梯度)。这样一来,计算图的反向传播就可以绘制成图:
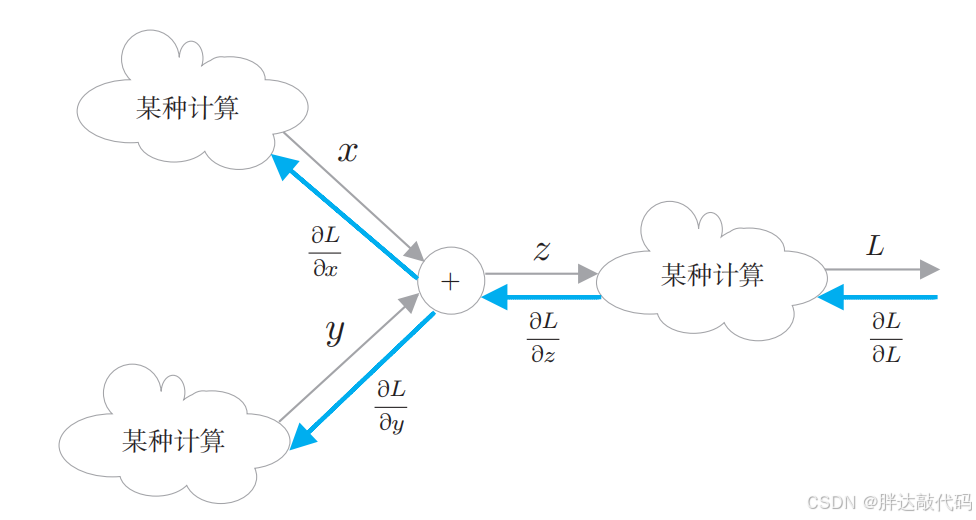
反向传播用蓝色的粗箭头表示,在箭头的下方标注传播的值。此时,传播的值是指最终的输出 L 关于各个变量的导数。
接着,该链式法则出场了。根据刚才复习的链式法则,反向传播中流动的导数的值是根据从上游(输出侧)传来的导数和各个运算节点的局部导数之积求得的。因此,在上面的例子中, ∂ L ∂ x = ∂ L ∂ z ∂ z ∂ x \frac{\partial L}{\partial x} = \frac{\partial L}{\partial z} \frac{\partial z}{\partial x} ∂x∂L=∂z∂L∂x∂z, ∂ L ∂ y = ∂ L ∂ z ∂ z ∂ y \frac{\partial L}{\partial y} = \frac{\partial L}{\partial z} \frac{\partial z}{\partial y} ∂y∂L=∂z∂L∂y∂z。
这里,我们来处理 z = x + y z = x + y z=x+y 这个基于加法节点的运算。此时,分别解析性地求得 ∂ z ∂ x = 1 \frac{\partial z}{\partial x} = 1 ∂x∂z=1, ∂ z ∂ y = 1 \frac{\partial z}{\partial y} = 1 ∂y∂z=1。因此,如图 1-18 所示,加法节点将上游传来的值乘以 1,再将该梯度向下游传播。也就是说,只是原样地将从上游传来的梯度传播出去。
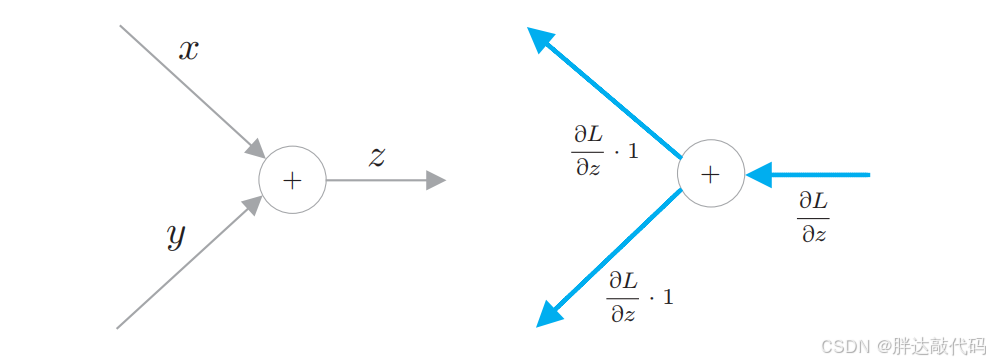
以上就是最基本的反向传播(加法节点),根据运算和节点结构的不同,还会有乘法节点、分支节点、Repeat节点、Sum节点等等,但运算本质基本上是如此。
🔥权重的更新
通过误差反向传播法求出梯度后,就可以使用该梯度更新神经网络的参数。此时,神经网络的学习按如下步骤进行。
• 步骤 1 :mini-batch
从训练数据中随机选出多笔数据。
• 步骤 2 :计算梯度
基于误差反向传播法,计算损失函数关于各个权重参数的梯度。
• 步骤 3 :更新参数
使用梯度更新权重参数。
• 步骤 4 :重复
根据需要重复多次步骤 1、步骤 2 和步骤 3。
按照上面的步骤进行神经网络的学习。首先,选择 mini-batch 数据,根据误差反向传播法获得权重的梯度。这个梯度指向当前的权重参数所处位置中损失增加最多的方向。因此,通过将参数向该梯度的反方向更新,可以降低损失。这就是梯度下降法(gradient descent) 。之后,根据需要将这一操作重复多次即可。
SGD 是一个很简单的方法。它将(当前的)权重朝梯度的(反)方向更新一定距离。如果用数学式表示,则有:
W ← W − η ∂ L ∂ W ( 1.16 ) \mathbf{W} \leftarrow \mathbf{W} - \eta \frac{\partial L}{\partial \mathbf{W}} \qquad (1.16) W←W−η∂W∂L(1.16)
这里将要更新的权重参数记为 W \mathbf{W} W,损失函数关于 W \mathbf{W} W 的梯度记为 ∂ L ∂ W \frac{\partial L}{\partial \mathbf{W}} ∂W∂L。 η \eta η 表示学习率,实际上使用 0.01、0.001 等预先定好的值。
学习率决定了权重更新的步长:
- 太大会"跳过": 导致在最小值附近震荡甚至直接发散,无法收敛。
- 太小会"爬行": 导致收敛速度极慢,且容易陷入局部最优解。
- 理想状态: 能够平滑、快速地抵达损失函数的谷底。
🌈结语
本篇博客注重通俗讲解神经网络的训练流程 和各个组成部分的底层机理 。神经网络训练的重点在于损失函数(loss function)的定义 和梯度下降算法(gradient descent)。