深入浅出 Kubernetes 探针:存活、就绪与启动探针的原理与实战指南
-
- [一、 引言:为什么我们需要探针?](#一、 引言:为什么我们需要探针?)
- [二、 核心概念详解:三大探针的角色定位](#二、 核心概念详解:三大探针的角色定位)
-
- [1. 存活探针:看门狗](#1. 存活探针:看门狗)
- [2. 就绪探针:流量守门人](#2. 就绪探针:流量守门人)
- [3. 启动探针:慢启动应用的救星](#3. 启动探针:慢启动应用的救星)
- [三、 探针的实现机制与配置参数](#三、 探针的实现机制与配置参数)
-
- [1. 三种探测方式](#1. 三种探测方式)
- [2. 核心配置参数深度解析](#2. 核心配置参数深度解析)
- [四、 实战演练:Kubernetes YAML 配置详解](#四、 实战演练:Kubernetes YAML 配置详解)
-
- [1. 场景描述](#1. 场景描述)
- [2. 完整 Deployment YAML 配置](#2. 完整 Deployment YAML 配置)
- [3. 配置解析与深度分析](#3. 配置解析与深度分析)
- [五、 Spring Boot 应用中的探针实现最佳实践](#五、 Spring Boot 应用中的探针实现最佳实践)
-
- [1. 引入依赖](#1. 引入依赖)
- [2. 开启探针端点](#2. 开启探针端点)
- [3. 自定义健康检查逻辑](#3. 自定义健康检查逻辑)
- [4. 针对慢启动应用的特殊处理](#4. 针对慢启动应用的特殊处理)
- [六、 高级话题与常见误区](#六、 高级话题与常见误区)
-
- [1. 存活探针 vs 就绪探针:混淆带来的灾难](#1. 存活探针 vs 就绪探针:混淆带来的灾难)
- [2. 探测端点的性能考量](#2. 探测端点的性能考量)
- [3. `initialDelaySeconds` 的陷阱](#3.
initialDelaySeconds的陷阱) - [4. 优雅关闭](#4. 优雅关闭)
- [七、 总结](#七、 总结)
一、 引言:为什么我们需要探针?
在传统的虚拟机或物理机时代,运维人员通常通过监控进程是否存在来判断服务的可用性。但在 Kubernetes 的微服务架构中,容器内的进程"存活"并不等于服务"可用"。
例如,一个 Java 应用可能因为内存溢出(OOM)而进入假死状态,进程依然存在,但已经无法响应任何请求;或者一个应用启动过程需要加载海量数据,在未完成初始化前就接收流量,必然导致业务报错。
为了解决这些问题,Kubernetes 引入了探针机制。探针是 Kubelet 对容器进行周期性健康检查的手段,根据检查结果,Kubelet 会决定重启容器或调整流量分发 \[1]\[2]。正确配置探针是实现零停机部署、故障自愈和弹性伸缩的基石。
二、 核心概念详解:三大探针的角色定位
Kubernetes 提供了三种不同类型的探针,分别应用于容器生命周期的不同阶段。理解它们的区别是正确使用的前提。
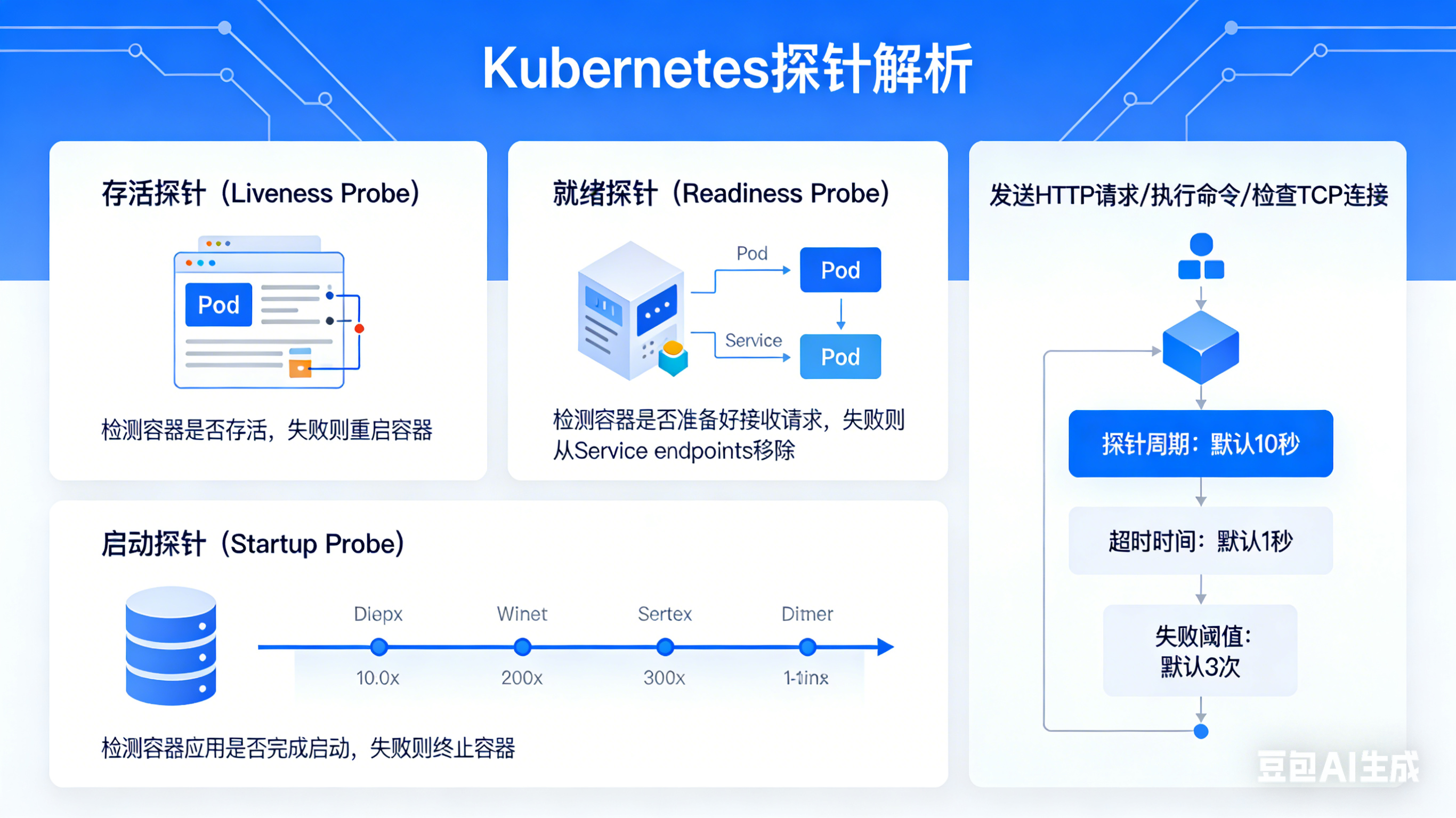
1. 存活探针:看门狗
定义与作用 :
存活探针用于检测容器是否处于"运行"状态。如果存活探针探测失败,Kubelet 会认为容器已经"死亡",并根据 Pod 的重启策略重启容器 \[3]\[4]\[5]。
核心逻辑:
- 探测成功:容器正常运行,无需干预。
- 探测失败 :容器被杀死并根据
restartPolicy重启。
典型场景 :
当应用程序陷入死锁、运行时异常导致线程池耗尽或内部状态不可恢复时,存活探针可以触发重启,使服务恢复。这是一种"毁灭后重生"的自愈机制。
2. 就绪探针:流量守门人
定义与作用 :
就绪探针用于检测容器是否准备好接收网络流量。如果探测失败,Kubernetes 会将该 Pod 从对应的 Service 的 Endpoints 列表中移除,停止向其发送流量,直到探测成功为止 \[6]\[7]\[8]。
核心逻辑:
- 探测成功:Pod 被加入到 Service 的负载均衡池中,开始处理请求。
- 探测失败:Pod 从 Service 中移除,流量被导向其他健康的 Pod。
典型场景 :
应用启动时需要加载配置、预热缓存或建立数据库连接池。在此期间,应用进程已启动(存活探针通过),但尚不能处理业务。此时应配置就绪探针,确保只有在完全准备就绪后才承接流量 \[9]。此外,当应用依赖的下游服务(如数据库、Redis)不可用时,应用可能暂时无法提供服务,此时可以通过让就绪探针失败来主动"屏蔽"自己,防止流量进入导致错误。
注意 :就绪探针的失败不会导致容器重启,这是它与存活探针最大的区别。
3. 启动探针:慢启动应用的救星
定义与作用 :
启动探针是 Kubernetes 1.16 版本引入的特性,专门用于处理启动时间较长的应用 \[10]\[11]。它在容器启动初期优先执行,只有当启动探针成功后,存活探针和就绪探针才会开始工作 \[12]\[13]。
核心逻辑:
- 启动中:启动探针接管检测。如果启动探针失败,容器会被重启。
- 启动完成:启动探针成功后,Kubernetes 停止执行启动探针,转而开始执行存活探针和就绪探针。
解决的问题 :
对于大型 Java 应用、AI 模型服务或需要从磁盘加载大量数据的服务,启动时间可能长达数分钟甚至更久。如果只配置存活探针,为了避免误判,必须将 initialDelaySeconds(初始延迟)设置得非常大,这会导致应用在运行期间真正发生故障时,Kubernetes 需要等待很久才开始探测,降低了故障恢复的灵敏度。启动探针通过"覆盖"启动阶段,允许我们为启动过程配置一个较长的失败阈值,同时保持存活探针的高灵敏度 \[14]\[15]。
三、 探针的实现机制与配置参数
1. 三种探测方式
无论是哪种探针,Kubernetes 都支持以下三种探测方式 \[16]\[17]:
- Exec Action :在容器内执行一条命令。如果命令退出码为 0,则认为探测成功;否则失败。
- 适用场景:检查文件是否存在、执行自定义脚本等。例如,检查某个锁文件是否存在来判断服务状态 \[18]\[19]。
- HTTP Get Action :对容器的 IP 地址和指定端口及路径发起 HTTP GET 请求。如果响应状态码在 200-399 之间,则认为探测成功。
- 适用场景 :Web 服务应用。这是最常用的方式,例如访问
/health端点。
- 适用场景 :Web 服务应用。这是最常用的方式,例如访问
- TCP Socket Action :尝试与容器指定端口建立 TCP 连接。如果连接成功,则认为探测成功。
- 适用场景:非 HTTP 服务,如数据库、Redis、MQTT 等。
2. 核心配置参数深度解析
探针的行为由一系列参数控制,精细调整这些参数是实现最佳实践的关键 \[20]\[21]。以下是详细参数说明:
| 参数名 | 含义 | 默认值 | 最佳实践建议 |
|---|---|---|---|
initialDelaySeconds |
容器启动后等待多少秒才开始探测。 | 0 | 对于无启动探针的场景,需根据应用启动时间估算。有启动探针后可设较小值。 |
periodSeconds |
探测的频率(间隔秒数)。 | 10 | 存活探针不宜过频,避免增加负载;就绪探针可稍快以响应状态变化。 |
timeoutSeconds |
探测操作的超时时间。 | 1 | 如果应用响应慢,需适当调大,否则易误判。 |
successThreshold |
探测失败后,连续成功多少次才被认为"探测成功"。 | 1 | 存活/启动探针必须为 1。就绪探针可设为 2-3,确保稳定后再接入流量。 |
failureThreshold |
探测成功后,连续失败多少次才被认为"探测失败"。 | 3 | 根据业务敏感度调整。启动探针通常设得很大,以容忍慢启动。 |
参数计算公式与调优逻辑:
- 最大启动时间计算 :对于启动探针,最大允许的启动时间 =
failureThreshold×periodSeconds。例如,设置failureThreshold: 30和periodSeconds: 10,则应用最多有 300 秒的时间来完成启动,之后才会被重启 \[22]。 - 灵敏度与误判平衡 :存活探针的
failureThreshold设置过小可能导致网络抖动等瞬时故障引发不必要的重启;设置过大则故障恢复慢。通常建议保持默认值 3,配合timeoutSeconds合理设置。
四、 实战演练:Kubernetes YAML 配置详解
下面我们通过具体的 YAML 配置示例,展示如何组合使用这三种探针。
1. 场景描述
假设我们有一个名为 my-app 的微服务,它具有以下特征:
- 需要加载配置文件并连接数据库(启动耗时约 30-60 秒)。
- 提供 REST API,健康检查端点为
/actuator/health。 - 如果进程死锁,需要自动重启。
- 如果数据库连接断开,暂时不应接收流量,但无需重启。
2. 完整 Deployment YAML 配置
yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: my-app-deployment
spec:
replicas: 2
selector:
matchLabels:
app: my-app
template:
metadata:
labels:
app: my-app
spec:
containers:
- name: my-app-container
image: my-app:latest
ports:
- containerPort: 8080
# 资源限制,防止应用因资源饥饿而异常
resources:
limits:
memory: "512Mi"
cpu: "500m"
requests:
memory: "256Mi"
cpu: "200m"
# 1. 启动探针配置
# 解决慢启动问题,给应用 5 分钟的启动时间窗口
startupProbe:
httpGet:
path: /actuator/health/liveness # 仅检测进程存活
port: 8080
initialDelaySeconds: 10 # 容器启动后 10s 开始检测
periodSeconds: 10 # 每 10s 检测一次
failureThreshold: 30 # 允许失败 30 次 (30 * 10s = 300s = 5分钟)
# successThreshold: 1 # 默认为1,启动成功一次即认为启动完成
# 2. 存活探针配置
# 应用启动后,每 10s 检查一次,若失败则重启
livenessProbe:
httpGet:
path: /actuator/health/liveness
port: 8080
# 注意:有了 startupProbe,initialDelaySeconds 可以设为 0 或较小值
# 因为 startupProbe 会阻塞 livenessProbe 的执行
initialDelaySeconds: 0
periodSeconds: 10
timeoutSeconds: 5
failureThreshold: 3
successThreshold: 1
# 3. 就绪探针配置
# 检查应用是否准备好处理业务(如 DB 连接正常)
readinessProbe:
httpGet:
path: /actuator/health/readiness
port: 8080
initialDelaySeconds: 0
periodSeconds: 5 # 就绪探针频率可稍高,以便快速感知状态变化
timeoutSeconds: 3
failureThreshold: 1 # 失败一次即切流,保证业务不受影响
successThreshold: 1 # 恢复成功一次即重新接入流量3. 配置解析与深度分析
- 启动探针的保护作用 :在上述配置中,
startupProbe设置了failureThreshold: 30和periodSeconds: 10,这意味着该应用有 300 秒的宽限期。在此期间,如果/actuator/health/liveness返回非 200 状态码,Kubernetes 不会 重启容器,而是继续等待下一次探测。这有效避免了因应用启动慢而导致的频繁重启循环 \[23]\[24]。 - 探针协作流程 :
- Pod 启动,容器创建。
initialDelaySeconds(10s) 后,startupProbe开始探测。- 如果在 300s 内某次探测成功,
startupProbe标记为成功并停止探测。此时livenessProbe和readinessProbe开始接管。 livenessProbe每 10s 检查一次进程存活。readinessProbe每 5s 检查一次业务就绪状态。如果数据库连不上,该端点返回 503,Kubernetes 将该 Pod 从 Service 中剔除。
- 端点分离 :示例中使用了
/actuator/health/liveness和/actuator/health/readiness两个不同端点。这是 Spring Boot 的最佳实践,将"进程存活"与"业务就绪"区分开来。readiness端点通常包含数据库、外部服务等依赖的健康检查,而liveness端点仅检查应用本身的状态 \[25]\[26]。
五、 Spring Boot 应用中的探针实现最佳实践
在现代微服务开发中,Spring Boot 是主流框架。从 Spring Boot 2.3 开始,官方提供了对 Kubernetes 探针的一流支持。我们可以通过 Actuator 轻松实现自定义的健康检查端点。
1. 引入依赖
首先,在 pom.xml 中引入 Actuator 依赖:
xml
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-actuator</artifactId>
</dependency>2. 开启探针端点
在 application.properties 或 application.yml 中配置:
properties
# 开启健康检查端点
management.endpoints.web.exposure.include=health
# 开启 Kubernetes 探针支持 (Spring Boot 2.3+ 自动配置,也可显式开启)
management.endpoint.health.probes.enabled=true
# 显示详细的健康信息(可选,生产环境建议设为 never 或 when_authorized)
management.endpoint.health.show-details=always开启后,Spring Boot 会自动暴露以下两个端点:
/actuator/health/liveness:用于存活探针。/actuator/health/readiness:用于就绪探针 \[27]\[28]。
3. 自定义健康检查逻辑
虽然 Spring Boot 默认会检查磁盘空间等,但业务往往有特定的健康指标。我们可以通过实现 HealthIndicator 接口来自定义逻辑。
场景 :我们需要检查一个关键的外部服务 ExternalService 是否可用,如果不通,则标记为未就绪(但不重启应用)。
步骤一:编写自定义 Readiness 指示器
我们可以利用 Spring Boot 的 Health Groups 机制,将特定的健康检查归类到 Readiness 组中。
java
import org.springframework.boot.actuate.health.Health;
import org.springframework.boot.actuate.health.HealthIndicator;
import org.springframework.stereotype.Component;
@Component("externalServiceHealthIndicator")
public class ExternalServiceHealthIndicator implements HealthIndicator {
private final ExternalServiceClient externalServiceClient;
public ExternalServiceHealthIndicator(ExternalServiceClient externalServiceClient) {
this.externalServiceClient = externalServiceClient;
}
@Override
public Health health() {
try {
// 尝试调用外部服务
if (externalServiceClient.ping()) {
return Health.up().withDetail("message", "External service is reachable").build();
} else {
return Health.down().withDetail("message", "External service returned false").build();
}
} catch (Exception e) {
return Health.down().withDetail("error", e.getMessage()).build();
}
}
}步骤二:配置健康组
默认情况下,自定义的 HealthIndicator 可能会被包含在主 /actuator/health 端点中,但可能不会自动加入 liveness 或 readiness 组。我们需要明确配置 \[29]。
在 application.properties 中添加:
properties
# 将自定义指示器加入 readiness 组
management.endpoint.health.group.readiness.include=externalServiceHealthIndicator,db
# 或者,如果不想影响默认的 readiness 探测行为,可以创建独立的组
# management.endpoint.health.group.customProbe.include=externalServiceHealthIndicator重要提示:存活探针不应包含外部依赖检查。如果存活探针因外部服务不可用而失败,会导致应用不断重启,这无助于解决问题,反而可能加剧雪崩效应 \[30]。因此,我们通常将外部依赖检查放在就绪探针中。
4. 针对慢启动应用的特殊处理
对于 Spring Boot 应用,如果启动时间较长(例如初始化 Bean 很多),我们可以利用 ApplicationStartedEvent 来控制就绪状态。
但更推荐的方式是使用 Kubernetes 的 Startup Probe 。Spring Boot 应用本身代码无需改动,只需在 K8s YAML 中配置 startupProbe 指向 /actuator/health/liveness 即可。这完美契合了"基础设施即代码"的思想,将启动逻辑与业务逻辑解耦。
六、 高级话题与常见误区
1. 存活探针 vs 就绪探针:混淆带来的灾难
这是最常见的错误。很多开发者将所有健康检查逻辑(包括 DB 连接)都放在存活探针中。
- 错误做法 :
livenessProbe检查数据库连接。当数据库宕机时,所有 Pod 的存活探针失败,Pod 被强制重启。 - 后果:数据库尚未恢复,Pod 重启依然失败,导致无限重启循环。Pod 重启瞬间可能会消耗大量 CPU,导致集群雪崩,且原本可能的"优雅降级"服务也无法提供。
- 正确做法 :
- Liveness:仅检测应用内部状态(如线程池状态、死锁检测、JVM 状态)。
- Readiness:检测应用处理请求的能力(如 DB 连接、Redis 连接、依赖服务状态)。
- 结果:DB 宕机 -> Readiness 失败 -> Pod 从 Service 移除 -> 流量导向其他健康实例(如有)或返回 503 -> Pod 保持运行(不重启)-> DB 恢复 -> Readiness 成功 -> 流量恢复。
2. 探测端点的性能考量
探针的探测频率很高(如每 10 秒一次),如果健康检查端点逻辑复杂(如执行大型 SQL 查询),会严重影响应用性能。
- 建议:健康检查逻辑应尽可能轻量。对于依赖检查,可以采用异步缓存机制。应用后台线程定期检查 DB 状态并更新内存变量,健康检查端点只需读取该变量即可,无需每次探测都发起真实的 DB 连接。
3. initialDelaySeconds 的陷阱
如果没有配置启动探针,initialDelaySeconds 的设置非常棘手。设置太短,应用未启动完就被重启;设置太长,故障响应不及时。
- 解决方案 :优先使用
startupProbe。配置startupProbe后,livenessProbe和readinessProbe的initialDelaySeconds可以设为0(或较小值),因为startupProbe成功前它们不会执行。这极大地简化了配置 \[31]。
4. 优雅关闭
当存活探针失败导致容器被杀死时,Kubernetes 会发送 SIGTERM 信号。应用应捕获此信号,进行资源清理(如关闭数据库连接、完成未处理完的请求)。Spring Boot 默认支持优雅关闭,可通过 server.shutdown=graceful 配置。这与探针机制相辅相成,共同保障服务的高可用。
七、 总结
Kubernetes 的探针机制是保障微服务稳定性的核心工具。通过本文的深入剖析,我们可以总结出以下核心实践原则:
- 职责分离:存活探针保"命",就绪探针保"流量",启动探针保"启动"。务必区分存活探针和就绪探针的职责,切勿在存活探针中检查外部依赖。
- 善用启动探针 :对于任何非瞬时启动的应用,强烈建议配置启动探针,以替代僵化的
initialDelaySeconds,实现更灵活的启动保护。 - 精细化配置 :根据应用的实际启动时间、响应速度和业务敏感度,调整
periodSeconds、failureThreshold等参数。 - Spring Boot 集成 :利用 Spring Boot Actuator 提供的
/actuator/health/liveness和/readiness端点,结合HealthIndicator接口实现业务层面的健康检查,是 Java 微服务的最佳实践。
通过合理配置这三种探针,我们可以让 Kubernetes 应用实现真正的"故障自愈"和"零停机更新",大幅提升系统的健壮性和用户体验。希望这篇博文能为你在 Kubernetes 探针的使用上提供详尽的指导和帮助。