
⚡ CYBER_PROFILE ⚡
/// SYSTEM READY ///
WARNING : DETECTING HIGH ENERGY
🌊 🌉 🌊 心手合一 · 水到渠成

|------------------------------------------------------------------------------------|--------------------------------------------------------------------------------------------------------------|
| >>> ACCESS TERMINAL <<< ||
| 🦾 作者主页 | 🔥 C语言核心 |
| 💾 编程百度 | 📡 代码仓库 |
Running Process: 100% | Latency: 0ms
索引与导读
-
- 一、左值和右值
- [二、左值引用 与 右值引用](#二、左值引用 与 右值引用)
- 三、引用延长生命周期
- 四、左值和右值的参数匹配
- 五、移动语义
- [六、左值引用 和 右值引用 的使用场景回顾](#六、左值引用 和 右值引用 的使用场景回顾)
-
- 6.1)左值引用的主要使用场景
- [6.2) 右值引用 和 移动语义 解决传值返回问题](#6.2) 右值引用 和 移动语义 解决传值返回问题)
- [七、右值引用(T&&)和移动语义 出现的核心场景](#七、右值引用(T&&)和移动语义 出现的核心场景)
- [八、 右值引用和移动语义在传参中的提效](#八、 右值引用和移动语义在传参中的提效)
- 九、类型分类
- 十、引用折叠
- 十一、完美转发
- [💻结尾--- 核心连接协议](#💻结尾— 核心连接协议)
一、左值和右值
二、左值引用 与 右值引用
| 特性 | 左值引用 (T&) |
右值引用 (T&&) |
|---|---|---|
| 绑定对象 | 绑定到左值 | 绑定到右值(临时对象) |
| 持久性 | 对象生命周期由作用域决定 | 延长临时对象的生命周期 |
| 主要目的 | 避免拷贝,共享内存 | 实现移动语义,减少重复开销 |
左值引用
我们平时用的引用就是左值引用,它只能绑定到左值上
cpp
int a = 10;
int& ref1 = a; // 合法:a 是左值
// int& ref2 = 10; // 非法:10 是右值,不能绑定到普通的左值引用常量左值引用 (const int&) 可以绑定到右值,这在 C++98 中是为了让函数能接受临时变量作为参数
cpp
void printString(const string& str) {
cout << str << endl;
}此时printString("C++")就能完美编译了
右值引用
右值引用的语法是两个 &
核心作用: 绑定到右值(临时对象)上,并延长这个临时对象的生命周期
cpp
int&& rref = 10; // 合法:rref 绑定到了右值 10 上
// int&& rref2 = a; // 非法:a 是左值,右值引用不能绑定到左值三、引用延长生命周期
右值引用可用于为临时对象延长生命周期
const 的左值引用也能延长临时对象生存期,但这些对象无法被修改
cpp
int main()
{
string s1 = "Test";
//❌错误:不能绑定到左值
/*string&& r1 = s1;*/
//OK: 对 const 的左值引用延长生存期
const string& r2 = s1 + s2;
//❌错误:不能通过到 const 的引用修改
/* r2 += "Test";*/
//OK: 右值引用延长生存期
string&& r3 = s1 + s2;
//OK: 能通过到非 const 的引用修改
r3 += "Test";
return 0;四、左值和右值的参数匹配
C++98中,我们实现一个const左值引用作为参数的函数,那么实参传递左值和右值都可以匹配C++11以后,分别重载左值引用、const左值引用、右值引用作为形参的f函数,那么实参是左值会匹配(左值引用),实参是const左值会匹配(const左值引用),实参是右值会匹配(右值引用)
cpp
#include<iostream>
using namespace std;
void f(int& x)
{
cout << "左值引用重载 f(" << x << ") \n";
}
void f(const int& x)
{
cout << "到 const 的左值引用重载 f(" << x << ") \n";
}
void f(int&& x)
{
cout << "右值引⽤重载 f(" << x << ")\n";
}
int main(){
int i = 1;
const int ci = 2;
//调用f(int&)
f(i);
//调用f(const int&)
f(ci);
//调⽤ f(int&&),如果没有 f(int&&) 重载则会调⽤ f(const int&)
f(3);
//调用f(int&&)
f(std::move(i));
//右值引⽤变量在⽤于表达式时是左值
int&& x = 1;
f(x); // 调⽤ f(int& x)
f(std::move(x)); // 调⽤ f(int&& x)
return 0;
}五、移动语义
移动语义的引入解决一个核心问题:消除不必要的深拷贝,从而大幅提升程序的性能
5.1)为何需要移动语义?
在C++11之前,当我们将一个对象赋值给另一个对象,或者从函数返回一个对象时,默认执行的是拷贝语义
假设你有一个管理了大量堆内存的 String 或 Vector 类
当你执行Vector B = A;时,编译器会调用拷贝构造函数:
1. 为 B 分配一块和 A 一样大的新内存。
2. 将 A 内存中的数据逐个复制到 B 的内存中。
很多时候,A只是一个临时对象(例如函数的返回值) ,或者我们在赋值后就不再需要A了。这时候新分配的内存和数据就会浪费
移动语义的思想就是偷 或资源转移:既然 A 马上就要消亡了,B 为什么不直接接管 A 已经分配好的内存呢?这样就不需要任何内存分配和数据复制了
5.2)移动构造函数
当一个类拥有堆内存(如指针 int* ptr)时,移动构造函数不会分配新内存,而是直接将指针指向源对象的内存
- 操作逻辑:
1. 接管资源:将当前对象的指针指向源对象的内存。
2. 源对象置空:将源对象的指针设为nullptr(防止源对象析构时把刚拿过来的内存释放掉)。
cpp
class MyBuffer {
int* data;
public:
// 移动构造函数
MyBuffer(MyBuffer&& other) noexcept {
this->data = other.data; // 1. 偷取资源
other.data = nullptr; // 2. 将原对象置空(安全移交)
}
};5.3)移动赋值运算符
用于处理两个已经存在的对象之间的资源转移。
-
它比移动构造多了一个步骤:清理自己现有的资源,防止内存泄漏。
-
操作逻辑 :
1. 自赋值检查:检查是不是自己给自己赋值(if(this!=&other))。
2. 释放旧资源:清理掉自己原本占用的内存。
3. 接管并置空:逻辑同移动构造。
cpp
MyBuffer& operator=(MyBuffer&& other) noexcept {
if (this != &other) {
delete[] data; // 释放自己的旧资产
data = other.data; // 拿走别人的资产
other.data = nullptr; // 让别人变成"穷光蛋"
}
return *this;
}5.4)std::move
std::move并不移动任何东西,它的唯一作用是:强制类型转换
-
它将一个左值(持久对象)强制转换成右值引用。
-
目的:告诉编译器,"虽然这个变量有名有姓,但我以后不用它了,你可以触发它的移动语义来优化性能"。
cpp
std::string a = "Hello";
std::string b = std::move(a); // a 变成空字符串,资源被移动到了 b六、左值引用 和 右值引用 的使用场景回顾
6.1)左值引用的主要使用场景
函数参数传递(避免拷贝)
对于大型对象(如 std::vector 或自定义类),通过引用传递可以避免昂贵的深拷贝
cpp
void printLargeString(const string& str) { // 加上 const 保证安全性
cout << str << endl;
}什么是"昂贵的深拷贝"?
当你直接按值传递一个大型对象(如
std::vector<int>v),里面有一百万个整数)时,程序会执行以下操作:
1. 申请内存:在堆上开辟一块同样大小的新空间。
2. 逐个复制:将原vector中的一百万个数字逐一读取并写入新空间。
3. 管理开销:如果对象复杂(比如嵌套了对象),还会递归触发所有成员的构造函数。这就是"昂贵"所在:它不仅消耗
CPU周期(搬运数据),还消耗内存带宽和内存空间通过引用传递"?
引用在底层通常被编译器实现为指针
- 按值传递: 相当于你把一本
1000页的书复印了一份给函数。你手里一本,函数手里一本。- 引用传递: 相当于你把这本书的地址(或书签) 给了函数。函数直接通过这个地址看你手里的那本书。
性能差异:
无论
std::vector有多大(1KB还是1GB),引用的传递成本通常只是一个64位(8字节)地址的传递。这几乎是瞬间完成的
函数返回值
当我们需要实现链式调用(如 operator<< 或 operator=)时,必须返回左值引用
cpp
class MyClass {
public:
MyClass& operator=(const MyClass& other) {
// 执行赋值逻辑...
return *this; // 返回自身引用,支持 a = b = c;
}
};6.2) 右值引用 和 移动语义 解决传值返回问题
我们观察下面这段代码:
cpp
#include <iostream>
#include <string>
#include <algorithm>
using namespace std;
namespace bit
{
string addStrings(string num1, string num2)
{
string str;
int end1 = num1.size() - 1;
int end2 = num2.size() - 1;
int next = 0; // 进位
// 核心加法逻辑
while (end1 >= 0 || end2 >= 0)
{
int val1 = (end1 >= 0) ? num1[end1--] - '0' : 0;
int val2 = (end2 >= 0) ? num2[end2--] - '0' : 0;
int ret = val1 + val2 + next;
next = ret / 10;
ret = ret % 10;
str += ('0' + ret);
}
// 处理最后可能的进位
if (next == 1)
{
str += '1';
}
reverse(str.begin(), str.end());
return str;
}
}
// --- 场景演示 ---
void scenario1()
{
// 场景1:直接初始化(调用拷贝构造/移动构造)
string ret = bit::addStrings("11111", "2222");
cout << "Scenario 1 Result: " << ret.c_str() << endl;
}
void scenario2()
{
// 场景2:先定义再赋值(调用赋值运算符)
string ret;
ret = bit::addStrings("11111", "2222");
cout << "Scenario 2 Result: " << ret.c_str() << endl;
}
int main()
{
scenario1();
scenario2();
return 0;
}在 C++ 中,addStrings 函数返回的是一个局部对象 str
按照最原始的逻辑,局部变量在函数结束时会销毁
这段代码主要通过 RVO(返回值优化) 和 移动语义
- 如果编译器因为逻辑太复杂没能触发
NRVO,C++11引入的移动构造函数- 当编译器看到你返回了函数内部定义的
str时,它不再在addStrings的栈帧里创建str,而是直接在调用者(如main函数)的栈帧里预留ret的空间 - 原本的创建
str-> 拷贝给临时对象 -> 拷贝给ret过程,被简化成了直接在 ret 的位置进行操作
- 当编译器看到你返回了函数内部定义的

直接初始化(移动构造)
cpp
bit::string ret = bit::addStrings("11111", "2222"); // 触发移动构造这里 str 是一个即将销毁的临时值(右值),ret 会直接"掠夺"它的资源,而不是重新开辟内存复制
-
bit::addStrings返回的是一个右值(临时对象)。 -
编译器会去
std::string的类定义里寻找最匹配的构造函数。 -
因为
std::string内部定义了string(string&&str),所以它会优先调用这个移动构造函数。 -
结果:
ret直接接管了函数返回值的内存,没有发生逐个字符的拷贝。
先定义再赋值(赋值运算符)
cpp
bit::string ret;
ret = bit::addStrings("11111", "2222");ret 会释放自己原来的旧空间,然后把 addStrings 返回的那个临时对象的内存指针"偷"过来。
-
这里
ret已经存在了。 -
编译器会调用
std::string内部定义的operator=(string&&str),即移动赋值运算符。 -
结果:
ret与临时对象交换了指针,效率极高。
七、右值引用(T&&)和移动语义 出现的核心场景
7.1)容器类
几乎所有管理动态内存或资源的类都实现了右值引用(移动语义)
-
std::vector<T>:移动时只需拷贝指向数组的指针、大小和容量,不需要拷贝整个数组。 -
std::list<T>、std::deque<T>:移动时直接接管整个链表或双端队列的控制权。 -
std::map<K,V>、std::unordered_map<K,V>:移动时接管整棵红黑树或哈希表。 -
std::string:正如我们之前讨论的。
7.2)智能指针
这个我们后面讲智能指针会讲到
7.3)输入输出流
std::fstream(文件流)std::stringstream(字符串流)
这些类禁用了拷贝构造,但支持移动构造。这意味着你不能把一个正在写的文件流复制给另一个变量,但你可以把它作为返回值传给调用者。
7.4)其他资源管理类
-
std::thread(线程对象):线程代表一个执行序列,是唯一的。你不能拷贝一个线程,但可以通过移动语义将线程的管理权转让。 -
std::promise<T>/std::future<T>:用于多线程异步通信,通常也是只许移动,不许拷贝。 -
std::function<T>:包装可调用对象,支持移动以提高效率。
八、 右值引用和移动语义在传参中的提效
右值引用和移动语义开辟了新的路:传值,但不拷贝,而是"偷"
-
核心原理:为什么能提效?
-
传统传参(拷贝):就像你要把一份厚文件给同事,你先去复印店复印一份,把复印件给他。你花钱、费纸、还慢
-
移动传参(偷):你发现你这份文件以后再也不用了,于是你直接把原件甩给了同事。你没花钱,速度极快,只是你手里变空了
❌ 传统方式:频繁深拷贝(效率低)
cpp
#include <iostream>
#include <vector>
#include <string>
void processData(std::vector<std::string> data) { // 传值
// 处理数据...
std::cout << "Data size: " << data.size() << std::endl;
}
int main() {
std::vector<std::string> largeData(1000000, "Heavy Data");
// 调用时会发生巨大的深拷贝!
processData(largeData);
return 0;
}✅ 移动语义:资源转让(效率高)
我们可以通过 std::move 将左值强制转为右值引用,从而触发移动语义
cpp
#include <iostream>
#include <vector>
#include <string>
// 重载一个接收右值引用的版本
void processData(std::vector<std::string>&& data) { // 注意这里的 &&
// data 此时直接接管了外部的内存,没有产生任何拷贝
std::cout << "Moving data, size: " << data.size() << std::endl;
} // 函数结束时,这块内存会被自动释放
int main() {
std::vector<std::string> largeData(1000000, "Heavy Data");
// std::move(largeData) 告诉编译器:
// "我不再需要 largeData 了,请把它当作右值处理,让函数把它的内存'偷'走吧!"
processData(std::move(largeData));
// 注意:此时 largeData 已经变空了,不能再使用了!
std::cout << "After move, original size: " << largeData.size() << std::endl; // 输出 0
return 0;
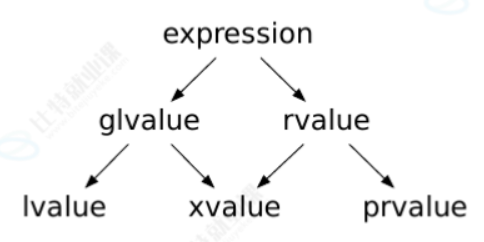
}九、类型分类
-
C++11以后,进一步对类型进行了划分,右值被划分纯右值(pure,简称prvalue)和将亡值(expiring,简称xvalue)。 -
纯右值是指那些字面值常量或求值结果相当于字面值或是一个不具名的临时对象。如:
42、true、nullptr或者类似str.substr(1,2)、str1+str2传值返回函数调用,或者整形a、b、a++,a+b等。纯右值和将亡值C++11中提出的,C++11中的纯右值概念划分等价于C++98中的右值。 -
将亡值是指返回右值引用的函数的调用表达式和转换为右值引用的转换函数的调用表达,如
move(x)、static_cast<X&&>(x) -
泛左值
(generalized,简称glvalue),泛左值包含将亡值和左值。 -
值类别 -cppreference.com关于值类型的官方文档,有兴趣可以了解细节。
十、引用折叠
在 C++ 中,你不能直接写出引用的引用,例如 int& & p = a; 会导致编译报错
但在模板编程或 using/typedef 别名定义中,这种情况会不可避免地发生
cpp
template<typename T>
void func(T&& param); // 这里的 T&& 是"万能引用"如果用户传入一个左值 int&,那么 T 就会被推导为 int&。此时模板实例化后的形式变成了 int& &&。为了让代码能跑通,编译器必须有一套规则把这些嵌套引用"拍扁"成单一引用
口诀
口诀非常简单:"只有双右为右,否则全为左"
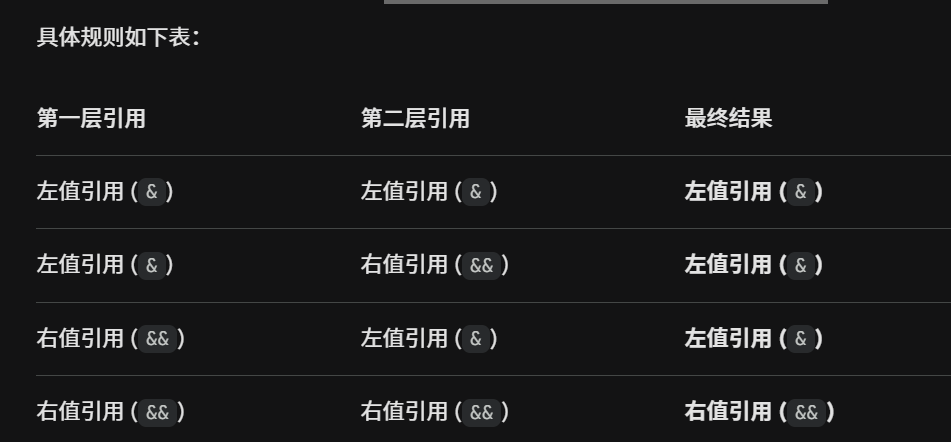
总结: 只要组合中出现了任何一个左值引用(&),结果就是左值引用。只有当两个都是右值引用(&&)时,结果才是右值引用
十一、完美转发
让一个函数把收到的参数,"原封不动"地转交给另一个函数
- 我们看下面的代码:
cpp
void target(int& x); // 处理左值
void target(int&& x); // 处理右值
template<typename T>
void wrapper(T&& arg) {
target(arg); // 报错隐患:这里的 arg 永远是左值!
}
int main() {
wrapper(10); // 10 本是右值,但在 wrapper 内部,arg 有名字,变成了左值
// 这会导致它去调用 target(int&),而不是 target(int&&)
}当我们调用 wrapper(10) 时:
1. 第一步(折叠规则生效):
10是右值,T被推导为int。T&&变成int&&。这里确实符合你说的"双右为右"。- 此时,
arg的类型确定了:它是int&&(右值引用)。
2. 第二步(传参过程):
- 进入函数体,执行
target(arg);。 - 此时编译器看
arg:这是一个变量名。 - 编译器判断:
arg是一个左值表达式。 - 匹配函数:
target(int&)。
为了把 arg 的"右值属性"找回来,我们需要 std::forward
cpp
template<typename T>
void wrapper(T&& arg) {
// std::forward 的作用就是:
// 如果 T 推导出来是右值类型,它就把 arg 重新转换为"无名右值"
target(std::forward<T>(arg));
}核心秘诀:std::forward
std::forward 的工作就是:
- 如果
T被推导为左值引用(如int&),它就把参数转成左值。 - 如果
T被推导为原始类型(说明进来的是右值),它就把参数转成右值。
💻结尾--- 核心连接协议
警告: 🌠🌠正在接入底层技术矩阵。如果你已成功破解学习中的逻辑断层,请执行以下指令序列以同步数据:🌠🌠
【📡】 建立深度链接: 关注本终端。在赛博丛林中深耕底层架构,从原始代码到进阶协议,同步见证每一次系统升级。
【⚡】 能量过载分发: 执行点赞操作。通过高带宽分发,让优质模组在信息流中高亮显示,赋予知识跨维度的传播力。
【💾】 离线缓存核心: 将本页加入收藏。把这些高频实战逻辑存入你的离线存储器,在遭遇系统崩溃或需要离线检索时,实现瞬时读取。
【💬】 协议加密解密: 在评论区留下你的散列码。分享你曾遭遇的代码冲突或系统漏洞(那些年踩过的坑),通过交互式编译共同绕过技术陷阱。
【🛰️】 信号频率投票: 通过投票发射你的选择。你的每一次点击都在重新定义矩阵的进化方向,决定下一个被全量拆解的技术节点。

